Konfigurowanie zautomatyzowanego trenowania uczenia maszynowego bez kodu na potrzeby danych tabelarycznych przy użyciu interfejsu użytkownika programu Studio
W tym artykule skonfigurujesz zadania trenowania zautomatyzowanego uczenia maszynowego przy użyciu zautomatyzowanego uczenia maszynowego w usłudze Azure Machine Learning Studio. Takie podejście umożliwia skonfigurowanie zadania bez konieczności pisania pojedynczego wiersza kodu. Zautomatyzowane uczenie maszynowe to proces, w którym usługa Azure Machine Learning wybiera najlepszy algorytm uczenia maszynowego dla konkretnych danych. Proces umożliwia szybkie generowanie modeli uczenia maszynowego. Aby uzyskać więcej informacji, zobacz Omówienie procesu zautomatyzowanego uczenia maszynowego.
Ten samouczek zawiera ogólne omówienie pracy z zautomatyzowanym uczeniem maszynowym w studio. Poniższe artykuły zawierają szczegółowe instrukcje dotyczące pracy z określonymi modelami uczenia maszynowego:
- Klasyfikacja: Samouczek: trenowanie modelu klasyfikacji za pomocą zautomatyzowanego uczenia maszynowego w studio
- Prognozowanie szeregów czasowych: Samouczek: prognozowanie zapotrzebowania za pomocą zautomatyzowanego uczenia maszynowego w studio
- Przetwarzanie języka naturalnego (NLP): konfigurowanie zautomatyzowanego uczenia maszynowego w celu trenowania modelu NLP (interfejs wiersza polecenia platformy Azure lub zestawu SDK języka Python)
- Przetwarzanie obrazów: konfigurowanie rozwiązania AutoML do trenowania modeli przetwarzania obrazów (interfejs wiersza polecenia platformy Azure lub zestaw SDK języka Python)
- Regresja: trenowanie modelu regresji za pomocą zautomatyzowanego uczenia maszynowego (python SDK)
Wymagania wstępne
Subskrypcja platformy Azure. Możesz utworzyć bezpłatne lub płatne konto dla usługi Azure Machine Learning.
Obszar roboczy usługi Azure Machine Learning lub wystąpienie obliczeniowe. Aby przygotować te zasoby, zobacz Szybki start: rozpoczynanie pracy z usługą Azure Machine Learning.
Zasób danych do użycia w zadaniu trenowania zautomatyzowanego uczenia maszynowego. W tym samouczku opisano sposób wybierania istniejącego zasobu danych lub tworzenia zasobu danych ze źródła danych, takiego jak plik lokalny, adres URL sieci Web lub magazyn danych. Aby uzyskać więcej informacji, zobacz Tworzenie zasobów danych i zarządzanie nimi.
Ważne
Istnieją dwa wymagania dotyczące danych szkoleniowych:
- Dane muszą być w formie tabelarycznej.
- Wartość do przewidzenia (kolumna docelowa) musi być obecna w danych.
Tworzenie eksperymentu
Utwórz i uruchom eksperyment, wykonując następujące kroki:
Zaloguj się do usługi Azure Machine Learning Studio i wybierz swoją subskrypcję i obszar roboczy.
W menu po lewej stronie wybierz pozycję Zautomatyzowane uczenie maszynowe w sekcji Tworzenie :
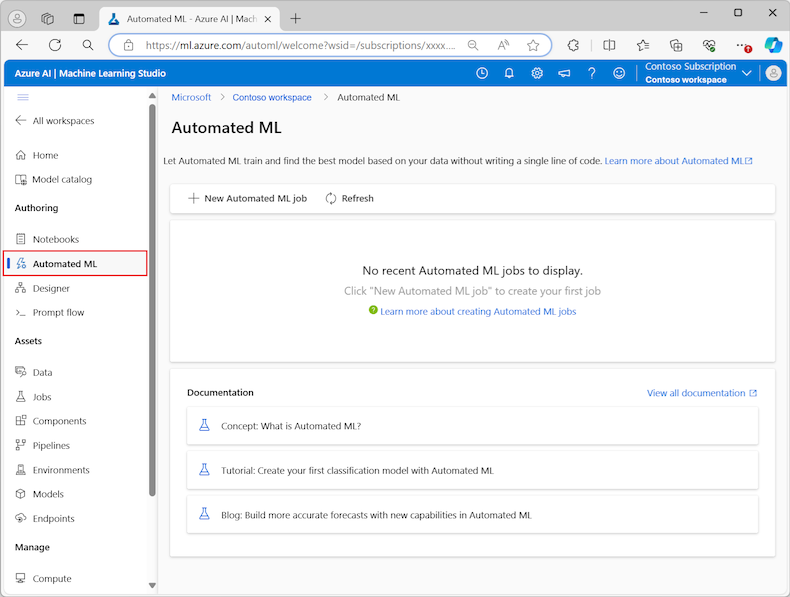
Podczas pierwszej pracy z eksperymentami w studio zostanie wyświetlona pusta lista i linki do dokumentacji. W przeciwnym razie zostanie wyświetlona lista ostatnich eksperymentów zautomatyzowanego uczenia maszynowego, w tym elementów utworzonych za pomocą zestawu Azure Machine Learning SDK.
Wybierz pozycję Nowe zadanie zautomatyzowanego uczenia maszynowego , aby rozpocząć proces przesyłania zautomatyzowanego uczenia maszynowego .
Domyślnie proces wybiera opcję Trenuj automatycznie na karcie Metoda trenowania i kontynuuje ustawienia konfiguracji.
Na karcie Ustawienia podstawowe wprowadź wartości wymaganych ustawień, w tym nazwę zadania i nazwę eksperymentu. Możesz również podać wartości ustawień opcjonalnych zgodnie z potrzebami.
Wybierz przycisk Dalej, aby kontynuować.

Identyfikowanie zasobu danych
Na karcie Typ zadania i dane należy określić zasób danych dla eksperymentu oraz model uczenia maszynowego, który będzie używany do trenowania danych.
W tym samouczku możesz użyć istniejącego zasobu danych lub utworzyć nowy zasób danych z pliku na komputerze lokalnym. Strony interfejsu użytkownika programu Studio zmieniają się w zależności od wybranego źródła danych i typu modelu trenowania.
Jeśli zdecydujesz się używać istniejącego zasobu danych, możesz przejść do sekcji Konfigurowanie modelu trenowania.
Aby utworzyć nowy zasób danych, wykonaj następujące kroki:
Aby utworzyć nowy zasób danych z pliku na komputerze lokalnym, wybierz pozycję Utwórz.
Na stronie Typ danych:
- Wprowadź nazwę zasobu dane.
- W polu Typ wybierz pozycję Tabelaryczny z listy rozwijanej.
- Wybierz Dalej.
Na stronie Źródło danych wybierz pozycję Z plików lokalnych.
Usługa Machine Learning Studio dodaje dodatkowe opcje do menu po lewej stronie, aby skonfigurować źródło danych.
Wybierz pozycję Dalej , aby przejść do strony Docelowy typ magazynu, na której określisz lokalizację usługi Azure Storage, aby przekazać zasób danych.
Domyślny kontener magazynu można określić automatycznie utworzony za pomocą obszaru roboczego lub wybrać kontener usługi Storage do użycia na potrzeby eksperymentu.
- W polu Typ magazynu danych wybierz pozycję Azure Blob Storage.
- Na liście magazynów danych wybierz pozycję workspaceblobstore.
- Wybierz Dalej.
Na stronie Wyboru pliku i folderu użyj menu rozwijanego Przekaż pliki lub folder, a następnie wybierz opcję Przekaż pliki lub Przekaż folder.
- Przejdź do lokalizacji danych do przekazania i wybierz pozycję Otwórz.
- Po przekazaniu plików wybierz pozycję Dalej.
Usługa Machine Learning Studio weryfikuje i przekazuje dane.
Uwaga
Jeśli dane stoją za siecią wirtualną, należy włączyć funkcję Pomiń walidację , aby upewnić się, że obszar roboczy będzie mógł uzyskiwać dostęp do danych. Aby uzyskać więcej informacji, zobacz Korzystanie z usługi Azure Machine Learning Studio w sieci wirtualnej platformy Azure.
Sprawdź przekazane dane na stronie Ustawienia , aby uzyskać dokładność. Pola na stronie są wstępnie wypełniane na podstawie typu pliku danych:
Pole opis Format pliku Definiuje układ i typ danych przechowywanych w pliku. Ogranicznik Określa co najmniej jeden znak określający granicę między oddzielnymi, niezależnymi regionami w postaci zwykłego tekstu lub innych strumieni danych. Kodowanie Określa, jakiego bitu do tabeli schematów znaków używać do odczytywania zestawu danych. Nagłówki kolumn Wskazuje, jak są traktowane nagłówki zestawu danych, jeśli istnieją. Pomiń wiersze Wskazuje, ile wierszy zostanie pominiętych w zestawie danych, jeśli istnieje. Wybierz przycisk Dalej , aby przejść do strony Schemat . Ta strona jest również wstępnie wypełniana na podstawie wybranych ustawień. Możesz skonfigurować typ danych dla każdej kolumny, przejrzeć nazwy kolumn i zarządzać kolumnami:
- Aby zmienić typ danych dla kolumny, użyj menu rozwijanego Typ , aby wybrać opcję.
- Aby wykluczyć kolumnę z zasobu danych, przełącz opcję Dołącz dla kolumny.
Wybierz przycisk Dalej , aby przejść do strony Przegląd . Przejrzyj podsumowanie ustawień konfiguracji zadania, a następnie wybierz pozycję Utwórz.
Konfigurowanie modelu trenowania
Gdy zasób danych jest gotowy, program Machine Learning Studio powraca do karty Typ zadania i dane dla procesu zadania Prześlij zautomatyzowane uczenie maszynowe . Nowy zasób danych znajduje się na stronie.
Wykonaj następujące kroki, aby ukończyć konfigurację zadania:
Rozwiń menu rozwijane Wybierz typ zadania, a następnie wybierz model trenowania, który ma być używany w eksperymencie. Opcje obejmują klasyfikację, regresję, prognozowanie szeregów czasowych, przetwarzanie języka naturalnego (NLP) lub przetwarzanie obrazów. Aby uzyskać więcej informacji na temat tych opcji, zobacz opisy obsługiwanych typów zadań.
Po określeniu modelu trenowania wybierz zestaw danych na liście.
Wybierz przycisk Dalej , aby przejść do karty Ustawienia zadania.
Z listy rozwijanej Kolumna docelowa wybierz kolumnę do użycia dla prognoz modelu.
W zależności od modelu trenowania skonfiguruj następujące wymagane ustawienia:
Klasyfikacja: wybierz, czy włączyć uczenie głębokie.
Prognozowanie szeregów czasowych: wybierz, czy włączyć uczenie głębokie, i potwierdzić preferencje dotyczące wymaganych ustawień:
Użyj kolumny Czas, aby określić dane czasu do użycia w modelu.
Wybierz, czy włączyć co najmniej jedną opcję autowykrywania . Po usunięciu zaznaczenia opcji Autowykrywanie, takiej jak horyzont prognozy autowykrywania, można określić określoną wartość. Wartość horyzontu Prognoza wskazuje, ile jednostek czasu (minuty/godziny/dni/tygodnie/miesiące/lata) model może przewidzieć dla przyszłości. Aby przewidzieć, tym bardziej dokładny staje się model, tym bardziej dokładny staje się model.
Aby uzyskać więcej informacji na temat konfigurowania tych ustawień, zobacz Używanie zautomatyzowanego uczenia maszynowego do trenowania modelu prognozowania szeregów czasowych.
Przetwarzanie języka naturalnego: potwierdź preferencje dotyczące wymaganych ustawień:
Użyj opcji Wybierz typ podrzędny, aby skonfigurować typ klasyfikacji podrzędnej dla modelu NLP. Możesz wybrać jedną z klasyfikacji wieloklasowej, klasyfikacji wielu etykiet i rozpoznawania jednostek nazwanych (NER).
W sekcji Ustawienia zamiatania podaj wartości algorytmu współczynnika slack i próbkowania.
W sekcji Obszar wyszukiwania skonfiguruj zestaw opcji algorytmu modelu.
Aby uzyskać więcej informacji na temat konfigurowania tych ustawień, zobacz Konfigurowanie zautomatyzowanego uczenia maszynowego w celu trenowania modelu NLP (interfejsu wiersza polecenia platformy Azure lub zestawu SDK języka Python).
Przetwarzanie obrazów: wybierz, czy włączyć ręczne zamiatanie, i potwierdź preferencje dotyczące wymaganych ustawień:
- Użyj opcji Wybierz typ podrzędny, aby skonfigurować typ klasyfikacji podrzędnej dla modelu przetwarzania obrazów. Możesz wybrać jedną z opcji Klasyfikacja obrazów (wieloklasowa) lub (Multi-label), Wykrywanie obiektów i Wielokąt (segmentacja wystąpień).
Aby uzyskać więcej informacji na temat konfigurowania tych ustawień, zobacz Konfigurowanie rozwiązania AutoML do trenowania modeli przetwarzania obrazów (interfejs wiersza polecenia platformy Azure lub zestaw SDK języka Python).
Określanie ustawień opcjonalnych
Usługa Machine Learning Studio udostępnia opcjonalne ustawienia, które można skonfigurować na podstawie wyboru modelu uczenia maszynowego. W poniższych sekcjach opisano dodatkowe ustawienia.
Konfiguracja dodatkowych ustawień
Możesz wybrać opcję Wyświetl dodatkowe ustawienia konfiguracji, aby wyświetlić akcje, które mają być wykonywane na danych w ramach przygotowań do trenowania.
Na stronie Dodatkowa konfiguracja są wyświetlane wartości domyślne na podstawie wybranego eksperymentu i danych. Możesz użyć wartości domyślnych lub skonfigurować następujące ustawienia:
| Ustawienie | opis |
|---|---|
| Metryka podstawowa | Zidentyfikuj główną metryę oceniania modelu. Aby uzyskać więcej informacji, zobacz Metryki modelu. |
| Włączanie stosu zespołu | Umożliwianie uczenia zespołowego i ulepszanie wyników uczenia maszynowego oraz wydajności predykcyjnej dzięki połączeniu wielu modeli w przeciwieństwie do używania pojedynczych modeli. Aby uzyskać więcej informacji, zobacz modele grupowe. |
| Korzystanie ze wszystkich obsługiwanych modeli | Użyj tej opcji, aby poinstruować zautomatyzowane uczenie maszynowe, czy używać wszystkich obsługiwanych modeli w eksperymencie. Aby uzyskać więcej informacji, zobacz obsługiwane algorytmy dla każdego typu zadania. — Wybierz tę opcję, aby skonfigurować ustawienie Zablokowane modele . — Usuń zaznaczenie tej opcji, aby skonfigurować ustawienie Dozwolone modele . |
| Zablokowane modele | (Dostępne, gdy Wybierz opcję Użyj wszystkich obsługiwanych modeli ) Użyj listy rozwijanej i wybierz modele do wykluczenia z zadania trenowania. |
| Dozwolone modele | (Dostępne, gdy Nie wybrano wszystkich obsługiwanych modeli ) Użyj listy rozwijanej i wybierz modele do użycia dla zadania szkoleniowego. Ważne: dostępne tylko dla eksperymentów zestawu SDK. |
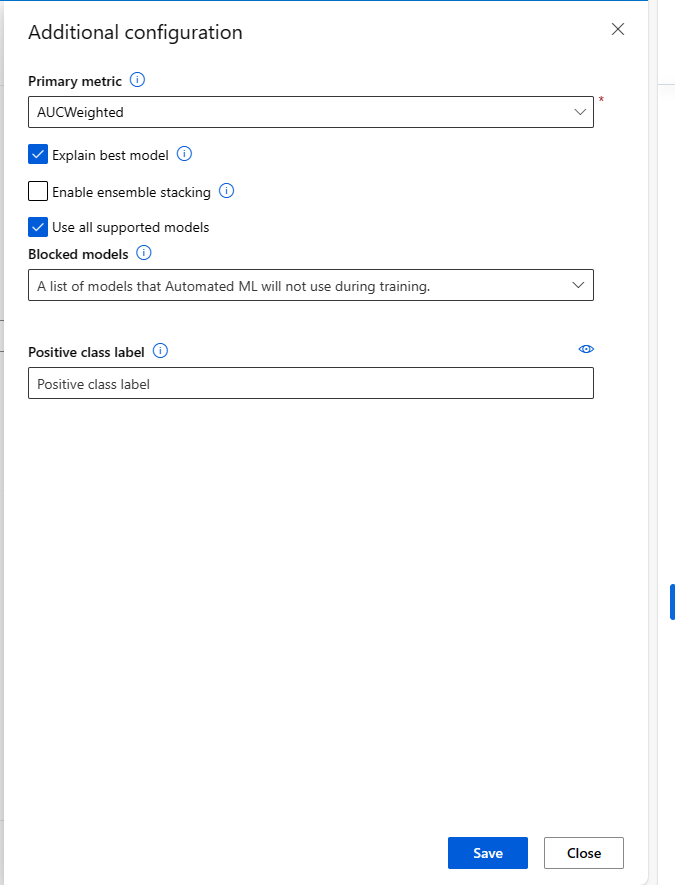
| Wyjaśnienie najlepszego modelu | Wybierz tę opcję, aby automatycznie wyświetlać objaśnienia dla najlepszego modelu utworzonego przez zautomatyzowane uczenie maszynowe. |
| Etykieta klasy dodatniej | Wprowadź etykietę zautomatyzowanego uczenia maszynowego, która ma być używana do obliczania metryk binarnych. |
Konfigurowanie ustawień cechowania
Możesz wybrać opcję Wyświetl ustawienia cechowania, aby wyświetlić akcje, które mają być wykonywane na danych w ramach przygotowań do trenowania.
Na stronie Cechowanie są wyświetlane domyślne techniki cechowania kolumn danych. Możesz włączyć/wyłączyć automatyczną cechowanie i dostosować ustawienia automatycznego cechowania dla eksperymentu.

Wybierz opcję Włącz cechowanie, aby zezwolić na konfigurację.
Ważne
Gdy dane zawierają kolumny nieliczbowe, cechowanie jest zawsze włączone.
Skonfiguruj każdą dostępną kolumnę zgodnie z potrzebami. Poniższa tabela zawiera podsumowanie dostosowań dostępnych obecnie za pośrednictwem programu Studio.
Kolumna Dostosowanie Typ funkcji Zmień typ wartości dla wybranej kolumny. Impute z Wybierz wartość do imputowania brakujących wartości w danych. 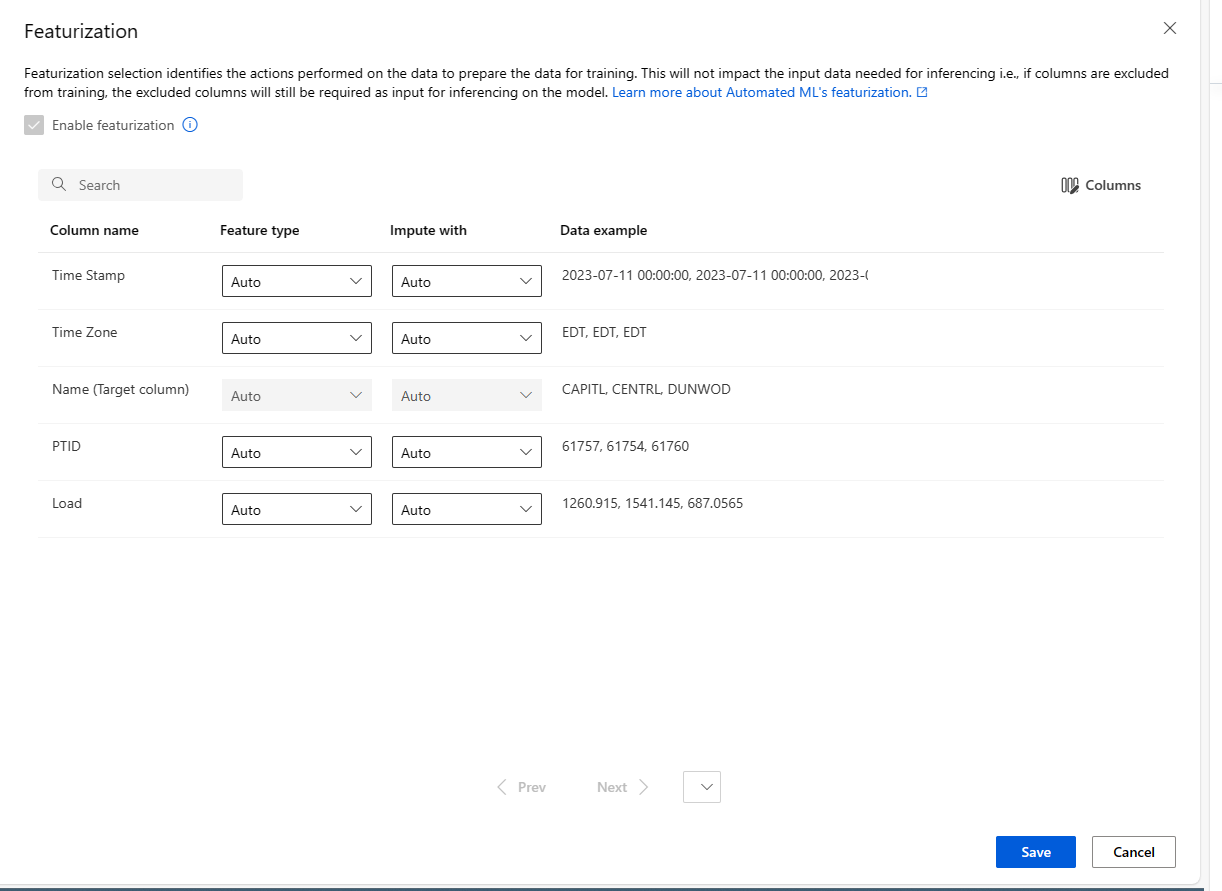

Ustawienia cechowania nie mają wpływu na dane wejściowe potrzebne do wnioskowania. Jeśli wykluczysz kolumny z trenowania, wykluczone kolumny są nadal wymagane jako dane wejściowe do wnioskowania w modelu.
Konfigurowanie limitów dla zadania
Sekcja Limity zawiera opcje konfiguracji dla następujących ustawień:
| Ustawienie | opis | Wartość |
|---|---|---|
| Maksymalna liczba prób | Określ maksymalną liczbę prób do wypróbowania podczas zadania zautomatyzowanego uczenia maszynowego, w którym każda wersja próbna ma inną kombinację algorytmów i hiperparametrów. | Liczba całkowita z zakresu od 1 do 1000 |
| Maksymalna liczba współbieżnych prób | Określ maksymalną liczbę zadań próbnych, które można wykonać równolegle. | Liczba całkowita z zakresu od 1 do 1000 |
| Maksymalna liczba węzłów | Określ maksymalną liczbę węzłów, których to zadanie może używać z wybranego celu obliczeniowego. | Co najmniej 1 w zależności od konfiguracji obliczeniowej |
| Próg wyniku metryki | Wprowadź wartość progu metryki iteracji. Gdy iteracja osiągnie próg, zadanie trenowania kończy się. Należy pamiętać, że znaczące modele mają korelację większą niż zero. W przeciwnym razie wynik jest taki sam jak zgadywanie. | Średni próg metryki między granicami [0, 10] |
| Limit czasu eksperymentu (w minutach) | Określ maksymalny czas uruchomienia całego eksperymentu. Po osiągnięciu limitu eksperyment system anuluje zadanie zautomatyzowanego uczenia maszynowego, w tym wszystkie próby (zadania podrzędne). | Liczba minut |
| Limit czasu iteracji (w minutach) | Określ maksymalny czas uruchamiania każdego zadania w wersji próbnej. Gdy zadanie wersji próbnej osiągnie ten limit, system anuluje wersję próbną. | Liczba minut |
| Włączanie wczesnego kończenia | Użyj tej opcji, aby zakończyć zadanie, gdy wynik nie poprawia się w krótkim okresie. | Wybierz opcję włączenia wczesnego zakończenia zadania |
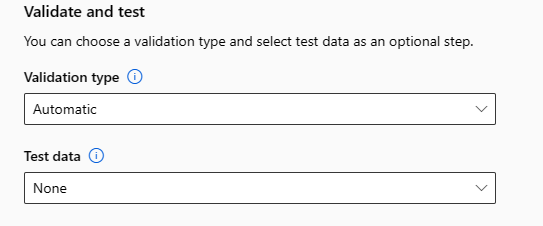
Zweryfikuj i przetestuj
Sekcja Weryfikowanie i testowanie zawiera następujące opcje konfiguracji:
Określ typ weryfikacji, który ma być używany dla zadania szkoleniowego. Jeśli nie określisz jawnie parametru
validation_datalubn_cross_validations, zautomatyzowane uczenie maszynowe stosuje techniki domyślne w zależności od liczby wierszy podanych w jednym zestawie danychtraining_data.Rozmiar danych treningowych Technika walidacji Więcej niż 20 000 wierszy Zastosowano podział danych trenowania/walidacji. Wartość domyślna to 10% początkowego zestawu danych treningowych jako zestawu weryfikacji. Z kolei ten zestaw weryfikacji jest używany do obliczania metryk. Mniejsze niż 20 000 wierszy Zastosowano podejście do krzyżowego sprawdzania poprawności. Domyślna liczba składań zależy od liczby wierszy.
- Zestaw danych z mniej niż 1000 wierszami: używane jest 10 razy
- Zestaw danych z 1000 do 20 000 wierszy: używane są trzy fałdyPodaj dane testowe (wersja zapoznawcza), aby ocenić zalecany model generowany przez zautomatyzowane uczenie maszynowe na końcu eksperymentu. Po podaniu zestawu danych testowych zadanie testowe zostanie automatycznie wyzwolone na końcu eksperymentu. To zadanie testowe jest jedynym zadaniem najlepszego modelu zalecanego przez zautomatyzowane uczenie maszynowe. Aby uzyskać więcej informacji, zobacz Wyświetlanie wyników zadania testu zdalnego (wersja zapoznawcza).
Ważne
Udostępnianie testowego zestawu danych do oceny wygenerowanych modeli jest funkcją w wersji zapoznawczej. Ta funkcja jest funkcją eksperymentalnej wersji zapoznawczej i może ulec zmianie w dowolnym momencie.
Dane testowe są uznawane za oddzielone od trenowania i walidacji i nie powinny odchylić wyników zadania testowego zalecanego modelu. Aby uzyskać więcej informacji, zobacz Szkolenie, walidacja i dane testowe.
Możesz podać własny zestaw danych testowych lub zdecydować się na użycie procentu zestawu danych treningowych. Dane testowe muszą być w postaci zestawu danych tabeli usługi Azure Machine Learning.
Schemat zestawu danych testowego powinien być zgodny z zestawem danych trenowania. Kolumna docelowa jest opcjonalna, ale jeśli żadna kolumna docelowa nie jest wskazana, nie są obliczane żadne metryki testowe.
Zestaw danych testowych nie powinien być taki sam jak zestaw danych trenowania ani zestaw danych weryfikacji.
Zadania prognozowania nie obsługują podziału trenowania /testowania.
Konfigurowanie obliczeń
Wykonaj następujące kroki i skonfiguruj obliczenia:
Wybierz przycisk Dalej , aby przejść do karty Obliczenia .
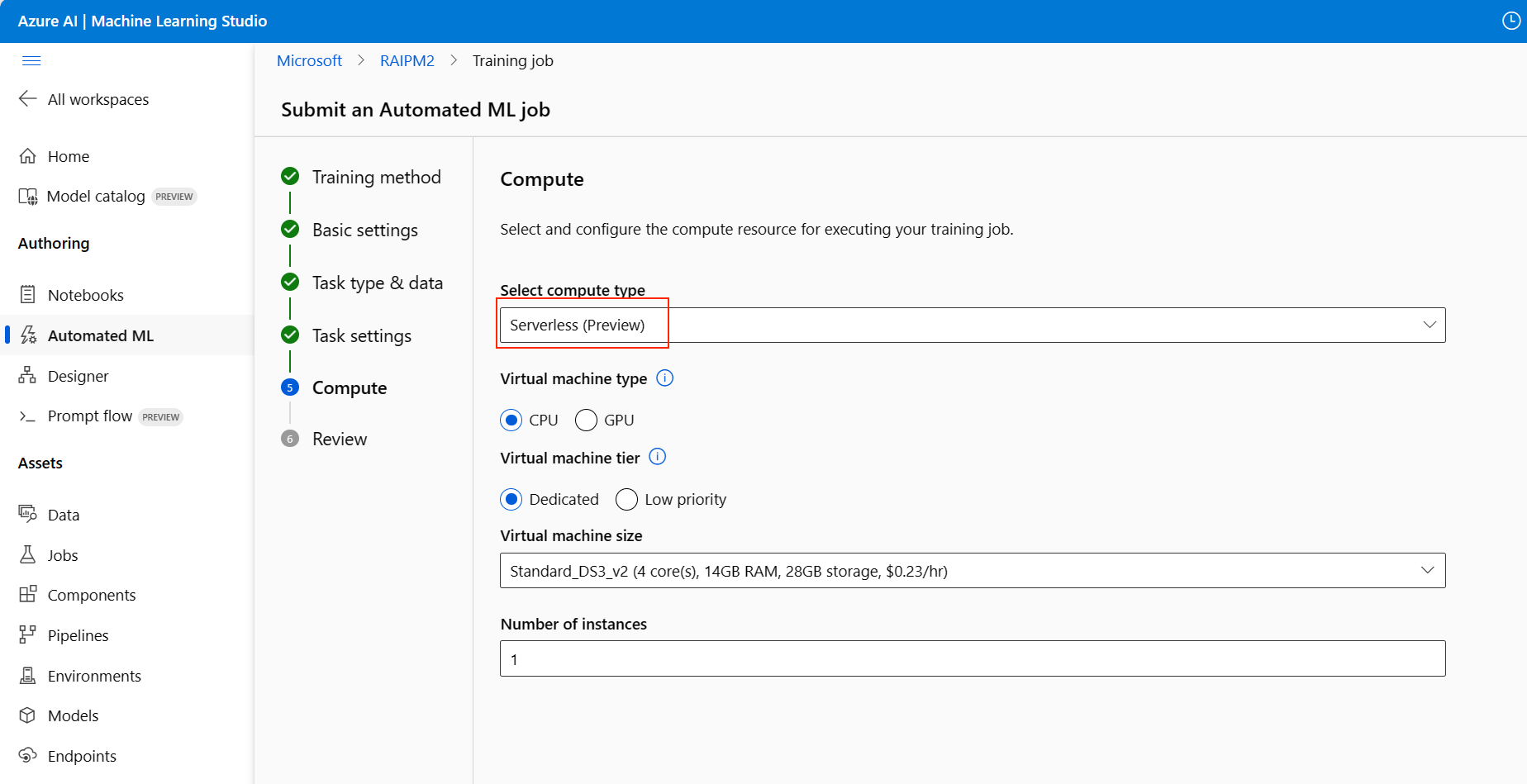
Użyj listy rozwijanej Wybierz typ obliczeniowy, aby wybrać opcję profilowania danych i zadania trenowania. Opcje obejmują klaster obliczeniowy, wystąpienie obliczeniowe lub bezserwerowe.
Po wybraniu typu obliczeniowego inny interfejs użytkownika na stronie zmienia się w zależności od wybranego wyboru:
Bezserwerowe: ustawienia konfiguracji są wyświetlane na bieżącej stronie. Przejdź do następnego kroku, aby uzyskać opisy ustawień do skonfigurowania.
Klaster obliczeniowy lub wystąpienie obliczeniowe: wybierz spośród następujących opcji:
Użyj listy rozwijanej Wybierz zautomatyzowane środowisko obliczeniowe uczenia maszynowego, aby wybrać istniejące zasoby obliczeniowe dla obszaru roboczego, a następnie wybierz pozycję Dalej. Przejdź do sekcji Uruchamianie eksperymentu i wyświetl wyniki .
Wybierz pozycję Nowy , aby utworzyć nowe wystąpienie obliczeniowe lub klaster. Ta opcja powoduje otwarcie strony Tworzenie zasobów obliczeniowych . Przejdź do następnego kroku, aby uzyskać opisy ustawień do skonfigurowania.
W przypadku obliczeń bezserwerowych lub nowych zasobów obliczeniowych skonfiguruj wszystkie wymagane* () ustawienia:
Ustawienia konfiguracji różnią się w zależności od typu obliczeniowego. Poniższa tabela zawiera podsumowanie różnych ustawień, które mogą być konieczne do skonfigurowania:
Pole opis Nazwa obliczeniowa Wprowadź unikatową nazwę identyfikującą kontekst obliczeniowy. Lokalizacja Określ region maszyny. Priorytet maszyny wirtualnej Maszyny wirtualne o niskim priorytcie są tańsze, ale nie gwarantują węzłów obliczeniowych. Typ maszyny wirtualnej Wybierz procesor CPU lub procesor GPU dla typu maszyny wirtualnej. Warstwa maszyny wirtualnej Wybierz priorytet eksperymentu. Rozmiar maszyny wirtualnej Wybierz rozmiar maszyny wirtualnej dla obliczeń. Minimalna/maksymalna liczba węzłów Aby profilować dane, należy określić co najmniej jeden węzeł. Wprowadź maksymalną liczbę węzłów dla obliczeń. Wartość domyślna to sześć węzłów dla usługi Azure Machine Learning Compute. Bezczynność sekund przed skalowaniem w dół Określ czas bezczynności przed automatycznym skalowaniem klastra w dół do minimalnej liczby węzłów. Ustawienia zaawansowane Te ustawienia umożliwiają skonfigurowanie konta użytkownika i istniejącej sieci wirtualnej na potrzeby eksperymentu. Po skonfigurowaniu wymaganych ustawień wybierz odpowiednio pozycję Dalej lub Utwórz.
Tworzenie nowego środowiska obliczeniowego może potrwać kilka minut. Po zakończeniu tworzenia wybierz przycisk Dalej.
Uruchamianie eksperymentu i wyświetlanie wyników
Wybierz pozycję Zakończ , aby uruchomić eksperyment. Proces przygotowywania eksperymentu może potrwać do 10 minut. Zadania trenowania mogą zająć kolejne 2–3 minuty dla każdego potoku. Jeśli określono generowanie pulpitu nawigacyjnego RAI dla najlepszego zalecanego modelu, może upłynąć do 40 minut.
Uwaga
Algorytmy zautomatyzowanego uczenia maszynowego mają nieodłączną losowość, która może spowodować niewielkie różnice w końcowym wyniku metryk zalecanego modelu, na przykład dokładność. Zautomatyzowane uczenie maszynowe wykonuje również operacje na danych, takich jak podział trenowania, podział weryfikacji pociągu lub krzyżowa walidacja, w razie potrzeby. Jeśli wielokrotnie uruchamiasz eksperyment z tymi samymi ustawieniami konfiguracji i metrykami podstawowymi, prawdopodobnie zobaczysz różnice w końcowym wyniku metryk każdego eksperymentu z powodu tych czynników.
Wyświetlanie szczegółów eksperymentu
Zostanie otwarty ekran Szczegóły zadania na karcie Szczegóły . Na tym ekranie przedstawiono podsumowanie zadania eksperymentu, w tym pasek stanu u góry obok numeru zadania.
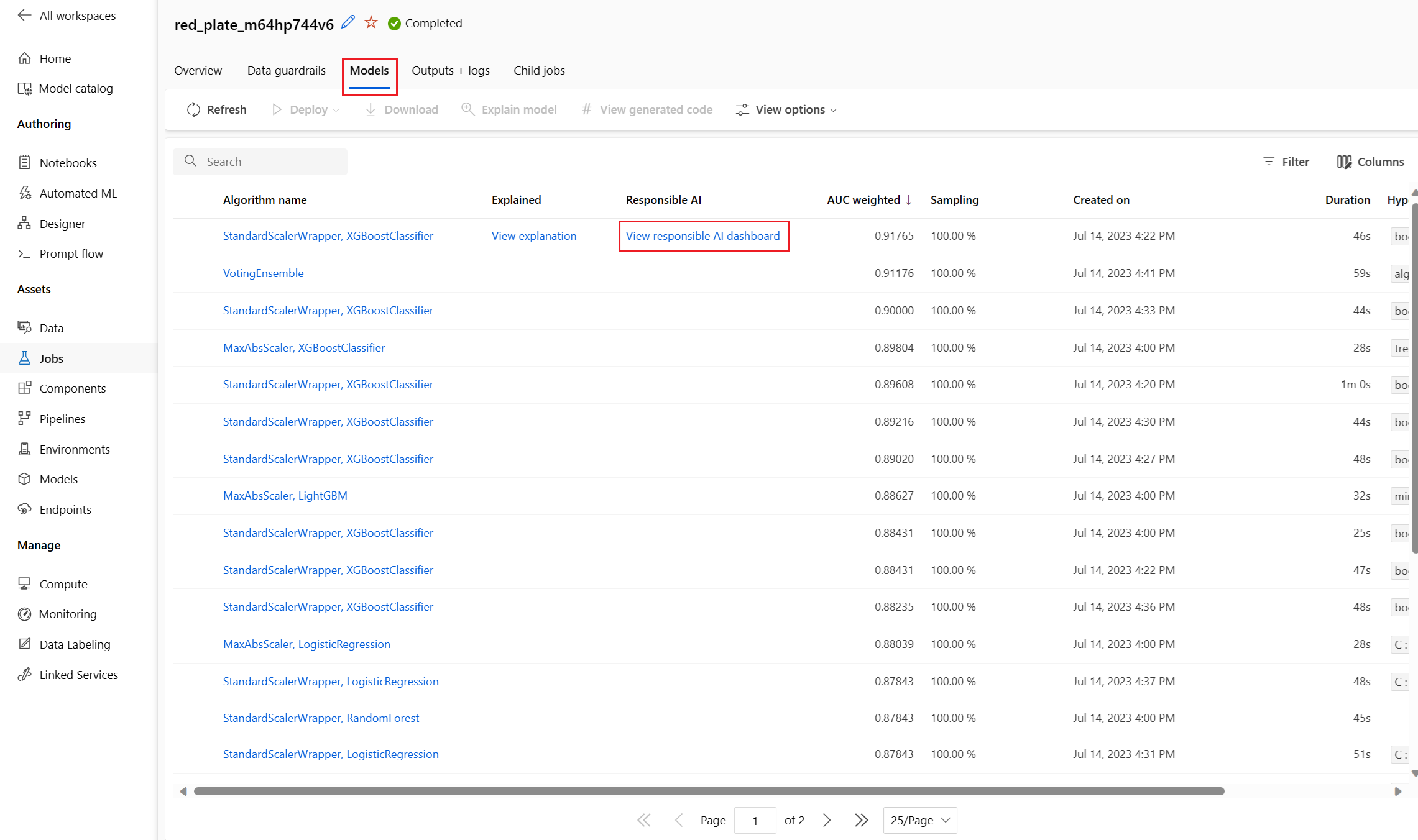
Karta Modele zawiera listę utworzonych modeli uporządkowaną według wyników metryk. Domyślnie model, który dla wybranej metryki uzyska najlepszy wynik, znajduje się na początku listy. Gdy zadanie trenowania próbuje więcej modeli, do listy są dodawane ćwiczenie modeli. Użyj tego podejścia, aby szybko porównać metryki dla modeli utworzonych do tej pory.
Wyświetlanie szczegółów zadania trenowania
Przejdź do szczegółów dowolnego z ukończonych modeli, aby uzyskać szczegółowe informacje o zadaniu trenowania. Wykresy metryk wydajności dla określonych modeli można wyświetlić na karcie Metryki . Aby uzyskać więcej informacji, zobacz Ocena wyników eksperymentu zautomatyzowanego uczenia maszynowego. Na tej stronie można również znaleźć szczegółowe informacje o wszystkich właściwościach modelu wraz ze skojarzonym kodem, zadaniami podrzędnymi i obrazami.
Wyświetlanie wyników zadania testu zdalnego (wersja zapoznawcza)
W przypadku określenia zestawu danych testowych lub wybrania podziału trenowania/testu podczas konfigurowania eksperymentu w formularzu Weryfikowanie i testowanie automatyczne uczenie maszynowe domyślnie testuje zalecany model. W rezultacie zautomatyzowane uczenie maszynowe oblicza metryki testów w celu określenia jakości zalecanego modelu i jego przewidywań.
Ważne
Testowanie modeli przy użyciu zestawu danych testowych w celu oceny wygenerowanych modeli jest funkcją w wersji zapoznawczej. Ta funkcja jest funkcją eksperymentalnej wersji zapoznawczej i może ulec zmianie w dowolnym momencie.
Ta funkcja nie jest dostępna w następujących scenariuszach zautomatyzowanego uczenia maszynowego:
- Zadania przetwarzania obrazów
- Wiele modeli i hiearchical trenowanie prognozowania szeregów czasowych (wersja zapoznawcza)
- Prognozowanie zadań, w których włączono sieci neuronowe uczenia głębokiego (DNN)
- Zautomatyzowane zadania uczenia maszynowego z lokalnych obliczeń lub klastrów usługi Azure Databricks
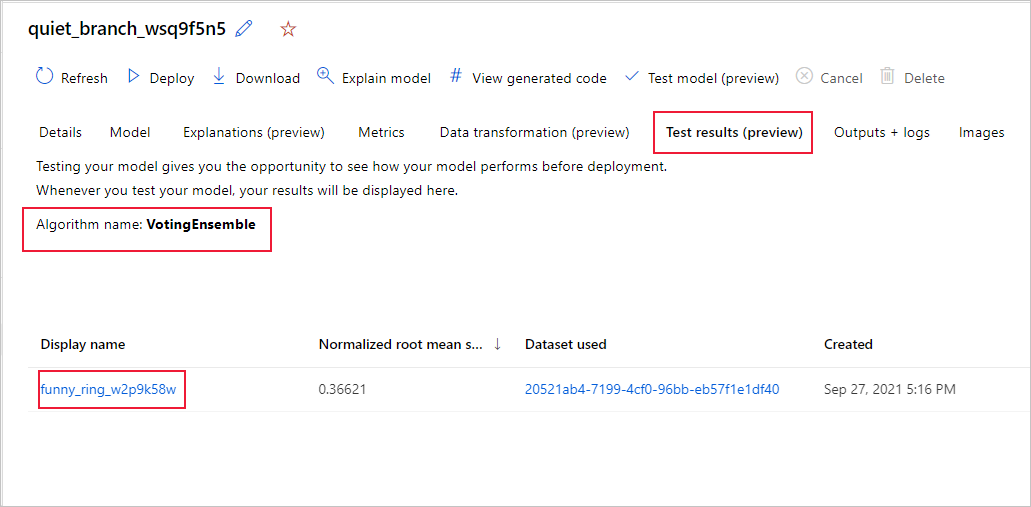
Wykonaj następujące kroki, aby wyświetlić metryki zadań testowych zalecanego modelu:
W studio przejdź do strony Modele i wybierz najlepszy model.
Wybierz kartę Wyniki testu (wersja zapoznawcza).
Wybierz żądane zadanie i wyświetl kartę Metryki :
Wyświetl przewidywania testów używane do obliczania metryk testów, wykonując następujące kroki:
W dolnej części strony wybierz link w obszarze Dane wyjściowe zestawu danych , aby otworzyć zestaw danych.
Na stronie Zestawy danych wybierz kartę Eksploruj, aby wyświetlić przewidywania z zadania testowego.
Plik przewidywania można również wyświetlić i pobrać z karty Dane wyjściowe i dzienniki . Rozwiń folder Predictions (Przewidywania), aby zlokalizować plik prediction.csv .
Zadanie testowania modelu generuje plik predictions.csv przechowywany w domyślnym magazynie danych utworzonym za pomocą obszaru roboczego. Ten magazyn danych jest widoczny dla wszystkich użytkowników z tą samą subskrypcją. Zadania testowe nie są zalecane w scenariuszach, jeśli którekolwiek z informacji używanych w ramach zadania testowego lub utworzone przez zadanie testowe musi pozostać prywatne.
Testowanie istniejącego modelu zautomatyzowanego uczenia maszynowego (wersja zapoznawcza)
Po zakończeniu eksperymentu możesz przetestować modele generowane przez zautomatyzowane uczenie maszynowe.
Ważne
Testowanie modeli przy użyciu zestawu danych testowych w celu oceny wygenerowanych modeli jest funkcją w wersji zapoznawczej. Ta funkcja jest eksperymentalną funkcją w wersji zapoznawczej i może ulec zmianie w dowolnym momencie.
Ta funkcja nie jest dostępna w następujących scenariuszach zautomatyzowanego uczenia maszynowego:
- Zadania przetwarzania obrazów
- Wiele modeli i hiearchical trenowanie prognozowania szeregów czasowych (wersja zapoznawcza)
- Prognozowanie zadań, w których włączono sieci neuronowe uczenia głębokiego (DNN)
- Zautomatyzowane zadania uczenia maszynowego z lokalnych obliczeń lub klastrów usługi Azure Databricks
Jeśli chcesz przetestować inny model wygenerowany przez zautomatyzowane uczenie maszynowe, a nie zalecany model, wykonaj następujące kroki:
Wybierz istniejące zadanie eksperymentu zautomatyzowanego uczenia maszynowego.
Przejdź do karty Modele zadania i wybierz ukończony model, który chcesz przetestować.
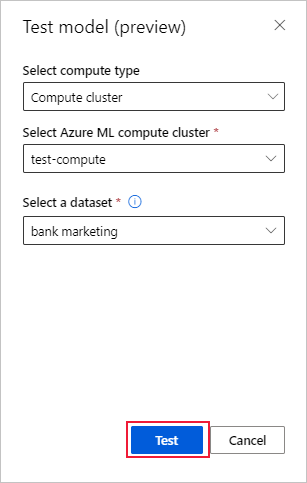
Na stronie Szczegóły modelu wybierz opcję Model testowy (wersja zapoznawcza), aby otworzyć okienko Model testowy.
W okienku Model testowy wybierz klaster obliczeniowy i testowy zestaw danych, którego chcesz użyć dla zadania testowego.
Wybierz opcję Testuj. Schemat zestawu danych testowego powinien być zgodny z zestawem danych trenowania, ale kolumna Target jest opcjonalna.
Po pomyślnym utworzeniu zadania testu modelu na stronie Szczegóły zostanie wyświetlony komunikat o powodzeniu. Wybierz kartę Wyniki testu, aby wyświetlić postęp zadania.
Aby wyświetlić wyniki zadania testowego, otwórz stronę Szczegóły i wykonaj kroki opisane w sekcji Wyświetlanie wyników zadania testu zdalnego (wersja zapoznawcza).
Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji (wersja zapoznawcza)
Aby lepiej zrozumieć model, możesz zobaczyć różne szczegółowe informacje o modelu przy użyciu pulpitu nawigacyjnego Odpowiedzialne używanie sztucznej inteligencji. Ten interfejs użytkownika umożliwia ocenę i debugowanie najlepszego modelu zautomatyzowanego uczenia maszynowego. Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji ocenia błędy modelu i problemy z sprawiedliwością, diagnozuje, dlaczego występują błędy, oceniając dane trenowania i/lub testu oraz obserwując wyjaśnienia modelu. Te szczegółowe informacje mogą pomóc w budowaniu zaufania z modelem i przekazaniu procesów inspekcji. Nie można wygenerować odpowiedzialnych pulpitów nawigacyjnych sztucznej inteligencji dla istniejącego modelu zautomatyzowanego uczenia maszynowego. Pulpit nawigacyjny jest tworzony tylko dla najlepszego zalecanego modelu podczas tworzenia nowego zadania zautomatyzowanego uczenia maszynowego. Użytkownicy powinni nadal używać wyjaśnień modelu (wersja zapoznawcza), dopóki nie zostanie udostępniona obsługa istniejących modeli.
Wygeneruj pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji dla określonego modelu, wykonując następujące kroki:
Podczas przesyłania zadania zautomatyzowanego uczenia maszynowego przejdź do sekcji Ustawienia zadania w menu po lewej stronie i wybierz opcję Wyświetl dodatkowe ustawienia konfiguracji.
Na stronie Dodatkowa konfiguracja wybierz opcję Wyjaśnij najlepszy model :
Przejdź do karty Obliczenia i wybierz opcję Bezserwerowa dla obliczeń:
Po zakończeniu operacji przejdź do strony Modele zadania zautomatyzowanego uczenia maszynowego, która zawiera listę wytrenowanych modeli. Wybierz link Wyświetl pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji:
Pulpit nawigacyjny Odpowiedzialne używanie sztucznej inteligencji zostanie wyświetlony dla wybranego modelu:
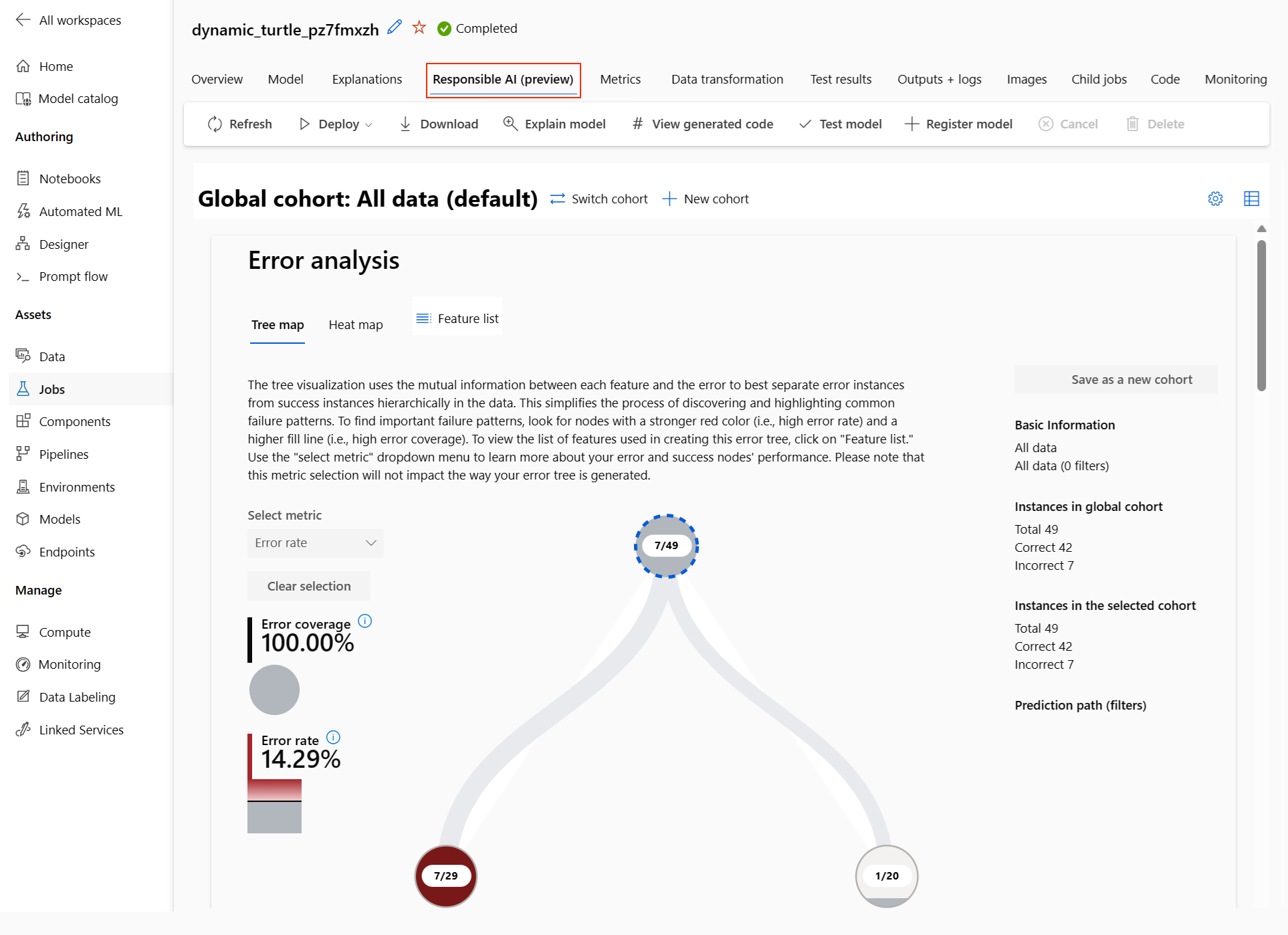
Na pulpicie nawigacyjnym zobaczysz cztery składniki aktywowane dla najlepszego modelu zautomatyzowanego uczenia maszynowego:
Składnik Co pokazuje składnik? Jak odczytać wykres? Analiza błędów Użyj analizy błędów, jeśli musisz:
— Poznaj sposób dystrybucji błędów modelu w zestawie danych oraz w kilku wymiarach danych wejściowych i funkcji.
— Podział zagregowanych metryk wydajności w celu automatycznego odnalezienia błędnej kohorty w celu poinformowania o ukierunkowanych krokach ograniczania ryzyka.Wykresy analizy błędów Omówienie modelu i sprawiedliwość Użyj tego składnika, aby:
— Uzyskaj głębokie zrozumienie wydajności modelu w różnych kohortach danych.
— Zapoznaj się z problemami dotyczącymi sprawiedliwości modelu, przeglądając metryki różnic. Te metryki mogą oceniać i porównywać zachowanie modelu w podgrupach określonych pod kątem funkcji poufnych (lub niewrażliwych).Omówienie modelu i wykresy sprawiedliwości Wyjaśnienia modelu Użyj składnika wyjaśnienia modelu, aby wygenerować zrozumiałe dla człowieka opisy przewidywań modelu uczenia maszynowego, patrząc na:
- Wyjaśnienia globalne: Na przykład jakie funkcje wpływają na ogólne zachowanie modelu alokacji pożyczki?
- Wyjaśnienia lokalne: na przykład dlaczego wniosek o pożyczkę klienta został zatwierdzony lub odrzucony?Wykresy objaśnienia modelu Analiza danych Użyj analizy danych, gdy musisz:
— Eksploruj statystyki zestawu danych, wybierając różne filtry, aby podzielić dane na różne wymiary (nazywane również kohortami).
— Omówienie dystrybucji zestawu danych w różnych kohortach i grupach funkcji.
— Określ, czy wyniki związane z uczciwością, analizą błędów i przyczynowością (pochodzące z innych składników pulpitu nawigacyjnego) są wynikiem dystrybucji zestawu danych.
- Zdecyduj, w których obszarach, aby zebrać więcej danych, aby ograniczyć błędy wynikające z problemów z reprezentacją, szum etykiet, szum funkcji, stronniczość etykiet i podobne czynniki.Wykresy eksploratora danych Możesz dalej tworzyć kohorty (podgrupy punktów danych, które mają określone cechy), aby skoncentrować analizę poszczególnych składników na różnych kohortach. Nazwa kohorty aktualnie stosowanej do pulpitu nawigacyjnego jest zawsze wyświetlana w lewym górnym rogu pulpitu nawigacyjnego. Widok domyślny na pulpicie nawigacyjnym to cały zestaw danych o nazwie Wszystkie dane domyślnie. Aby uzyskać więcej informacji, zobacz Kontrolki globalne dla pulpitu nawigacyjnego.


Edytowanie i przesyłanie zadań (wersja zapoznawcza)
W scenariuszach, w których chcesz utworzyć nowy eksperyment na podstawie ustawień istniejącego eksperymentu, zautomatyzowane uczenie maszynowe udostępnia opcję Edytuj i prześlij w interfejsie użytkownika programu Studio. Ta funkcja jest ograniczona do eksperymentów zainicjowanych z interfejsu użytkownika studio i wymaga schematu danych dla nowego eksperymentu, aby był zgodny z oryginalnym eksperymentem.
Ważne
Możliwość kopiowania, edytowania i przesyłania nowego eksperymentu na podstawie istniejącego eksperymentu jest funkcją w wersji zapoznawczej. Ta funkcja jest funkcją eksperymentalnej wersji zapoznawczej i może ulec zmianie w dowolnym momencie.
Opcja Edytuj i prześlij otwiera kreatora Tworzenie nowego zadania zautomatyzowanego uczenia maszynowego ze wstępnie wypełnionymi ustawieniami danych, obliczeń i eksperymentów. Możesz skonfigurować opcje na każdej karcie kreatora i edytować wybrane opcje zgodnie z potrzebami dla nowego eksperymentu.
Wdrażanie modelu
Po utworzeniu najlepszego modelu możesz wdrożyć model jako usługę internetową, aby przewidywać nowe dane.
Uwaga
Aby wdrożyć model wygenerowany za pomocą pakietu przy użyciu automl zestawu SDK języka Python, musisz zarejestrować model) w obszarze roboczym.
Po zarejestrowaniu modelu możesz zlokalizować model w studio, wybierając pozycję Modele w menu po lewej stronie. Na stronie przeglądu modelu możesz wybrać opcję Wdróż i przejść do kroku 2 w tej sekcji.
Zautomatyzowane uczenie maszynowe ułatwia wdrażanie modelu bez pisania kodu.
Zainicjuj wdrożenie przy użyciu jednej z następujących metod:
Wdróż najlepszy model przy użyciu zdefiniowanych kryteriów metryk:
Po zakończeniu eksperymentu wybierz pozycję Zadanie 1 i przejdź do strony nadrzędnego zadania.
Wybierz model wymieniony w sekcji Podsumowanie najlepszego modelu, a następnie wybierz pozycję Wdróż.
Wdróż określoną iterację modelu z tego eksperymentu:
- Wybierz żądany model na karcie Modele , a następnie wybierz pozycję Wdróż.
Wypełnij okienko Wdrażanie modelu:
Pole Wartość Nazwa/nazwisko Wprowadź unikatową nazwę wdrożenia. Opis Wprowadź opis, aby lepiej zidentyfikować cel wdrożenia. Typ obliczeniowy Wybierz typ punktu końcowego, który chcesz wdrożyć: Azure Kubernetes Service (AKS) lub Azure Container Instance (ACI). Nazwa obliczeniowa (Dotyczy tylko usługi AKS) Wybierz nazwę klastra usługi AKS, do którego chcesz wdrożyć. Włączanie uwierzytelniania Wybierz, aby zezwolić na uwierzytelnianie oparte na tokenach lub oparte na kluczach. Korzystanie z niestandardowych zasobów wdrażania Włącz zasoby niestandardowe, jeśli chcesz przekazać własny skrypt oceniania i plik środowiska. W przeciwnym razie zautomatyzowane uczenie maszynowe domyślnie udostępnia te zasoby. Aby uzyskać więcej informacji, zobacz Wdrażanie i ocenianie modelu uczenia maszynowego przy użyciu punktu końcowego online. Ważne
Nazwy plików muszą mieć od 1 do 32 znaków. Nazwa musi zaczynać się od alfanumeryki i może zawierać kreski, podkreślenia, kropki i alfanumeryczne między nimi. Spacje nie są dozwolone.
Menu Zaawansowane oferuje domyślne funkcje wdrażania, takie jak zbieranie danych i ustawienia wykorzystania zasobów. Aby zastąpić te wartości domyślne, możesz użyć opcji w tym menu. Aby uzyskać więcej informacji, zobacz Monitorowanie punktów końcowych online.
Wybierz Wdróż. Wdrażanie może potrwać około 20 minut.
Po rozpoczęciu wdrażania zostanie otwarta karta Podsumowanie modelu. Postęp wdrażania można monitorować w sekcji Stan wdrażania .
Masz teraz działającą usługę internetową umożliwiającą generowanie przewidywań. Przewidywania można przetestować, wysyłając zapytanie do usługi z przykładów kompleksowej sztucznej inteligencji w usłudze Microsoft Fabric.
Powiązana zawartość
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla