Konfigurowanie rozwiązania AutoML do trenowania modelu prognozowania szeregów czasowych przy użyciu języka Python (SDKv1)
DOTYCZY: Zestaw SDK języka Python w wersji 1
Zestaw SDK języka Python w wersji 1
Z tego artykułu dowiesz się, jak skonfigurować trenowanie automatycznego uczenia maszynowego dla modeli prognozowania szeregów czasowych przy użyciu zautomatyzowanego uczenia maszynowego usługi Azure Machine Learning w zestawie SDK języka Python usługi Azure Machine Learning.
W tym celu wykonasz następujące czynności:
- Przygotowywanie danych do modelowania szeregów czasowych.
- Skonfiguruj określone parametry szeregów czasowych w
AutoMLConfigobiekcie. - Uruchamianie przewidywań z danymi szeregów czasowych.
Aby uzyskać małe środowisko kodu, zobacz Samouczek: prognozowanie zapotrzebowania za pomocą zautomatyzowanego uczenia maszynowego dla przykładu prognozowania szeregów czasowych przy użyciu zautomatyzowanego uczenia maszynowego w usłudze Azure Machine Learning Studio.
W przeciwieństwie do klasycznych metod szeregów czasowych, w zautomatyzowanym uczeniu maszynowym wcześniejsze wartości szeregów czasowych są "przestawne", aby stać się dodatkowymi wymiarami regresji wraz z innymi predyktorami. Takie podejście obejmuje wiele zmiennych kontekstowych i ich relacji ze sobą podczas trenowania. Ponieważ wiele czynników może mieć wpływ na prognozę, ta metoda dobrze pasuje do rzeczywistych scenariuszy prognozowania. Na przykład podczas prognozowania sprzedaży, interakcji historycznych trendów, kursu wymiany i ceny wszystkie wspólnie napędzają wynik sprzedaży.
Wymagania wstępne
Na potrzeby tego artykułu potrzebne są następujące elementy:
Obszar roboczy usługi Azure Machine Learning. Aby utworzyć obszar roboczy, zobacz Tworzenie zasobów obszaru roboczego.
W tym artykule założono, że znasz konfigurowanie eksperymentu zautomatyzowanego uczenia maszynowego. Postępuj zgodnie z instrukcjami, aby zobaczyć główne wzorce projektowania eksperymentów zautomatyzowanego uczenia maszynowego.
Ważne
Polecenia języka Python w tym artykule wymagają najnowszej
azureml-train-automlwersji pakietu.- Zainstaluj najnowszy
azureml-train-automlpakiet w środowisku lokalnym. - Aby uzyskać szczegółowe informacje na temat najnowszego
azureml-train-automlpakietu, zobacz informacje o wersji.
- Zainstaluj najnowszy
Dane trenowania i walidacji
Najważniejszą różnicą między typem zadania regresji prognozowania a typem zadania regresji w ramach zautomatyzowanego uczenia maszynowego jest uwzględnienie funkcji w danych treningowych reprezentujących prawidłowy szereg czasowy. Szeregi czasowe regularne mają dobrze zdefiniowaną i spójną częstotliwość i mają wartość w każdym punkcie próbki w ciągłym przedziale czasu.
Ważne
Podczas trenowania modelu prognozowania przyszłych wartości upewnij się, że wszystkie funkcje używane w trenowaniu mogą być używane podczas uruchamiania przewidywań dla zamierzonego horyzontu. Na przykład podczas tworzenia prognozy popytu, w tym funkcji dla bieżącej ceny akcji, może znacznie zwiększyć dokładność trenowania. Jeśli jednak zamierzasz prognozować z długim horyzontem, może nie być w stanie dokładnie przewidzieć przyszłych wartości zapasów odpowiadających przyszłym punktom szeregów czasowych, a dokładność modelu może cierpieć.
Możesz określić oddzielne dane szkoleniowe i dane weryfikacji bezpośrednio w AutoMLConfig obiekcie. Dowiedz się więcej o autoMLConfig.
W przypadku prognozowania szeregów czasowych domyślnie do walidacji jest używana tylko walidacja krzyżowa ROCV (Rolling Origin Cross Validation). ROCV dzieli serię na dane trenowania i walidacji przy użyciu punktu czasu pochodzenia. Przesuwanie źródła w czasie generuje fałdy krzyżowej weryfikacji. Ta strategia zachowuje integralność danych szeregów czasowych i eliminuje ryzyko wycieku danych.
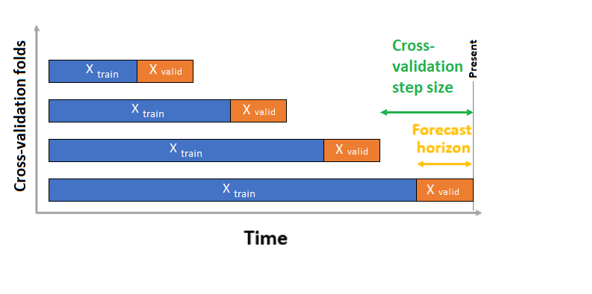
Przekaż dane trenowania i weryfikacji jako jeden zestaw danych do parametru training_data. Ustaw liczbę składań krzyżowych za pomocą parametru n_cross_validations i ustaw liczbę okresów między dwoma kolejnymi fałdami krzyżowymi walidacji z wartością cv_step_size. Można również pozostawić parametry puste lub oba, a automl ustawia je automatycznie.
DOTYCZY: Zestaw SDK języka Python w wersji 1
automl_config = AutoMLConfig(task='forecasting',
training_data= training_data,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
...
**time_series_settings)
Możesz również przynieść własne dane weryfikacji, dowiedzieć się więcej w temacie Konfigurowanie podziałów danych i krzyżowego sprawdzania poprawności w rozwiązaniu AutoML.
Dowiedz się więcej o tym, jak rozwiązanie AutoML stosuje krzyżową walidację, aby zapobiec nadmiernemu dopasowaniu modeli.
Konfigurowanie eksperymentu
Obiekt AutoMLConfig definiuje ustawienia i dane niezbędne do zadania zautomatyzowanego uczenia maszynowego. Konfiguracja modelu prognozowania jest podobna do konfiguracji standardowego modelu regresji, ale niektóre modele, opcje konfiguracji i kroki cechowania istnieją specjalnie dla danych szeregów czasowych.
Obsługiwane modele
Zautomatyzowane uczenie maszynowe automatycznie próbuje różnych modeli i algorytmów w ramach procesu tworzenia i dostrajania modelu. Jako użytkownik nie ma potrzeby określania algorytmu. W przypadku eksperymentów prognozowania zarówno natywne modele szeregów czasowych, jak i uczenia głębokiego są częścią systemu rekomendacji.
Napiwek
Tradycyjne modele regresji są również testowane w ramach systemu rekomendacji na potrzeby prognozowania eksperymentów. Zapoznaj się z pełną listą obsługiwanych modeli w dokumentacji referencyjnej zestawu SDK.
Ustawienia konfiguracji
Podobnie jak w przypadku problemu regresji, definiujesz standardowe parametry trenowania, takie jak typ zadania, liczba iteracji, dane treningowe i liczba krzyżowych walidacji. Zadania prognozowania wymagają time_column_name parametrów i forecast_horizon do skonfigurowania eksperymentu. Jeśli dane zawierają wiele szeregów czasowych, takich jak dane sprzedaży dla wielu magazynów lub danych energetycznych w różnych stanach, automatyczne uczenie maszynowe automatycznie wykrywa to i ustawia time_series_id_column_names parametr (wersja zapoznawcza) dla Ciebie. Możesz również uwzględnić dodatkowe parametry, aby lepiej skonfigurować przebieg, zobacz sekcję opcjonalne konfiguracje , aby uzyskać więcej szczegółowych informacji na temat tego, co można uwzględnić.
Ważne
Automatyczna identyfikacja szeregów czasowych jest obecnie dostępna w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
| Nazwa parametru | opis |
|---|---|
time_column_name |
Służy do określania kolumny datetime w danych wejściowych używanych do tworzenia szeregów czasowych i wnioskowania o jego częstotliwości. |
forecast_horizon |
Określa liczbę okresów do przodu, które chcesz prognozować. Horyzont znajduje się w jednostkach częstotliwości szeregów czasowych. Jednostki są oparte na interwale czasu danych treningowych, na przykład co miesiąc, co tydzień, które prognostyk powinien przewidzieć. |
Poniższy kod,
ForecastingParametersUżywa klasy do definiowania parametrów prognozowania na potrzeby trenowania eksperymentutime_column_nameUstawia wartość poladay_datetimew zestawie danych.- Ustawia wartość
forecast_horizon50, aby przewidzieć dla całego zestawu testów.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
freq='W')
Są forecasting_parameters one następnie przekazywane do obiektu standardowego AutoMLConfig wraz z forecasting typem zadania, podstawową metrykę, kryteria wyjścia i dane treningowe.
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
import logging
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=15,
enable_early_stopping=True,
training_data=train_data,
label_column_name=label,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
enable_ensembling=False,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
Ilość danych wymaganych do pomyślnego wytrenowania modelu prognozowania za pomocą zautomatyzowanego uczenia maszynowego ma wpływ na forecast_horizonwartości , n_cross_validationsi lub target_rolling_window_size target_lags określone podczas konfigurowania .AutoMLConfig
Poniższa formuła oblicza ilość danych historycznych, które byłyby potrzebne do konstruowania funkcji szeregów czasowych.
Wymagane minimalne dane historyczne: (2x forecast_horizon) + #n_cross_validations + max(max(target_lags), target_rolling_window_size)
Element Error exception jest zgłaszany dla dowolnej serii w zestawie danych, która nie spełnia wymaganej ilości danych historycznych dla określonych ustawień.
Kroki cechowania
W każdym eksperymencie zautomatyzowanego uczenia maszynowego domyślnie stosowane są automatyczne techniki skalowania i normalizacji danych. Te techniki to typy cech , które pomagają niektórym algorytmom, które są wrażliwe na funkcje w różnych skalach. Dowiedz się więcej o domyślnych krokach cechowania w temacie Cechowanie w rozwiązaniu AutoML
Jednak następujące kroki są wykonywane tylko dla forecasting typów zadań:
- Wykrywanie częstotliwości próbkowania szeregów czasowych (na przykład godzinowych, dziennych, tygodniowych) i tworzenie nowych rekordów dla nieobecnych punktów czasowych w celu ciągłego tworzenia serii.
- Impute missing values in the target (via forward-fill) and feature columns (using median column values) (Impute missing values in the target (via forward-fill) and feature columns (using median column values) (Impute missing values in the target (via forward-fill) and feature columns (using median column values)
- Tworzenie funkcji opartych na identyfikatorach szeregów czasowych w celu włączenia stałych efektów w różnych seriach
- Tworzenie funkcji opartych na czasie w celu ułatwienia uczenia się wzorców sezonowych
- Kodowanie zmiennych kategorii do ilości liczbowych
- Wykryj niestądające szeregi czasowe i automatycznie je różnicuje, aby ograniczyć wpływ elementów głównych jednostek.
Aby wyświetlić pełną listę możliwych funkcji opracowanych na podstawie danych szeregów czasowych, zobacz TimeIndexFeaturizer Class (Klasa TimeIndexFeaturizer).
Uwaga
Zautomatyzowane kroki cechowania uczenia maszynowego (normalizacja cech, obsługa brakujących danych, konwertowanie tekstu na liczbowe itp.) stają się częścią modelu bazowego. W przypadku korzystania z modelu do przewidywania te same kroki cechowania stosowane podczas trenowania są stosowane automatycznie do danych wejściowych.
Dostosowywanie cechowania
Istnieje również możliwość dostosowania ustawień cechowania w celu zapewnienia, że dane i funkcje używane do trenowania modelu uczenia maszynowego powodują odpowiednie przewidywania.
Obsługiwane dostosowania zadań forecasting obejmują:
| Dostosowanie | Definicja |
|---|---|
| Aktualizacja celu kolumny | Zastąpij automatycznie wykryty typ funkcji dla określonej kolumny. |
| Aktualizacja parametrów transformatora | Zaktualizuj parametry określonego transformatora. Obecnie obsługuje program Imputer (fill_value i medianę). |
| Usuwanie kolumn | Określa kolumny do upuszczania z cechowania. |
Aby dostosować cechowanie za pomocą zestawu SDK, określ "featurization": FeaturizationConfig w AutoMLConfig obiekcie . Dowiedz się więcej o cechach niestandardowych.
Uwaga
Funkcja upuszczania kolumn jest przestarzała w wersji 1.19 zestawu SDK. Porzucanie kolumn z zestawu danych w ramach czyszczenia danych przed użyciem ich w zautomatyzowanym eksperymencie uczenia maszynowego.
featurization_config = FeaturizationConfig()
# `logQuantity` is a leaky feature, so we remove it.
featurization_config.drop_columns = ['logQuantitity']
# Force the CPWVOL5 feature to be of numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeroes.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill mising values in the `INCOME` column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
Jeśli używasz programu Azure Machine Learning Studio do eksperymentu, zobacz , jak dostosować cechowanie w studio.
Konfiguracje opcjonalne
Bardziej opcjonalne konfiguracje są dostępne dla zadań prognozowania, takich jak włączanie uczenia głębokiego i określanie docelowej agregacji okna kroczącego. Pełna lista dodatkowych parametrów jest dostępna w dokumentacji referencyjnej zestawu SDK ForecastingParameters.
Częstotliwość i docelowa agregacja danych
Użyj parametru frequency, freq, aby uniknąć błędów spowodowanych przez nieregularne dane. Nieregularne dane obejmują dane, które nie są zgodne z określonym cyklem, takimi jak dane godzinowe lub dzienne.
W przypadku wysoce nieregularnych danych lub w przypadku różnych potrzeb biznesowych użytkownicy mogą opcjonalnie ustawić żądaną częstotliwość prognoz, freqi określić target_aggregation_function wartość , aby zagregować kolumnę docelową szeregów czasowych. Te dwa ustawienia w AutoMLConfig obiekcie mogą pomóc zaoszczędzić trochę czasu na przygotowaniu danych.
Obsługiwane operacje agregacji dla wartości kolumn docelowych obejmują:
| Function | opis |
|---|---|
sum |
Suma wartości docelowych |
mean |
Średnia lub średnia wartości docelowych |
min |
Minimalna wartość elementu docelowego |
max |
Maksymalna wartość elementu docelowego |
Włączanie uczenia głębokiego
Uwaga
Obsługa sieci rozproszonej na potrzeby prognozowania w zautomatyzowanym uczeniu maszynowym jest dostępna w wersji zapoznawczej i nie jest obsługiwana w przypadku lokalnych przebiegów lub przebiegów zainicjowanych w usłudze Databricks.
Możesz również zastosować uczenie głębokie za pomocą głębokich sieci neuronowych, DNN, aby poprawić wyniki modelu. Uczenie głębokie zautomatyzowanego uczenia maszynowego umożliwia prognozowanie niezmiennych i wielowarianicznych danych szeregów czasowych.
Modele uczenia głębokiego mają trzy funkcje wewnętrzne:
- Mogą uczyć się z dowolnych mapowań z danych wejściowych do danych wyjściowych
- Obsługują one wiele danych wejściowych i wyjściowych
- Mogą one automatycznie wyodrębniać wzorce w danych wejściowych obejmujących długie sekwencje.
Aby włączyć uczenie głębokie, ustaw element enable_dnn=True w AutoMLConfig obiekcie .
automl_config = AutoMLConfig(task='forecasting',
enable_dnn=True,
...
forecasting_parameters=forecasting_parameters)
Ostrzeżenie
Po włączeniu nazwy sieci rozproszonej dla eksperymentów utworzonych za pomocą zestawu SDK najlepsze wyjaśnienia modelu są wyłączone.
Aby włączyć nazwę sieci rozproszonej dla eksperymentu automatycznego uczenia maszynowego utworzonego w usłudze Azure Machine Learning Studio, zobacz ustawienia typu zadania w interfejsie użytkownika programu Studio.
Agregacja okna operacyjnego docelowego
Często najlepsze informacje dla prognostycy to ostatnia wartość celu. Docelowe agregacje okien rolowych umożliwiają dodawanie agregacji stopniowej wartości danych jako funkcji. Generowanie i używanie tych funkcji jako dodatkowych danych kontekstowych pomaga w dokładności modelu trenowania.
Załóżmy na przykład, że chcesz przewidzieć zapotrzebowanie na energię. Możesz dodać funkcję okna rolkowego z trzech dni, aby uwzględnić zmiany cieplne w ogrzewanych przestrzeniach. W tym przykładzie utwórz to okno, ustawiając target_rolling_window_size= 3 w konstruktorze AutoMLConfig .
W tabeli przedstawiono wynikowe inżynierii cech, które występują po zastosowaniu agregacji okien. Kolumny dla wartości minimalnej, maksymalnej i sumy są generowane w oknie przesuwanym z trzech na podstawie zdefiniowanych ustawień. Każdy wiersz ma nową funkcję obliczeniową, w przypadku znacznika czasu dla 8 września 2017 r. 4:00 maksymalna, minimalna i suma wartości są obliczane przy użyciu wartości zapotrzebowania dla 8 września 2017 r. 1:00–3:00. To okno z trzema przesunięciami w celu wypełnienia danych dla pozostałych wierszy.

Wyświetl przykładowy kod języka Python stosujący funkcję agregacji docelowego okna kroczącego.
Obsługa serii krótkiej
Zautomatyzowane uczenie maszynowe uwzględnia szereg czasowy serii krótkiej, jeśli nie ma wystarczającej liczby punktów danych, aby przeprowadzić fazy trenowania i walidacji tworzenia modelu. Liczba punktów danych różni się w przypadku każdego eksperymentu i zależy od max_horizon, liczby podziałów krzyżowej weryfikacji i długości wyszukiwania wstecznego modelu, czyli maksymalnej historii potrzebnej do konstruowania funkcji szeregów czasowych.
Zautomatyzowane uczenie maszynowe domyślnie oferuje obsługę serii krótkich z parametrem short_series_handling_configuration ForecastingParameters w obiekcie.
Aby włączyć obsługę serii krótkich, freq należy również zdefiniować parametr . Aby zdefiniować częstotliwość godzinową, ustawimy wartość freq='H'. Wyświetl opcje ciągów częstotliwości, odwiedzając sekcję obiektów DataOffset na stronie szeregów czasowych biblioteki pandas. Aby zmienić domyślne zachowanie, short_series_handling_configuration = 'auto'zaktualizuj short_series_handling_configuration parametr w ForecastingParameter obiekcie .
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecast_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
short_series_handling_configuration='auto',
freq = 'H',
target_lags='auto')
Poniższa tabela zawiera podsumowanie dostępnych ustawień programu short_series_handling_config.
| Ustawienie | opis |
|---|---|
auto |
Wartość domyślna obsługi serii krótkich. - Jeśli wszystkie serie są krótkie, dodaj dane. - Jeśli nie wszystkie serie są krótkie, upuść krótką serię. |
pad |
Jeśli short_series_handling_config = padwartość , zautomatyzowane uczenie maszynowe dodaje losowe wartości do każdej znalezionej serii krótkiej. Poniżej wymieniono typy kolumn i ich zawartość: - Kolumny obiektów z siecią NaNs - Kolumny liczbowe z 0 - Kolumny logiczne/logiczne z fałszem - Kolumna docelowa jest dopełniona wartościami losowymi o średniej zera i odchylenia standardowego 1. |
drop |
W przypadku short_series_handling_config = drop, zautomatyzowane uczenie maszynowe pominie serię krótką i nie będzie używane do trenowania ani przewidywania. Przewidywania dla tych serii zwracają wartości NaN. |
None |
Żadna seria nie jest wypełniona lub porzucona |
Ostrzeżenie
Wypełnienie może mieć wpływ na dokładność wynikowego modelu, ponieważ wprowadzamy sztuczne dane tylko w celu wcześniejszego trenowania bez niepowodzeń. Jeśli wiele serii jest krótkich, może być również widoczny wpływ na wyniki objaśnienia
Wykrywanie i obsługa niestacjonarnych szeregów czasowych
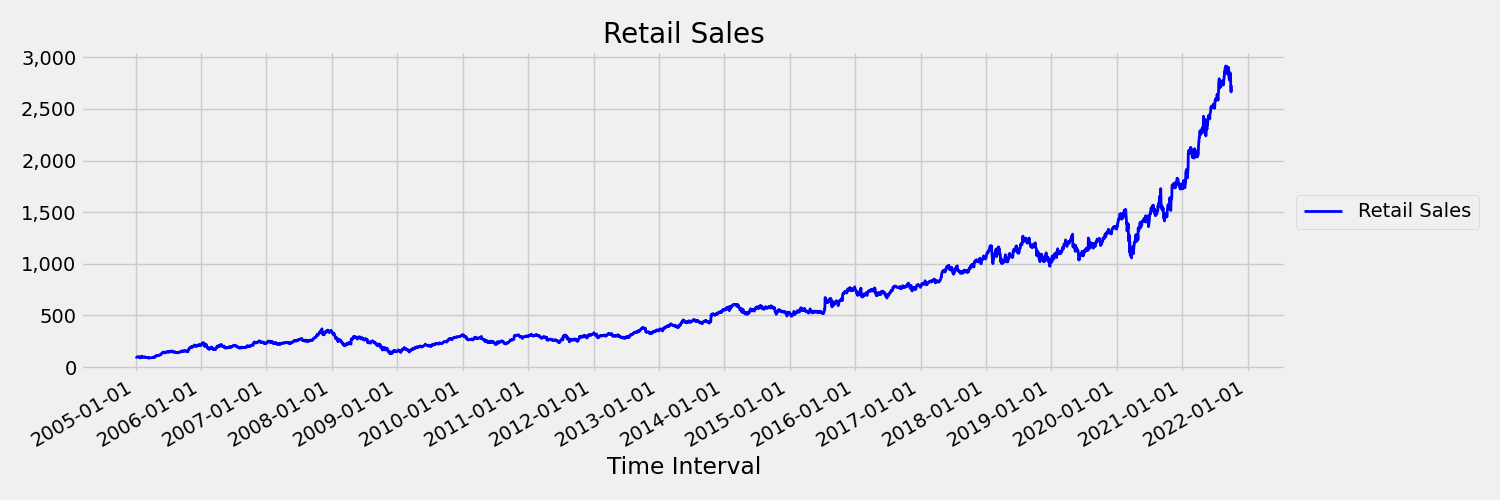
Szereg czasowy, którego momenty (średnia i wariancja) zmieniają się w czasie, jest nazywany nieruchomym. Na przykład szeregi czasowe, które wykazują trendy stochastyczne, są nieruchome z natury. Aby to zwizualizować, na poniższej ilustracji przedstawiono serię, która zwykle rośnie. Teraz oblicz i porównaj wartości średnie (średnie) dla pierwszej i drugiej połowy serii. Czy są one takie same? Tutaj średnia serii w pierwszej połowie wykresu jest mniejsza niż w drugiej połowie. Fakt, że średnia serii zależy od interwału czasu, na którym patrzy, jest przykładem różnych momentów. Tutaj średnia serii jest pierwszą chwilą.
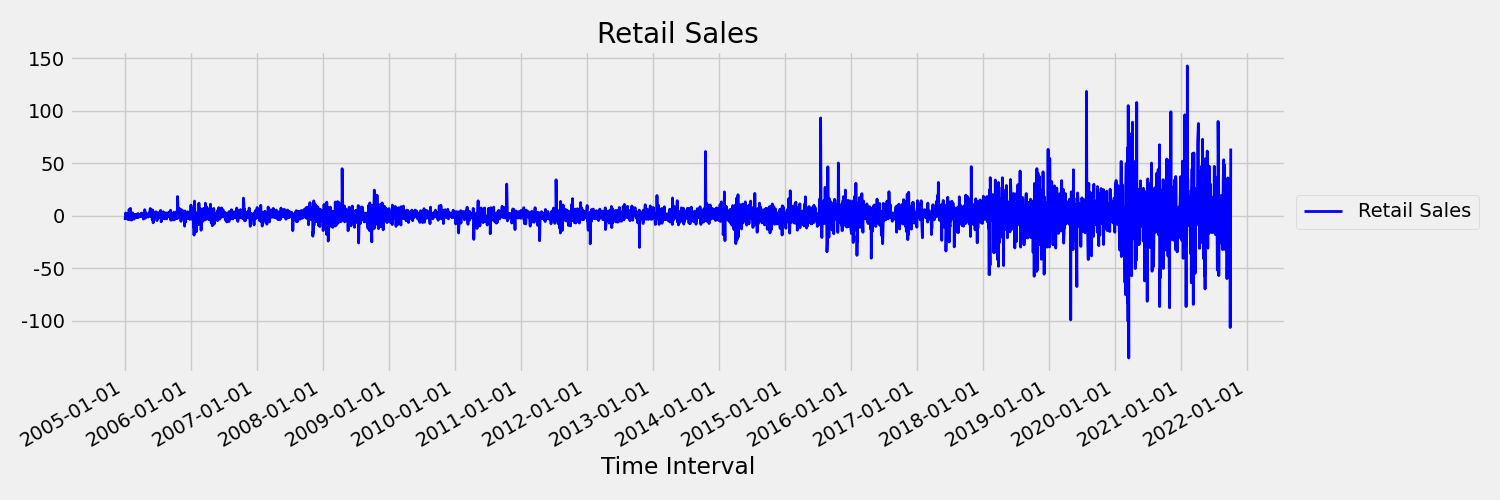
Następnie przyjrzyjmy się obrazowi, który przedstawia oryginalną serię w pierwszych różnicach, $x_t = y_t - y_{t-1}$ gdzie $x_t$ jest zmianą sprzedaży detalicznej i $y_t$ i $y_{t-1}$ reprezentują oryginalną serię i jej pierwsze opóźnienie. Średnia serii jest w przybliżeniu stała, niezależnie od przedziału czasu, na który patrzy. Jest to przykład serii czasów stacjonarnych pierwszej kolejności. Powodem, dla którego dodaliśmy pierwszy termin zamówienia, jest to, że pierwszy moment (średnia) nie zmienia się z interwałem czasu, nie można powiedzieć o wariancji, co jest drugą chwilą.
Modele uczenia maszynowego rozwiązania AutoML nie mogą z natury radzić sobie z trendami stochastycznymi lub innymi znanymi problemami związanymi z nieruchomymi szeregami czasowymi. W związku z tym ich dokładność prognozy z próbki jest "słaba", jeśli takie trendy są obecne.
Rozwiązanie AutoML automatycznie analizuje zestaw danych szeregów czasowych, aby sprawdzić, czy jest on nieruchomy, czy nie. W przypadku wykrycia nieruchomych szeregów czasowych rozwiązanie AutoML automatycznie stosuje przekształcenie różnicowe w celu ograniczenia wpływu nieruchomych szeregów czasowych.
Uruchamianie eksperymentu
AutoMLConfig Gdy obiekt jest gotowy, możesz przesłać eksperyment. Po zakończeniu działania modelu pobierz najlepszą iterację uruchamiania.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-forecasting")
local_run = experiment.submit(automl_config, show_output=True)
best_run, fitted_model = local_run.get_output()
Prognozowanie przy użyciu najlepszego modelu
Użyj najlepszej iteracji modelu, aby prognozować wartości danych, które nie były używane do trenowania modelu.
Ocenianie dokładności modelu za pomocą prognozy stopniowej
Przed wprowadzeniem modelu do środowiska produkcyjnego należy ocenić jego dokładność na zestawie testowym przechowywanym na podstawie danych treningowych. Procedura najlepszych rozwiązań to tak zwana ocena krocząca, która przerzuca trenowany prognostator w czasie w czasie w zestawie testowym, średnio uśrednione metryki błędów w kilku oknach przewidywania w celu uzyskania statystycznie niezawodnych szacunków dla niektórych zestawów wybranych metryk. Najlepiej, aby zestaw testowy oceny był długi w stosunku do horyzontu prognozy modelu. Oszacowania błędu prognozowania mogą być w przeciwnym razie statystycznie hałaśliwe i dlatego mniej wiarygodne.
Załóżmy na przykład, że wytrenujesz model sprzedaży dziennej, aby przewidywać zapotrzebowanie do dwóch tygodni (14 dni) w przyszłości. Jeśli jest wystarczająca ilość dostępnych danych historycznych, możesz zarezerwować ostatnie kilka miesięcy do nawet roku danych dla zestawu testowego. Ocena stopniowa rozpoczyna się od wygenerowania 14-dniowej prognozy z wyprzedzeniem dla pierwszych dwóch tygodni zestawu testowego. Następnie prognostyk jest zaawansowany o kilka dni do zestawu testów i generuje kolejną 14-dniową prognozę z nowej pozycji. Proces będzie kontynuowany do momentu, aż do końca zestawu testów.
Aby przeprowadzić ocenę stopniową, należy wywołać rolling_forecast metodę fitted_model, a następnie obliczyć żądane metryki w wyniku. Załóżmy na przykład, że masz funkcje zestawu testów w ramce danych biblioteki pandas o nazwie test_features_df i zestaw testów wartości rzeczywistych obiektu docelowego w tablicy numpy o nazwie test_target. Ocena stopniowa przy użyciu błędu średniokwadratowego jest wyświetlana w poniższym przykładzie kodu:
from sklearn.metrics import mean_squared_error
rolling_forecast_df = fitted_model.rolling_forecast(
test_features_df, test_target, step=1)
mse = mean_squared_error(
rolling_forecast_df[fitted_model.actual_column_name], rolling_forecast_df[fitted_model.forecast_column_name])
W tym przykładzie rozmiar kroku prognozy stopniowej jest ustawiony na jeden, co oznacza, że prognostator jest zaawansowany jeden okres lub jeden dzień w naszym przykładzie przewidywania zapotrzebowania w każdej iteracji. Łączna liczba prognoz zwracanych w rolling_forecast ten sposób zależy od długości zestawu testowego i tego rozmiaru kroku. Aby uzyskać więcej szczegółów i przykładów, zobacz dokumentację rolling_forecast() i notes prognozowanie danych szkoleniowych.
Przewidywanie w przyszłości
Funkcja forecast_quantiles() umożliwia określenie, kiedy powinny być uruchamiane przewidywania, w przeciwieństwie do predict() metody, która jest zwykle używana do zadań klasyfikacji i regresji. Metoda forecast_quantiles() domyślnie generuje prognozę punktu lub prognozę średniej/mediany, która nie ma stożka niepewności wokół niej. Dowiedz się więcej w notesie Prognozowanie od danych szkoleniowych.
W poniższym przykładzie najpierw zastąp NaNwszystkie wartości w pliku y_pred . Źródło prognozy znajduje się na końcu danych treningowych w tym przypadku. Jeśli jednak zastąpisz tylko drugą połowę y_pred wartością NaN, funkcja pozostawi wartości liczbowe w pierwszej połowie niezmodyfikowane, ale prognozowanie NaN wartości w drugiej połowie. Funkcja zwraca zarówno prognozowane wartości, jak i wyrównane funkcje.
Można również użyć parametru forecast_destination forecast_quantiles() w funkcji do prognozowania wartości do określonej daty.
label_query = test_labels.copy().astype(np.float)
label_query.fill(np.nan)
label_fcst, data_trans = fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Często klienci chcą zrozumieć przewidywania w określonym kwantylu dystrybucji. Na przykład gdy prognoza jest używana do kontrolowania spisu, takiego jak artykuły spożywcze lub maszyny wirtualne dla usługi w chmurze. W takich przypadkach punkt kontrolny jest zwykle podobny do "chcemy, aby element był w magazynie i nie zabrakło 99% czasu". Poniżej pokazano, jak określić kwantyle, które mają być widoczne dla prognoz, takich jak 50. lub 95. percentyl. Jeśli nie określisz kwantylu, na przykład w powyższym przykładzie kodu, generowane są tylko 50. przewidywania percentylu.
# specify which quantiles you would like
fitted_model.quantiles = [0.05,0.5, 0.9]
fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
Możesz obliczyć metryki modelu, takie jak błąd średniokwadratowy (RMSE) lub średni bezwzględny błąd procentowy (MAPE), aby ułatwić oszacowanie wydajności modeli. Zobacz sekcję Evaluate (Ocena) notesu Dotyczącego udziału rowerów, aby zapoznać się z przykładem.
Po ustaleniu ogólnej dokładności modelu najbardziej realistycznym następnym krokiem jest użycie modelu do prognozowania nieznanych wartości w przyszłości.
Podaj zestaw danych w tym samym formacie co zestaw test_dataset testów, ale z przyszłymi datami/godzinami, a wynikowy zestaw przewidywania to prognozowane wartości dla każdego kroku szeregów czasowych. Załóżmy, że ostatnie rekordy szeregów czasowych w zestawie danych były przeznaczone dla 31.01.2018 r. Aby prognozować zapotrzebowanie na następny dzień (lub dowolną liczbę okresów, które należy przewidzieć, <= forecast_horizon), utwórz pojedynczy rekord szeregów czasowych dla każdego magazynu 01/01/2019.
day_datetime,store,week_of_year
01/01/2019,A,1
01/01/2019,A,1
Powtórz kroki niezbędne do załadowania tych przyszłych danych do ramki danych, a następnie uruchom polecenie best_run.forecast_quantiles(test_dataset) , aby przewidzieć przyszłe wartości.
Uwaga
Przewidywania w przykładach nie są obsługiwane w przypadku prognozowania za pomocą zautomatyzowanego uczenia maszynowego, gdy target_lags i/lub target_rolling_window_size są włączone.
Prognozowanie na dużą skalę
Istnieją scenariusze, w których jeden model uczenia maszynowego jest niewystarczający, a wymagane jest wiele modeli uczenia maszynowego. Na przykład przewidywanie sprzedaży dla każdego indywidualnego sklepu dla marki lub dostosowanie środowiska do poszczególnych użytkowników. Tworzenie modelu dla każdego wystąpienia może prowadzić do zwiększenia wyników wielu problemów z uczeniem maszynowym.
Grupowanie to koncepcja prognozowania szeregów czasowych, która umożliwia łączenie szeregów czasowych w celu wytrenowania pojedynczego modelu na grupę. Takie podejście może być szczególnie przydatne, jeśli masz szeregi czasowe, które wymagają złagodzenia, wypełnienia lub jednostek w grupie, które mogą korzystać z historii lub trendów z innych jednostek. Wiele modeli i hierarchicznych prognozowania szeregów czasowych to rozwiązania oparte na zautomatyzowanym uczeniu maszynowym dla tych scenariuszy prognozowania na dużą skalę.
Wiele modeli
Rozwiązanie wielu modeli usługi Azure Machine Learning z automatycznym uczeniem maszynowym umożliwia użytkownikom równoległe trenowanie milionów modeli i zarządzanie nimi. Wiele modeli Akcelerator rozwiązań używa potoków usługi Azure Machine Learning do trenowania modelu. W szczególności jest używany obiekt Pipeline i ParalleRunStep i wymagają określonych parametrów konfiguracji ustawionych za pomocą parametrów ParallelRunConfig.
Na poniższym diagramie przedstawiono przepływ pracy dla wielu modeli rozwiązania.

Poniższy kod demonstruje kluczowe parametry, które użytkownicy muszą skonfigurować w wielu uruchomionych modelach. Zobacz wiele modeli — notes zautomatyzowanego uczenia maszynowego, aby zapoznać się z przykładem prognozowania wielu modeli
from azureml.train.automl.runtime._many_models.many_models_parameters import ManyModelsTrainParameters
partition_column_names = ['Store', 'Brand']
automl_settings = {"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10, #This needs to be changed based on the dataset. Explore how long training is taking before setting this value
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,}
mm_paramters = ManyModelsTrainParameters(automl_settings=automl_settings, partition_column_names=partition_column_names)
Prognozowanie hierarchicznych szeregów czasowych
W większości aplikacji klienci muszą zrozumieć swoje prognozy na poziomie makro i mikro. Prognozy mogą przewidywać sprzedaż produktów w różnych lokalizacjach geograficznych lub zrozumieć oczekiwane zapotrzebowanie pracowników na różne organizacje w firmie. Niezbędna jest możliwość trenowania modelu uczenia maszynowego w celu inteligentnego prognozowania danych hierarchii.
Hierarchiczny szereg czasowy to struktura, w której każda z unikatowych serii jest rozmieszczona w hierarchii na podstawie wymiarów, takich jak lokalizacja geograficzna lub typ produktu. W poniższym przykładzie przedstawiono dane z unikatowymi atrybutami, które tworzą hierarchię. Nasza hierarchia jest definiowana przez: typ produktu, taki jak słuchawki lub tablety, kategoria produktu, która dzieli typy produktów na akcesoria i urządzenia, a region, w którym są sprzedawane produkty.

Aby jeszcze bardziej to zwizualizować, poziomy liści hierarchii zawierają wszystkie szeregi czasowe z unikatowymi kombinacjami wartości atrybutów. Każdy wyższy poziom w hierarchii uwzględnia jeden mniejszy wymiar do definiowania szeregów czasowych i agreguje każdy zestaw węzłów podrzędnych z niższego poziomu do węzła nadrzędnego.

Hierarchiczne rozwiązanie szeregów czasowych jest oparte na rozwiązaniu Wiele modeli i współużytkuje podobną konfigurację.
Poniższy kod przedstawia kluczowe parametry konfigurowania hierarchicznych przebiegów prognozowania szeregów czasowych. Zobacz hierarchiczny notes szeregów czasowych — zautomatyzowanego uczenia maszynowego, aby zapoznać się z przykładem końcowym.
from azureml.train.automl.runtime._hts.hts_parameters import HTSTrainParameters
model_explainability = True
engineered_explanations = False # Define your hierarchy. Adjust the settings below based on your dataset.
hierarchy = ["state", "store_id", "product_category", "SKU"]
training_level = "SKU"# Set your forecast parameters. Adjust the settings below based on your dataset.
time_column_name = "date"
label_column_name = "quantity"
forecast_horizon = 7
automl_settings = {"task" : "forecasting",
"primary_metric" : "normalized_root_mean_squared_error",
"label_column_name": label_column_name,
"time_column_name": time_column_name,
"forecast_horizon": forecast_horizon,
"hierarchy_column_names": hierarchy,
"hierarchy_training_level": training_level,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,
"model_explainability": model_explainability,# The following settings are specific to this sample and should be adjusted according to your own needs.
"iteration_timeout_minutes" : 10,
"iterations" : 10,
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
}
hts_parameters = HTSTrainParameters(
automl_settings=automl_settings,
hierarchy_column_names=hierarchy,
training_level=training_level,
enable_engineered_explanations=engineered_explanations
)
Przykładowe notesy
Zobacz przykładowe notesy prognozowania, aby uzyskać szczegółowe przykłady kodu zaawansowanej konfiguracji prognozowania obejmujące następujące elementy:
- wykrywanie świąt i dobór cech
- weryfikacja krzyżowa przy użyciu źródła kroczącego
- konfigurowalne opóźnienia
- zagregowane funkcje kroczącego przedziału czasu
Następne kroki
- Dowiedz się więcej na temat wdrażania modelu AutoML w punkcie końcowym online.
- Dowiedz się więcej o możliwości interpretowania: wyjaśnienia modelu w zautomatyzowanym uczeniu maszynowym (wersja zapoznawcza).
- Dowiedz się, jak rozwiązanie AutoML tworzy modele prognozowania.