Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: SDK v1 usługi Azure Machine Learning dla języka Python
SDK v1 usługi Azure Machine Learning dla języka Python
Ważne
Niektóre polecenia interfejsu wiersza polecenia platformy Azure w tym artykule używają azure-cli-mlrozszerzenia , lub w wersji 1 dla usługi Azure Machine Learning. Obsługa rozszerzenia w wersji 1 zakończy się 30 września 2025 r. Możesz zainstalować rozszerzenie v1 i używać go do tej daty.
Zalecamy przejście do mlrozszerzenia , lub w wersji 2 przed 30 września 2025 r. Aby uzyskać więcej informacji na temat rozszerzenia w wersji 2, zobacz Rozszerzenie interfejsu wiersza polecenia usługi Azure Machine Learning i zestaw Python SDK w wersji 2.
Ważne
Ten artykuł zawiera informacje na temat korzystania z zestawu Azure Machine Learning SDK w wersji 1. Zestaw SDK w wersji 1 jest przestarzały od 31 marca 2025 r. Wsparcie dla niego zakończy się 30 czerwca 2026 r. Do tej pory można zainstalować zestaw SDK w wersji 1 i używać go.
Zalecamy przejście do zestawu SDK w wersji 2 przed 30 czerwca 2026 r. Aby uzyskać więcej informacji na temat zestawu SDK w wersji 2, zobacz Co to jest interfejs wiersza polecenia usługi Azure Machine Learning i zestaw Python SDK w wersji 2? oraz dokumentacja zestawu SDK w wersji 2.
Ważne
Ta funkcja jest obecnie w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Z tego artykułu dowiesz się, jak trenować modele przetwarzania obrazów na danych obrazów za pomocą zautomatyzowanego uczenia maszynowego w zestawie SDK języka Python usługi Azure Machine Learning.
Zautomatyzowane uczenie maszynowe obsługuje trenowanie modeli dla zadań przetwarzania obrazów, takich jak klasyfikowanie obrazów, wykrywanie obiektów i segmentacja wystąpień. Tworzenie modeli zautomatyzowanego uczenia maszynowego dla zadań przetwarzania obrazów jest obecnie obsługiwane za pośrednictwem zestawu Azure Machine Learning Python SDK. Wynikowe przebiegi eksperymentów, modele i dane wyjściowe są dostępne z poziomu interfejsu użytkownika usługi Azure Machine Learning Studio. Dowiedz się więcej na temat zautomatyzowanego uczenia maszynowego na potrzeby zadań przetwarzania obrazów na danych obrazów.
Uwaga
Zautomatyzowane uczenie maszynowe dla zadań przetwarzania obrazów jest dostępne tylko za pośrednictwem zestawu SDK języka Python usługi Azure Machine Learning.
Wymagania wstępne
Obszar roboczy usługi Azure Machine Learning. Aby utworzyć obszar roboczy, zobacz Tworzenie zasobów obszaru roboczego.
Zainstalowany zestaw SDK języka Python usługi Azure Machine Learning. Aby zainstalować zestaw SDK, możesz wykonać jedną z następujących czynności:
Utwórz wystąpienie obliczeniowe, które automatycznie instaluje zestaw SDK i jest wstępnie skonfigurowane dla przepływów pracy uczenia maszynowego. Aby uzyskać więcej informacji, zobacz Tworzenie wystąpienia obliczeniowego usługi Azure Machine Learning i zarządzanie nim.
Zainstaluj pakiet
automlsamodzielnie, który obejmuje domyślną instalację zestawu SDK.
Uwaga
Tylko języki Python 3.7 i 3.8 są zgodne z automatyczną obsługą uczenia maszynowego na potrzeby zadań przetwarzania obrazów.
Wybierz typ zadania
Zautomatyzowane uczenie maszynowe dla obrazów obsługuje następujące typy zadań:
| Typ zadania | Składnia konfiguracji AutoMLImage |
|---|---|
| klasyfikacja obrazów | ImageTask.IMAGE_CLASSIFICATION |
| klasyfikacja obrazów — wiele etykiet | ImageTask.IMAGE_CLASSIFICATION_MULTILABEL |
| wykrywanie obiektu obrazu | ImageTask.IMAGE_OBJECT_DETECTION |
| segmentacja wystąpienia obrazu | ImageTask.IMAGE_INSTANCE_SEGMENTATION |
Ten typ zadania jest wymaganym parametrem i jest przekazywany przy użyciu parametru task w pliku AutoMLImageConfig.
Na przykład:
from azureml.train.automl import AutoMLImageConfig
from azureml.automl.core.shared.constants import ImageTask
automl_image_config = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION)
Dane trenowania i walidacji
Aby wygenerować modele przetwarzania obrazów, należy wprowadzić dane obrazów z etykietą jako dane wejściowe na potrzeby trenowania modelu w postaci zestawu danych tabelarycznych usługi Azure Machine Learning. Możesz użyć TabularDataset elementu wyeksportowanego z projektu etykietowania danych lub utworzyć nowy TabularDataset z danymi treningowymi oznaczonymi etykietami.
Jeśli dane szkoleniowe mają inny format (np. pascal VOC lub COCO), możesz zastosować skrypty pomocnika dołączone do przykładowych notesów, aby przekonwertować dane na format JSONL. Dowiedz się więcej na temat przygotowywania danych do zadań przetwarzania obrazów za pomocą zautomatyzowanego uczenia maszynowego.
Ostrzeżenie
Tworzenie zestawów TabularDatasets z danych w formacie JSONL jest obsługiwane tylko przy użyciu zestawu SDK. Tworzenie zestawu danych za pośrednictwem interfejsu użytkownika nie jest obecnie obsługiwane. Od tej pory interfejs użytkownika nie rozpoznaje typu danych StreamInfo, który jest typem danych używanym dla adresów URL obrazów w formacie JSONL.
Uwaga
Zestaw danych trenowania musi mieć co najmniej 10 obrazów, aby można było przesłać przebieg rozwiązania AutoML.
Przykłady schematów JSONL
Struktura zestawu TabularDataset zależy od zadania. W przypadku typów zadań przetwarzania obrazów składa się z następujących pól:
| Pole | opis |
|---|---|
image_url |
Zawiera ścieżkę pliku jako obiekt StreamInfo |
image_details |
Informacje o metadanych obrazu składają się z wysokości, szerokości i formatu. To pole jest opcjonalne, dlatego może lub nie istnieje. |
label |
Reprezentacja json etykiety obrazu na podstawie typu zadania. |
Poniżej przedstawiono przykładowy plik JSONL na potrzeby klasyfikacji obrazów:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "AmlDatastore://image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
Poniższy kod to przykładowy plik JSONL do wykrywania obiektów:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "AmlDatastore://image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Korzystanie z danych
Gdy dane są w formacie JSONL, możesz utworzyć zestaw TabularDataset z następującym kodem:
ws = Workspace.from_config()
ds = ws.get_default_datastore()
from azureml.core import Dataset
training_dataset = Dataset.Tabular.from_json_lines_files(
path=ds.path('odFridgeObjects/odFridgeObjects.jsonl'),
set_column_types={'image_url': DataType.to_stream(ds.workspace)})
training_dataset = training_dataset.register(workspace=ws, name=training_dataset_name)
Zautomatyzowane uczenie maszynowe nie nakłada żadnych ograniczeń dotyczących rozmiaru danych trenowania ani sprawdzania poprawności na potrzeby zadań przetwarzania obrazów. Maksymalny rozmiar zestawu danych jest ograniczony tylko przez warstwę magazynu za zestawem danych (tj. magazyn obiektów blob). Nie ma minimalnej liczby obrazów ani etykiet. Zalecamy jednak rozpoczęcie od co najmniej 10–15 próbek na etykietę, aby upewnić się, że model wyjściowy jest wystarczająco wytrenowany. Im większa łączna liczba etykiet/klas, tym więcej próbek potrzebujesz na etykietę.
Dane szkoleniowe są wymagane i są przekazywane przy użyciu parametru training_data . Opcjonalnie możesz określić inny zestaw danych tabelarycznych jako zestaw danych sprawdzania poprawności, który ma być używany dla modelu przy użyciu validation_data parametru AutoMLImageConfig. Jeśli nie określono zestawu danych sprawdzania poprawności, domyślnie do weryfikacji zostanie użyte 20% danych treningowych, chyba że argument zostanie przekazany validation_size z inną wartością.
Na przykład:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(training_data=training_dataset)
Obliczenia w celu uruchomienia eksperymentu
Podaj docelowy obiekt obliczeniowy dla zautomatyzowanego uczenia maszynowego w celu przeprowadzenia trenowania modelu. Zautomatyzowane modele uczenia maszynowego na potrzeby zadań przetwarzania obrazów wymagają jednostek SKU procesora GPU oraz obsługi rodzin NC i ND. W celu szybszego trenowania zalecamy serię NCsv3 (z procesorami GPU w wersji 100). Docelowy obiekt obliczeniowy z procesorem SKU maszyny wirtualnej z wieloma procesorami GPU wykorzystuje wiele procesorów GPU, aby przyspieszyć trenowanie. Ponadto podczas konfigurowania docelowego obiektu obliczeniowego z wieloma węzłami można przeprowadzić szybsze trenowanie modelu za pomocą równoległości podczas dostrajania hiperparametrów dla modelu.
Uwaga
Jeśli używasz wystąpienia obliczeniowego jako celu obliczeniowego, upewnij się, że wiele zadań automatycznego uczenia maszynowego nie jest uruchamianych w tym samym czasie. Upewnij się również, że max_concurrent_iterations ustawiono wartość 1 w zasobach eksperymentu.
Docelowy obiekt obliczeniowy jest wymaganym parametrem i jest przekazywany przy użyciu compute_target parametru AutoMLImageConfig. Na przykład:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(compute_target=compute_target)
Konfigurowanie algorytmów modelu i hiperparametrów
Dzięki obsłudze zadań przetwarzania obrazów można kontrolować algorytm modelu i zamiatać hiperparametry. Te algorytmy modelu i hiperparametry są przekazywane jako przestrzeń parametrów dla zamiatania.
Algorytm modelu jest wymagany i przekazywany za pośrednictwem model_name parametru. Można określić jeden model_name lub wybrać między wieloma.
Obsługiwane algorytmy modelu
W poniższej tabeli przedstawiono podsumowanie obsługiwanych modeli dla każdego zadania przetwarzania obrazów.
| Zadanie | Algorytmy modelu | Składnia literału ciągudefault_model* oznaczany za pomocą * |
|---|---|---|
| Klasyfikacja obrazów (wiele klas i wiele etykiet) |
MobileNet: lekkie modele dla aplikacji mobilnych ResNet: sieci resztkowe ResNeSt: Dzielenie sieci uwagi SE-ResNeXt50: Sieci wyciśnięcia i ekscytacji ViT: Sieci przekształcania obrazów |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (mały) vitb16r224* (podstawa) vitl16r224 (duży) |
| Wykrywanie obiektów |
YOLOv5: jeden model wykrywania obiektów etapu Szybsza funkcja RCNN ResNet FPN: dwa etapowe modele wykrywania obiektów RetinaNet ResNet FPN: rozwiązywanie dysproporcji klas z utratą ogniskową Uwaga: zapoznaj się z model_size hiperparametrem dla rozmiarów modeli YOLOv5. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Segmentacja wystąpień | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn maskrcnn_resnet50_fpn |
Oprócz kontrolowania algorytmu modelu można również dostroić hiperparametry używane do trenowania modelu. Chociaż wiele hiperparametrów uwidocznionych jest niezależny od modelu, istnieją wystąpienia, w których hiperparametry są specyficzne dla zadań lub specyficzne dla modelu. Dowiedz się więcej na temat dostępnych hiperparametrów dla tych wystąpień.
Rozszerzanie danych
Ogólnie rzecz biorąc, wydajność modelu uczenia głębokiego może często poprawić się przy użyciu większej ilości danych. Rozszerzanie danych to praktyczna technika wzmacniania rozmiaru danych i zmienności zestawu danych, co ułatwia zapobieganie nadmiernemu dopasowaniu i ulepszaniu uogólniania modelu w przypadku niezaużytowanych danych. Zautomatyzowane uczenie maszynowe stosuje różne techniki rozszerzania danych na podstawie zadania przetwarzania obrazów przed przekazywaniem obrazów wejściowych do modelu. Obecnie nie ma uwidocznionych hiperparametrów do kontrolowania rozszerzeń danych.
| Zadanie | Zestaw danych, na który ma to wpływ | Zastosowane techniki rozszerzania danych |
|---|---|---|
| Klasyfikacja obrazów (wiele klas i wiele etykiet) | Szkolenie Walidacja i testowanie |
Losowy rozmiar i przycinanie, przerzucanie poziome, zakłócenia kolorów (jasność, kontrast, nasycenie i odcienie), normalizacja przy użyciu średniej i odchylenia standardowego sieci ImageNet opartej na kanale Zmienianie rozmiaru, wyśrodkowanie przycinania, normalizacja |
| Wykrywanie obiektów, segmentacja wystąpień | Szkolenie Walidacja i testowanie |
Losowe przycinanie wokół pól ograniczenia, rozwijanie, przerzucanie w poziomie, normalizacja, zmiana rozmiaru Normalizacja, zmiana rozmiaru |
| Wykrywanie obiektów przy użyciu narzędzia yolov5 | Szkolenie Walidacja i testowanie |
Mozaika, losowa szafka (obrót, tłumaczenie, skala, ścinanie), przerzucanie poziome Zmiana rozmiaru skrzynki pocztowej |
Konfigurowanie ustawień eksperymentu
Przed przeprowadzeniem dużego zamiatania w celu wyszukania optymalnych modeli i hiperparametrów zalecamy wypróbowanie wartości domyślnych w celu uzyskania pierwszego punktu odniesienia. Następnie możesz zapoznać się z wieloma hiperparametrami dla tego samego modelu przed zamiataniem wielu modeli i ich parametrów. Dzięki temu można stosować bardziej iteracyjne podejście, ponieważ w przypadku wielu modeli i wielu hiperparametrów dla każdego miejsca wyszukiwania rośnie wykładniczo i potrzebujesz większej liczby iteracji w celu znalezienia optymalnych konfiguracji.
Jeśli chcesz użyć domyślnych wartości hiperparametrów dla danego algorytmu (np. yolov5), możesz określić konfigurację dla obrazu AutoML działa w następujący sposób:
from azureml.train.automl import AutoMLImageConfig
from azureml.train.hyperdrive import GridParameterSampling, choice
from azureml.automl.core.shared.constants import ImageTask
automl_image_config_yolov5 = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION,
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
hyperparameter_sampling=GridParameterSampling({'model_name': choice('yolov5')}),
iterations=1)
Po utworzeniu modelu bazowego możesz chcieć zoptymalizować wydajność modelu, aby zamiatać algorytm modelu i przestrzeń hiperparametrów. Przy użyciu poniższej przykładowej konfiguracji można zamiatać hiperparametry dla każdego algorytmu, wybierając spośród zakresu wartości dla learning_rate, optymalizatora, lr_scheduler itp., aby wygenerować model z optymalną metryką podstawową. Jeśli nie określono wartości hiperparametrów, wartości domyślne są używane dla określonego algorytmu.
Metryka podstawowa
Podstawowa metryka używana do optymalizacji modelu i dostrajania hiperparametrów zależy od typu zadania. Korzystanie z innych podstawowych wartości metryki nie jest obecnie obsługiwane.
-
accuracyIMAGE_CLASSIFICATION -
iouIMAGE_CLASSIFICATION_MULTILABEL -
mean_average_precisionIMAGE_OBJECT_DETECTION -
mean_average_precisionIMAGE_INSTANCE_SEGMENTATION
Budżet eksperymentu
Opcjonalnie możesz określić maksymalny budżet czasu eksperymentu automl vision przy użyciu — experiment_timeout_hours ilość czasu w godzinach przed zakończeniem eksperymentu. Jeśli żaden nie zostanie określony, domyślny limit czasu eksperymentu wynosi siedem dni (maksymalnie 60 dni).
Zamiatanie hiperparametrów dla modelu
Podczas trenowania modeli przetwarzania obrazów wydajność modelu zależy w dużym stopniu od wybranych wartości hiperparametrów. Często warto dostosować hiperparametry, aby uzyskać optymalną wydajność. Dzięki obsłudze zadań przetwarzania obrazów w zautomatyzowanym uczeniu maszynowym można zamiatać hiperparametry, aby znaleźć optymalne ustawienia dla modelu. Ta funkcja stosuje możliwości dostrajania hiperparametrów w usłudze Azure Machine Learning. Dowiedz się, jak dostroić hiperparametry.
Definiowanie przestrzeni wyszukiwania parametrów
Można zdefiniować algorytmy modelu i hiperparametry, aby zamiatać w przestrzeni parametrów.
- Zobacz Konfigurowanie algorytmów modelu i hiperparametrów , aby uzyskać listę obsługiwanych algorytmów modelu dla każdego typu zadania.
- Zobacz Hiperparametry dla hiperparametrów zadań przetwarzania obrazów dla każdego typu zadania przetwarzania obrazów.
- Szczegółowe informacje na temat obsługiwanych dystrybucji dla dyskretnych i ciągłych hiperparametrów.
Metody próbkowania dla zamiatania
Podczas zamiatania hiperparametrów należy określić metodę próbkowania, która ma być używana do zamiatania przez zdefiniowaną przestrzeń parametrów. Obecnie następujące metody próbkowania są obsługiwane za pomocą parametru hyperparameter_sampling :
Uwaga
Obecnie tylko próbkowanie losowe i siatki obsługuje tylko warunkowe przestrzenie hiperparametryczne.
Zasady wczesnego kończenia
Możesz automatycznie zakończyć przebiegi o niskiej wydajności z zasadami wczesnego kończenia. Wczesne zakończenie poprawia wydajność obliczeniową, oszczędzając zasoby obliczeniowe, które w przeciwnym razie zostałyby wydane na mniej obiecujące konfiguracje. Zautomatyzowane uczenie maszynowe dla obrazów obsługuje następujące zasady wczesnego zakończenia przy użyciu parametru early_termination_policy . Jeśli nie określono żadnych zasad zakończenia, wszystkie konfiguracje są uruchamiane do ukończenia.
Dowiedz się więcej na temat konfigurowania zasad wczesnego zakończenia dla zamiatania hiperparametrów.
Zasoby dla zamiatania
Możesz kontrolować zasoby wydane na zamiatanie hiperparametrów, określając iterations wartości i max_concurrent_iterations dla zamiatania.
| Parametr | Szczegół |
|---|---|
iterations |
Wymagany parametr dla maksymalnej liczby konfiguracji do zamiatania. Musi być liczbą całkowitą z zakresu od 1 do 1000. Podczas eksplorowania tylko domyślnych hiperparametrów dla danego algorytmu modelu ustaw ten parametr na 1. |
max_concurrent_iterations |
Maksymalna liczba przebiegów, które mogą być uruchamiane współbieżnie. Jeśli nie zostanie określony, wszystkie uruchomienia są uruchamiane równolegle. W przypadku określenia musi być liczbą całkowitą z zakresu od 1 do 100. UWAGA: Liczba współbieżnych uruchomień jest bramowana na zasobach dostępnych w określonym obiekcie docelowym obliczeniowym. Upewnij się, że docelowy obiekt obliczeniowy ma dostępne zasoby dla żądanej współbieżności. |
Uwaga
Aby zapoznać się z kompletnym przykładem konfiguracji zamiatania, zapoznaj się z tym samouczkiem.
Argumenty
Możesz przekazać stałe ustawienia lub parametry, które nie zmieniają się podczas zamiatania przestrzeni parametrów jako argumenty. Argumenty są przekazywane w parach nazwa-wartość, a nazwa musi być poprzedzona podwójnym kreską.
from azureml.train.automl import AutoMLImageConfig
arguments = ["--early_stopping", 1, "--evaluation_frequency", 2]
automl_image_config = AutoMLImageConfig(arguments=arguments)
Trenowanie przyrostowe (opcjonalnie)
Po zakończeniu przebiegu trenowania masz możliwość dalszego trenowania modelu przez załadowanie wytrenowanego punktu kontrolnego modelu. Do trenowania przyrostowego można użyć tego samego zestawu danych lub innego zestawu danych.
Dostępne są dwie opcje trenowania przyrostowego. Masz następujące możliwości:
- Przekaż identyfikator przebiegu, z którego chcesz załadować punkt kontrolny.
- Przekazywanie punktów kontrolnych za pośrednictwem zestawu plikówDataset.
Przekazywanie punktu kontrolnego za pomocą identyfikatora przebiegu
Aby znaleźć identyfikator przebiegu z żądanego modelu, możesz użyć następującego kodu.
# find a run id to get a model checkpoint from
target_checkpoint_run = automl_image_run.get_best_child()
Aby przekazać punkt kontrolny za pośrednictwem identyfikatora przebiegu, należy użyć parametru checkpoint_run_id .
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_run_id= target_checkpoint_run.id,
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
Przekazywanie punktu kontrolnego za pośrednictwem elementu FileDataset
Aby przekazać punkt kontrolny za pośrednictwem elementu FileDataset, należy użyć parametrów checkpoint_dataset_id i checkpoint_filename .
# download the checkpoint from the previous run
model_name = "outputs/model.pt"
model_local = "checkpoints/model_yolo.pt"
target_checkpoint_run.download_file(name=model_name, output_file_path=model_local)
# upload the checkpoint to the blob store
ds.upload(src_dir="checkpoints", target_path='checkpoints')
# create a FileDatset for the checkpoint and register it with your workspace
ds_path = ds.path('checkpoints/model_yolo.pt')
checkpoint_yolo = Dataset.File.from_files(path=ds_path)
checkpoint_yolo = checkpoint_yolo.register(workspace=ws, name='yolo_checkpoint')
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_dataset_id= checkpoint_yolo.id,
checkpoint_filename='model_yolo.pt',
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
Przesyłanie przebiegu
AutoMLImageConfig Gdy obiekt jest gotowy, możesz przesłać eksperyment.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-image-object-detection")
automl_image_run = experiment.submit(automl_image_config)
Dane wyjściowe i metryki oceny
Przebiegi zautomatyzowanego trenowania uczenia maszynowego generują pliki modelu wyjściowego, metryki oceny, dzienniki i artefakty wdrożenia, takie jak plik oceniania i plik środowiska, który można wyświetlić z karty danych wyjściowych i dzienników i metryk przebiegów podrzędnych.
Napiwek
Sprawdź, jak przejść do wyników zadania w sekcji Wyświetlanie wyników przebiegu.
Aby zapoznać się z definicjami i przykładami wykresów wydajności i metryk podanych dla każdego przebiegu, zobacz Ocena wyników eksperymentu zautomatyzowanego uczenia maszynowego
Rejestrowanie i wdrażanie modelu
Po zakończeniu przebiegu można zarejestrować model, który został utworzony na podstawie najlepszego przebiegu (konfiguracja, która spowodowała najlepsze metryki podstawowe)
best_child_run = automl_image_run.get_best_child()
model_name = best_child_run.properties['model_name']
model = best_child_run.register_model(model_name = model_name, model_path='outputs/model.pt')
Po zarejestrowaniu modelu, którego chcesz użyć, możesz wdrożyć go jako usługę internetową w usłudze Azure Container Instances (ACI) lub Azure Kubernetes Service (AKS). Usługa ACI to idealna opcja testowania wdrożeń, a usługa AKS jest lepiej odpowiednia do użycia w środowisku produkcyjnym na dużą skalę.
W tym przykładzie model jest wdrażany jako usługa internetowa w usłudze AKS. Aby wdrożyć w usłudze AKS, najpierw utwórz klaster obliczeniowy usługi AKS lub użyj istniejącego klastra usługi AKS. Możesz użyć jednostek SKU maszyn wirtualnych procesora GPU lub procesora CPU dla klastra wdrażania.
from azureml.core.compute import ComputeTarget, AksCompute
from azureml.exceptions import ComputeTargetException
# Choose a name for your cluster
aks_name = "cluster-aks-gpu"
# Check to see if the cluster already exists
try:
aks_target = ComputeTarget(workspace=ws, name=aks_name)
print('Found existing compute target')
except ComputeTargetException:
print('Creating a new compute target...')
# Provision AKS cluster with GPU machine
prov_config = AksCompute.provisioning_configuration(vm_size="STANDARD_NC6",
location="eastus2")
# Create the cluster
aks_target = ComputeTarget.create(workspace=ws,
name=aks_name,
provisioning_configuration=prov_config)
aks_target.wait_for_completion(show_output=True)
Następnie możesz zdefiniować konfigurację wnioskowania, która opisuje sposób konfigurowania usługi internetowej zawierającej model. Możesz użyć skryptu oceniania i środowiska z przebiegu trenowania w konfiguracji wnioskowania.
from azureml.core.model import InferenceConfig
best_child_run.download_file('outputs/scoring_file_v_1_0_0.py', output_file_path='score.py')
environment = best_child_run.get_environment()
inference_config = InferenceConfig(entry_script='score.py', environment=environment)
Następnie możesz wdrożyć model jako usługę internetową usługi AKS.
# Deploy the model from the best run as an AKS web service
from azureml.core.webservice import AksWebservice
from azureml.core.webservice import Webservice
from azureml.core.model import Model
from azureml.core.environment import Environment
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
cpu_cores=1,
memory_gb=50,
enable_app_insights=True)
aks_service = Model.deploy(ws,
models=[model],
inference_config=inference_config,
deployment_config=aks_config,
deployment_target=aks_target,
name='automl-image-test',
overwrite=True)
aks_service.wait_for_deployment(show_output=True)
print(aks_service.state)
Alternatywnie możesz wdrożyć model z poziomu interfejsu użytkownika usługi Azure Machine Learning Studio. Przejdź do modelu, który chcesz wdrożyć na karcie Modele zautomatyzowanego uruchamiania uczenia maszynowego, a następnie wybierz pozycję Wdróż.
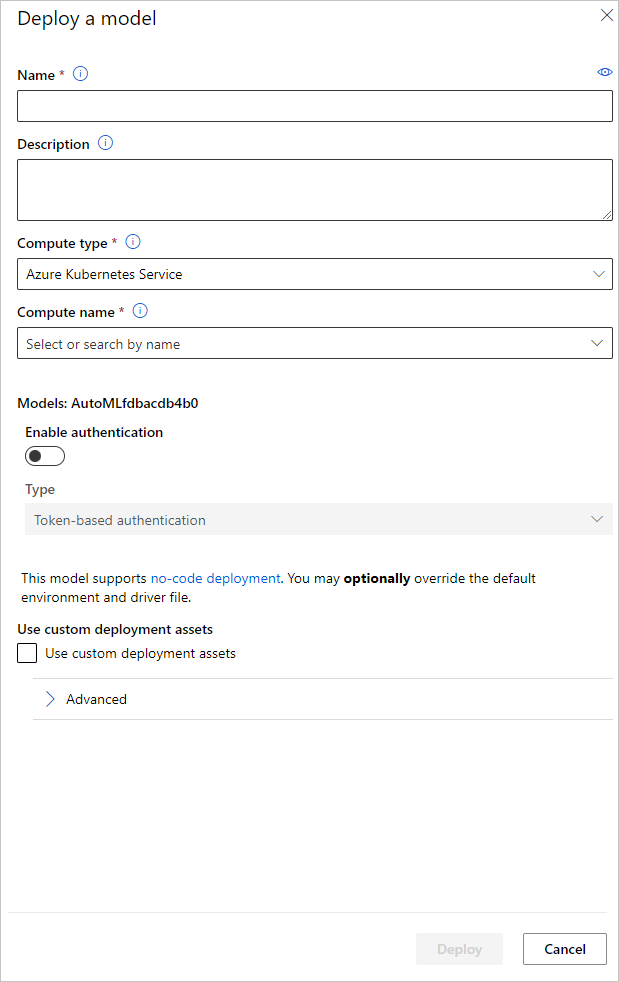
Nazwę punktu końcowego wdrożenia modelu i klaster wnioskowania można skonfigurować do użycia na potrzeby wdrożenia modelu w okienku Wdrażanie modelu .
Aktualizowanie konfiguracji wnioskowania
W poprzednim kroku pobraliśmy plik outputs/scoring_file_v_1_0_0.py oceniania z najlepszego modelu do pliku lokalnego score.py i użyliśmy go do utworzenia InferenceConfig obiektu. Ten skrypt można zmodyfikować, aby zmienić ustawienia wnioskowania określonego modelu, jeśli jest to konieczne po pobraniu i przed utworzeniem .InferenceConfig Na przykład jest to sekcja kodu, która inicjuje model w pliku oceniania:
...
def init():
...
try:
logger.info("Loading model from path: {}.".format(model_path))
model_settings = {...}
model = load_model(TASK_TYPE, model_path, **model_settings)
logger.info("Loading successful.")
except Exception as e:
logging_utilities.log_traceback(e, logger)
raise
...
Każde z zadań (i niektórych modeli) ma zestaw parametrów w słowniku model_settings . Domyślnie używamy tych samych wartości dla parametrów, które były używane podczas trenowania i walidacji. W zależności od zachowania, którego potrzebujemy podczas korzystania z modelu do wnioskowania, możemy zmienić te parametry. Poniżej znajduje się lista parametrów dla każdego typu zadania i modelu.
| Zadanie | Nazwa parametru | Wartość domyślna |
|---|---|---|
| Klasyfikacja obrazów (wiele klas i wiele etykiet) | valid_resize_sizevalid_crop_size |
256 224 |
| Wykrywanie obiektów | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0,3 0,5 100 |
Wykrywanie obiektów przy użyciu yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 Średni 0.1 0,5 |
| Segmentacja wystąpień | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0,3 0,5 100 0,5 100 Fałsz JPG |
Aby uzyskać szczegółowy opis hiperparametrów specyficznych dla zadań podrzędnych, zapoznaj się z hiperparametrami dotyczącymi zadań przetwarzania obrazów w zautomatyzowanym uczeniu maszynowym.
Jeśli chcesz użyć tilingu i chcesz kontrolować zachowanie tilingu, dostępne są następujące parametry: tile_grid_size, tile_overlap_ratio i tile_predictions_nms_thresh. Aby uzyskać więcej informacji na temat tych parametrów, zobacz Trenowanie małego modelu wykrywania obiektów przy użyciu rozwiązania AutoML.
Przykładowe notesy
Przejrzyj szczegółowe przykłady kodu i przypadki użycia w repozytorium notesów GitHub, aby zapoznać się z przykładami zautomatyzowanego uczenia maszynowego. Sprawdź foldery z prefiksem "image-" dla przykładów specyficznych dla tworzenia modeli przetwarzania obrazów.