Integrowanie przepływu monitów z usługą DevOps dla aplikacji opartych na usłudze LLM
Przepływ monitów usługi Azure Machine Learning to przyjazna dla deweloperów i łatwa w użyciu metoda typu code-first do tworzenia i iterowania przepływów na potrzeby tworzenia aplikacji opartych na dużym modelu językowym (LLM). Przepływ monitów udostępnia zestaw SDK i interfejs wiersza polecenia, rozszerzenie programu Visual Studio Code oraz interfejs użytkownika tworzenia przepływu. Te narzędzia ułatwiają tworzenie przepływów lokalnych, wyzwalanie przebiegu przepływu lokalnego i uruchamianie oceny oraz przenoszenie przepływów między środowiskami obszaru roboczego lokalnego i chmury.
Możesz połączyć środowisko przepływu monitów i możliwości kodu z operacjami deweloperskimi (DevOps), aby ulepszyć przepływy pracy tworzenia aplikacji oparte na usłudze LLM. Ten artykuł koncentruje się na integracji przepływu monitów i metodyki DevOps dla aplikacji opartych na usłudze Azure Machine Learning LLM.
Na poniższym diagramie przedstawiono interakcję z lokalnym i chmurowym tworzeniem przepływu monitów za pomocą metodyki DevOps.

Wymagania wstępne
Obszar roboczy usługi Azure Machine Learning. Aby je utworzyć, zobacz Tworzenie zasobów, aby rozpocząć pracę.
Lokalne środowisko języka Python z zainstalowanym zestawem SDK języka Python usługi Azure Machine Learning w wersji 2 zostało utworzone zgodnie z instrukcjami w temacie Wprowadzenie.
Uwaga
To środowisko jest oddzielone od środowiska używanego przez sesję obliczeniową do uruchamiania przepływu, który definiuje się jako część przepływu. Aby uzyskać więcej informacji, zobacz Zarządzanie sesją obliczeniową przepływu monitów w usłudze Azure Machine Learning Studio.
Program Visual Studio Code z zainstalowanymi rozszerzeniami przepływu Python i Monituj.

Używanie środowiska code-first w przepływie monitu
Tworzenie aplikacji opartych na języku LLM zwykle jest zgodne ze standardowym procesem inżynierii aplikacji, który obejmuje repozytoria kodu źródłowego i potoki ciągłego wdrażania/ciągłego wdrażania (CI/CD). Ten proces promuje usprawnione programowanie, kontrolę wersji i współpracę między członkami zespołu.
Integrowanie metodyki DevOps z interfejsem kodu przepływu monitów oferuje deweloperom kodu wydajniejszy proces iteracji GenAIOps lub LLMOps z następującymi kluczowymi funkcjami i korzyściami:
Przechowywanie wersji przepływu w repozytorium kodu. Pliki przepływu można definiować w formacie YAML i być zgodne z przywoływanymi plikami źródłowymi w tej samej strukturze folderów.
Integracja przebiegu przepływu z potokami ciągłej integracji/ciągłego wdrażania. Przepływ monitów można bezproblemowo zintegrować z potokami ciągłej integracji/ciągłego wdrażania i procesem dostarczania przy użyciu interfejsu wiersza polecenia przepływu monitu lub zestawu SDK w celu automatycznego wyzwalania przebiegów przepływu.
Bezproblemowe przejście między chmurą i lokalną. Możesz łatwo wyeksportować folder przepływu do lokalnego lub nadrzędnego repozytorium kodu na potrzeby kontroli wersji, programowania lokalnego i udostępniania. Możesz również bez wysiłku zaimportować folder przepływu z powrotem do usługi Azure Machine Learning w celu dalszego tworzenia, testowania i wdrażania przy użyciu zasobów w chmurze.
Kod przepływu monitu dostępu
Każdy przepływ monitów ma strukturę folderów przepływu zawierającą niezbędne pliki kodu definiujące przepływ. Struktura folderów organizuje przepływ, ułatwiając bezproblemowe przejścia między środowiskiem lokalnym i chmurą.
Usługa Azure Machine Learning udostępnia udostępniony system plików dla wszystkich użytkowników obszaru roboczego. Po utworzeniu przepływu odpowiedni folder przepływu jest automatycznie generowany i przechowywany w katalogu Users/<username>/promptflow .

Praca z plikami kodu przepływu
Po utworzeniu przepływu w usłudze Azure Machine Learning Studio możesz wyświetlać, edytować i zarządzać plikami przepływu w sekcji Pliki na stronie tworzenia przepływu. Wszelkie modyfikacje wprowadzone w plikach odzwierciedlają się bezpośrednio w magazynie udziałów plików.

Folder przepływu dla przepływu opartego na usłudze LLM zawiera następujące pliki kluczy.
flow.dag.yaml jest podstawowym plikiem definicji przepływu w formacie YAML. Ten plik jest integralną częścią tworzenia i definiowania przepływu monitu. Plik zawiera informacje o danych wejściowych, danych wyjściowych, węzłach, narzędziach i wariantach używanych przez przepływ.
Pliki kodu źródłowego zarządzanego przez użytkownika w języku Python (.py) lub Jinja 2 (jinja2) konfigurują narzędzia i węzły w przepływie. Narzędzie języka Python używa plików języka Python do definiowania niestandardowej logiki języka Python. Narzędzie monitu i narzędzie LLM używają plików Jinja 2 do zdefiniowania kontekstu monitu.
Pliki inne niż źródła, takie jak narzędzia i pliki danych, mogą być zawarte w folderze przepływu wraz z plikami źródłowymi.
Aby wyświetlić i edytować nieprzetworzone kod plików flow.dag.yaml i źródłowych w edytorze plików, włącz tryb nieprzetworzonych plików.

Alternatywnie możesz uzyskiwać dostęp do wszystkich folderów i plików przepływu oraz edytować je na stronie Notesy usługi Azure Machine Learning Studio.

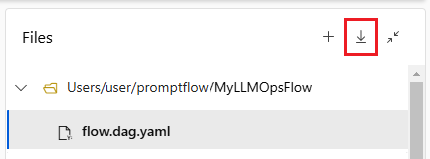
Pobierz i zaewidencjonuj kod przepływu monitu
Aby sprawdzić przepływ do repozytorium kodu, wyeksportuj folder przepływu z usługi Azure Machine Learning Studio do komputera lokalnego. Wybierz ikonę pobierania w sekcji Pliki strony tworzenia przepływu, aby pobrać pakiet ZIP zawierający wszystkie pliki przepływu. Następnie możesz sprawdzić ten plik w repozytorium kodu lub rozpakować go, aby pracować z plikami lokalnie.
Aby uzyskać więcej informacji na temat integracji metodyki DevOps z usługą Azure Machine Learning, zobacz Integracja z usługą Git dla usługi Azure Machine Learning.
Programowanie i testowanie lokalne
W miarę udoskonalania i dostosowywania przepływu lub monitów podczas opracowywania iteracyjnego można wykonywać wiele iteracji lokalnie w repozytorium kodu. Wersja społeczności programu VS Code, rozszerzenie przepływu monitu programu VS Code oraz lokalny zestaw SDK i interfejs wiersza polecenia monitu ułatwiają tworzenie i testowanie bez powiązania platformy Azure.
Praca lokalna umożliwia szybkie wprowadzanie i testowanie zmian bez konieczności każdorazowego aktualizowania głównego repozytorium kodu. Aby uzyskać więcej szczegółów i wskazówek dotyczących korzystania z wersji lokalnych, zapoznaj się ze społecznością GitHub monituj o przepływ.
Korzystanie z rozszerzenia przepływu monitu programu VS Code
Korzystając z rozszerzenia VS Code Monituj przepływ, możesz łatwo utworzyć przepływ lokalnie w edytorze programu VS Code z podobnym środowiskiem interfejsu użytkownika, jak w chmurze.
Aby edytować pliki lokalnie w programie VS Code za pomocą rozszerzenia Monituj przepływ:
W programie VS Code z włączonym rozszerzeniem przepływu monitu otwórz folder przepływu monitów.
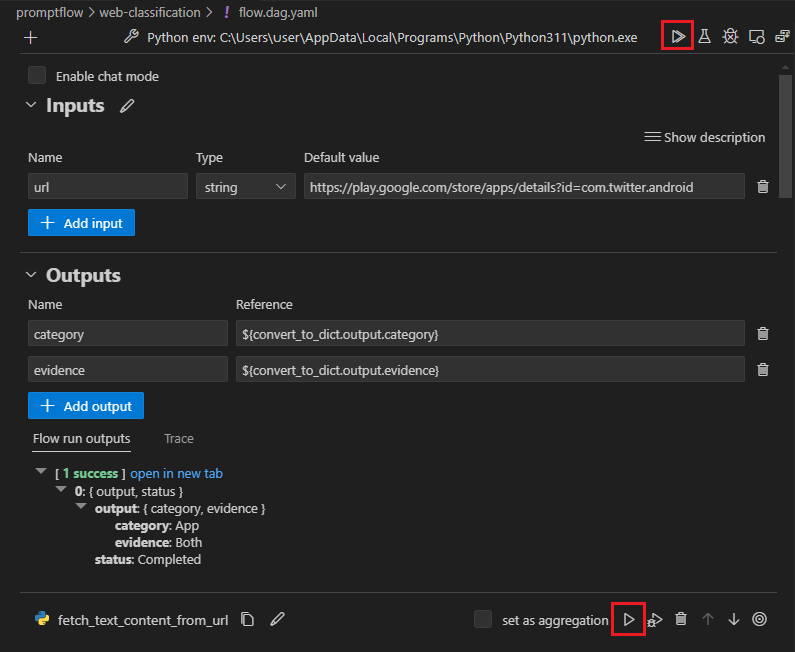
Otwórz plik flow.dag.yaml i wybierz link Edytor wizualizacji w górnej części pliku.
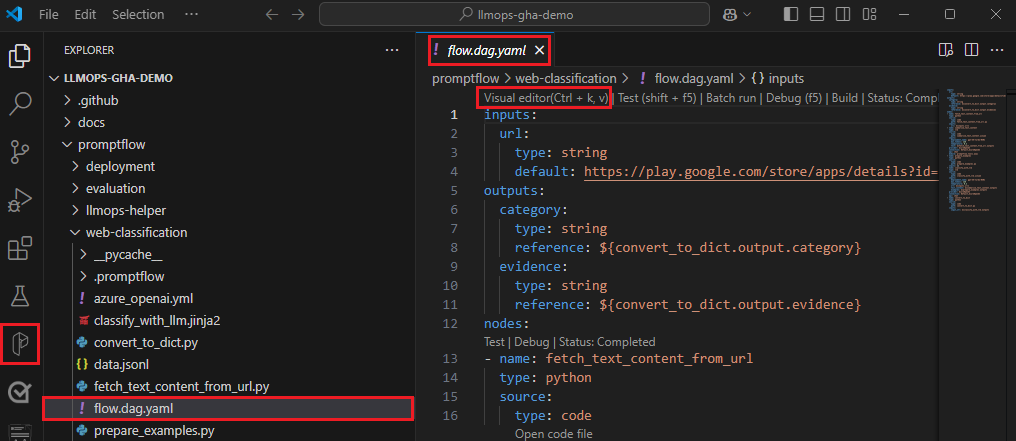
Użyj edytora wizualizacji przepływu monitu, aby wprowadzić zmiany w przepływie, takie jak dostrajanie monitów w wariantach lub dodawanie większej liczby węzłów.
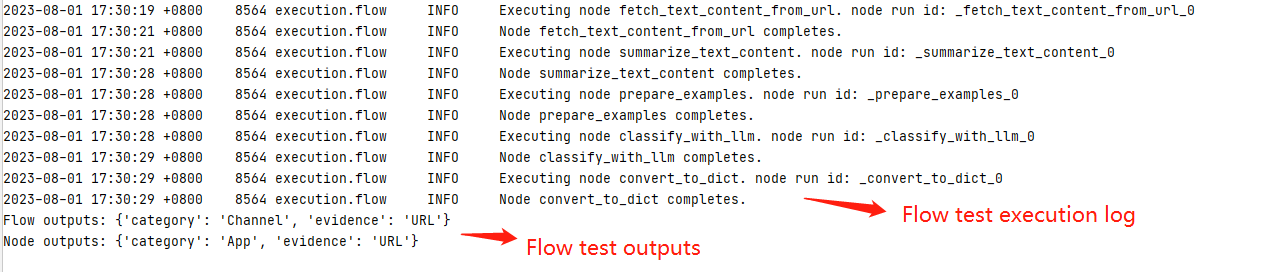
Aby przetestować przepływ, wybierz ikonę Uruchom w górnej części edytora wizualizacji lub aby przetestować dowolny węzeł, wybierz ikonę Uruchom w górnej części węzła.



Korzystanie z zestawu SDK przepływu monitów i interfejsu wiersza polecenia
Jeśli wolisz pracować bezpośrednio w kodzie lub użyć programu Jupyter, PyCharm, Visual Studio lub innego zintegrowanego środowiska projektowego (IDE), możesz bezpośrednio zmodyfikować kod YAML w pliku flow.dag.yaml .

Następnie można wyzwolić pojedynczy przebieg przepływu na potrzeby testowania przy użyciu interfejsu wiersza polecenia przepływu monitu lub zestawu SDK w terminalu w następujący sposób.
Aby wyzwolić uruchomienie z katalogu roboczego, uruchom następujący kod:
pf flow test --flow <directory-name>
Zwracane wartości to dzienniki i dane wyjściowe testów.

Przesyłanie przebiegów do chmury z repozytorium lokalnego
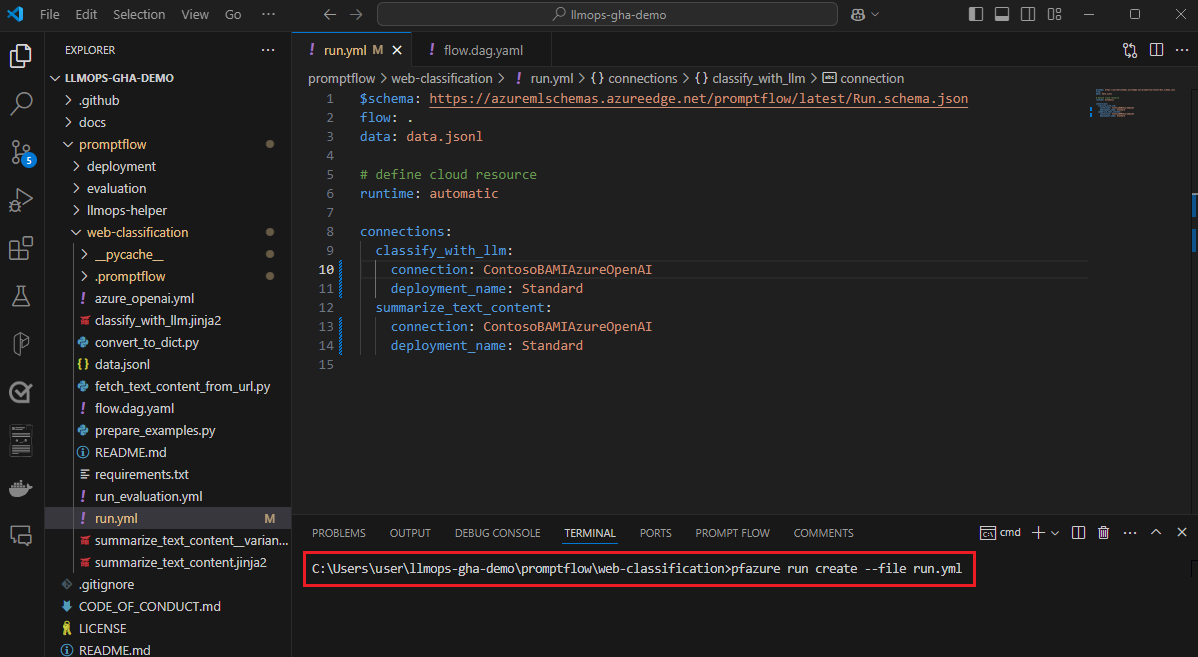
Gdy wyniki testowania lokalnego będą zadowalające, możesz użyć interfejsu wiersza polecenia przepływu monitu lub zestawu SDK, aby przesłać przebiegi do chmury z repozytorium lokalnego. Poniższa procedura i kod są oparte na projekcie pokazowym klasyfikacji internetowej w usłudze GitHub. Możesz sklonować repozytorium projektu lub pobrać kod przepływu monitu do komputera lokalnego.
Instalowanie zestawu SDK przepływu monitów
Zainstaluj zestaw SDK/interfejs wiersza polecenia przepływu monitu platformy Azure, uruchamiając polecenie pip install promptflow[azure] promptflow-tools.
Jeśli używasz projektu demonstracyjnego, pobierz zestaw SDK i inne niezbędne pakiety, instalując requirements.txt za pomocą poleceniapip install -r <path>/requirements.txt.
Nawiązywanie połączenia z obszarem roboczym usługi Azure Machine Learning
Przekazywanie przepływu i tworzenie przebiegu
Przygotuj plik run.yml do zdefiniowania konfiguracji dla tego przepływu uruchomionego w chmurze.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path-to-flow>
data: <path-to-flow>/<data-file>.jsonl
column_mapping:
url: ${data.url}
# Define cloud compute resource
resources:
instance_type: <compute-type>
# If using compute instance compute type, also specify instance name
# compute: <compute-instance-name>
# Specify connections
<node-name>:
connection: <connection-name>
deployment_name: <deployment-name>
Możesz określić nazwę połączenia i wdrożenia dla każdego narzędzia w przepływie, który wymaga połączenia. Jeśli nie określisz nazwy połączenia i wdrożenia, narzędzie użyje połączenia i wdrożenia w pliku flow.dag.yaml . Użyj następującego kodu, aby sformatować połączenia:
...
connections:
<node-name>:
connection: <connection-name>
deployment_name: <deployment-name>
...
Utwórz przebieg.
pfazure run create --file run.yml
Tworzenie przebiegu przepływu oceny
Przygotuj plik run_evaluation.yml, aby zdefiniować konfigurację dla tego przepływu oceny uruchomionego w chmurze.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path-to-flow>
data: <path-to-flow>/<data-file>.jsonl
run: <id-of-base-flow-run>
column_mapping:
<input-name>: ${data.<column-from-test-dataset>}
<input-name>: ${run.outputs.<column-from-run-output>}
resources:
instance_type: <compute-type>
compute: <compute_instance_name>
connections:
<node-name>:
connection: <connection-name>
deployment_name: <deployment-name>
<node-name>:
connection: <connection-name>
deployment_name: <deployment-name>
Utwórz przebieg oceny.
pfazure run create --file run_evaluation.yml
Wyświetlanie wyników przebiegu
Przesyłanie przebiegu przepływu do chmury zwraca adres URL chmury przebiegu. Możesz otworzyć adres URL, aby wyświetlić wyniki przebiegu w usłudze Azure Machine Learning Studio. Możesz również uruchomić następujące polecenia interfejsu wiersza polecenia lub zestawu SDK, aby wyświetlić wyniki uruchamiania.
Przesyłanie strumieniowe dzienników
pfazure run stream --name <run-name>
Wyświetlanie danych wyjściowych przebiegu
pfazure run show-details --name <run-name>
Wyświetlanie metryk przebiegu oceny
pfazure run show-metrics --name <evaluation-run-name>
Integracja z usługą DevOps
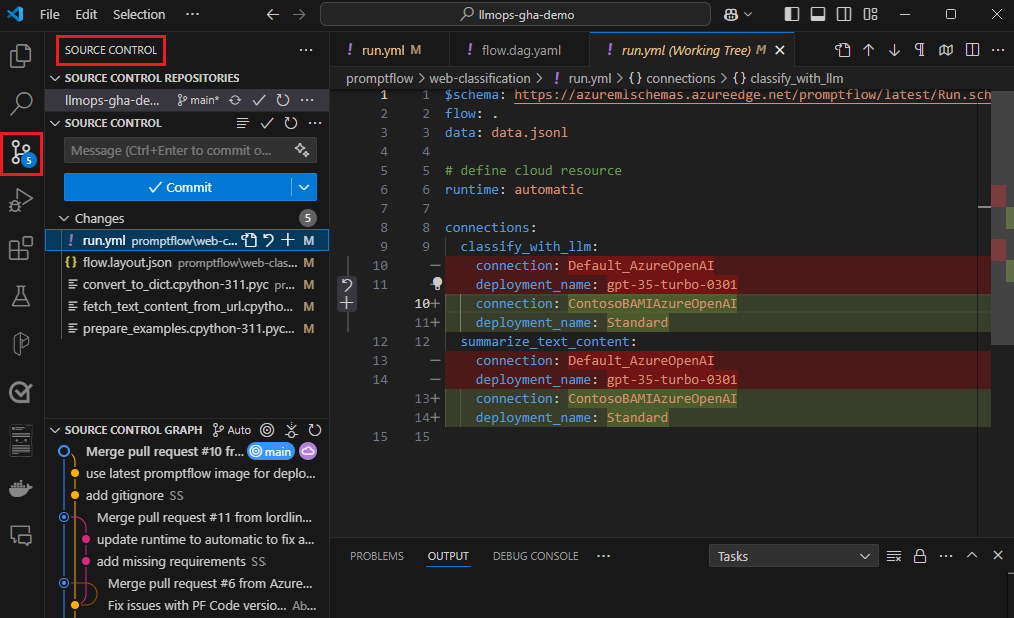
Połączenie lokalnego środowiska programistycznego i systemu kontroli wersji, takiego jak Git, jest zwykle najbardziej skuteczne w przypadku programowania iteracyjnego. Możesz wprowadzić modyfikacje i przetestować kod lokalnie, a następnie zatwierdzić zmiany w usłudze Git. Ten proces tworzy bieżący rekord zmian i umożliwia przywrócenie wcześniejszych wersji w razie potrzeby.
Jeśli musisz udostępniać przepływy w różnych środowiskach, możesz wypchnąć je do repozytorium kodu opartego na chmurze, takiego jak GitHub lub Azure Repos. Ta strategia umożliwia dostęp do najnowszej wersji kodu z dowolnej lokalizacji i udostępnia narzędzia do współpracy i zarządzania kodem.
Postępując zgodnie z tymi rozwiązaniami, zespoły mogą tworzyć bezproblemowe, wydajne i wydajne środowisko współpracy na potrzeby tworzenia monitów dotyczących przepływu.
Na przykład kompleksowe potoki LLMOps, które wykonują przepływy klasyfikacji internetowej, zobacz Konfigurowanie kompleksowej metodyki GenAIOps z monitami Flow i GitHub oraz projektem demonstracyjnym klasyfikacji internetowej usługi GitHub.
Przebiegi przepływu wyzwalacza w potokach ciągłej integracji
Po pomyślnym opracowaniu i przetestowaniu przepływu i zaewidencjonowaniu go jako wersji początkowej możesz przystąpić do dostrajania i testowania iteracji. Na tym etapie można wyzwalać przebiegi przepływu, w tym przebiegi testowania wsadowego i oceny, przy użyciu interfejsu wiersza polecenia przepływu monitu w celu zautomatyzowania kroków w potoku ciągłej integracji.
W całym cyklu życia iteracji przepływu można zautomatyzować następujące operacje za pomocą interfejsu wiersza polecenia:
- Uruchamianie przepływu monitu po żądaniu ściągnięcia
- Uruchamianie oceny przepływu monitów w celu zapewnienia wysokiej jakości wyników
- Rejestrowanie modeli przepływu monitów
- Wdrażanie modeli przepływu monitów
Używanie interfejsu użytkownika programu Studio do ciągłego opracowywania
W dowolnym momencie tworzenia przepływu możesz wrócić do interfejsu użytkownika usługi Azure Machine Learning Studio i użyć zasobów i środowisk w chmurze, aby wprowadzić zmiany w przepływie.
Aby kontynuować opracowywanie i pracę z najbardziej aktualnymi wersjami plików przepływu, możesz uzyskać dostęp do terminalu na stronie Notes i ściągnąć najnowsze pliki przepływu z repozytorium. Możesz też bezpośrednio zaimportować folder przepływu lokalnego jako nowy przepływ roboczy, aby bezproblemowo przejść między programowaniem lokalnym i chmurowym.

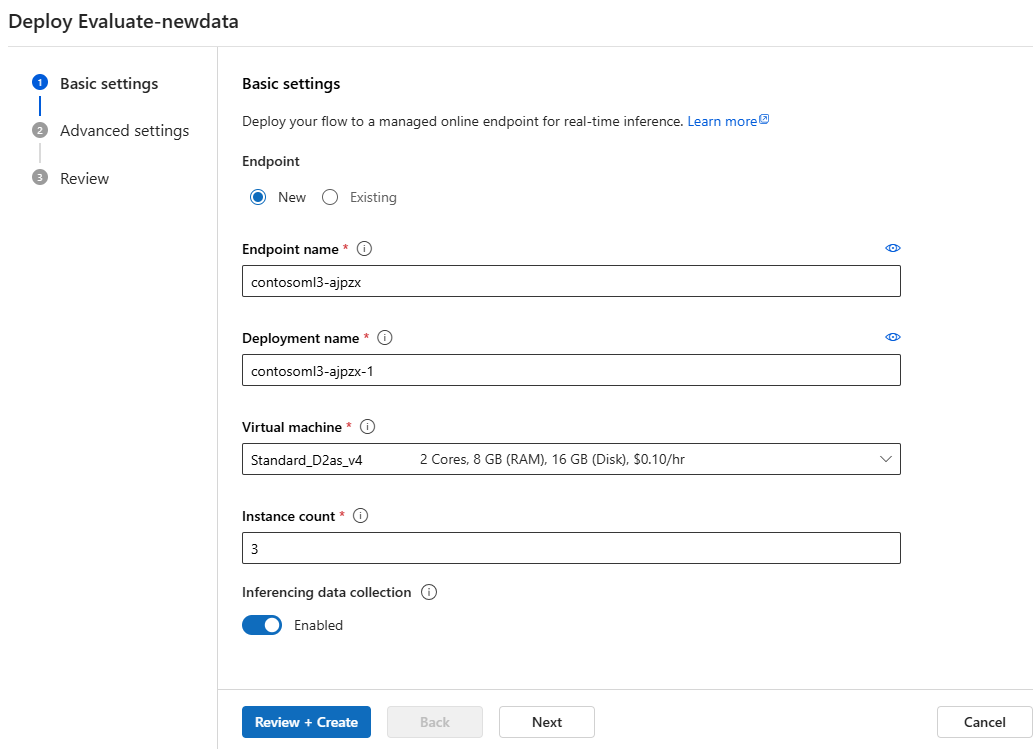
Wdrażanie przepływu jako punktu końcowego online
Ostatnim krokiem przechodzenia do środowiska produkcyjnego jest wdrożenie przepływu jako punktu końcowego online w usłudze Azure Machine Learning. Ten proces umożliwia zintegrowanie przepływu z aplikacją i udostępnienie go do użycia. Aby uzyskać więcej informacji na temat wdrażania przepływu, zobacz Wdrażanie przepływów w zarządzanym punkcie końcowym online usługi Azure Machine Learning w celu wnioskowania w czasie rzeczywistym.
Współpraca nad programowaniem przepływu
Współpraca między członkami zespołu może być niezbędna podczas tworzenia aplikacji opartej na usłudze LLM z przepływem monitów. Członkowie zespołu mogą tworzyć i testować ten sam przepływ, pracować nad różnymi aspektami przepływu lub jednocześnie wprowadzać iteracyjne zmiany i ulepszenia. Ta współpraca wymaga wydajnego i usprawnionego podejścia do udostępniania kodu, śledzenia modyfikacji, zarządzania wersjami i integrowania zmian w końcowym projekcie.
Zestaw SDK przepływu monitów/interfejs wiersza polecenia i rozszerzenie przepływu monitu programu VS Code ułatwiają współpracę w zakresie tworzenia przepływów opartych na kodzie w repozytorium kodu źródłowego. Możesz użyć opartego na chmurze systemu kontroli źródła, takiego jak GitHub lub Azure Repos, do śledzenia zmian, zarządzania wersjami i integrowania tych modyfikacji w końcowym projekcie.
Postępuj zgodnie z najlepszymi rozwiązaniami dotyczącymi tworzenia aplikacji do współpracy
Skonfiguruj scentralizowane repozytorium kodu.
Pierwszym krokiem procesu współpracy jest skonfigurowanie repozytorium kodu jako podstawy kodu projektu, w tym kodu przepływu monitu. To scentralizowane repozytorium umożliwia wydajną organizację, śledzenie zmian i współpracę między członkami zespołu.
Utwórz i przetestuj przepływ lokalnie w programie VS Code za pomocą rozszerzenia Monituj przepływ.
Po skonfigurowaniu repozytorium członkowie zespołu mogą używać programu VS Code z rozszerzeniem Monituj przepływ na potrzeby lokalnego tworzenia i testowania pojedynczego wejściowego przepływu. Ustandaryzowane zintegrowane środowisko projektowe promuje współpracę między wieloma członkami pracującymi nad różnymi aspektami przepływu.
Użyj interfejsu
pfazurewiersza polecenia lub zestawu SDK, aby przesłać uruchomienia wsadowe i uruchomienia ewaluacyjne z przepływów lokalnych do chmury.Po lokalnym tworzeniu i testowaniu członkowie zespołu mogą przesyłać i oceniać przebiegi wsadowe i ewaluacyjne do chmury przy użyciu interfejsu wiersza polecenia przepływu monitu. Ten proces umożliwia użycie zasobów obliczeniowych w chmurze, trwały magazyn wyników, tworzenie punktu końcowego dla wdrożeń i efektywne zarządzanie w interfejsie użytkownika programu Studio.
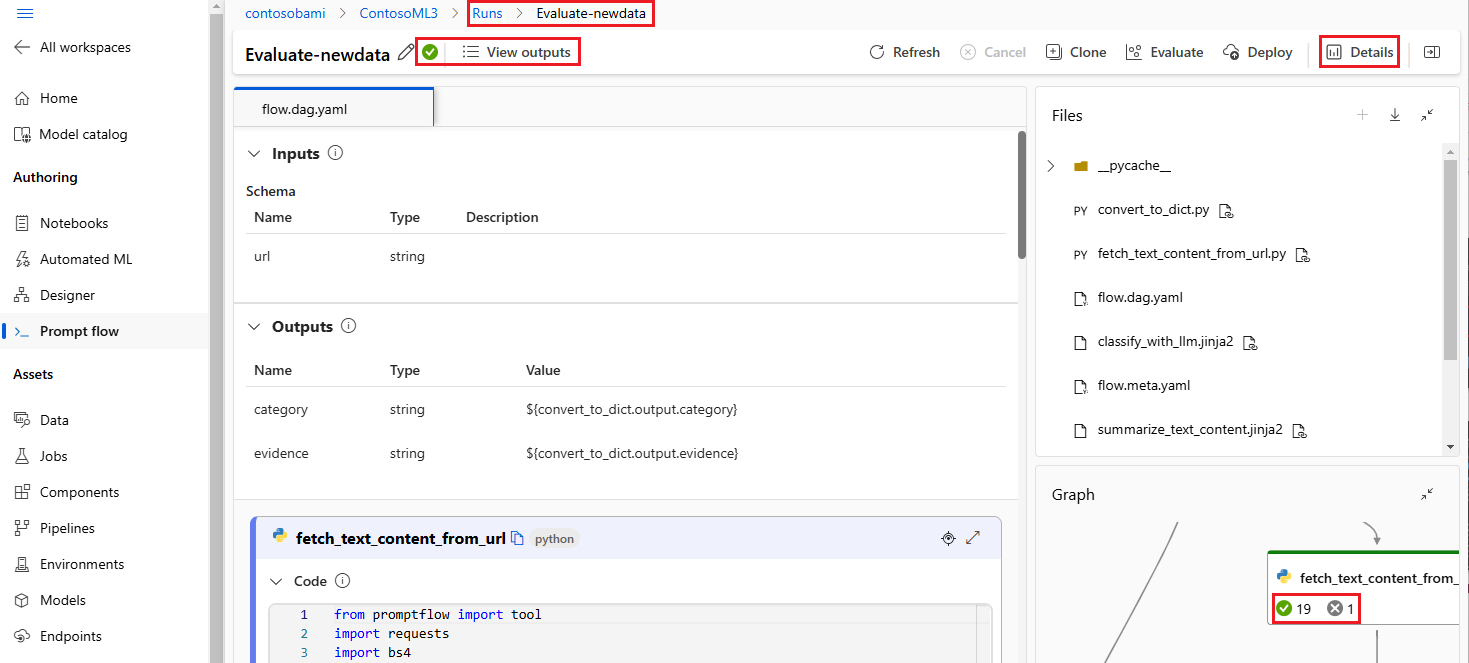
Wyświetlanie wyników uruchamiania i zarządzanie nimi w interfejsie użytkownika obszaru roboczego usługi Azure Machine Learning Studio.
Po przesłaniu przebiegów do chmury członkowie zespołu mogą uzyskać dostęp do interfejsu użytkownika studio, aby efektywnie wyświetlać wyniki i zarządzać eksperymentami. Obszar roboczy w chmurze zapewnia scentralizowaną lokalizację do zbierania historii uruchamiania, dzienników, migawek, kompleksowych wyników oraz danych wejściowych i wyjściowych na poziomie wystąpienia oraz zarządzania nimi.
Użyj listy Przebiegi, która rejestruje całą historię uruchamiania, aby łatwo porównać wyniki różnych przebiegów, ułatwiając analizę jakości i niezbędne korekty.
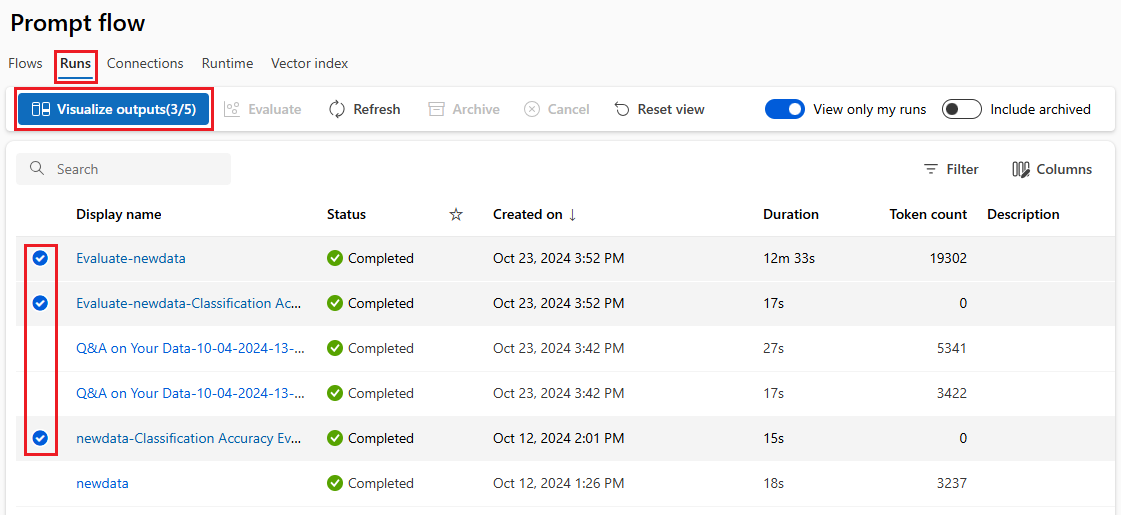
Kontynuuj korzystanie z lokalnego programowania iteracyjnego.
Po przeanalizowaniu wyników eksperymentów członkowie zespołu mogą wrócić do lokalnego środowiska i repozytorium kodu, aby uzyskać więcej możliwości programowania i dostrajania, a następnie iteracyjnie przesyłać kolejne uruchomienia do chmury. Takie podejście iteracyjne zapewnia spójne ulepszenia, dopóki zespół nie będzie zadowolony z jakości środowiska produkcyjnego.
Użyj wdrożenia jednoetapowego do środowiska produkcyjnego w studio.
Gdy zespół jest w pełni pewny jakości przepływu, może bezproblemowo wdrożyć go jako punkt końcowy online w niezawodnym środowisku chmury. Wdrożenie jako punkt końcowy online może być oparte na migawki przebiegu, co umożliwia stabilną i bezpieczną obsługę, dalszą alokację zasobów i śledzenie użycia oraz monitorowanie dzienników w chmurze.
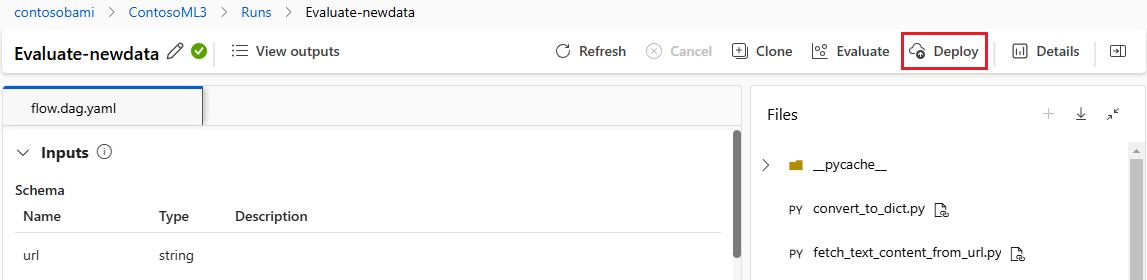
Kreator wdrażania usługi Azure Machine Learning Studio ułatwia skonfigurowanie wdrożenia.