Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Automatyzowanie wydajnego dostrajania hiperparametrów przy użyciu zestawu Azure Machine Learning SDK w wersji 2 i interfejsu wiersza polecenia w wersji 2 za pomocą typu SweepJob.
- Definiowanie miejsca wyszukiwania parametrów dla wersji próbnej
- Określanie algorytmu próbkowania dla zadania zamiatania
- Określanie celu optymalizacji
- Określanie zasad wczesnego zakończenia dla zadań o niskiej wydajności
- Definiowanie limitów dla zadania zamiatania
- Uruchamianie eksperymentu ze zdefiniowaną konfiguracją
- Wizualizowanie zadań szkoleniowych
- Wybierz najlepszą konfigurację modelu
Co to jest dostrajanie hiperparametrów?
Hiperparametry są regulowanymi parametrami , które umożliwiają sterowanie procesem trenowania modelu. Na przykład w przypadku sieci neuronowych decydujesz o liczbie ukrytych warstw i liczbie węzłów w każdej warstwie. Wydajność modelu zależy w dużym stopniu od hiperparametrów.
Dostrajanie hiperparametryczne, nazywane również optymalizacją hiperparametrów, jest procesem znajdowania konfiguracji hiperparametrów, które zapewniają najlepszą wydajność. Proces jest zazwyczaj kosztowny obliczeniowo i ręczny.
Usługa Azure Machine Learning umożliwia automatyzowanie dostrajania hiperparametrów i równoległe uruchamianie eksperymentów w celu wydajnego optymalizowania hiperparametrów.
Definiowanie przestrzeni wyszukiwania
Dostrajanie hiperparametrów przez eksplorowanie zakresu wartości zdefiniowanych dla każdego hiperparametru.
Hiperparametry mogą być dyskretne lub ciągłe i mają rozkład wartości opisanych przez wyrażenie parametru.
Dyskretne hiperparametry
Dyskretne hiperparametry są określane jako wartości Choice dyskretne.
Choice może to być:
- co najmniej jedna wartość rozdzielona przecinkami
-
rangeobiekt -
listdowolny obiekt
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32, 64, 128]),
number_of_hidden_layers=Choice(values=range(1,5)),
)
W tym przypadku jedna batch_size z wartości [16, 32, 64, 128] i number_of_hidden_layers przyjmuje jedną z wartości [1, 2, 3, 4].
Następujące zaawansowane hiperparametry dyskretne można również określić przy użyciu rozkładu:
-
QUniform(min_value, max_value, q)- Zwraca wartość, na przykład round(Uniform(min_value, max_value) / q) * q -
QLogUniform(min_value, max_value, q)- Zwraca wartość podobną do round(exp(Uniform(min_value, max_value)) / q) * q -
QNormal(mu, sigma, q)- Zwraca wartość podobną do round(Normal(mu, sigma) / q) * q -
QLogNormal(mu, sigma, q)- Zwraca wartość, na przykład round(exp(Normal(mu, sigma)) / q) * q
Hiperparametry ciągłe
Hiperparametry ciągłe są określane jako rozkład na ciągły zakres wartości:
-
Uniform(min_value, max_value)- Zwraca wartość równomiernie rozłożoną między min_value a max_value -
LogUniform(min_value, max_value)- Zwraca wartość rysowaną zgodnie z wyrażeniem (Uniform(min_value, max_value)), tak aby logarytm wartości zwracanej był równomiernie rozłożony -
Normal(mu, sigma)- Zwraca wartość rzeczywistą, która jest zwykle rozłożona ze średnią mu i odchylenie standardowe sigma -
LogNormal(mu, sigma)- Zwraca wartość narysowaną zgodnie z wyrażeniem (normal(mu, sigma)), tak aby logarytm wartości zwracanej był zwykle dystrybuowany
Przykład definicji przestrzeni parametrów:
from azure.ai.ml.sweep import Normal, Uniform
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
)
Ten kod definiuje przestrzeń wyszukiwania z dwoma parametrami — learning_rate i keep_probability.
learning_rate ma rozkład normalny o średniej wartości 10 i odchylenie standardowe 3.
keep_probability ma jednolity rozkład z minimalną wartością 0,05 i maksymalną wartością 0,1.
W przypadku interfejsu wiersza polecenia można użyć schematu YAML zadania zamiatania, aby zdefiniować przestrzeń wyszukiwania w pliku YAML:
search_space:
conv_size:
type: choice
values: [2, 5, 7]
dropout_rate:
type: uniform
min_value: 0.1
max_value: 0.2
Próbkowanie przestrzeni hiperparametrów
Określ metodę próbkowania parametrów do użycia w przestrzeni hiperparametrów. Usługa Azure Machine Learning obsługuje następujące metody:
- Losowe próbkowanie
- Próbkowanie siatki
- Próbkowanie Bayesowskie
Losowe próbkowanie
Losowe próbkowanie obsługuje dyskretne i ciągłe hiperparametry. Obsługuje wczesne zakończenie zadań o niskiej wydajności. Niektórzy użytkownicy wykonują wstępne wyszukiwanie przy użyciu losowego próbkowania, a następnie uściśliją przestrzeń wyszukiwania, aby poprawić wyniki.
W losowym próbkowaniu wartości hiperparametryczne są losowo wybierane ze zdefiniowanej przestrzeni wyszukiwania. Po utworzeniu zadania polecenia można użyć parametru zamiatania do zdefiniowania algorytmu próbkowania.
from azure.ai.ml.sweep import Normal, Uniform, RandomParameterSampling
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "random",
...
)
Sobol
Sobol to typ losowego próbkowania obsługiwanego przez typy zadań zamiatania. Można użyć sobol, aby odtworzyć wyniki za pomocą inicjacji i pokryć rozkład przestrzeni wyszukiwania bardziej równomiernie.
Aby użyć sobol, użyj klasy RandomParameterSampling, aby dodać inicjator i regułę, jak pokazano w poniższym przykładzie.
from azure.ai.ml.sweep import RandomParameterSampling
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = RandomParameterSampling(seed=123, rule="sobol"),
...
)
Próbkowanie siatki
Próbkowanie siatki obsługuje dyskretne hiperparametry. Użyj próbkowania siatki, jeśli możesz zastosować budżet, aby wyczerpująco przeszukiwać miejsce wyszukiwania. Obsługuje wczesne zakończenie zadań o niskiej wydajności.
Próbkowanie siatki wykonuje proste wyszukiwanie siatki na wszystkich możliwych wartościach. Próbkowanie siatki może być używane tylko z choice hiperparametrami. Na przykład następująca przestrzeń zawiera sześć przykładów:
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32]),
number_of_hidden_layers=Choice(values=[1,2,3]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "grid",
...
)
Próbkowanie Bayesowskie
Próbkowanie bayesowskie opiera się na algorytmie optymalizacji Bayesa. Wybiera próbki na podstawie sposobu, w jaki były poprzednie próbki, aby nowe próbki ulepszały metryki podstawowe.
Próbkowanie bayesowskie jest zalecane, jeśli masz wystarczający budżet, aby zbadać przestrzeń hiperparametrów. Aby uzyskać najlepsze wyniki, zalecamy maksymalną liczbę zadań większą lub równą 20-krotnej liczbie dostrojonych hiperparametrów.
Liczba współbieżnych zadań ma wpływ na skuteczność procesu dostrajania. Mniejsza liczba współbieżnych zadań może prowadzić do lepszej zbieżności próbkowania, ponieważ mniejszy stopień równoległości zwiększa liczbę miejsc pracy, które korzystają z poprzednio ukończonych zadań.
Próbkowanie bayesowskie obsługuje choicetylko dystrybucje , uniformi quniform w przestrzeni wyszukiwania.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
...
)
Określanie celu zamiatania
Zdefiniuj cel zadania zamiatania, określając podstawową metrykę i cel, który chcesz dostrajać hiperparametrów do optymalizacji. Każde zadanie trenowania jest oceniane dla metryki podstawowej. Zasady wczesnego zakończenia używają podstawowej metryki do identyfikowania zadań o niskiej wydajności.
-
primary_metric: Nazwa metryki podstawowej musi dokładnie odpowiadać nazwie metryki zarejestrowanej przez skrypt trenowania -
goal: Może to byćMaximizelubMinimizei określa, czy metryka podstawowa zostanie zmaksymalizowana, czy zminimalizowana podczas oceniania zadań.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
primary_metric="accuracy",
goal="Maximize",
)
Ten przykład maksymalizuje "dokładność".
Metryki dziennika na potrzeby dostrajania hiperparametrów
Skrypt trenowania dla modelu musi rejestrować metryki podstawowe podczas trenowania modelu przy użyciu tej samej odpowiedniej nazwy metryki, aby program SweepJob mógł uzyskać do niego dostęp w celu dostrajania hiperparametrów.
Zarejestruj metrykę podstawową w skrypcie trenowania przy użyciu następującego przykładowego fragmentu kodu:
import mlflow
mlflow.log_metric("accuracy", float(val_accuracy))
Skrypt trenowania oblicza val_accuracy i rejestruje go jako podstawową metryki "dokładność". Za każdym razem, gdy metryka jest rejestrowana, jest odbierana przez usługę dostrajania hiperparametrów. Zależy to od ciebie, aby określić częstotliwość raportowania.
Aby uzyskać więcej informacji na temat rejestrowania wartości zadań szkoleniowych, zobacz Włączanie rejestrowania w zadaniach szkoleniowych usługi Azure Machine Learning.
Określanie zasad wczesnego kończenia
Automatyczne kończenie zadań o niskiej wydajności przy użyciu zasad wczesnego kończenia. Wczesne zakończenie poprawia wydajność obliczeniową.
Można skonfigurować następujące parametry, które kontrolują zastosowanie zasad:
-
evaluation_interval: częstotliwość stosowania zasad. Za każdym razem, gdy skrypt trenowania rejestruje metryki podstawowe są liczone jako jeden interwał. Wartośćevaluation_interval1 będzie stosować zasady za każdym razem, gdy skrypt trenowania zgłasza metryki podstawowej. Wartośćevaluation_interval2 będzie stosować zasady za każdym razem. Jeśli nie zostanie określony,evaluation_intervaldomyślnie ustawiono wartość 0. -
delay_evaluation: opóźnia pierwszą ocenę zasad dla określonej liczby interwałów. Jest to opcjonalny parametr, który pozwala uniknąć przedwczesnego zakończenia zadań szkoleniowych, umożliwiając uruchamianie wszystkich konfiguracji dla minimalnej liczby interwałów. W przypadku określenia zasady stosują każdą wielokrotność evaluation_interval, która jest większa lub równa delay_evaluation. Jeśli nie zostanie określony,delay_evaluationdomyślnie ustawiono wartość 0.
Usługa Azure Machine Learning obsługuje następujące zasady wczesnego zakończenia:
Zasady bandytu
Zasady bandytu są oparte na współczynniku slack/slack ilość i interwał oceny. Zasady bandytu kończą zadanie, gdy podstawowa metryka nie mieści się w określonym współczynniku slack/slack największej liczby zadań, które zakończyły się powodzeniem.
Określ następujące parametry konfiguracji:
slack_factorlubslack_amount: luz dozwolony w odniesieniu do najlepiej działającej pracy szkoleniowej.slack_factorokreśla dozwolony luz jako stosunek.slack_amountokreśla dozwolony luz jako bezwzględną kwotę zamiast współczynnika.Rozważmy na przykład zastosowanie zasad bandytu w interwale 10. Załóżmy, że najlepiej działające zadanie w interwale 10 zgłosiło metrykę podstawową 0,8 z celem zmaksymalizowania podstawowej metryki. Jeśli zasady określają
slack_factorwartość 0,2, wszystkie zadania szkoleniowe, których najlepsza metryka w interwale 10 jest mniejsza niż 0,66 (0,8/(1+slack_factor)) zostanie zakończona.evaluation_interval: (opcjonalnie) częstotliwość stosowania zasaddelay_evaluation: (opcjonalnie) opóźnia pierwszą ocenę zasad dla określonej liczby interwałów
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(slack_factor = 0.1, delay_evaluation = 5, evaluation_interval = 1)
W tym przykładzie zasady wczesnego zakończenia są stosowane w każdym interwale, gdy są zgłaszane metryki, począwszy od interwału oceny 5. Wszystkie zadania, których najlepsza metryka jest mniejsza niż (1/(1+0,1) lub 91% najlepszych zadań, zostaną zakończone.
Mediana zatrzymywania zasad
Mediana zatrzymywania to zasady wczesnego zakończenia oparte na średnich uruchamiania podstawowych metryk zgłaszanych przez zadania. Ta zasada oblicza średnie uruchomione we wszystkich zadaniach szkoleniowych i zatrzymuje zadania, których podstawowa wartość metryki jest gorsza niż mediana średnich.
Te zasady mają następujące parametry konfiguracji:
-
evaluation_interval: częstotliwość stosowania zasad (opcjonalny parametr). -
delay_evaluation: opóźnia pierwszą ocenę zasad dla określonej liczby interwałów (parametr opcjonalny).
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(delay_evaluation = 5, evaluation_interval = 1)
W tym przykładzie zasady wczesnego zakończenia są stosowane w każdym interwale rozpoczynającym się od interwału oceny 5. Zadanie jest zatrzymywane w interwale 5, jeśli jego najlepsza podstawowa metryka jest gorsza niż mediana średnich uruchomionych w odstępach 1:5 we wszystkich zadaniach szkoleniowych.
Zasady wyboru obcięcia
Zaznaczenie obcinania anuluje procent zadań o najniższej wydajności w każdym interwale oceny. Zadania są porównywane przy użyciu podstawowej metryki.
Te zasady mają następujące parametry konfiguracji:
-
truncation_percentage: procent zadań o najniższej wydajności do zakończenia w każdym interwale oceny. Wartość całkowita z zakresu od 1 do 99. -
evaluation_interval: (opcjonalnie) częstotliwość stosowania zasad -
delay_evaluation: (opcjonalnie) opóźnia pierwszą ocenę zasad dla określonej liczby interwałów -
exclude_finished_jobs: określa, czy należy wykluczyć ukończone zadania podczas stosowania zasad
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
W tym przykładzie zasady wczesnego zakończenia są stosowane w każdym interwale rozpoczynającym się od interwału oceny 5. Zadanie kończy się w interwale 5, jeśli jego wydajność w interwale 5 mieści się w najniższym 20% wydajności wszystkich zadań w interwale 5 i wykluczy ukończone zadania podczas stosowania zasad.
Brak zasad zakończenia (ustawienie domyślne)
Jeśli nie określono żadnych zasad, usługa dostrajania hiperparametrów umożliwia wykonanie wszystkich zadań szkoleniowych do ukończenia.
sweep_job.early_termination = None
Wybieranie zasad wczesnego kończenia
- W przypadku konserwatywnej polityki, która zapewnia oszczędności bez kończenia obiecujących miejsc pracy, rozważ medianę zatrzymywania zasad z wartością
evaluation_interval1 idelay_evaluation5. Są to konserwatywne ustawienia, które mogą zapewnić około 25%-35% oszczędności bez utraty na podstawowej metryce (na podstawie naszych danych oceny). - Aby uzyskać bardziej agresywne oszczędności, użyj zasad bandytu z mniejszym dozwolonym luzem lub obcinanymi zasadami wyboru z większą wartością procentową obcięcia.
Ustawianie limitów dla zadania zamiatania
Kontroluj budżet zasobów, ustawiając limity dla zadania zamiatania.
-
max_total_trials: Maksymalna liczba zadań w wersji próbnej. Musi być liczbą całkowitą z zakresu od 1 do 1000. -
max_concurrent_trials: (opcjonalnie) Maksymalna liczba zadań próbnych, które mogą być uruchamiane współbieżnie. Jeśli nie zostanie określony, max_total_trials liczbę uruchomień zadań równolegle. W przypadku określenia musi być liczbą całkowitą z zakresu od 1 do 1000. -
timeout: Maksymalny czas w sekundach, w których można uruchomić całe zadanie zamiatania. Po osiągnięciu tego limitu system anuluje zadanie zamiatania, w tym wszystkie wersje próbne. -
trial_timeout: Maksymalny czas w sekundach każdego zadania w wersji próbnej może zostać uruchomiony. Po osiągnięciu tego limitu system anuluje wersję próbną.
Uwaga
Jeśli określono zarówno max_total_trials, jak i limit czasu, eksperyment dostrajania hiperparametrów kończy się po osiągnięciu pierwszego z tych dwóch progów.
Uwaga
Liczba współbieżnych zadań w wersji próbnej jest bramowana dla zasobów dostępnych w określonym docelowym obiekcie obliczeniowym. Upewnij się, że docelowy obiekt obliczeniowy ma dostępne zasoby dla żądanej współbieżności.
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=4, timeout=1200)
Ten kod umożliwia skonfigurowanie eksperymentu dostrajania hiperparametrów w celu użycia maksymalnie 20 całkowitych zadań próbnych, uruchamiając cztery zadania w wersji próbnej jednocześnie z limitem czasu wynoszącym 1200 sekund dla całego zadania zamiatania.
Konfigurowanie eksperymentu dostrajania hiperparametrów
Aby skonfigurować eksperyment dostrajania hiperparametrów, podaj następujące informacje:
- Zdefiniowana przestrzeń wyszukiwania hiperparametrów
- Algorytm próbkowania
- Zasady wczesnego zakończenia
- Twój cel
- Limity zasobów
- CommandJob lub CommandComponent
- Zamiatanie
Funkcja SweepJob może uruchamiać zamiatanie hiperparametrów w składniku polecenia lub polecenia.
Uwaga
Docelowy obiekt obliczeniowy używany w programie sweep_job musi mieć wystarczającą ilość zasobów, aby spełnić poziom współbieżności. Aby uzyskać więcej informacji na temat docelowych obiektów obliczeniowych, zobacz Obiekty docelowe obliczeń.
Skonfiguruj eksperyment dostrajania hiperparametrów:
from azure.ai.ml import MLClient
from azure.ai.ml import command, Input
from azure.ai.ml.sweep import Choice, Uniform, MedianStoppingPolicy
from azure.identity import DefaultAzureCredential
# Create your base command job
command_job = command(
code="./src",
command="python main.py --iris-csv ${{inputs.iris_csv}} --learning-rate ${{inputs.learning_rate}} --boosting ${{inputs.boosting}}",
environment="AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu@latest",
inputs={
"iris_csv": Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/iris.csv",
),
"learning_rate": 0.9,
"boosting": "gbdt",
},
compute="cpu-cluster",
)
# Override your inputs with parameter expressions
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.01, max_value=0.9),
boosting=Choice(values=["gbdt", "dart"]),
)
# Call sweep() on your command job to sweep over your parameter expressions
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm="random",
primary_metric="test-multi_logloss",
goal="Minimize",
)
# Specify your experiment details
sweep_job.display_name = "lightgbm-iris-sweep-example"
sweep_job.experiment_name = "lightgbm-iris-sweep-example"
sweep_job.description = "Run a hyperparameter sweep job for LightGBM on Iris dataset."
# Define the limits for this sweep
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=10, timeout=7200)
# Set early stopping on this one
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation=5, evaluation_interval=2
)
Element command_job jest wywoływany jako funkcja, aby można było zastosować wyrażenia parametrów do danych wejściowych zamiatania. Funkcja sweep jest następnie konfigurowana przy użyciu trialfunkcji , , sampling-algorithmobjective, limitsi compute. Powyższy fragment kodu jest pobierany z przykładowego notesu Run hyperparameter sweep on a CommandComponent (Polecenie lub PolecenieComponent). W tym przykładzie learning_rate parametry i boosting są dostrojone. Wczesne zatrzymywanie zadań jest określane przez MedianStoppingPolicyelement , który zatrzymuje zadanie, którego podstawowa wartość metryki jest gorsza niż mediana średnich we wszystkich zadaniach szkoleniowych.( zobacz MedianStoppingPolicy, odwołanie do klasy).
Aby zobaczyć, jak wartości parametrów są odbierane, analizowane i przekazywane do skryptu szkoleniowego, które mają zostać dostrojone, zapoznaj się z tym przykładem kodu
Ważne
Każde zadanie zamiatania hiperparametrów uruchamia trenowanie od podstaw, w tym ponowne kompilowanie modelu i wszystkich modułów ładujących dane. Ten koszt można zminimalizować przy użyciu potoku usługi Azure Machine Learning lub procesu ręcznego, aby wykonać jak najwięcej przygotowań danych przed zadaniami trenowania.
Przesyłanie eksperymentu dostrajania hiperparametrów
Po zdefiniowaniu konfiguracji dostrajania hiperparametrów prześlij zadanie:
# submit the sweep
returned_sweep_job = ml_client.create_or_update(sweep_job)
# get a URL for the status of the job
returned_sweep_job.services["Studio"].endpoint
Wizualizowanie zadań dostrajania hiperparametrów
Wszystkie zadania dostrajania hiperparametrów można wizualizować w usłudze Azure Machine Learning Studio. Aby uzyskać więcej informacji na temat wyświetlania eksperymentu w portalu, zobacz Wyświetlanie rekordów zadań w programie Studio.
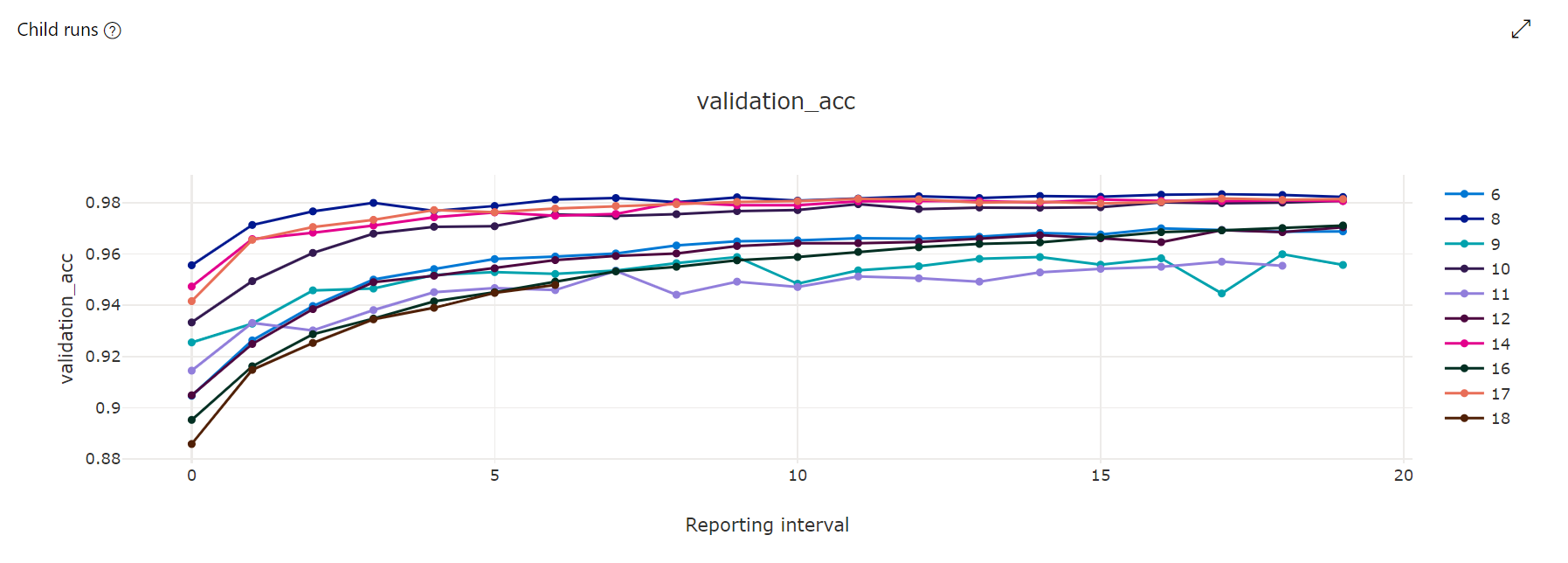
Wykres metryk: ta wizualizacja śledzi metryki rejestrowane dla każdego zadania podrzędnego hiperdrive w czasie trwania dostrajania hiperparametrów. Każdy wiersz reprezentuje zadanie podrzędne, a każdy punkt mierzy podstawową wartość metryki w tej iteracji środowiska uruchomieniowego.
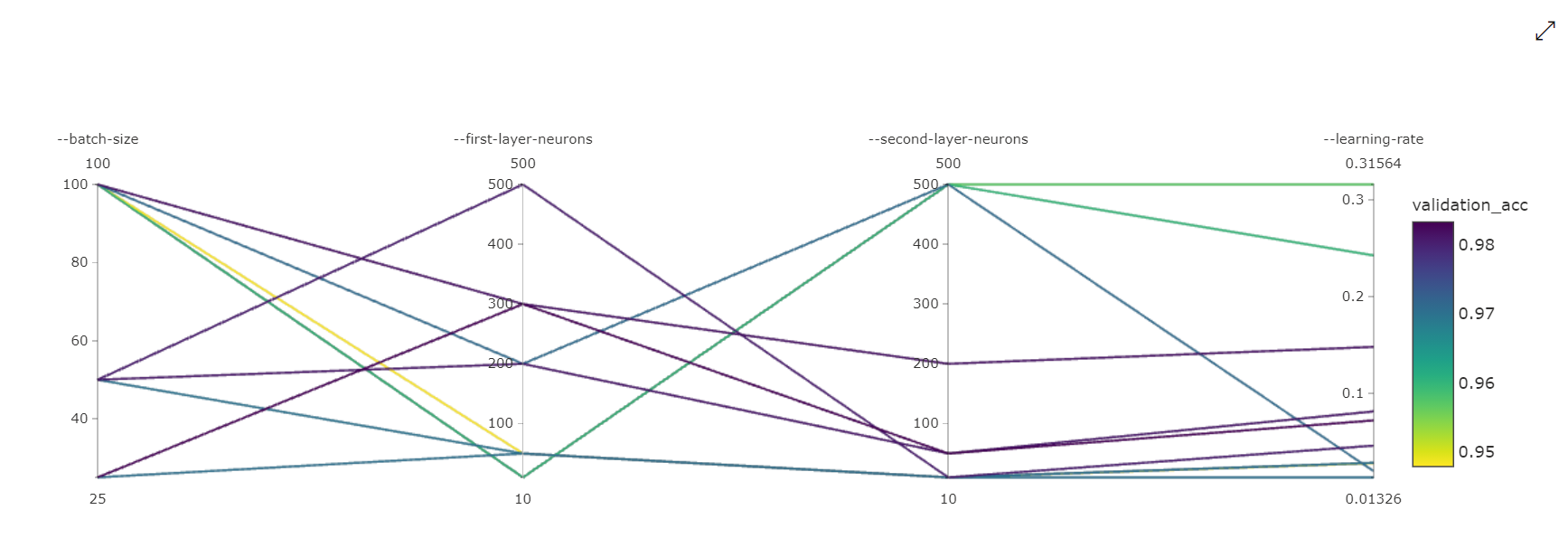
Wykres współrzędnych równoległych: ta wizualizacja pokazuje korelację między wydajnością podstawowej metryki a poszczególnymi wartościami hiperparametrów. Wykres jest interaktywny przez ruch osi (zaznacz i przeciągnij według etykiety osi), a następnie wyróżniając wartości na jednej osi (zaznacz i przeciągnij pionowo wzdłuż pojedynczej osi, aby wyróżnić zakres żądanych wartości). Wykres współrzędnych równoległych zawiera oś na najbardziej prawej części wykresu, która kreśli najlepszą wartość metryki odpowiadającą hiperparametrom ustawionym dla tego wystąpienia zadania. Ta oś jest udostępniana w celu projekcji legendy gradientu wykresu na dane w bardziej czytelny sposób.
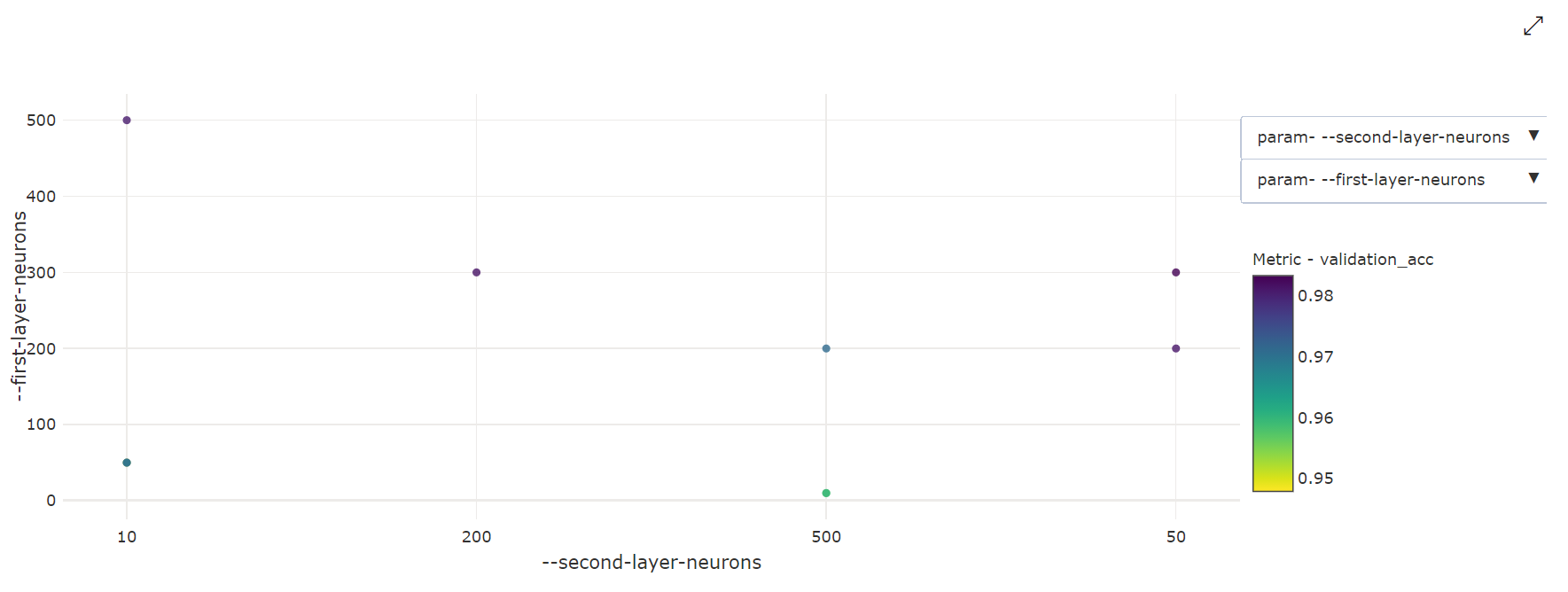
2-wymiarowy wykres punktowy: ta wizualizacja pokazuje korelację między dwoma poszczególnymi hiperparametrami wraz ze skojarzona z nimi podstawową wartością metryki.
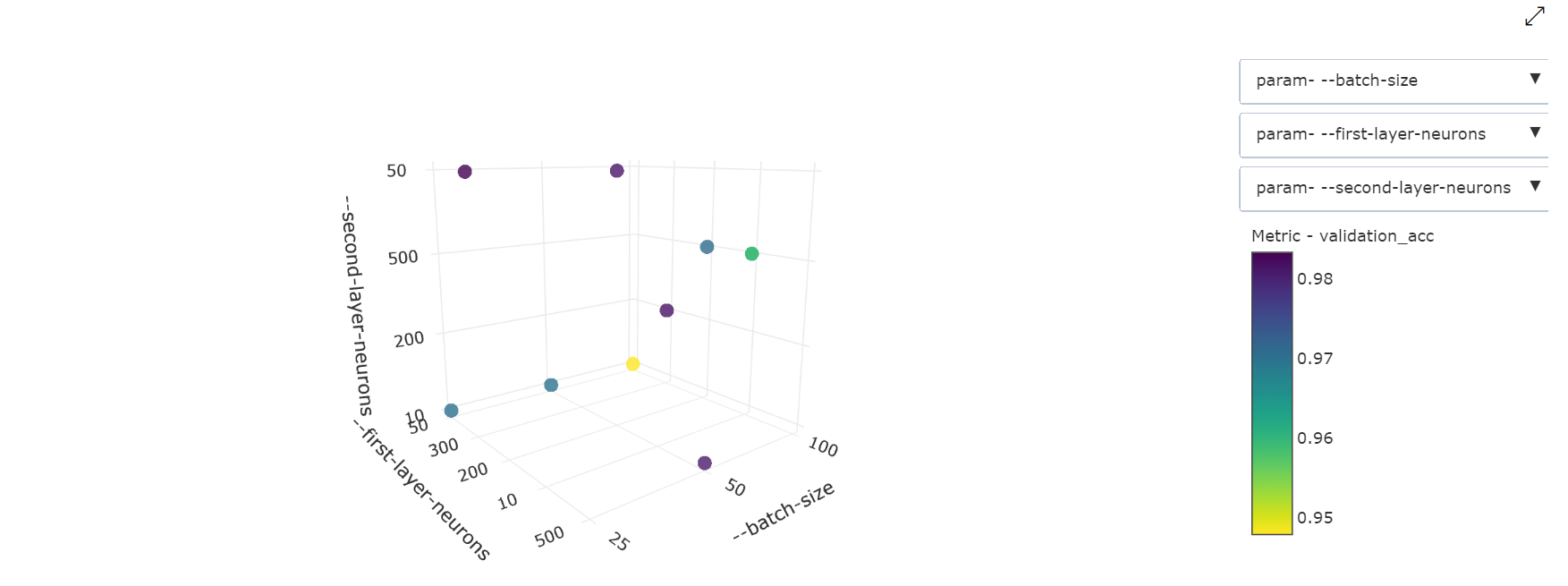
Wykres punktowy 3-wymiarowy: ta wizualizacja jest taka sama jak 2D, ale umożliwia trzy wymiary hiperparametru korelacji z podstawową wartością metryki. Możesz również wybrać i przeciągnąć, aby ponownie zorientować się na wykres, aby wyświetlić różne korelacje w przestrzeni 3D.
Znajdowanie najlepszego zadania w wersji próbnej
Po zakończeniu wszystkich zadań dostrajania hiperparametrów pobierz najlepsze dane wyjściowe wersji próbnej:
# Download best trial model output
ml_client.jobs.download(returned_sweep_job.name, output_name="model")
Interfejs wiersza polecenia umożliwia pobranie wszystkich domyślnych i nazwanych danych wyjściowych najlepszego zadania w wersji próbnej i dzienników zadania zamiatania.
az ml job download --name <sweep-job> --all
Opcjonalnie, aby pobrać wyłącznie najlepsze dane wyjściowe wersji próbnej
az ml job download --name <sweep-job> --output-name model
Informacje
- Przykład dostrajania hiperparametrów
- Schemat YAML zadania zamiatania interfejsu wiersza polecenia (wersja 2) tutaj