Ocena systemów sztucznej inteligencji przy użyciu pulpitu nawigacyjnego Odpowiedzialne używanie sztucznej inteligencji
Implementowanie odpowiedzialnej sztucznej inteligencji w praktyce wymaga rygorystycznej inżynierii. Jednak rygorystyczna inżynieria może być żmudna, ręczna i czasochłonna bez odpowiednich narzędzi i infrastruktury.
Pulpit nawigacyjny Odpowiedzialne używanie sztucznej inteligencji udostępnia jeden interfejs, który ułatwia efektywne i wydajne wdrażanie odpowiedzialnej sztucznej inteligencji. Łączy ona kilka dojrzałych narzędzi odpowiedzialnej sztucznej inteligencji w następujących obszarach:
- Ocena wydajności i sprawiedliwości modelu
- eksploracja danych
- Możliwość interpretacji uczenia maszynowego
- Analiza błędów
- Analiza kontraktualna i perturbacje
- Wnioskowanie przyczynowe
Pulpit nawigacyjny oferuje całościową ocenę i debugowanie modeli, dzięki czemu można podejmować świadome decyzje oparte na danych. Dostęp do wszystkich tych narzędzi w jednym interfejsie umożliwia:
Oceń i debuguj modele uczenia maszynowego, identyfikując błędy modelu i problemy z sprawiedliwością, diagnozując, dlaczego te błędy występują, i informując o krokach ograniczania ryzyka.
Zwiększ możliwości podejmowania decyzji opartych na danych, odpowiadając na pytania, takie jak:
"Jaka jest minimalna zmiana, którą użytkownicy mogą zastosować do swoich funkcji, aby uzyskać inny wynik od modelu?"
"Jaki jest przyczynowy wpływ zmniejszenia lub zwiększenia funkcji (na przykład czerwonego spożycia mięsa) na rzeczywisty wynik (na przykład progresja cukrzycy)?"
Pulpit nawigacyjny można dostosować tak, aby zawierał tylko podzbiór narzędzi, które są istotne dla danego przypadku użycia.
Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji jest dołączony do karty wyników w formacie PDF. Karta wyników umożliwia eksportowanie metadanych odpowiedzialnej sztucznej inteligencji i wglądu w dane i modele. Następnie możesz udostępnić je w trybie offline uczestnikom projektu produktu i zgodności.
Składniki pulpitu nawigacyjnego odpowiedzialnego używania sztucznej inteligencji
Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji łączy się w kompleksowym widoku różnych nowych i wstępnie istniejących narzędzi. Pulpit nawigacyjny integruje te narzędzia z interfejsem wiersza polecenia platformy Azure Edukacja w wersji 2, zestawem Azure Machine Edukacja Python SDK w wersji 2 i programem Azure Machine Edukacja Studio. Narzędzia te zawierają następujące składniki:
- Analiza danych, aby zrozumieć i eksplorować dystrybucje i statystyki zestawu danych.
- Przegląd modelu i ocena sprawiedliwości, aby ocenić wydajność modelu i ocenić problemy z sprawiedliwością grupy modelu (jak przewidywania modelu wpływają na różne grupy osób).
- Analiza błędów, aby wyświetlić i zrozumieć, jak błędy są dystrybuowane w zestawie danych.
- Możliwość interpretacji modelu (wartości ważności dla agregacji i poszczególnych cech), aby zrozumieć przewidywania modelu oraz sposób ich opracowywania ogólnych i indywidualnych przewidywań.
- Kontraktualne analizy co-jeżeli, aby zaobserwować, jak perturbacje funkcji miałyby wpływ na przewidywania modelu przy jednoczesnym zapewnieniu najbliższych punktów danych z przeciwstawnymi lub różnymi przewidywaniami modelu.
- Analiza przyczynowa, aby użyć danych historycznych w celu wyświetlenia przyczynowych skutków leczenia cech rzeczywistych.
Te narzędzia ułatwiają debugowanie modeli uczenia maszynowego przy jednoczesnym informowaniu o decyzjach biznesowych opartych na danych i opartych na modelu. Na poniższym diagramie pokazano, jak można je uwzględnić w cyklu życia sztucznej inteligencji, aby poprawić modele i uzyskać solidne szczegółowe informacje o danych.
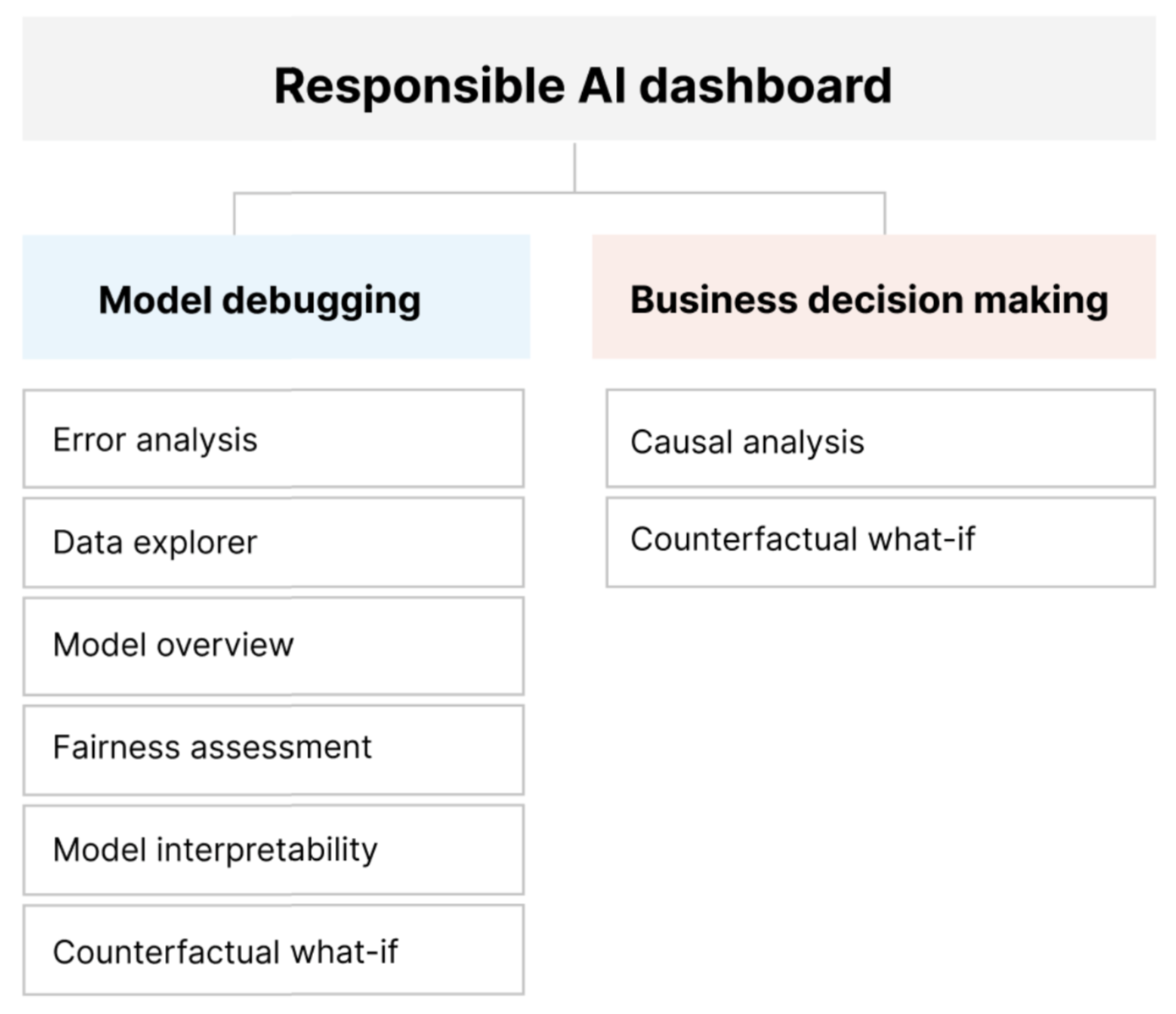
Debugowanie modelu
Ocenianie i debugowanie modeli uczenia maszynowego ma kluczowe znaczenie dla niezawodności modelu, możliwości interpretacji, sprawiedliwości i zgodności. Pomaga określić, jak i dlaczego systemy sztucznej inteligencji zachowują się tak, jak działają. Następnie możesz użyć tej wiedzy, aby zwiększyć wydajność modelu. Koncepcyjnie debugowanie modelu składa się z trzech etapów:
Zidentyfikuj, aby zrozumieć i rozpoznać błędy modelu i/lub problemy z sprawiedliwością, odpowiadając na następujące pytania:
"Jakie rodzaje błędów ma mój model?"
"W jakich obszarach błędy są najbardziej powszechne?"
Zdiagnozuj, aby zbadać przyczyny zidentyfikowanych błędów, zwracając się do:
"Jakie są przyczyny tych błędów?"
"Gdzie należy skupić swoje zasoby, aby ulepszyć model?"
Zniweluj problem, aby użyć szczegółowych informacji dotyczących identyfikacji i diagnostyki z poprzednich etapów, aby wykonać ukierunkowane kroki zaradcze i rozwiązać takie pytania, jak:
"Jak mogę ulepszyć model?"
"Jakie rozwiązania społeczne lub techniczne istnieją dla tych problemów?"

W poniższej tabeli opisano, kiedy używać składników pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji do obsługi debugowania modelu:
| Etap | Składnik | opis |
|---|---|---|
| Określ | Analiza błędów | Składnik analizy błędów pomaga lepiej zrozumieć rozkład awarii modelu i szybko zidentyfikować błędne kohorty (podgrupy) danych. Możliwości tego składnika na pulpicie nawigacyjnym pochodzą z pakietu Analiza błędów. |
| Określ | Analiza sprawiedliwości | Składnik sprawiedliwości definiuje grupy pod względem poufnych atrybutów, takich jak płeć, rasa i wiek. Następnie ocenia, w jaki sposób przewidywania modelu wpływają na te grupy i jak można wyeliminować różnice. Ocenia wydajność modelu, eksplorując dystrybucję wartości przewidywania i wartości metryk wydajności modelu w grupach. Możliwości tego składnika na pulpicie nawigacyjnym pochodzą z pakietu Fairlearn . |
| Określ | Omówienie modelu | Składnik przeglądu modelu agreguje metryki oceny modelu w ogólnym widoku dystrybucji przewidywania modelu w celu lepszego zbadania wydajności. Ten składnik umożliwia również ocenę sprawiedliwości grup przez wyróżnienie podziału wydajności modelu między poufnymi grupami. |
| Zdiagnozować | Analiza danych | Analiza danych wizualizuje zestawy danych na podstawie przewidywanych i rzeczywistych wyników, grup błędów i określonych funkcji. Następnie można zidentyfikować problemy z nadmiernym przedstawianiem i niedoreprezentacją, a także zobaczyć, jak dane są klastrowane w zestawie danych. |
| Diagnozuj | Możliwość interpretowania modelu | Składnik możliwości interpretacji generuje zrozumiałe dla człowieka wyjaśnienia przewidywań modelu uczenia maszynowego. Zapewnia wiele widoków w zachowaniu modelu: - Globalne wyjaśnienia (na przykład, które funkcje wpływają na ogólne zachowanie modelu alokacji pożyczki) - Lokalne wyjaśnienia (na przykład dlaczego wniosek o pożyczkę wnioskodawcy został zatwierdzony lub odrzucony) Możliwości tego składnika na pulpicie nawigacyjnym pochodzą z pakietu InterpretML . |
| Diagnozuj | Analiza kontraktualna i analizy warunkowe | Ten składnik składa się z dwóch funkcji w celu uzyskania lepszej diagnostyki błędów: — Generowanie zestawu przykładów, w których minimalne zmiany w określonym punkcie zmieniają przewidywanie modelu. Oznacza to, że w przykładach pokazano najbliższe punkty danych z przeciwnymi przewidywaniami modelu. — Włączanie interakcyjnych i niestandardowych zagnieżdżenia warunkowych dla poszczególnych punktów danych w celu zrozumienia, w jaki sposób model reaguje na zmiany funkcji. Możliwości tego składnika na pulpicie nawigacyjnym pochodzą z pakietu DiCE . |
Kroki ograniczania ryzyka są dostępne za pośrednictwem autonomicznych narzędzi, takich jak Fairlearn. Aby uzyskać więcej informacji, zobacz algorytmy ograniczania niesprawiedliwości.
Odpowiedzialne podejmowanie decyzji
Podejmowanie decyzji jest jednym z największych obietnic uczenia maszynowego. Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji może pomóc w podejmowaniu świadomych decyzji biznesowych za pomocą następujących czynności:
Szczegółowe informacje oparte na danych, aby lepiej zrozumieć wpływ leczenia przyczynowego na wynik przy użyciu tylko danych historycznych. Na przykład:
"Jak lek wpłynie na ciśnienie krwi pacjenta?"
"W jaki sposób dostarczanie wartości promocyjnych niektórym klientom wpływa na przychody?"
Te szczegółowe informacje są udostępniane za pośrednictwem składnika wnioskowania przyczynowego pulpitu nawigacyjnego.
Szczegółowe informacje oparte na modelu, aby odpowiedzieć na pytania użytkowników (takie jak "Co mogę zrobić, aby uzyskać inny wynik od sztucznej inteligencji przy następnym razem?"), aby mogli podjąć działania. Te szczegółowe informacje są udostępniane analitykom danych za pośrednictwem alternatywnego składnika analizy warunkowej .

Eksploracyjna analiza danych, wnioskowanie przyczynowe i możliwości analizy kontrakcyjnej mogą pomóc w odpowiedzialnym podejmowaniu świadomych decyzji opartych na modelu i decyzjach opartych na danych.
Te składniki pulpitu nawigacyjnego odpowiedzialnego używania sztucznej inteligencji obsługują odpowiedzialne podejmowanie decyzji:
Analiza danych: możesz ponownie użyć składnika analizy danych w tym miejscu, aby zrozumieć dystrybucje danych i zidentyfikować nadmierne przedstawianie i niedostateczne przedstawianie. Eksploracja danych jest krytyczną częścią podejmowania decyzji, ponieważ nie jest możliwe podejmowanie świadomych decyzji dotyczących kohorty, która jest niedostatecznie reprezentowana w danych.
Wnioskowanie przyczynowe: składnik wnioskowania przyczynowego szacuje, w jaki sposób rzeczywisty wynik zmienia się w obecności interwencji. Pomaga również w konstruowaniu obiecujących interwencji poprzez symulowanie reakcji cech na różne interwencje i tworzenie zasad w celu określenia, które kohorty ludności skorzystałyby z konkretnej interwencji. Zbiorczo te funkcje umożliwiają stosowanie nowych zasad i wprowadzanie rzeczywistych zmian.
Możliwości tego składnika pochodzą z pakietu EconML , który szacuje heterogeniczne efekty leczenia z danych obserwacyjnych za pośrednictwem uczenia maszynowego.
Analiza antyraktualna: w tym miejscu można ponownie użyć składnika analizy kontraktualnej, aby wygenerować minimalne zmiany zastosowane do funkcji punktu danych, które prowadzą do przeciwnych przewidywań modelu. Na przykład: Taylor uzyskałby zgodę na pożyczkę ze sztucznej inteligencji, jeśli zarobili 10 000 USD więcej w rocznym dochodzie i mieliby dwie mniej otwartych kart kredytowych.
Podanie tych informacji użytkownikom informuje ich perspektywę. Uczy ich, jak mogą podejmować działania, aby uzyskać pożądany wynik od sztucznej inteligencji w przyszłości.
Możliwości tego składnika pochodzą z pakietu DiCE .
Przyczyny korzystania z pulpitu nawigacyjnego Odpowiedzialne używanie sztucznej inteligencji
Chociaż poczyniono postępy w poszczególnych narzędziach dla określonych obszarów odpowiedzialnej sztucznej inteligencji, analitycy danych często muszą używać różnych narzędzi do holistycznej oceny modeli i danych. Na przykład: może być konieczne użycie razem oceny interpretacji modelu i sprawiedliwości.
Jeśli analitycy danych odkryją problem z sprawiedliwością z jednym narzędziem, muszą przejść do innego narzędzia, aby zrozumieć, jakie czynniki danych lub modeli leżą u podstaw problemu przed podjęciem jakichkolwiek kroków w zakresie ograniczania ryzyka. Następujące czynniki jeszcze bardziej komplikują ten trudny proces:
- Nie ma centralnej lokalizacji do odkrywania i poznawania narzędzi, wydłużając czas potrzebny na badania i poznawanie nowych technik.
- Różne narzędzia nie komunikują się ze sobą. Analitycy danych muszą rozmieścić zestawy danych, modele i inne metadane podczas przekazywania ich między narzędziami.
- Metryki i wizualizacje nie są łatwo porównywalne, a wyniki są trudne do udostępnienia.
Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji wymaga tego status quo. Jest to kompleksowe, ale dostosowywalne narzędzie, które łączy fragmentowane środowiska w jednym miejscu. Umożliwia ona bezproblemowe dołączanie do jednej, dostosowywalnej struktury na potrzeby debugowania modelu i podejmowania decyzji opartych na danych.
Korzystając z pulpitu nawigacyjnego Odpowiedzialne używanie sztucznej inteligencji, możesz tworzyć kohorty zestawów danych, przekazywać te kohorty do wszystkich obsługiwanych składników i obserwować kondycję modelu dla zidentyfikowanych kohort. Możesz dokładniej porównać szczegółowe informacje ze wszystkich obsługiwanych składników w różnych wstępnie utworzonych kohortach, aby przeprowadzić analizę rozagregowaną i znaleźć martwe plamy modelu.
Gdy wszystko będzie gotowe do udostępnienia tych szczegółowych informacji innym uczestnikom projektu, możesz je łatwo wyodrębnić przy użyciu karty wyników w formacie PDF odpowiedzialnej sztucznej inteligencji. Dołącz raport PDF do raportów zgodności lub udostępnij go współpracownikom, aby utworzyć zaufanie i uzyskać ich zatwierdzenie.
Sposoby dostosowywania pulpitu nawigacyjnego Odpowiedzialne używanie sztucznej inteligencji
Siła pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji leży w jego możliwości dostosowywania. Umożliwia ona użytkownikom projektowanie dostosowanych, kompleksowego debugowania modeli i przepływów pracy podejmowania decyzji, które odpowiadają ich konkretnym potrzebom.
Potrzebujesz inspiracji? Poniżej przedstawiono kilka przykładów sposobu łączenia składników pulpitu nawigacyjnego w celu analizowania scenariuszy na różne sposoby:
| Przepływ odpowiedzialnego pulpitu nawigacyjnego sztucznej inteligencji | Przypadek użycia |
|---|---|
| Analiza danych analizy błędów w > modelu — omówienie > | Aby zidentyfikować błędy modelu i zdiagnozować je, rozumiejąc podstawową dystrybucję danych |
| Analiza danych oceny sprawiedliwości w modelu > — omówienie > | Aby zidentyfikować problemy z uczciwością modelu i zdiagnozować je, rozumiejąc podstawową dystrybucję danych |
| > Omówienie analizy błędów analizy > błędów i analizy co-jeżeli | Aby zdiagnozować błędy w poszczególnych wystąpieniach przy użyciu analizy kontraktualnej (minimalna zmiana prowadząca do innego przewidywania modelu) |
| Analiza danych z omówieniem > modelu | Aby zrozumieć główną przyczynę błędów i problemów z sprawiedliwością wprowadzonych za pośrednictwem dysproporcji danych lub braku reprezentacji określonej kohorty danych |
| Omówienie > możliwości interpretacji modelu | Aby zdiagnozować błędy modelu poprzez zrozumienie sposobu, w jaki model dokonał przewidywań |
| Wnioskowanie przyczynowe analizy danych > | Aby odróżnić korelacje i przyczynowe w danych lub zdecydować, które najlepsze metody leczenia mają być stosowane w celu uzyskania pozytywnego wyniku |
| Wnioskowanie przyczynowe z interpretacją > | Aby dowiedzieć się, czy czynniki używane przez model do prognozowania mają jakikolwiek wpływ przyczynowy na rzeczywisty wynik |
| Analiza liczników analizy > danych i analizy warunkowej | Aby rozwiązać pytania klientów dotyczące tego, co mogą zrobić następnym razem, aby uzyskać inny wynik od systemu sztucznej inteligencji |
Osoby, kto powinien korzystać z pulpitu nawigacyjnego Odpowiedzialne używanie sztucznej inteligencji
Następujące osoby mogą używać pulpitu nawigacyjnego Odpowiedzialne użycie sztucznej inteligencji i odpowiadającej jej karty wyników odpowiedzialnej sztucznej inteligencji w celu budowania zaufania z systemami sztucznej inteligencji:
- Specjaliści ds. uczenia maszynowego i analitycy danych zainteresowani debugowaniem i ulepszaniem modeli uczenia maszynowego przed wdrożeniem
- Specjaliści ds. uczenia maszynowego i analitycy danych, którzy są zainteresowani udostępnianiem swoich rekordów kondycji modelu menedżerom produktów i uczestnikom biznesowym w celu budowania zaufania i otrzymywania uprawnień do wdrażania
- Menedżerowie produktów i osoby biorące udział w projekcie, którzy przeglądają modele uczenia maszynowego przed wdrożeniem
- Pracownicy zajmujący się ryzykiem, którzy przeglądają modele uczenia maszynowego, aby zrozumieć problemy z sprawiedliwością i niezawodnością
- Dostawcy rozwiązań sztucznej inteligencji, którzy chcą wyjaśnić decyzje dotyczące modelu użytkownikom lub pomóc im poprawić wynik
- Specjaliści w ściśle regulowanych przestrzeniach, którzy muszą przeglądać modele uczenia maszynowego za pomocą regulatorów i audytorów
Obsługiwane scenariusze i ograniczenia
- Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji obsługuje obecnie modele regresji i klasyfikacji (binarne i wieloklasowe) trenowane na tabelarycznych danych ustrukturyzowanych.
- Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji obsługuje obecnie modele MLflow zarejestrowane w usłudze Azure Machine Edukacja za pomocą sklearn (scikit-learn). Modele scikit-learn powinny implementować
predict()/predict_proba()metody lub model powinien być opakowany w klasie, która implementujepredict()/predict_proba()metody. Modele muszą być ładowalne w środowisku składników i muszą być możliwe do wyboru. - Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji obecnie wizualizuje maksymalnie 5 000 punktów danych w interfejsie użytkownika pulpitu nawigacyjnego. Przed przekazaniem go do pulpitu nawigacyjnego należy obniżyć rozmiar zestawu danych do rozmiaru 5K lub mniej.
- Dane wejściowe zestawu danych do pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji muszą być ramkami danych pandas w formacie Parquet. Pliki NumPy i SciPy rozrzedliwe dane nie są obecnie obsługiwane.
- Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji obsługuje obecnie funkcje liczbowe lub podzielone na kategorie. W przypadku funkcji kategorii użytkownik musi jawnie określić nazwy funkcji.
- Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji obecnie nie obsługuje zestawów danych z więcej niż 10 000 kolumn.
- Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji obecnie nie obsługuje modelu rozwiązania AutoML MLFlow.
- Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji obecnie nie obsługuje zarejestrowanych modeli automatycznego uczenia maszynowego z interfejsu użytkownika.
Następne kroki
- Dowiedz się, jak wygenerować pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji za pomocą interfejsu wiersza polecenia i zestawu SDK lub interfejsu użytkownika usługi Azure Machine Edukacja Studio.
- Dowiedz się, jak wygenerować kartę wyników odpowiedzialnej sztucznej inteligencji na podstawie szczegółowych informacji obserwowanych na pulpicie nawigacyjnym odpowiedzialnej sztucznej inteligencji.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla