Tworzenie zadań i danych wejściowych dla punktów końcowych wsadowych
Punkty końcowe usługi Batch umożliwiają wykonywanie długich operacji wsadowych na dużych ilościach danych. Dane mogą znajdować się w różnych miejscach, takich jak w różnych regionach. Niektóre typy punktów końcowych wsadowych mogą również odbierać parametry literału jako dane wejściowe.
W tym artykule opisano sposób określania danych wejściowych parametrów dla punktów końcowych wsadowych i tworzenia zadań wdrażania. Proces obsługuje pracę z różnymi typami danych. Aby zapoznać się z niektórymi przykładami, zobacz Omówienie danych wejściowych i wyjściowych.
Wymagania wstępne
Aby pomyślnie wywołać punkt końcowy wsadowy i utworzyć zadania, upewnij się, że zostały spełnione następujące wymagania wstępne:
Punkt końcowy i wdrożenie wsadowe. Jeśli nie masz tych zasobów, zobacz Wdrażanie modeli oceniania w punktach końcowych wsadowych , aby utworzyć wdrożenie.
Uprawnienia do uruchamiania wdrożenia punktu końcowego wsadowego. Role usługi AzureML badacze dancyh, Współautor i Właściciel mogą służyć do uruchamiania wdrożenia. Aby zapoznać się z definicjami ról niestandardowych, zobacz Autoryzacja w punktach końcowych wsadowych , aby przejrzeć określone wymagane uprawnienia.
Prawidłowy token identyfikatora Entra firmy Microsoft reprezentujący podmiot zabezpieczeń w celu wywołania punktu końcowego. Ten podmiot zabezpieczeń może być jednostką użytkownika lub jednostką usługi. Po wywołaniu punktu końcowego usługa Azure Machine Learning tworzy zadanie wdrożenia wsadowego w ramach tożsamości skojarzonej z tokenem. Możesz użyć własnych poświadczeń do wywołania, zgodnie z opisem w poniższych procedurach.
Użyj interfejsu wiersza polecenia platformy Azure, aby zalogować się przy użyciu uwierzytelniania kodu interakcyjnego lub urządzenia :
az loginAby dowiedzieć się więcej na temat uruchamiania zadań wdrażania wsadowego przy użyciu różnych typów poświadczeń, zobacz Jak uruchamiać zadania przy użyciu różnych typów poświadczeń.
Klaster obliczeniowy, w którym wdrożony punkt końcowy ma dostęp do odczytywania danych wejściowych.
Napiwek
Jeśli używasz magazynu danych bez poświadczeń lub zewnętrznego konta usługi Azure Storage jako danych wejściowych, upewnij się, że skonfigurowaliśmy klastry obliczeniowe na potrzeby dostępu do danych. Tożsamość zarządzana klastra obliczeniowego jest używana do instalowania konta magazynu. Tożsamość zadania (invoker) jest nadal używana do odczytywania danych bazowych, co pozwala uzyskać szczegółową kontrolę dostępu.
Podstawy tworzenia zadań
Aby utworzyć zadanie na podstawie punktu końcowego wsadowego, należy wywołać punkt końcowy. Wywołanie można wykonać przy użyciu interfejsu wiersza polecenia platformy Azure, zestawu AZURE Machine Learning SDK dla języka Python lub wywołania interfejsu API REST. W poniższych przykładach przedstawiono podstawy wywołania punktu końcowego wsadowego, który odbiera pojedynczy folder danych wejściowych na potrzeby przetwarzania. Przykłady z różnymi danymi wejściowymi i wyjściowymi można znaleźć w temacie Understand inputs and outputs (Omówienie danych wejściowych i wyjściowych).
invoke Użyj operacji w obszarze punktów końcowych wsadowych:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Wywoływanie określonego wdrożenia
Punkty końcowe usługi Batch mogą hostować wiele wdrożeń w ramach tego samego punktu końcowego. Domyślny punkt końcowy jest używany, chyba że użytkownik określi inaczej. Wdrożenie można zmienić tak, aby było używane z następującymi procedurami.
Użyj argumentu --deployment-name lub -d określ nazwę wdrożenia:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Konfigurowanie właściwości zadania
Niektóre właściwości utworzonego zadania można skonfigurować w czasie wywołania.
Uwaga
Możliwość konfigurowania właściwości zadania jest obecnie dostępna tylko w punktach końcowych wsadowych z wdrożeniami składników potoku.
Konfigurowanie nazwy eksperymentu
Aby skonfigurować nazwę eksperymentu, użyj poniższych procedur.
Użyj argumentu --experiment-name , aby określić nazwę eksperymentu:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Informacje o danych wejściowych i wyjściowych
Punkty końcowe usługi Batch zapewniają trwały interfejs API, którego użytkownicy mogą używać do tworzenia zadań wsadowych. Ten sam interfejs może służyć do określania danych wejściowych i wyjściowych, których oczekuje wdrożenie. Użyj danych wejściowych, aby przekazać wszelkie informacje potrzebne do wykonania zadania przez punkt końcowy.
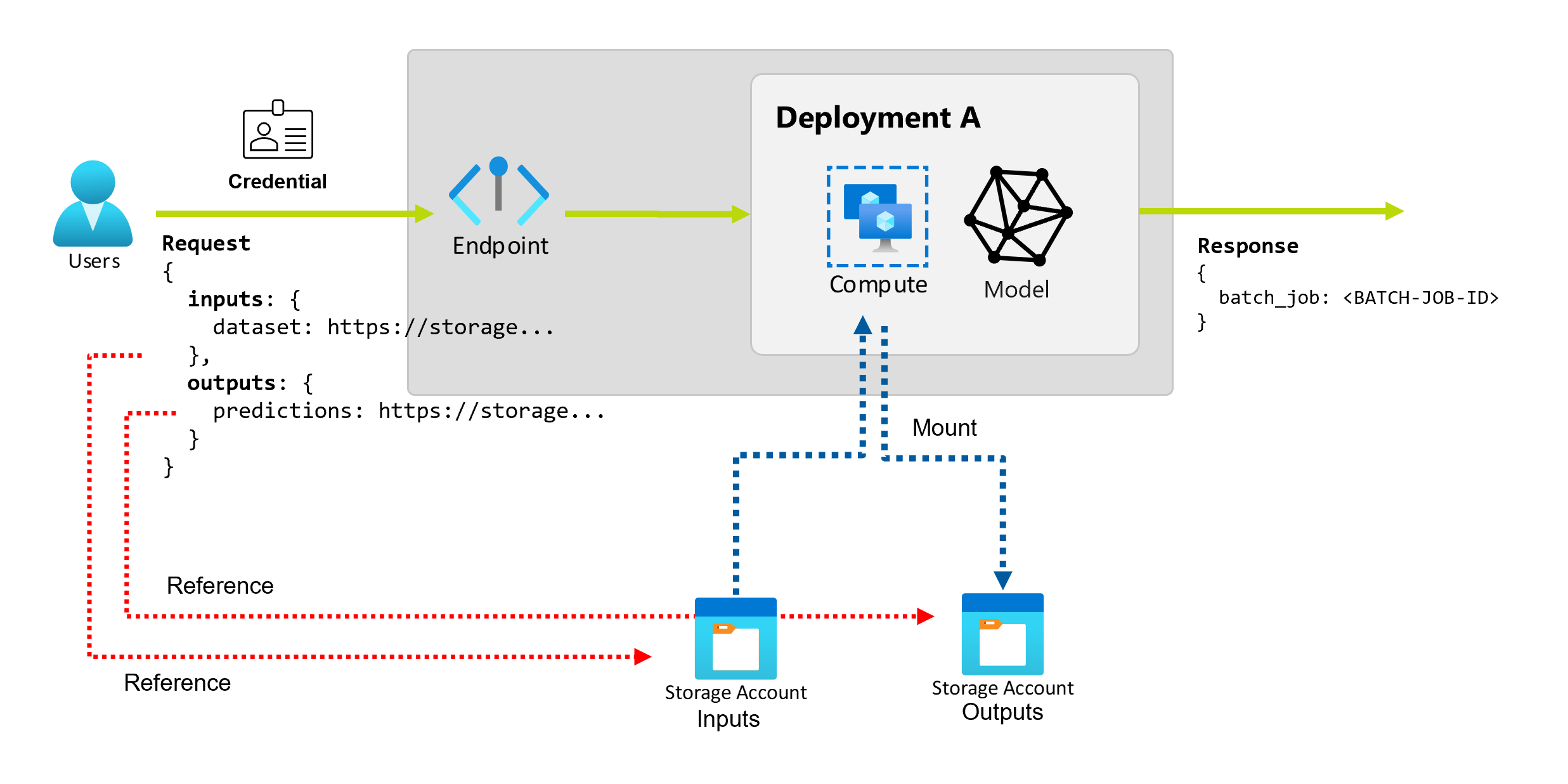
Punkty końcowe usługi Batch obsługują dwa typy danych wejściowych:
- Dane wejściowe: wskaźniki do określonej lokalizacji magazynu lub zasobu usługi Azure Machine Learning.
- Dane wejściowe literału: wartości literału, takie jak liczby lub ciągi, które chcesz przekazać do zadania.
Liczba i typ danych wejściowych i wyjściowych zależą od typu wdrożenia wsadowego. Wdrożenia modelu zawsze wymagają jednego danych wejściowych i generują jedno dane wyjściowe. Dane wejściowe literału nie są obsługiwane. Jednak wdrożenia składników potoku zapewniają bardziej ogólną konstrukcję do tworzenia punktów końcowych i umożliwiają określenie dowolnej liczby danych wejściowych (danych i literałów) i danych wyjściowych.
Poniższa tabela zawiera podsumowanie danych wejściowych i wyjściowych dla wdrożeń wsadowych:
| Typ wdrożenia | Liczba danych wejściowych | Obsługiwane typy danych wejściowych | Liczba danych wyjściowych | Obsługiwane typy danych wyjściowych |
|---|---|---|---|---|
| Wdrażanie modelu | 1 | Dane wejściowe danych | 1 | Dane wyjściowe |
| Wdrożenie składnika potoku | [0..N] | Dane wejściowe i dane wejściowe literału | [0..N] | Dane wyjściowe |
Napiwek
Dane wejściowe i wyjściowe są zawsze nazwane. Nazwy służą jako klucze do identyfikowania danych i przekazywania rzeczywistej wartości podczas wywołania. Ponieważ wdrożenia modelu zawsze wymagają jednego danych wejściowych i wyjściowych, nazwa jest ignorowana podczas wywołania. Możesz przypisać nazwę, która najlepiej opisuje przypadek użycia, taki jak "sales_estimation".
Eksplorowanie danych wejściowych
Dane wejściowe odnoszą się do danych wejściowych, które wskazują lokalizację, w której są umieszczane dane. Ponieważ punkty końcowe wsadowe zwykle zużywają duże ilości danych, nie można przekazać danych wejściowych w ramach żądania wywołania. Zamiast tego należy określić lokalizację, w której powinien znajdować się punkt końcowy wsadowy, aby wyszukać dane. Dane wejściowe są instalowane i przesyłane strumieniowo na docelowym obiekcie obliczeniowym w celu zwiększenia wydajności.
Punkty końcowe usługi Batch obsługują odczytywanie plików znajdujących się w następujących opcjach magazynu:
- Zasoby danych usługi Azure Machine Learning, w tym folder (
uri_folder) i plik (uri_file). - Magazyny danych usługi Azure Machine Learning, w tym usługi Azure Blob Storage, Azure Data Lake Storage Gen1 i Azure Data Lake Storage Gen2.
- Konta usługi Azure Storage, w tym usługi Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 i Azure Blob Storage.
- Lokalne foldery danych/pliki (interfejs wiersza polecenia usługi Azure Machine Learning lub zestaw Azure Machine Learning SDK dla języka Python). Jednak ta operacja powoduje przekazanie danych lokalnych do domyślnego magazynu danych usługi Azure Machine Learning obszaru roboczego, nad którym pracujesz.
Ważne
Powiadomienie o wycofaniu: Zestawy danych typu FileDataset (V1) są przestarzałe i zostaną wycofane w przyszłości. Istniejące punkty końcowe wsadowe korzystające z tej funkcji będą nadal działać. Punkty końcowe usługi Batch utworzone przy użyciu ogólnie dostępnej wersji CLIv2 (2.4.0 i nowszej) lub interfejsu API REST ga (2022-05-01 i nowsze) nie będą obsługiwać zestawu danych w wersji 1.
Eksplorowanie danych wejściowych literału
Dane wejściowe literałów odnoszą się do danych wejściowych, które mogą być reprezentowane i rozwiązywane w czasie wywołania, takie jak ciągi, liczby i wartości logiczne. Zazwyczaj dane wejściowe literału są używane do przekazywania parametrów do punktu końcowego w ramach wdrożenia składnika potoku. Punkty końcowe usługi Batch obsługują następujące typy literałów:
stringbooleanfloatinteger
Dane wejściowe literału są obsługiwane tylko we wdrożeniach składników potoku. Zobacz Tworzenie zadań z danymi wejściowymi literału, aby dowiedzieć się, jak je określić.
Eksplorowanie danych wyjściowych
Dane wyjściowe odnoszą się do lokalizacji, w której powinny zostać umieszczone wyniki zadania wsadowego. Każde dane wyjściowe mają rozpoznawalną nazwę, a usługa Azure Machine Learning automatycznie przypisuje unikatową ścieżkę do poszczególnych nazwanych danych wyjściowych. Możesz określić inną ścieżkę zgodnie z potrzebami.
Ważne
Punkty końcowe usługi Batch obsługują tylko zapisywanie danych wyjściowych w magazynach danych usługi Azure Blob Storage. Jeśli musisz zapisać na koncie magazynu z włączonymi hierarchicznymi przestrzeniami nazw (znanymi również jako Azure Datalake Gen2 lub ADLS Gen2), możesz zarejestrować usługę magazynu jako magazyn danych usługi Azure Blob Storage, ponieważ usługi są w pełni zgodne. W ten sposób można zapisywać dane wyjściowe z punktów końcowych wsadowych do usługi ADLS Gen2.
Tworzenie zadań przy użyciu danych wejściowych
W poniższych przykładach pokazano, jak tworzyć zadania, pobierać dane wejściowe z zasobów danych, magazynów danych i kont usługi Azure Storage.
Używanie danych wejściowych z zasobu danych
Zasoby danych usługi Azure Machine Learning (wcześniej znane jako zestawy danych) są obsługiwane jako dane wejściowe dla zadań. Wykonaj następujące kroki, aby uruchomić zadanie punktu końcowego wsadowego przy użyciu danych przechowywanych w zarejestrowanym zasobie danych w usłudze Azure Machine Learning.
Ostrzeżenie
Zasoby danych typu Tabela (MLTable) nie są obecnie obsługiwane.
Najpierw utwórz zasób danych. Ten zasób danych składa się z folderu z wieloma plikami CSV, które są przetwarzane równolegle przy użyciu punktów końcowych wsadowych. Ten krok można pominąć, jeśli dane są już zarejestrowane jako zasób danych.
Utwórz definicję zasobu danych w pliku
YAML:heart-dataset-unlabeled.yml
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-dataset-unlabeled description: An unlabeled dataset for heart classification. type: uri_folder path: heart-classifier-mlflow/dataNastępnie utwórz zasób danych:
az ml data create -f heart-dataset-unlabeled.ymlUtwórz dane wejściowe lub żądanie:
DATASET_ID=$(az ml data show -n heart-dataset-unlabeled --label latest | jq -r .id)Uruchom punkt końcowy:
Użyj argumentu ,
--setaby określić dane wejściowe:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$DATASET_IDW przypadku punktu końcowego obsługującego wdrożenie modelu można użyć argumentu
--input, aby określić dane wejściowe, ponieważ wdrożenie modelu zawsze wymaga tylko jednego danych wejściowych.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATASET_IDArgument
--setma tendencję do tworzenia długich poleceń, gdy określono wiele danych wejściowych. W takich przypadkach umieść dane wejściowe wYAMLpliku i użyj argumentu--file, aby określić wymagane dane wejściowe dla wywołania punktu końcowego.inputs.yml
inputs: heart_dataset: azureml:/<datasset_name>@latestUruchom następujące polecenie:
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Używanie danych wejściowych z magazynów danych
Możesz bezpośrednio odwoływać się do danych z zarejestrowanych magazynów danych usługi Azure Machine Learning z zadaniami wdrożeń wsadowych. W tym przykładzie najpierw przekażesz dane do domyślnego magazynu danych w obszarze roboczym usługi Azure Machine Learning, a następnie uruchomisz wdrożenie wsadowe. Wykonaj następujące kroki, aby uruchomić zadanie punktu końcowego wsadowego przy użyciu danych przechowywanych w magazynie danych.
Uzyskaj dostęp do domyślnego magazynu danych w obszarze roboczym usługi Azure Machine Learning. Jeśli dane są w innym magazynie, możesz zamiast tego użyć tego magazynu. Nie musisz używać domyślnego magazynu danych.
DATASTORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')Identyfikator magazynów danych wygląda następująco:
/subscriptions/<subscription>/resourceGroups/<resource-group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace>/datastores/<data-store>.Napiwek
Domyślny magazyn danych obiektów blob w obszarze roboczym nosi nazwę workspaceblobstore. Ten krok można pominąć, jeśli znasz już identyfikator zasobu domyślnego magazynu danych w obszarze roboczym.
Przekaż przykładowe dane do magazynu danych.
W tym przykładzie przyjęto założenie, że przykładowe dane zawarte w repozytorium zostały już przekazane w folderze w folderze
sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/dataheart-disease-uci-unlabeledna koncie usługi Blob Storage. Pamiętaj, aby wykonać ten krok przed kontynuowaniem.Utwórz dane wejściowe lub żądanie:
Umieść ścieżkę pliku w zmiennej
INPUT_PATH:DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="$DATASTORE_ID/paths/$DATA_PATH"Zwróć uwagę, że zmienna
pathsdla ścieżki jest dołączana do identyfikatora zasobu magazynu danych. Ten format wskazuje, że następująca wartość jest ścieżką.Napiwek
Możesz również użyć formatu
azureml://datastores/<data-store>/paths/<data-path>, aby określić dane wejściowe.Uruchom punkt końcowy:
Użyj argumentu ,
--setaby określić dane wejściowe:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$INPUT_PATHW przypadku punktu końcowego obsługującego wdrożenie modelu można użyć argumentu
--input, aby określić dane wejściowe, ponieważ wdrożenie modelu zawsze wymaga tylko jednego danych wejściowych.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folderArgument
--setma tendencję do tworzenia długich poleceń, gdy określono wiele danych wejściowych. W takich przypadkach umieść dane wejściowe wYAMLpliku i użyj argumentu--file, aby określić wymagane dane wejściowe dla wywołania punktu końcowego.inputs.yml
inputs: heart_dataset: type: uri_folder path: azureml://datastores/<data-store>/paths/<data-path>Uruchom następujące polecenie:
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlJeśli dane są plikiem, zamiast tego użyj
uri_filetypu danych wejściowych.
Używanie danych wejściowych z kont usługi Azure Storage
Punkty końcowe usługi Azure Machine Learning wsadowe mogą odczytywać dane z lokalizacji w chmurze na kontach usługi Azure Storage, zarówno publicznych, jak i prywatnych. Wykonaj poniższe kroki, aby uruchomić zadanie punktu końcowego wsadowego z danymi przechowywanymi na koncie magazynu.
Aby dowiedzieć się więcej o dodatkowej wymaganej konfiguracji odczytu danych z kont magazynu, zobacz Konfigurowanie klastrów obliczeniowych na potrzeby dostępu do danych.
Utwórz dane wejściowe lub żądanie:
Ustaw zmienną
INPUT_DATA:INPUT_DATA = "https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Jeśli dane są plikiem, ustaw zmienną w następującym formacie:
INPUT_DATA = "https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data/heart.csv"Uruchom punkt końcowy:
Użyj argumentu ,
--setaby określić dane wejściowe:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$INPUT_DATAW przypadku punktu końcowego obsługującego wdrożenie modelu można użyć argumentu
--input, aby określić dane wejściowe, ponieważ wdrożenie modelu zawsze wymaga tylko jednego danych wejściowych.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folderArgument
--setma tendencję do tworzenia długich poleceń, gdy określono wiele danych wejściowych. W takich przypadkach umieść dane wejściowe wYAMLpliku i użyj argumentu--file, aby określić wymagane dane wejściowe dla wywołania punktu końcowego.inputs.yml
inputs: heart_dataset: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/dataUruchom następujące polecenie:
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlJeśli dane są plikiem, zamiast tego użyj
uri_filetypu danych wejściowych.
Tworzenie zadań z danymi wejściowymi literału
Wdrożenia składników potoku mogą przyjmować dane wejściowe literału. W poniższym przykładzie pokazano, jak określić dane wejściowe o nazwie score_mode, typu string, z wartością append:
Umieść dane wejściowe w YAML pliku i użyj polecenia --file , aby określić wymagane dane wejściowe dla wywołania punktu końcowego.
inputs.yml
inputs:
score_mode:
type: string
default: append
Uruchom następujące polecenie:
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Możesz również użyć argumentu --set , aby określić wartość. Jednak takie podejście zwykle tworzy długie polecenia, gdy określono wiele danych wejściowych:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
Tworzenie zadań przy użyciu danych wyjściowych
W poniższym przykładzie pokazano, jak zmienić lokalizację, w której znajduje się dane wyjściowe o nazwie score . Na potrzeby kompletności te przykłady umożliwiają również skonfigurowanie danych wejściowych o nazwie heart_dataset.
Zapisz dane wyjściowe przy użyciu domyślnego magazynu danych w obszarze roboczym usługi Azure Machine Learning. Możesz użyć dowolnego innego magazynu danych w obszarze roboczym, o ile jest to konto usługi Blob Storage.
DATASTORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')Identyfikator magazynów danych wygląda następująco:
/subscriptions/<subscription>/resourceGroups/<resource-group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace>/datastores/<data-store>.Tworzenie danych wyjściowych:
Ustaw zmienną
OUTPUT_PATH:DATA_PATH="batch-jobs/my-unique-path" OUTPUT_PATH="$DATASTORE_ID/paths/$DATA_PATH"Aby uzyskać pełne informacje, utwórz również dane wejściowe:
INPUT_PATH="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Uwaga
Zwróć uwagę, że zmienna
pathsdla ścieżki jest dołączana do identyfikatora zasobu magazynu danych. Ten format wskazuje, że następująca wartość jest ścieżką.Uruchom wdrożenie:
Użyj argumentu ,
--setaby określić dane wejściowe:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.path=$INPUT_PATH \ --set outputs.score.path=$OUTPUT_PATH