Tworzenie i uruchamianie potoków uczenia maszynowego przy użyciu składników za pomocą interfejsu wiersza polecenia usługi Azure Machine Learning
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
Z tego artykułu dowiesz się, jak tworzyć i uruchamiać potoki uczenia maszynowego przy użyciu interfejsu wiersza polecenia platformy Azure i składników. Potoki można tworzyć bez używania składników, ale składniki oferują największą elastyczność i ponowne użycie. Potoki usługi Azure Machine Learning można definiować w języku YAML i uruchamiać z interfejsu wiersza polecenia, utworzonego w języku Python lub komponowanego w projektancie usługi Azure Machine Learning Studio za pomocą interfejsu użytkownika przeciągania i upuszczania. Ten dokument koncentruje się na interfejsie wiersza polecenia.
Wymagania wstępne
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto. Wypróbuj bezpłatną lub płatną wersję usługi Azure Machine Learning.
Obszar roboczy usługi Azure Machine Learning. Tworzenie zasobów obszaru roboczego.
Sklonuj repozytorium przykładów:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/basics
Sugerowane wstępne odczytywanie
Tworzenie pierwszego potoku za pomocą składnika
Utwórzmy pierwszy potok ze składnikami przy użyciu przykładu. Ta sekcja ma na celu wstępne wrażenie, jak wygląda potok i składnik w usłudze Azure Machine Learning z konkretnym przykładem.
cli/jobs/pipelines-with-components/basics W katalogu azureml-examples repozytorium przejdź do podkatalogu3b_pipeline_with_data. W tym katalogu znajdują się trzy typy plików. Są to pliki, które należy utworzyć podczas tworzenia własnego potoku.
pipeline.yml: ten plik YAML definiuje potok uczenia maszynowego. W tym pliku YAML opisano sposób dzielenia pełnego zadania uczenia maszynowego na wieloetapowy przepływ pracy. Na przykład biorąc pod uwagę proste zadanie uczenia maszynowego dotyczące używania danych historycznych do trenowania modelu prognozowania sprzedaży, warto utworzyć sekwencyjny przepływ pracy z przetwarzaniem danych, trenowaniem modelu i krokami oceny modelu. Każdy krok jest składnikiem, który ma dobrze zdefiniowany interfejs i można go opracowywać, testować i optymalizować niezależnie. Potok YAML definiuje również sposób, w jaki kroki podrzędne łączą się z innymi krokami w potoku, na przykład krok trenowania modelu generuje plik modelu, a plik modelu zostanie przekazany do kroku oceny modelu.
component.yml: ten plik YAML definiuje składnik. Pakietuje następujące informacje:
- Metadane: nazwa, nazwa wyświetlana, wersja, opis, typ itp. Metadane ułatwiają opisywanie składnika i zarządzanie nim.
- Interfejs: dane wejściowe i wyjściowe. Na przykład składnik trenowania modelu pobiera dane treningowe i liczbę epok jako dane wejściowe i generuje wytrenowany plik modelu jako dane wyjściowe. Po zdefiniowaniu interfejsu różne zespoły mogą opracowywać i testować składnik niezależnie.
- Polecenie, kod i środowisko: polecenie, kod i środowisko do uruchomienia składnika. Polecenie to polecenie powłoki do wykonania składnika. Kod zwykle odwołuje się do katalogu kodu źródłowego. Środowisko może być środowiskiem usługi Azure Machine Learning (wyselekcjonowane lub utworzone przez klienta), obrazem platformy Docker lub środowiskiem conda.
component_src: jest to katalog kodu źródłowego dla określonego składnika. Zawiera kod źródłowy wykonywany w składniku. Możesz użyć preferowanego języka (Python, R...). Kod musi być wykonywany przez polecenie powłoki. Kod źródłowy może wykonać kilka danych wejściowych z wiersza polecenia powłoki, aby kontrolować sposób wykonywania tego kroku. Na przykład krok trenowania może wykonać dane szkoleniowe, szybkość nauki, liczbę epok w celu kontrolowania procesu trenowania. Argument polecenia powłoki służy do przekazywania danych wejściowych i wyjściowych do kodu.
Teraz utwórzmy potok przy użyciu przykładu 3b_pipeline_with_data . Objaśniamy szczegółowe znaczenie każdego pliku w poniższych sekcjach.
Najpierw wyświetl listę dostępnych zasobów obliczeniowych za pomocą następującego polecenia:
az ml compute list
Jeśli go nie masz, utwórz klaster o nazwie cpu-cluster , uruchamiając polecenie:
Uwaga
Pomiń ten krok, aby użyć bezserwerowych obliczeń.
az ml compute create -n cpu-cluster --type amlcompute --min-instances 0 --max-instances 10
Teraz utwórz zadanie potoku zdefiniowane w pliku pipeline.yml za pomocą następującego polecenia. Docelowy obiekt obliczeniowy jest przywołyny w pliku pipeline.yml jako azureml:cpu-cluster. Jeśli docelowy obiekt obliczeniowy używa innej nazwy, pamiętaj, aby zaktualizować go w pliku pipeline.yml.
az ml job create --file pipeline.yml
Powinien zostać wyświetlony słownik JSON zawierający informacje o zadaniu potoku, w tym:
| Key | opis |
|---|---|
name |
Nazwa zadania oparta na identyfikatorze GUID. |
experiment_name |
Nazwa, w ramach której zadania będą zorganizowane w studio. |
services.Studio.endpoint |
Adres URL monitorowania i przeglądania zadania potoku. |
status |
Stan zadania. Prawdopodobnie będzie Preparing to w tym momencie. |
Otwórz adres URL, services.Studio.endpoint aby wyświetlić wizualizację wykresu potoku.
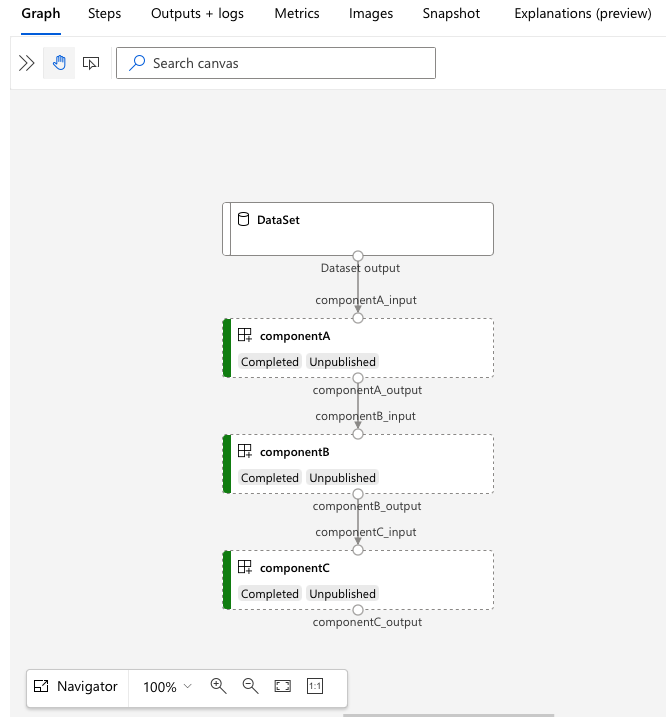
Omówienie definicji potoku YAML
Przyjrzyjmy się definicji potoku w pliku 3b_pipeline_with_data/pipeline.yml .
Uwaga
Aby użyć bezserwerowych obliczeń, zastąp ciąg default_compute: azureml:cpu-cluster ciągiem default_compute: azureml:serverless w tym pliku.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 3b_pipeline_with_data
description: Pipeline with 3 component jobs with data dependencies
settings:
default_compute: azureml:cpu-cluster
outputs:
final_pipeline_output:
mode: rw_mount
jobs:
component_a:
type: command
component: ./componentA.yml
inputs:
component_a_input:
type: uri_folder
path: ./data
outputs:
component_a_output:
mode: rw_mount
component_b:
type: command
component: ./componentB.yml
inputs:
component_b_input: ${{parent.jobs.component_a.outputs.component_a_output}}
outputs:
component_b_output:
mode: rw_mount
component_c:
type: command
component: ./componentC.yml
inputs:
component_c_input: ${{parent.jobs.component_b.outputs.component_b_output}}
outputs:
component_c_output: ${{parent.outputs.final_pipeline_output}}
# mode: upload
W tabeli opisano najczęściej używane pola schematu YAML potoku. Aby dowiedzieć się więcej, zobacz pełny schemat YAML potoku.
| key | opis |
|---|---|
| type | Wymagany. Typ zadania musi być pipeline przeznaczony dla zadań potoku. |
| display_name | Nazwa wyświetlana zadania potoku w interfejsie użytkownika programu Studio. Możliwość edycji w interfejsie użytkownika programu Studio. Nie musi być unikatowa we wszystkich zadaniach w obszarze roboczym. |
| Zadania | Wymagany. Słownik zestawu poszczególnych zadań do uruchomienia jako kroków w potoku. Te zadania są uznawane za podrzędne zadania nadrzędnego potoku. W tej wersji obsługiwane typy zadań w potoku to command i sweep |
| Wejścia | Słownik danych wejściowych zadania potoku. Klucz jest nazwą danych wejściowych w kontekście zadania, a wartość jest wartością wejściową. Te dane wejściowe potoku można odwoływać się do danych wejściowych pojedynczego zadania kroku w potoku przy użyciu elementu ${{ parent.inputs.<> wyrażenie input_name }}. |
| Wyjść | Słownik konfiguracji wyjściowych zadania potoku. Klucz jest nazwą danych wyjściowych w kontekście zadania, a wartość jest konfiguracją wyjściową. Te dane wyjściowe potoku można odwoływać się do danych wyjściowych pojedynczego zadania kroku w potoku przy użyciu elementu ${{ parents.outputs.<> output_name }} wyrażenie. |
W przykładzie 3b_pipeline_with_data utworzyliśmy trzy kroki potoku.
- Trzy kroki są definiowane w obszarze
jobs. Wszystkie trzy kroki to zadanie polecenia. Definicja każdego kroku znajduje się w odpowiednimcomponent.ymlpliku. Pliki YAML składnika są widoczne w katalogu 3b_pipeline_with_data . Wyjaśnimy componentA.yml w następnej sekcji. - Ten potok ma zależność danych, która jest powszechna w większości rzeczywistych potoków. Component_a pobiera dane wejściowe z folderu lokalnego w obszarze
./data(wiersz 17–20) i przekazuje dane wyjściowe do składnikaB (wiersz 29). dane wyjściowe Component_a mogą być przywołyne jako${{parent.jobs.component_a.outputs.component_a_output}}. - Element
computedefiniuje domyślne obliczenia dla tego potoku. Jeśli składnik w obszarzejobsdefiniuje inne zasoby obliczeniowe dla tego składnika, system uwzględnia ustawienie specyficzne dla składnika.

Odczytywanie i zapisywanie danych w potoku
Jednym z typowych scenariuszy jest odczytywanie i zapisywanie danych w potoku. W usłudze Azure Machine Learning używamy tego samego schematu do odczytywania i zapisywania danych dla wszystkich typów zadań (zadanie potoku, zadanie polecenia i zadanie zamiatania). Poniżej przedstawiono przykłady zadań potoku użycia danych w typowych scenariuszach.
- dane lokalne
- plik internetowy z publicznym adresem URL
- Magazyn danych i ścieżka usługi Azure Machine Learning
- Zasób danych usługi Azure Machine Learning
Omówienie definicji składnika YAML
Teraz przyjrzyjmy się componentA.yml jako przykładowi, aby zrozumieć definicję składnika YAML.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
type: command
name: component_a
display_name: componentA
version: 1
inputs:
component_a_input:
type: uri_folder
outputs:
component_a_output:
type: uri_folder
code: ./componentA_src
environment:
image: python
command: >-
python hello.py --componentA_input ${{inputs.component_a_input}} --componentA_output ${{outputs.component_a_output}}
Najczęściej używany schemat składnika YAML został opisany w tabeli. Aby dowiedzieć się więcej, zobacz pełny schemat YAML składnika.
| key | opis |
|---|---|
| name | Wymagany. Nazwa składnika. Musi być unikatowa w obszarze roboczym usługi Azure Machine Learning. Musi zaczynać się od małej litery. Zezwalaj na małe litery, cyfry i podkreślenie(_). Maksymalna długość to 255 znaków. |
| display_name | Nazwa wyświetlana składnika w interfejsie użytkownika programu Studio. Może być nonunique w obszarze roboczym. |
| polecenie | Wymagane polecenie do wykonania |
| code | Ścieżka lokalna do katalogu kodu źródłowego, który ma zostać przekazany i użyty dla składnika. |
| Środowisko usługi | Wymagany. Środowisko używane do wykonywania składnika. |
| Wejścia | Słownik danych wejściowych składników. Klucz jest nazwą danych wejściowych w kontekście składnika, a wartość jest definicją danych wejściowych składnika. Przy użyciu danych wejściowych ${{ można odwoływać się do danych wejściowych w poleceniu .<> wyrażenie input_name }}. |
| Wyjść | Słownik danych wyjściowych składników. Klucz jest nazwą danych wyjściowych w kontekście składnika, a wartość jest definicją danych wyjściowych składnika. Dane wyjściowe można przywoływać w poleceniu przy użyciu danych wyjściowych ${{.<> output_name }} wyrażenie. |
| is_deterministic | Czy ponownie użyć wyniku poprzedniego zadania, jeśli dane wejściowe składnika nie uległy zmianie. Wartość domyślna to true, nazywana również domyślnie ponownym użyciem. Typowy scenariusz ustawiany w false taki sposób, aby wymusić ponowne ładowanie danych z magazynu w chmurze lub adresu URL. |
Na przykład w 3b_pipeline_with_data/componentA.yml składnikA ma jedno dane wejściowe i jedno dane wyjściowe, które można połączyć z innymi krokami w potoku nadrzędnym. Wszystkie pliki w code sekcji w składniku YAML zostaną przekazane do usługi Azure Machine Learning podczas przesyłania zadania potoku. W tym przykładzie pliki w obszarze ./componentA_src zostaną przekazane (wiersz 16 w componentA.yml). Możesz zobaczyć przekazany kod źródłowy w interfejsie użytkownika programu Studio: dwukrotnie wybierz krok ComponentA i przejdź do karty Migawka, jak pokazano na poniższym zrzucie ekranu. Widzimy, że jest to skrypt hello-world po prostu wykonuje proste drukowanie i zapisuje bieżącą datę/godzinę na ścieżce componentA_output . Składnik pobiera dane wejściowe i wyjściowe za pośrednictwem argumentu wiersza polecenia i jest obsługiwany w hello.py przy użyciu polecenia argparse.

Dane wejściowe i wyjściowe
Dane wejściowe i wyjściowe definiują interfejs składnika. Dane wejściowe i wyjściowe mogą być jedną z wartości literałów (typu string,integernumber lub ) lub booleanobiektu zawierającego schemat wejściowy.
Dane wejściowe obiektu (typu uri_file, uri_folder,mltable,mlflow_model)custom_model mogą łączyć się z innymi krokami w zadaniu potoku nadrzędnego, a tym samym przekazywać dane/model do innych kroków. W grafie potoku typ obiektu dane wejściowe są renderowane jako kropka połączenia.
Dane wejściowe wartości literału (string,number,integer)boolean to parametry, które można przekazać do składnika w czasie wykonywania. W polu można dodać wartość domyślną danych wejściowych literału default . W przypadku number i integer typu można również dodać minimalną i maksymalną wartość zaakceptowanej wartości przy użyciu pól min i max . Jeśli wartość wejściowa przekroczy wartość minimalną i maksymalną, potok zakończy się niepowodzeniem podczas walidacji. Walidacja odbywa się przed przesłaniem zadania potoku w celu zaoszczędzenia czasu. Walidacja działa w przypadku interfejsu wiersza polecenia, zestawu SDK języka Python i interfejsu użytkownika projektanta. Poniższy zrzut ekranu przedstawia przykład weryfikacji w interfejsie użytkownika projektanta. Podobnie można zdefiniować dozwolone wartości w enum polu.

Jeśli chcesz dodać dane wejściowe do składnika, pamiętaj, aby edytować trzy miejsca:
inputspole w składniku YAMLcommandpole w składniku YAML.- Kod źródłowy składnika do obsługi danych wejściowych wiersza polecenia. Jest ona oznaczona w zielonym polu na poprzednim zrzucie ekranu.
Aby dowiedzieć się więcej na temat danych wejściowych i wyjściowych, zobacz Zarządzanie danymi wejściowymi i wyjściowymi składnika i potoku.
Środowisko
Środowisko definiuje środowisko do wykonania składnika. Może to być środowisko usługi Azure Machine Learning (nadzorowane lub niestandardowe), obraz platformy Docker lub środowisko conda. Zobacz poniższe przykłady.
- Zasób zarejestrowanego środowiska usługi Azure Machine Learning. Odwołuje się do niego składnik po
azureml:<environment-name>:<environment-version>składni. - publiczny obraz platformy Docker
- Plik Conda conda musi być używany razem z obrazem podstawowym.
Rejestrowanie składnika do ponownego użycia i udostępniania
Chociaż niektóre składniki są specyficzne dla określonego potoku, rzeczywiste korzyści ze składników wynikają z ponownego użycia i udostępniania. Zarejestruj składnik w obszarze roboczym usługi Machine Learning, aby udostępnić go do ponownego użycia. Zarejestrowane składniki obsługują automatyczne przechowywanie wersji, dzięki czemu można zaktualizować składnik, ale zapewnić, że potoki wymagające starszej wersji będą nadal działać.
W repozytorium azureml-examples przejdź do cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components katalogu.
Aby zarejestrować składnik, użyj az ml component create polecenia :
az ml component create --file train.yml
az ml component create --file score.yml
az ml component create --file eval.yml
Po uruchomieniu tych poleceń do ukończenia można zobaczyć składniki w programie Studio w obszarze Zasób —> składniki:

Wybierz składnik. Zostaną wyświetlone szczegółowe informacje dotyczące każdej wersji składnika.
Na karcie Szczegóły zostaną wyświetlone podstawowe informacje o składniku, takie jak nazwa, utworzona przez, wersja itp. Zostaną wyświetlone pola edytowalne dla tagów i opisu. Tagi mogą służyć do dodawania szybko wyszukiwanych słów kluczowych. Pole opisu obsługuje formatowanie języka Markdown i powinno służyć do opisywania funkcjonalności i podstawowego użycia składnika.
Na karcie Zadania zostanie wyświetlona historia wszystkich zadań, które używają tego składnika.
Używanie zarejestrowanych składników w pliku YAML zadania potoku
Użyjmy polecenia , aby użyć 1b_e2e_registered_components zarejestrowanego składnika w potoku YAML. Przejdź do 1b_e2e_registered_components katalogu, otwórz pipeline.yml plik. Klucze i wartości w polach inputs i outputs są podobne do tych, które zostały już omówione. Jedyną znaczącą różnicą jest wartość component pola w jobs.<JOB_NAME>.component wpisach. Wartość component ma postać azureml:<COMPONENT_NAME>:<COMPONENT_VERSION>. Definicja train-job określa na przykład najnowszą wersję zarejestrowanego składnika my_train :
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
Zarządzanie składnikami
Szczegóły składnika można sprawdzić i zarządzać składnikiem przy użyciu interfejsu wiersza polecenia (wersja 2). Użyj az ml component -h polecenia , aby uzyskać szczegółowe instrukcje dotyczące polecenia składnika. W poniższej tabeli wymieniono wszystkie dostępne polecenia. Zobacz więcej przykładów w dokumentacji interfejsu wiersza polecenia platformy Azure.
| rozruchu kasety | opis |
|---|---|
az ml component create |
Tworzenie składnika |
az ml component list |
Wyświetlanie listy składników w obszarze roboczym |
az ml component show |
Pokaż szczegóły składnika |
az ml component update |
Aktualizowanie składnika. Tylko kilka pól (opis, display_name) obsługuje aktualizację |
az ml component archive |
Archiwizowanie kontenera składników |
az ml component restore |
Przywracanie zarchiwizowanego składnika |