Programowanie interakcyjne języka R
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
W tym artykule pokazano, jak używać języka R w usłudze Azure Machine Learning Studio w wystąpieniu obliczeniowym, które uruchamia jądro języka R w notesie Jupyter.
Działa również popularne środowisko IDE programu RStudio. Program RStudio lub Posit Workbench można zainstalować w kontenerze niestandardowym w wystąpieniu obliczeniowym. Jednak ma to ograniczenia dotyczące odczytywania i zapisywania w obszarze roboczym usługi Azure Machine Learning.
Ważne
Kod przedstawiony w tym artykule działa w wystąpieniu obliczeniowym usługi Azure Machine Learning. Wystąpienie obliczeniowe ma plik środowiska i konfiguracji niezbędny do pomyślnego uruchomienia kodu.
Wymagania wstępne
- Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto. Wypróbuj bezpłatną lub płatną wersję usługi Azure Machine Learning już dziś
- Obszar roboczy usługi Azure Machine Learning i wystąpienie obliczeniowe
- Podstawowa wiedza na temat korzystania z notesów Jupyter w usłudze Azure Machine Learning Studio. Aby uzyskać więcej informacji, odwiedź stronę Tworzenie modelu na zasobie stacji roboczej w chmurze.
Uruchamianie języka R w notesie w programie Studio
W wystąpieniu obliczeniowym użyjesz notesu w obszarze roboczym usługi Azure Machine Learning.
Zaloguj się do usługi Azure Machine Learning Studio
Otwórz obszar roboczy, jeśli nie został jeszcze otwarty
W obszarze nawigacji po lewej stronie wybierz pozycję Notesy
Tworzenie nowego notesu o nazwie RunR.ipynb
Napiwek
Jeśli nie masz pewności, jak tworzyć notesy i pracować z notesami w programie Studio, zapoznaj się z tematem Uruchamianie notesów Jupyter w obszarze roboczym
Wybierz notes.
Na pasku narzędzi notesu upewnij się, że wystąpienie obliczeniowe jest uruchomione. Jeśli nie, uruchom go teraz.
Na pasku narzędzi notesu przełącz jądro na język R.


Notes jest teraz gotowy do uruchamiania poleceń języka R.
Uzyskiwanie dostępu do danych
Możesz przekazać pliki do zasobu magazynu plików obszaru roboczego, a następnie uzyskać dostęp do tych plików w języku R. Jednak w przypadku plików przechowywanych w zasobach danych platformy Azure lub danych z magazynów danych należy zainstalować niektóre pakiety.
W tej sekcji opisano sposób używania języka Python i reticulate pakietu do ładowania zasobów danych i magazynów danych do języka R z sesji interaktywnej. Pakiet języka Python i reticulate pakiet języka R służą azureml-fsspec do odczytywania danych tabelarycznych jako ramek danych biblioteki Pandas. Ta sekcja zawiera również przykład odczytywania zasobów danych i magazynów danych w języku R data.frame.
Aby zainstalować te pakiety:
Utwórz nowy plik w wystąpieniu obliczeniowym o nazwie setup.sh.
Skopiuj ten kod do pliku:
#!/bin/bash set -e # Installs azureml-fsspec in default conda environment # Does not need to run as sudo eval "$(conda shell.bash hook)" conda activate azureml_py310_sdkv2 pip install azureml-fsspec conda deactivate # Checks that version 1.26 of reticulate is installed (needs to be done as sudo) sudo -u azureuser -i <<'EOF' R -e "if (packageVersion('reticulate') >= 1.26) message('Version OK') else install.packages('reticulate')" EOFWybierz pozycję Zapisz i uruchom skrypt w terminalu , aby uruchomić skrypt
Skrypt instalacji obsługuje następujące kroki:
pipprogram jest instalowanyazureml-fsspecw domyślnym środowisku conda dla wystąpienia obliczeniowego- Instaluje pakiet języka R
reticulatew razie potrzeby (wersja musi być 1.26 lub nowsza)
Odczytywanie danych tabelarycznych z zarejestrowanych zasobów danych lub magazynów danych
W przypadku danych przechowywanych w zasobie danych utworzonym w usłudze Azure Machine Learning wykonaj następujące kroki, aby odczytać ten plik tabelaryczny w ramce danych Biblioteki Pandas lub R data.frame:
Uwaga
Odczytywanie pliku z reticulate tylko danymi tabelarycznymi.
Upewnij się, że masz poprawną wersję programu
reticulate. W przypadku wersji mniejszej niż 1.26 spróbuj użyć nowszego wystąpienia obliczeniowego.packageVersion("reticulate")Ładowanie
reticulatei ustawianie środowiska conda, w którymazureml-fsspeczainstalowanolibrary(reticulate) use_condaenv("azureml_py310_sdkv2") print("Environment is set")Znajdź ścieżkę identyfikatora URI do pliku danych.
Najpierw uzyskaj dojście do obszaru roboczego
py_code <- "from azure.identity import DefaultAzureCredential from azure.ai.ml import MLClient credential = DefaultAzureCredential() ml_client = MLClient.from_config(credential=credential)" py_run_string(py_code) print("ml_client is configured")Użyj tego kodu, aby pobrać zasób. Pamiętaj, aby zastąpić
<MY_NAME>element i<MY_VERSION>nazwą i numerem zasobu danych.Napiwek
W programie Studio wybierz pozycję Dane w obszarze nawigacji po lewej stronie, aby znaleźć nazwę i numer wersji zasobu danych.
# Replace <MY_NAME> and <MY_VERSION> with your values py_code <- "my_name = '<MY_NAME>' my_version = '<MY_VERSION>' data_asset = ml_client.data.get(name=my_name, version=my_version) data_uri = data_asset.path"Aby pobrać identyfikator URI, uruchom kod.
py_run_string(py_code) print(paste("URI path is", py$data_uri))
Użyj funkcji odczytu biblioteki Pandas, aby odczytać plik lub pliki w środowisku języka R.
pd <- import("pandas") cc <- pd$read_csv(py$data_uri) head(cc)
Możesz również użyć identyfikatora URI magazynu danych, aby uzyskać dostęp do różnych plików w zarejestrowanym magazynie danych i odczytać te zasoby w języku R data.frame.
W tym formacie utwórz identyfikator URI magazynu danych przy użyciu własnych wartości:
subscription <- '<subscription_id>' resource_group <- '<resource_group>' workspace <- '<workspace>' datastore_name <- '<datastore>' path_on_datastore <- '<path>' uri <- paste0("azureml://subscriptions/", subscription, "/resourcegroups/", resource_group, "/workspaces/", workspace, "/datastores/", datastore_name, "/paths/", path_on_datastore)Napiwek
Zamiast pamiętać format identyfikatora URI magazynu danych, możesz skopiować i wkleić identyfikator URI magazynu danych z poziomu interfejsu użytkownika programu Studio, jeśli znasz magazyn danych, w którym znajduje się plik:
- Przejdź do pliku/folderu, który chcesz odczytać do języka R
- Wybierz wielokropek (...) obok niego.
- Wybierz z menu Kopiuj identyfikator URI.
- Wybierz identyfikator URI magazynu danych, aby skopiować go do notesu/skryptu.
Należy pamiętać, że musisz utworzyć zmienną dla
<path>elementu w kodzie.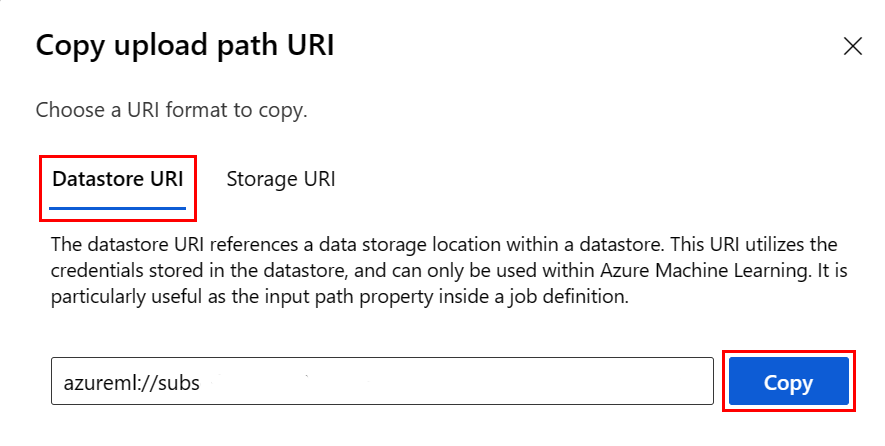
Utwórz obiekt magazynu plików przy użyciu wcześniej wymienionego identyfikatora URI:
fs <- azureml.fsspec$AzureMachineLearningFileSystem(uri, sep = "")
- Przeczytaj w języku R
data.frame:
df <- with(fs$open("<path>)", "r") %as% f, {
x <- as.character(f$read(), encoding = "utf-8")
read.csv(textConnection(x), header = TRUE, sep = ",", stringsAsFactors = FALSE)
})
print(df)
Instalowanie pakietów R
Wystąpienie obliczeniowe ma wiele wstępnie zainstalowanych pakietów języka R.
Aby zainstalować inne pakiety, należy jawnie stwierdzić lokalizację i zależności.
Napiwek
Podczas tworzenia lub używania innego wystąpienia obliczeniowego należy ponownie zainstalować wszystkie zainstalowane pakiety.
Aby na przykład zainstalować tsibble pakiet:
install.packages("tsibble",
dependencies = TRUE,
lib = "/home/azureuser")
Uwaga
W przypadku instalowania pakietów w ramach sesji języka R, która jest uruchamiana w notesie Jupyter, dependencies = TRUE jest wymagana. W przeciwnym razie pakiety zależne nie zostaną automatycznie zainstalowane. Lokalizacja lib jest również wymagana do zainstalowania w prawidłowej lokalizacji wystąpienia obliczeniowego.
Ładowanie bibliotek języka R
Dodaj /home/azureuser do ścieżki biblioteki języka R.
.libPaths("/home/azureuser")
Napiwek
Aby uzyskać dostęp do bibliotek zainstalowanych przez użytkownika, należy zaktualizować .libPaths skrypt w każdym interakcyjnym języku R. Dodaj ten kod na początku każdego interaktywnego skryptu języka R lub notesu.
Po zaktualizowaniu biblioteki libPath załaduj biblioteki tak jak zwykle.
library('tsibble')
Używanie języka R w notesie
Poza opisanymi wcześniej problemami należy użyć języka R, tak jak w każdym innym środowisku, w tym lokalnej stacji roboczej. W notesie lub skryscie możesz odczytywać i zapisywać w ścieżce, w której jest przechowywany notes/skrypt.
Uwaga
- Z interakcyjnej sesji języka R można zapisywać tylko w systemie plików obszaru roboczego.
- Z interakcyjnej sesji języka R nie można wchodzić w interakcje z platformą MLflow (na przykład z modelem dziennika lub rejestrem zapytań).