Diagnostyka modułu równoważenia obciążenia w warstwie Standardowa przy użyciu metryk, alertów i kondycji zasobów
Usługa Azure Load Balancer uwidacznia następujące możliwości diagnostyczne:
Metryki i alerty wielowymiarowe: udostępnia wielowymiarowe możliwości diagnostyczne za pośrednictwem usługi Azure Monitor dla konfiguracji usługi Azure Load Balancer. Możesz monitorować zasoby modułu równoważenia obciążenia w warstwie Standardowa i zarządzać nimi oraz zarządzać nimi.
Kondycja zasobu: Stan kondycji zasobu modułu równoważenia obciążenia jest dostępny na stronie Kondycja zasobu w obszarze Monitorowanie. Ta automatyczna kontrola informuje o bieżącej dostępności zasobu modułu równoważenia obciążenia.
Ten artykuł zawiera krótki przewodnik po tych funkcjach i oferuje sposoby ich używania na potrzeby standardowego modułu równoważenia obciążenia.
Metryki wielowymiarowe
Usługa Azure Load Balancer udostępnia metryki wielowymiarowe za pośrednictwem metryk platformy Azure w witrynie Azure Portal i pomaga uzyskać szczegółowe informacje diagnostyczne dotyczące zasobów modułu równoważenia obciążenia w czasie rzeczywistym. Należy pamiętać, że metryki wielowymiarowe nie są obsługiwane w przypadku podstawowych modułów równoważenia obciążenia
Różne konfiguracje modułu równoważenia obciążenia zawierają następujące metryki:
| Metric | Typ zasobu | opis | Zalecana agregacja |
|---|---|---|---|
| Dostępność ścieżki danych | Publiczny i wewnętrzny moduł równoważenia obciążenia | Moduł równoważenia obciążenia stale używa ścieżki danych z regionu do frontonu modułu równoważenia obciążenia do sieci obsługującej maszynę wirtualną. Jeśli wystąpienia są w dobrej kondycji, pomiar jest zgodny z tą samą ścieżką co ruch z równoważeniem obciążenia aplikacji. Ścieżka danych używana jest weryfikowana. Pomiar jest niewidoczny dla aplikacji i nie zakłóca innych operacji. | Średnia |
| Stan sondy kondycji | Publiczny i wewnętrzny moduł równoważenia obciążenia | Moduł równoważenia obciążenia używa rozproszonej usługi sondowania kondycji, która monitoruje kondycję punktu końcowego aplikacji zgodnie z ustawieniami konfiguracji. Ta metryka zawiera zagregowany widok lub widok filtrowany dla każdego punktu końcowego wystąpienia w puli modułu równoważenia obciążenia. Możesz zobaczyć, jak moduł równoważenia obciążenia wyświetla kondycję aplikacji, zgodnie z konfiguracją sondy kondycji. | Średnia |
| Liczba znaków SYN | Publiczny i wewnętrzny moduł równoważenia obciążenia | Moduł równoważenia obciążenia nie przerywa połączeń protokołu TCP (Transmission Control Protocol) ani nie wchodzi w interakcje z przepływami TCP lub User Data-Gram Packet (UDP). Przepływy i ich uzgodnienia są zawsze realizowane między wystąpieniem źródłowym a wystąpieniem maszyny wirtualnej. Aby lepiej rozwiązać problemy ze scenariuszami protokołu TCP, można użyć liczników pakietów SYN w celu sprawdzenia, ile wykonano prób połączenia TCP. Metryka zgłasza liczbę odebranych pakietów TCP SYN. | Sum |
| Liczba połączeń translacji adresów sieciowych źródła (SNAT) | Publiczny moduł równoważenia obciążenia | Moduł równoważenia obciążenia zgłasza liczbę przepływów wychodzących, które są podszywane do frontonu publicznego adresu IP. Porty SNAT to wyczerpany zasób. Ta metryka może wskazywać na to, jak bardzo aplikacja jest zależna od translatora SNAT dla przepływów przychodzących. Są zgłaszane liczniki dla przepływów wychodzących SNAT zakończonych powodzeniem i niepowodzeniem. Liczniki mogą służyć do rozwiązywania problemów i zrozumienia kondycji przepływów wychodzących. | Sum |
| Przydzielone porty SNAT | Publiczny moduł równoważenia obciążenia | Moduł równoważenia obciążenia zgłasza liczbę portów SNAT przydzielonych na wystąpienie zaplecza | Średnia. |
| Używane porty SNAT | Publiczny moduł równoważenia obciążenia | Moduł równoważenia obciążenia zgłasza liczbę portów SNAT, które są używane na wystąpienie zaplecza. | Średnia |
| Liczba bajtów | Publiczny i wewnętrzny moduł równoważenia obciążenia | Moduł równoważenia obciążenia raportuje dane przetwarzane na fronton. Możesz zauważyć, że bajty nie są równomiernie dystrybuowane w wystąpieniach zaplecza. Jest to oczekiwane, ponieważ algorytm usługi Azure Load Balancer jest oparty na przepływach | Sum |
| Liczba pakietów | Publiczny i wewnętrzny moduł równoważenia obciążenia | Moduł równoważenia obciążenia raportuje pakiety przetwarzane na fronton. | Sum |
Uwaga
Metryki związane z przepustowością, takie jak pakiet SYN, liczba bajtów i liczba pakietów, nie przechwytują żadnego ruchu do wewnętrznego modułu równoważenia obciążenia za pośrednictwem trasy zdefiniowanej przez użytkownika (np. z urządzenia WUS lub zapory).
Agregacje maksymalne i minimalne nie są dostępne dla metryk liczby synów, liczby pakietów, liczby połączeń SNAT i liczby bajtów. Agregacja liczby nie jest zalecana w przypadku dostępności ścieżki danych i stanu sondy kondycji. Zamiast tego użyj średniej, aby najlepiej przedstawiać dane dotyczące kondycji.
Wyświetlanie metryk modułu równoważenia obciążenia w witrynie Azure Portal
Witryna Azure Portal uwidacznia metryki modułu równoważenia obciążenia za pośrednictwem strony Metryki. Ta strona jest dostępna zarówno na stronie zasobu modułu równoważenia obciążenia dla określonego zasobu, jak i na stronie usługi Azure Monitor.
Uwaga
Usługa Azure Load Balancer nie wysyła sond kondycji do cofniętych przydziałów maszyn wirtualnych. Po cofnięciu przydziału maszyn wirtualnych moduł równoważenia obciążenia przestanie zgłaszać metryki dla tego wystąpienia. Metryki, które są niedostępne, będą wyświetlane jako linia przerywana w portalu lub wyświetlają komunikat o błędzie wskazujący, że nie można pobrać metryk.
Aby wyświetlić metryki dla zasobów modułu równoważenia obciążenia:
Przejdź do strony metryk i wykonaj jedno z następujących zadań:
Na stronie zasobu modułu równoważenia obciążenia wybierz typ metryki z listy rozwijanej.
Na stronie Azure Monitor wybierz zasób modułu równoważenia obciążenia.
Ustaw odpowiedni typ agregacji metryk.
Opcjonalnie skonfiguruj wymagane filtrowanie i grupowanie.
Opcjonalnie skonfiguruj zakres czasu i agregację. Domyślnie czas jest wyświetlany w formacie UTC.
Uwaga
Agregacja czasu jest ważna podczas interpretowania określonych metryk, ponieważ dane są próbkowane raz na minutę. Jeśli agregacja czasu jest ustawiona na pięć minut, a typ agregacji metryk Sum jest używany dla metryk, takich jak alokacja SNAT, wykres będzie wyświetlany pięć razy więcej przydzielonych portów SNAT.
Zalecenie: Podczas analizowania typu agregacji metryki Sum i Count zalecamy użycie wartości agregacji czasu, która jest większa niż minuta.
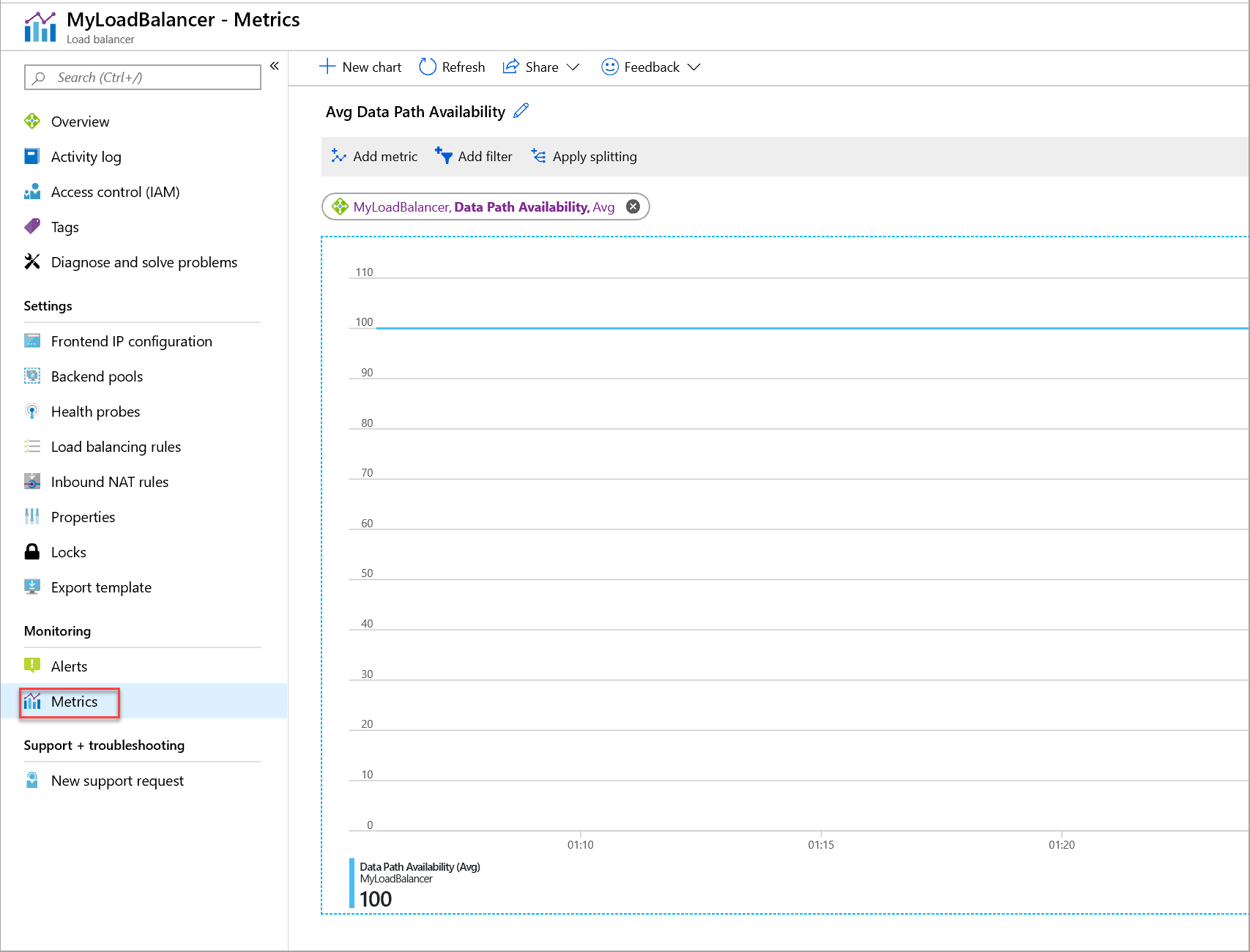
Rysunek: Metryka dostępności ścieżki danych dla standardowego modułu równoważenia obciążenia
Programowe pobieranie metryk wielowymiarowych za pośrednictwem interfejsów API
Aby uzyskać wskazówki dotyczące interfejsu API pobierania wielowymiarowych definicji i wartości metryk, zobacz Przewodnik po interfejsie API REST monitorowania platformy Azure. Te metryki można zapisywać na koncie magazynu, dodając ustawienie diagnostyczne dla kategorii "Wszystkie metryki".
Typowe scenariusze diagnostyczne i zalecane widoki
Czy ścieżka danych jest w górę i dostępna dla frontonu modułu równoważenia obciążenia?
Rozszerzać
Metryka Dostępność ścieżki danych opisuje kondycję w regionie ścieżki danych do hosta obliczeniowego, na którym znajdują się maszyny wirtualne. Metryka jest odzwierciedleniem kondycji modułu równoważenia obciążenia na podstawie konfiguracji i infrastruktury platformy Azure. Za pomocą metryki można wykonywać następujące czynności:
Monitoruj zewnętrzną dostępność usługi.
Zbadaj platformę, na której wdrożono usługę, i ustal, czy jest w dobrej kondycji. Ustal, czy system operacyjny gościa lub wystąpienie aplikacji jest w dobrej kondycji.
Izoluj, czy zdarzenie jest powiązane z usługą, czy bazową płaszczyzną danych. Nie należy mylić tej metryki z metryki Stan sondy kondycji.
Aby uzyskać dostępność ścieżki danych dla zasobów modułu równoważenia obciążenia:
Upewnij się, że wybrano prawidłowy zasób modułu równoważenia obciążenia.
Z listy rozwijanej Metryka wybierz pozycję Dostępność ścieżki danych.
Z listy rozwijanej Agregacja wybierz pozycję Średnia.
Ponadto dodaj filtr dla adresu IP frontonu lub portu frontonu jako wymiar z wymaganym adresem IP frontonu lub portem frontonu. Następnie pogrupuj je według wybranego wymiaru.
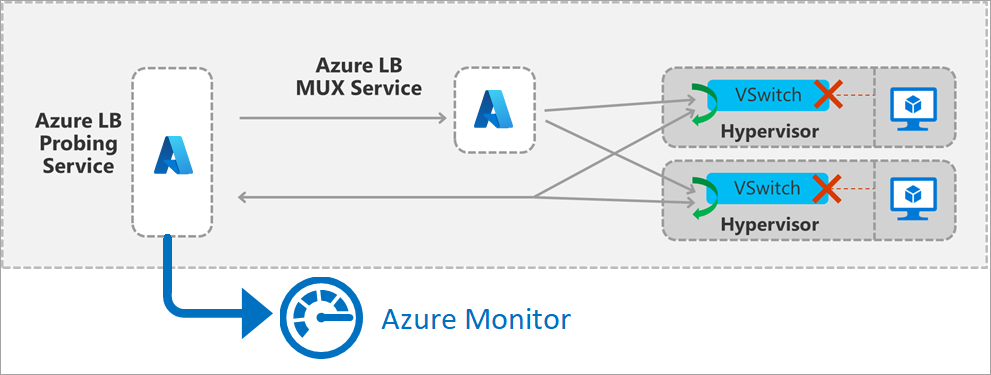
Rysunek: Szczegóły sondowania frontonu modułu równoważenia obciążenia
Metryka jest generowana przez usługę sondowania w regionie, który symuluje ruch. Usługa sondowania okresowo generuje pakiet zgodny z frontonem wdrożenia i regułą równoważenia obciążenia. Następnie pakiet przechodzi przez region ze źródła do hosta maszyny wirtualnej w puli zaplecza. Infrastruktura modułu równoważenia obciążenia wykonuje te same operacje równoważenia obciążenia i tłumaczenia, co w przypadku całego innego ruchu. Po nadejściu sondy na hoście, gdzie znajduje się maszyna wirtualna w puli zaplecza, host generuje odpowiedź na usługę sondowania. Maszyna wirtualna nie widzi tego ruchu.
Należy pamiętać, że metryka Dostępność ścieżki danych zostanie wygenerowana tylko w konfiguracjach adresów IP frontonu z regułami równoważenia obciążenia.
Metryka dostępność ścieżki danych może być obniżona z następujących powodów:
Wdrożenie nie ma maszyn wirtualnych w dobrej kondycji pozostałych w puli zaplecza.
Wystąpiła awaria infrastruktury.
W celach diagnostycznych można użyć metryki na potrzeby dostępności ścieżki danych wraz ze stanem sondy kondycji.
W przypadku większości scenariuszy użyj opcji Average (Średnia ) jako agregacji.
Czy wystąpienia zaplecza dla modułu równoważenia obciążenia odpowiadają na sondy?
Rozszerzać
Metryka Stan sondy kondycji opisuje kondycję wdrożenia aplikacji zgodnie z konfiguracją podczas konfigurowania sondy kondycji modułu równoważenia obciążenia. Moduł równoważenia obciążenia używa stanu sondy kondycji, aby określić, gdzie wysyłać nowe przepływy. Sondy kondycji pochodzą z adresu infrastruktury platformy Azure i są widoczne w systemie operacyjnym gościa maszyny wirtualnej.
Aby uzyskać metrykę Stan sondy kondycji dla zasobów modułu równoważenia obciążenia:
Wybierz metrykę Stan sondy kondycji z typem Śr. agregacja.
Zastosuj filtr do wymaganego adresu IP lub portu frontonu (albo obu).
Sondy kondycji kończą się niepowodzeniem z następujących powodów:
Należy skonfigurować sondę kondycji do portu, który nie nasłuchuje lub nie odpowiada lub używa nieprawidłowego protokołu. Jeśli usługa używa reguł zwrotu serwera bezpośredniego lub pływających adresów IP, sprawdź, czy usługa nasłuchuje na adresie IP konfiguracji adresu IP karty sieciowej i sprzężenia zwrotnego skonfigurowanego przy użyciu adresu IP frontonu.
Sieciowa grupa zabezpieczeń, zapora systemu operacyjnego gościa maszyny wirtualnej lub filtry warstwy aplikacji nie zezwalają na ruch sondy kondycji.
W przypadku większości scenariuszy użyj opcji Average (Średnia ) jako agregacji.
Jak mogę sprawdzić statystyki połączeń wychodzących?
Rozszerzać
Metryka Połączeń SNAT opisuje liczbę pomyślnych i zakończonych niepowodzeniem połączeń dla przepływów wychodzących.
Liczba nieudanych połączeń większa niż zero wskazuje na wyczerpanie portów SNAT. Należy dokładniej zbadać, co może powodować te błędy. Manifesty wyczerpania portów SNAT jako błąd ustanowienia przepływu wychodzącego. Zapoznaj się z artykułem dotyczącym połączeń wychodzących, aby zrozumieć scenariusze i mechanizmy w pracy oraz dowiedzieć się, jak ograniczyć i zaprojektować, aby uniknąć wyczerpania portów SNAT.
Aby uzyskać statystyki połączeń SNAT:
Wybierz typ metryki Połączenia SNAT i Sum jako agregację.
Pogrupuj według stanu połączenia, aby pomyślnie i nie powiodło się liczba połączeń SNAT, które mają być reprezentowane przez różne wiersze.
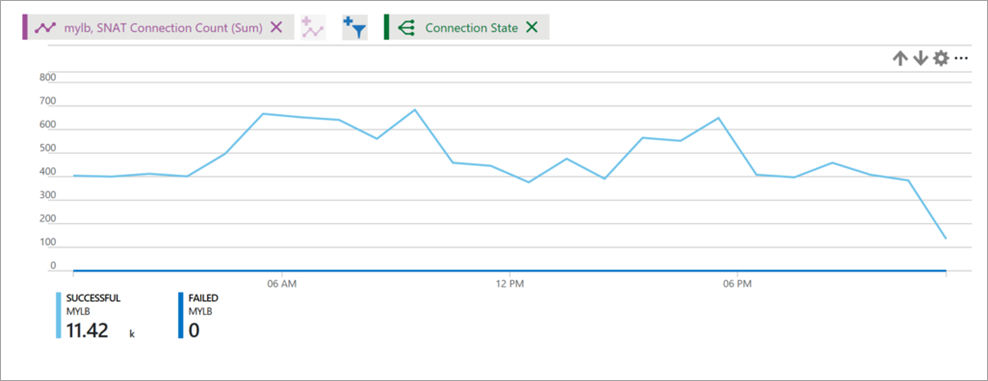
Rysunek: Liczba połączeń SNAT modułu równoważenia obciążenia
Jak mogę sprawdzić użycie i alokację portów SNAT?
Rozszerzać
Używana metryka portów SNAT śledzi liczbę używanych portów SNAT do obsługi przepływów wychodzących. Ta metryka wskazuje, ile unikatowych przepływów jest ustanawianych między źródłem internetowym a maszyną wirtualną zaplecza lub zestawem skalowania maszyn wirtualnych, który znajduje się za modułem równoważenia obciążenia i nie ma publicznego adresu IP. Porównując liczbę portów SNAT używanych z metryki Przydzielone porty SNAT, możesz określić, czy w twojej usłudze występuje wyczerpanie portów SNAT lub występuje ryzyko awarii przepływu wychodzącego.
Jeśli metryki wskazują na ryzyko awarii przepływu wychodzącego, zapoznaj się z artykułem i podejmij kroki w celu ograniczenia tego problemu w celu zapewnienia kondycji usługi.
Aby wyświetlić użycie i alokację portów SNAT:
Ustaw agregację czasu grafu na 1 minutę, aby upewnić się, że są wyświetlane żądane dane.
Wybierz pozycję Używane porty SNAT i/lub Przydzielone porty SNAT jako typ metryki i Średnia jako agregacja.
Domyślnie te metryki są średnią liczbą portów SNAT przydzielonych lub używanych przez każdą maszynę wirtualną zaplecza lub zestaw skalowania maszyn wirtualnych. Odpowiadają one wszystkim publicznym adresom IP frontonu zamapowanym na moduł równoważenia obciążenia zagregowany za pośrednictwem protokołów TCP i UDP.
Aby wyświetlić łączną liczbę portów SNAT używanych przez lub przydzielonych dla modułu równoważenia obciążenia, użyj agregacji metryk Suma.
Filtruj do określonego typu protokołu, zestawu adresów IP zaplecza i/lub adresów IP frontonu.
Aby monitorować kondycję na zaplecze lub wystąpienie frontonu, zastosuj dzielenie.
- Dzielenie notatek umożliwia wyświetlanie tylko jednej metryki naraz.
Aby na przykład monitorować użycie protokołu SNAT dla przepływów TCP na maszynę, agregować według wartości Średnia, podzielić według adresów IP zaplecza i filtrować według typu protokołu.
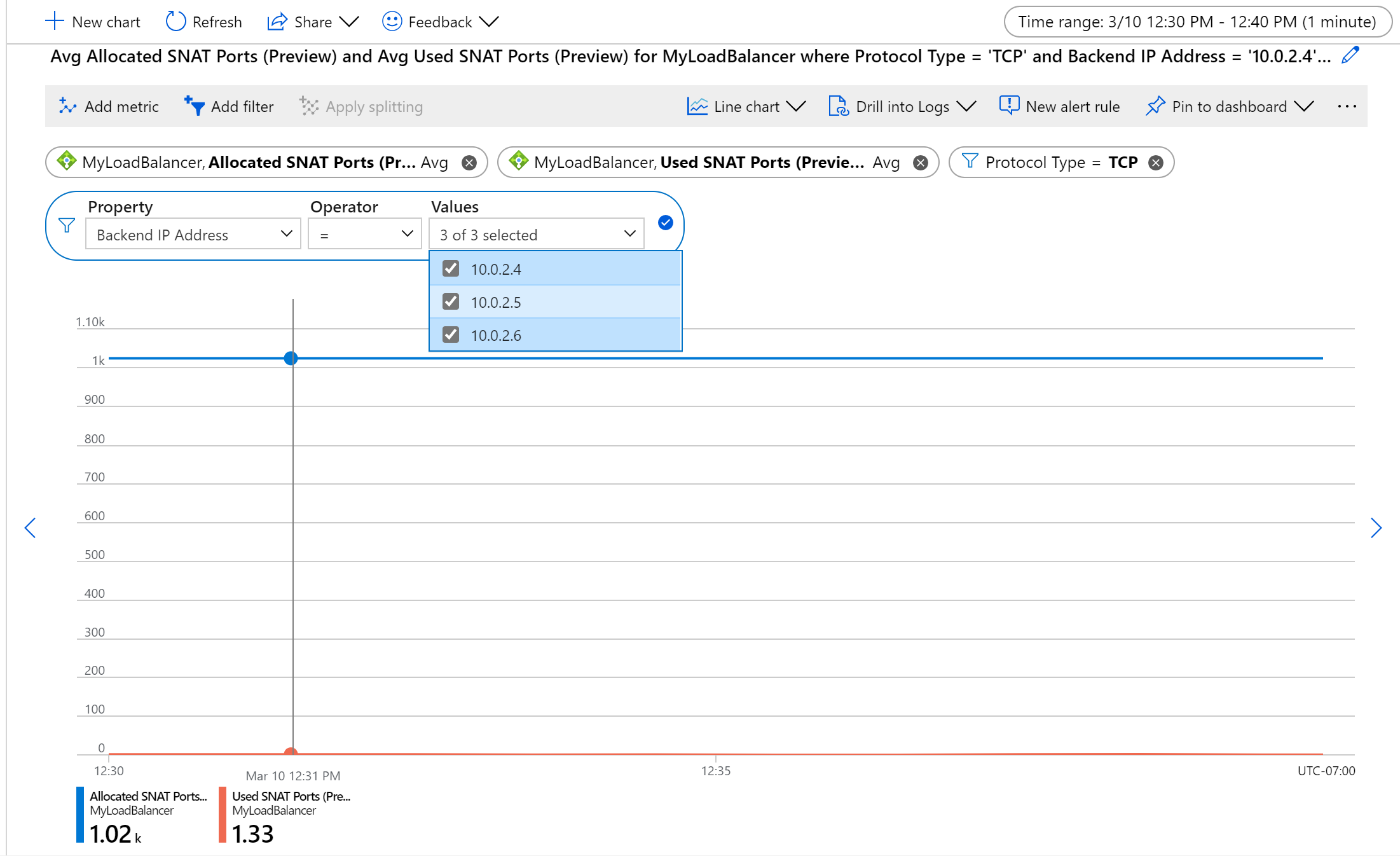
Rysunek: Średnia alokacja i użycie portów SNAT protokołu TCP dla zestawu maszyn wirtualnych zaplecza
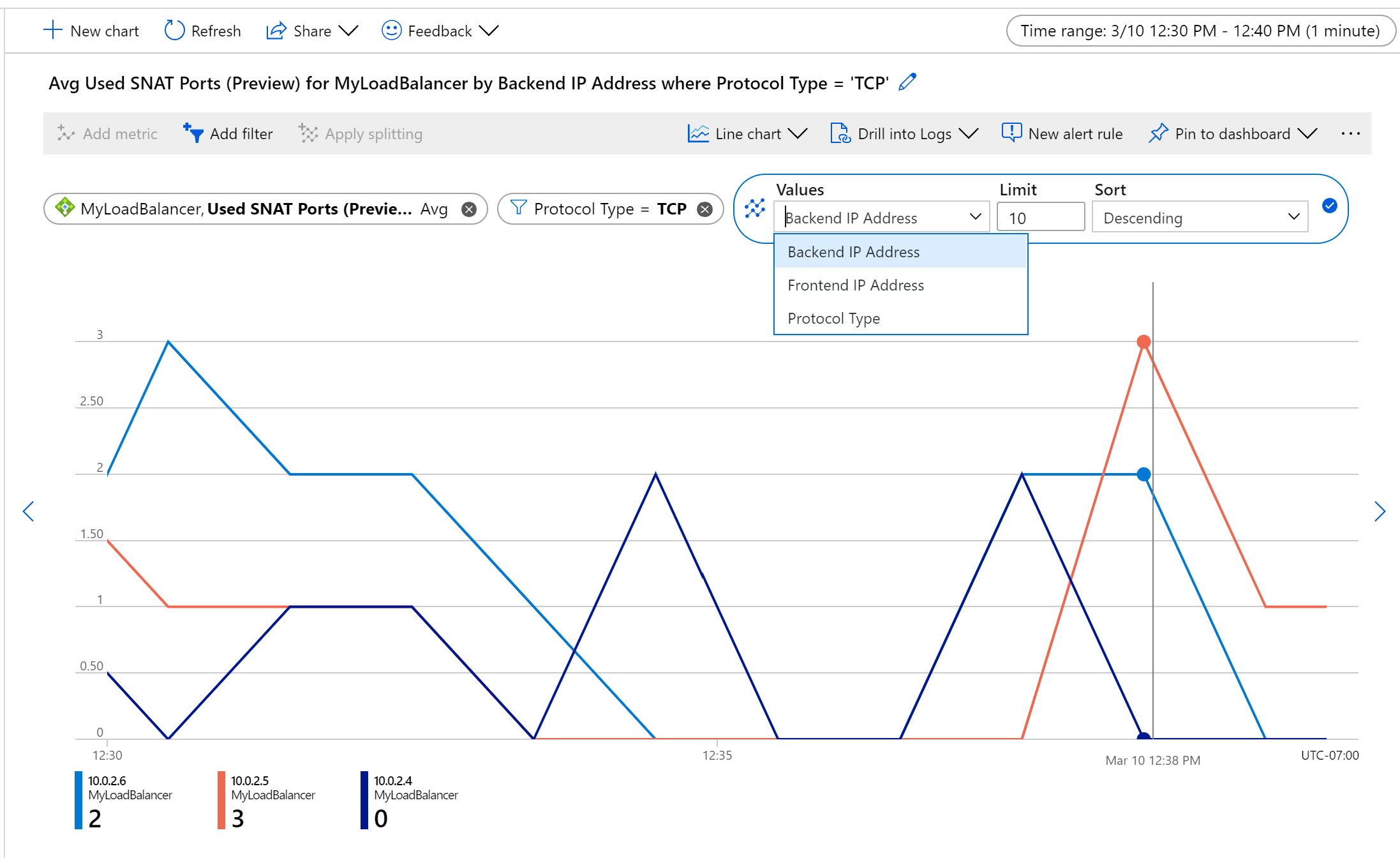
Rysunek: Użycie portów SNAT protokołu TCP na wystąpienie zaplecza
Jak mogę sprawdzić próby połączenia przychodzącego/wychodzącego dla mojej usługi?
Rozwiń
metrykę Pakiety SYN opisuje wolumin pakietów TCP SYN, które dotarły lub zostały wysłane dla przepływów wychodzących skojarzonych z określonym frontonem. Tej metryki można użyć do zrozumienia prób połączenia TCP z usługą.Aby uzyskać więcej informacji na temat połączeń wychodzących, zobacz Source Network Address Translation (SNAT) for outbound connections (Source Network Address Translation) for outbound connections (Translacja adresów sieciowych (SNAT) dla połączeń wychodzących
W przypadku większości scenariuszy użyj opcji Suma jako agregacji.
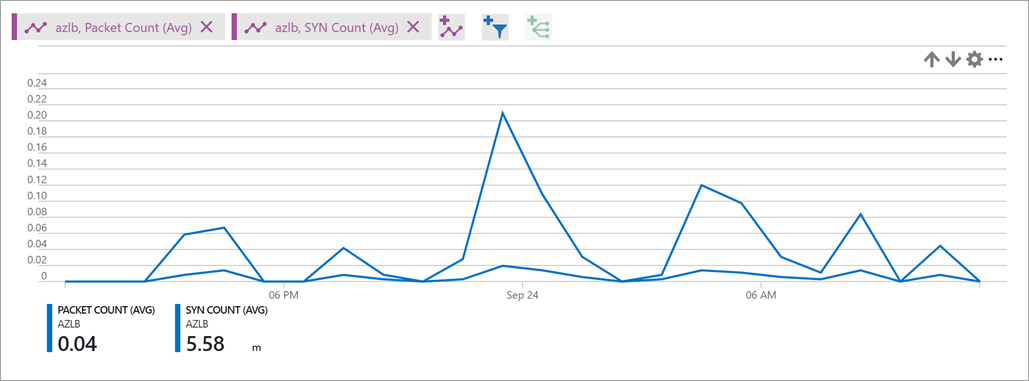
Rysunek: Liczba synów modułu równoważenia obciążenia
Jak mogę sprawdzić użycie przepustowości sieci?
Rozszerzać
Metryka bajtów i liczników pakietów opisuje ilość bajtów i pakietów wysyłanych lub odbieranych przez usługę dla poszczególnych frontonów.
W przypadku większości scenariuszy użyj opcji Suma jako agregacji.
Aby uzyskać statystyki liczby bajtów lub pakietów:
Wybierz typ metryki Liczba bajtów i/lub Liczba pakietów z sumą jako agregacją.
Wykonaj jedną z następujących czynności:
Zastosuj filtr dla określonego adresu IP frontonu, portu frontonu, adresu IP zaplecza lub portu zaplecza.
Uzyskaj ogólne statystyki dla zasobu modułu równoważenia obciążenia bez żadnego filtrowania.
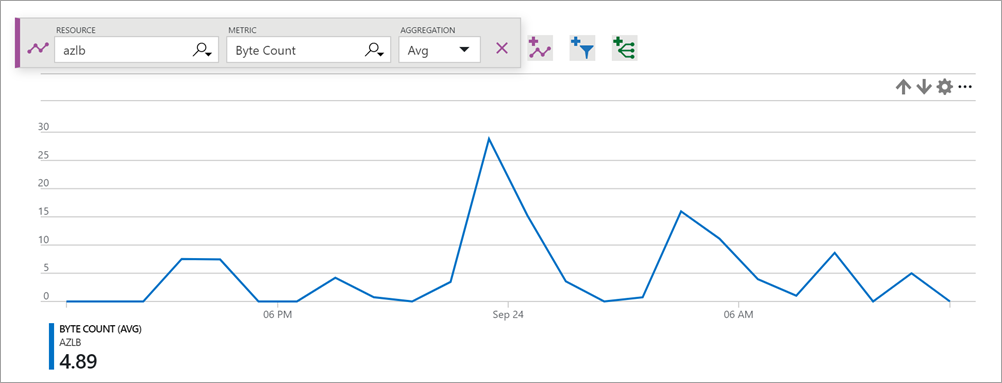
Rysunek: Liczba bajtów modułu równoważenia obciążenia
Jak mogę zdiagnozować wdrożenie modułu równoważenia obciążenia?
Rozszerzać
Korzystając z kombinacji metryk dostępności ścieżki danych i stanu sondy kondycji na pojedynczym wykresie, możesz określić, gdzie szukać problemu i rozwiązać problem. Możesz uzyskać pewność, że platforma Azure działa prawidłowo i użyj tej wiedzy, aby jednoznacznie określić, czy konfiguracja lub aplikacja jest główną przyczyną.
Możesz użyć metryk sondy kondycji, aby zrozumieć, jak platforma Azure wyświetla kondycję wdrożenia zgodnie z podaną konfiguracją. Patrząc na sondy kondycji, zawsze jest to doskonały pierwszy krok w monitorowaniu lub określaniu przyczyny.
Możesz wykonać krok dalej i użyć metryki dostępności ścieżki danych, aby uzyskać wgląd w sposób, w jaki platforma Azure wyświetla kondycję bazowej płaszczyzny danych, która jest odpowiedzialna za konkretne wdrożenie. Po połączeniu obu metryk możesz odizolować miejsce, w którym może występować błąd, jak pokazano w tym przykładzie:
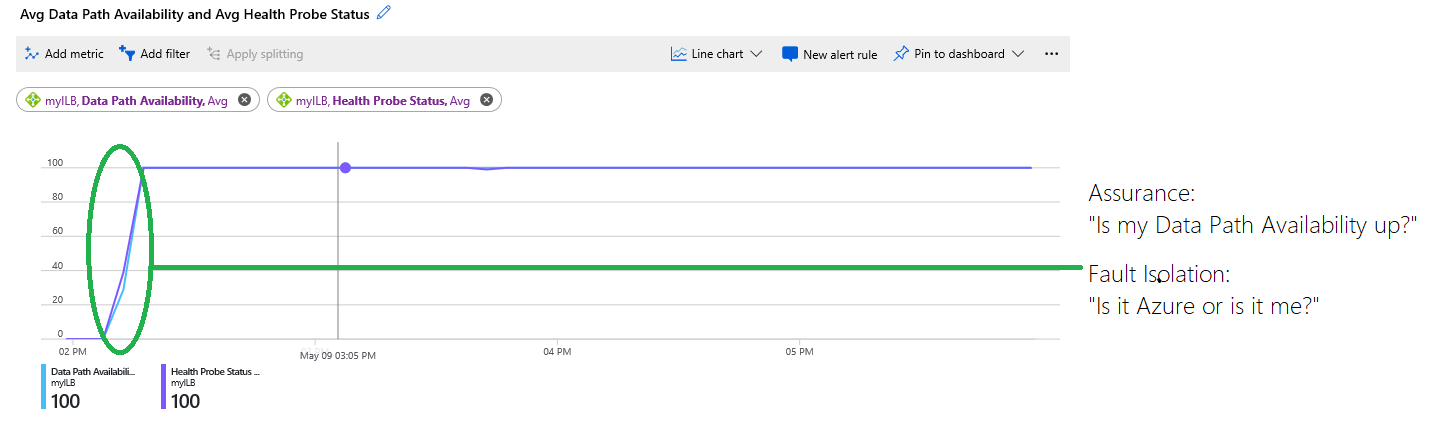
Rysunek: Łączenie metryk dostępności ścieżki danych i stanu sondy kondycji
Na wykresie są wyświetlane następujące informacje:
Infrastruktura hostująca maszyny wirtualne była niedostępna i na początku wykresu wynosiła 0%. Później infrastruktura była w dobrej kondycji, a maszyny wirtualne były osiągalne, a na zapleczu umieszczono więcej niż jedną maszynę wirtualną. Te informacje są wskazywane przez niebieski ślad dostępności ścieżki danych, który później wynosił 100%.
Stan sondy kondycji wskazywany przez fioletowy ślad wynosi 0% na początku wykresu. Obszar okręgowy w kolorze zielonym wyróżnia miejsce, w którym stan sondy kondycji stał się w dobrej kondycji i w którym momencie wdrożenie klienta mogło akceptować nowe przepływy.
Wykres umożliwia klientom samodzielne rozwiązywanie problemów z wdrożeniem bez konieczności odgadnięcia lub pytania pomocy technicznej, czy występują inne problemy. Usługa była niedostępna, ponieważ sondy kondycji zakończyły się niepowodzeniem z powodu błędnej konfiguracji lub aplikacji, która zakończyła się niepowodzeniem.
Konfigurowanie alertów dla metryk wielowymiarowych
Usługa Azure Load Balancer obsługuje łatwe konfigurowanie alertów dla metryk wielowymiarowych. Skonfiguruj niestandardowe progi dla określonych metryk, aby wyzwalać alerty o różnych poziomach ważności, aby umożliwić monitorowanie zasobów dotykowych.
Aby skonfigurować alerty:
Przejdź do strony alertu modułu równoważenia obciążenia
Tworzenie nowej reguły alertu
Skonfiguruj warunek alertu (Uwaga: aby uniknąć hałaśliwych alertów, zalecamy skonfigurowanie alertów z typem agregacji ustawionym na Wartość Średnia, patrząc wstecz na pięciominutowe okno danych i z progiem 95%)
(Opcjonalnie) Dodawanie grupy akcji na potrzeby automatycznej naprawy
Przypisz ważność, nazwę i opis alertu, który umożliwia intuicyjną reakcję
Alerty dotyczące dostępności dla ruchu przychodzącego
Uwaga
Jeśli pule zaplecza modułu równoważenia obciążenia są puste, moduł równoważenia obciążenia nie będzie miał żadnych prawidłowych ścieżek danych do testowania. W związku z tym metryka dostępności ścieżki danych nie będzie dostępna, a żadne skonfigurowane alerty platformy Azure dotyczące metryki dostępności ścieżki danych nie będą wyzwalane.
Aby otrzymywać alerty dotyczące dostępności dla ruchu przychodzącego, można utworzyć dwa oddzielne alerty przy użyciu metryk dostępności ścieżki danych i stanu sondy kondycji. Klienci mogą mieć różne scenariusze, które wymagają określonej logiki alertów, ale poniższe przykłady są przydatne w przypadku większości konfiguracji.
Przy użyciu dostępności ścieżki danych można uruchamiać alerty, gdy określona reguła równoważenia obciążenia stanie się niedostępna. Ten alert można skonfigurować, ustawiając warunek alertu dla dostępności ścieżki danych i dzieląc je według wszystkich bieżących wartości i przyszłych wartości dla portu frontonu i adresu IP frontonu. Ustawienie logiki alertu na wartość mniejszą lub równą 0 spowoduje, że ten alert zostanie wyzwolony, gdy każda reguła równoważenia obciążenia przestanie odpowiadać. Ustaw stopień szczegółowości agregacji i częstotliwość oceny zgodnie z żądaną oceną.
W przypadku stanu sondy kondycji można otrzymywać alerty, gdy dane wystąpienie zaplecza nie może odpowiedzieć na sondę kondycji przez znaczną ilość czasu. Skonfiguruj warunek alertu, aby użyć metryki stanu sondy kondycji i podzielić według adresu IP zaplecza i portu zaplecza. Dzięki temu można wysyłać alerty oddzielnie dla poszczególnych wystąpień zaplecza, aby obsługiwać ruch na określonym porcie. Użyj średniego typu agregacji i ustaw wartość progową zgodnie z częstotliwość sondowania wystąpienia zaplecza i uznawany za próg dobrej kondycji.
Możesz również otrzymywać alerty na poziomie puli zaplecza, nie dzieląc ich przez żadne wymiary i używając średniego typu agregacji. Dzięki temu można skonfigurować reguły alertów, takie jak alert, gdy 50% elementów członkowskich puli zaplecza jest w złej kondycji.
Alerty dotyczące dostępności dla ruchu wychodzącego
W przypadku dostępności ruchu wychodzącego można skonfigurować dwa oddzielne alerty przy użyciu liczby połączeń SNAT i metryki portów SNAT.
Aby wykryć błędy połączeń wychodzących, skonfiguruj alert przy użyciu liczby połączeń SNAT i filtrowania do stanu połączenia = Niepowodzenie. Użyj agregacji Total (Łączna agregacja). Następnie możesz podzielić tę wartość według adresu IP zaplecza ustawionego na wszystkie bieżące i przyszłe wartości, aby otrzymywać alerty oddzielnie dla każdego wystąpienia zaplecza, w którym występują nieudane połączenia. Ustaw wartość progową na większą niż zero lub większą liczbę, jeśli spodziewasz się, że wystąpią pewne błędy połączeń wychodzących.
W przypadku używanych portów SNAT można otrzymywać alerty o wyższym ryzyku wyczerpania I awarii połączenia wychodzącego SNAT. Upewnij się, że dzielisz się przy użyciu adresu IP zaplecza i protokołu podczas korzystania z tego alertu. Użyj agregacji Średnia. Ustaw wartość progową na większą niż procent liczby przydzielonych portów na określone wystąpienie jest niebezpieczna. Na przykład skonfiguruj alert o niskiej ważności, gdy wystąpienie zaplecza używa 75% przydzielonych portów. Skonfiguruj alert o wysokiej ważności, gdy używa 90% lub 100% przydzielonych portów.
Stan kondycji zasobu
Stan kondycji zasobów modułu równoważenia obciążenia w warstwie Standardowa jest udostępniany za pośrednictwem istniejącej kondycji zasobu w obszarze Monitorowanie > Kondycja usługi. Jest ona oceniana co dwie minuty , mierząc dostępność ścieżki danych, która określa, czy punkty końcowe równoważenia obciążenia frontonu są dostępne.
| Stan kondycji zasobu | Opis |
|---|---|
| Dostępny | Zasób modułu równoważenia obciążenia w warstwie Standardowa jest w dobrej kondycji i jest dostępny. |
| Obniżona wydajność | Standardowy moduł równoważenia obciążenia ma zdarzenia inicjowane przez platformę lub użytkownika wpływające na wydajność. Metryka dostępności ścieżki danych zgłosiła mniej niż 90%, ale ponad 25% kondycji przez co najmniej dwie minuty. W przypadku tego stanu występuje umiarkowany do poważny efekt wydajności. Postępuj zgodnie z przewodnikiem rozwiązywania problemów z protokołem RHC, aby określić, czy istnieją zdarzenia inicjowane przez użytkownika powodujące wpływ na dostępność. |
| Niedostępny | Zasób modułu równoważenia obciążenia w warstwie Standardowa nie jest w dobrej kondycji. Metryka dostępności ścieżki danych zgłosiła mniej kondycji 25% przez co najmniej dwie minuty. W przypadku tego stanu występuje znaczący wpływ na wydajność lub brak dostępności dla łączności przychodzącej. Mogą wystąpić zdarzenia użytkownika lub platformy powodujące niedostępność. Postępuj zgodnie z przewodnikiem rozwiązywania problemów z protokołem RHC, aby określić, czy istnieją zdarzenia inicjowane przez użytkownika wpływające na dostępność. |
| Nieznane | Stan kondycji zasobu modułu równoważenia obciążenia nie został zaktualizowany lub nie odebrano informacji o dostępności ścieżki danych w ciągu ostatnich 10 minut. Ten stan powinien występować przejściowo i zmienić się na prawidłowy stan po otrzymaniu danych. |
Aby wyświetlić kondycję publicznych zasobów modułu równoważenia obciążenia w warstwie Standardowa:
Wybierz pozycję Monitor> Kondycja usługi.
Rysunek: Link kondycji usługi w usłudze Azure Monitor
Wybierz pozycję Kondycja zasobu, a następnie upewnij się, że wybrano pozycję Identyfikator subskrypcji i Typ zasobu = moduł równoważenia obciążenia.

Rysunek: Wybieranie zasobu dla widoku kondycji
Na liście wybierz zasób modułu równoważenia obciążenia, aby wyświetlić jego historyczny stan kondycji.
Rysunek: Stan kondycji zasobu
Ogólny opis stanu kondycji zasobu jest dostępny w dokumentacji dotyczącej kondycji zasobów.
Reguły alertów dotyczących kondycji zasobu
Alerty usługi Azure Resource Health mogą powiadamiać Cię niemal w czasie rzeczywistym, gdy stan kondycji zasobu modułu równoważenia obciążenia ulegnie zmianie. Zaleca się ustawienie alertów dotyczących kondycji zasobów w celu powiadamiania o tym, kiedy zasób modułu równoważenia obciążenia jest w stanie Obniżona lub Niedostępna .
Podczas tworzenia alertów usługi Azure Resource Health dla modułu równoważenia obciążenia platforma Azure wysyła powiadomienia o kondycji zasobów do subskrypcji platformy Azure. Alerty można tworzyć i dostosowywać na podstawie:
- Subskrypcja, której dotyczy problem
- Grupa zasobów, której dotyczy problem
- Typ zasobu, którego dotyczy problem (moduł równoważenia obciążenia)
- Określony zasób (dowolny zasób modułu równoważenia obciążenia, dla którego chcesz skonfigurować alert)
- Stan zdarzenia zasobu modułu równoważenia obciążenia, którego dotyczy problem
- Bieżący stan zasobu modułu równoważenia obciążenia, którego dotyczy problem
- Poprzedni stan zasobu modułu równoważenia obciążenia, którego dotyczy problem
- Typ przyczyny zasobu modułu równoważenia obciążenia, którego dotyczy problem
Możesz również skonfigurować, do kogo powinien zostać wysłany alert:
- Nowa grupa akcji (która może służyć do przyszłych alertów)
- Istniejąca grupa akcji
Aby uzyskać więcej informacji na temat konfigurowania tych alertów dotyczących kondycji zasobów, zobacz:
- Alerty dotyczące kondycji zasobów przy użyciu witryny Azure Portal
- Alerty dotyczące kondycji zasobów przy użyciu szablonów usługi Resource Manager
Następne kroki
- Dowiedz się więcej o analizie sieci.
- Dowiedz się więcej na temat używania usługi Insights do wyświetlania wstępnie skonfigurowanych metryk dla modułu równoważenia obciążenia.
- Dowiedz się więcej o module równoważenia obciążenia w warstwie Standardowa.