DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (bieżąca)PYTHON SDK azure-ai-ml v2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (bieżąca)PYTHON SDK azure-ai-ml v2 (bieżąca)
Z tego artykułu dowiesz się, jak wdrożyć model w punkcie końcowym online do użycia w wnioskowaniu w czasie rzeczywistym. Zacznij od wdrożenia modelu na komputerze lokalnym w celu debugowania błędów. Następnie wdrożysz i przetestujesz model na platformie Azure, wyświetlisz dzienniki wdrażania i będziesz monitorować umowę dotyczącą poziomu usług (SLA). Na końcu tego artykułu masz skalowalny punkt końcowy HTTPS/REST, którego można użyć do wnioskowania w czasie rzeczywistym.
Interfejsy końcowe online to interfejsy końcowe używane do wnioskowania w czasie rzeczywistym. Istnieją dwa typy punktów końcowych online: zarządzane punkty końcowe online i punkty końcowe online Kubernetes. Aby uzyskać więcej informacji na temat różnic, zobacz Managed online endpoints vs. Kubernetes online endpoints (Zarządzane punkty końcowe online a punkty końcowe online platformy Kubernetes).
Zarządzane punkty końcowe online ułatwiają wdrażanie modeli uczenia maszynowego w prosty i zautomatyzowany sposób. Zarządzane punkty końcowe online współpracują z maszynami o zaawansowanych procesorach CPU i GPU na platformie Azure w sposób skalowalny i w pełni zarządzany. Zarządzane punkty końcowe online dbają o obsługę, skalowanie, zabezpieczanie i monitorowanie modeli. Ta pomoc zwalnia Cię z nakładu pracy związanego z konfigurowaniem podstawowej infrastruktury i zarządzaniem nią.
Główny przykład w tym artykule używa zarządzanych punktów końcowych online do wdrożenia. Aby zamiast tego użyć platformy Kubernetes, zapoznaj się z uwagami w tym dokumencie, które są wbudowane w dyskusję na temat zarządzanego punktu końcowego online.
Wymagania wstępne
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
Kontrola dostępu oparta na rolach (RBAC) platformy Azure służy do udzielania dostępu do operacji w usłudze Azure Machine Learning. Aby wykonać kroki opisane w tym artykule, konto użytkownika musi mieć przypisaną rolę Właściciela lub Współtwórcy dla obszaru roboczego usługi Azure Machine Learning, lub rola niestandardowa musi na to zezwalać.Microsoft.MachineLearningServices/workspaces/onlineEndpoints/* Jeśli używasz usługi Azure Machine Learning Studio do tworzenia punktów końcowych lub wdrożeń online i zarządzania nimi, potrzebujesz dodatkowych uprawnień Microsoft.Resources/deployments/write od właściciela grupy zasobów. Aby uzyskać więcej informacji, zobacz Zarządzanie dostępem do obszarów roboczych usługi Azure Machine Learning.
(Opcjonalnie) Aby wdrożyć lokalnie, należy zainstalować silnik Docker na komputerze lokalnym.
Zdecydowanie zalecamy tę opcję, co ułatwia debugowanie problemów.
DOTYCZY: Python SDK azure-ai-ml wersja 2 (bieżąca)
Obszar roboczy usługi Azure Machine Learning. Aby uzyskać instrukcje dotyczące tworzenia obszaru roboczego, zobacz Tworzenie obszaru roboczego.
Zestaw SDK usługi Azure Machine Learning dla języka Python w wersji 2. Aby zainstalować zestaw SDK, użyj następującego polecenia:
pip install azure-ai-ml azure-identity
Aby zaktualizować istniejącą instalację zestawu SDK do najnowszej wersji, użyj następującego polecenia:
pip install --upgrade azure-ai-ml azure-identity
Aby uzyskać więcej informacji, zobacz Azure Machine Learning Package client library for Python.
Azure RBAC służy do udzielania dostępu do operacji na platformie Azure Machine Learning. Aby wykonać kroki opisane w tym artykule, konto użytkownika musi mieć przypisaną rolę Właściciela lub Współtwórcy dla obszaru roboczego usługi Azure Machine Learning, lub rola niestandardowa musi na to zezwalać.Microsoft.MachineLearningServices/workspaces/onlineEndpoints/* Aby uzyskać więcej informacji, zobacz Zarządzanie dostępem do obszarów roboczych usługi Azure Machine Learning.
(Opcjonalnie) Aby wdrożyć lokalnie, należy zainstalować silnik Docker na komputerze lokalnym.
Zdecydowanie zalecamy tę opcję, co ułatwia debugowanie problemów.
Przed wykonaniem kroków opisanych w tym artykule upewnij się, że masz następujące wymagania wstępne:
- Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto. Wypróbuj bezpłatną lub płatną wersję usługi Azure Machine Learning.
- Obszar roboczy usługi Azure Machine Learning i wystąpienie obliczeniowe. Jeśli nie masz tych zasobów, zobacz Stwórz zasoby potrzebne do rozpoczęcia.
- Azure RBAC służy do udzielania dostępu do operacji na platformie Azure Machine Learning. Aby wykonać kroki opisane w tym artykule, konto użytkownika musi mieć przypisaną rolę Właściciela lub Współtwórcy dla obszaru roboczego usługi Azure Machine Learning, lub rola niestandardowa musi na to zezwalać.
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/* Aby uzyskać więcej informacji, zobacz Zarządzanie dostępem do obszaru roboczego usługi Azure Machine Learning.
Interfejs wiersza polecenia platformy Azure i rozszerzenie interfejsu wiersza polecenia dla uczenia maszynowego są używane w tych krokach, ale nie są one głównym celem. Są one używane bardziej jako narzędzia do przekazywania szablonów na platformę Azure i sprawdzania stanu wdrożeń szablonów.
- Azure RBAC służy do udzielania dostępu do operacji na platformie Azure Machine Learning. Aby wykonać kroki opisane w tym artykule, konto użytkownika musi mieć przypisaną rolę Właściciela lub Współtwórcy dla obszaru roboczego usługi Azure Machine Learning, lub rola niestandardowa musi na to zezwalać.
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/* Aby uzyskać więcej informacji, zobacz Zarządzanie dostępem do obszaru roboczego usługi Azure Machine Learning.
Upewnij się, że masz wystarczający przydział maszyny wirtualnej przydzielony do wdrożenia. Usługa Azure Machine Learning rezerwuje 20% zasobów obliczeniowych na potrzeby przeprowadzania uaktualnień w niektórych wersjach maszyn wirtualnych. Jeśli na przykład zażądasz 10 wystąpień we wdrożeniu, musisz mieć limit przydziału wynoszący 12 dla każdej liczby rdzeni dla wersji maszyny wirtualnej. Niewzięcie pod uwagę dodatkowych zasobów obliczeniowych prowadzi do błędu. Niektóre wersje maszyn wirtualnych są wykluczone z dodatkowej rezerwacji przydziału. Aby uzyskać więcej informacji na temat alokacji, zobacz alokację maszyny wirtualnej dla wdrożenia.
Alternatywnie możesz użyć limitu przydziału z udostępnionej puli przydziałów usługi Azure Machine Learning przez ograniczony czas. Usługa Azure Machine Learning udostępnia udostępnioną pulę przydziałów, z której użytkownicy w różnych regionach mogą uzyskiwać dostęp do limitu przydziału w celu przeprowadzania testów przez ograniczony czas, w zależności od dostępności.
Gdy używasz programu Studio do wdrażania modeli Llama-2, Phi, Nemotron, Mistral, Dolly i Deci-DeciLM z katalogu modeli do zarządzanego punktu końcowego online, usługa Azure Machine Learning umożliwia dostęp do udostępnionej puli przydziałów przez krótki czas, aby można było przeprowadzić testowanie. Aby uzyskać więcej informacji na temat udostępnionej puli przydziałów, zobacz Udostępniony przydział Azure Machine Learning.
Przygotowywanie systemu
Ustawianie zmiennych środowiskowych
Jeśli nie ustawiono jeszcze ustawień domyślnych dla interfejsu wiersza polecenia platformy Azure, zapisz ustawienia domyślne. Aby uniknąć wielokrotnego przekazywania wartości dla subskrypcji, obszaru roboczego i grupy zasobów, uruchom następujący kod:
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
Klonowanie repozytorium przykładów
Aby wykonać czynności opisane w tym artykule, najpierw sklonuj repozytorium azureml-examples, a następnie przejdź do katalogu azureml-examples/cli repozytorium:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli
Użyj --depth 1, aby sklonować tylko najnowszy commit do repozytorium, co skraca czas na ukończenie operacji.
Polecenia w tym samouczku znajdują się w plikach deploy-local-endpoint.sh i deploy-managed-online-endpoint.sh w katalogu cli. Pliki konfiguracji YAML znajdują się w podkatalogu endpoints/online/managed/sample/ .
Uwaga
Pliki konfiguracji YAML dla punktów końcowych online platformy Kubernetes znajdują się w podkatalogu endpoints/online/kubernetes.
Klonowanie repozytorium przykładów
Aby uruchomić przykłady szkoleniowe, najpierw sklonuj repozytorium azureml-examples, a następnie przejdź do katalogu azureml-examples/sdk/python/endpoints/online/managed.
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/sdk/python/endpoints/online/managed
Użyj --depth 1, aby sklonować tylko najnowszy commit do repozytorium, co skraca czas na ukończenie operacji.
Informacje przedstawione w tym artykule są oparte na notebooku online-endpoints-simple-deployment.ipynb. Zawiera on tę samą zawartość co ten artykuł, chociaż kolejność kodów jest nieco inna.
Nawiązywanie połączenia z obszarem roboczym usługi Azure Machine Learning
Obszar roboczy to zasób najwyższego poziomu dla usługi Azure Machine Learning. Zapewnia scentralizowane miejsce do pracy ze wszystkimi artefaktami tworzonymi podczas korzystania z usługi Azure Machine Learning. W tej sekcji połączysz się z obszarem roboczym, w którym wykonujesz zadania wdrażania. Aby śledzić, otwórz swój notatnik online-endpoints-simple-deployment.ipynb.
Zaimportuj wymagane biblioteki:
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
CodeConfiguration
)
from azure.identity import DefaultAzureCredential
Uwaga
Jeśli używasz punktu końcowego online platformy Kubernetes, zaimportuj klasy KubernetesOnlineEndpoint i KubernetesOnlineDeployment z biblioteki azure.ai.ml.entities.
Konfigurowanie szczegółów obszaru roboczego i uzyskiwanie dojścia do obszaru roboczego.
Aby nawiązać połączenie z obszarem roboczym, potrzebne są następujące parametry identyfikatora: subskrypcja, grupa zasobów i nazwa obszaru roboczego. Te szczegóły są używane w programie MLClient , azure.ai.ml aby uzyskać dojście do wymaganego obszaru roboczego usługi Azure Machine Learning. W tym przykładzie użyto domyślnego uwierzytelniania platformy Azure.
# enter details of your Azure Machine Learning workspace
subscription_id = "<subscription ID>"
resource_group = "<resource group>"
workspace = "<workspace name>"
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
Jeśli na komputerze lokalnym zainstalowano usługę Git, możesz wykonać instrukcje klonowania repozytorium przykładów. W przeciwnym razie postępuj zgodnie z instrukcjami, aby pobrać pliki z repozytorium przykładów.
Klonowanie repozytorium przykładów
Aby skorzystać z tego artykułu, najpierw sklonuj repozytorium azureml-examples, a następnie przejdź do katalogu azureml-examples/cli/endpoints/online/model-1 .
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli/endpoints/online/model-1
Użyj --depth 1, aby sklonować tylko najnowszy commit do repozytorium, co skraca czas na ukończenie operacji.
Pobieranie plików z repozytorium przykładów
Jeśli sklonujesz repozytorium przykładów, maszyna lokalna ma już kopie plików w tym przykładzie i możesz przejść do następnej sekcji. Jeśli nie sklonujesz repozytorium, pobierz je na komputer lokalny.
- Przejdź do repozytorium przykładów (azureml-examples).
- Przejdź do <> przycisku Kod na stronie, a następnie na karcie Lokalne wybierz pozycję Pobierz plik ZIP.
- Znajdź folder /cli/endpoints/online/model-1/model i plik /cli/endpoints/online/model-1/onlinescoring/score.py.
Ustawianie zmiennych środowiskowych
Ustaw następujące zmienne środowiskowe, aby można było ich używać w przykładach w tym artykule. Zastąp wartości identyfikatorem subskrypcji platformy Azure, regionem świadczenia usługi Azure, w którym znajduje się obszar roboczy, grupą zasobów zawierającą obszar roboczy i nazwą obszaru roboczego:
export SUBSCRIPTION_ID="<subscription ID>"
export LOCATION="<your region>"
export RESOURCE_GROUP="<resource group>"
export WORKSPACE="<workspace name>"
Kilka przykładów szablonów wymaga przekazania plików do usługi Azure Blob Storage dla obszaru roboczego. W poniższych krokach wykonasz zapytanie dotyczące obszaru roboczego i zapisz te informacje w zmiennych środowiskowych używanych w przykładach:
Uzyskiwanie tokenu dostępu:
TOKEN=$(az account get-access-token --query accessToken -o tsv)
Ustaw wersję interfejsu API REST:
API_VERSION="2022-05-01"
Uzyskaj informacje o pamięci
# Get values for storage account
response=$(curl --location --request GET "https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices/workspaces/$WORKSPACE/datastores?api-version=$API_VERSION&isDefault=true" \
--header "Authorization: Bearer $TOKEN")
AZUREML_DEFAULT_DATASTORE=$(echo $response | jq -r '.value[0].name')
AZUREML_DEFAULT_CONTAINER=$(echo $response | jq -r '.value[0].properties.containerName')
export AZURE_STORAGE_ACCOUNT=$(echo $response | jq -r '.value[0].properties.accountName')
Klonowanie repozytorium przykładów
Aby wykonać czynności opisane w tym artykule, najpierw sklonuj repozytorium azureml-examples, a następnie przejdź do katalogu azureml-examples :
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
Użyj --depth 1, aby sklonować tylko najnowszy commit do repozytorium, co skraca czas na ukończenie operacji.
Definiowanie punktu końcowego
Aby zdefiniować punkt końcowy online, określ nazwę punktu końcowego i tryb uwierzytelniania. Aby uzyskać więcej informacji na temat zarządzanych punktów końcowych online, zobacz Punkty końcowe online.
Ustawianie nazwy punktu końcowego
Aby ustawić nazwę punktu końcowego, uruchom następujące polecenie. Zastąp <YOUR_ENDPOINT_NAME> ciąg nazwą unikatową w regionie świadczenia usługi Azure. Aby uzyskać więcej informacji na temat reguł nazewnictwa, zobacz Limity punktów końcowych.
export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"
Poniższy fragment kodu przedstawia plik endpoints/online/managed/sample/endpoint.yml :
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
Odwołanie do formatu YAML dla punktu końcowego znajduje się w poniższej tabeli. Aby dowiedzieć się, jak określić te atrybuty, zobacz referencję YAML punktu końcowego online. Aby uzyskać informacje o limitach związanych z zarządzanymi punktami końcowymi, zobacz Punkty końcowe online usługi Azure Machine Learning i punkty końcowe wsadowe.
| Klucz |
opis |
$schema |
(Opcjonalnie) Schemat YAML. Aby wyświetlić wszystkie dostępne opcje w pliku YAML, możesz wyświetlić schemat w poprzednim fragmencie kodu w przeglądarce. |
name |
Nazwa punktu końcowego. |
auth_mode |
Służy key do uwierzytelniania opartego na kluczach.
Użyj aml_token do uwierzytelniania opartego na tokenach w Azure Machine Learning.
Użyj aad_token do uwierzytelniania opartego na tokenach Microsoft Entra (wersja zapoznawcza).
Aby uzyskać więcej informacji na temat uwierzytelniania, zobacz Uwierzytelnianie klientów dla punktów końcowych online. |
Najpierw zdefiniuj nazwę punktu końcowego online, a następnie skonfiguruj punkt końcowy.
Zastąp <YOUR_ENDPOINT_NAME> ciąg nazwą unikatową w regionie świadczenia usługi Azure lub użyj przykładowej metody, aby zdefiniować losową nazwę. Pamiętaj, aby usunąć metodę, której nie używasz. Aby uzyskać więcej informacji na temat reguł nazewnictwa, zobacz Limity punktów końcowych.
# method 1: define an endpoint name
endpoint_name = "<YOUR_ENDPOINT_NAME>"
# method 2: example way to define a random name
import datetime
endpoint_name = "endpt-" + datetime.datetime.now().strftime("%m%d%H%M%f")
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name = endpoint_name,
description="this is a sample endpoint",
auth_mode="key"
)
Poprzedni kod używa key do uwierzytelniania opartego na kluczach. Aby użyć uwierzytelniania opartego na tokenach usługi Azure Machine Learning, użyj polecenia aml_token. Aby użyć uwierzytelniania opartego na tokenach firmy Microsoft (wersja zapoznawcza), użyj polecenia aad_token. Aby uzyskać więcej informacji na temat uwierzytelniania, zobacz Uwierzytelnianie klientów dla punktów końcowych online.
Podczas wdrażania na platformie Azure z poziomu programu Studio utworzysz punkt końcowy i wdrożenie, które ma zostać dodane. W tym czasie zostanie wyświetlony monit o podanie nazw punktu końcowego i wdrożenia.
Ustawianie nazwy punktu końcowego
Aby ustawić nazwę punktu końcowego, uruchom następujące polecenie, aby wygenerować losową nazwę. Musi być unikatowa w regionie świadczenia usługi Azure. Aby uzyskać więcej informacji na temat reguł nazewnictwa, zobacz Limity punktów końcowych.
export ENDPOINT_NAME=endpoint-`echo $RANDOM`
Aby zdefiniować punkt końcowy i wdrożenie, w tym artykule użyto szablonów usługi Azure Resource Manager (szablonów usługi ARM) online-endpoint.json i online-endpoint-deployment.json. Aby użyć szablonów do definiowania punktu końcowego i wdrożenia online, zobacz sekcję Wdrażanie na platformie Azure .
Definiowanie wdrożenia
Wdrożenie to zestaw zasobów wymaganych do hostowania modelu, który wykonuje rzeczywiste wnioskowanie. W tym przykładzie wdrożysz model, który wykonuje regresję scikit-learn i użyjesz skryptu oceniania score.py , aby uruchomić model w określonym żądaniu wejściowym.
Aby dowiedzieć się więcej o kluczowych atrybutach wdrożenia, zobacz Wdrożenia online.
Konfiguracja wdrożenia używa lokalizacji modelu, który chcesz wdrożyć.
Poniższy fragment kodu przedstawia pliki endpoints/online/managed/sample/blue-deployment.yml z wszystkimi wymaganymi danymi wejściowymi w celu skonfigurowania wdrożenia:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
Plik blue-deployment.yml określa następujące atrybuty wdrożenia:
-
model: określa właściwości modelu bezpośrednio przy użyciu parametru path (skąd przesyłać pliki). Interfejs wiersza polecenia automatycznie przekazuje pliki modelu i rejestruje model przy użyciu automatycznie wygenerowanej nazwy.
-
environment: używa wbudowanych definicji, które zawierają lokalizację przekazywania plików. Interfejs wiersza polecenia automatycznie przesyła plik conda.yaml i rejestruje środowisko. Później, aby skompilować środowisko, wdrożenie używa parametru image dla obrazu podstawowego. W tym przykładzie jest to mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest. Zależności conda_file są instalowane na podstawie obrazu podstawowego.
-
code_configuration: Przesyła pliki lokalne, takie jak źródła kodu Python dla modelu oceny, ze środowiska deweloperskiego podczas wdrażania.
Aby uzyskać więcej informacji na temat schematu YAML, zobacz dokumentację YAML punktu końcowego online.
Uwaga
Aby użyć punktów końcowych platformy Kubernetes zamiast zarządzanych punktów końcowych online jako celu obliczeniowego:
- Utwórz i dołącz klaster Kubernetes jako docelowy obiekt obliczeniowy do obszaru roboczego usługi Azure Machine Learning przy użyciu usługi Azure Machine Learning Studio.
- Użyj kodu YAML punktu końcowego , aby kierować platformę Kubernetes zamiast zarządzanego punktu końcowego YAML. Musisz edytować plik YAML, aby zmienić wartość
compute na nazwę zarejestrowanego docelowego obiektu obliczeniowego. Możesz użyć tego pliku deployment.yaml , który ma inne właściwości, które mają zastosowanie do wdrożenia platformy Kubernetes.
Wszystkie polecenia używane w tym artykule dla zarządzanych punktów końcowych online dotyczą również punktów końcowych platformy Kubernetes, z wyjątkiem następujących możliwości, które nie mają zastosowania do punktów końcowych platformy Kubernetes:
Aby skonfigurować wdrożenie, użyj następującego kodu:
model = Model(path="../model-1/model/sklearn_regression_model.pkl")
env = Environment(
conda_file="../model-1/environment/conda.yaml",
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
-
Model: określa właściwości modelu bezpośrednio przy użyciu parametru path (skąd przesyłać pliki). Zestaw SDK automatycznie przekazuje pliki modelu i rejestruje model przy użyciu automatycznie wygenerowanej nazwy.
-
Environment: używa wbudowanych definicji, które zawierają lokalizację przekazywania plików. Zestaw SDK automatycznie przekazuje plik conda.yaml i rejestruje środowisko. Później, aby skompilować środowisko, wdrożenie używa parametru image dla obrazu podstawowego. W tym przykładzie jest to mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest. Zależności conda_file są instalowane na podstawie obrazu podstawowego.
-
CodeConfiguration: Przesyła pliki lokalne, takie jak źródła kodu Python dla modelu oceny, ze środowiska deweloperskiego podczas wdrażania.
Aby uzyskać więcej informacji na temat definicji wdrożenia online, zobacz OnlineDeployment Class (Klasa OnlineDeployment).
Podczas wdrażania w Azure tworzysz punkt końcowy i wdrożenie, które do niego dodajesz. W tym czasie zostanie wyświetlony monit o podanie nazw punktu końcowego i wdrożenia.
Omówienie skryptu oceniania
Format skryptu oceniania dla punktów końcowych online jest taki sam, jak w poprzedniej wersji CLI i w Python SDK.
Skrypt oceniania określony w code_configuration.scoring_script musi mieć funkcję init() i funkcję run().
Skrypt oceniania musi mieć init() funkcję i run() funkcję.
Skrypt oceniania musi mieć init() funkcję i run() funkcję.
Skrypt oceniania musi mieć init() funkcję i run() funkcję. W tym artykule jest używany plik score.py.
Jeśli używasz szablonu do wdrożenia, musisz najpierw przekazać plik oceniania do usługi Blob Storage, a następnie zarejestrować go:
Poniższy kod używa polecenia Azure CLI az storage blob upload-batch do przesłania pliku wynikowego.
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/score -s cli/endpoints/online/model-1/onlinescoring --account-name $AZURE_STORAGE_ACCOUNT
Poniższy kod używa szablonu do zarejestrowania kodu:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/code-version.json \
--parameters \
workspaceName=$WORKSPACE \
codeAssetName="score-sklearn" \
codeUri="https://$AZURE_STORAGE_ACCOUNT.blob.core.windows.net/$AZUREML_DEFAULT_CONTAINER/score"
W tym przykładzie użyto pliku score.py z sklonowanego lub pobranego wcześniej repozytorium:
import os
import logging
import json
import numpy
import joblib
def init():
"""
This function is called when the container is initialized/started, typically after create/update of the deployment.
You can write the logic here to perform init operations like caching the model in memory
"""
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment.
# It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION)
# Please provide your model's folder name if there is one
model_path = os.path.join(
os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl"
)
# deserialize the model file back into a sklearn model
model = joblib.load(model_path)
logging.info("Init complete")
def run(raw_data):
"""
This function is called for every invocation of the endpoint to perform the actual scoring/prediction.
In the example we extract the data from the json input and call the scikit-learn model's predict()
method and return the result back
"""
logging.info("model 1: request received")
data = json.loads(raw_data)["data"]
data = numpy.array(data)
result = model.predict(data)
logging.info("Request processed")
return result.tolist()
Funkcja init() jest wywoływana przy inicjowaniu lub uruchamianiu kontenera. Inicjalizacja zwykle następuje krótko po utworzeniu lub zaktualizowaniu wdrożenia. Funkcja init jest miejscem do zapisu logiki dla globalnych operacji inicjowania, takich jak buforowanie modelu w pamięci (jak pokazano w tym pliku score.py ).
Funkcja run() jest wywoływana za każdym razem, gdy punkt końcowy jest wywoływany. Wykonuje on rzeczywiste ocenianie i przewidywanie. W tym funkcja wyodrębnia dane z danych wejściowych JSON, wywołuje metodę modelu run() scikit-learn, a następnie zwraca wynik przewidywania.
Wdrażanie i debugowanie lokalnie przy użyciu lokalnego punktu końcowego
Zdecydowanie zalecamy przetestowanie lokalnego uruchomienia punktu końcowego w celu zweryfikowania i debugowania kodu i konfiguracji przed wdrożeniem na platformie Azure. Interfejs wiersza polecenia Azure i zestaw SDK języka Python obsługują lokalne punkty końcowe i wdrożenia, ale studio Azure Machine Learning i szablony ARM tego nie robią.
Aby można było wdrażać lokalnie, aparat platformy Docker musi być zainstalowany i uruchomiony. Aparat platformy Docker zwykle uruchamia się po uruchomieniu komputera. Jeśli tak nie jest, możesz rozwiązać problemy z aparatem platformy Docker.
Możesz użyć pakietu Python serwera HTTP wnioskowania Azure Machine Learning, aby debugować skrypt oceniania lokalnie bez silnika Docker. Debugowanie za pomocą serwera wnioskowania ułatwia debugowanie skryptu oceniania przed wdrożeniem w lokalnych punktach końcowych, dzięki czemu można debugować bez wpływu na konfiguracje kontenera wdrożenia.
Aby uzyskać więcej informacji na temat lokalnego debugowania punktów końcowych online przed wdrożeniem na platformie Azure, zobacz Debugowanie punktów końcowych online.
Lokalne wdrażanie modelu
Najpierw utwórz punkt końcowy. Opcjonalnie dla lokalnego punktu końcowego możesz pominąć ten krok. Wdrożenie można utworzyć bezpośrednio (następny krok), który z kolei tworzy wymagane metadane. Lokalne wdrażanie modeli jest przydatne do celów programistycznych i testowych.
az ml online-endpoint create --local -n $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
ml_client.online_endpoints.begin_create_or_update(endpoint, local=True)
Studio nie obsługuje lokalnych punktów końcowych. Aby uzyskać instrukcje testowania punktu końcowego lokalnie, zobacz karty interfejsu wiersza polecenia platformy Azure lub języka Python.
Szablon nie obsługuje lokalnych punktów końcowych. Aby uzyskać instrukcje testowania punktu końcowego lokalnie, zobacz karty interfejsu wiersza polecenia platformy Azure lub języka Python.
Teraz utwórz wdrożenie o nazwie blue w punkcie końcowym.
az ml online-deployment create --local -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml
Flaga --local instruuje CLI do wdrożenia punktu końcowego w środowisku Docker.
ml_client.online_deployments.begin_create_or_update(
deployment=blue_deployment, local=True
)
Flaga local=True kieruje zestaw SDK do wdrożenia punktu końcowego w środowisku platformy Docker.
Studio nie obsługuje lokalnych punktów końcowych. Aby uzyskać instrukcje testowania punktu końcowego lokalnie, zobacz karty interfejsu wiersza polecenia platformy Azure lub języka Python.
Szablon nie obsługuje lokalnych punktów końcowych. Aby uzyskać instrukcje testowania punktu końcowego lokalnie, zobacz karty interfejsu wiersza polecenia platformy Azure lub języka Python.
Sprawdź, czy wdrożenie lokalne zakończyło się pomyślnie
Sprawdź stan wdrożenia, aby sprawdzić, czy model został wdrożony bez błędu:
az ml online-endpoint show -n $ENDPOINT_NAME --local
Dane wyjściowe powinny wyglądać podobnie do poniższego kodu JSON. Parametr provisioning_state jest Succeeded.
{
"auth_mode": "key",
"location": "local",
"name": "docs-endpoint",
"properties": {},
"provisioning_state": "Succeeded",
"scoring_uri": "http://localhost:49158/score",
"tags": {},
"traffic": {}
}
ml_client.online_endpoints.get(name=endpoint_name, local=True)
Metoda zwraca ManagedOnlineEndpoint jednostkę. Parametr provisioning_state jest Succeeded.
ManagedOnlineEndpoint({'public_network_access': None, 'provisioning_state': 'Succeeded', 'scoring_uri': 'http://localhost:49158/score', 'swagger_uri': None, 'name': 'endpt-10061534497697', 'description': 'this is a sample endpoint', 'tags': {}, 'properties': {}, 'id': None, 'Resource__source_path': None, 'base_path': '/path/to/your/working/directory', 'creation_context': None, 'serialize': <msrest.serialization.Serializer object at 0x7ffb781bccd0>, 'auth_mode': 'key', 'location': 'local', 'identity': None, 'traffic': {}, 'mirror_traffic': {}, 'kind': None})
Studio nie obsługuje lokalnych punktów końcowych. Aby uzyskać instrukcje testowania punktu końcowego lokalnie, zobacz karty interfejsu wiersza polecenia platformy Azure lub języka Python.
Szablon nie obsługuje lokalnych punktów końcowych. Aby uzyskać instrukcje testowania punktu końcowego lokalnie, zobacz karty interfejsu wiersza polecenia platformy Azure lub języka Python.
Poniższa tabela zawiera możliwe wartości dla elementu provisioning_state:
| Wartość |
opis |
Creating |
Zasób jest tworzony. |
Updating |
Zasób jest aktualizowany. |
Deleting |
Zasób jest usuwany. |
Succeeded |
Operacja tworzenia lub aktualizacji zakończyła się pomyślnie. |
Failed |
Operacja tworzenia, aktualizowania lub usuwania nie powiodła się. |
Wywoływanie lokalnego punktu końcowego w celu oceny danych przy użyciu modelu
Wywołaj punkt końcowy, aby ocenić model przy użyciu invoke polecenia i przekazać parametry zapytania przechowywane w pliku JSON:
az ml online-endpoint invoke --local --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
Jeśli chcesz użyć klienta REST (na przykład curl), musisz mieć URI oceniania. Aby uzyskać URI oceniania, uruchom az ml online-endpoint show --local -n $ENDPOINT_NAME. W zwracanych danych znajdź scoring_uri atrybut .
Wywołaj punkt końcowy, aby ocenić model przy użyciu invoke polecenia i przekazać parametry zapytania przechowywane w pliku JSON.
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
request_file="../model-1/sample-request.json",
local=True,
)
Jeśli chcesz użyć klienta REST (na przykład curl), musisz mieć URI oceniania. Aby uzyskać identyfikator URI oceniania, uruchom następujący kod. W zwracanych danych znajdź scoring_uri atrybut .
endpoint = ml_client.online_endpoints.get(endpoint_name, local=True)
scoring_uri = endpoint.scoring_uri
Studio nie obsługuje lokalnych punktów końcowych. Aby uzyskać instrukcje testowania punktu końcowego lokalnie, zobacz karty interfejsu wiersza polecenia platformy Azure lub języka Python.
Szablon nie obsługuje lokalnych punktów końcowych. Aby uzyskać instrukcje testowania punktu końcowego lokalnie, zobacz karty interfejsu wiersza polecenia platformy Azure lub języka Python.
Przejrzyj dzienniki pod kątem danych wyjściowych operacji invoke
W przykładowym pliku score.py metoda rejestruje wynik na konsoli.
Te dane wyjściowe można wyświetlić za pomocą get-logs polecenia :
az ml online-deployment get-logs --local -n blue --endpoint $ENDPOINT_NAME
Te dane wyjściowe można wyświetlić przy użyciu get_logs metody :
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, local=True, lines=50
)
Studio nie obsługuje lokalnych punktów końcowych. Aby uzyskać instrukcje testowania punktu końcowego lokalnie, zobacz karty interfejsu wiersza polecenia platformy Azure lub języka Python.
Szablon nie obsługuje lokalnych punktów końcowych. Aby uzyskać instrukcje testowania punktu końcowego lokalnie, zobacz karty interfejsu wiersza polecenia platformy Azure lub języka Python.
Wdrażanie punktu końcowego online na platformie Azure
Następnie wdróż punkt końcowy online na platformie Azure. Najlepszym rozwiązaniem w środowisku produkcyjnym jest zarejestrowanie modelu i środowiska używanego we wdrożeniu.
Rejestrowanie modelu i środowiska
Zalecamy zarejestrowanie modelu i środowiska przed wdrożeniem na platformie Azure, aby można było określić ich zarejestrowane nazwy i wersje podczas wdrażania. Po zarejestrowaniu zasobów możesz ponownie je wykorzystać bez konieczności przekazywania ich za każdym razem, gdy tworzysz nowe wdrożenia. Ta praktyka zwiększa powtarzalność i możliwość śledzenia.
W przeciwieństwie do wdrożenia na platformie Azure wdrożenie lokalne nie obsługuje używania zarejestrowanych modeli i środowisk. Zamiast tego wdrożenie lokalne używa plików modelu lokalnego i używa środowisk tylko z plikami lokalnymi.
W przypadku wdrożenia na platformie Azure można użyć zasobów lokalnych lub zarejestrowanych (modeli i środowisk). W tej sekcji artykułu wdrożenie na platformie Azure używa zarejestrowanych zasobów, ale zamiast tego masz możliwość korzystania z zasobów lokalnych. Aby zapoznać się z przykładem konfiguracji wdrożenia, która przekazuje pliki lokalne do użycia na potrzeby wdrożenia lokalnego, zobacz Konfigurowanie wdrożenia.
Aby zarejestrować model i środowisko, użyj formularza model: azureml:my-model:1 lub environment: azureml:my-env:1.
W celu rejestracji można wyodrębnić definicje model i environment do oddzielnych plików YAML w folderze endpoints/online/managed/sample, a następnie użyć poleceń az ml model create i az ml environment create. Aby dowiedzieć się więcej o tych poleceniach, uruchom az ml model create -h i az ml environment create -h.
Utwórz definicję YAML dla modelu. Nadaj plikowi nazwę model.yml:
$schema: https://azuremlschemas.azureedge.net/latest/model.schema.json
name: my-model
path: ../../model-1/model/
Zarejestruj model:
az ml model create -n my-model -v 1 -f endpoints/online/managed/sample/model.yml
Utwórz definicję YAML dla środowiska. Nadaj plikowi nazwę environment.yml:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: my-env
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
conda_file: ../../model-1/environment/conda.yaml
Zarejestruj środowisko:
az ml environment create -n my-env -v 1 -f endpoints/online/managed/sample/environment.yml
Aby uzyskać więcej informacji na temat rejestrowania modelu jako zasobu, zobacz Rejestrowanie modelu przy użyciu interfejsu wiersza polecenia platformy Azure lub zestawu SDK języka Python. Aby uzyskać więcej informacji na temat tworzenia środowiska, zobacz Tworzenie środowiska niestandardowego.
Rejestrowanie modelu:
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
file_model = Model(
path="../model-1/model/",
type=AssetTypes.CUSTOM_MODEL,
name="my-model",
description="Model created from local file.",
)
ml_client.models.create_or_update(file_model)
Zarejestruj środowisko:
from azure.ai.ml.entities import Environment
env_docker_conda = Environment(
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
conda_file="../model-1/environment/conda.yaml",
name="my-env",
description="Environment created from a Docker image plus Conda environment.",
)
ml_client.environments.create_or_update(env_docker_conda)
Aby dowiedzieć się, jak zarejestrować model jako zasób, aby można było określić jego zarejestrowaną nazwę i wersję podczas wdrażania, zobacz Rejestrowanie modelu przy użyciu interfejsu wiersza polecenia platformy Azure lub zestawu SDK języka Python.
Aby uzyskać więcej informacji na temat tworzenia środowiska, zobacz Tworzenie środowiska niestandardowego.
Rejestrowanie modelu
Rejestracja modelu to jednostka logiczna w obszarze roboczym, która może zawierać jeden plik modelu lub katalog wielu plików. Najlepszym rozwiązaniem dla środowiska produkcyjnego jest zarejestrowanie modelu i środowiska. Przed utworzeniem punktu końcowego i wdrożenia w tym artykule zarejestruj folder modelu zawierający model.
Aby zarejestrować przykładowy model, wykonaj następujące kroki:
Przejdź do usługi Azure Machine Learning Studio.
W okienku po lewej stronie wybierz stronę Modele .
Wybierz pozycję Zarejestruj, a następnie wybierz pozycję Z plików lokalnych.
Wybierz nieokreślony typ dla typu modelu.
Wybierz pozycję Przeglądaj, a następnie wybierz pozycję Przeglądaj folder.
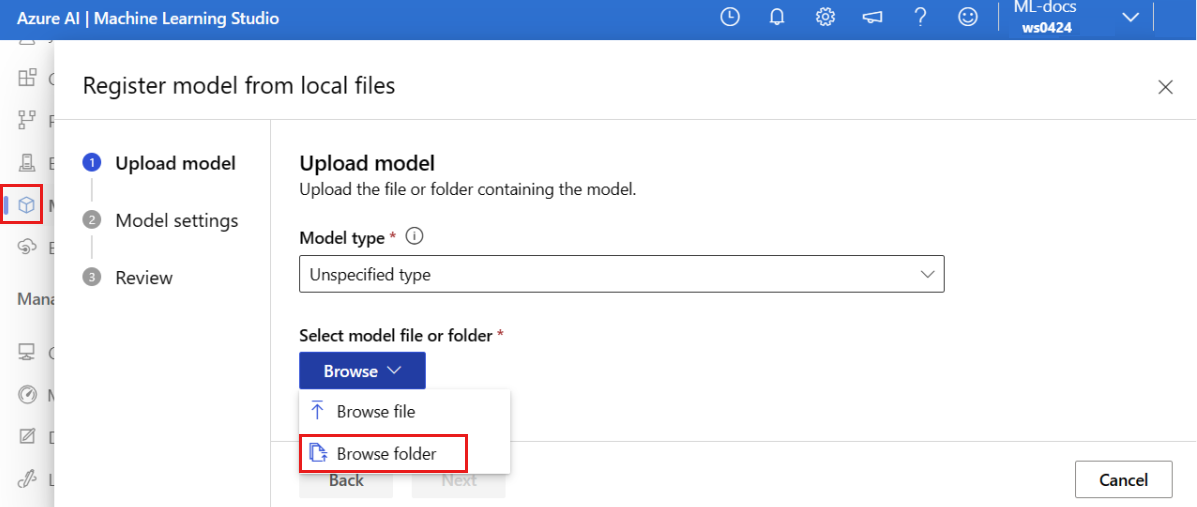
Wybierz folder \azureml-examples\cli\endpoints\online\model-1\model z lokalnej kopii sklonowanego lub pobranego wcześniej repozytorium. Po wyświetleniu monitu wybierz pozycję Przekaż i poczekaj na zakończenie przekazywania.
Wybierz Dalej.
Wprowadź przyjazną nazwę modelu. W krokach w tym artykule przyjęto założenie, że model ma nazwę model-1.
Wybierz przycisk Dalej, a następnie wybierz pozycję Zarejestruj , aby zakończyć rejestrację.
Aby uzyskać więcej informacji na temat pracy z zarejestrowanymi modelami, zobacz Praca z zarejestrowanymi modelami.
Tworzenie i rejestrowanie środowiska
W okienku po lewej stronie wybierz stronę Środowiska .
Wybierz kartę Środowiska niestandardowe , a następnie wybierz pozycję Utwórz.
Na stronie Ustawienia wprowadź nazwę, taką jak my-env dla środowiska.
W obszarze Wybierz źródło środowiska wybierz pozycję Użyj istniejącego obrazu platformy Docker z opcjonalnym źródłem conda.
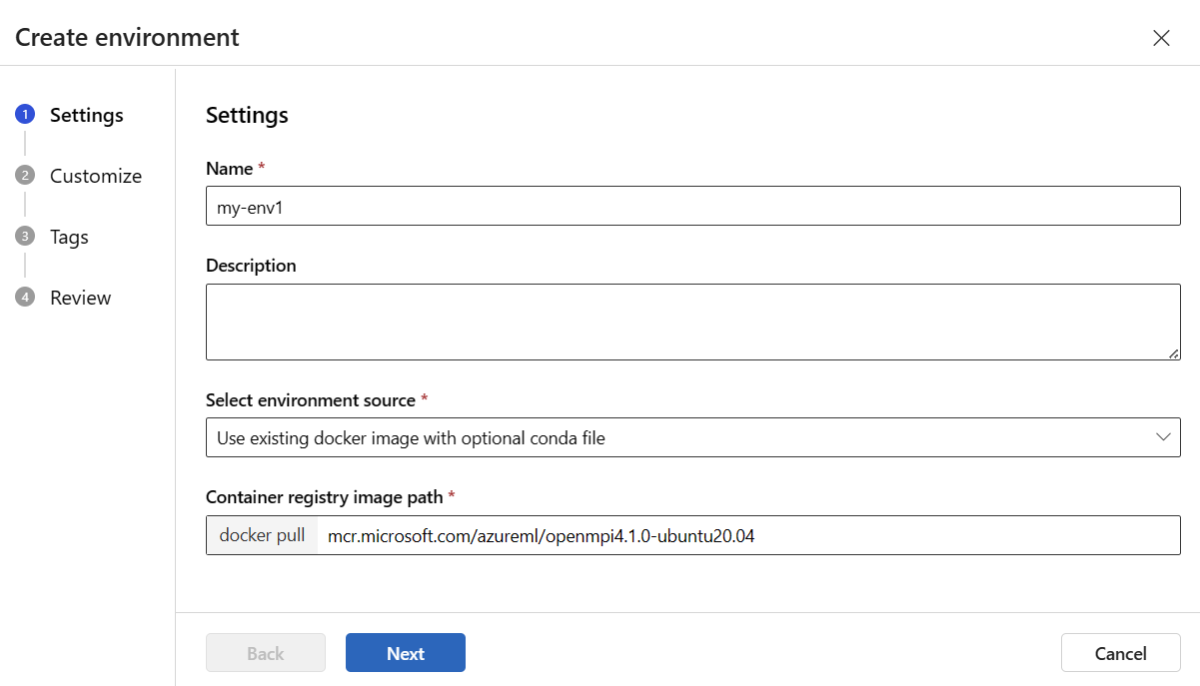
Wybierz przycisk Dalej , aby przejść do strony Dostosowywanie .
Skopiuj zawartość pliku \azureml-examples\cli\endpoints\online\model-1\environment\conda.yaml z sklonowanego lub pobranego wcześniej repozytorium.
Wklej zawartość do pola tekstowego.
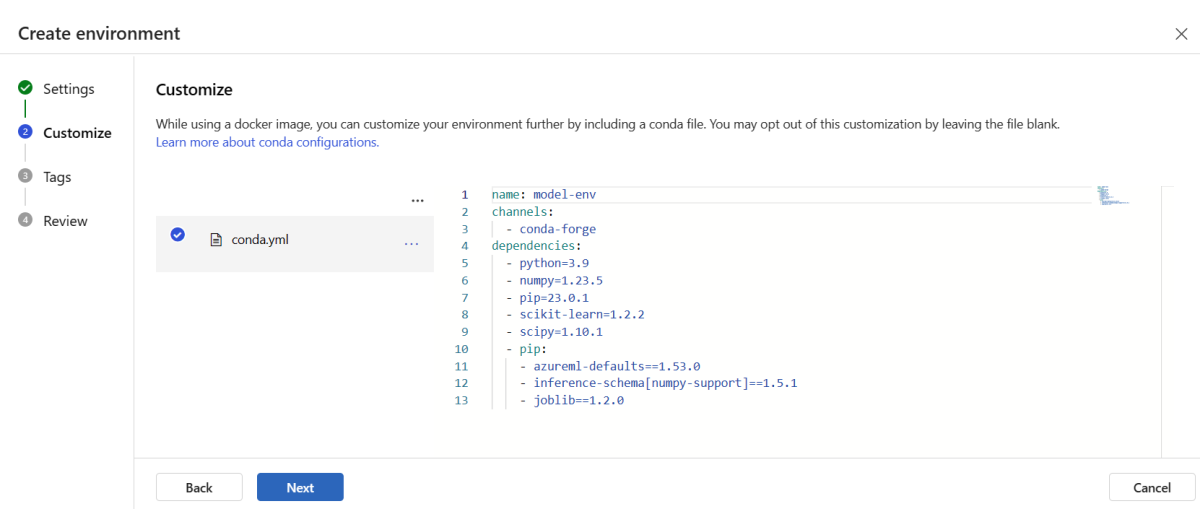
Wybierz przycisk Dalej , dopóki nie zostanie wyświetlona strona Utwórz , a następnie wybierz pozycję Utwórz.
Aby uzyskać więcej informacji na temat tworzenia środowiska w studio, zobacz Tworzenie środowiska.
Aby zarejestrować model przy użyciu szablonu, należy najpierw przekazać plik modelu do usługi Blob Storage. W poniższym przykładzie użyto polecenia az storage blob upload-batch, aby przekazać plik do domyślnego magazynu dla obszaru roboczego.
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/model -s cli/endpoints/online/model-1/model --account-name $AZURE_STORAGE_ACCOUNT
Po przesłaniu pliku, użyj szablonu, aby utworzyć rejestrację modelu. W poniższym przykładzie modelUri parametr zawiera ścieżkę do modelu:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/model-version.json \
--parameters \
workspaceName=$WORKSPACE \
modelAssetName="sklearn" \
modelUri="azureml://subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/workspaces/$WORKSPACE/datastores/$AZUREML_DEFAULT_DATASTORE/paths/model/sklearn_regression_model.pkl"
Częścią środowiska jest plik conda, który określa zależności modelu, które są wymagane do hostowania modelu. W poniższym przykładzie pokazano, jak odczytać zawartość pliku conda do zmiennych środowiskowych:
CONDA_FILE=$(cat cli/endpoints/online/model-1/environment/conda.yaml)
W poniższym przykładzie pokazano, jak używać szablonu do rejestrowania środowiska. Zawartość pliku conda z poprzedniego kroku jest przekazywana do szablonu przy użyciu parametru condaFile :
ENV_VERSION=$RANDOM
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/environment-version.json \
--parameters \
workspaceName=$WORKSPACE \
environmentAssetName=sklearn-env \
environmentAssetVersion=$ENV_VERSION \
dockerImage=mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04:20210727.v1 \
condaFile="$CONDA_FILE"
Ważne
Podczas definiowania środowiska niestandardowego dla wdrożenia upewnij się, że azureml-inference-server-http pakiet jest uwzględniony w pliku conda. Ten pakiet jest niezbędny do prawidłowego działania serwera wnioskowania. Jeśli nie wiesz, jak tworzyć własne niestandardowe środowisko, skorzystaj z jednego z naszych kuratorowanych środowisk, takich jak minimal-py-inference (dla modeli niestandardowych, które nie używają mlflow) lub mlflow-py-inference (dla modeli korzystających z mlflow). Te wyselekcjonowane środowiska można znaleźć na karcie Środowiska wystąpienia usługi Azure Machine Learning Studio.
Konfiguracja wdrożenia używa zarejestrowanego modelu, który chcesz wdrożyć, oraz zarejestrowanego środowiska.
Użyj zarejestrowanych zasobów (modelu i środowiska) w definicji wdrożenia. Poniższy fragment przedstawia plik endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml ze wszystkimi wymaganymi danymi wejściowymi do skonfigurowania wdrożenia:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model: azureml:my-model:1
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment: azureml:my-env:1
instance_type: Standard_DS3_v2
instance_count: 1
Aby skonfigurować wdrożenie, użyj zarejestrowanego modelu i środowiska:
model = "azureml:my-model:1"
env = "azureml:my-env:1"
blue_deployment_with_registered_assets = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
Podczas wdrażania z poziomu programu Studio utworzysz punkt końcowy i wdrożenie, które ma zostać dodane. Wówczas zostanie wyświetlony komunikat o wprowadzenie nazw dla punktu końcowego i wdrożenia.
Użycie różnych typów wystąpień CPU i GPU oraz obrazów
Można określić typy instancji CPU lub GPU oraz obrazy w konfiguracji wdrożenia, zarówno dla wdrożenia lokalnego, jak i wdrożenia na platformie Azure.
Definicja wdrożenia w pliku blue-deployment-with-registered-assets.yml używa instancji typu ogólnego przeznaczenia Standard_DS3_v2 i obrazu Docker mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest bez GPU. W przypadku obliczeń GPU wybierz wersję typu obliczeniowego GPU i obraz Docker dla GPU.
Aby uzyskać informacje o obsługiwanych typach instancji ogólnego przeznaczenia i GPU, zobacz Lista jednostek SKU zarządzanych punktów końcowych online. Aby uzyskać listę bazowych obrazów CPU i GPU usługi Azure Machine Learning, zobacz Obrazy bazowe usługi Azure Machine Learning.
Typy i obrazy wystąpień procesora CPU lub procesora GPU można określić w konfiguracji wdrożenia zarówno dla lokalnego wdrożenia, jak i wdrożenia na platformie Azure.
Wcześniej skonfigurowano wdrożenie, które używało wystąpienia typu Standard_DS3_v2 ogólnego przeznaczenia i obrazu mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest platformy Docker bez procesora GPU. W przypadku obliczeń GPU wybierz wersję typu obliczeniowego GPU i obraz Docker dla GPU.
Aby uzyskać informacje o obsługiwanych typach instancji ogólnego przeznaczenia i GPU, zobacz Lista jednostek SKU zarządzanych punktów końcowych online. Aby uzyskać listę bazowych obrazów CPU i GPU usługi Azure Machine Learning, zobacz Obrazy bazowe usługi Azure Machine Learning.
Poprzednia rejestracja środowiska określa obraz Docker bez GPU, przekazując wartość do szablonu mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04 przy użyciu parametru . W przypadku obliczeń GPU podaj wartość dla obrazu Docker GPU do szablonu (użyj parametru dockerImage) i podaj wersję typu obliczeniowego GPU do szablonu online-endpoint-deployment.json (użyj parametru skuName).
Aby uzyskać informacje o obsługiwanych typach instancji ogólnego przeznaczenia i GPU, zobacz Lista jednostek SKU zarządzanych punktów końcowych online. Aby uzyskać listę bazowych obrazów CPU i GPU usługi Azure Machine Learning, zobacz Obrazy bazowe usługi Azure Machine Learning.
Następnie wdróż punkt końcowy online na platformie Azure.
Wdróż na platformie Azure
Utwórz punkt końcowy w chmurze platformy Azure:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
Utwórz wdrożenie o nazwie blue w punkcie końcowym:
az ml online-deployment create --name blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml --all-traffic
Tworzenie wdrożenia może potrwać do 15 minut, w zależności od tego, czy podstawowe środowisko lub obraz jest tworzony po raz pierwszy. Kolejne wdrożenia korzystające z tego samego środowiska są przetwarzane szybciej.
Jeśli nie chcesz blokować konsoli interfejsu wiersza polecenia, możesz dodać flagę --no-wait do polecenia . Jednak ta opcja zatrzymuje interakcyjne wyświetlanie stanu wdrożenia.
Flaga --all-traffic w kodzie az ml online-deployment create użytym do utworzenia wdrożenia przydziela 100% ruchu punktu końcowego do nowo utworzonego niebieskiego wdrożenia. Użycie tej flagi jest przydatne w celach programistycznych i testowych, ale w środowisku produkcyjnym możesz chcieć kierować ruch do nowego wdrożenia za pomocą jawnego polecenia. Użyj na przykład nazwy az ml online-endpoint update -n $ENDPOINT_NAME --traffic "blue=100".
Utwórz punkt końcowy:
Używając wcześniej zdefiniowanego parametru endpoint oraz parametru MLClient, który utworzyłeś wcześniej, możesz teraz utworzyć punkt końcowy w obszarze roboczym. To polecenie uruchamia tworzenie punktu końcowego i zwraca odpowiedź potwierdzenia, gdy tworzenie punktu końcowego będzie kontynuowane.
ml_client.online_endpoints.begin_create_or_update(endpoint)
Utwórz wdrożenie:
Używając zdefiniowanego wcześniej parametru blue_deployment_with_registered_assets i utworzonego wcześniej parametru MLClient , możesz teraz utworzyć wdrożenie w obszarze roboczym. To polecenie uruchamia tworzenie wdrożenia i zwraca odpowiedź potwierdzenia, gdy tworzenie wdrożenia będzie kontynuowane.
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
Jeśli nie chcesz blokować konsoli języka Python, możesz dodać flagę no_wait=True do parametrów. Jednak ta opcja zatrzymuje interakcyjne wyświetlanie stanu wdrożenia.
# blue deployment takes 100 traffic
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint)
Tworzenie zarządzanego punktu końcowego online i wdrożenia
Użyj programu Studio, aby utworzyć zarządzany punkt końcowy online bezpośrednio w przeglądarce. Podczas tworzenia zarządzanego punktu końcowego online w programie Studio należy zdefiniować początkowe wdrożenie. Nie można utworzyć pustego zarządzanego punktu końcowego online.
Jednym ze sposobów utworzenia zarządzanego punktu końcowego online w programie Studio jest strona Modele . Ta metoda umożliwia również łatwe dodawanie modelu do istniejącego zarządzanego wdrożenia online. Aby wdrożyć model o nazwie model-1 zarejestrowanej wcześniej w sekcji Rejestrowanie modelu i środowiska :
Przejdź do usługi Azure Machine Learning Studio.
W okienku po lewej stronie wybierz stronę Modele .
Wybierz model o nazwie model-1.
Wybierz pozycję Wdróż>punkt końcowy w czasie rzeczywistym.
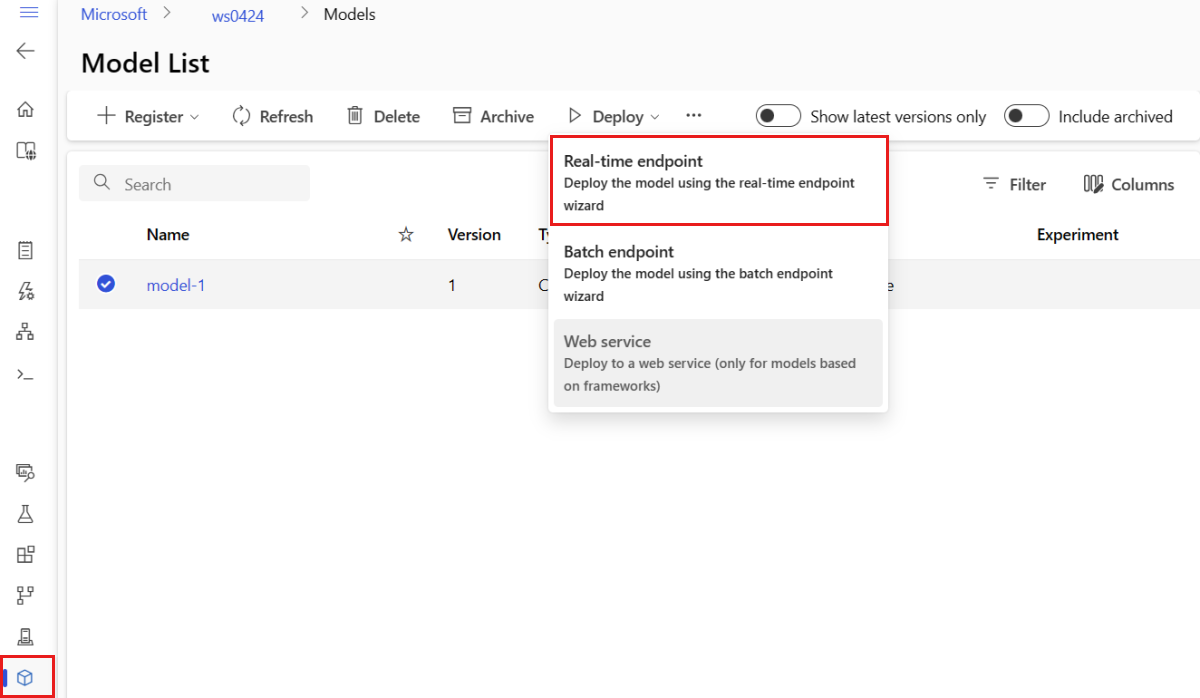
Ta akcja powoduje otwarcie okna, w którym można określić szczegóły dotyczące punktu końcowego.
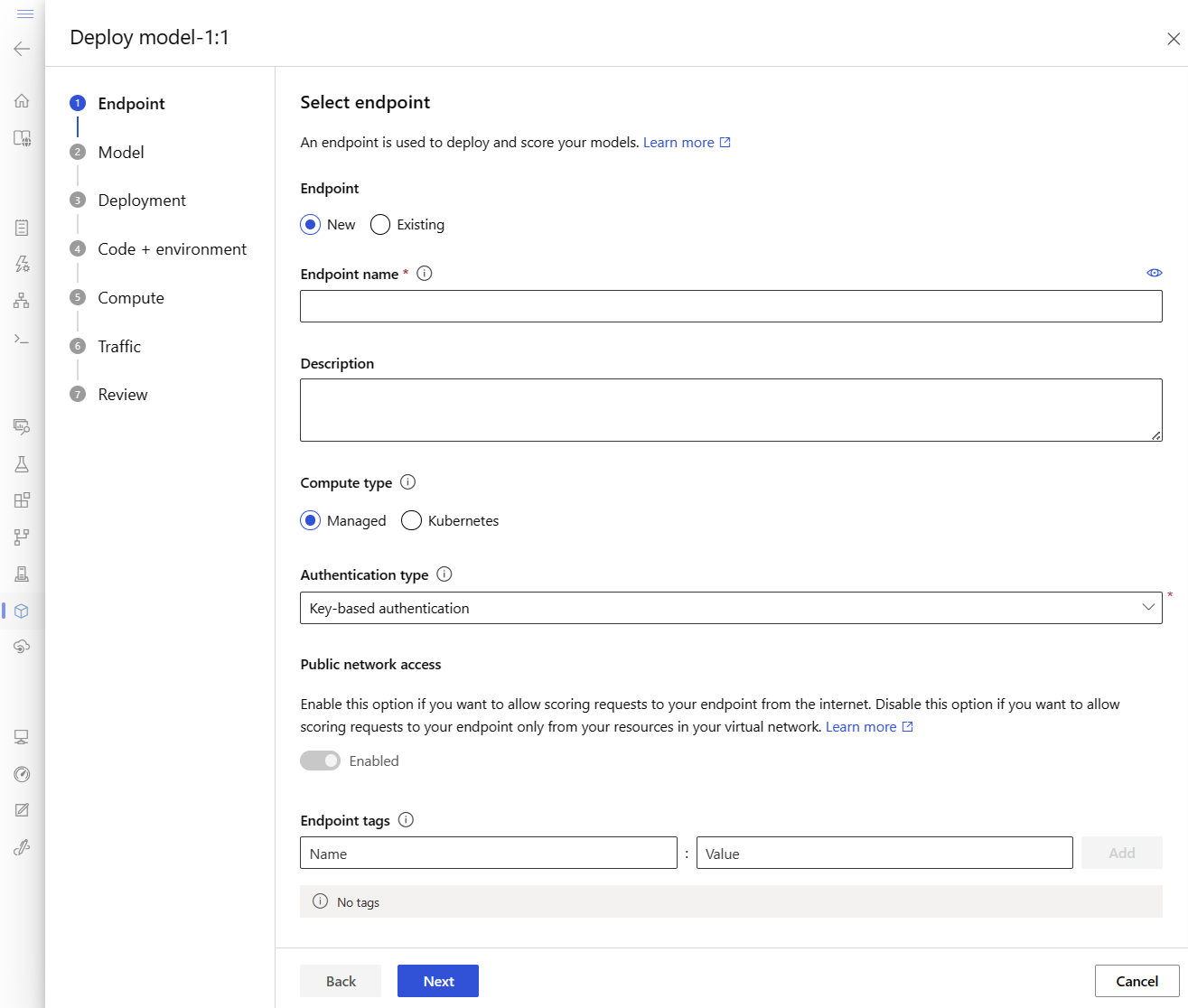
Wprowadź unikatową nazwę punktu końcowego w regionie świadczenia usługi Azure. Aby uzyskać więcej informacji na temat reguł nazewnictwa, zobacz Limity punktów końcowych.
Zachowaj wybór domyślny: Zarządzany dla typu obliczeniowego.
Zachowaj wybór domyślny: uwierzytelnianie oparte na kluczach dla typu uwierzytelniania. Aby uzyskać więcej informacji na temat uwierzytelniania, zobacz Uwierzytelnianie klientów dla punktów końcowych online.
Wybierz przycisk Dalej , dopóki nie zostanie wyświetlona strona Wdrożenie . Przełącz diagnostykę usługi Application Insights na włączone , aby można było wyświetlać grafy działań punktu końcowego w studio później i analizować metryki i dzienniki przy użyciu usługi Application Insights.
Wybierz przycisk Dalej , aby przejść do strony Kod i środowisko . Wybierz jedną z następujących opcji:
-
Wybierz skrypt oceniania na potrzeby wnioskowania: Przejrzyj i wybierz plik \azureml-examples\cli\endpoints\online\model-1\onlinescoring\score.py z wcześniej sklonowanego lub pobranego repozytorium.
-
Wybierz sekcję środowiska: wybierz pozycję Środowiska niestandardowe, a następnie wybierz utworzone wcześniej środowisko my-env:1.
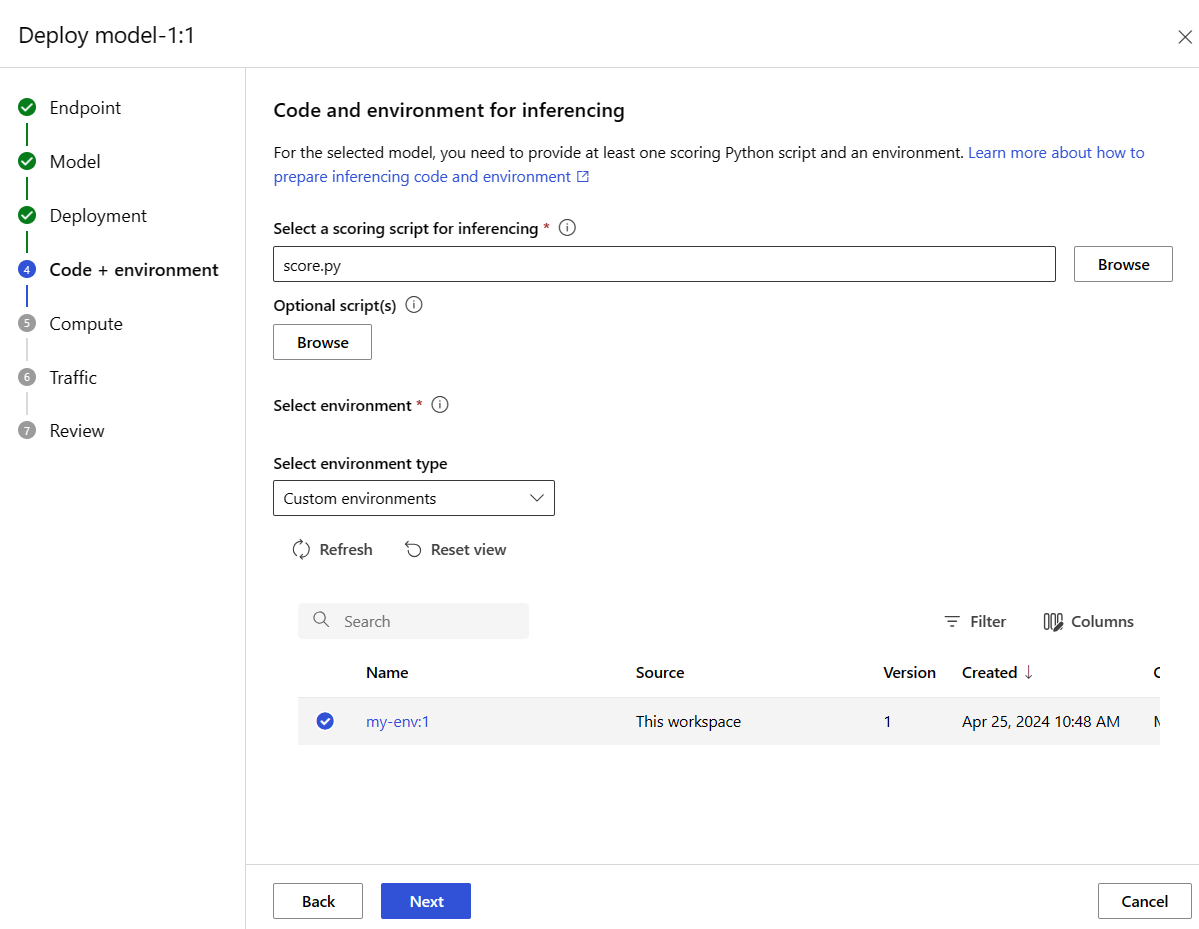
Wybierz pozycję Dalej i zaakceptuj wartości domyślne do momentu wyświetlenia monitu o utworzenie wdrożenia.
Przejrzyj ustawienia wdrożenia i wybierz pozycję Utwórz.
Alternatywnie możesz utworzyć zarządzany punkt końcowy online na stronie Punkty końcowe w programie Studio.
Przejdź do usługi Azure Machine Learning Studio.
W okienku po lewej stronie wybierz stronę Punkty końcowe .
Wybierz + Utwórz.
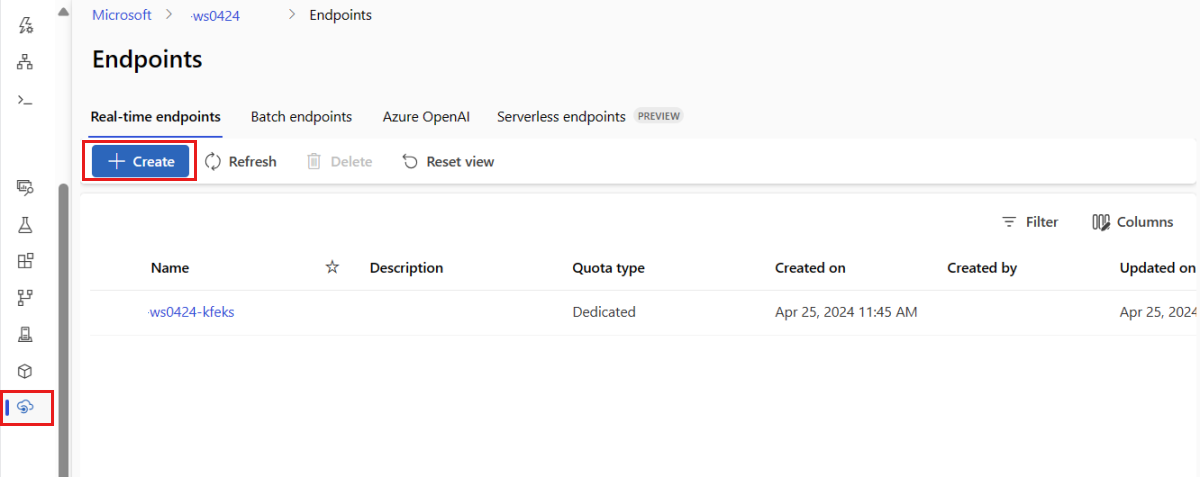
Ta akcja spowoduje otwarcie okna umożliwiającego wybranie modelu i określenie szczegółów dotyczących punktu końcowego i wdrożenia. Wprowadź ustawienia punktu końcowego i wdrożenia zgodnie z wcześniejszym opisem, a następnie wybierz pozycję Utwórz , aby utworzyć wdrożenie.
Użyj szablonu, aby utworzyć punkt końcowy online:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint.json \
--parameters \
workspaceName=$WORKSPACE \
onlineEndpointName=$ENDPOINT_NAME \
identityType=SystemAssigned \
authMode=AMLToken \
location=$LOCATION
Wdróż model do punktu końcowego po jego utworzeniu.
resourceScope="/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices"
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint-deployment.json \
--parameters \
workspaceName=$WORKSPACE \
location=$LOCATION \
onlineEndpointName=$ENDPOINT_NAME \
onlineDeploymentName=blue \
codeId="$resourceScope/workspaces/$WORKSPACE/codes/score-sklearn/versions/1" \
scoringScript=score.py \
environmentId="$resourceScope/workspaces/$WORKSPACE/environments/sklearn-env/versions/$ENV_VERSION" \
model="$resourceScope/workspaces/$WORKSPACE/models/sklearn/versions/1" \
endpointComputeType=Managed \
skuName=Standard_F2s_v2 \
skuCapacity=1
Aby debugować błędy we wdrożeniu, zobacz Rozwiązywanie problemów z wdrożeniami punktów końcowych online.
Sprawdzanie stanu punktu końcowego online
Użyj polecenia show, aby wyświetlić informacje w provisioning_state dla punktu końcowego i wdrożenia.
az ml online-endpoint show -n $ENDPOINT_NAME
Wyświetl listę wszystkich punktów końcowych w obszarze roboczym w formacie tabeli przy użyciu list polecenia :
az ml online-endpoint list --output table
Sprawdź stan punktu końcowego, aby sprawdzić, czy model został wdrożony bez błędu:
ml_client.online_endpoints.get(name=endpoint_name)
Wyświetl listę wszystkich punktów końcowych w obszarze roboczym w formacie tabeli przy użyciu list metody :
for endpoint in ml_client.online_endpoints.list():
print(endpoint.name)
Metoda zwraca listę (iteratora) ManagedOnlineEndpoint jednostek.
Aby uzyskać więcej informacji, określ więcej parametrów. Na przykład wyświetl listę punktów końcowych, takich jak tabela:
print("Kind\tLocation\tName")
print("-------\t----------\t------------------------")
for endpoint in ml_client.online_endpoints.list():
print(f"{endpoint.kind}\t{endpoint.location}\t{endpoint.name}")
Wyświetlanie zarządzanych punktów końcowych online
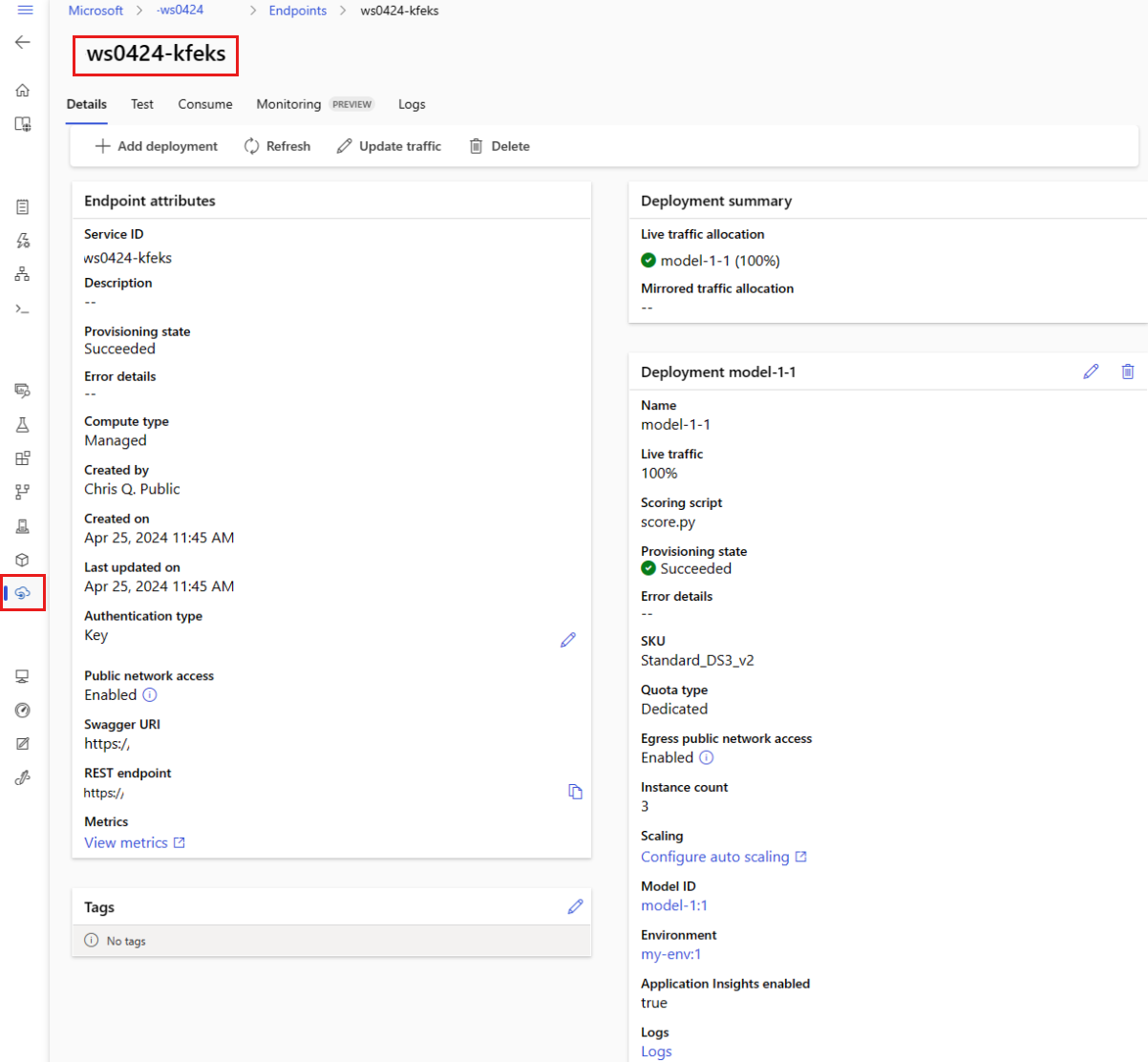
Wszystkie zarządzane punkty końcowe online można wyświetlić na stronie Punkty końcowe . Przejdź do strony Szczegóły punktu końcowego, aby znaleźć krytyczne informacje, takie jak identyfikator URI punktu końcowego, stan, narzędzia do testowania, monitory aktywności, dzienniki wdrażania i przykładowy kod użycia.
W okienku po lewej stronie wybierz pozycję Punkty końcowe , aby wyświetlić listę wszystkich punktów końcowych w obszarze roboczym.
(Opcjonalnie) Utwórz filtr w typie obliczeniowym , aby wyświetlić tylko zarządzane typy obliczeniowe.
Wybierz nazwę punktu końcowego, aby wyświetlić stronę Szczegóły punktu końcowego.
Szablony są przydatne do wdrażania zasobów, ale nie można ich używać do listowania, pokazywania ani wywoływania zasobów. Aby wykonać te operacje, użyj interfejsu wiersza polecenia platformy Azure, zestawu PYTHON SDK lub programu Studio. Poniższy kod używa interfejsu wiersza polecenia platformy Azure.
Użyj polecenia show, aby wyświetlić informacje w parametrze provisioning_state dla punktu końcowego i wdrożenia:
az ml online-endpoint show -n $ENDPOINT_NAME
Wyświetl listę wszystkich punktów końcowych w obszarze roboczym w formacie tabeli przy użyciu list polecenia :
az ml online-endpoint list --output table
Sprawdzanie stanu wdrożenia online
Sprawdź dzienniki, aby sprawdzić, czy model został wdrożony bez błędu.
Aby wyświetlić dane wyjściowe dziennika z kontenera, użyj następującego polecenia interfejsu wiersza polecenia:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Domyślnie dzienniki są pobierane z kontenera serwera wnioskowania. Aby wyświetlić dzienniki z kontenera inicjatora magazynu, dodaj flagę --container storage-initializer . Aby uzyskać więcej informacji na temat dzienników wdrażania, zobacz Pobieranie dzienników kontenera.
Dane wyjściowe dziennika można wyświetlić przy użyciu get_logs metody :
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
Domyślnie dzienniki są pobierane z kontenera serwera wnioskowania. Aby zobaczyć dzienniki z kontenera inicjatora magazynu, dodaj opcję container_type="storage-initializer". Aby uzyskać więcej informacji na temat dzienników wdrażania, zobacz Pobieranie dzienników kontenera.
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50, container_type="storage-initializer"
)
Aby wyświetlić dane wyjściowe dziennika, wybierz kartę Dzienniki na stronie punktu końcowego. Jeśli masz wiele wdrożeń w punkcie docelowym, użyj listy rozwijanej, aby wybrać wdrożenie z logiem, który chcesz wyświetlić.
Domyślnie dzienniki są pobierane z serwera wnioskowania. Aby wyświetlić dzienniki z kontenera inicjatora magazynu, użyj interfejsu wiersza polecenia platformy Azure lub zestawu SDK języka Python (zobacz każdą kartę, aby uzyskać szczegółowe informacje). Dzienniki z kontenera inicjującego magazyn zawierają informacje o tym, czy kod i dane modelu zostały pomyślnie pobrane do kontenera. Aby uzyskać więcej informacji na temat dzienników wdrażania, zobacz Pobieranie dzienników kontenera.
Szablony są przydatne do wdrażania zasobów, ale nie można ich używać do listowania, pokazywania ani wywoływania zasobów. Aby wykonać te operacje, użyj interfejsu wiersza polecenia platformy Azure, zestawu PYTHON SDK lub programu Studio. Poniższy kod używa interfejsu wiersza polecenia platformy Azure.
Aby wyświetlić dane wyjściowe dziennika z kontenera, użyj następującego polecenia interfejsu wiersza polecenia:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Domyślnie dzienniki są pobierane z kontenera serwera wnioskowania. Aby wyświetlić dzienniki z kontenera inicjatora magazynu, dodaj flagę --container storage-initializer . Aby uzyskać więcej informacji na temat dzienników wdrażania, zobacz Pobieranie dzienników kontenera.
Wywoływanie punktu końcowego w celu oceny danych przy użyciu modelu
invoke Użyj wybranego polecenia lub klienta REST, aby wywołać punkt końcowy i ocenić niektóre dane:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
Pobierz klucz używany do uwierzytelniania w punkcie końcowym:
Możesz kontrolować, które podmioty zabezpieczeń Microsoft Entra mogą uzyskać klucz uwierzytelniania, przypisując je do roli niestandardowej, która zezwala na Microsoft.MachineLearningServices/workspaces/onlineEndpoints/token/action i Microsoft.MachineLearningServices/workspaces/onlineEndpoints/listkeys/action. Aby uzyskać więcej informacji na temat zarządzania autoryzacją w obszarach roboczych, zobacz Zarządzanie dostępem do obszaru roboczego usługi Azure Machine Learning.
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n $ENDPOINT_NAME -o tsv --query primaryKey)
Użyj narzędzia curl, aby ocenić dane.
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @endpoints/online/model-1/sample-request.json
Zwróć uwagę, że używasz poleceń show i get-credentials, aby uzyskać poświadczenia uwierzytelniania. Zwróć również uwagę, że używasz flagi --query do filtrowania tylko wymaganych atrybutów. Aby dowiedzieć się więcej na temat flagi --query, zobacz Zapytanie o dane wyjściowe polecenia Azure CLI.
Aby wyświetlić dzienniki wywołania, uruchom ponownie get-logs.
Korzystając z utworzonego wcześniej parametru MLClient , uzyskasz dojście do punktu końcowego. Następnie można wywołać punkt końcowy przy użyciu invoke polecenia z następującymi parametrami:
-
endpoint_name: nazwa punktu końcowego.
-
request_file: Plik z danymi żądania.
-
deployment_name: nazwa konkretnego wdrożenia do testowania na punkcie końcowym.
Wyślij przykładowe żądanie przy użyciu pliku JSON .
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
deployment_name="blue",
request_file="../model-1/sample-request.json",
)
Użyj karty Test na stronie szczegółów punktu końcowego, aby przetestować zarządzane wdrożenie online. Wprowadź przykładowe dane wejściowe i wyświetl wyniki.
Wybierz kartę Test na stronie szczegółów punktu końcowego.
Użyj listy rozwijanej, aby wybrać wdrożenie, które chcesz przetestować.
Wprowadź przykładowe dane wejściowe.
Kliknij przycisk Testuj.
Szablony są przydatne do wdrażania zasobów, ale nie można ich używać do listowania, pokazywania ani wywoływania zasobów. Aby wykonać te operacje, użyj interfejsu wiersza polecenia platformy Azure, zestawu PYTHON SDK lub programu Studio. Poniższy kod używa interfejsu wiersza polecenia platformy Azure.
invoke Użyj wybranego polecenia lub klienta REST, aby wywołać punkt końcowy i ocenić niektóre dane:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file cli/endpoints/online/model-1/sample-request.json
(Opcjonalnie) Aktualizowanie wdrożenia
Jeśli chcesz zaktualizować kod, model lub środowisko, zaktualizuj plik YAML. Następnie uruchom az ml online-endpoint update polecenie .
Jeśli zaktualizujesz liczbę wystąpień (w celu skalowania wdrożenia) wraz z innymi ustawieniami modelu (takimi jak kod, model lub środowisko) w jednym update poleceniu, najpierw wykonywana jest operacja skalowania. Pozostałe aktualizacje zostaną zastosowane w następnej kolejności. Dobrym rozwiązaniem jest oddzielne wykonywanie tych operacji w środowisku produkcyjnym.
Aby zrozumieć, jak update działa:
Otwórz plik online/model-1/onlinescoring/score.py.
Zmień ostatni wiersz funkcji init(): po logging.info("Init complete") dodaj logging.info("Updated successfully").
Zapisz plik.
Uruchom następujące polecenie:
az ml online-deployment update -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml
Aktualizowanie przy użyciu języka YAML jest deklaratywne. Oznacza to, że zmiany w yaML są odzwierciedlane w podstawowych zasobach usługi Resource Manager (punktach końcowych i wdrożeniach). Podejście deklaratywne ułatwia metodykę GitOps: wszystkie zmiany w punktach końcowych i wdrożeniach (nawet instance_count) przechodzą przez kod YAML.
Możesz użyć ogólnych parametrów aktualizacji, takich jak --set parametr, poleceniem CLI update, aby zastąpić atrybuty w YAML lub ustawić określone atrybuty bez przekazywania ich w pliku YAML. Używanie --set dla pojedynczych atrybutów jest szczególnie przydatne w scenariuszach programowania i testowania. Na przykład, aby skalować wartość w górę instance_count dla pierwszego wdrożenia, możesz użyć flagi --set instance_count=2 . Jednak ze względu na to, że kod YAML nie jest aktualizowany, ta technika nie ułatwia metodyki GitOps.
Określanie pliku YAML nie jest obowiązkowe. Jeśli na przykład chcesz przetestować różne ustawienia współbieżności dla określonego wdrożenia, możesz wypróbować coś takiego jak az ml online-deployment update -n blue -e my-endpoint --set request_settings.max_concurrent_requests_per_instance=4 environment_variables.WORKER_COUNT=4. Takie podejście zachowuje całą istniejącą konfigurację, ale aktualizuje tylko określone parametry.
Ponieważ zmodyfikowano funkcję, która jest uruchamiana po utworzeniu init() lub zaktualizowaniu punktu końcowego, komunikat Updated successfully pojawia się w dziennikach. Pobierz dzienniki, uruchamiając poniższe polecenie:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Polecenie update działa również z wdrożeniami lokalnymi. Użyj tego samego az ml online-deployment update polecenia z flagą --local .
Jeśli chcesz zaktualizować kod, model lub środowisko, zaktualizuj konfigurację, a następnie uruchom metodę MLClientonline_deployments.begin_create_or_update w celu utworzenia lub zaktualizowania wdrożenia.
Jeśli zaktualizujesz liczbę wystąpień (w celu skalowania wdrożenia) wraz z innymi ustawieniami modelu (takimi jak kod, model lub środowisko) w jednej begin_create_or_update metodzie, najpierw wykonywana jest operacja skalowania. Następnie zostaną zastosowane inne aktualizacje. Dobrym rozwiązaniem jest oddzielne wykonywanie tych operacji w środowisku produkcyjnym.
Aby zrozumieć, jak begin_create_or_update działa:
Otwórz plik online/model-1/onlinescoring/score.py.
Zmień ostatni wiersz funkcji init(): po logging.info("Init complete") dodaj logging.info("Updated successfully").
Zapisz plik.
Uruchom metodę:
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
Ponieważ zmodyfikowano funkcję, która jest uruchamiana po utworzeniu init() lub zaktualizowaniu punktu końcowego, komunikat Updated successfully pojawia się w dziennikach. Pobierz dzienniki, uruchamiając poniższe polecenie:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
Metoda begin_create_or_update współpracuje również z wdrożeniami lokalnymi. Użyj tej samej metody z flagą local=True .
Obecnie można aktualizować tylko liczbę instancji wdrożenia. Skorzystaj z poniższych instrukcji, aby skalować pojedyncze wdrożenie w górę lub w dół, dostosowując liczbę wystąpień:
- Otwórz stronę Szczegóły punktu końcowego i znajdź kartę z wdrożeniem, które chcesz zaktualizować.
- Wybierz ikonę edycji (ikonę ołówka) obok nazwy wdrożenia.
- Zaktualizuj liczbę wystąpień skojarzonych z wdrożeniem. Wybierz opcję Domyślne lub Docelowe wykorzystanie dla typu skalowania wdrożenia.
- Jeśli wybierzesz wartość Domyślna, możesz również określić wartość liczbową dla pozycji Liczba wystąpień.
- W przypadku wybrania opcji Wykorzystanie docelowe można określić wartości, które mają być używane dla parametrów podczas automatycznego skalowania wdrożenia.
- Wybierz Aktualizuj, aby zakończyć aktualizację liczby instancji w wdrożeniu.
Obecnie nie ma możliwości zaktualizowania wdrożenia przy użyciu szablonu ARM.
Uwaga
Aktualizacja wdrożenia w tej sekcji jest przykładem aktualizacji ciągłej bez przestojów.
- W przypadku zarządzanego punktu końcowego online wdrożenie jest aktualizowane do nowej konfiguracji, aktualizując jednocześnie 20% węzłów. Oznacza to, że jeśli wdrożenie ma 10 węzłów, aktualizowane są 2 węzły naraz.
- W przypadku punktu końcowego Kubernetes online, system iteracyjnie tworzy nowe wystąpienie wdrożenia z nową konfiguracją i usuwa stare.
- W przypadku użycia produkcyjnego rozważ wdrożenie niebiesko-zielone, które oferuje bezpieczniejsze rozwiązanie do aktualizowania usługi internetowej.
Automatyczne skalowanie uruchamia właściwą liczbę zasobów w celu obsługi obciążenia aplikacji. Zarządzane punkty końcowe online obsługują skalowanie automatyczne za pośrednictwem integracji z funkcją automatycznego skalowania usługi Azure Monitor. Aby skonfigurować skalowanie automatyczne, zobacz Autoskalowanie punktów końcowych online.
(Opcjonalnie) Monitorowanie umowy SLA przy użyciu usługi Azure Monitor
Aby wyświetlić metryki i ustawić alerty na podstawie umowy SLA, wykonaj kroki opisane w temacie Monitorowanie punktów końcowych online.
(Opcjonalnie) Integracja z usługą Log Analytics
Polecenie get-logs dla interfejsu CLI lub metoda get_logs dla zestawu SDK dostarcza tylko kilkaset ostatnich wierszy logów z automatycznie wybranego wystąpienia. Jednak usługa Log Analytics umożliwia trwałe przechowywanie i analizowanie dzienników. Aby uzyskać więcej informacji na temat korzystania z rejestrowania, zobacz Używanie dzienników.
Usuń punkt końcowy i wdrożenie
Użyj następującego polecenia, aby usunąć punkt końcowy i wszystkie jego podstawowe wdrożenia:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
Użyj następującego polecenia, aby usunąć punkt końcowy i wszystkie jego podstawowe wdrożenia:
ml_client.online_endpoints.begin_delete(name=endpoint_name)
Jeśli nie zamierzasz używać punktu końcowego i wdrożenia, usuń je. Usunięcie punktu końcowego powoduje również usunięcie wszystkich jego wdrożeń bazowych.
- Przejdź do usługi Azure Machine Learning Studio.
- W okienku po lewej stronie wybierz stronę Punkty końcowe .
- Wybierz punkt końcowy.
- Wybierz Usuń.
Alternatywnie możesz usunąć zarządzany punkt końcowy online bezpośrednio, wybierając ikonę Usuń na stronie szczegółów punktu końcowego.
Użyj następującego polecenia, aby usunąć punkt końcowy i wszystkie jego podstawowe wdrożenia:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
Powiązana zawartość









