Samouczek 1. Przewidywanie ryzyka kredytowego — Machine Learning Studio (wersja klasyczna)
DOTYCZY: Machine Learning Studio (wersja klasyczna)
Machine Learning Studio (wersja klasyczna)  Azure Machine Learning
Azure Machine Learning
Ważne
Obsługa programu Machine Learning Studio (wersja klasyczna) zakończy się 31 sierpnia 2024 r. Zalecamy przejście do usługi Azure Machine Learning przed tym terminem.
Od 1 grudnia 2021 r. nie będzie można tworzyć nowych zasobów programu Machine Learning Studio (wersja klasyczna). Do 31 sierpnia 2024 r. można będzie nadal korzystać z istniejących zasobów programu Machine Learning Studio (wersja klasyczna).
- Zobacz informacje dotyczące przenoszenia projektów uczenia maszynowego z usługi ML Studio (klasycznej) do usługi Azure Machine Learning.
- Dowiedz się więcej o usłudze Azure Machine Learning
Dokumentacja programu ML Studio (wersja klasyczna) jest wycofywana i może nie być aktualizowana w przyszłości.
W tym samouczku szczegółowo przedstawiono proces opracowywania rozwiązania analizy predykcyjnej. Utworzysz prosty model w usłudze Machine Learning Studio (wersja klasyczna). Następnie wdrożysz model jako usługę internetową usługi Machine Learning. Wdrożony model może tworzyć przewidywania przy użyciu nowych danych. Ten samouczek jest pierwszą częścią trzyczęściowej serii.
Załóżmy, że chcesz przewidzieć ryzyko kredytowe osoby na podstawie informacji przekazanych we wniosku kredytowym.
Ocena ryzyka kredytowego to złożony problem, ale w tym samouczku zostanie on nieco uproszczony. Użyjesz go jako przykładu sposobu tworzenia rozwiązania analizy predykcyjnej przy użyciu usługi Machine Learning Studio (klasycznej). W tym rozwiązaniu użyjesz usługi aMachine Learning Studio (klasycznej) i usługi internetowej Machine Learning.
W tym trzyczęściowym samouczku zaczniesz od publicznie dostępnych danych ryzyka kredytowego. Następnie wdrożysz i wytrenujesz model predykcyjny. Na koniec wdrożysz model jako usługę internetową.
W tej części samouczka zostaną wykonane następujące czynności:
- Tworzenie obszaru roboczego usługi Machine Learning Studio (wersja klasyczna)
- Przekazywanie istniejących danych
- Tworzenie eksperymentu
Następnie możesz użyć tego eksperymentu, aby wytrenować modele w części 2 i wdrożyć je w części 3.
Wymagania wstępne
W tym samouczku założono, że wcześniej użyto usługi Machine Learning Studio (klasycznej) i że znasz pewne pojęcia dotyczące uczenia maszynowego. Nie zakładamy jednak, że jesteś ekspertem w którejkolwiek z tych dziedzin.
Jeśli wcześniej nie używano usługi Machine Learning Studio (klasycznej), możesz zacząć od przewodnika Szybki start, utwórz swój pierwszy eksperyment nauki o danych w usłudze Machine Learning Studio (wersja klasyczna). Przewodnik Szybki start przeprowadzi Cię przez usługę Machine Learning Studio (klasyczną) po raz pierwszy. Podstawowe informacje przedstawione w tym samouczku obejmują przeciąganie modułów i upuszczanie ich w obszarze eksperymentu, łączenie modułów ze sobą, uruchamianie eksperymentu oraz przeglądanie wyników.
Porada
Funkcjonalną kopię eksperymentu opracowywanego w tym samouczku można znaleźć w witrynie Azure AI Gallery. Przejdź do pozycji Samouczek — przewidywanie ryzyka kredytowego i kliknij pozycję Otwórz w programie Studio, aby pobrać kopię eksperymentu do obszaru roboczego usługi Machine Learning Studio (klasycznego).
Tworzenie obszaru roboczego usługi Machine Learning Studio (wersja klasyczna)
Aby użyć usługi Machine Learning Studio (klasycznej), musisz mieć obszar roboczy usługi Machine Learning Studio (wersja klasyczna). Ten obszar roboczy zawiera narzędzia potrzebne do tworzenia i publikowania eksperymentów oraz zarządzania nimi.
Aby utworzyć obszar roboczy, zobacz Tworzenie i udostępnianie obszaru roboczego usługi Machine Learning Studio (wersja klasyczna).
Po utworzeniu obszaru roboczego otwórz program Machine Learning Studio (klasyczny) (https://studio.azureml.net/Home). Jeśli masz więcej niż jeden obszar roboczy, możesz wybrać odpowiedni obszar roboczy na pasku narzędzi w prawym górnym rogu okna.
Porada
Jeśli jesteś właścicielem obszaru roboczego, możesz udostępniać eksperymenty, nad którymi pracujesz, zapraszając inne osoby do obszaru roboczego. Możesz to zrobić w usłudze Machine Learning Studio (klasycznym) na stronie USTAWIENIA . Wystarczy, że każdy użytkownik będzie miał konto Microsoft lub konto organizacji.
Na stronie SETTINGS (USTAWIENIA) kliknij pozycję USERS (UŻYTKOWNICY), a następnie kliknij przycisk INVITE MORE USERS (ZAPROŚ UŻYTKOWNIKÓW) w dolnej części okna.
Przekazywanie istniejących danych
Aby opracować model predykcyjny na potrzeby oceny ryzyka kredytowego, potrzebujesz danych, których można użyć do wytrenowania, a następnie przetestowania modelu. Na potrzeby tego samouczka użyjesz zestawu danych „UCI Statlog (German Credit Data) Data Set” z repozytorium UC Irvine Machine Learning. Znajdziesz go tutaj:
https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)
Użyjesz pliku o nazwie german.data. Pobierz ten plik na lokalny dysk twardy.
Zestaw danych german.data zawiera wiersze 20 zmiennych z 1000 złożonych w przeszłości wniosków kredytowych. Tych 20 zmiennych reprezentuje zestaw cech tego zestawu danych (wektor cech), który dostarcza charakterystyki identyfikujące każdego wnioskodawcę kredytowego. Dodatkowa kolumna w każdym wierszu reprezentuje obliczone ryzyko kredytowe wnioskodawcy, przy czym dla 700 kandydatów ryzyko kredytowe oceniono jako niskie, a dla 300 kandydatów jako wysokie.
Witryna internetowa UCI zawiera opis atrybutów wektora cech dla tych danych. Te dane obejmują informacje finansowe, historię kredytową, stan zatrudnienia i dane osobowe. Każdy wnioskodawca został poddany klasyfikacji binarnej, która wskazuje, czy jego ryzyko kredytowe jest wysokie, czy niskie.
Użyjesz tych danych, aby wytrenować model analizy predykcyjnej. Po zakończeniu model powinien być w stanie zaakceptować wektor funkcji dla nowej osoby i przewidzieć, czy są niskie, czy wysokie ryzyko kredytowe.
Jest jeszcze pewien interesujący zwrot.
Opis zestawu danych w witrynie internetowej UCI zawiera informację, jakie są koszty, jeśli ryzyko kredytowe osoby zostanie ocenione błędnie. Jeśli model przewidzi wysokie ryzyko kredytowe dla osoby, której faktyczne ryzyko jest niskie, oznacza to, że model przeprowadził błędną klasyfikację.
Jednak odwrotna błędna klasyfikacja jest pięć razy bardziej kosztowna dla instytucji finansowej: jeśli model przewidzi niskie ryzyko kredytowe dla osoby, której faktyczne ryzyko jest wysokie.
Dlatego warto wytrenować model tak, aby koszt tego drugiego typu błędnej klasyfikacji był pięć razy wyższy, niż odwrotnej błędnej klasyfikacji.
Prostym sposobem, aby to zrobić podczas trenowania modelu w eksperymencie, jest zduplikowanie (pięć razy) tych wpisów, które reprezentują wnioskodawcę z wysokim ryzykiem kredytowym.
W takim przypadku, jeśli model błędnie sklasyfikuje niskie ryzyko kredytowe dla kogoś, kogo rzeczywiste ryzyko kredytowe jest wysokie, zrobi ten sam błąd pięć razy — po razie dla każdego duplikatu. Takie rozwiązanie zwiększy koszt tego błędu w wynikach trenowania.
Konwertowanie formatu zestawu danych
Oryginalny zestaw danych ma format wartości rozdzielanych spacją. Usługa Machine Learning Studio (klasyczna) działa lepiej z plikiem wartości rozdzielanej przecinkami (CSV), więc przekonwertujesz zestaw danych, zastępując spacje przecinkami.
Istnieje wiele sposobów na przekonwertowanie danych. Jednym z nich jest użycie następującego polecenia programu Windows PowerShell:
cat german.data | %{$_ -replace " ",","} | sc german.csv
Innym sposobem jest użycie polecenia sed systemu Unix:
sed 's/ /,/g' german.data > german.csv
W obu przypadkach zostanie utworzona rozdzielana przecinkami wersja danych w pliku o nazwie german.csv, którego możesz użyć w eksperymencie.
Przekazywanie zestawu danych do usługi Machine Learning Studio (wersja klasyczna)
Po przekonwertowaniu danych na format CSV należy przekazać je do usługi Machine Learning Studio (klasycznej).
Otwórz stronę głównąhttps://studio.azureml.net usługi Machine Learning Studio (klasyczną).
Kliknij menu
 W lewym górnym rogu okna kliknij pozycję Azure Machine Learning, wybierz pozycję Studio i zaloguj się.
W lewym górnym rogu okna kliknij pozycję Azure Machine Learning, wybierz pozycję Studio i zaloguj się.Kliknij pozycję + NEW (+NOWY) w dolnej części okna.
Wybierz pozycję ZESTAW DANYCH.
Wybierz pozycję FROM LOCAL FILE (Z PLIKU LOKALNEGO).
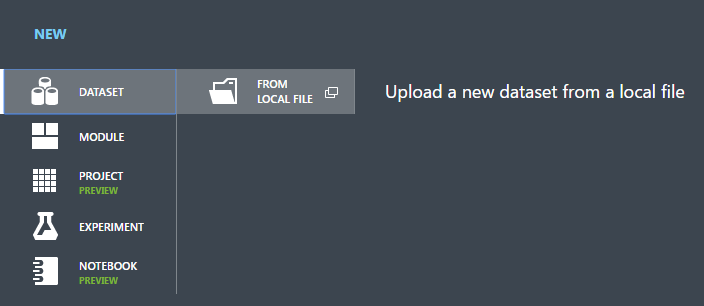
W oknie dialogowym Upload a new dataset (Przekazywanie nowego zestawu danych) kliknij przycisk Browse (Przeglądaj) i znajdź utworzony plik german.csv.
Wprowadź nazwę dla zestawu danych. Na potrzeby tego samouczka nadaj mu nazwę „UCI German Credit Card Data”.
Jako typ danych wybierz opcję Generic CSV File With no header (.nh.csv) (Ogólny plik CSV bez nagłówka).
Dodaj opis, jeśli chcesz.
Kliknij znacznik wyboru OK.
Spowoduje to przekazanie danych do modułu zestawu danych, którego możesz użyć w eksperymencie.
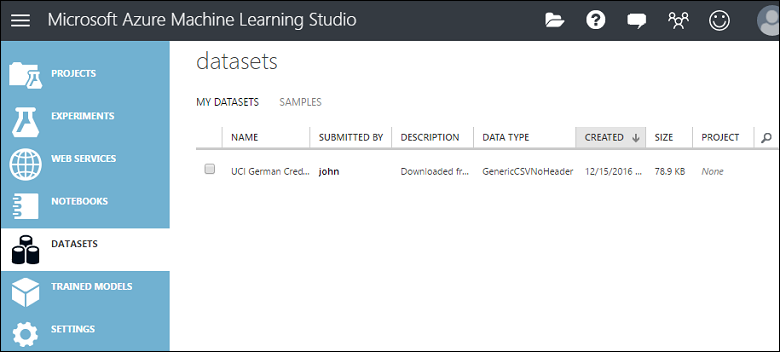
Możesz zarządzać zestawami danych przekazanymi do programu Studio (wersja klasyczna), klikając kartę ZESTAWY DANYCH po lewej stronie okna Studio (wersja klasyczna).
Aby uzyskać więcej informacji na temat importowania innych typów danych do eksperymentu, zobacz Importowanie danych treningowych do usługi Machine Learning Studio (wersja klasyczna).
Tworzenie eksperymentu
Następnym krokiem w tym samouczku jest utworzenie eksperymentu w usłudze Machine Learning Studio (klasycznym), który używa przekazanego zestawu danych.
W programie Studio (wersja klasyczna) kliknij pozycję +NOWY w dolnej części okna.
Wybierz pozycję EXPERIMENT (EKSPERYMENT), a następnie wybierz pozycję „Blank Experiment” (Pusty eksperyment).
Wybierz domyślną nazwę eksperymentu w górnej części kanwy i zmień ją, wpisując tekst opisowy.

Porada
Dobrym pomysłem jest wypełnienie pól Summary (Podsumowanie) i Description (Opis) dla eksperymentu w okienku Properties (Właściwości). Te właściwości dają możliwość udokumentowania eksperymentu, aby każdy, kto będzie go później przeglądał, mógł zrozumieć jego cele i metodologię.

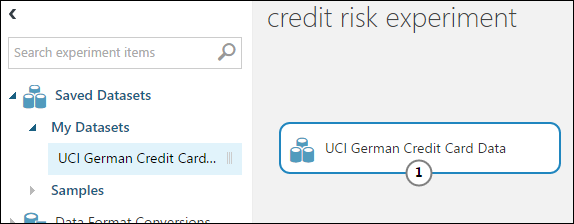
W palecie modułów z lewej strony kanwy eksperymentu rozwiń pozycję Saved Datasets (Zapisane zestawy danych).
W obszarze My Datasets (Moje zestawy danych) znajdź utworzony przez siebie zestaw danych i przeciągnij go na kanwę. Zestaw danych możesz również znaleźć, wprowadzając jego nazwę w polu wyszukiwania nad paletą.
Przygotowywanie danych
Możesz wyświetlić pierwsze 100 wierszy danych i niektóre informacje statystyczne dla całego zestawu danych: kliknij port wyjściowy zestawu danych (mały okrąg u dołu) i wybierz pozycję Wizualizuj.
Ponieważ plik danych nie zawiera nagłówków kolumn, program Studio (wersja klasyczna) udostępnia nagłówki ogólne (Col1, Col2 itp.). Dobre nagłówki nie są niezbędne do utworzenia modelu, ale ułatwiają pracę z danymi w eksperymencie. Ponadto po opublikowaniu tego modelu w usłudze internetowej nagłówki pomagają w identyfikowaniu kolumn użytkownikowi usługi.
Nagłówki kolumn możesz dodać za pomocą modułu Edit Metadata (Edytowanie metadanych).
Modułu Edit Metadata (Edytowanie metadanych) możesz użyć, aby zmienić metadane skojarzone z zestawem danych. W tym przypadku użyjesz go do nadania bardziej przyjaznych nazw nagłówkom kolumn.
Aby użyć funkcji Edytuj metadane, należy najpierw określić kolumny do zmodyfikowania (w tym przypadku wszystkie z nich). Następnie określ akcję do wykonania w tych kolumnach (w tym przypadku zmieniając nagłówki kolumn).
W palecie modułów wpisz wyraz „metadata” (metadane) w polu Search (Wyszukaj). Moduł Edit Metadata (Edytowanie metadanych) zostanie wyświetlony na liście modułów.
Kliknij i przeciągnij moduł Edit Metadata (Edytowanie metadanych) na kanwę i upuść go poniżej dodanego wcześniej zestawu danych.
Połącz zestaw danych z modułem Edit Metadata (Edytowanie metadanych): kliknij port wyjściowy zestawu danych (mały okrąg w dolnej części zestawu danych), przeciągnij go do portu wejściowego modułu Edit Metadata (Edytowanie metadanych) (mały okrąg w górnej części modułu), a następnie zwolnij przycisk myszy. Zestaw danych i moduł pozostaną połączone, nawet jeśli będziesz przenosić je w obrębie kanwy.
Eksperyment powinien wyglądać teraz mniej więcej tak:
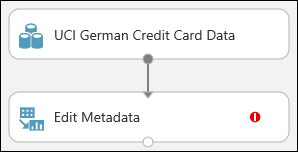
Czerwony wykrzyknik wskazuje, że dla tego modułu nie ustawiono jeszcze właściwości. Zrobisz to w następnej kolejności.
Porada
Aby dodać komentarz do modułu, kliknij dwukrotnie moduł i wpisz tekst. Pozwoli to od razu sprawdzić rolę modułu w eksperymencie. W tym przypadku kliknij dwukrotnie moduł Edit Metadata (Edytowanie metadanych) i wpisz komentarz „Dodawanie nagłówków kolumn”. Kliknij dowolne miejsce na kanwie, aby zamknąć pole tekstowe. Aby wyświetlić komentarz, kliknij strzałkę w dół na module.
Wybierz moduł Edit Metadata (Edytowanie metadanych), a następnie w okienku Properties (Właściwości) po prawej stronie kanwy kliknij pozycję Launch column selector (Uruchom selektor kolumn).
W oknie dialogowym Wybieranie kolumn zaznacz wszystkie wiersze w obszarze Dostępne kolumny i kliknij > , aby przenieść je do wybranych kolumn. Okno dialogowe powinno wyglądać następująco:
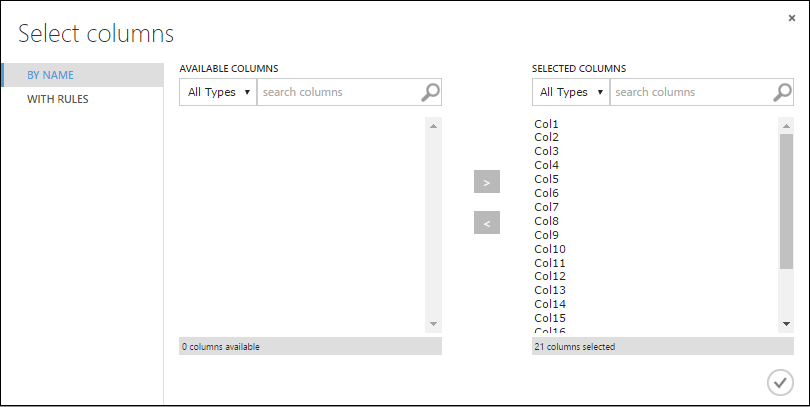
Kliknij znacznik wyboru OK.
Z powrotem w okienku Properties (Właściwości) poszukaj parametru New column names (Nowe nazwy kolumn). W tym polu wprowadź listę nazw dla 21 kolumn w zestawie danych, rozdzielane przecinkami i w kolejności kolumn. Nazwy kolumn możesz uzyskać z dokumentacji zestawu danych w witrynie UCI lub, dla wygody, możesz skopiować i wkleić poniższą listę:
Status of checking account, Duration in months, Credit history, Purpose, Credit amount, Savings account/bond, Present employment since, Installment rate in percentage of disposable income, Personal status and sex, Other debtors, Present residence since, Property, Age in years, Other installment plans, Housing, Number of existing credits, Job, Number of people providing maintenance for, Telephone, Foreign worker, Credit riskOkienko Properties (Właściwości) wygląda następująco:
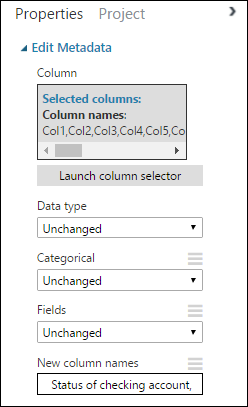
Porada
Jeśli chcesz zweryfikować nagłówki kolumn, uruchom eksperyment (kliknij przycisk RUN (URUCHOM) poniżej kanwy eksperymentu). Po zakończeniu eksperymentu (na module Edit Metadata (Edytowanie metadanych) zostanie wyświetlony zielony znacznik wyboru), kliknij port wyjściowy modułu Edit Metadata (Edytowanie metadanych) i wybierz pozycję Visualize (Wizualizuj). W ten sam sposób możesz wyświetlić dane wyjściowe każdego modułu, aby sprawdzić postęp danych w eksperymencie.
Tworzenie szkoleniowych i testowych zestawów danych
Potrzebujesz danych, aby wytrenować model i aby go przetestować. Z tego względu w następnym kroku eksperymentu podzielisz zestaw danych na dwa oddzielne zestawy danych: jeden na potrzeby trenowania naszego modelu, a drugi na potrzeby testowania.
Aby to zrobić, należy użyć modułu Split Data (Podział danych).
Znajdź moduł Split Data (Podział danych), przeciągnij go na kanwę, a następnie połącz go z modułem Edit Metadata (Edytowanie metadanych).
Domyślnie współczynnik podziału wynosi 0,5 i jest ustawiony parametr Randomized split (Podział losowy). Oznacza to, że losowa połowa danych przechodzi przez jeden port wyjściowy modułu Split Data (Podział danych), a pozostała połowa przez drugi. Możesz dostosować te parametry, jak również parametr Random seed (Podział losowy), aby zmienić podział między danymi szkoleniowymi i testowymi. W tym przykładzie pozostaw je tak, jak są.
Porada
Właściwość Fraction of rows in the first output dataset (Odsetek wierszy w pierwszym zestawie danych wyjściowych) określa, ile danych przechodzi przez lewy port wyjściowy. Jeśli na przykład ustawisz współczynnik o wartości 0,7, to 70% danych będzie przechodzić przez lewy port wyjściowy, a 30% przez prawy port.
Kliknij dwukrotnie moduł Split Data (Podział danych) i wprowadź komentarz „Podział na dane szkoleniowe/testowe 50%”.
Danych wyjściowych modułu Split Data (Podział danych) możesz używać, jak chcesz, ustalmy jednak, że lewych danych wyjściowych użyjemy do trenowania, a prawych danych wyjściowych do testowania.
Jak wspomnieliśmy w poprzednim kroku, koszt błędnego sklasyfikowania wysokiego ryzyka kredytowego jako niskiego jest pięć razy wyższy, niż koszt błędnego sklasyfikowania niskiego ryzyka kredytowego jako wysokiego. Aby to uwzględnić, musisz wygenerować nowy zestaw danych, który odzwierciedla tę cechę kosztu. W nowym zestawie danych każdy przykład wysokiego ryzyka jest replikowany pięć razy, podczas gdy przykłady niskiego ryzyka nie są replikowane.
Tę replikację możesz przeprowadzić przy użyciu kodu języka R:
Znajdź moduł Execute R Script (Wykonywanie skryptu R) i przeciągnij go na kanwę eksperymentu.
Połącz lewy port wyjściowy modułu Split Data (Podział danych) z pierwszy portem wejściowym („Dataset1”) modułu Execute R Script (Wykonywanie skryptu R).
Kliknij dwukrotnie moduł Execute R Script (Wykonywanie skryptu R) i wprowadź komentarz „Ustawianie korekty kosztu”.
W okienku Properties (Właściwości) usuń domyślny tekst dla parametru R Script (Skrypt R) i wprowadź ten skrypt:
dataset1 <- maml.mapInputPort(1) data.set<-dataset1[dataset1[,21]==1,] pos<-dataset1[dataset1[,21]==2,] for (i in 1:5) data.set<-rbind(data.set,pos) maml.mapOutputPort("data.set")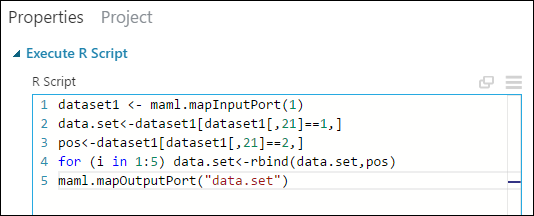
Musisz wykonać tę samą operację replikacji dla wszystkich danych wyjściowych modułu Split Data (Podział danych), aby dane szkoleniowe i testowe miały taką samą korektę kosztów. Najłatwiejszym sposobem na zrobienie tego jest zduplikowanie właśnie utworzonego modułu Execute R Script (Wykonywanie skryptu R) i połączenie go z drugim portem wyjściowym modułu Split Data (Podział danych).
Kliknij prawym przyciskiem myszy moduł Execute R Script (Wykonywanie skryptu R), a następnie wybierz pozycję Copy (Kopiuj).
Kliknij prawym przyciskiem myszy kanwę eksperymentu, a następnie wybierz pozycję Paste (Wklej).
Przeciągnij nowy moduł w odpowiednie miejsce, a następnie połącz prawy port wyjściowy modułu Split Data (Podział danych) z pierwszym portem wejściowym tego nowego modułu Execute R Script (Wykonywanie skryptu R).
W dolnej części kanwy kliknij przycisk Run (Uruchom).
Porada
Kopia modułu wykonywania skryptu R zawiera ten sam skrypt, co oryginalny moduł. Podczas kopiowania i wklejania modułu na kanwie kopia zachowuje wszystkie właściwości oryginału.
Nasz eksperyment wygląda teraz mniej więcej tak:
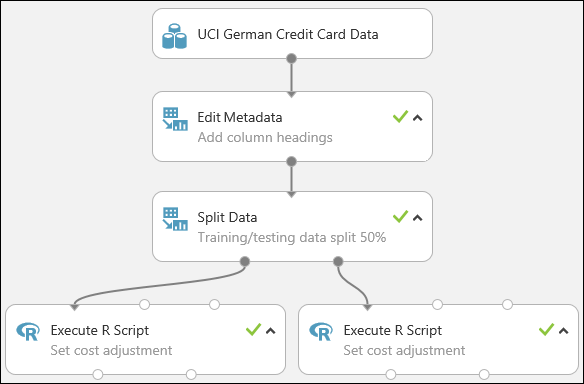
Aby uzyskać więcej informacji na temat używania skryptów języka R w eksperymentach, zobacz Rozszerzanie eksperymentu przy użyciu języka R.
Czyszczenie zasobów
Jeśli nie potrzebujesz już zasobów, które zostały utworzone w tym artykule, usuń je, aby uniknąć ponoszenia opłat. Aby dowiedzieć się, jak to zrobić, zapoznaj się z artykułem Export and delete in-product user data (Eksportowanie i usuwanie danych użytkownika w produkcie).
Następne kroki
W tym samouczku wykonano następujące kroki:
- Tworzenie obszaru roboczego usługi Machine Learning Studio (wersja klasyczna)
- Przekazywanie istniejących danych do obszaru roboczego
- Tworzenie eksperymentu
Teraz możesz przystąpić do trenowania i ewaluowania modeli dla tych danych.