Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
Z tego artykułu dowiesz się, jak tworzyć i uruchamiać potoki uczenia maszynowego przy użyciu interfejsu wiersza polecenia platformy Azure i składników. Można tworzyć kanały bez używania składników, ale dzięki nim można uzyskać elastyczność i możliwość ponownego użycia. Potoki usługi Azure Machine Learning można definiować w języku YAML i uruchamiać z interfejsu wiersza polecenia (CLI), napisanego w Pythonie lub tworzonego w projektancie usługi Azure Machine Learning Studio za pomocą interfejsu przeciągnij i upuść. Ten artykuł koncentruje się na interfejsie wiersza polecenia.
Wymagania wstępne
Subskrypcja platformy Azure. Jeśli go nie masz, przed rozpoczęciem utwórz bezpłatne konto. Wypróbuj bezpłatną lub płatną wersję usługi Azure Machine Learning.
Obszar roboczy usługi Azure Machine Learning.
Rozszerzenie interfejsu wiersza polecenia platformy Azure dla Uczenia Maszynowego, zainstalowane i skonfigurowane.
Klon repozytorium przykładów. Możesz użyć tych poleceń, aby sklonować repo:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/basics
Sugerowane wstępne odczytywanie
Utwórz swój pierwszy rurociąg przy użyciu komponentów
Najpierw utworzysz przepływ ze składnikami na przykładzie. Daje to początkowe wrażenie tego, jak wygląda pipeline i składnik w usłudze Azure Machine Learning.
W katalogu cli/jobs/pipelines-with-components/basics repozytorium azureml-examples przejdź do podkatalogu 3b_pipeline_with_data. W tym katalogu znajdują się trzy typy plików. Są to pliki, które należy utworzyć przy budowie własnego potoku.
pipeline.yml. Ten plik YAML definiuje potok uczenia maszynowego. W tym artykule opisano sposób dzielenia pełnego zadania uczenia maszynowego na wieloetapowy przepływ pracy. Rozważmy na przykład proste zadanie uczenia maszynowego przy użyciu danych historycznych w celu wytrenowania modelu prognozowania sprzedaży. Możesz utworzyć sekwencyjny przepływ pracy zawierający kroki przetwarzania danych, trenowania modelu i oceny modelu. Każdy krok jest składnikiem, który ma dobrze zdefiniowany interfejs i można go opracowywać, testować i optymalizować niezależnie. Potok YAML definiuje również sposób, w jaki kroki podrzędne łączą się z innymi krokami w potoku. Na przykład krok trenowania modelu generuje plik modelu, a plik modelu jest przekazywany do kroku oceny modelu.
component.yml. Te pliki YAML definiują składniki. Zawierają one następujące informacje:
- Metadane: nazwa, nazwa wyświetlana, wersja, opis, typ itd. Metadane ułatwiają opisywanie składnika i zarządzanie nim.
- Interfejs: dane wejściowe i wyjściowe. Na przykład składnik trenowania modelu pobiera dane treningowe i liczbę epok jako dane wejściowe i generuje wytrenowany plik modelu jako dane wyjściowe. Po zdefiniowaniu interfejsu różne zespoły mogą opracowywać i testować składnik niezależnie.
- Polecenie, kod i środowisko: polecenie, kod i środowisko do uruchomienia składnika. Polecenie jest poleceniem powłoki do uruchomienia składnika. Kod zwykle odwołuje się do katalogu kodu źródłowego. Środowisko może być środowiskiem usługi Azure Machine Learning (wyselekcjonowane lub utworzone przez klienta), obrazem platformy Docker lub środowiskiem conda.
component_src. Są to katalogi kodu źródłowego dla określonych składników. Zawierają kod źródłowy, który jest uruchamiany w składniku. Możesz użyć preferowanego języka, w tym języka Python, R i innych. Kod musi być uruchamiany za pomocą polecenia powłoki. Kod źródłowy może przyjąć kilka danych wejściowych z wiersza polecenia powłoki, aby kontrolować sposób, w jaki uruchamiany jest ten krok. Na przykład, krok trenowania może użyć danych szkoleniowych, szybkości nauki i liczby epok w celu kontrolowania procesu trenowania. Argument polecenia powłoki służy do przekazywania danych wejściowych i wyjściowych do kodu.
Teraz utworzysz pipeline przy użyciu przykładu 3b_pipeline_with_data. Każdy plik jest bardziej szczegółowo opisany w poniższych sekcjach.
Najpierw wyświetl listę dostępnych zasobów obliczeniowych przy użyciu następującego polecenia:
az ml compute list
Jeśli go nie masz, utwórz klaster o nazwie cpu-cluster , uruchamiając następujące polecenie:
Uwaga
Pomiń ten krok, aby użyć bezserwerowych obliczeń.
az ml compute create -n cpu-cluster --type amlcompute --min-instances 0 --max-instances 10
Teraz utwórz zadanie potoku zdefiniowane w pliku pipeline.yml, uruchamiając następujące polecenie. Docelowy obiekt obliczeniowy jest przywołyny w pliku pipeline.yml jako azureml:cpu-cluster. Jeśli docelowy obiekt obliczeniowy używa innej nazwy, pamiętaj, aby zaktualizować go w pliku pipeline.yml.
az ml job create --file pipeline.yml
Powinieneś otrzymać słownik JSON zawierający informacje o zadaniu potoku, w tym:
| Klawisz | opis |
|---|---|
name |
Nazwa zadania oparta na identyfikatorze GUID. |
experiment_name |
Nazwa, w ramach której zadania będą zorganizowane w studio. |
services.Studio.endpoint |
Adres URL monitorowania i przeglądania zadania potoku. |
status |
Stan zadania. To prawdopodobnie będzie Preparing w tym momencie. |
Przejdź do adresu URL, services.Studio.endpoint aby wyświetlić wizualizację potoku:
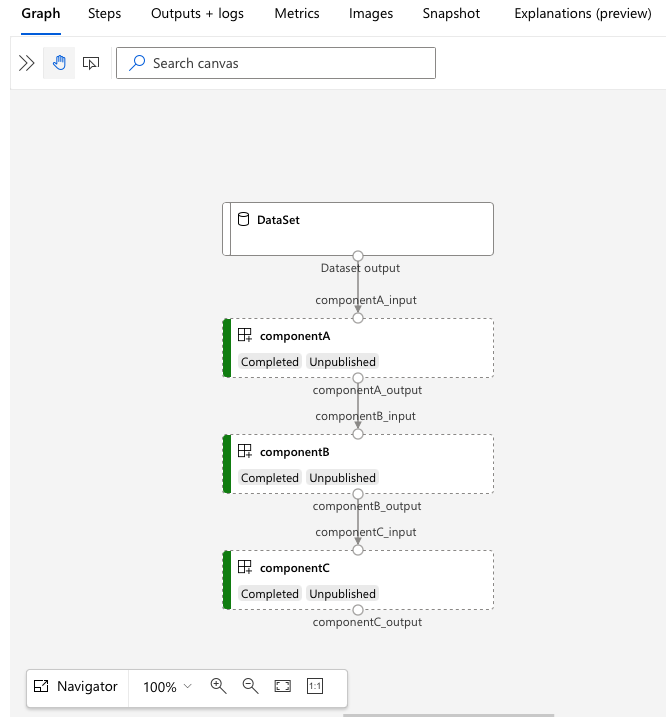
Omówienie definicji potoku YAML
Teraz przyjrzysz się definicji pipeline w pliku 3b_pipeline_with_data/pipeline.yml .
Uwaga
Aby użyć bezserwerowych obliczeń, zastąp ciąg default_compute: azureml:cpu-cluster ciągiem default_compute: azureml:serverless w tym pliku.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 3b_pipeline_with_data
description: Pipeline with 3 component jobs with data dependencies
settings:
default_compute: azureml:cpu-cluster
outputs:
final_pipeline_output:
mode: rw_mount
jobs:
component_a:
type: command
component: ./componentA.yml
inputs:
component_a_input:
type: uri_folder
path: ./data
outputs:
component_a_output:
mode: rw_mount
component_b:
type: command
component: ./componentB.yml
inputs:
component_b_input: ${{parent.jobs.component_a.outputs.component_a_output}}
outputs:
component_b_output:
mode: rw_mount
component_c:
type: command
component: ./componentC.yml
inputs:
component_c_input: ${{parent.jobs.component_b.outputs.component_b_output}}
outputs:
component_c_output: ${{parent.outputs.final_pipeline_output}}
# mode: upload
W poniższej tabeli opisano najczęściej używane pola schematu YAML potoku. Aby dowiedzieć się więcej, zobacz pełny schemat YAML potoku.
| Klawisz | opis |
|---|---|
type |
Wymagany. Typ zadania. Musi być pipeline dla zadań w potoku. |
display_name |
Nazwa wyświetlana zadania potoku w interfejsie użytkownika programu Studio. Możliwość edycji w interfejsie użytkownika programu Studio. Nie musi być wyjątkowa we wszystkich pracach w obszarze roboczym. |
jobs |
Wymagany. Słownik zestawu poszczególnych zadań do uruchomienia jako etapy w potoku przetwarzania. Te zadania są uznawane za podrzędne zadania nadrzędnego potoku. W bieżącej wersji obsługiwane typy zadań w potoku to command i sweep. |
inputs |
Zbiór danych wejściowych do zadania w potoku. Klucz jest nazwą danych wejściowych w kontekście zadania, a wartość jest wartością wejściową. Dane wejściowe potoku można odnosić do danych wejściowych poszczególnego zadania w ramach tego potoku, używając wyrażenia ${{ parent.inputs.<input_name> }}. |
outputs |
Słownik konfiguracji wyników operacji przetwarzania danych. Klucz jest nazwą danych wyjściowych w kontekście zadania, a wartość jest konfiguracją danych wyjściowych. Możesz odwoływać się do tych danych wyjściowych potoku poprzez dane wyjściowe pojedynczego zadania kroku w potoku, używając wyrażenia ${{ parents.outputs.<output_name> }}. |
Przykład 3b_pipeline_with_data zawiera trzyetapowy potok danych.
- Trzy kroki są definiowane w obszarze
jobs. Wszystkie trzy kroki mają typcommand. Definicja każdego kroku znajduje się w odpowiednimcomponent*.ymlpliku. Pliki YAML składnika można znaleźć w katalogu 3b_pipeline_with_data.componentA.ymljest opisany w następnej sekcji. - Ten pipeline ma zależność danych, która jest powszechna w rzeczywistych pipeline'ach. Składnik A pobiera dane wejściowe z folderu lokalnego w obszarze
./data(wiersze 18–21) i przekazuje dane wyjściowe do składnika B (wiersz 29). Dane wyjściowe składnika A mogą być przywołyne jako${{parent.jobs.component_a.outputs.component_a_output}}. -
default_computedefiniuje domyślne obliczenia dla potoku. Jeśli składnikjobsdefiniuje inne obliczenia, ustawienia specyficzne dla składnika są przestrzegane.

Odczytywanie i zapisywanie danych w strumieniu
Jednym z typowych scenariuszy jest odczytywanie i zapisywanie danych w potoku. W usłudze Azure Machine Learning używasz tego samego schematu do odczytywania i zapisywania danych dla wszystkich typów zadań (zadań potoku, zadań poleceń i zadań zamiatania). Poniżej przedstawiono przykłady zastosowania danych w potokach dla typowych scenariuszy.
- Dane lokalne
- Plik internetowy z publicznym adresem URL
- Magazyn danych i ścieżka usługi Azure Machine Learning
- Zasób danych usługi Azure Machine Learning
Omówienie definicji składnika YAML
Oto plik componentA.yml , przykład yaML definiujący składnik:
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
type: command
name: component_a
display_name: componentA
version: 1
inputs:
component_a_input:
type: uri_folder
outputs:
component_a_output:
type: uri_folder
code: ./componentA_src
environment:
image: python
command: >-
python hello.py --componentA_input ${{inputs.component_a_input}} --componentA_output ${{outputs.component_a_output}}
Ta tabela definiuje najczęściej używane pola składnika YAML. Aby dowiedzieć się więcej, zobacz pełny schemat YAML składnika.
| Klawisz | opis |
|---|---|
name |
Wymagany. Nazwa składnika. Musi być unikatowa w obszarze roboczym usługi Azure Machine Learning. Musi zaczynać się od małej litery. Małe litery, cyfry i podkreślenia (_) są dozwolone. Maksymalna długość to 255 znaków. |
display_name |
Nazwa wyświetlana składnika w interfejsie użytkownika programu Studio. Nie musi być unikatowa w obszarze roboczym. |
command |
Wymagany. Polecenie do uruchomienia. |
code |
Ścieżka lokalna do katalogu kodu źródłowego, który ma zostać przekazany i użyty dla składnika. |
environment |
Wymagany. Środowisko używane do uruchamiania składnika. |
inputs |
Słownik danych wejściowych składników. Klucz jest nazwą danych wejściowych w kontekście składnika, a wartość jest definicją danych wejściowych składnika. W poleceniu można odwoływać się do danych wejściowych, używając wyrażenia ${{ inputs.<input_name> }}. |
outputs |
Słownik danych wyjściowych składników. Klucz jest nazwą danych wyjściowych w kontekście składnika, a wartość jest definicją danych wyjściowych składnika. Możesz odwoływać się do danych wyjściowych w poleceniu ${{ outputs.<output_name> }} przy użyciu wyrażenia . |
is_deterministic |
Czy ponownie użyć wyniku poprzedniego zadania, jeśli dane wejściowe składnika nie ulegają zmianie. Wartość domyślna to true. To ustawienie jest również znane jako reuse by default. Typowym scenariuszem, w którym ustawiono wartość , false jest wymuszenie ponownego załadowania danych z magazynu w chmurze lub adresu URL. |
W przykładzie w 3b_pipeline_with_data/componentA.yml składnik A zawiera jedno dane wejściowe i jedno dane wyjściowe, które można połączyć z innymi krokami w potoku nadrzędnym. Wszystkie pliki w sekcji w code składniku YAML zostaną przekazane do usługi Azure Machine Learning po przesłaniu zadania potoku. W tym przykładzie pliki pod ./componentA_src zostaną załadowane. (Wiersz 16 w componentA.yml). Możesz zobaczyć załadowany kod źródłowy w interfejsie użytkownika Studio: kliknij dwukrotnie krok componentA na wykresie i przejdź do karty Kod, jak pokazano na poniższym zrzucie ekranu. Widać, że jest to skrypt hello-world wykonujący proste operacje drukowania i zapisujący bieżącą datę oraz godzinę na ścieżce componentA_output. Składnik pobiera dane wejściowe i dostarcza dane wyjściowe za pośrednictwem wiersza polecenia. Jest on obsługiwany w hello.py za pośrednictwem metody argparse.

Dane wejściowe i wyjściowe
Dane wejściowe i wyjściowe definiują interfejs składnika. Dane wejściowe i wyjściowe mogą być wartościami literałów (typu string, number, integer lub boolean) lub obiektem zawierającym schemat wejściowy.
Wejście obiektu (typu uri_file, uri_folder, mltable, mlflow_model lub custom_model) może łączyć się z innymi krokami w zadaniu potoku nadrzędnego, aby przekazać dane/modele do innych kroków. Na wykresie przepływu dane wejściowe typu obiektu są renderowane jako kropka połączenia.
Literalne dane wejściowe (string, number, integer, boolean) to parametry, które można przekazać do składnika podczas wykonywania. W polu default można dodać domyślną wartość danych wejściowych literału. W przypadku typów number i integer można również dodawać wartości minimalne i maksymalne przy użyciu pól min i max. Jeśli wartość wejściowa jest mniejsza niż wartość minimalna lub większa niż maksymalna, potok nie przechodzi walidacji. Walidacja jest wykonywana przed przesłaniem zadania potoku, co może zaoszczędzić czas. Walidacja działa dla CLI, zestawu SDK Pythona i interfejsu projektanta. Poniższy zrzut ekranu przedstawia przykład weryfikacji w interfejsie użytkownika projektanta. Podobnie można zdefiniować dozwolone wartości w enum polach.

Jeśli chcesz dodać dane wejściowe do składnika, musisz wprowadzić zmiany w trzech miejscach:
- Pole
inputsw składniku YAML. - Pole
commandw składniku YAML. - W kodzie źródłowym składnika do obsługi danych wejściowych wiersza polecenia.
Te lokalizacje są oznaczone zielonymi polami na powyższym zrzucie ekranu.
Aby dowiedzieć się więcej na temat danych wejściowych i wyjściowych, zobacz Zarządzanie danymi wejściowymi i wyjściowymi składników i potoków.
Środowiska
Środowisko to środowisko, w którym jest uruchamiany składnik. Może to być środowisko Azure Machine Learning (opracowane lub niestandardowe), obraz Dockera lub środowisko conda. Zobacz następujące przykłady:
-
Zarejestrowany zasób środowiska usługi Azure Machine Learning. Środowisko jest przywołyne w składniku ze składnią
azureml:<environment-name>:<environment-version>. - Publiczny obraz platformy Docker.
- Plik Conda. Plik conda musi być używany razem z obrazem podstawowym.
Rejestrowanie składnika do ponownego użycia i udostępniania
Chociaż niektóre składniki są specyficzne dla określonego potoku, prawdziwe korzyści ze składników wynikają z ponownego użycia i udostępniania innym. Możesz zarejestrować składnik w obszarze roboczym usługi Machine Learning, aby udostępnić go do ponownego użycia. Zarejestrowane składniki obsługują automatyczne przechowywanie wersji, dzięki czemu można zaktualizować składnik, ale upewnij się, że potoki wymagające starszej wersji będą nadal działać.
W repozytorium azureml-examples przejdź do katalogu cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components.
Aby zarejestrować składnik, użyj az ml component create polecenia :
az ml component create --file train.yml
az ml component create --file score.yml
az ml component create --file eval.yml
Po uruchomieniu tych poleceń do końca, można zobaczyć składniki w studio, w obszarze Zasoby>Składniki.

Wybierz składnik. Zostaną wyświetlone szczegółowe informacje dotyczące każdej wersji składnika.
Karta Szczegóły zawiera podstawowe informacje, takie jak nazwa składnika, która ją utworzyła i wersja. Istnieją pola edytowalne dla tagów i opisu. Możesz użyć tagów, aby dodać słowa kluczowe wyszukiwania. Pole opisu obsługuje formatowanie języka Markdown. Należy go użyć do opisania funkcjonalności i podstawowego użycia składnika.
Na karcie Zadania zostanie wyświetlona historia wszystkich zadań, które używają składnika.
Używanie zarejestrowanych składników w pliku YAML zadania potoku
Zastosujesz teraz 1b_e2e_registered_components jako przykład zastosowania zarejestrowanego składnika w potoku YAML. Przejdź do 1b_e2e_registered_components katalogu i otwórz pipeline.yml plik. Klucze i wartości w polach inputs i outputs są podobne do tych, które zostały już omówione. Jedyną znaczącą różnicą jest wartość component pola w jobs.<job_name>.component wpisach. Wartość component ma postać azureml:<component_name>:<component_version>. Definicja train-job określa na przykład, że powinna być używana najnowsza wersja zarejestrowanego składnika my_train :
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
Zarządzanie składnikami
Szczegóły składnika i zarządzanie składnikami można sprawdzić przy użyciu interfejsu wiersza polecenia w wersji 2. Użyj az ml component -h polecenia, aby uzyskać szczegółowe instrukcje dotyczące poleceń dotyczących składników. W poniższej tabeli wymieniono wszystkie dostępne polecenia. Zobacz więcej przykładów w dokumentacji interfejsu wiersza polecenia platformy Azure.
| Komenda | opis |
|---|---|
az ml component create |
Utwórz składnik. |
az ml component list |
Wyświetl listę składników w obszarze roboczym. |
az ml component show |
Pokaż szczegóły składnika. |
az ml component update |
Aktualizowanie składnika. Tylko kilka pól (opis, nazwa_wyświetlana) może zostać zaktualizowanych. |
az ml component archive |
Archiwizowanie kontenera składników. |
az ml component restore |
Przywracanie zarchiwizowanego składnika. |
Następny krok
- Wypróbuj przykład składnika CLI w wersji 2