Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: SDK v1 usługi Azure Machine Learning dla języka Python
SDK v1 usługi Azure Machine Learning dla języka Python
Ważne
Ten artykuł zawiera informacje na temat korzystania z zestawu Azure Machine Learning SDK w wersji 1. Zestaw SDK w wersji 1 jest przestarzały od 31 marca 2025 r. Wsparcie dla niego zakończy się 30 czerwca 2026 r. Do tej pory można zainstalować zestaw SDK w wersji 1 i używać go. Istniejące przepływy pracy korzystające z zestawu SDK w wersji 1 będą nadal działać po dacie zakończenia pomocy technicznej. Mogą one jednak być narażone na zagrożenia bezpieczeństwa lub niespójności w przypadku zmian architektury w produkcie.
Zalecamy przejście do zestawu SDK w wersji 2 przed 30 czerwca 2026 r. Aby uzyskać więcej informacji na temat zestawu SDK w wersji 2, zobacz Co to jest interfejs wiersza polecenia usługi Azure Machine Learning i zestaw Python SDK w wersji 2? oraz dokumentacja zestawu SDK w wersji 2.
Dryf danych (wersja zapoznawcza) zostanie wycofany pod numerem 09/01/2025 i można rozpocząć korzystanie z monitora modelu na potrzeby zadań dryfu danych. Zapoznaj się z poniższą zawartością, aby zrozumieć zastąpienie, luki funkcji i ręczne kroki zmiany.
Dowiedz się, jak monitorować dryf danych i ustawiać alerty, gdy dryf jest wysoki.
Uwaga
Monitorowanie modelu usługi Azure Machine Learning (wersja 2) zapewnia ulepszone możliwości dryfu danych wraz z dodatkowymi funkcjami monitorowania sygnałów i metryk. Aby dowiedzieć się więcej na temat możliwości monitorowania modeli w usłudze Azure Machine Learning (wersja 2), zobacz Monitorowanie modelu za pomocą usługi Azure Machine Learning.
Za pomocą monitorów zestawu danych usługi Azure Machine Learning (wersja zapoznawcza) można wykonywać następujące czynności:
- Przeanalizuj dryf danych, aby dowiedzieć się, jak zmieniają się one w czasie.
- Monitorowanie danych modelu pod kątem różnic między trenowania i obsługi zestawów danych. Zacznij od zebrania danych modelu z wdrożonych modeli.
- Monitoruj nowe dane pod kątem różnic między dowolnym punktem odniesienia i docelowym zestawem danych.
- Funkcje profilu w danych umożliwiają śledzenie zmian właściwości statystycznych w czasie.
- Skonfiguruj alerty dotyczące dryfu danych, aby wczesne ostrzeżenia dotyczyły potencjalnych problemów.
- Utwórz nową wersję zestawu danych, gdy określisz, że dane dryfowały zbyt wiele.
Zestaw danych usługi Azure Machine Learning służy do tworzenia monitora. Zestaw danych musi zawierać kolumnę znacznika czasu.
Metryki dryfu danych można wyświetlać za pomocą zestawu SDK języka Python lub w usłudze Azure Machine Learning Studio. Inne metryki i szczegółowe informacje są dostępne za pośrednictwem zasobu aplikacja systemu Azure Insights skojarzonego z obszarem roboczym usługi Azure Machine Learning.
Ważne
Wykrywanie dryfu danych dla zestawów danych jest obecnie dostępne w publicznej wersji zapoznawczej. Wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie jest zalecana w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Wymagania wstępne
Aby utworzyć monitory zestawu danych i pracować z tym zestawem danych, potrzebne są następujące elementy:
- Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto. Wypróbuj bezpłatną lub płatną wersję usługi Azure Machine Learning już dziś.
- Obszar roboczy usługi Azure Machine Learning.
- Zainstalowany zestaw SDK usługi Azure Machine Learning dla języka Python, który zawiera pakiet azureml-datasets.
- Dane ustrukturyzowane (tabelaryczne) z sygnaturą czasową określoną w ścieżce pliku, nazwie pliku lub kolumnie w danych.
Wymagania wstępne (migrowanie do monitora modelu)
Podczas migracji do monitora modelu sprawdź wymagania wstępne, jak wspomniano w tym artykule Wymagania wstępne monitorowania modelu usługi Azure Machine Learning.
Co to jest dryf danych?
Dokładność modelu spada w czasie, głównie z powodu dryfu danych. W przypadku modeli uczenia maszynowego dryf danych to zmiana danych wejściowych modelu, która prowadzi do obniżenia wydajności modelu. Monitorowanie dryfu danych pomaga wykrywać te problemy z wydajnością modelu.
Przyczyny dryfu danych obejmują:
- Zmiany procesów nadrzędnych, takie jak wymiana czujnika, który zmienia jednostki miary od cali do centymetrów.
- Problemy z jakością danych, takie jak uszkodzony czujnik, zawsze odczyt 0.
- Naturalny dryf danych, taki jak średnia temperatura zmienia się wraz z sezonami.
- Zmiana relacji między funkcjami lub kowariantna zmiana.
Usługa Azure Machine Learning upraszcza wykrywanie dryfu przez obliczenie pojedynczej metryki abstrakcyjnej złożoności porównywanych zestawów danych. Te zestawy danych mogą zawierać setki funkcji i dziesiątki tysięcy wierszy. Po wykryciu dryfu przejdź do szczegółów, które funkcje powodują dryf. Następnie należy sprawdzić metryki na poziomie funkcji, aby debugować i izolować główną przyczynę dryfu.
Takie podejście od góry ułatwia monitorowanie danych zamiast tradycyjnych technik opartych na regułach. Techniki oparte na regułach, takie jak dozwolony zakres danych lub dozwolone wartości unikatowe, mogą być czasochłonne i podatne na błędy.
W usłudze Azure Machine Learning monitory zestawów danych służą do wykrywania i zgłaszania alertów dotyczących dryfu danych.
Monitory zestawu danych
Za pomocą monitora zestawu danych można wykonywać następujące czynności:
- Wykrywanie dryfu danych i zgłaszanie alertów dotyczących nowych danych w zestawie danych.
- Analizowanie danych historycznych pod kątem dryfu.
- Profilowanie nowych danych w czasie.
Algorytm dryfu danych zapewnia ogólną miarę zmian w danych i wskazanie, które funkcje są odpowiedzialne za dalsze badanie. Monitory zestawu danych generują wiele innych metryk przez profilowanie nowych danych w timeseries zestawie danych.
Niestandardowe alerty można skonfigurować dla wszystkich metryk generowanych przez monitor za pośrednictwem usługi aplikacja systemu Azure Insights. Monitory zestawu danych mogą służyć do szybkiego przechwytywania problemów z danymi i skrócenia czasu debugowania problemu, identyfikując prawdopodobne przyczyny.
Koncepcyjnie istnieją trzy podstawowe scenariusze konfigurowania monitorów zestawów danych w usłudze Azure Machine Learning.
| Scenariusz | opis |
|---|---|
| Monitorowanie obsługi danych modelu pod kątem dryfu z danych treningowych | Wyniki z tego scenariusza można interpretować jako monitorowanie serwera proxy dokładności modelu, ponieważ dokładność modelu spada, gdy dane obsługujące dryfują od danych treningowych. |
| Monitorowanie zestawu danych szeregów czasowych pod kątem dryfu z poprzedniego okresu. | Ten scenariusz jest bardziej ogólny i może służyć do monitorowania zestawów danych związanych z nadrzędnym lub podrzędnym tworzeniem modelu. Docelowy zestaw danych musi mieć kolumnę znacznika czasu. Zestaw danych odniesienia może być dowolnym tabelarycznym zestawem danych, który ma funkcje wspólne z docelowym zestawem danych. |
| Przeprowadź analizę przeszłych danych. | Ten scenariusz może służyć do zrozumienia danych historycznych i informowania decyzji w ustawieniach monitorów zestawu danych. |
Monitory zestawów danych zależą od następujących usług platformy Azure.
| Usługa platformy Azure | opis |
|---|---|
| Dataset | Drift używa zestawów danych usługi Machine Learning do pobierania danych treningowych i porównywania danych na potrzeby trenowania modelu. Generowanie profilu danych służy do generowania niektórych zgłoszonych metryk, takich jak minimalna, maksymalna, unikatowa wartość, liczba unikatowych wartości. |
| Potok i obliczenia usługi Azure Machine Learning | Zadanie obliczania dryfu jest hostowane w potoku usługi Azure Machine Learning. Zadanie jest wyzwalane na żądanie lub zgodnie z harmonogramem, aby było uruchamiane na obliczeniach skonfigurowanych w czasie tworzenia monitora dryfu. |
| Szczegółowe dane dotyczące aplikacji | Drift emituje metryki do usługi Application Insights należącej do obszaru roboczego uczenia maszynowego. |
| Azure Blob Storage | Drift emituje metryki w formacie JSON do usługi Azure Blob Storage. |
Zestawy danych według planu bazowego i docelowego
Monitorujesz zestawy danych usługi Azure Machine Learning pod kątem dryfu danych. Podczas tworzenia monitora zestawu danych odwołujesz się do:
- Zestaw danych punktu odniesienia — zazwyczaj zestaw danych trenowania dla modelu.
- Docelowy zestaw danych — zazwyczaj dane wejściowe modelu — jest porównywany z czasem do bazowego zestawu danych. To porównanie oznacza, że docelowy zestaw danych musi mieć określoną kolumnę znacznika czasu.
Monitor porównuje zestawy danych odniesienia i docelowych.
Migrowanie do monitora modelu
W monitorze modelu można znaleźć odpowiednie pojęcia w następujący sposób. Więcej szczegółów można znaleźć w tym artykule Konfigurowanie monitorowania modelu, wprowadzając dane produkcyjne do usługi Azure Machine Learning:
- Zestaw danych referencyjnych: podobny do zestawu danych odniesienia do wykrywania dryfu danych, jest ustawiony jako ostatni zestaw danych wnioskowania produkcyjnego.
- Dane wnioskowania produkcyjnego: podobnie jak docelowy zestaw danych w wykrywaniu dryfu danych, dane wnioskowania produkcyjnego można zbierać automatycznie z modeli wdrożonych w środowisku produkcyjnym. Może to być również dane wnioskowania przechowywane przez Ciebie.
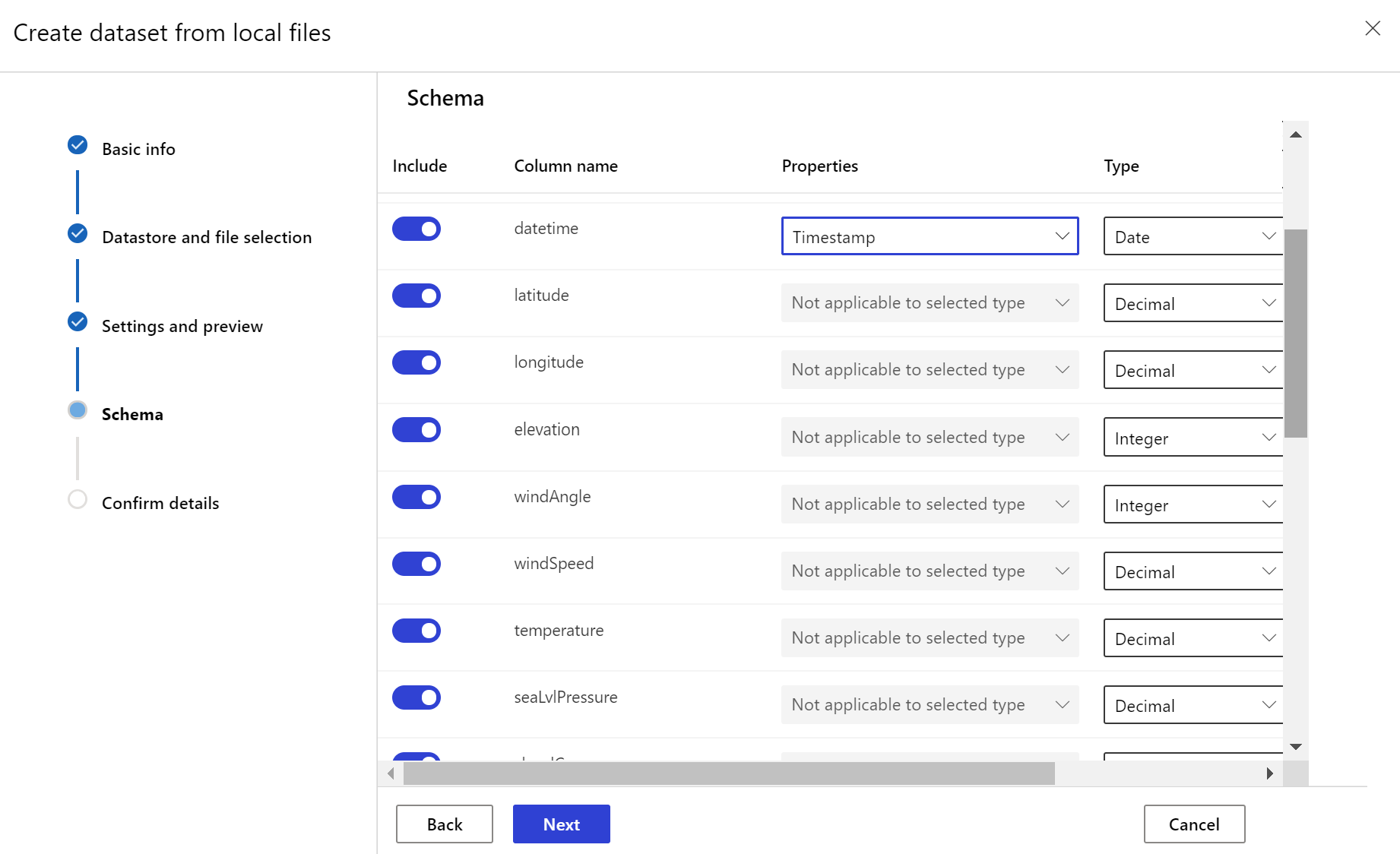
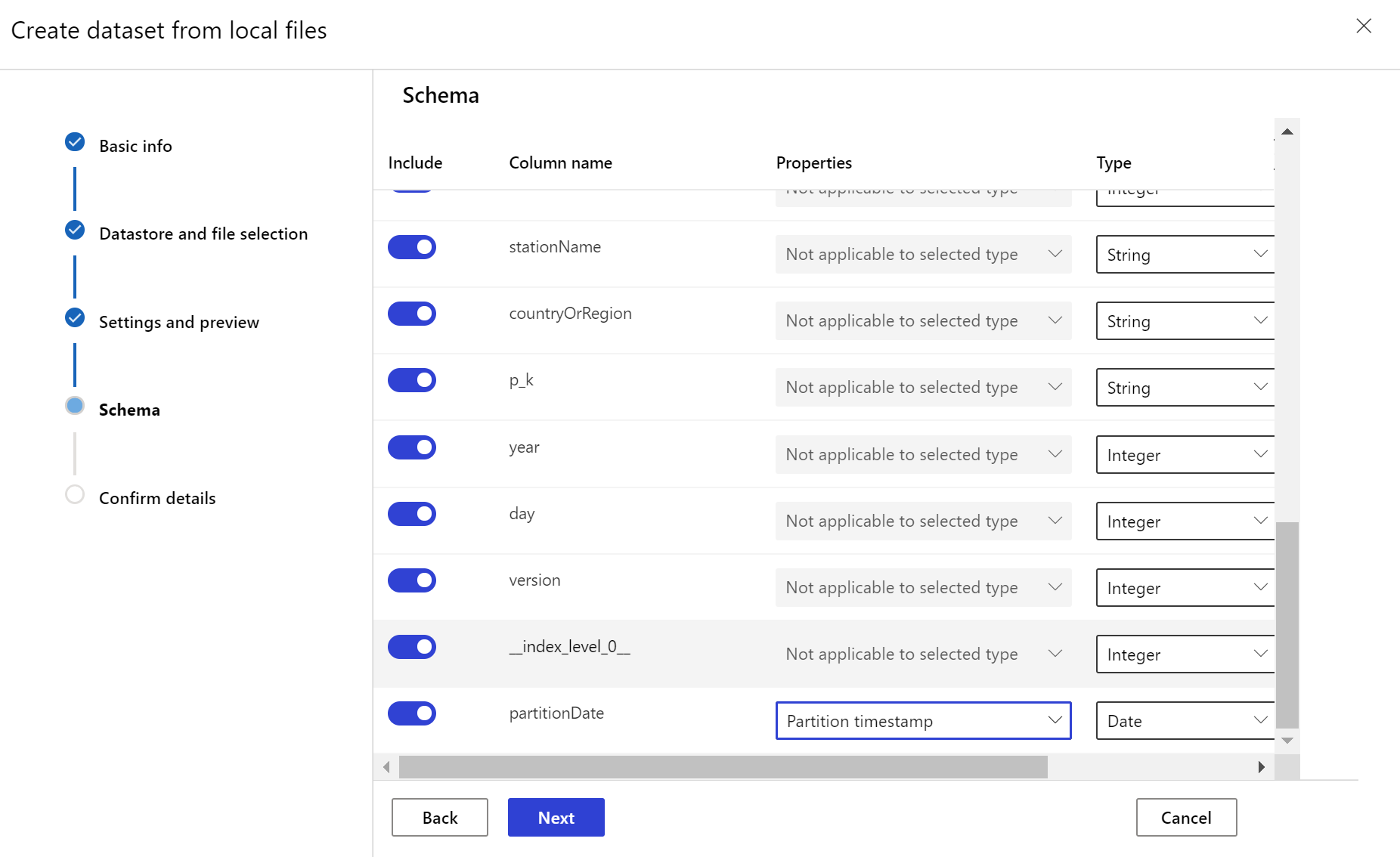
Tworzenie docelowego zestawu danych
Docelowy zestaw danych wymaga ustawionej timeseries na nim cech, określając kolumnę znacznika czasu z kolumny w danych lub kolumnie wirtualnej pochodzącej ze wzorca ścieżki plików. Utwórz zestaw danych ze znacznikiem czasu za pomocą zestawu SDK języka Python lub usługi Azure Machine Learning Studio. Aby dodać timeseries cechę do zestawu danych, należy określić kolumnę reprezentującą znacznik czasu. Jeśli dane są podzielone na strukturę folderów z informacjami o czasie, takimi jak "{rrrr/MM/dd}", utwórz kolumnę wirtualną za pomocą ustawienia wzorca ścieżki i ustaw ją jako "sygnaturę czasową partycji", aby włączyć funkcję interfejsu API szeregów czasowych.
DOTYCZY:SDK v1 usługi Azure Machine Learning dla języka Python
Metoda Dataset klasy with_timestamp_columns() definiuje kolumnę sygnatury czasowej dla zestawu danych.
from azureml.core import Workspace, Dataset, Datastore
# get workspace object
ws = Workspace.from_config()
# get datastore object
dstore = Datastore.get(ws, 'your datastore name')
# specify datastore paths
dstore_paths = [(dstore, 'weather/*/*/*/*/data.parquet')]
# specify partition format
partition_format = 'weather/{state}/{date:yyyy/MM/dd}/data.parquet'
# create the Tabular dataset with 'state' and 'date' as virtual columns
dset = Dataset.Tabular.from_parquet_files(path=dstore_paths, partition_format=partition_format)
# assign the timestamp attribute to a real or virtual column in the dataset
dset = dset.with_timestamp_columns('date')
# register the dataset as the target dataset
dset = dset.register(ws, 'target')
Napiwek
Pełny przykład użycia timeseries cech zestawów danych można znaleźć w przykładowym notesie lub dokumentacji zestawu SDK zestawów danych.

Tworzenie monitora zestawu danych
Tworzenie monitora zestawu danych w celu wykrywania i zgłaszania alertów dotyczących dryfu danych w nowym zestawie danych. Użyj zestawu SDK języka Python lub usługi Azure Machine Learning Studio.
Jak opisano później, monitor zestawu danych jest uruchamiany z ustawioną częstotliwością (codziennie, co tydzień, co miesiąc). Analizuje nowe dane dostępne w docelowym zestawie danych od czasu ostatniego uruchomienia. W niektórych przypadkach taka analiza najnowszych danych może nie wystarczyć:
- Nowe dane ze źródła nadrzędnego zostały opóźnione z powodu uszkodzonego potoku danych, a nowe dane nie były dostępne po uruchomieniu monitora zestawu danych.
- Zestaw danych szeregów czasowych miał tylko dane historyczne i chcesz analizować wzorce dryfu w zestawie danych w czasie. Na przykład: porównaj ruch przepływujący do witryny internetowej w sezonach zimowych i letnich, aby zidentyfikować wzorce sezonowe.
- Dopiero zaczynasz korzystać z monitorów zestawów danych. Chcesz ocenić, jak funkcja działa z istniejącymi danymi przed skonfigurowaniem jej w celu monitorowania przyszłych dni. W takich scenariuszach można przesłać przebieg na żądanie z określonym docelowym zakresem dat zestawu danych w celu porównania z zestawem danych odniesienia.
Funkcja wypełniania zaplecza uruchamia zadanie wypełniania dla określonego zakresu dat rozpoczęcia i zakończenia. Zadanie wypełniania wypełnia oczekiwane brakujące punkty danych w zestawie danych jako sposób zapewnienia dokładności i kompletności danych.
Uwaga
Monitorowanie modelu usługi Azure Machine Learning nie obsługuje funkcji ręcznego wypełniania, jeśli chcesz ponownie utworzyć monitor modelu dla określonego zakresu czasu, możesz utworzyć inny monitor modelu dla tego określonego zakresu czasu.
DOTYCZY:SDK v1 usługi Azure Machine Learning dla języka Python
Aby uzyskać szczegółowe informacje, zobacz dokumentację referencyjną zestawu PYTHON SDK dotyczącą dryfu danych.
W poniższym przykładzie pokazano, jak utworzyć monitor zestawu danych przy użyciu zestawu SDK języka Python:
from azureml.core import Workspace, Dataset
from azureml.datadrift import DataDriftDetector
from datetime import datetime
# get the workspace object
ws = Workspace.from_config()
# get the target dataset
target = Dataset.get_by_name(ws, 'target')
# set the baseline dataset
baseline = target.time_before(datetime(2019, 2, 1))
# set up feature list
features = ['latitude', 'longitude', 'elevation', 'windAngle', 'windSpeed', 'temperature', 'snowDepth', 'stationName', 'countryOrRegion']
# set up data drift detector
monitor = DataDriftDetector.create_from_datasets(ws, 'drift-monitor', baseline, target,
compute_target='cpu-cluster',
frequency='Week',
feature_list=None,
drift_threshold=.6,
latency=24)
# get data drift detector by name
monitor = DataDriftDetector.get_by_name(ws, 'drift-monitor')
# update data drift detector
monitor = monitor.update(feature_list=features)
# run a backfill for January through May
backfill1 = monitor.backfill(datetime(2019, 1, 1), datetime(2019, 5, 1))
# run a backfill for May through today
backfill1 = monitor.backfill(datetime(2019, 5, 1), datetime.today())
# disable the pipeline schedule for the data drift detector
monitor = monitor.disable_schedule()
# enable the pipeline schedule for the data drift detector
monitor = monitor.enable_schedule()
Napiwek
Pełny przykład konfigurowania zestawu danych i narzędzia do wykrywania timeseries dryfu danych można znaleźć w naszym przykładowym notesie.
Tworzenie monitora modelu (migrowanie do monitora modelu)
W przypadku migracji do monitora modelu, jeśli model został wdrożony w środowisku produkcyjnym w punkcie końcowym online usługi Azure Machine Learning i włączeniu zbierania danych we wdrożeniu, usługa Azure Machine Learning zbiera dane wnioskowania produkcyjnego i automatycznie przechowuje je w usłudze Microsoft Azure Blob Storage. Następnie możesz użyć monitorowania modelu usługi Azure Machine Learning, aby stale monitorować te dane wnioskowania produkcyjnego, a następnie bezpośrednio wybrać model, aby utworzyć docelowy zestaw danych (dane wnioskowania produkcyjnego w monitorze modelu).
W przypadku migracji do monitora modelu, jeśli model nie został wdrożony w środowisku produkcyjnym w punkcie końcowym online usługi Azure Machine Learning lub nie chcesz używać zbierania danych, możesz również skonfigurować monitorowanie modelu za pomocą niestandardowych sygnałów i metryk.
Poniższe sekcje zawierają więcej szczegółowych informacji na temat migracji do monitora modelu.
Tworzenie monitora modelu za pośrednictwem automatycznie zebranych danych produkcyjnych (migrowanie do monitora modelu)
Jeśli model został wdrożony w środowisku produkcyjnym w punkcie końcowym online usługi Azure Machine Learning i włączono zbieranie danych w czasie wdrażania.
Aby skonfigurować wbudowane monitorowanie modelu, możesz użyć następującego kodu:
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
AlertNotification,
MonitoringTarget,
MonitorDefinition,
MonitorSchedule,
RecurrencePattern,
RecurrenceTrigger,
ServerlessSparkCompute
)
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(),
subscription_id="subscription_id",
resource_group_name="resource_group_name",
workspace_name="workspace_name",
)
# create the compute
spark_compute = ServerlessSparkCompute(
instance_type="standard_e4s_v3",
runtime_version="3.3"
)
# specify your online endpoint deployment
monitoring_target = MonitoringTarget(
ml_task="classification",
endpoint_deployment_id="azureml:credit-default:main"
)
# create alert notification object
alert_notification = AlertNotification(
emails=['abc@example.com', 'def@example.com']
)
# create the monitor definition
monitor_definition = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
alert_notification=alert_notification
)
# specify the schedule frequency
recurrence_trigger = RecurrenceTrigger(
frequency="day",
interval=1,
schedule=RecurrencePattern(hours=3, minutes=15)
)
# create the monitor
model_monitor = MonitorSchedule(
name="credit_default_monitor_basic",
trigger=recurrence_trigger,
create_monitor=monitor_definition
)
poller = ml_client.schedules.begin_create_or_update(model_monitor)
created_monitor = poller.result()


Tworzenie monitora modelu za pomocą niestandardowego składnika przetwarzania wstępnego danych (migrowanie do monitora modelu)
W przypadku migracji do monitora modelu, jeśli model nie został wdrożony w środowisku produkcyjnym w punkcie końcowym online usługi Azure Machine Learning lub nie chcesz używać zbierania danych, możesz również skonfigurować monitorowanie modelu za pomocą niestandardowych sygnałów i metryk.
Jeśli nie masz wdrożenia, ale masz dane produkcyjne, możesz użyć tych danych do ciągłego monitorowania modelu. Aby monitorować te modele, musisz mieć możliwość:
- Zbieranie danych wnioskowania produkcyjnego z modeli wdrożonych w środowisku produkcyjnym.
- Zarejestruj dane wnioskowania produkcyjnego jako zasób danych usługi Azure Machine Learning i zapewnij ciągłe aktualizacje danych.
- Podaj niestandardowy składnik przetwarzania wstępnego danych i zarejestruj go jako składnik usługi Azure Machine Learning.
Jeśli dane nie są zbierane z modułem zbierającym dane, musisz podać niestandardowy składnik przetwarzania wstępnego danych. Bez tego niestandardowego składnika przetwarzania wstępnego danych system monitorowania modelu usługi Azure Machine Learning nie będzie wiedział, jak przetwarzać dane w formie tabelarycznej z obsługą okien czasowych.
Niestandardowy składnik przetwarzania wstępnego musi mieć następujące podpisy wejściowe i wyjściowe:
| Dane wejściowe/wyjściowe | Nazwa podpisu | Typ | opis | Przykładowa wartość |
|---|---|---|---|---|
| dane wejściowe | data_window_start |
Literału | godzina rozpoczęcia okna danych w formacie ISO8601. | 2023-05-01T04:31:57.012Z |
| dane wejściowe | data_window_end |
Literału | godzina zakończenia okna danych w formacie ISO8601. | 2023-05-01T04:31:57.012Z |
| dane wejściowe | input_data |
uri_folder | Zebrane dane wnioskowania produkcyjnego zarejestrowane jako zasób danych usługi Azure Machine Learning. | azureml:myproduction_dane_inferencyjne:1 |
| We/Wy | preprocessed_data |
tabela ML | Tabelaryczny zestaw danych zgodny z podzbiorem schematu danych referencyjnych. |
Aby zapoznać się z przykładem niestandardowego składnika przetwarzania wstępnego danych, zobacz custom_preprocessing w repozytorium GitHub azuremml-examples.
Omówienie wyników dryfu danych
W tej sekcji przedstawiono wyniki monitorowania zestawu danych znajdującego się na stronie Monitory zestawu danych zestawów danych w usłudze / Azure Studio. Możesz zaktualizować ustawienia i przeanalizować istniejące dane przez określony okres na tej stronie.
Zacznij od szczegółowych informacji najwyższego poziomu na temat wielkości dryfu danych i wyróżnienia funkcji, które należy dokładniej zbadać.
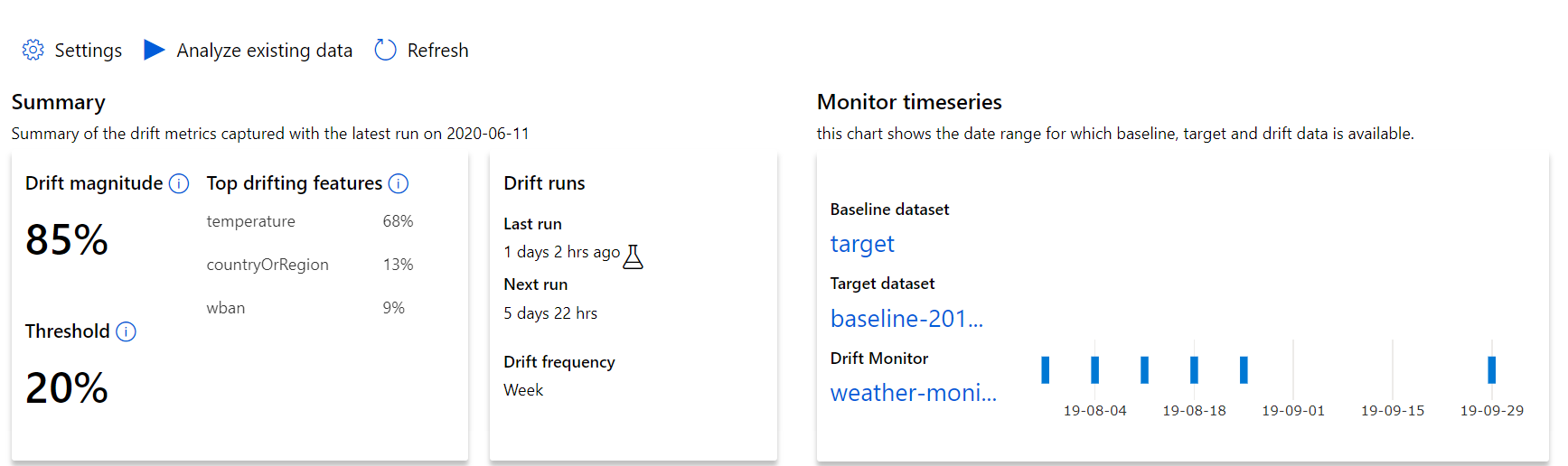
| Metryczne | opis |
|---|---|
| Wielkość dryfu danych | Procent dryfu między punktem odniesienia a docelowym zestawem danych w czasie. Ten procent waha się od 0 do 100, 0 wskazuje identyczne zestawy danych i 100 wskazuje, że model dryfu danych usługi Azure Machine Learning może całkowicie odróżnić dwa zestawy danych. Oczekuje się, że szum w dokładnej wartości procentowej jest spowodowany technikami uczenia maszynowego używanymi do generowania tej wielkości. |
| Najważniejsze funkcje dryfujące | Przedstawia funkcje z zestawu danych, które najwięcej dryfowały i w związku z tym przyczyniają się najbardziej do metryki Drift Magnitude. Ze względu na zmianę wariancji podstawowa dystrybucja funkcji nie musi zmieniać się, aby mieć stosunkowo duże znaczenie funkcji. |
| Próg | Wielkość dryfu danych poza ustawionym progiem wyzwala alerty. Skonfiguruj wartość progową w ustawieniach monitora. |
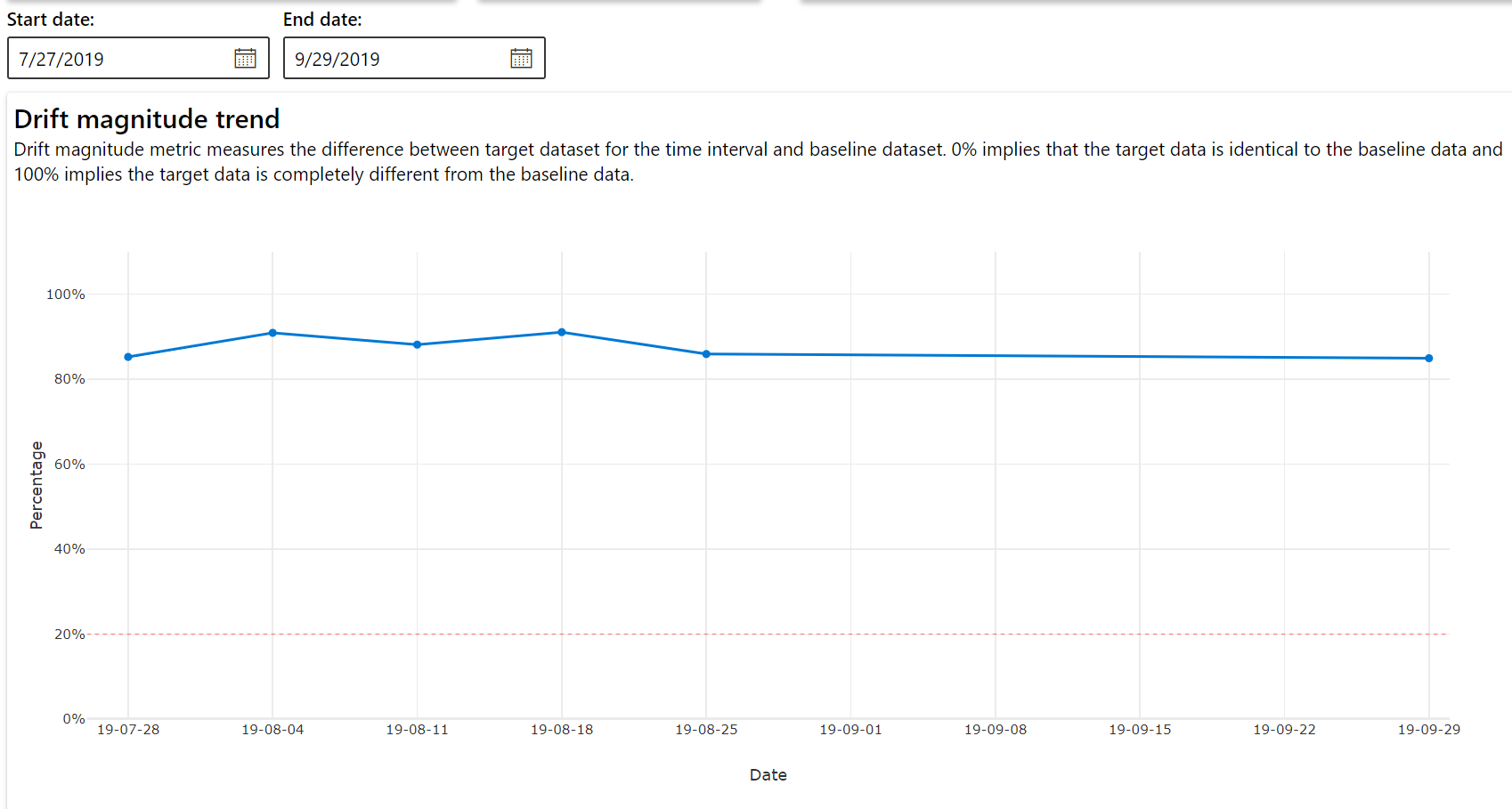
Trend wielkości dryfu
Zobacz, jak zestaw danych różni się od docelowego zestawu danych w określonym przedziale czasu. Im bliżej 100%, tym więcej dwóch zestawów danych różni się.
Wielkość dryfu według cech
Ta sekcja zawiera szczegółowe informacje na poziomie funkcji dotyczące zmiany w dystrybucji wybranej funkcji oraz inne statystyki w czasie.
Docelowy zestaw danych jest również profilowany w czasie. Odległość statystyczna między rozkładem bazowym każdej funkcji jest porównywana z docelowym zestawem danych w czasie. Koncepcyjnie przypomina to wielkość dryfu danych. Jednak ta odległość statystyczna dotyczy pojedynczej funkcji, a nie wszystkich funkcji. Dostępne są również wartości minimalne, maksymalne i średnie.
W usłudze Azure Machine Learning Studio wybierz pasek na grafie, aby wyświetlić szczegóły na poziomie funkcji dla tej daty. Domyślnie jest widoczna dystrybucja zestawu danych odniesienia i najnowsza dystrybucja tego samego zadania.
Te metryki można również pobrać w zestawie SDK języka Python za pomocą get_metrics() metody na DataDriftDetector obiekcie.
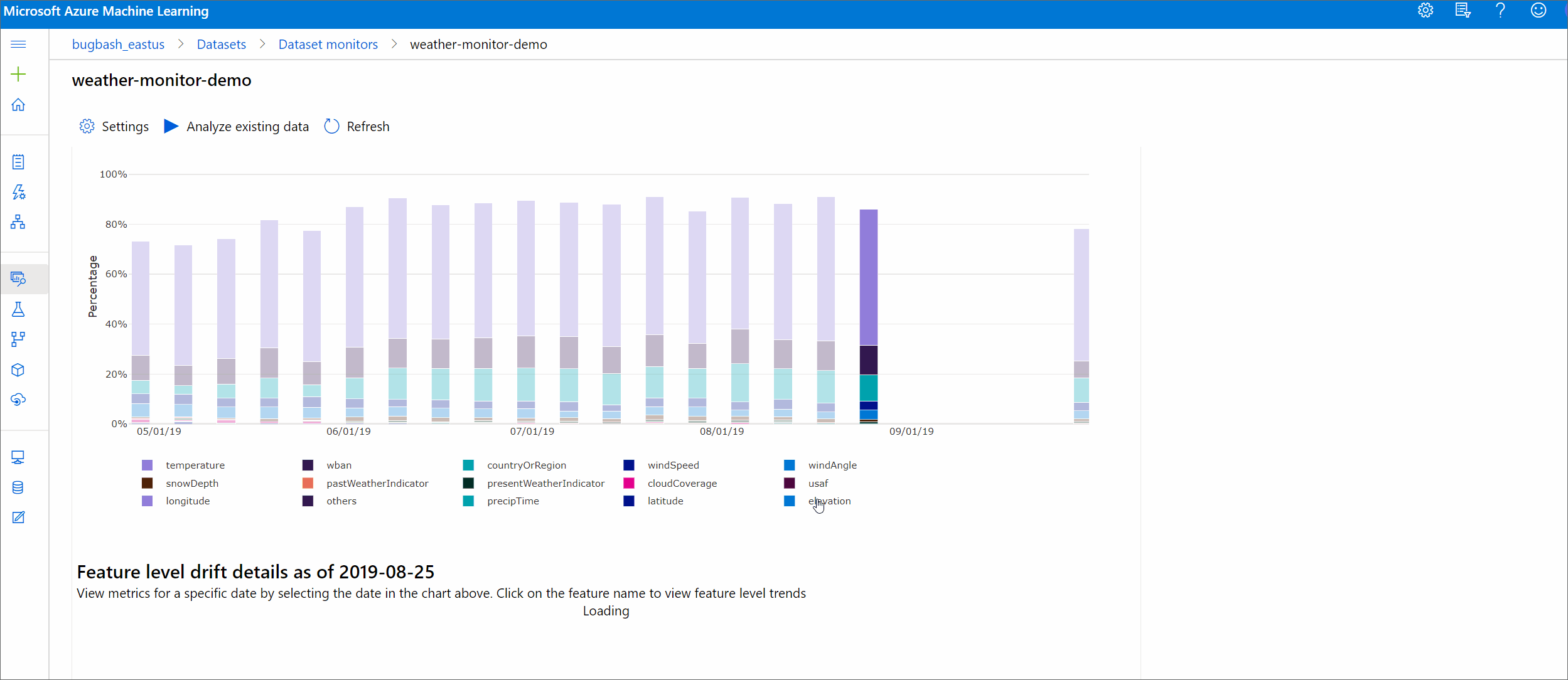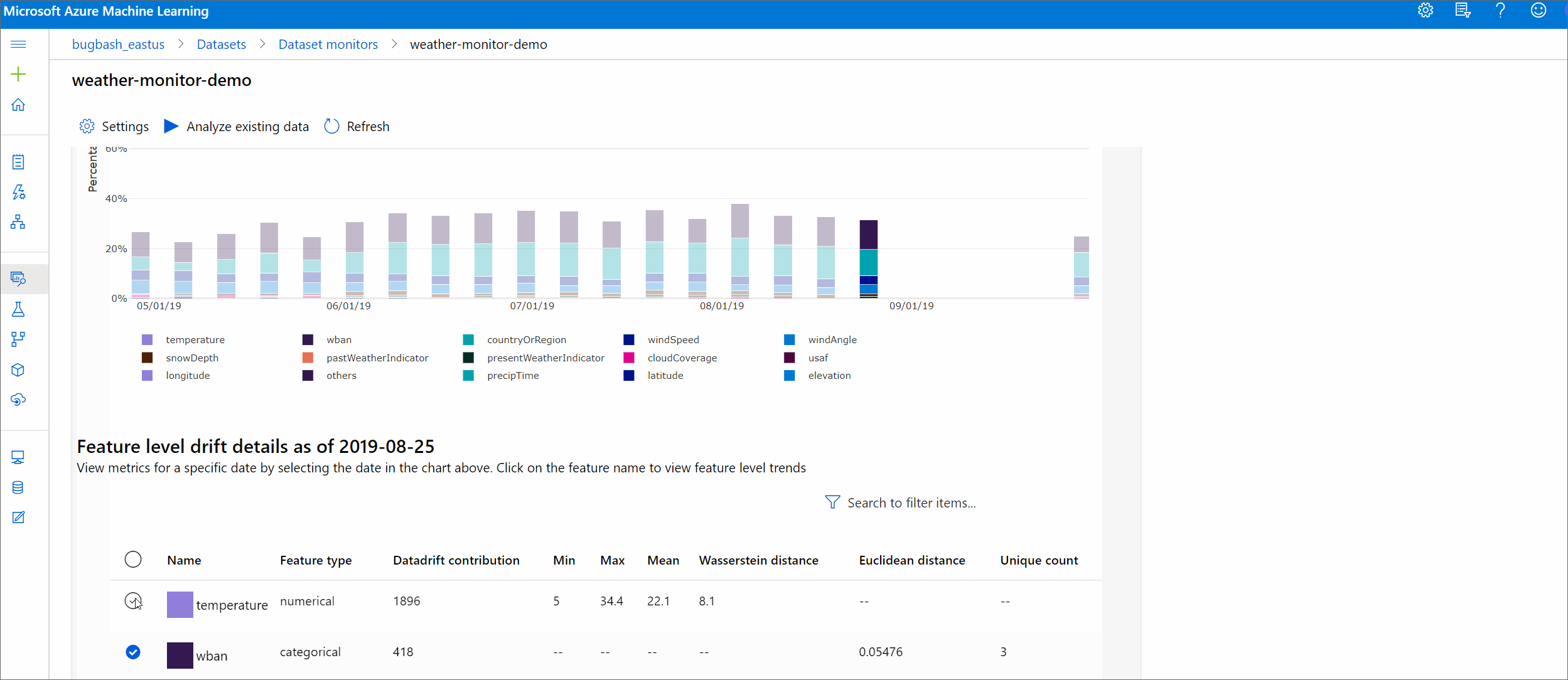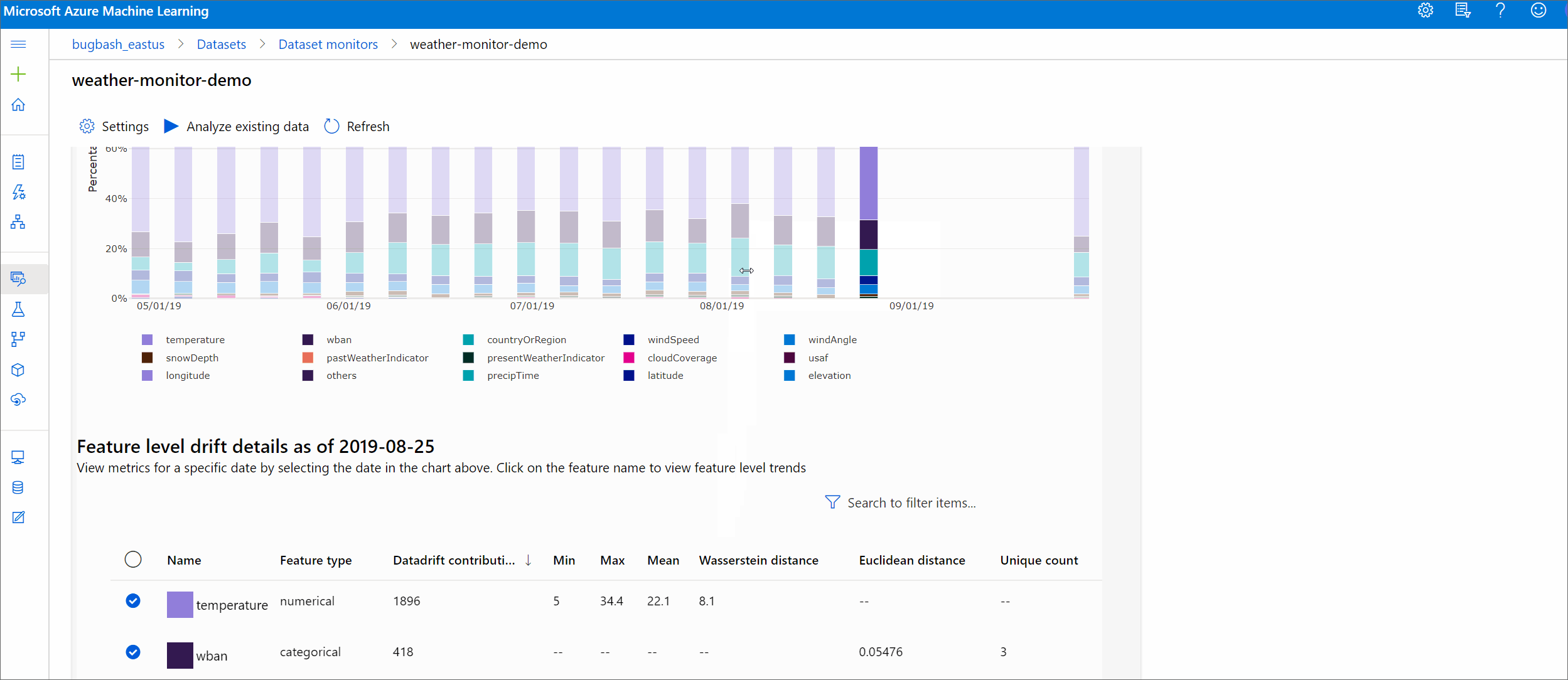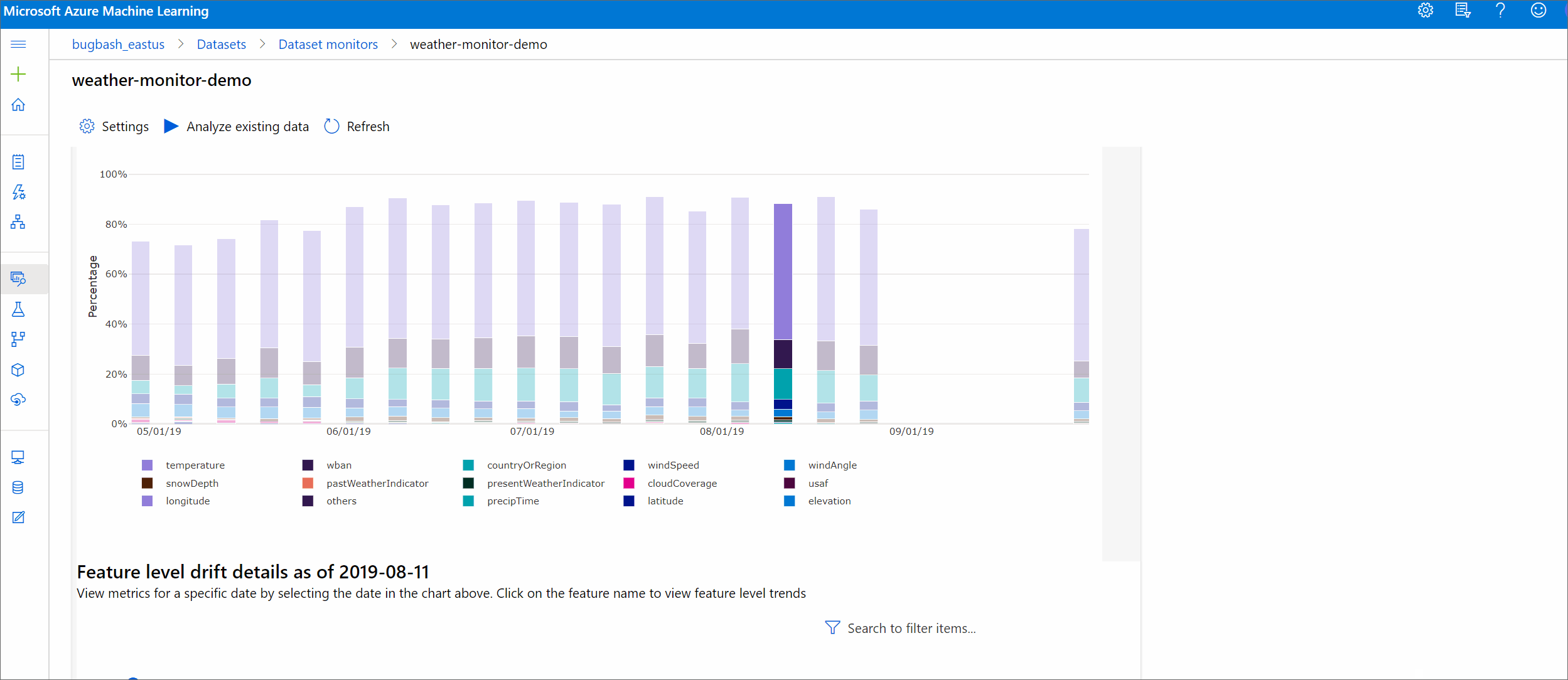
Szczegóły funkcji
Na koniec przewiń w dół, aby wyświetlić szczegóły poszczególnych funkcji. Użyj list rozwijanych powyżej wykresu, aby wybrać tę funkcję, a następnie wybierz metryki, którą chcesz wyświetlić.
Metryki na wykresie zależą od typu funkcji.
Funkcje liczbowe
Metryczne opis Odległość Wassersteina Minimalna ilość pracy w celu przekształcenia rozkładu linii bazowej w dystrybucję docelową. Średnia wartość Średnia wartość funkcji. Wartość minimalna Minimalna wartość funkcji. Wartość maksymalna Maksymalna wartość funkcji. Funkcje podzielone na kategorie
Metryczne opis Odległość euklidianowa Obliczane dla kolumn kategorii. Odległość euklidesowa jest obliczana na dwóch wektorach, generowanych na podstawie rozkładu empirycznego tej samej kolumny kategorii z dwóch zestawów danych. 0 nie wskazuje różnicy w rozkładach empirycznych. Tym bardziej odbiega od 0, tym bardziej ta kolumna dryfuje. Trendy można zaobserwować na podstawie wykresu szeregów czasowych tej metryki i mogą być pomocne w odkrywaniu funkcji dryfującej. Unikatowe wartości Liczba unikatowych wartości (kardynalność) funkcji.
Na tym wykresie wybierz jedną datę, aby porównać rozkład funkcji między elementem docelowym a tą datą dla wyświetlanej funkcji. W przypadku funkcji liczbowych przedstawiono dwa rozkłady prawdopodobieństwa. Jeśli funkcja jest liczbowa, zostanie wyświetlony wykres słupkowy.
Metryki, alerty i zdarzenia
Metryki można wykonywać względem zasobu usługi aplikacja systemu Azure Insights skojarzonego z obszarem roboczym uczenia maszynowego. Masz dostęp do wszystkich funkcji usługi Application Insights, w tym skonfigurowania niestandardowych reguł alertów i grup akcji w celu wyzwolenia akcji, takiej jak wiadomość e-mail/sms/wypychanie/głos lub funkcja platformy Azure. Szczegółowe informacje można znaleźć w pełnej dokumentacji usługi Application Insights.
Aby rozpocząć, przejdź do witryny Azure Portal i wybierz stronę Przegląd obszaru roboczego. Skojarzony zasób usługi Application Insights znajduje się po prawej stronie:

Wybierz pozycję Dzienniki (analiza) w obszarze Monitorowanie w okienku po lewej stronie:
Metryki monitora zestawu danych są przechowywane jako customMetrics. Możesz napisać i uruchomić zapytanie po skonfigurowaniu monitora zestawu danych, aby je wyświetlić:

Po zidentyfikowaniu metryk w celu skonfigurowania reguł alertów utwórz nową regułę alertu:
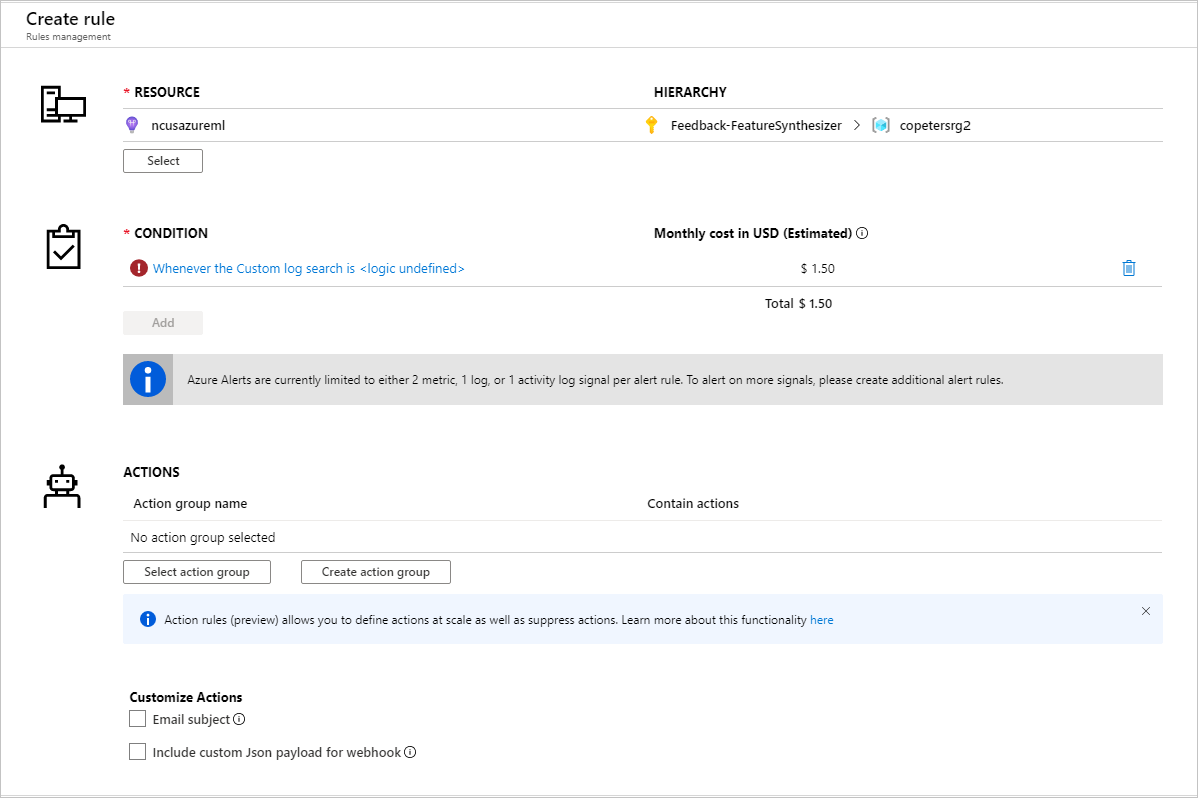
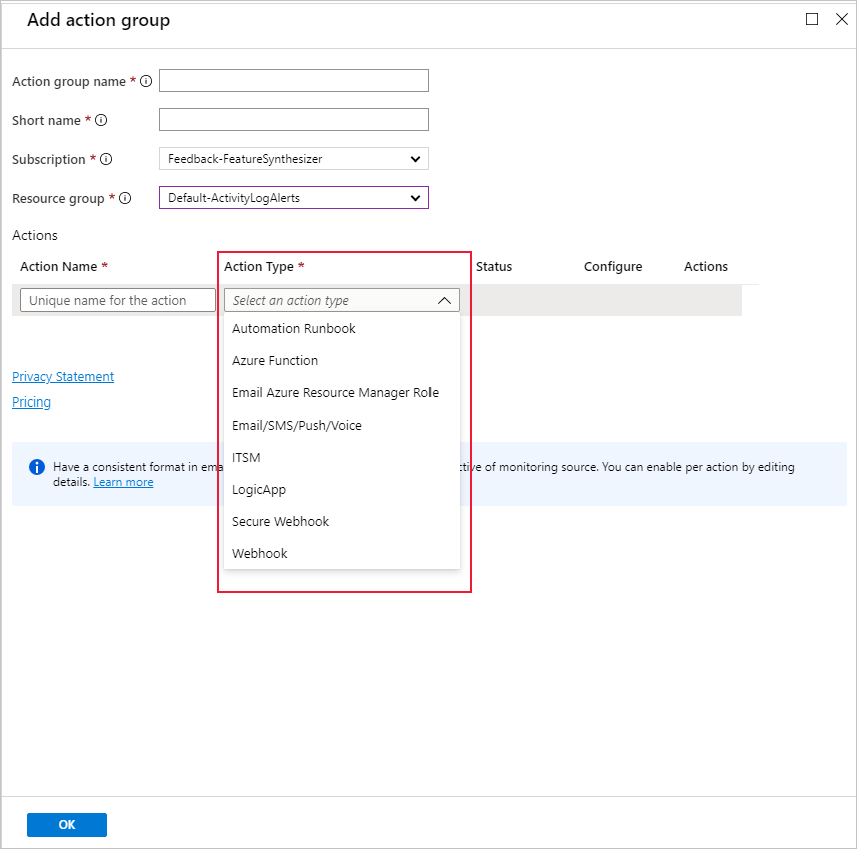
Możesz użyć istniejącej grupy akcji lub utworzyć nową, aby zdefiniować akcję, która ma zostać podjęta po spełnieniu określonych warunków:
Rozwiązywanie problemów
Ograniczenia i znane problemy dotyczące monitorów dryfu danych:
Zakres czasu analizowania danych historycznych jest ograniczony do 31 interwałów ustawienia częstotliwości monitora.
Ograniczenie 200 funkcji, chyba że nie określono listy funkcji (wszystkie używane funkcje).
Rozmiar obliczeniowy musi być wystarczająco duży, aby obsłużyć dane.
Upewnij się, że zestaw danych zawiera dane w dacie rozpoczęcia i zakończenia danego zadania monitora.
Monitory zestawu danych działają tylko na zestawach danych zawierających co najmniej 50 wierszy.
Kolumny lub funkcje w zestawie danych są klasyfikowane jako kategorialne lub liczbowe na podstawie warunków w poniższej tabeli. Jeśli funkcja nie spełnia tych warunków — na przykład kolumna ciągu typu z 100 unikatowymi wartościami >— funkcja zostanie porzucona z algorytmu dryfu danych, ale nadal jest profilowana.
Typ funkcji Typ danych Stan Ograniczenia Podzielone na kategorie ciąg Liczba unikatowych wartości w funkcji jest mniejsza niż 100 i mniejsza niż 5% liczby wierszy. Wartość null jest traktowana jako własna kategoria. Numeryczny int, float Wartości w funkcji są typu danych liczbowych i nie spełniają warunku funkcji podzielonej na kategorie. Funkcja została porzucona, jeśli >15% wartości ma wartość null. Po utworzeniu monitora dryfu danych, ale nie widać danych na stronie Monitory zestawu danych w usłudze Azure Machine Learning Studio, spróbuj wykonać następujące czynności.
- Sprawdź, czy w górnej części strony wybrano odpowiedni zakres dat.
- Na karcie Monitory zestawu danych wybierz link eksperymentu, aby sprawdzić stan zadania. Ten link znajduje się po prawej stronie tabeli.
- Jeśli zadanie zostało ukończone pomyślnie, sprawdź dzienniki sterowników, aby zobaczyć, ile metryk zostało wygenerowanych lub czy istnieją jakieś komunikaty ostrzegawcze. Po wybraniu eksperymentu znajdź dzienniki sterowników na karcie Dane wyjściowe i dzienniki .
Jeśli funkcja ZESTAWU SDK
backfill()nie generuje oczekiwanych danych wyjściowych, może to być spowodowane problemem z uwierzytelnianiem. Podczas tworzenia obliczeń do przekazania do tej funkcji nie używaj poleceniaRun.get_context().experiment.workspace.compute_targets. Zamiast tego użyj polecenia ServicePrincipalAuthentication , na przykład następującego, aby utworzyć zasoby obliczeniowe przekazywane do tejbackfill()funkcji:
Uwaga
Nie koduj trwale hasła jednostki usługi w kodzie. Zamiast tego pobierz je ze środowiska języka Python, magazynu kluczy lub innej bezpiecznej metody uzyskiwania dostępu do wpisów tajnych.
auth = ServicePrincipalAuthentication(
tenant_id=tenant_id,
service_principal_id=app_id,
service_principal_password=client_secret
)
ws = Workspace.get("xxx", auth=auth, subscription_id="xxx", resource_group="xxx")
compute = ws.compute_targets.get("xxx")
Z poziomu modułu zbierającego dane modelu może upłynąć do 10 minut, aż dane pojawią się na koncie magazynu obiektów blob. Jednak zwykle zajmuje to mniej czasu. W skrycie lub notesie poczekaj 10 minut, aby upewnić się, że poniższe komórki zostały pomyślnie uruchomione.
import time time.sleep(600)
Następne kroki
- Przejdź do usługi Azure Machine Learning Studio lub notesu języka Python, aby skonfigurować monitor zestawu danych.
- Zobacz, jak skonfigurować dryf danych na modelach wdrożonych w usłudze Azure Kubernetes Service.
- Konfigurowanie monitorów dryfu zestawów danych za pomocą usługi Azure Event Grid.