Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano składnik w projektancie usługi Azure Machine Learning.
Dowiedz się, jak za pomocą składnika Create Python Model (Tworzenie modelu języka Python) utworzyć nietrenowany model na podstawie skryptu języka Python. Model można opierać na każdym uczniu, który jest uwzględniony w pakiecie języka Python w środowisku projektanta usługi Azure Machine Learning.
Po utworzeniu modelu możesz użyć polecenia Train Model (Trenowanie modelu) do trenowania modelu w zestawie danych, podobnie jak w przypadku innych osób uczących się w usłudze Azure Machine Learning. Wytrenowany model można przekazać do score model (Generowanie wyników dla modelu ), aby tworzyć przewidywania. Następnie możesz zapisać wytrenowany model i opublikować przepływ pracy oceniania jako usługę internetową.
Ostrzeżenie
Obecnie nie można połączyć tego składnika ze składnikiem Tune Model Hyperparameters lub przekazać wyniki ocenionego modelu w języku Python do oceny modelu. Jeśli chcesz dostroić hiperparametry lub ocenić model, możesz napisać niestandardowy skrypt języka Python przy użyciu składnika Wykonaj skrypt języka Python.
Konfigurowanie składnika
Użycie tego składnika wymaga pośredniej lub specjalistycznej wiedzy na temat języka Python. Składnik obsługuje korzystanie z dowolnego ucznia uwzględnionego w pakietach języka Python zainstalowanych już w usłudze Azure Machine Learning. Zobacz listę wstępnie zainstalowanych pakietów języka Python w temacie Execute Python Script (Wykonywanie skryptu języka Python).
Uwaga
Podczas pisania skryptu należy zachować ostrożność i upewnić się, że nie ma błędu składniowego, takiego jak użycie obiektu niezdeklarowanego lub nieimportowanego składnika.
Uwaga
Zwróć również szczególną uwagę na listę wstępnie zainstalowanych składników w temacie Execute Python Script (Wykonywanie skryptu języka Python). Importuj tylko wstępnie zainstalowane składniki. Nie instaluj dodatkowych pakietów, takich jak "install xgboost" w tym skrypcie, w przeciwnym razie błędy będą zgłaszane podczas odczytywania modeli w składnikach strumienia w dół.
W tym artykule pokazano, jak używać polecenia Create Python Model with a simple pipeline (Tworzenie modelu języka Python przy użyciu prostego potoku). Oto diagram potoku:
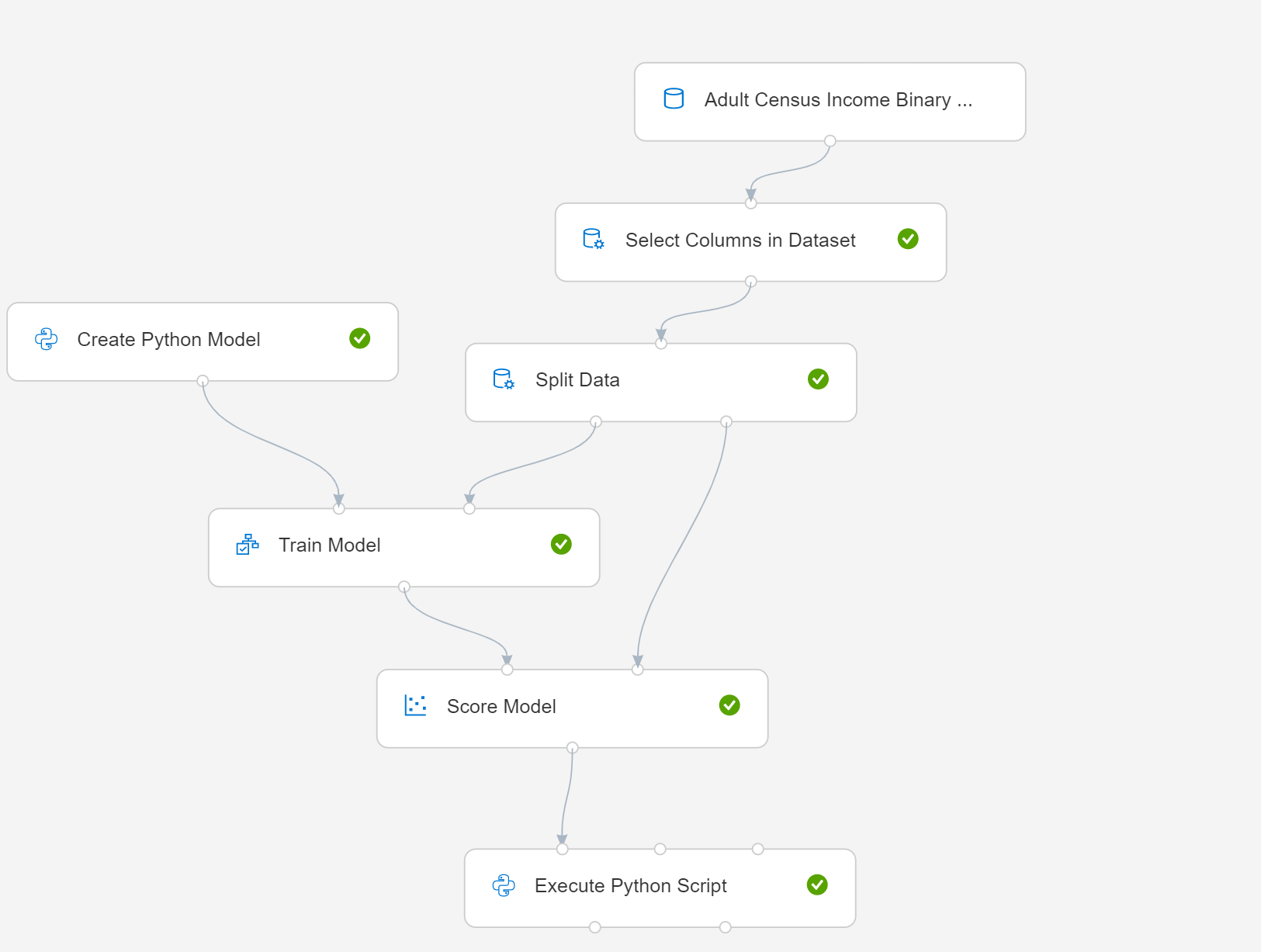
- Wybierz pozycję Utwórz model języka Python i edytuj skrypt, aby zaimplementować proces modelowania lub zarządzania danymi. Model można utworzyć na podstawie dowolnego ucznia uwzględnionego w pakiecie języka Python w środowisku usługi Azure Machine Learning.
Uwaga
Zwróć szczególną uwagę na komentarze w przykładowym kodzie skryptu i upewnij się, że skrypt jest ściśle zgodny z wymaganiami, w tym nazwę klasy, metody, a także podpis metody. Naruszenie doprowadzi do wyjątków. Tworzenie modelu języka Python obsługuje tylko tworzenie modelu opartego na platformie Sklearn do trenowania przy użyciu trenowania modelu.
Poniższy przykładowy kod dwuklasowego klasyfikatora Bayesa używa popularnego pakietu sklearn :
# The script MUST define a class named Azure Machine LearningModel.
# This class MUST at least define the following three methods:
# __init__: in which self.model must be assigned,
# train: which trains self.model, the two input arguments must be pandas DataFrame,
# predict: which generates prediction result, the input argument and the prediction result MUST be pandas DataFrame.
# The signatures (method names and argument names) of all these methods MUST be exactly the same as the following example.
# Please do not install extra packages such as "pip install xgboost" in this script,
# otherwise errors will be raised when reading models in down-stream components.
import pandas as pd
from sklearn.naive_bayes import GaussianNB
class AzureMLModel:
def __init__(self):
self.model = GaussianNB()
self.feature_column_names = list()
def train(self, df_train, df_label):
# self.feature_column_names records the column names used for training.
# It is recommended to set this attribute before training so that the
# feature columns used in predict and train methods have the same names.
self.feature_column_names = df_train.columns.tolist()
self.model.fit(df_train, df_label)
def predict(self, df):
# The feature columns used for prediction MUST have the same names as the ones for training.
# The name of score column ("Scored Labels" in this case) MUST be different from any other columns in input data.
return pd.DataFrame(
{'Scored Labels': self.model.predict(df[self.feature_column_names]),
'probabilities': self.model.predict_proba(df[self.feature_column_names])[:, 1]}
)
Połącz składnik Create Python Model (Tworzenie modelu języka Python), który został właśnie utworzony w celu trenowania modelu i generowania wyników dla modelu.
Jeśli chcesz ocenić model, dodaj składnik Execute Python Script (Wykonywanie skryptu języka Python) i edytuj skrypt języka Python.
Poniższy skrypt to przykładowy kod oceny:
# The script MUST contain a function named azureml_main # which is the entry point for this component. # imports up here can be used to import pandas as pd # The entry point function MUST have two input arguments: # Param<dataframe1>: a pandas.DataFrame # Param<dataframe2>: a pandas.DataFrame def azureml_main(dataframe1 = None, dataframe2 = None): from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score, roc_curve import pandas as pd import numpy as np scores = dataframe1.ix[:, ("income", "Scored Labels", "probabilities")] ytrue = np.array([0 if val == '<=50K' else 1 for val in scores["income"]]) ypred = np.array([0 if val == '<=50K' else 1 for val in scores["Scored Labels"]]) probabilities = scores["probabilities"] accuracy, precision, recall, auc = \ accuracy_score(ytrue, ypred),\ precision_score(ytrue, ypred),\ recall_score(ytrue, ypred),\ roc_auc_score(ytrue, probabilities) metrics = pd.DataFrame(); metrics["Metric"] = ["Accuracy", "Precision", "Recall", "AUC"]; metrics["Value"] = [accuracy, precision, recall, auc] return metrics,
Następne kroki
Zobacz zestaw składników dostępnych dla usługi Azure Machine Learning.