Korzystanie z pulpitu nawigacyjnego Odpowiedzialne używanie sztucznej inteligencji w usłudze Azure Machine Edukacja Studio
Pulpity nawigacyjne odpowiedzialnej sztucznej inteligencji są połączone z zarejestrowanymi modelami. Aby wyświetlić pulpit nawigacyjny Odpowiedzialne używanie sztucznej inteligencji, przejdź do rejestru modeli i wybierz zarejestrowany model, dla którego został wygenerowany pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji. Następnie wybierz kartę Odpowiedzialne używanie sztucznej inteligencji , aby wyświetlić listę wygenerowanych pulpitów nawigacyjnych.

Możesz skonfigurować wiele pulpitów nawigacyjnych i dołączyć je do zarejestrowanego modelu. Różne kombinacje składników (możliwość interpretacji, analiza błędów, analiza przyczynowa itd.) mogą być dołączone do każdego pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji. Na poniższej ilustracji przedstawiono dostosowywanie pulpitu nawigacyjnego i składniki, które zostały w nim wygenerowane. Na każdym pulpicie nawigacyjnym można wyświetlać lub ukrywać różne składniki w samym interfejsie użytkownika pulpitu nawigacyjnego.

Wybierz nazwę pulpitu nawigacyjnego, aby otworzyć go w pełnym widoku w przeglądarce. Aby powrócić do listy pulpitów nawigacyjnych, możesz w dowolnym momencie wybrać pozycję Wstecz do szczegółów modeli .

Pełna funkcjonalność ze zintegrowanym zasobem obliczeniowym
Niektóre funkcje pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji wymagają dynamicznego, na bieżąco i obliczeń w czasie rzeczywistym (na przykład analizy warunkowej). Jeśli nie połączysz zasobu obliczeniowego z pulpitem nawigacyjnym, może się okazać, że brakuje niektórych funkcji. Po nawiązaniu połączenia z zasobem obliczeniowym włączysz pełną funkcjonalność pulpitu nawigacyjnego Odpowiedzialne używanie sztucznej inteligencji dla następujących składników:
- Analiza błędów
- Ustawienie kohorty globalnych danych na dowolną kohortę zainteresowań spowoduje zaktualizowanie drzewa błędów zamiast wyłączenia go.
- Obsługiwane jest wybieranie innych metryk błędów lub wydajności.
- Obsługiwane jest wybieranie dowolnego podzestawu funkcji do trenowania mapy drzewa błędów.
- Obsługiwana jest zmiana minimalnej liczby próbek wymaganych na węzeł liścia i głębokość drzewa błędów.
- Dynamiczne aktualizowanie mapy cieplnej dla maksymalnie dwóch funkcji jest obsługiwane.
- Ważność funkcji
- Obsługiwany jest indywidualny wykres oczekiwania warunkowego (ICE) na karcie ważności poszczególnych funkcji.
- Kontraktualne analizy warunkowe
- Generowanie nowego punktu danych warunkowych analizy warunkowej w celu zrozumienia minimalnej zmiany wymaganej dla żądanego wyniku jest obsługiwane.
- Analiza przyczynowa
- Wybranie dowolnego pojedynczego punktu danych, wypaczenie jego cech leczenia i obserwowanie oczekiwanego wyniku przyczynowego przyczynowego przyczynowego, co-jeżeli jest obsługiwane (tylko w przypadku scenariuszy uczenia maszynowego regresji).
Te informacje można również znaleźć na stronie pulpitu nawigacyjnego Odpowiedzialne używanie sztucznej inteligencji, wybierając ikonę Informacje , jak pokazano na poniższej ilustracji:

Włączanie pełnej funkcjonalności pulpitu nawigacyjnego Odpowiedzialne używanie sztucznej inteligencji
Wybierz uruchomione wystąpienie obliczeniowe na liście rozwijanej Obliczenia w górnej części pulpitu nawigacyjnego. Jeśli nie masz uruchomionego środowiska obliczeniowego, utwórz nowe wystąpienie obliczeniowe, wybierając znak plus (+) obok listy rozwijanej. Możesz też wybrać przycisk Uruchom obliczenia , aby uruchomić zatrzymane wystąpienie obliczeniowe. Tworzenie lub uruchamianie wystąpienia obliczeniowego może potrwać kilka minut.

Gdy środowisko obliczeniowe jest w stanie Uruchomiony, pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji rozpoczyna nawiązywanie połączenia z wystąpieniem obliczeniowym. Aby to osiągnąć, w wybranym wystąpieniu obliczeniowym zostanie utworzony proces terminalu, a w terminalu zostanie uruchomiony punkt końcowy odpowiedzialnej sztucznej inteligencji. Wybierz pozycję Wyświetl dane wyjściowe terminalu , aby wyświetlić bieżący proces terminalu.

Gdy pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji jest połączony z wystąpieniem obliczeniowym, zobaczysz zielony pasek komunikatów, a pulpit nawigacyjny jest teraz w pełni funkcjonalny.

Jeśli proces trwa chwilę, a pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji nadal nie jest połączony z wystąpieniem obliczeniowym lub zostanie wyświetlony czerwony pasek komunikatu o błędzie, oznacza to, że występują problemy z uruchamianiem punktu końcowego odpowiedzialnej sztucznej inteligencji. Wybierz pozycję Wyświetl dane wyjściowe terminalu i przewiń w dół do dołu, aby wyświetlić komunikat o błędzie.

Jeśli masz trudności z ustaleniem, jak rozwiązać problem "Nie można nawiązać połączenia z wystąpieniem obliczeniowym", wybierz ikonę Uśmiech w prawym górnym rogu. Prześlij opinię do nas o wszelkich napotkanych błędach lub problemach. Możesz dołączyć zrzut ekranu i swój adres e-mail w formularzu opinii.




Omówienie interfejsu użytkownika pulpitu nawigacyjnego Odpowiedzialne używanie sztucznej inteligencji
Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji zawiera niezawodny, bogaty zestaw wizualizacji i funkcji, które ułatwiają analizowanie modelu uczenia maszynowego lub podejmowanie decyzji biznesowych opartych na danych:
- Kontrolki globalne
- Analiza błędów
- Omówienie modelu i metryki sprawiedliwości
- Analiza danych
- Znaczenie funkcji (wyjaśnienia modelu)
- Kontraktualne analizy warunkowe
- Analiza przyczynowa
Kontrolki globalne
W górnej części pulpitu nawigacyjnego można tworzyć kohorty (podgrupy punktów danych, które mają określone cechy), aby skoncentrować analizę poszczególnych składników. Nazwa kohorty, która jest obecnie stosowana do pulpitu nawigacyjnego, jest zawsze wyświetlana w lewym górnym rogu pulpitu nawigacyjnego. Widok domyślny na pulpicie nawigacyjnym to cały zestaw danych zatytułowany Wszystkie dane (wartość domyślna).

- Ustawienia kohorty: umożliwia wyświetlanie i modyfikowanie szczegółów każdej kohorty na panelu bocznym.
- Konfiguracja pulpitu nawigacyjnego: umożliwia wyświetlanie i modyfikowanie układu ogólnego pulpitu nawigacyjnego na panelu bocznym.
- Kohorta przełącznika: umożliwia wybranie innej kohorty i wyświetlenie statystyk w oknie podręcznym.
- Nowa kohorta: umożliwia tworzenie i dodawanie nowej kohorty do pulpitu nawigacyjnego.
Wybierz pozycję Ustawienia kohorty, aby otworzyć panel z listą kohort, gdzie można je tworzyć, edytować, duplikować lub usuwać.

Wybierz pozycję Nowa kohorta w górnej części pulpitu nawigacyjnego lub w ustawieniach Kohorty, aby otworzyć nowy panel z opcjami filtrowania według następujących elementów:
- Indeks: filtruje według pozycji punktu danych w pełnym zestawie danych.
- Zestaw danych: filtruje według wartości określonej funkcji w zestawie danych.
- Przewidywana wartość Y: filtruje według przewidywania dokonanego przez model.
- Prawda Y: filtruje według rzeczywistej wartości funkcji docelowej.
- Błąd (regresja): Filtruje według błędu (lub Wynik klasyfikacji): Filtruje według typu i dokładności klasyfikacji.
- Wartości podzielone na kategorie: filtruj według listy wartości, które powinny być uwzględnione.
- Wartości liczbowe: filtruj według operacji logicznej na wartości (na przykład wybierz punkty danych, w których wiek 64 lat < ).

Możesz nazwać nową kohortę zestawu danych, wybrać pozycję Dodaj filtr, aby dodać każdy filtr , którego chcesz użyć, a następnie wykonać jedną z następujących czynności:
- Wybierz pozycję Zapisz , aby zapisać nową kohortę na liście kohorty.
- Wybierz pozycję Zapisz i przełącz, aby zapisać i natychmiast przełączyć globalną kohortę pulpitu nawigacyjnego na nowo utworzoną kohortę.

Wybierz pozycję Konfiguracja pulpitu nawigacyjnego, aby otworzyć panel z listą składników skonfigurowanych na pulpicie nawigacyjnym. Możesz ukryć składniki na pulpicie nawigacyjnym, wybierając ikonę Kosza , jak pokazano na poniższej ilustracji:

Składniki można dodać z powrotem do pulpitu nawigacyjnego za pomocą niebieskiego okrągłego znaku plus (+) w dzielniku między poszczególnymi składnikami, jak pokazano na poniższej ilustracji:

Analiza błędów
W następnych sekcjach opisano sposób interpretowania i używania map drzewa błędów oraz map cieplnych.
Mapa drzewa błędów
Pierwszym okienkiem składnika analizy błędów jest mapa drzewa, która ilustruje rozkład awarii modelu między różne kohorty z wizualizacją drzewa. Wybierz dowolny węzeł, aby wyświetlić ścieżkę przewidywania w funkcjach, w których znaleziono błąd.

- Widok mapy cieplnej: przełącza się na wizualizację mapy cieplnej rozkładu błędów.
- Lista funkcji: umożliwia modyfikowanie funkcji używanych w mapie cieplnej przy użyciu panelu bocznego.
- Pokrycie błędów: wyświetla procent wszystkich błędów w zestawie danych skoncentrowanym w wybranym węźle.
- Błąd (regresja) lub współczynnik błędów (klasyfikacja):Wyświetla błąd lub procent awarii wszystkich punktów danych w wybranym węźle.
- Węzeł: reprezentuje kohortę zestawu danych, potencjalnie z zastosowanymi filtrami oraz liczbę błędów z łącznej liczby punktów danych w kohortie.
- Linia wypełnienia: wizualizuje rozkład punktów danych na kohorty podrzędne na podstawie filtrów z liczbą punktów danych reprezentowanych przez grubość linii.
- Informacje o zaznaczeniu: zawiera informacje o wybranym węźle w panelu bocznym.
- Zapisz jako nową kohortę: tworzy nową kohortę z określonymi filtrami.
- Wystąpienia kohorty podstawowej: wyświetla łączną liczbę punktów w całym zestawie danych oraz liczbę poprawnie i niepoprawnie przewidywanych punktów.
- Wystąpienia wybranej kohorty: wyświetla łączną liczbę punktów w wybranym węźle oraz liczbę poprawnie i niepoprawnie przewidywanych punktów.
- Ścieżka przewidywania (filtry): Wyświetla listę filtrów umieszczonych w pełnym zestawie danych w celu utworzenia tej mniejszej kohorty.
Wybierz przycisk Lista funkcji, aby otworzyć panel boczny, z którego można ponownie wytrenować drzewo błędów w określonych funkcjach.

- Funkcje wyszukiwania: umożliwia znajdowanie określonych funkcji w zestawie danych.
- Funkcje: wyświetla nazwę funkcji w zestawie danych.
- Ważność: wskazówki dotyczące tego, jak powiązana z funkcją może być błąd. Obliczane za pomocą współczynnika wzajemnych informacji między funkcją a błędem na etykietach. Możesz użyć tej oceny, aby ułatwić podjęcie decyzji o funkcjach do wyboru w analizie błędów.
- Znacznik wyboru: umożliwia dodawanie lub usuwanie funkcji z mapy drzewa.
- Maksymalna głębokość: maksymalna głębokość drzewa zastępczego wytrenowanego na błędach.
- Liczba liści: liczba liści drzewa zastępczego wyszkolonych na błędy.
- Minimalna liczba próbek w jednym liściu: minimalna ilość danych wymaganych do utworzenia jednego liścia.
Błąd mapy cieplnej
Wybierz kartę Mapa cieplna , aby przełączyć się do innego widoku błędu w zestawie danych. Możesz wybrać jedną lub wiele komórek mapy cieplnej i utworzyć nową kohortę. Możesz wybrać maksymalnie dwie funkcje, aby utworzyć mapę cieplną.

- Komórki: wyświetla liczbę zaznaczonych komórek.
- Pokrycie błędów: wyświetla procent wszystkich błędów skoncentrowanych w zaznaczonych komórkach.
- Współczynnik błędów: wyświetla procent niepowodzeń wszystkich punktów danych w wybranych komórkach.
- Funkcje osi: wybiera przecięcie cech do wyświetlenia na mapie cieplnej.
- Komórki: reprezentuje kohortę zestawu danych z zastosowanymi filtrami oraz procent błędów z łącznej liczby punktów danych w kohortie. Niebieski kontur wskazuje wybrane komórki, a ciemność koloru czerwonego reprezentuje koncentrację błędów.
- Ścieżka przewidywania (filtry): Wyświetla listę filtrów umieszczonych w pełnym zestawie danych dla każdej wybranej kohorty.
Omówienie modelu i metryki sprawiedliwości
Składnik przeglądu modelu zawiera kompleksowy zestaw metryk wydajności i sprawiedliwości do oceny modelu wraz z kluczowymi metrykami różnic wydajności wraz z określonymi funkcjami i kohortami zestawów danych.
Kohorty zestawów danych
W okienku Kohorty zestawów danych możesz zbadać model, porównując wydajność modelu różnych kohort zestawów danych określonych przez użytkownika (dostęp za pośrednictwem ikony Ustawienia kohorty w prawym górnym rogu pulpitu nawigacyjnego).

- Pomóż mi wybrać metryki: wybierz tę ikonę, aby otworzyć panel zawierający więcej informacji na temat dostępnych metryk wydajności modelu w tabeli. Łatwo dostosuj metryki do wyświetlenia przy użyciu listy rozwijanej wielokrotnego wyboru, aby wybrać i usunąć zaznaczenie metryk wydajności.
- Pokaż mapę cieplną: włącz i wyłącz, aby pokazać lub ukryć wizualizację mapy cieplnej w tabeli. Gradient mapy cieplnej odpowiada zakresowi znormalizowanemu między najniższą wartością a najwyższą wartością w każdej kolumnie.
- Tabela metryk dla każdej kohorty zestawów danych: Wyświetl kolumny kohort zestawów danych, rozmiar próbki każdej kohorty i wybrane metryki wydajności modelu dla każdej kohorty.
- Wykres słupkowy wizualizujący pojedynczą metryki: Wyświetlanie błędu bezwzględnego w kohortach w celu łatwego porównania.
- Wybierz metrykę (oś x): wybierz ten przycisk, aby wybrać metryki do wyświetlenia na wykresie słupkowym.
- Wybierz kohorty (oś y): wybierz ten przycisk, aby wybrać kohorty do wyświetlenia na wykresie słupkowym. Wybór kohorty funkcji może zostać wyłączony, chyba że najpierw określisz funkcje na karcie Kohorta funkcji składnika.
Wybierz pozycję Pomoc, aby wybrać metryki , aby otworzyć panel z listą metryk wydajności modelu i ich definicjami, co może ułatwić wybranie odpowiednich metryk do wyświetlenia.
| Scenariusz uczenia maszynowego | Metryki |
|---|---|
| Regresja | Średni błąd bezwzględny, błąd średniokwadratowy, R kwadrat, przewidywanie średniej. |
| Klasyfikacja | Dokładność, Precyzja, Kompletność, Wynik F1, Współczynnik wyników fałszywie dodatnich, Współczynnik fałszywie ujemny, Wskaźnik wyboru. |
Kohorty funkcji
W okienku Kohorty funkcji możesz zbadać model, porównując wydajność modelu między określonymi przez użytkownika funkcjami poufnymi i niewrażliwymi (na przykład wydajność w różnych kohortach płci, rasy i dochodów).

Pomóż mi wybrać metryki: Wybierz tę ikonę, aby otworzyć panel z więcej informacji na temat dostępnych metryk w tabeli. Łatwo dostosuj metryki do wyświetlenia przy użyciu listy rozwijanej wielokrotnego wyboru, aby wybrać i usunąć zaznaczenie metryk wydajności.
Pomóż mi wybrać funkcje: Wybierz tę ikonę, aby otworzyć panel z więcej informacji na temat dostępnych funkcji, które można wyświetlić w tabeli, z deskryptorami każdej funkcji i ich możliwości kwantowania (zobacz poniżej). Łatwo dostosuj funkcje do wyświetlenia przy użyciu listy rozwijanej wielokrotnego wyboru, aby je zaznaczyć i usunąć ich zaznaczenie.
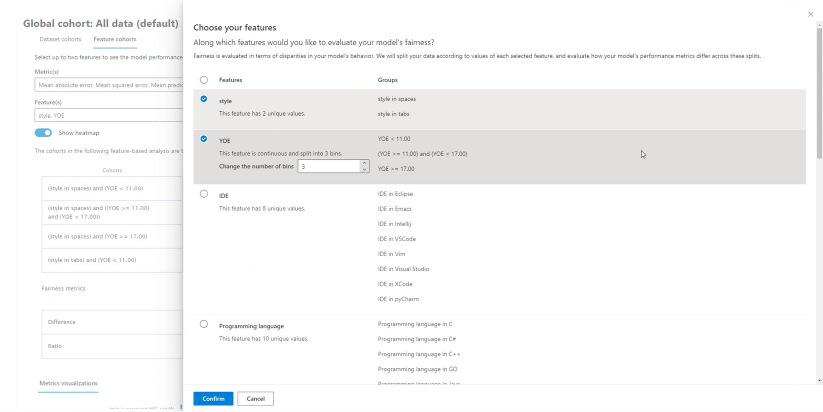
Pokaż mapę cieplną: włącz i wyłącz, aby wyświetlić wizualizację mapy cieplnej. Gradient mapy cieplnej odpowiada zakresowi znormalizowanemu między najniższą wartością a najwyższą wartością w każdej kolumnie.
Tabela metryk dla każdej kohorty funkcji: tabela z kolumnami dla kohort funkcji (sub-kohorta wybranej funkcji), rozmiar próbki każdej kohorty i wybrane metryki wydajności modelu dla każdej kohorty funkcji.
Metryki sprawiedliwości/metryki różnicy: tabela odpowiadająca tabeli metryk i pokazuje maksymalną różnicę lub maksymalny współczynnik wyników wydajności między dowolną dwiema kohortami funkcji.
Wykres słupkowy wizualizujący pojedynczą metryki: Wyświetlanie błędu bezwzględnego w kohortach w celu łatwego porównania.
Wybierz kohorty (oś y): wybierz ten przycisk, aby wybrać kohorty do wyświetlenia na wykresie słupkowym.
Wybranie pozycji Wybierz kohortę powoduje otwarcie panelu z opcją wyświetlania porównania wybranych kohort zestawów danych lub kohort funkcji w zależności od tego, co wybierzesz na liście rozwijanej wielokrotnego wyboru poniżej. Wybierz pozycję Potwierdź , aby zapisać zmiany w widoku wykresu słupkowego.
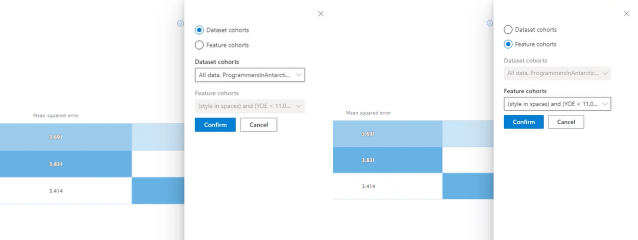
Wybierz metryki (oś x): wybierz ten przycisk, aby wybrać metryki do wyświetlenia na wykresie słupkowym.


Analiza danych
W przypadku składnika analizy danych w okienku Widok tabeli zostanie wyświetlony widok tabeli zestawu danych dla wszystkich funkcji i wierszy.
Panel Widok wykresu przedstawia agregację i poszczególne wykresy punktów danych. Statystyki danych można analizować wzdłuż osi x i osi y, używając filtrów, takich jak przewidywany wynik, funkcje zestawu danych i grupy błędów. Ten widok pomaga zrozumieć nadmierne przedstawianie i niedoreprezentowanie w zestawie danych.

Wybierz kohortę zestawu danych, aby eksplorować: określ kohortę zestawu danych z listy kohort, dla których chcesz wyświetlić statystyki danych.
Oś X: wyświetla typ wartości wykreślinej w poziomie. Zmodyfikuj wartości, wybierając przycisk , aby otworzyć panel boczny.
Oś Y: wyświetla typ wartości wykreślinej w pionie. Zmodyfikuj wartości, wybierając przycisk , aby otworzyć panel boczny.
Typ wykresu: określa typ wykresu. Wybierz między wykresami agregowanymi (wykresami słupkowymi) lub poszczególnymi punktami danych (wykres punktowy).
Wybierając opcję Poszczególne punkty danych w obszarze Typ wykresu, możesz przejść do widoku rozagregowanego danych z dostępnością osi kolorów.

Znaczenie funkcji (wyjaśnienia modelu)
Korzystając ze składnika wyjaśnienia modelu, możesz zobaczyć, które funkcje były najważniejsze w przewidywaniach modelu. Możesz wyświetlić, jakie funkcje mają wpływ na ogólną prognozę modelu w okienku Agregacja ważności funkcji lub wyświetlić znaczenie funkcji dla poszczególnych punktów danych w okienku Ważność poszczególnych funkcji .
Agregowanie ważności cech (wyjaśnienia globalne)

Najważniejsze funkcje k: Wyświetla listę najważniejszych funkcji globalnych przewidywania i umożliwia jej zmianę przy użyciu paska suwaka.
Zagregowane znaczenie cech: wizualizuje wagę każdej funkcji, wpływając na decyzje dotyczące modelu we wszystkich przewidywaniach.
Sortuj według: umożliwia wybranie ważności kohorty w celu posortowania wykresu ważności funkcji agregacji według.
Typ wykresu: umożliwia wybranie między widokiem wykresu słupkowego średniego znaczenia dla każdej funkcji i wykresem pola ważności dla wszystkich danych.
Po wybraniu jednej z funkcji na wykresie słupka wykres zależności jest wypełniany, jak pokazano na poniższej ilustracji. Wykres zależności przedstawia relację wartości funkcji z odpowiadającymi jej wartościami ważności cech, które mają wpływ na przewidywanie modelu.
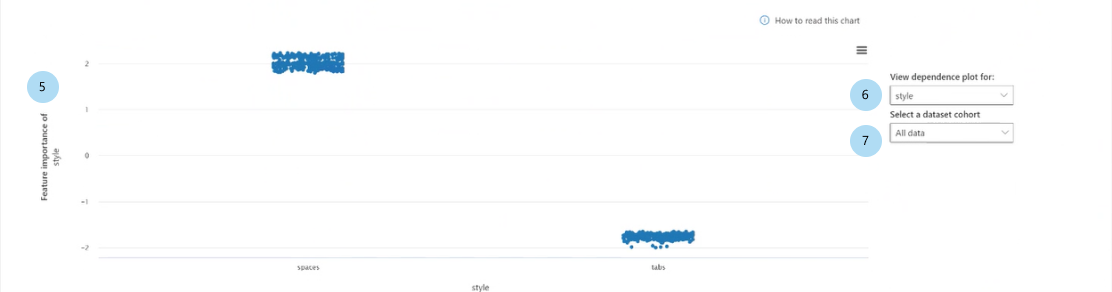
Znaczenie funkcji [feature] (regresja) lub Ważność funkcji [feature] w [przewidywanej klasie] (klasyfikacja): kreśli znaczenie konkretnej funkcji w przewidywaniach. W przypadku scenariuszy regresji wartości ważności są pod względem danych wyjściowych, więc pozytywne znaczenie cech oznacza, że pozytywnie przyczyniły się do danych wyjściowych. Odwrotnie ma zastosowanie do negatywnego znaczenia funkcji. W przypadku scenariuszy klasyfikacji pozytywne znaczenie cech oznacza, że wartość funkcji przyczynia się do przewidywanej klasy oznaczonej tytułem osi y. Negatywne znaczenie cech oznacza, że przyczynia się do przewidywanej klasy.
Wyświetl wykres zależności dla: wybiera funkcję, której znaczenie chcesz wykreślić.
Wybierz kohortę zestawu danych: wybiera kohortę, której znaczenie chcesz wykreślić.

Znaczenie poszczególnych cech (wyjaśnienia lokalne)
Na poniższej ilustracji pokazano, jak funkcje wpływają na przewidywania, które są wykonywane na określonych punktach danych. Możesz wybrać maksymalnie pięć punktów danych, aby porównać znaczenie funkcji.

Tabela wyboru punktów: wyświetl punkty danych i wybierz maksymalnie pięć punktów do wyświetlenia na wykresie ważności funkcji lub wykresie ICE poniżej tabeli.

Wykres ważności funkcji: wykres słupkowy o znaczeniu każdej funkcji dla przewidywania modelu dla wybranych punktów danych.
- Najważniejsze funkcje k: umożliwia określenie liczby funkcji, które mają pokazywać znaczenie za pomocą suwaka.
- Sortuj według: Umożliwia wybranie punktu (z zaznaczonych powyżej), którego znaczenie funkcji są wyświetlane w kolejności malejącej na wykresie ważności funkcji.
- Wyświetl wartości bezwzględne: przełącz się, aby posortować wykres słupkowy według wartości bezwzględnych. Dzięki temu można zobaczyć najbardziej wpływowe funkcje niezależnie od ich pozytywnego lub negatywnego kierunku.
- Wykres słupkowy: wyświetla znaczenie każdej funkcji w zestawie danych na potrzeby przewidywania modelu wybranych punktów danych.
Wykres indywidualnego oczekiwania warunkowego (ICE): przełącza się na wykres ICE, który przedstawia przewidywania modelu dla zakresu wartości określonej funkcji.

- Minimalna (cechy liczbowe): określa dolną granicę zakresu przewidywań na wykresie ICE.
- Max (cechy liczbowe): określa górną granicę zakresu przewidywań na wykresie ICE.
- Kroki (cechy liczbowe): określa liczbę punktów do pokazania przewidywań dla przedziału czasu.
- Wartości cech (funkcje podzielone na kategorie): określa, które wartości cech kategorii mają pokazywać przewidywania.
- Funkcja: określa funkcję do przewidywania.
Kontraktualne analizy warunkowe
Analiza kontraktualna udostępnia zróżnicowany zestaw przykładów analizy warunkowej generowanych przez zmianę wartości funkcji minimalnie w celu utworzenia żądanej klasy przewidywania (klasyfikacji) lub zakresu (regresja).

Wybór punktu: wybiera punkt, aby utworzyć licznik dla i wyświetlić go w wykresie funkcji najwyższego rankingu poniżej.
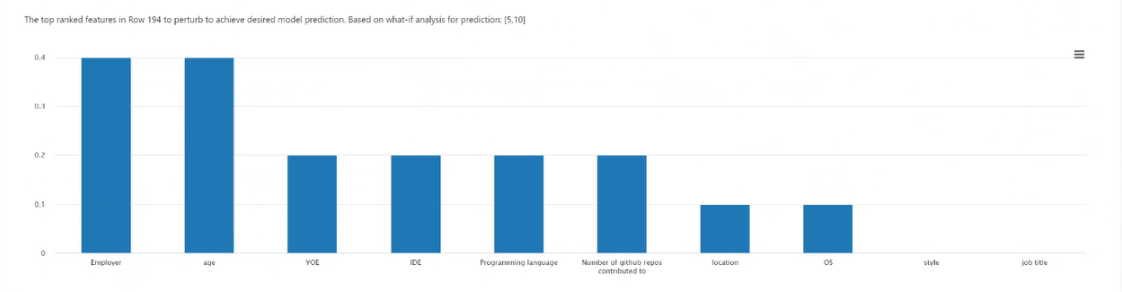
Wykres funkcji o najwyższej klasyfikacji: Wyświetla w kolejności malejącej średniej częstotliwości funkcje, które mają zostać wypaczane w celu utworzenia zróżnicowanego zestawu kontraktów żądanej klasy. Aby włączyć ten wykres, musisz wygenerować co najmniej 10 różnych kontraktów na punkt danych, ponieważ brakuje dokładności z mniejszą liczbą kontraktualistów.
Wybrany punkt danych: wykonuje tę samą akcję co wybór punktu w tabeli, z wyjątkiem menu rozwijanego.
Żądana klasa dla kontraktów: określa klasę lub zakres, dla którego mają być generowane liczniki.
Tworzenie warunkowego licznika: otwiera panel umożliwiający utworzenie punktu danych warunkowego analizy warunkowej.
Wybierz przycisk Create what-if counterfactual (Utwórz co-jeżeli), aby otworzyć panel pełnego okna.
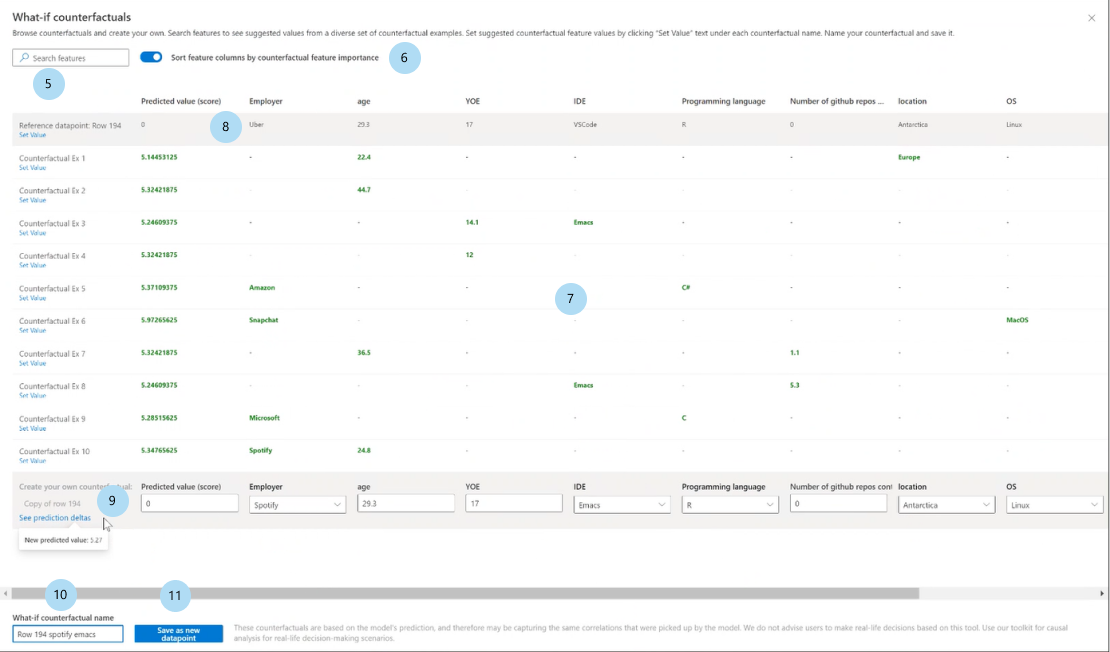
Funkcje wyszukiwania: znajduje funkcje do obserwowania i zmieniania wartości.
Sortuj counterfactual według sklasyfikowanych funkcji: Sortuje przykłady counterfactual w kolejności efektu perturbacji. (Zobacz teżNajwyżej sklasyfikowany wykres funkcji, omówiony wcześniej).
Przykłady alternatywne: wyświetla listę wartości cech przykładowych kontraktów z żądaną klasą lub zakresem. Pierwszy wiersz jest oryginalnym punktem danych referencyjnych. Wybierz pozycję Ustaw wartość , aby ustawić wszystkie wartości własnego punktu danych counterfactual w dolnym wierszu z wartościami wstępnie wygenerowanego przykładu counterfactual.
Przewidywana wartość lub klasa: Wyświetla prognozę modelu klasy counterfactual, biorąc pod uwagę te zmienione funkcje.
Utwórz własny kontraktykalny: umożliwia wypaczenie własnych funkcji w celu zmodyfikowania kontrataku. Funkcje, które zostały zmienione z oryginalnej wartości funkcji, są oznaczane pogrubionym tytułem (na przykład pracodawcą i językiem programowania). Wybierz pozycję Zobacz różnicę przewidywania, aby wyświetlić różnicę w nowej wartości przewidywania z oryginalnego punktu danych.
Nazwa warunkowa warunkowa: umożliwia unikatowe nadawanie nazwy counterfactual.
Zapisz jako nowy punkt danych: zapisuje utworzony licznik.


Analiza przyczynowa
W następnych sekcjach opisano sposób odczytywania analizy przyczynowej zestawu danych w przypadku wybierania metod leczenia określonego przez użytkownika.
Zagregowane skutki przyczynowe
Wybierz kartę Zagregowane skutki przyczynowe składnika analizy przyczynowej, aby wyświetlić średnie skutki przyczynowe dla wstępnie zdefiniowanych cech leczenia (cechy, które mają być traktowane w celu optymalizacji wyniku).
Uwaga
Globalne funkcje kohorty nie są obsługiwane dla składnika analizy przyczynowej.

Tabela bezpośrednich zagregowanych efektów przyczynowych: przedstawia przyczynowy wpływ każdej funkcji zagregowanej na cały zestaw danych i skojarzone statystyki ufności.
- Leczenie ciągłe: średnio w tej próbie zwiększenie tej funkcji o jedną jednostkę spowoduje zwiększenie prawdopodobieństwa zwiększenia klasy o jednostki X, gdzie X jest skutkiem przyczynowym.
- Zabiegi binarne: średnio w tej próbce włączenie tej funkcji spowoduje zwiększenie prawdopodobieństwa zwiększenia klasy o jednostki X, gdzie X jest skutkiem przyczynowym.
Wykres wąsów bezpośrednich zagregowanych przyczynowych: wizualizuje skutki przyczynowe i interwały ufności punktów w tabeli.
Skutki przyczynowe i przyczynowe analizy warunkowej
Aby uzyskać szczegółowy wgląd w wpływ przyczynowy na pojedynczy punkt danych, przejdź do karty Analizy przyczynowe poszczególnych przyczyn.

- Oś X: wybiera funkcję do wykreślenia na osi x.
- Oś Y: wybiera funkcję do wykreślenia na osi y.
- Pojedynczy wykres punktowy przyczynowy: wizualizowanie punktów w tabeli jako wykresu punktowego w celu wybrania punktów danych do analizy przyczynowej analizy przyczynowej co-jeżeli i wyświetlenia poszczególnych skutków przyczynowych poniżej.
- Ustaw nową wartość leczenia:
- (liczbowe): Przedstawia suwak, aby zmienić wartość funkcji liczbowej jako interwencję w świecie rzeczywistym.
- (kategorialne): Pokazuje listę rozwijaną, aby wybrać wartość funkcji kategorii.
Zasady leczenia
Wybierz kartę Zasady leczenia, aby przełączyć się do widoku, aby pomóc określić rzeczywiste interwencje i pokazać zabiegi, które mają być stosowane w celu osiągnięcia określonego wyniku.

Ustaw funkcję leczenia: wybiera funkcję, która zostanie zmieniona jako interwencja w świecie rzeczywistym.
Zalecane globalne zasady leczenia: wyświetla zalecane interwencje dla kohort danych w celu poprawy wartości docelowej funkcji. Tabela może być odczytywana od lewej do prawej, gdzie segmentacja zestawu danych jest najpierw w wierszach, a następnie w kolumnach. Na przykład w przypadku 658 osób, których pracodawca nie jest Snapchatem i którego językiem programowania nie jest JavaScript, zalecaną polityką leczenia jest zwiększenie liczby repozytoriów GitHub.
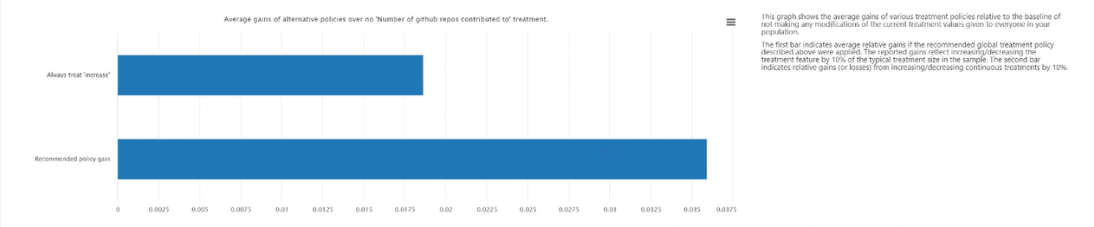
Średnie zyski z zasad alternatywnych w stosunku do zawsze stosowanego leczenia: Wykreśli wartość funkcji docelowej na wykresie słupkowym średniego zysku w wyniku dla powyższych zalecanych zasad leczenia w porównaniu z zawsze stosowaniem leczenia.
Zalecane indywidualne zasady leczenia:
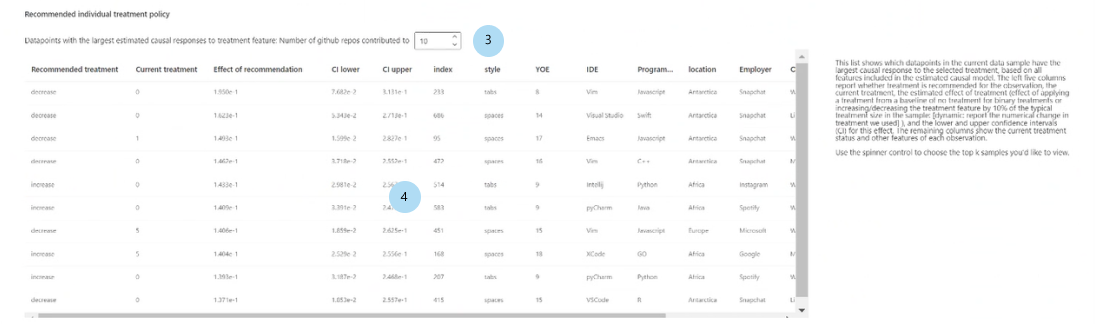
Pokaż najlepsze k próbki punktów danych uporządkowane według skutków przyczynowych dla zalecanej funkcji leczenia: wybiera liczbę punktów danych do pokazania w tabeli.
Zalecana tabela zasad leczenia indywidualnego: listy, w kolejności malejącej skutku przyczynowego, punkty danych, których cechy docelowe byłyby najbardziej ulepszone przez interwencję.


Następne kroki
- Podsumuj i udostępnij szczegółowe informacje o odpowiedzialnej sztucznej inteligencji za pomocą karty wyników odpowiedzialnej sztucznej inteligencji jako eksportu w formacie PDF.
- Dowiedz się więcej o pojęciach i technikach związanych z pulpitem nawigacyjnym odpowiedzialnej sztucznej inteligencji.
- Wyświetl przykładowe notesy YAML i Python, aby wygenerować pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji przy użyciu języka YAML lub Python.
- Zapoznaj się z funkcjami pulpitu nawigacyjnego Odpowiedzialne używanie sztucznej inteligencji za pomocą tego interaktywnego pokazu internetowego laboratorium sztucznej inteligencji.
- Dowiedz się więcej o sposobie używania pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji i karty wyników do debugowania danych i modeli oraz informowania o lepszym podejmowaniu decyzji w tym wpisie w blogu społeczności technicznej.
- Dowiedz się, jak pulpit nawigacyjny i karta wyników odpowiedzialnej sztucznej inteligencji były używane przez brytyjski narodowy Usługa kondycji (NHS) w prawdziwej historii klienta.