Niektóre polecenia interfejsu wiersza polecenia platformy Azure w tym artykule używają azure-cli-mlrozszerzenia , lub w wersji 1 dla usługi Azure Machine Learning. Obsługa rozszerzenia w wersji 1 zakończy się 30 września 2025 r. Będzie można zainstalować rozszerzenie v1 i używać go do tej daty.
Z tego artykułu dowiesz się, jak używać programu Open Neural Network Exchange (ONNX) do przewidywania modeli przetwarzania obrazów generowanych na podstawie zautomatyzowanego uczenia maszynowego (AutoML) w usłudze Azure Machine Learning.
Aby użyć polecenia ONNX do przewidywania, należy wykonać następujące kroki:
Pobierz pliki modelu ONNX z przebiegu trenowania rozwiązania AutoML.
Omówienie danych wejściowych i wyjściowych modelu ONNX.
Wstępnie przetwarza dane, aby był w wymaganym formacie dla obrazów wejściowych.
Wnioskowanie za pomocą środowiska uruchomieniowego ONNX dla języka Python.
Wizualizuj przewidywania pod kątem zadań wykrywania obiektów i segmentacji wystąpień.
ONNX to otwarty standard dla modeli uczenia maszynowego i uczenia głębokiego. Umożliwia importowanie i eksportowanie modelu (współdziałanie) w popularnych strukturach sztucznej inteligencji. Aby uzyskać więcej informacji, zapoznaj się z projektem ONNX GitHub.
Środowisko uruchomieniowe ONNX to projekt typu open source, który obsługuje wnioskowanie międzyplatformowe. Środowisko uruchomieniowe ONNX udostępnia interfejsy API w różnych językach programowania (w tym Python, C++, C#, C, Java i JavaScript). Te interfejsy API umożliwiają wnioskowanie na obrazach wejściowych. Po wyeksportowaniu modelu do formatu ONNX możesz użyć tych interfejsów API w dowolnym języku programowania, którego potrzebuje projekt.
W tym przewodniku dowiesz się, jak używać interfejsów API języka Python dla środowiska uruchomieniowego ONNX do przewidywania obrazów na potrzeby popularnych zadań przetwarzania obrazów. Możesz użyć tych wyeksportowanych modeli ONNX w różnych językach.
Pliki modelu ONNX można pobrać z poziomu przebiegów rozwiązania AutoML przy użyciu interfejsu użytkownika usługi Azure Machine Learning Studio lub zestawu SDK języka Python usługi Azure Machine Learning. Zalecamy pobranie za pośrednictwem zestawu SDK z nazwą eksperymentu i nadrzędnym identyfikatorem przebiegu.
Azure Machine Learning Studio
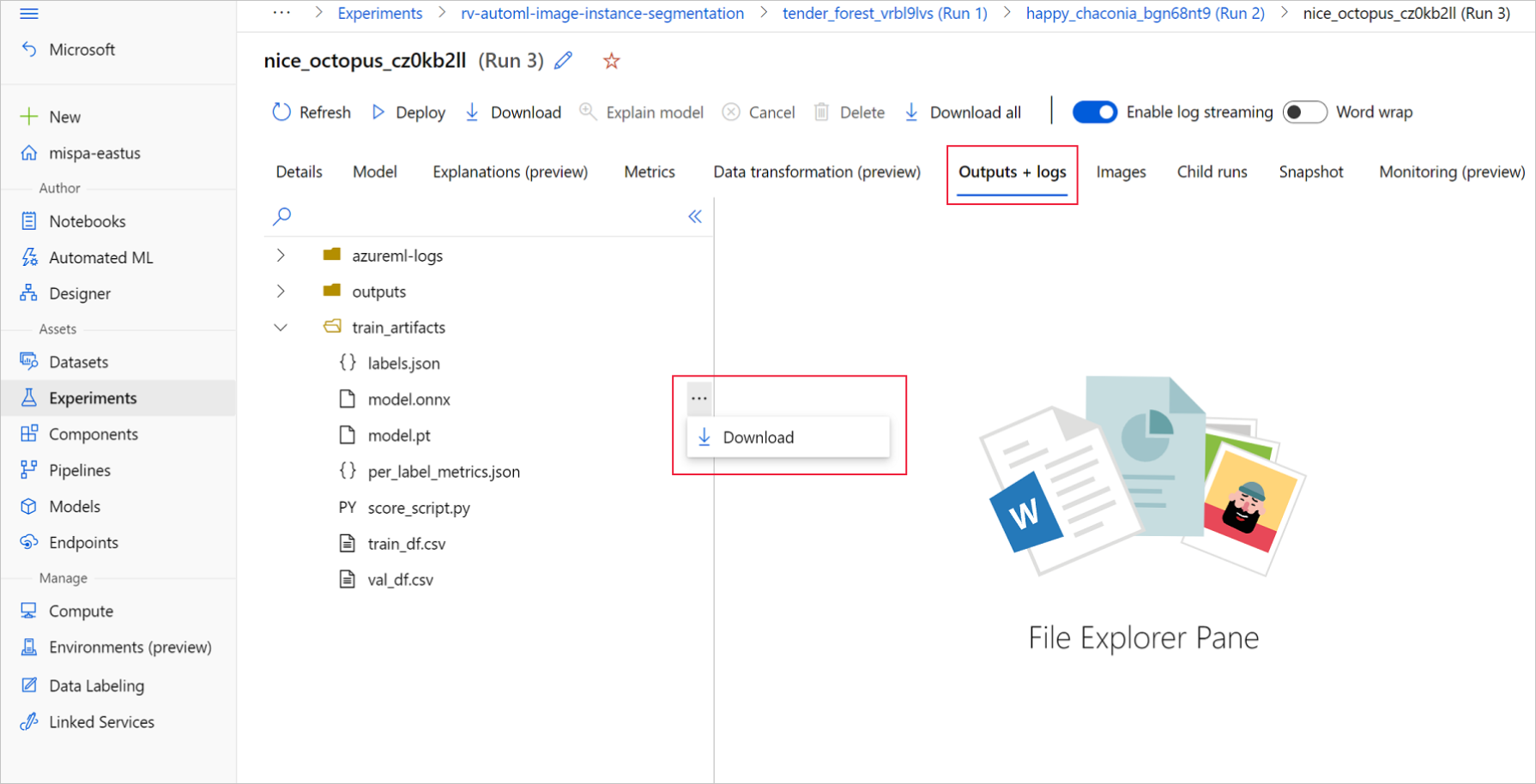
W usłudze Azure Machine Learning Studio przejdź do eksperymentu, używając hiperlinku do eksperymentu wygenerowanego w notesie szkoleniowym lub wybierając nazwę eksperymentu na karcie Eksperymenty w obszarze Zasoby. Następnie wybierz najlepszy przebieg podrzędny.
W ramach najlepszego uruchomienia podrzędnego przejdź do pozycji Dane wyjściowe i dzienniki>train_artifacts. Użyj przycisku Pobierz, aby ręcznie pobrać następujące pliki:
labels.json: plik zawierający wszystkie klasy lub etykiety w zestawie danych trenowania.
model.onnx: model w formacie ONNX.
Zapisz pobrane pliki modelu w katalogu. W przykładzie w tym artykule jest używany katalog ./automl_models .
Zestaw SDK języka Python usługi Azure Machine Learning
Za pomocą zestawu SDK możesz wybrać najlepszy przebieg podrzędny (według podstawowej metryki) z nazwą eksperymentu i nadrzędnym identyfikatorem uruchomienia. Następnie możesz pobrać pliki labels.json i model.onnx .
Poniższy kod zwraca najlepszy przebieg podrzędny na podstawie odpowiedniej metryki podstawowej.
from azureml.train.automl.run import AutoMLRun
# Select the best child run
run_id = '' # Specify the run ID
automl_image_run = AutoMLRun(experiment=experiment, run_id=run_id)
best_child_run = automl_image_run.get_best_child()
Pobierz plik labels.json zawierający wszystkie klasy i etykiety w zestawie danych trenowania.
Generowanie modelu na potrzeby oceniania wsadowego
Domyślnie rozwiązanie AutoML dla obrazów obsługuje ocenianie wsadowe klasyfikacji. Jednak modele wykrywania obiektów i segmentacji wystąpień nie obsługują wnioskowania wsadowego. W przypadku wnioskowania wsadowego na potrzeby wykrywania obiektów i segmentacji wystąpień użyj poniższej procedury, aby wygenerować model ONNX dla wymaganego rozmiaru partii. Modele generowane dla określonego rozmiaru partii nie działają w przypadku innych rozmiarów partii.
from azureml.core.script_run_config import ScriptRunConfig
from azureml.train.automl.run import AutoMLRun
from azureml.core.workspace import Workspace
from azureml.core import Experiment
# specify experiment name
experiment_name = ''
# specify workspace parameters
subscription_id = ''
resource_group = ''
workspace_name = ''
# load the workspace and compute target
ws = ''
compute_target = ''
experiment = Experiment(ws, name=experiment_name)
# specify the run id of the automl run
run_id = ''
automl_image_run = AutoMLRun(experiment=experiment, run_id=run_id)
best_child_run = automl_image_run.get_best_child()
Aby uzyskać wartości argumentów potrzebne do utworzenia modelu oceniania wsadowego, zapoznaj się ze skryptami oceniania wygenerowanymi w folderze outputs przebiegów trenowania rozwiązania AutoML. Użyj wartości hiperparametrów dostępnych w zmiennej ustawień modelu wewnątrz pliku oceniania, aby uzyskać najlepszy przebieg podrzędny.
W przypadku klasyfikacji obrazów wieloklasowych wygenerowany model ONNX dla najlepszego podrzędnego uruchamiania domyślnie obsługuje ocenianie wsadowe. W związku z tym nie są potrzebne żadne argumenty specyficzne dla modelu dla tego typu zadania i można przejść do sekcji Ładowanie etykiet i plików modelu ONNX.
W przypadku klasyfikacji obrazów z wieloma etykietami wygenerowany model ONNX dla najlepszego podrzędnego uruchomienia domyślnie obsługuje ocenianie wsadowe. W związku z tym nie są potrzebne żadne argumenty specyficzne dla modelu dla tego typu zadania i można przejść do sekcji Ładowanie etykiet i plików modelu ONNX.
arguments = ['--model_name', 'fasterrcnn_resnet34_fpn', # enter the faster rcnn or retinanet model name
'--batch_size', 8, # enter the batch size of your choice
'--height_onnx', 600, # enter the height of input to ONNX model
'--width_onnx', 800, # enter the width of input to ONNX model
'--experiment_name', experiment_name,
'--subscription_id', subscription_id,
'--resource_group', resource_group,
'--workspace_name', workspace_name,
'--run_id', run_id,
'--task_type', 'image-object-detection',
'--min_size', 600, # minimum size of the image to be rescaled before feeding it to the backbone
'--max_size', 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'--box_score_thresh', 0.3, # threshold to return proposals with a classification score > box_score_thresh
'--box_nms_thresh', 0.5, # NMS threshold for the prediction head
'--box_detections_per_img', 100 # maximum number of detections per image, for all classes
]
arguments = ['--model_name', 'yolov5', # enter the yolo model name
'--batch_size', 8, # enter the batch size of your choice
'--height_onnx', 640, # enter the height of input to ONNX model
'--width_onnx', 640, # enter the width of input to ONNX model
'--experiment_name', experiment_name,
'--subscription_id', subscription_id,
'--resource_group', resource_group,
'--workspace_name', workspace_name,
'--run_id', run_id,
'--task_type', 'image-object-detection',
'--img_size', 640, # image size for inference
'--model_size', 'medium', # size of the yolo model
'--box_score_thresh', 0.1, # threshold to return proposals with a classification score > box_score_thresh
'--box_iou_thresh', 0.5 # IOU threshold used during inference in nms post processing
]
arguments = ['--model_name', 'maskrcnn_resnet50_fpn', # enter the maskrcnn model name
'--batch_size', 8, # enter the batch size of your choice
'--height_onnx', 600, # enter the height of input to ONNX model
'--width_onnx', 800, # enter the width of input to ONNX model
'--experiment_name', experiment_name,
'--subscription_id', subscription_id,
'--resource_group', resource_group,
'--workspace_name', workspace_name,
'--run_id', run_id,
'--task_type', 'image-instance-segmentation',
'--min_size', 600, # minimum size of the image to be rescaled before feeding it to the backbone
'--max_size', 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'--box_score_thresh', 0.3, # threshold to return proposals with a classification score > box_score_thresh
'--box_nms_thresh', 0.5, # NMS threshold for the prediction head
'--box_detections_per_img', 100 # maximum number of detections per image, for all classes
]
Pobierz i zachowaj ONNX_batch_model_generator_automl_for_images.py plik w bieżącym katalogu i prześlij skrypt. Użyj polecenia ScriptRunConfig , aby przesłać skrypt ONNX_batch_model_generator_automl_for_images.py dostępny w repozytorium GitHub azureml-examples, aby wygenerować model ONNX o określonym rozmiarze partii. W poniższym kodzie wytrenowane środowisko modelu służy do przesyłania tego skryptu w celu wygenerowania i zapisania modelu ONNX w katalogu outputs.
Po wygenerowaniu modelu wsadowego pobierz go z danych wyjściowych +dzienników>wyjściowych ręcznie lub użyj następującej metody:
batch_size= 8 # use the batch size used to generate the model
onnx_model_path = 'automl_models/model.onnx' # local path to save the model
remote_run.download_file(name='outputs/model_'+str(batch_size)+'.onnx', output_file_path=onnx_model_path)
Wytrenowaliśmy modele dla wszystkich zadań przetwarzania obrazów przy użyciu odpowiednich zestawów danych, aby zademonstrować wnioskowanie modelu ONNX.
Ładowanie etykiet i plików modelu ONNX
Poniższy fragment kodu ładuje labels.json, gdzie nazwy klas są uporządkowane. Oznacza to, że jeśli model ONNX przewiduje identyfikator etykiety jako 2, odpowiada nazwie etykiety podanej w trzecim indeksie w pliku labels.json .
import json
import onnxruntime
labels_file = "automl_models/labels.json"
with open(labels_file) as f:
classes = json.load(f)
print(classes)
try:
session = onnxruntime.InferenceSession(onnx_model_path)
print("ONNX model loaded...")
except Exception as e:
print("Error loading ONNX file: ",str(e))
Pobieranie oczekiwanych danych wejściowych i wyjściowych dla modelu ONNX
Jeśli masz model, ważne jest, aby poznać szczegóły dotyczące określonego modelu i zadania. Te szczegóły obejmują liczbę danych wejściowych i liczbę danych wyjściowych, oczekiwany kształt wejściowy lub format przetwarzania wstępnego obrazu oraz kształt danych wyjściowych, aby znać dane wyjściowe specyficzne dla modelu lub dane wyjściowe specyficzne dla danego modelu.
sess_input = session.get_inputs()
sess_output = session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
for idx, input_ in enumerate(range(len(sess_input))):
input_name = sess_input[input_].name
input_shape = sess_input[input_].shape
input_type = sess_input[input_].type
print(f"{idx} Input name : { input_name }, Input shape : {input_shape}, \
Input type : {input_type}")
for idx, output in enumerate(range(len(sess_output))):
output_name = sess_output[output].name
output_shape = sess_output[output].shape
output_type = sess_output[output].type
print(f" {idx} Output name : {output_name}, Output shape : {output_shape}, \
Output type : {output_type}")
Oczekiwane formaty danych wejściowych i wyjściowych dla modelu ONNX
Każdy model ONNX ma wstępnie zdefiniowany zestaw formatów wejściowych i wyjściowych.
W tym przykładzie model jest stosowany wytrenowany na zestawie danych fridgeObjects z 134 obrazami i 4 klasami/etykietami w celu wyjaśnienia wnioskowania modelu ONNX. Aby uzyskać więcej informacji na temat trenowania zadania klasyfikacji obrazów, zobacz notes klasyfikacji obrazów wieloklasowych.
Format danych wejściowych
Dane wejściowe to wstępnie przetworzony obraz.
Nazwa danych wejściowych
Kształt wejściowy
Input type
opis
input1
(batch_size, num_channels, height, width)
ndarray(float)
Dane wejściowe to wstępnie przetworzony obraz o kształcie (1, 3, 224, 224) partii o rozmiarze 1 oraz wysokości i szerokości 224. Te liczby odpowiadają wartościom używanym crop_size w przykładzie trenowania.
Format wyjściowy
Dane wyjściowe to tablica logits dla wszystkich klas/etykiet.
Nazwa danych wyjściowych
Kształt danych wyjściowych
Typ danych wyjściowych
opis
output1
(batch_size, num_classes)
ndarray(float)
Model zwraca logits (bez softmaxelementu ). Na przykład w przypadku klas o rozmiarze partii 1 i 4 zwraca wartość (1, 4).
W tym przykładzie użyto modelu wytrenowanego na zestawie danych z wieloma etykietami fridgeObjects z 128 obrazami i 4 klasami/etykietami, aby wyjaśnić wnioskowanie modelu ONNX. Aby uzyskać więcej informacji na temat trenowania modelu klasyfikacji obrazów z wieloma etykietami, zobacz notes klasyfikacji obrazów z wieloma etykietami.
Format danych wejściowych
Dane wejściowe to wstępnie przetworzony obraz.
Nazwa danych wejściowych
Kształt wejściowy
Input type
opis
input1
(batch_size, num_channels, height, width)
ndarray(float)
Dane wejściowe to wstępnie przetworzony obraz o kształcie (1, 3, 224, 224) partii o rozmiarze 1 oraz wysokości i szerokości 224. Te liczby odpowiadają wartościom używanym crop_size w przykładzie trenowania.
Format wyjściowy
Dane wyjściowe to tablica logits dla wszystkich klas/etykiet.
Nazwa danych wyjściowych
Kształt danych wyjściowych
Typ danych wyjściowych
opis
output1
(batch_size, num_classes)
ndarray(float)
Model zwraca logits (bez sigmoidelementu ). Na przykład w przypadku klas o rozmiarze partii 1 i 4 zwraca wartość (1, 4).
W tym przykładzie wykrywania obiektów użyto modelu wytrenowanego na zestawie danych wykrywania lodówObjects 128 obrazów i 4 klas/etykiet, aby wyjaśnić wnioskowanie modelu ONNX. W tym przykładzie przedstawiono szybsze modele R-CNN w celu zademonstrowania kroków wnioskowania. Aby uzyskać więcej informacji na temat modeli wykrywania obiektów szkoleniowych, zobacz notes wykrywania obiektów.
Format danych wejściowych
Dane wejściowe to wstępnie przetworzony obraz.
Nazwa danych wejściowych
Kształt wejściowy
Input type
opis
Dane wejściowe
(batch_size, num_channels, height, width)
ndarray(float)
Dane wejściowe to wstępnie przetworzony obraz o kształcie (1, 3, 600, 800) partii o rozmiarze 1 oraz wysokości 600 i szerokości 800.
Format wyjściowy
Dane wyjściowe są krotką output_names i przewidywaniami. output_names W tym miejscu znajdują predictions się listy o długości 3*batch_size. W przypadku szybszej kolejności R-CNN danych wyjściowych są pola, etykiety i wyniki, natomiast w przypadku danych wyjściowych RetinaNet są polami, wynikami, etykietami.
Nazwa danych wyjściowych
Kształt danych wyjściowych
Typ danych wyjściowych
opis
output_names
(3*batch_size)
Lista kluczy
W przypadku partii o rozmiarze 2 output_names będzie ['boxes_0', 'labels_0', 'scores_0', 'boxes_1', 'labels_1', 'scores_1']
predictions
(3*batch_size)
Lista ndarray(float)
W przypadku partii o rozmiarze 2 predictions będzie mieć kształt [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n2_boxes, 4), (n2_boxes), (n2_boxes)]. W tym miejscu wartości w każdym indeksie odpowiadają temu samemu indeksowi w pliku output_names.
W poniższej tabeli opisano pola, etykiety i wyniki zwracane dla każdej próbki w partii obrazów.
Nazwisko
Kształt
Type
Opis
Pola
(n_boxes, 4), gdzie każde pole ma x_min, y_min, x_max, y_max
ndarray(float)
Model zwraca n pól ze współrzędnymi w lewym górnym i dolnym rogu.
Etykiety
(n_boxes)
ndarray(float)
Etykieta lub identyfikator klasy obiektu w każdym polu.
Wyniki
(n_boxes)
ndarray(float)
Współczynnik ufności obiektu w każdym polu.
W tym przykładzie wykrywania obiektów użyto modelu wytrenowanego na zestawie danych wykrywania lodówObjects 128 obrazów i 4 klas/etykiet, aby wyjaśnić wnioskowanie modelu ONNX. W tym przykładzie przedstawiono modele YOLO w celu zademonstrowania kroków wnioskowania. Aby uzyskać więcej informacji na temat modeli wykrywania obiektów szkoleniowych, zobacz notes wykrywania obiektów.
Format danych wejściowych
Dane wejściowe to wstępnie przetworzony obraz o kształcie (1, 3, 640, 640) partii o rozmiarze 1 oraz wysokości i szerokości 640. Te liczby odpowiadają wartościom używanym w przykładzie trenowania.
Nazwa danych wejściowych
Kształt wejściowy
Input type
opis
Dane wejściowe
(batch_size, num_channels, height, width)
ndarray(float)
Dane wejściowe to wstępnie przetworzony obraz o kształcie (1, 3, 640, 640) partii o rozmiarze 1 oraz wysokości 640 i szerokości 640.
Format wyjściowy
Przewidywania modelu ONNX zawierają wiele danych wyjściowych. Pierwsze dane wyjściowe są potrzebne do wykonania pomijania nienależących do maksymalnej liczby wykryć. W celu ułatwienia użycia zautomatyzowane uczenie maszynowe wyświetla format danych wyjściowych po kroku przetwarzania po przetworzeniu nmS. Dane wyjściowe po nmS to lista pól, etykiet i wyników dla każdej próbki w partii.
Nazwa danych wyjściowych
Kształt danych wyjściowych
Typ danych wyjściowych
opis
Wyjście
(batch_size)
Lista ndarray(float)
Model zwraca wykrycia pól dla każdej próbki w partii
Każda komórka na liście wskazuje wykrywanie pola próbki z kształtem (n_boxes, 6), gdzie każde pole ma wartość x_min, y_min, x_max, y_max, confidence_score, class_id.
W tym przykładzie segmentacji wystąpienia użyjesz modelu Mask R-CNN, który został wytrenowany na zestawie danych fridgeObjects z 128 obrazami i 4 klasami/etykietami, aby wyjaśnić wnioskowanie modelu ONNX. Aby uzyskać więcej informacji na temat trenowania modelu segmentacji wystąpienia, zobacz notes segmentacji wystąpienia.
Ważne
W przypadku zadań segmentacji wystąpień obsługiwane są tylko sieci R-CNN. Formaty danych wejściowych i wyjściowych są oparte tylko na sieci R-CNN.
Format danych wejściowych
Dane wejściowe to wstępnie przetworzony obraz. Model ONNX maski R-CNN został wyeksportowany do pracy z obrazami różnych kształtów. Zalecamy zmianę ich rozmiaru na stały rozmiar zgodny z rozmiarami obrazów treningowych w celu uzyskania lepszej wydajności.
Nazwa danych wejściowych
Kształt wejściowy
Input type
opis
Dane wejściowe
(batch_size, num_channels, height, width)
ndarray(float)
Dane wejściowe to wstępnie przetworzony obraz o kształcie (1, 3, input_image_height, input_image_width) partii o rozmiarze 1 oraz wysokości i szerokości podobnej do obrazu wejściowego.
Format wyjściowy
Dane wyjściowe są krotką output_names i przewidywaniami. output_namespredictions W tym miejscu znajdują się listy o długości 4*batch_size.
Nazwa danych wyjściowych
Kształt danych wyjściowych
Typ danych wyjściowych
opis
output_names
(4*batch_size)
Lista kluczy
W przypadku partii o rozmiarze 2 output_names będzie ['boxes_0', 'labels_0', 'scores_0', 'masks_0', 'boxes_1', 'labels_1', 'scores_1', 'masks_1']
predictions
(4*batch_size)
Lista ndarray(float)
W przypadku partii o rozmiarze 2 predictions będzie mieć kształt [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n1_boxes, 1, height_onnx, width_onnx), (n2_boxes, 4), (n2_boxes), (n2_boxes), (n2_boxes, 1, height_onnx, width_onnx)]. W tym miejscu wartości w każdym indeksie odpowiadają temu samemu indeksowi w pliku output_names.
Nazwisko
Kształt
Type
Opis
Pola
(n_boxes, 4), gdzie każde pole ma x_min, y_min, x_max, y_max
ndarray(float)
Model zwraca n pól ze współrzędnymi w lewym górnym i dolnym rogu.
Etykiety
(n_boxes)
ndarray(float)
Etykieta lub identyfikator klasy obiektu w każdym polu.
Wyniki
(n_boxes)
ndarray(float)
Współczynnik ufności obiektu w każdym polu.
Maski
(n_boxes, 1, height_onnx, width_onnx)
ndarray(float)
Maski (wielokąty) wykrytych obiektów o wysokości kształtu i szerokości obrazu wejściowego.
Wykonaj następujące kroki przetwarzania wstępnego dla wnioskowania modelu ONNX:
Przekonwertuj obraz na RGB.
Zmień rozmiar obrazu na valid_resize_size i valid_resize_size wartości, które odpowiadają wartościom używanym podczas przekształcania zestawu danych weryfikacji podczas trenowania. Wartość domyślna parametru valid_resize_size to 256.
Wyśrodkuj obraz do height_onnx_crop_size i width_onnx_crop_size. Odpowiada valid_crop_size on wartości domyślnej 224.
Zmień HxWxC na CxHxW.
Przekonwertuj na typ zmiennoprzecinkowy.
Normalizuj przy użyciu sieci mean = [0.485, 0.456, 0.406] ImageNet i std = [0.229, 0.224, 0.225].
Jeśli wybrano różne wartości hiperparametrów valid_resize_size i valid_crop_size podczas trenowania, należy użyć tych wartości.
Pobierz kształt wejściowy wymagany dla modelu ONNX.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Z PyTorch
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Wykonaj następujące kroki przetwarzania wstępnego dla wnioskowania modelu ONNX. Te kroki są takie same w przypadku klasyfikacji obrazów wieloklasowych.
Przekonwertuj obraz na RGB.
Zmień rozmiar obrazu na valid_resize_size i valid_resize_size wartości, które odpowiadają wartościom używanym podczas przekształcania zestawu danych weryfikacji podczas trenowania. Wartość domyślna parametru valid_resize_size to 256.
Wyśrodkuj obraz do height_onnx_crop_size i width_onnx_crop_size. valid_crop_size Odpowiada to wartości domyślnej 224.
Zmień HxWxC na CxHxW.
Przekonwertuj na typ zmiennoprzecinkowy.
Normalizuj przy użyciu sieci mean = [0.485, 0.456, 0.406] ImageNet i std = [0.229, 0.224, 0.225].
Jeśli wybrano różne wartości hiperparametrów valid_resize_size i valid_crop_size podczas trenowania, należy użyć tych wartości.
Pobierz kształt wejściowy wymagany dla modelu ONNX.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Z PyTorch
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
W przypadku wykrywania obiektów za pomocą algorytmu Faster R-CNN wykonaj te same kroki przetwarzania wstępnego co klasyfikacja obrazów, z wyjątkiem przycinania obrazów. Rozmiar obrazu można zmienić na wysokość 600 i szerokość 800. Możesz uzyskać oczekiwaną wysokość i szerokość danych wejściowych przy użyciu następującego kodu.
import glob
import numpy as np
from PIL import Image
def preprocess(image, height_onnx, width_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param height_onnx: expected height of an input image in onnx model
:type height_onnx: Int
:param width_onnx: expected width of an input image in onnx model
:type width_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((width_onnx, height_onnx))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_od/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
W przypadku wykrywania obiektów za pomocą algorytmu YOLO wykonaj te same kroki przetwarzania wstępnego co klasyfikacja obrazów, z wyjątkiem przycinania obrazów. Możesz zmienić rozmiar obrazu na wysokość 600 i szerokość 800oraz uzyskać oczekiwaną wysokość i szerokość danych wejściowych przy użyciu następującego kodu.
import glob
import numpy as np
from yolo_onnx_preprocessing_utils import preprocess
# use height and width based on the generated model
test_images_path = "automl_models_od_yolo/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
pad_list = []
for i in range(batch_size):
img_processed, pad = preprocess(image_files[i])
img_processed_list.append(img_processed)
pad_list.append(pad)
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Ważne
W przypadku zadań segmentacji wystąpień obsługiwane są tylko sieci R-CNN. Kroki przetwarzania wstępnego są oparte tylko na sieci R-CNN.
Wykonaj następujące kroki przetwarzania wstępnego dla wnioskowania modelu ONNX:
Przekonwertuj obraz na RGB.
Zmień rozmiar obrazu.
Zmień HxWxC na CxHxW.
Przekonwertuj na typ zmiennoprzecinkowy.
Normalizuj przy użyciu sieci mean = [0.485, 0.456, 0.406] ImageNet i std = [0.229, 0.224, 0.225].
W przypadku resize_height elementów i resize_widthmożna również użyć wartości używanych podczas trenowania, ograniczonych przez min_size hiperparametry i max_sizedla opcji Mask R-CNN.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_height, resize_width):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_height: resize height of an input image
:type resize_height: Int
:param resize_width: resize width of an input image
:type resize_width: Int
:return: pre-processed image in numpy format
:rtype: ndarray of shape 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((resize_width, resize_height))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
# use height and width based on the trained model
# use height and width based on the generated model
test_images_path = "automl_models_is/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Wnioskowanie za pomocą środowiska uruchomieniowego ONNX
Wnioskowanie przy użyciu środowiska uruchomieniowego ONNX różni się w przypadku każdego zadania przetwarzania obrazów.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session, img_data):
"""perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
(No. of boxes, 4) (No. of boxes,) (No. of boxes,)
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""perform predictions with ONNX Runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
:rtype: list
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
pred = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return pred[0]
result = get_predictions_from_ONNX(session, img_data)
Model segmentacji wystąpienia przewiduje pola, etykiety, wyniki i maski. FUNKCJA ONNX generuje przewidywaną maskę na wystąpienie wraz z odpowiednimi polami ograniczenia i współczynnikiem ufności klasy. W razie potrzeby może być konieczne przekonwertowanie z maski binarnej na wielokąt.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores , masks with shapes
(No. of instances, 4) (No. of instances,) (No. of instances,)
(No. of instances, 1, HEIGHT, WIDTH))
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
Zastosuj softmax() wartości przewidywane, aby uzyskać wyniki ufności klasyfikacji (prawdopodobieństwa) dla każdej klasy. Następnie przewidywanie będzie klasą o najwyższym prawdopodobieństwie.
conf_scores = torch.nn.functional.softmax(torch.from_numpy(scores), dim=1)
class_preds = torch.argmax(conf_scores, dim=1)
print("predicted classes:", ([(class_idx.item(), classes[class_idx]) for class_idx in class_preds]))
Ten krok różni się od klasyfikacji wieloklasowej. Należy zastosować sigmoid do logits (dane wyjściowe ONNX), aby uzyskać wyniki ufności dla klasyfikacji obrazów z wieloma etykietami.
Bez PyTorch
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = sigmoid(scores)
image_wise_preds = np.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
Z PyTorch
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = torch.sigmoid(torch.from_numpy(scores))
image_wise_preds = torch.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
W przypadku klasyfikacji wieloklasowej i wieloerytowej można wykonać te same kroki wymienione wcześniej dla wszystkich obsługiwanych algorytmów w rozwiązaniu AutoML.
W przypadku wykrywania obiektów przewidywania są automatycznie skalowane w skali height_onnx, width_onnx. Aby przekształcić współrzędne przewidywanego pola na oryginalne wymiary, można zaimplementować następujące obliczenia.
Xmin * original_width/width_onnx
Ymin * original_height/height_onnx
Xmax * original_width/width_onnx
Ymax * original_height/height_onnx
Inną opcją jest użycie następującego kodu w celu skalowania wymiarów pola w zakresie [0, 1]. Dzięki temu współrzędne pola mogą być mnożone z oryginalną wysokością i szerokością obrazów z odpowiednimi współrzędnymi (zgodnie z opisem w sekcji wizualizowania przewidywań) w celu pobrania pól w oryginalnych wymiarach obrazu.
def _get_box_dims(image_shape, box):
box_keys = ['topX', 'topY', 'bottomX', 'bottomY']
height, width = image_shape[0], image_shape[1]
box_dims = dict(zip(box_keys, [coordinate.item() for coordinate in box]))
box_dims['topX'] = box_dims['topX'] * 1.0 / width
box_dims['bottomX'] = box_dims['bottomX'] * 1.0 / width
box_dims['topY'] = box_dims['topY'] * 1.0 / height
box_dims['bottomY'] = box_dims['bottomY'] * 1.0 / height
return box_dims
def _get_prediction(boxes, labels, scores, image_shape, classes):
bounding_boxes = []
for box, label_index, score in zip(boxes, labels, scores):
box_dims = _get_box_dims(image_shape, box)
box_record = {'box': box_dims,
'label': classes[label_index],
'score': score.item()}
bounding_boxes.append(box_record)
return bounding_boxes
# Filter the results with threshold.
# Please replace the threshold for your test scenario.
score_threshold = 0.8
filtered_boxes_batch = []
for batch_sample in range(0, batch_size*3, 3):
# in case of retinanet change the order of boxes, labels, scores to boxes, scores, labels
# confirm the same from order of boxes, labels, scores output_names
boxes, labels, scores = predictions[batch_sample], predictions[batch_sample + 1], predictions[batch_sample + 2]
bounding_boxes = _get_prediction(boxes, labels, scores, (height_onnx, width_onnx), classes)
filtered_bounding_boxes = [box for box in bounding_boxes if box['score'] >= score_threshold]
filtered_boxes_batch.append(filtered_bounding_boxes)
Poniższy kod tworzy pola, etykiety i wyniki. Użyj tych szczegółów pola ograniczenia, aby wykonać te same kroki przetwarzania końcowego, co w przypadku szybszego modelu R-CNN.
Możesz użyć kroków wymienionych w sekcji Faster R-CNN (w przypadku maskowania R-CNN każdy przykład zawiera cztery pola elementów, etykiety, wyniki, maski) lub odwołać się do sekcji wizualizowania przewidywań dla segmentacji wystąpień.
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
 Zestaw SDK języka Python w wersji 1
Zestaw SDK języka Python w wersji 1