Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Platforma Azure używa limitów przydziałów i limitów, aby zapobiec przekroczeniom budżetu z powodu oszustw i przestrzegać ograniczeń pojemności platformy Azure. Uwzględnij te limity podczas skalowania obciążeń produkcyjnych. Z tego artykułu dowiesz się więcej o:
- Domyślne limity zasobów platformy Azure związane z usługą Azure Machine Learning.
- Tworzenie przydziałów na poziomie obszaru roboczego.
- Wyświetlanie limitów przydziału i limitów.
- Żądanie zwiększenia limitu przydziału.
Oprócz zarządzania limitami przydziałów i limitami możesz dowiedzieć się, jak planować koszty usługi Azure Machine Learning i zarządzać nimi lub dowiedzieć się więcej o limitach usług w usłudze Azure Machine Learning.
Specjalne uwagi
Limity przydziału są stosowane do każdej subskrypcji na koncie. Jeśli masz wiele subskrypcji, musisz zażądać zwiększenia limitu przydziału dla każdej subskrypcji.
Limit przydziału to limit środków na zasoby platformy Azure, a nie gwarancja pojemności. Jeśli potrzebujesz wydajności w dużej skali, skontaktuj się z pomocą techniczną platformy Azure, aby zwiększyć limit przydziału.
Limit przydziału jest współdzielony we wszystkich usługach w Twoich subskrypcjach, włącznie z usługą Azure Machine Learning. Podczas oceniania wydajności oblicz użycie we wszystkich usługach.
Uwaga
Obliczenia w usłudze Azure Machine Learning są wyjątkiem. Mają one oddzielny limit przydziału od podstawowego limitu przydziału obliczeń.
Limity domyślne różnią się w zależności od typu kategorii ofert, takich jak bezpłatna wersja próbna, Standardowa i seria maszyn wirtualnych (np. Dv2, F i G).
Domyślne przydziały i limity zasobów
W tej sekcji dowiesz się więcej o domyślnych i maksymalnych limitach przydziału i limitach dla następujących zasobów:
- Zasoby usługi Azure Machine Learning
- Obliczenia usługi Azure Machine Learning (w tym bezserwerowa platforma Spark)
- Udostępniony limit przydziału usługi Azure Machine Learning
- Punkty końcowe online usługi Azure Machine Learning (zarządzane i Kubernetes) oraz punkty końcowe wsadowe
- Potoki usługi Azure Machine Learning
- Integracja usługi Azure Machine Learning z usługą Synapse
- Maszyny wirtualne
- Azure Container Instances (Instancje Kontenerów Azure)
- Azure Storage
Ważne
Limity mogą ulec zmianie. Aby uzyskać najnowsze informacje, zobacz Limity usług w usłudze Azure Machine Learning.
Zasoby usługi Azure Machine Learning
Następujące limity zasobów mają zastosowanie dla poszczególnych obszarów roboczych .
| Zasób | Limit maksymalny |
|---|---|
| Zestawy danych | 10 mln |
| Przebiegi | 10 mln |
| Modele | 10 mln |
| Składnik | 10 mln |
| Artefakty | 10 mln |
Ponadto maksymalny czas wykonywania wynosi 30 dni, a maksymalna liczba zarejestrowanych metryk na przebieg wynosi 1 milion.
Środowisko obliczeniowe usługi Azure Machine Learning
Usługa Azure Machine Learning Compute ma domyślny limit przydziału dla liczby rdzeni i liczby unikatowych zasobów obliczeniowych dozwolonych w poszczególnych regionach w ramach subskrypcji.
Uwaga
- Limit przydziału liczby rdzeni jest podzielony przez każdą rodzinę maszyn wirtualnych i łączną łączną liczbę rdzeni.
- Limit przydziału liczby unikatowych zasobów obliczeniowych na region jest oddzielony od limitu przydziału rdzeni maszyny wirtualnej, ponieważ dotyczy tylko zarządzanych zasobów obliczeniowych usługi Azure Machine Learning.
Aby zwiększyć limity dla następujących elementów, zażądaj zwiększenia limitu przydziału:
- Limity przydziału rdzeni rodziny maszyn wirtualnych. Aby dowiedzieć się więcej na temat rodziny maszyn wirtualnych, dla których należy zażądać zwiększenia limitu przydziału, zobacz Rozmiary maszyn wirtualnych na platformie Azure. Na przykład rodziny maszyn wirtualnych z procesorem GPU zaczynają się od "N" w nazwie rodziny (np. serii NCv3).
- Łączne limity przydziału rdzeni subskrypcji
- Limit przydziału klastra
- Inne zasoby w tej sekcji
Dostępne zasoby:
Rdzenie dedykowane dla poszczególnych regionów mają domyślny limit od 24 do 300, w zależności od typu oferty subskrypcji. Możesz zwiększyć liczbę rdzeni dedykowanych na subskrypcję dla każdej rodziny maszyn wirtualnych. Wyspecjalizowane rodziny maszyn wirtualnych, takie jak NCv2, NCv3 lub seria ND, zaczynają się od domyślnej liczby rdzeni zerowych. Procesory GPU również domyślnie mają zero rdzeni.
Rdzenie o niskim priorytecie dla poszczególnych regionów mają domyślny limit od 100 do 3000, w zależności od typu oferty subskrypcji. Liczbę rdzeni o niskim priorytecie na subskrypcję można zwiększyć i jest to jedna wartość dla wszystkich rodzin maszyn wirtualnych.
Łączny limit zasobów obliczeniowych na region ma domyślny limit 500 na region w ramach danej subskrypcji i można go zwiększyć do maksymalnej wartości 2500 na region. Limit ten jest współdzielony między klastrami szkoleniowymi, wystąpieniami środowiska obliczeniowego i wdrożeniami punktów końcowych zarządzanych online. Wystąpienie obliczeniowe jest uznawane za klaster z jednym węzłem na potrzeby limitu przydziału.
W poniższej tabeli przedstawiono więcej limitów na platformie. Skontaktuj się z zespołem produktu usługi Azure Machine Learning za pośrednictwem biletu pomocy technicznej, aby poprosić o wyjątek.
| Zasób lub akcja | Limit maksymalny |
|---|---|
| Obszary robocze na grupę zasobów | 800 |
| Węzły w jednym klastrze obliczeniowym usługi Azure Machine Learning (AmlCompute) skonfigurowane jako pula bez komunikacji (czyli nie można uruchamiać zadań MPI) | 100 węzłów, ale można skonfigurować do 65 000 węzłów |
| Węzły w jednym kroku przebiegu równoległego są uruchamiane w klastrze obliczeniowym usługi Azure Machine Learning (AmlCompute) | 100 węzłów, ale można skonfigurować do 65 000 węzłów, jeśli klaster został skonfigurowany do skalowania, jak wspomniano wcześniej |
| Węzły w jednym klastrze obliczeniowym usługi Azure Machine Learning (AmlCompute) skonfigurowane jako pula z obsługą komunikacji | 300 węzłów, ale można skonfigurować do 4000 węzłów |
| Węzły w jednym klastrze obliczeniowym usługi Azure Machine Learning (AmlCompute) skonfigurowane jako pula z obsługą komunikacji w rodzinie maszyn wirtualnych z włączoną funkcją RDMA | 100 węzłów |
| Węzły w jednym interfejsie MPI działają w klastrze obliczeniowym usługi Azure Machine Learning (AmlCompute) | 100 węzłów |
| Okres istnienia zadania | 21 dni1 |
| Okres istnienia zadania w węźle o niskim priorytcie | 7 dni2 |
| Serwery parametrów na węzeł | 1 |
1 Maksymalny okres istnienia to czas między rozpoczęciem zadania a zakończeniem. Ukończone zadania są utrwalane na czas nieokreślony. Dane zadań, które nie zostały ukończone w ciągu maksymalnego okresu istnienia, nie są dostępne.
2 Zadania w węźle o niskim priorytcie mogą zostać wywłaszczone za każdym razem, gdy występuje ograniczenie pojemności. Zalecamy zaimplementowanie punktów kontrolnych w zadaniu.
Udostępniony limit przydziału usługi Azure Machine Learning
Usługa Azure Machine Learning udostępnia udostępnioną pulę przydziałów, z której użytkownicy w różnych regionach mogą uzyskiwać dostęp do limitu przydziału w celu przeprowadzenia testów przez ograniczony czas, w zależności od dostępności. Określony czas trwania zależy od przypadku użycia. Tymczasowo korzystając z limitu przydziału z puli przydziałów, nie musisz już składać biletu pomocy technicznej na krótkoterminowy wzrost limitu przydziału lub poczekać na zatwierdzenie żądania przydziału, zanim będzie można kontynuować obciążenie.
Użycie udostępnionej puli przydziałów jest dostępne do uruchamiania zadań platformy Spark oraz do testowania wnioskowania dla llama-2, Phi, Nemotron, Mistral, Dolly i Deci-DeciLM z wykazu modeli przez krótki czas. Aby można było wdrożyć te modele za pośrednictwem udostępnionego limitu przydziału, musisz mieć subskrypcję Umowa Enterprise. Aby uzyskać więcej informacji na temat korzystania z udostępnionego limitu przydziału na potrzeby wdrażania punktów końcowych online, zobacz How to deploy foundation models using the studio (Jak wdrażać modele podstawowe przy użyciu programu Studio).
Udostępniony limit przydziału należy używać tylko do tworzenia tymczasowych punktów końcowych testów, a nie produkcyjnych punktów końcowych. W przypadku punktów końcowych w środowisku produkcyjnym należy zażądać dedykowanego limitu przydziału, tworząc bilet pomocy technicznej. Rozliczenia dotyczące przydziału współużytkowanego są oparte na użyciu, podobnie jak rozliczenia dla dedykowanych rodzin maszyn wirtualnych. Aby zrezygnować z przydziału współużytkowanego dla zadań platformy Spark, wypełnij formularz rezygnacji z alokacji pojemności udostępnionej usługi Azure Machine Learning.
Punkty końcowe online i punkty końcowe wsadowe usługi Azure Machine Learning
Punkty końcowe online i punkty końcowe wsadowe usługi Azure Machine Learning mają limity zasobów opisane w poniższej tabeli.
Ważne
Te limity są regionalne, co oznacza, że można użyć maksymalnie tych limitów dla każdego używanego regionu. Jeśli na przykład bieżący limit liczby punktów końcowych na subskrypcję wynosi 100, możesz utworzyć 100 punktów końcowych w regionie Wschodnie stany USA, 100 punktów końcowych w regionie Zachodnie stany USA i 100 punktów końcowych w każdym z pozostałych obsługiwanych regionów w jednej subskrypcji. Ta sama zasada ma zastosowanie do wszystkich pozostałych limitów.
Aby określić bieżące użycie punktu końcowego, wyświetl metryki.
Aby zażądać wyjątku od zespołu produktu Azure Machine Learning, wykonaj kroki opisane w temacie Zwiększanie limitu punktów końcowych.
| Zasób | Limit 1 | Zezwala na wyjątek | Dotyczy |
|---|---|---|---|
| Nazwa punktu końcowego | Nazwy punktów końcowych muszą |
- | Wszystkie typy punktów końcowych 3 |
| Nazwa wdrożenia | Nazwy wdrożeń muszą |
- | Wszystkie typy punktów końcowych 3 |
| Liczba punktów końcowych na subskrypcję | 100 | Tak | Wszystkie typy punktów końcowych 3 |
| Liczba punktów końcowych na klaster | 60 | - | Punkt końcowy online platformy Kubernetes |
| Liczba wdrożeń na subskrypcję | 500 | Tak | Wszystkie typy punktów końcowych 3 |
| Liczba wdrożeń na punkt końcowy | 20 | Tak | Wszystkie typy punktów końcowych 3 |
| Liczba wdrożeń na klaster | 100 | - | Punkt końcowy online platformy Kubernetes |
| Liczba wystąpień na wdrożenie | 50 4 | Tak | Zarządzany punkt końcowy online |
| Maksymalny limit czasu żądania na poziomie punktu końcowego | 180 sekund 5 | - | Zarządzany punkt końcowy online |
| Maksymalny limit czasu żądania na poziomie punktu końcowego | 300 sekund | - | Punkt końcowy online platformy Kubernetes |
| Łączna liczba żądań na sekundę na poziomie punktu końcowego dla wszystkich wdrożeń | 500 6 | Tak | Zarządzany punkt końcowy online |
| Łączna liczba połączeń na sekundę na poziomie punktu końcowego dla wszystkich wdrożeń | 500 6 | Tak | Zarządzany punkt końcowy online |
| Łączna liczba połączeń aktywnych na poziomie punktu końcowego dla wszystkich wdrożeń | 500 6 | Tak | Zarządzany punkt końcowy online |
| Łączna przepustowość na poziomie punktu końcowego dla wszystkich wdrożeń | 5 MB/ s 6 | Tak | Zarządzany punkt końcowy online |
1 Jest to limit regionalny. Jeśli na przykład bieżący limit liczby punktów końcowych wynosi 100, możesz utworzyć 100 punktów końcowych w regionie Wschodnie stany USA, 100 punktów końcowych w regionie Zachodnie stany USA i 100 punktów końcowych w każdym z pozostałych obsługiwanych regionów w jednej subskrypcji. Ta sama zasada ma zastosowanie do wszystkich pozostałych limitów.
2 Pojedyncze kreski, takie jak , my-endpoint-namesą akceptowane w nazwach punktów końcowych i wdrożeń.
3 Punkty końcowe i wdrożenia mogą być różne typy, ale limity mają zastosowanie do sumy wszystkich typów. Na przykład suma zarządzanych punktów końcowych online, punkt końcowy online platformy Kubernetes i punkt końcowy wsadowy w ramach każdej subskrypcji nie może domyślnie przekraczać 100 na region. Podobnie suma zarządzanych wdrożeń online, wdrożeń online platformy Kubernetes i wdrożeń wsadowych w ramach każdej subskrypcji nie może domyślnie przekraczać 500 na region.
4 Rezerwujemy 20% dodatkowych zasobów obliczeniowych na potrzeby przeprowadzania uaktualnień. Jeśli na przykład zażądasz 10 wystąpień we wdrożeniu, musisz mieć limit przydziału dla 12. W przeciwnym razie zostanie wyświetlony błąd. Istnieją pewne jednostki SKU maszyn wirtualnych, które są zwolnione z dodatkowego limitu przydziału. Aby uzyskać więcej informacji na temat alokacji przydziału, zobacz Alokacja przydziału maszyn wirtualnych dla wdrożenia.
5 Maksymalny limit czasu żądania wynosi 180 sekund, chyba że jest to wdrożenie przepływu (przepływ monitu). Maksymalny limit czasu żądania dla wdrożenia przepływu wynosi 300 sekund. Aby uzyskać więcej informacji na temat limitu czasu wdrożeń przepływu, zobacz wdrażanie przepływu w przepływie monitu.
6 Żądań na sekundę, połączenia, przepustowość itp. są powiązane. Jeśli poprosisz o zwiększenie dowolnego z tych limitów, upewnij się, że szacujesz/obliczasz inne powiązane limity razem.
Alokacja przydziału maszyny wirtualnej na potrzeby wdrożenia
W przypadku zarządzanych punktów końcowych online usługa Azure Machine Learning rezerwuje 20% zasobów obliczeniowych na potrzeby przeprowadzania uaktualnień na niektórych jednostkach SKU maszyn wirtualnych. Jeśli żądasz określonej liczby wystąpień dla tych jednostek SKU maszyny wirtualnej we wdrożeniu, musisz mieć limit przydziału ceil(1.2 * number of instances requested for deployment) * number of cores for the VM SKU dostępny, aby uniknąć wystąpienia błędu. Jeśli na przykład zażądasz 10 wystąpień maszyny wirtualnej Standard_DS3_v2 (która jest dostarczana z czterema rdzeniami) we wdrożeniu, musisz mieć limit przydziału dla 48 rdzeni (12 instances * 4 cores) dostępnych. Ten dodatkowy limit przydziału jest zarezerwowany dla operacji inicjowanych przez system, takich jak uaktualnienia systemu operacyjnego i odzyskiwanie maszyny wirtualnej, i nie będzie ponosić kosztów, chyba że takie operacje zostaną uruchomione.
Istnieją pewne jednostki SKU maszyn wirtualnych, które są zwolnione z dodatkowego limitu przydziału rezerwacji. Aby wyświetlić pełną listę, zobacz Lista jednostek SKU zarządzanych punktów końcowych online. Aby wyświetlić wzrost użycia i limitu przydziału żądań, zobacz Wyświetlanie użycia i limitów przydziału w witrynie Azure Portal. Aby wyświetlić koszt uruchamiania zarządzanego punktu końcowego online, zobacz Wyświetlanie kosztów zarządzanego punktu końcowego online.
Potoki usługi Azure Machine Learning
Potoki usługi Azure Machine Learning mają następujące limity.
| Zasób | Ograniczenie |
|---|---|
| Etapy potoku | 30,000 |
| Obszary robocze na grupę zasobów | 800 |
Integracja usługi Azure Machine Learning z usługą Synapse
Bezserwerowa platforma Spark w usłudze Azure Machine Learning zapewnia łatwy dostęp do funkcji przetwarzania rozproszonego na potrzeby skalowania zadań platformy Apache Spark. Bezserwerowa platforma Spark korzysta z tego samego dedykowanego limitu przydziału co usługa Azure Machine Learning Compute. Limity przydziału można zwiększyć, przesyłając bilet pomocy technicznej i żądając zwiększenia limitu przydziału i limitu dla serii ESv3 w kategorii "Machine Learning Service: Limit przydziału maszyny wirtualnej".
Aby wyświetlić użycie limitu przydziału, przejdź do usługi Machine Learning Studio i wybierz nazwę subskrypcji, dla której chcesz wyświetlić użycie. Wybierz pozycję "Limit przydziału" w panelu po lewej stronie.

Maszyny wirtualne
Każda subskrypcja platformy Azure ma limit liczby maszyn wirtualnych we wszystkich usługach. Rdzenie maszyn wirtualnych mają regionalny limit całkowity i limit regionalny na serię rozmiarów. Oba limity są wymuszane oddzielnie.
Rozważmy na przykład subskrypcję z całkowitym limitem rdzeni maszyn wirtualnych dla regionu Wschodnie stany USA wynoszącym 30, limitem rdzeni dla serii A wynoszącym 30 i limitem rdzeni dla serii D wynoszącym 30. Ta subskrypcja może wdrażać 30 maszyn wirtualnych A1 lub 30 maszyn wirtualnych D1 albo kombinację tych dwóch, które nie przekraczają łącznie 30 rdzeni.
Nie można podnieść limitów dla maszyn wirtualnych powyżej wartości przedstawionych w poniższej tabeli.
| Zasób | Ograniczenie |
|---|---|
| Subskrypcje platformy Azure skojarzone z dzierżawą firmy Microsoft Entra | Nieograniczony |
| Współadministratorzy na subskrypcję | Nieograniczony |
| Grupy zasobów na subskrypcję | 980 |
| Rozmiar żądania interfejsu API usługi Azure Resource Manager | 4 194 304 bajty |
| Tagi na subskrypcję1 | 50 |
| Unikatowe obliczenia tagów na subskrypcję2 | 80 000 |
| Wdrożenia na poziomie subskrypcji na lokalizację | 8003 |
| Lokalizacje wdrożeń na poziomie subskrypcji | 10 |
1Do subskrypcji można zastosować maksymalnie 50 tagów. W ramach subskrypcji każdy zasób lub grupa zasobów jest również ograniczony do 50 tagów. Jednak subskrypcja może zawierać nieograniczoną liczbę tagów rozproszonych między zasobami i grupami zasobów.
2Usługa Resource Manager zwraca listę nazw tagów i wartości w subskrypcji tylko wtedy, gdy liczba unikatowych tagów wynosi 80 000 lub mniej. Unikatowy tag jest definiowany przez kombinację identyfikatora zasobu, nazwy tagu i wartości tagu. Na przykład dwa zasoby o tej samej nazwie tagu i wartości zostaną obliczone jako dwa unikatowe tagi. Nadal możesz znaleźć zasób według tagu, gdy liczba przekracza 80 000.
3Wdrożenia są automatycznie usuwane z historii, gdy zbliżasz się do limitu. Aby uzyskać więcej informacji, zobacz Automatyczne usuwanie z historii wdrożenia.
Instancje kontenera
Aby uzyskać więcej informacji, zobacz Container Instances limits (Limity wystąpień kontenera).
Przechowywanie danych
Usługa Azure Storage ma limit 250 kont magazynu na region, na subskrypcję. Ten limit obejmuje zarówno konta magazynu w warstwie Standardowa, jak i Premium.
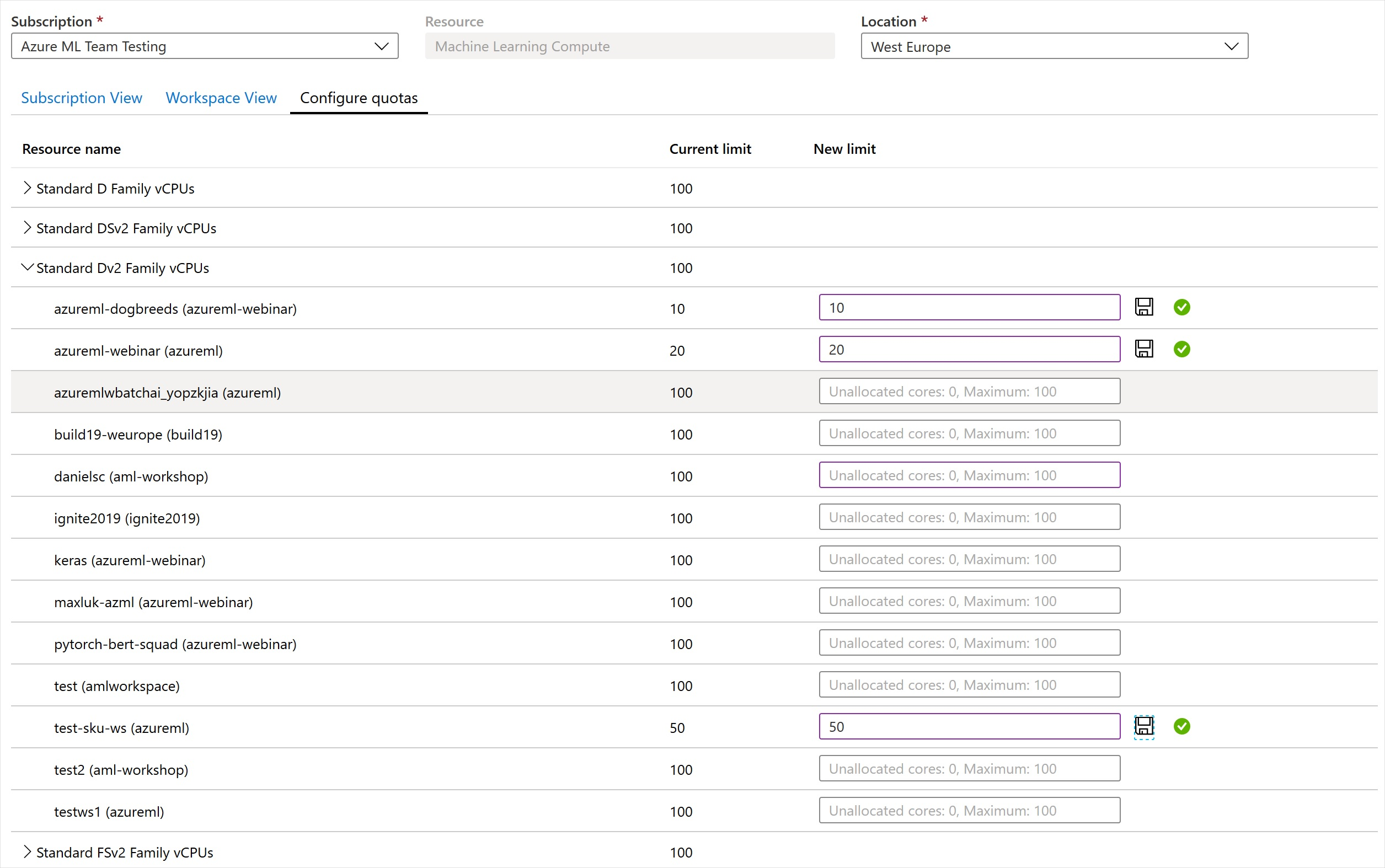
Limity przydziału na poziomie obszaru roboczego
Użyj limitów przydziałów na poziomie obszaru roboczego, aby zarządzać docelowym przydziałem zasobów obliczeniowych usługi Azure Machine Learning między wieloma obszarami roboczymi w ramach tej samej subskrypcji.
Domyślnie wszystkie obszary robocze mają taki sam limit przydziału jak limit przydziału na poziomie subskrypcji dla rodzin maszyn wirtualnych. Można jednak ustawić maksymalny limit przydziału dla poszczególnych rodzin maszyn wirtualnych w obszarach roboczych w subskrypcji. Limity przydziału dla poszczególnych rodzin maszyn wirtualnych umożliwiają współużytkowanie wydajności i unikanie problemów z rywalizacją o zasoby.
- Przejdź do dowolnego obszaru roboczego w subskrypcji.
- W lewym okienku wybierz pozycję Użycie + limity przydziału.
- Wybierz kartę Konfigurowanie limitów przydziałów, aby wyświetlić limity przydziałów.
- Rozwiń rodzinę maszyn wirtualnych.
- Ustaw limit przydziału dla dowolnego obszaru roboczego wymienionego w tej rodzinie maszyn wirtualnych.
Nie można ustawić wartości ujemnej ani wartości wyższej niż limit przydziału na poziomie subskrypcji.
Uwaga
Musisz mieć uprawnienia na poziomie subskrypcji, aby ustawić limit przydziału na poziomie obszaru roboczego.
Wyświetlanie limitów przydziału w programie Studio
Podczas tworzenia nowego zasobu obliczeniowego domyślnie widoczne są tylko rozmiary maszyn wirtualnych, których już używasz. Przełącz widok na Wybierz ze wszystkich opcji.
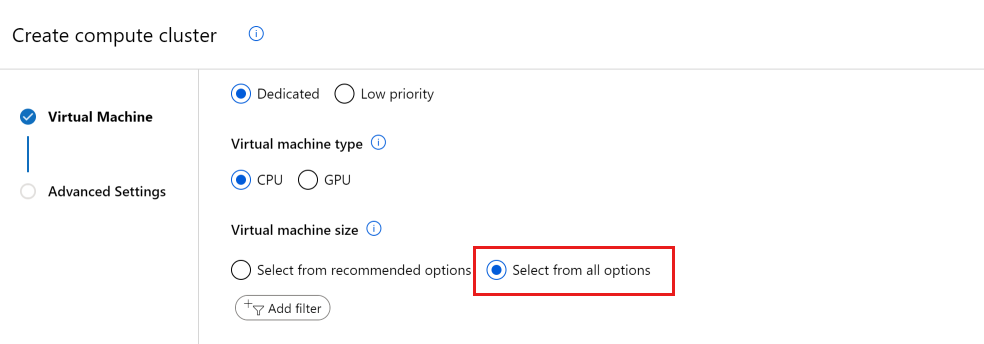
Przewiń w dół, aż zostanie wyświetlona lista rozmiarów maszyn wirtualnych, dla których nie masz limitu przydziału.
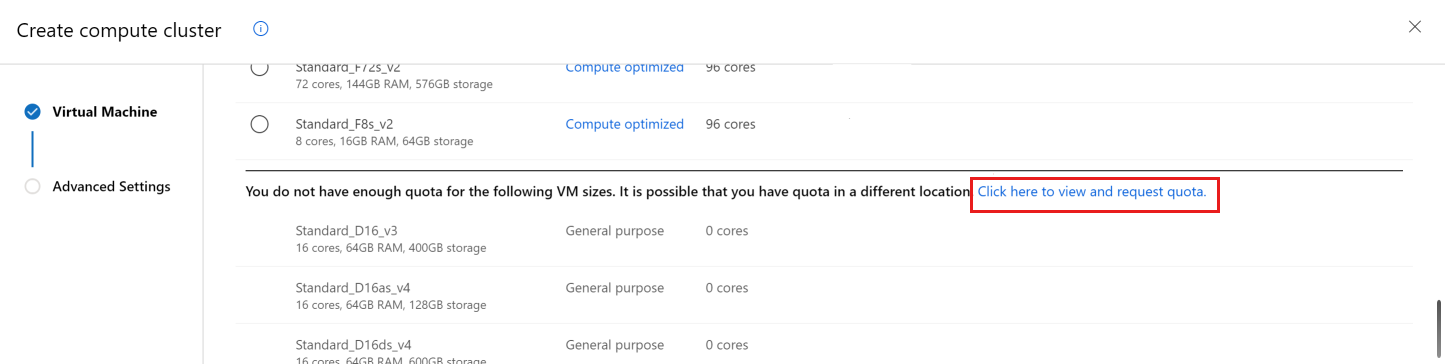
Użyj linku, aby przejść bezpośrednio do żądania pomocy technicznej online w celu uzyskania większego limitu przydziału.
Wyświetlanie użycia i limitów przydziału w witrynie Azure Portal
Aby wyświetlić limit przydziału dla różnych zasobów platformy Azure, takich jak maszyny wirtualne, magazyn lub sieć, użyj witryny Azure Portal:
W okienku po lewej stronie wybierz pozycję Wszystkie usługi , a następnie wybierz pozycję Subskrypcje w kategorii Ogólne .
Z listy subskrypcji wybierz subskrypcję, której limit przydziału szukasz.
Wybierz pozycję Użycie i limity przydziału , aby wyświetlić bieżące limity przydziału i użycie. Użyj filtrów, aby wybrać dostawcę i lokalizacje.
Limit przydziału zasobów obliczeniowych usługi Azure Machine Learning można zarządzać w ramach subskrypcji niezależnie od innych przydziałów platformy Azure:
Przejdź do obszaru roboczego usługi Azure Machine Learning w witrynie Azure Portal.
W okienku po lewej stronie w sekcji Pomoc techniczna i rozwiązywanie problemów wybierz pozycję Użycie i limity przydziału , aby wyświetlić bieżące limity przydziału i użycie.
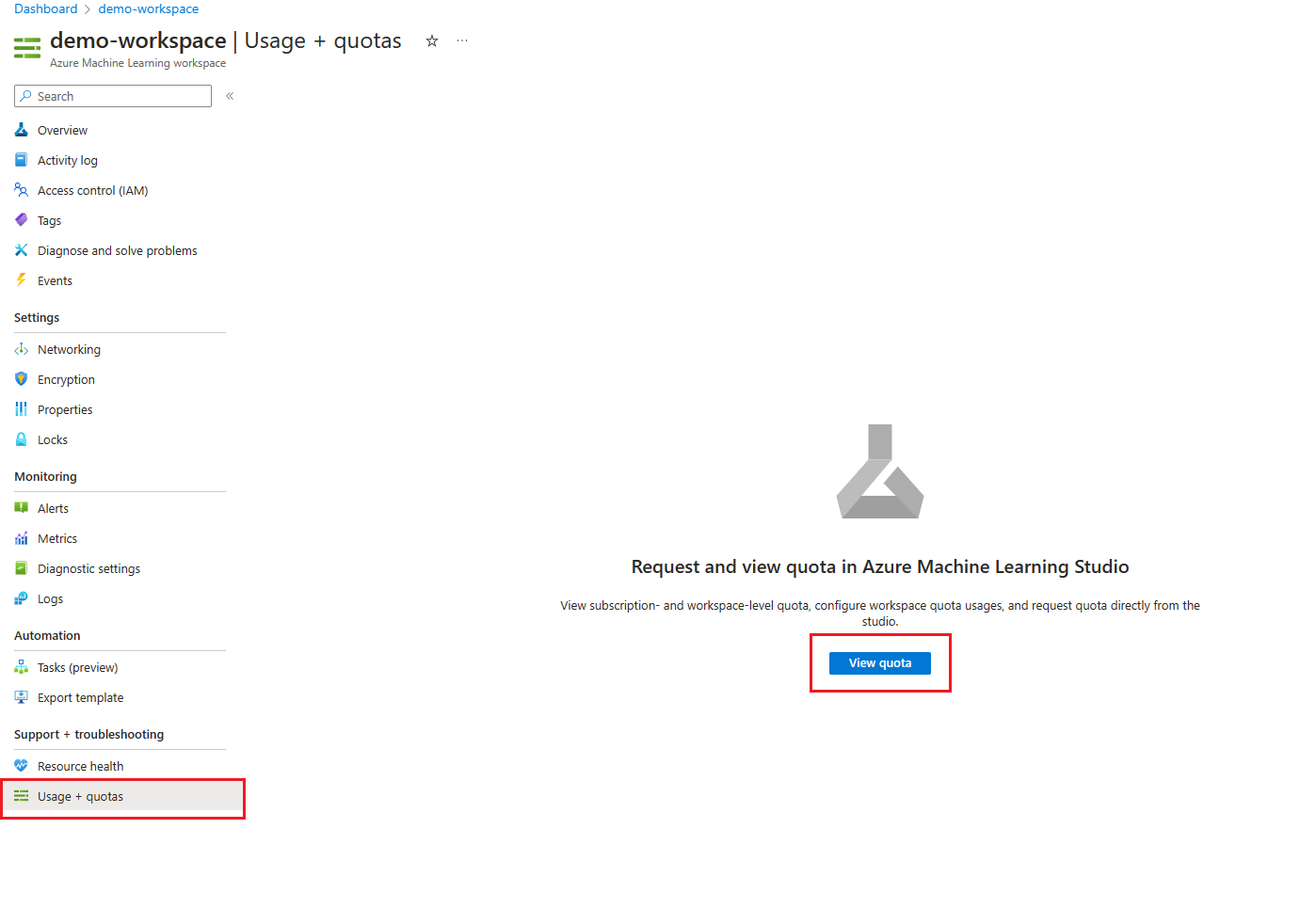
Wybierz subskrypcję, aby wyświetlić limity przydziału. Odfiltruj region, w którym cię interesujesz.
Możesz przełączać się między widokiem na poziomie subskrypcji a widokiem na poziomie obszaru roboczego.
Zażądaj zwiększenia limitów i przydziału
Zwiększenie limitu przydziału maszyn wirtualnych polega na zwiększeniu liczby rdzeni na rodzinę maszyn wirtualnych na region. Zwiększenie limitu punktów końcowych polega na zwiększeniu limitów specyficznych dla punktu końcowego na subskrypcję na region. Pamiętaj, aby wybrać odpowiednią kategorię podczas przesyłania żądania zwiększenia limitu przydziału zgodnie z opisem w następnej sekcji.
Zwiększenie limitu przydziału maszyny wirtualnej
Aby zwiększyć limit przydziału maszyn wirtualnych usługi Azure Machine Learning powyżej domyślnego limitu, możesz zażądać zwiększenia limitu przydziału z powyższego widoku Użycie i przydziały lub przesłać żądanie zwiększenia limitu przydziału z usługi Azure Machine Learning Studio.
Przejdź do strony Użycie + przydziały, postępując zgodnie z instrukcjami powyżej. Wyświetl bieżące limity przydziału. Wybierz jednostkę SKU, dla której chcesz zażądać zwiększenia.
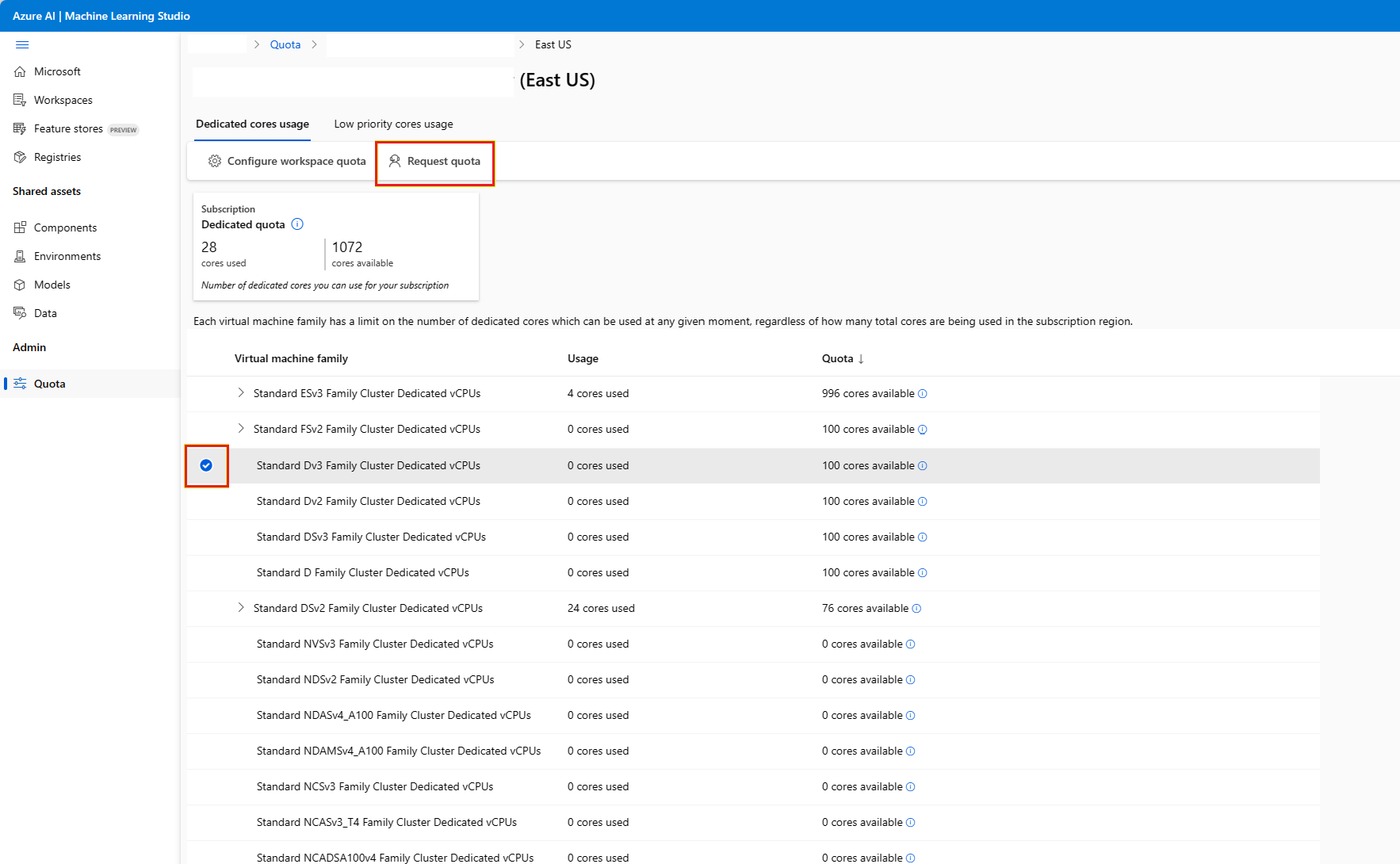
Podaj limit przydziału, który chcesz zwiększyć, oraz nową wartość limitu. Na koniec wybierz pozycję Prześlij, aby kontynuować.
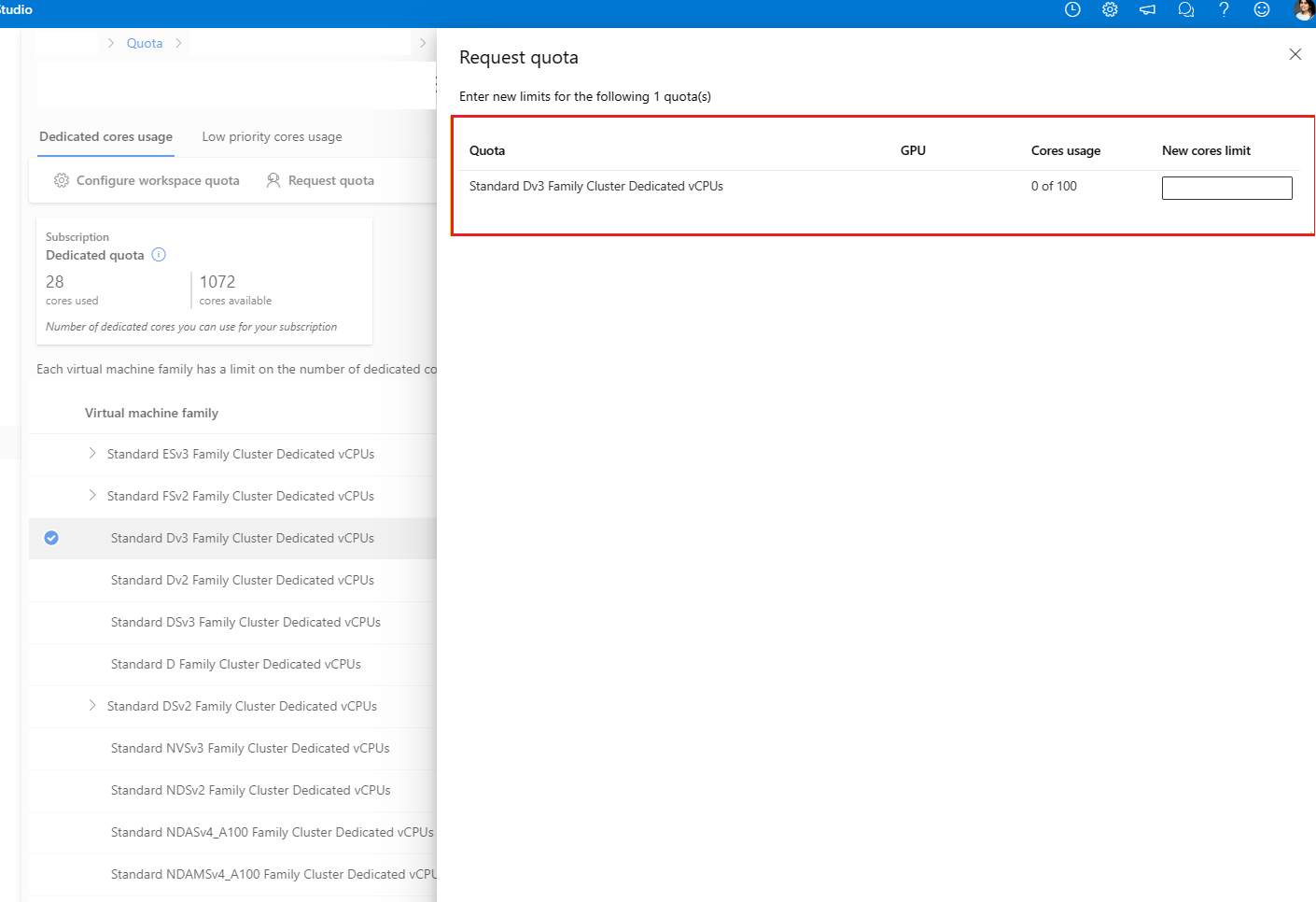
Zwiększenie limitu punktów końcowych
Aby zwiększyć limit punktów końcowych, otwórz wniosek o pomoc techniczną online. Podczas żądania zwiększenia limitu punktu końcowego podaj następujące informacje:
Podczas otwierania wniosku o pomoc techniczną wybierz pozycję Limity usługi i subskrypcji (limity przydziału) jako Typ problemu.
Wybierz subskrypcję.
Wybierz pozycję Usługa Machine Learning: limity punktów końcowych jako Typ limitu przydziału.
Na karcie Dodatkowe szczegóły podaj szczegółowe informacje dotyczące przyczyn zwiększenia limitu, aby umożliwić przetworzenie żądania. Wybierz pozycję Wprowadź szczegóły, a następnie podaj limit przydziału, który chcesz zwiększyć, oraz nowe wartości poszczególnych limitów, przyczynę żądania zwiększenia limitu przydziału i lokalizacje, w których potrzebujesz zwiększenia limitu przydziału. Podając przyczynę zwiększenia limitu, koniecznie uwzględnij następujące informacje:
- Opis scenariusza i obciążenia (na przykład tekst, obraz itd.).
- Uzasadnienie żądanego zwiększenia.
- Podaj docelową przepływność i jej wzorzec (średnia/szczytowa liczba zapytań na sekundę, równocześni użytkownicy).
- Podaj opóźnienie docelowe na dużą skalę i bieżące opóźnienie obserwowane w przypadku jednego wystąpienia.
- Podaj łączną liczbę wystąpień i jednostek SKU maszyn wirtualnych wymaganych do obsługi docelowej przepływność i opóźnienia. Podaj liczbę punktów końcowych/wdrożeń/wystąpień, które mają być używane w każdym regionie.
- Potwierdź, czy masz test porównawczy wskazujący, że wybrana jednostka SKU maszyny wirtualnej i liczba wystąpień spełnia wymagania dotyczące przepływności i opóźnień.
- Podaj typ ładunku i rozmiar pojedynczego ładunku. Przepustowość sieci powinna być zgodna z rozmiarem ładunku i żądaniami na sekundę.
- Podaj zaplanowany plan czasu (jeśli potrzebujesz zwiększonych limitów — podaj plan etapowy, jeśli to możliwe) i sprawdź, (1) czy koszt jego działania w tej skali jest odzwierciedlony w budżecie i (2) czy docelowe jednostki SKU maszyn wirtualnych zostaną zatwierdzone.
Na koniec wybierz pozycję Zapisz i kontynuuj, aby kontynuować.
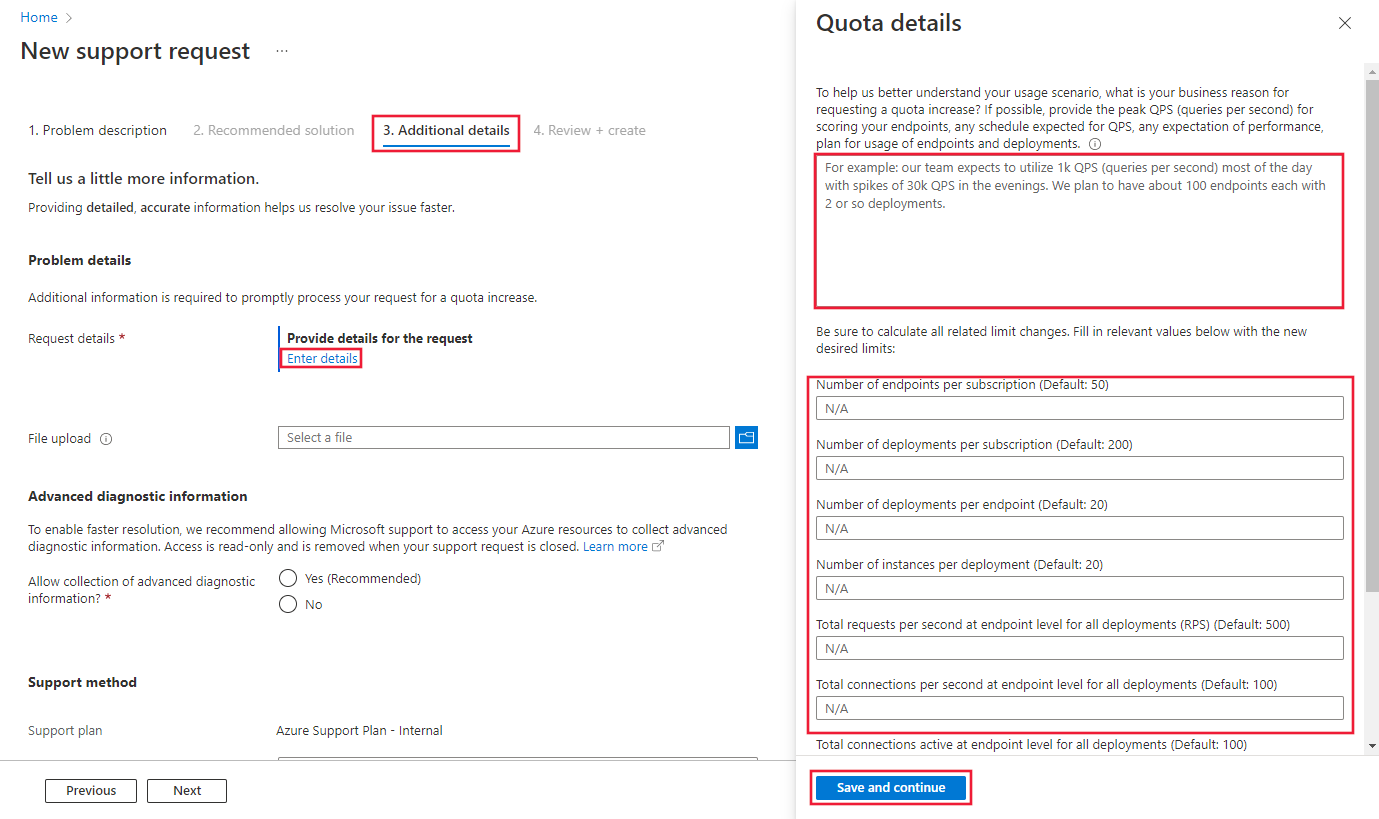
Uwaga
To żądanie zwiększenia limitu punktu końcowego różni się od żądania zwiększenia limitu przydziału maszyny wirtualnej. Jeśli Twoje żądanie jest związane ze zwiększeniem limitu przydziału maszyn wirtualnych, postępuj zgodnie z instrukcjami podanymi w sekcji Zwiększanie limitu przydziału maszyn wirtualnych.
Zwiększenie limitu zasobów obliczeniowych
Aby zwiększyć całkowity limit zasobów obliczeniowych, otwórz wniosek o pomoc techniczną online. Podaj poniższe informacje:
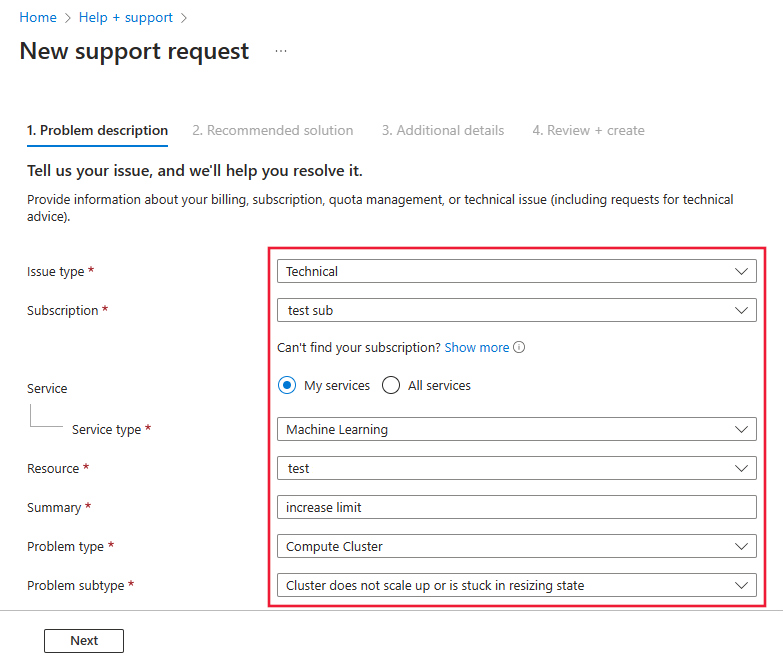
Podczas otwierania wniosku o pomoc techniczną wybierz Techniczny jako Typ problemu.
Wybierz subskrypcję
Wybierz Uczenie maszynowe jako Usługę.
Wybierz zasób
W podsumowaniu uwzględnij informację „Zwiększ łączne limity zasobów obliczeniowych”
Wybierz Klaster obliczeniowy jako Typ problemu oraz Klaster nie skaluje się w górę lub jest zablokowany w trybie zmiany rozmiaru jako Podtyp problemu.
Na karcie Dodatkowe szczegóły podaj identyfikator subskrypcji, region, nowy limit (od 500 do 2500) i uzasadnienie biznesowe, jeśli chcesz zwiększyć łączne limity zasobów obliczeniowych w tym regionie.
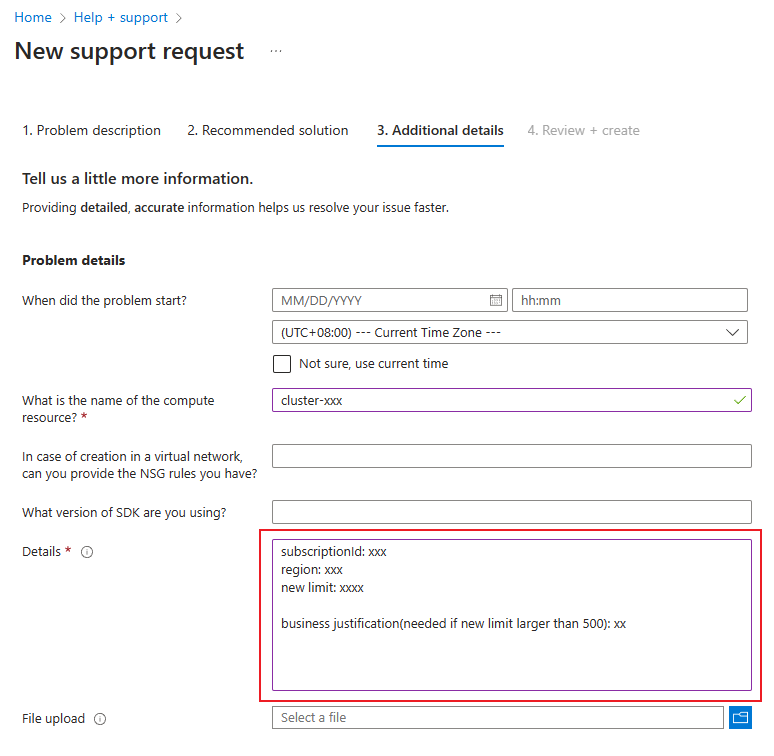
Na koniec wybierz pozycję Utwórz, aby utworzyć bilet wniosku o pomoc techniczną.