Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano składnik w projektancie usługi Azure Machine Learning.
Ten składnik służy do przekształcania zestawu danych za pomocą normalizacji.
Normalizacja to technika często stosowana w ramach przygotowywania danych do uczenia maszynowego. Celem normalizacji jest zmiana wartości kolumn liczbowych w zestawie danych w celu użycia wspólnej skali bez zniekształcania różnic w zakresach wartości lub utraty informacji. Normalizacja jest również wymagana, aby niektóre algorytmy prawidłowo modelować dane.
Załóżmy na przykład, że wejściowy zestaw danych zawiera jedną kolumnę zawierającą wartości z zakresu od 0 do 1, a drugą kolumnę z wartościami z zakresu od 10 000 do 100 000. Duża różnica w skali liczb może powodować problemy podczas próby połączenia wartości jako funkcji podczas modelowania.
Normalizacja pozwala uniknąć tych problemów, tworząc nowe wartości, które utrzymują ogólny rozkład i współczynniki w danych źródłowych, zachowując jednocześnie wartości w skali stosowanej we wszystkich kolumnach liczbowych używanych w modelu.
Ten składnik oferuje kilka opcji przekształcania danych liczbowych:
- Można zmienić wszystkie wartości na 0–1 skalę lub przekształcić wartości, reprezentując je jako klasyfikacje percentylu, a nie wartości bezwzględne.
- Normalizację można zastosować do jednej kolumny lub do wielu kolumn w tym samym zestawie danych.
- Jeśli musisz powtórzyć potok lub zastosować te same kroki normalizacji do innych danych, możesz zapisać kroki jako przekształcenie normalizacji i zastosować go do innych zestawów danych, które mają ten sam schemat.
Ostrzeżenie
Niektóre algorytmy wymagają normalizacji danych przed rozpoczęciem trenowania modelu. Inne algorytmy wykonują własne skalowanie lub normalizację danych. W związku z tym podczas wybierania algorytmu uczenia maszynowego do użycia w tworzeniu modelu predykcyjnego należy zapoznać się z wymaganiami dotyczącymi danych algorytmu przed zastosowaniem normalizacji do danych treningowych.
Konfigurowanie normalizacji danych
Za pomocą tego składnika można zastosować tylko jedną metodę normalizacji. W związku z tym ta sama metoda normalizacji jest stosowana do wszystkich wybranych kolumn. Aby użyć różnych metod normalizacji, użyj drugiego wystąpienia normalizacji danych.
Dodaj składnik Normalize Data (Normalizacja danych) do potoku. Składnik w usłudze Azure Machine Learning można znaleźć w obszarze Przekształcanie danych w kategorii Skalowanie i redukcja .
Połącz zestaw danych zawierający co najmniej jedną kolumnę wszystkich liczb.
Użyj selektora kolumn, aby wybrać kolumny liczbowe do normalizacji. Jeśli nie wybierzesz poszczególnych kolumn, domyślnie zostaną uwzględnione wszystkie kolumny typu liczbowego w danych wejściowych, a ten sam proces normalizacji zostanie zastosowany do wszystkich wybranych kolumn.
Może to prowadzić do dziwnych wyników, jeśli uwzględnisz kolumny liczbowe, które nie powinny być znormalizowane! Zawsze uważnie sprawdzaj kolumny.
Jeśli nie wykryto żadnych kolumn liczbowych, sprawdź metadane kolumny, aby sprawdzić, czy typ danych kolumny jest obsługiwanym typem liczbowym.
Napiwek
Aby upewnić się, że kolumny określonego typu są dostarczane jako dane wejściowe, spróbuj użyć składnika Select Columns in Dataset (Wybieranie kolumn w zestawie danych ) przed normalizacją danych.
Użyj wartości 0 dla kolumn stałych po zaznaczeniu: wybierz tę opcję, gdy dowolna kolumna liczbowa zawiera jedną niezmieniającą się wartość. Dzięki temu takie kolumny nie są używane w operacjach normalizacji.
Z listy rozwijanej Metoda przekształcania wybierz pojedynczą funkcję matematyczną, która ma być stosowana do wszystkich zaznaczonych kolumn.
Zscore: konwertuje wszystkie wartości na wynik z.
Wartości w kolumnie są przekształcane przy użyciu następującej formuły:
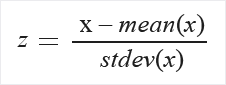
Średnie i odchylenie standardowe są obliczane osobno dla każdej kolumny. Używane jest odchylenie standardowe populacji.
MinMax: normalizator min-max liniowo skaluje każdą funkcję do interwału [0,1].
Przeskalowanie do interwału [0,1] odbywa się przez przesunięcie wartości każdej funkcji tak, aby minimalna wartość wynosi 0, a następnie dzieliła przez nową maksymalną wartość (co jest różnicą między oryginalnymi maksymalnymi i minimalnymi wartościami).
Wartości w kolumnie są przekształcane przy użyciu następującej formuły:

Logistyczne: wartości w kolumnie są przekształcane przy użyciu następującej formuły:

LogNormal: ta opcja konwertuje wszystkie wartości na skalę lognormalną.
Wartości w kolumnie są przekształcane przy użyciu następującej formuły:

W tym μ i σ są parametrami rozkładu obliczonymi empirycznie na podstawie danych jako maksymalnymi oszacowaniami prawdopodobieństwa dla każdej kolumny oddzielnie.
TanH: wszystkie wartości są konwertowane na tangens hiperboliczny.
Wartości w kolumnie są przekształcane przy użyciu następującej formuły:

Prześlij potok lub kliknij dwukrotnie składnik Normalize Data (Normalizacja danych ) i wybierz pozycję Run Selected (Uruchom wybrane).
Wyniki
Składnik Normalize Data (Normalizacja danych ) generuje dwa dane wyjściowe:
Aby wyświetlić przekształcone wartości, kliknij prawym przyciskiem myszy składnik i wybierz polecenie Visualize (Wizualizacja).
Domyślnie wartości są przekształcane. Jeśli chcesz porównać przekształcone wartości z oryginalnymi wartościami, użyj składnika Dodaj kolumny , aby ponownie połączyć zestawy danych i wyświetlić kolumny obok siebie.
Aby zapisać transformację, aby zastosować tę samą metodę normalizacji do innego zestawu danych, wybierz składnik, a następnie wybierz pozycję Zarejestruj zestaw danych na karcie Dane wyjściowe w prawym panelu.
Następnie można załadować zapisane przekształcenia z grupy Przekształcenia w okienku po lewej stronie i zastosować je do zestawu danych z tym samym schematem przy użyciu funkcji Zastosuj przekształcenie.
Następne kroki
Zobacz zestaw składników dostępnych dla usługi Azure Machine Learning.