Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Zestaw PYTHON SDK azure-ai-ml w wersji 2 (bieżąca)
Zestaw PYTHON SDK azure-ai-ml w wersji 2 (bieżąca)
W tym samouczku przedstawiono niektóre z najczęściej używanych funkcji usługi Azure Machine Learning. Tworzysz, rejestrujesz i wdrażasz model. Ten samouczek ułatwia zapoznanie się z podstawowymi pojęciami dotyczącymi usługi Azure Machine Learning i ich najczęstszym użyciem.
W tym przewodniku szybkiego startu wytrenujesz, zarejestrujesz i wdrożysz model uczenia maszynowego przy użyciu usługi Azure Machine Learning — wszystko w notatniku Pythona. Na koniec będziesz mieć działający punkt końcowy, który można wywołać dla przewidywań.
Uczysz się, jak:
- Uruchamianie zadania szkoleniowego na temat skalowalnych obliczeń w chmurze
- Zarejestruj wytrenowany model
- Wdrażanie modelu jako punktu końcowego online
- Testowanie punktu końcowego przy użyciu przykładowych danych
Utworzysz skrypt szkoleniowy do obsługi przygotowywania, trenowania i rejestrowania modelu. Po wytrenowaniu modelu należy wdrożyć go jako punkt końcowy, a następnie wywołać punkt końcowy w celu wnioskowania.
Czynności, które należy wykonać, to:
- Konfigurowanie dojścia do obszaru roboczego usługi Azure Machine Learning
- Tworzenie skryptu szkoleniowego
- Tworzenie skalowalnego zasobu obliczeniowego, klastra obliczeniowego
- Utwórz i uruchom zadanie polecenia, które uruchamia skrypt trenowania w klastrze obliczeniowym, skonfigurowane przy użyciu odpowiedniego środowiska zadań
- Wyświetlanie danych wyjściowych skryptu szkoleniowego
- Wdrażanie nowo wytrenowanego modelu jako punktu końcowego
- Wywoływanie punktu końcowego usługi Azure Machine Learning na potrzeby wnioskowania
Wymagania wstępne
-
Aby korzystać z usługi Azure Machine Learning, potrzebny jest obszar roboczy. Jeśli go nie masz, ukończ tworzenie zasobów, aby rozpocząć tworzenie obszaru roboczego i dowiedz się więcej na temat korzystania z niego.
Ważne
Jeśli obszar roboczy usługi Azure Machine Learning jest skonfigurowany z zarządzaną siecią wirtualną, może być konieczne dodanie reguł ruchu wychodzącego w celu umożliwienia dostępu do publicznych repozytoriów pakietów języka Python. Aby uzyskać więcej informacji, zobacz Scenariusz: Uzyskiwanie dostępu do publicznych pakietów uczenia maszynowego.
-
Zaloguj się do programu Studio i wybierz swój obszar roboczy, jeśli jeszcze nie jest otwarty.
-
Otwórz lub utwórz notes w obszarze roboczym:
- Jeśli chcesz skopiować i wkleić kod do komórek, utwórz nowy notes.
- Możesz też otworzyć plik tutorials/get-started-notebooks/quickstart.ipynb z sekcji Przykłady w programie Studio. Następnie wybierz pozycję Klonuj, aby dodać notes do plików. Aby znaleźć przykładowe notesy, zobacz Learn from sample notebooks (Informacje na podstawie przykładowych notesów).
Ustawianie jądra i otwieranie go w programie Visual Studio Code (VS Code)
Na górnym pasku powyżej otwartego notesu utwórz wystąpienie obliczeniowe, jeśli jeszcze go nie masz.

Jeśli wystąpienie obliczeniowe zostanie zatrzymane, wybierz pozycję Uruchom obliczenia i zaczekaj na jego uruchomienie.

Poczekaj na uruchomienie wystąpienia obliczeniowego. Następnie upewnij się, że jądro znajdujące się w prawym górnym rogu ma wartość
Python 3.10 - SDK v2. Jeśli nie, użyj listy rozwijanej, aby wybrać to jądro.
Jeśli to jądro nie jest widoczne, sprawdź, czy wystąpienie obliczeniowe jest uruchomione. Jeśli tak jest, wybierz przycisk Odśwież w prawym górnym rogu notesu.
Jeśli zostanie wyświetlony baner z informacją o konieczności uwierzytelnienia, wybierz pozycję Uwierzytelnij.
Możesz uruchomić notes tutaj lub otworzyć go w programie VS Code w celu uzyskania pełnego zintegrowanego środowiska projektowego (IDE) z możliwościami zasobów usługi Azure Machine Learning. Wybierz pozycję Otwórz w programie VS Code, a następnie wybierz opcję internetową lub klasyczną. Po uruchomieniu w ten sposób program VS Code jest dołączony do wystąpienia obliczeniowego, jądra i systemu plików obszaru roboczego.





Ważne
W pozostałej części tego samouczka znajdują się komórki notesu samouczka. Skopiuj je i wklej do nowego notesu lub przejdź do notesu teraz, jeśli go sklonujesz.
Tworzenie dojścia do obszaru roboczego
Przed rozpoczęciem pracy z kodem potrzebny jest sposób odwołowania się do obszaru roboczego. Obszar roboczy jest zasobem najwyższego poziomu dla usługi Azure Machine Learning, który udostępnia scentralizowane miejsce do pracy z wszystkimi tworzonymi podczas korzystania usługi Azure Machine Learning artefaktami.
Utwórz ml_client jako dojście do obszaru roboczego — ten klient zarządza wszystkimi zasobami i zadaniami.
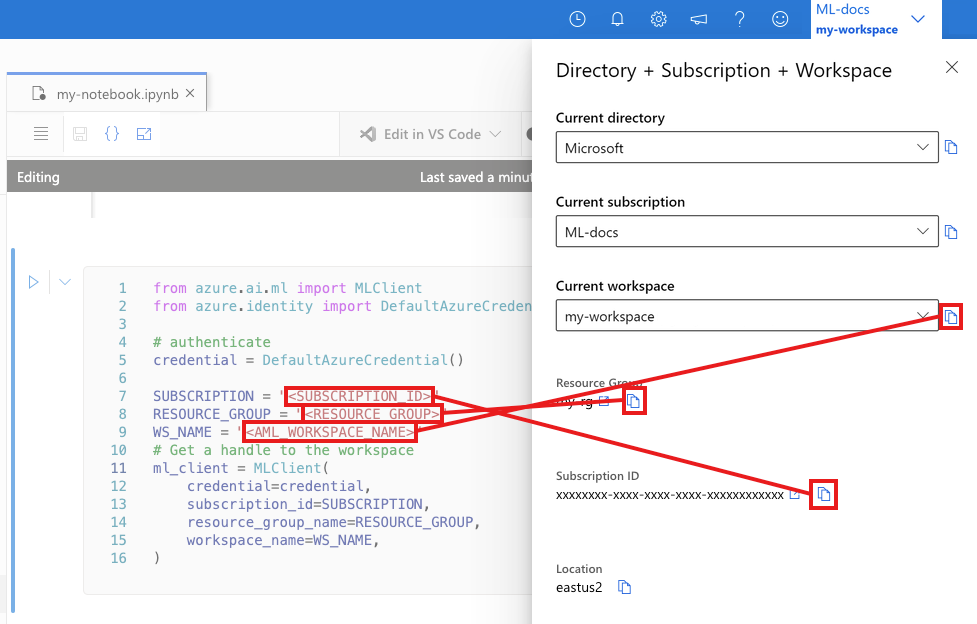
W następnej komórce wprowadź identyfikator subskrypcji, nazwę grupy zasobów i nazwę obszaru roboczego. Aby znaleźć następujące wartości:
- Na pasku narzędzi usługi Azure Machine Learning Studio w prawym górnym rogu wybierz nazwę obszaru roboczego.
- Skopiuj wartość obszaru roboczego, grupy zasobów i identyfikatora subskrypcji do kodu.
- Skopiuj jedną wartość, zamknij obszar i wklej ją. Następnie wróć do następnej wartości.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# authenticate
try:
credential = DefaultAzureCredential()
credential.get_token("https://management.azure.com/.default")
except Exception:
credential = InteractiveBrowserCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Uwaga
Tworzenie klasy MLClient nie łączy się z obszarem roboczym. Inicjowanie klienta jest leniwe. Czeka, aż po raz pierwszy musi wykonać połączenie. Ta akcja odbywa się w następnej komórce kodu.
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
Tworzenie skryptu szkoleniowego
Utwórz skrypt trenowania, który jest plikiem main.py Python.
Najpierw utwórz folder źródłowy skryptu:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Ten skrypt wstępnie przetwarza dane i dzieli je na zbiory danych testowych i treningowe. Trenuje model oparty na drzewie przy użyciu tych danych i zwraca model wyjściowy.
Podczas uruchamiania potoku użyj MLFlow, aby zarejestrować parametry i metryki.
Poniższa komórka wykorzystuje funkcje magiczne IPython do zapisania skryptu szkoleniowego w właśnie utworzonym katalogu.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
# pin numpy
conda_env = {
'name': 'mlflow-env',
'channels': ['conda-forge'],
'dependencies': [
'python=3.10.15',
'pip<=21.3.1',
{
'pip': [
'mlflow==2.17.0',
'cloudpickle==2.2.1',
'pandas==1.5.3',
'psutil==5.8.0',
'scikit-learn==1.5.2',
'numpy==1.26.4',
]
}
],
}
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
conda_env=conda_env,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Po wytrenowanym modelu skrypt zapisuje i rejestruje plik modelu w obszarze roboczym. Zarejestrowany model można używać w punktach końcowych wnioskowania.
Może być konieczne wybranie pozycji Odśwież, aby wyświetlić nowy folder i skrypt w plikach.
Konfigurowanie polecenia
Masz teraz skrypt, który może wykonywać żądane zadania, oraz klaster obliczeniowy do uruchamiania skryptu. Użyj polecenia ogólnego przeznaczenia, które umożliwia uruchamianie akcji wiersza polecenia. Ta akcja wiersza polecenia może bezpośrednio wywoływać polecenia systemowe lub uruchamiać skrypt.
Utwórz zmienne wejściowe, aby określić dane wejściowe, współczynnik podziału, szybkość nauki i nazwę zarejestrowanego modelu. Skrypt polecenia:
- Używa środowiska definiującego biblioteki oprogramowania i środowiska uruchomieniowego potrzebne do skryptu szkoleniowego. Usługa Azure Machine Learning udostępnia wiele wyselekcjonowanych lub gotowych środowisk, które są przydatne w przypadku typowych scenariuszy trenowania i wnioskowania. W tym miejscu użyjesz jednego z tych środowisk. W artykule Samouczek: trenowanie modelu w usłudze Azure Machine Learning zawiera informacje na temat tworzenia środowiska niestandardowego.
- Konfiguruje samą akcję wiersza polecenia —
python main.pyw tym przypadku. Dane wejściowe i wyjściowe są dostępne w poleceniu za pomocą notacji${{ ... }}. - Uzyskuje dostęp do danych z pliku w Internecie.
- Ponieważ nie określono zasobu obliczeniowego, skrypt jest uruchamiany w klastrze obliczeniowym bezserwerowym , który jest tworzony automatycznie.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="azureml://registries/azureml/environments/sklearn-1.5/labels/latest",
display_name="credit_default_prediction",
)
Przesyłanie zadania
Prześlij zadanie do uruchomienia w usłudze Azure Machine Learning. Tym razem użyj polecenia create_or_update w pliku ml_client.
ml_client.create_or_update(job)
Wyświetlanie danych wyjściowych zadania i oczekiwanie na ukończenie zadania
Wyświetl zadanie w usłudze Azure Machine Learning Studio, wybierając link w danych wyjściowych poprzedniej komórki.
Dane wyjściowe tego zadania wyglądają następująco w usłudze Azure Machine Learning Studio. Przeglądaj zakładki, aby uzyskać różne szczegóły, takie jak metryki, wyniki i inne. Po zakończeniu zadanie zarejestruje model w obszarze roboczym jako wynik trenowania.
Ważne
Przed kontynuowaniem poczekaj, aż stan zadania będzie wyświetlany jako Ukończono — zazwyczaj 2–3 minuty. Jeśli klaster obliczeniowy został skalowany do zera, należy oczekiwać do 10 minut, aż będzie gotowy do użycia.
Podczas oczekiwania zapoznaj się ze szczegółami zadania w programie Studio:
- Karta Metryki: Wyświetlanie metryk trenowania zarejestrowanych przez platformę MLflow
- Karta Dane wyjściowe i dzienniki: Sprawdź dzienniki trenowania
- Karta Modele: zobacz zarejestrowany model (po zakończeniu)
Wdrażanie modelu jako punktu końcowego online
Wdróż model uczenia maszynowego jako usługę internetową w chmurze platformy Azure przy użyciu elementu online endpoint.
Aby wdrożyć usługę uczenia maszynowego, użyj zarejestrowanego modelu.
Tworzenie nowego punktu końcowego online
Teraz, gdy zarejestrowałeś model, utwórz swój punkt końcowy online. Nazwa punktu końcowego musi być unikatowa w całym regionie świadczenia usługi Azure. Na potrzeby tego samouczka utwórz unikatową nazwę przy użyciu polecenia UUID.
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Utwórz punkt końcowy.
# Expect the endpoint creation to take a few minutes
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
"model_type": "sklearn.GradientBoostingClassifier",
},
)
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
print(f"Endpoint {endpoint.name} provisioning state: {endpoint.provisioning_state}")
Uwaga
Poczekaj kilka minut na utworzenie punktu końcowego.
Po utworzeniu punktu końcowego pobierz go, jak pokazano w poniższym kodzie:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Wdrażanie modelu w punkcie końcowym
Po utworzeniu punktu końcowego wdróż model przy użyciu skryptu wejścia. Każdy punkt końcowy może mieć wiele wdrożeń. Możesz określić reguły kierowania ruchu do tych wdrożeń. W tym przykładzie utworzysz pojedyncze wdrożenie obsługujące 100% ruchu przychodzącego. Wybierz nazwę koloru wdrożenia, na przykład niebieską, zieloną lub czerwoną. Wybór jest dowolny.
Aby znaleźć najnowszą wersję zarejestrowanego modelu, sprawdź stronę Modele w usłudze Azure Machine Learning Studio. Alternatywnie użyj następującego kodu, aby pobrać najnowszy numer wersji.
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(f'Latest model is version "{latest_model_version}" ')
Wdróż najnowszą wersję modelu.
# picking the model to deploy. Here we use the latest version of our registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# Expect this deployment to take approximately 6 to 8 minutes.
# create an online deployment.
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()
Uwaga
Spodziewaj się, że wdrożenie potrwa około 6 do 8 minut.
Po zakończeniu wdrażania możesz go przetestować.
Testowanie przy użyciu przykładowego zapytania
Po wdrożeniu modelu w punkcie końcowym uruchom wnioskowanie przy użyciu modelu.
Utwórz przykładowy plik żądania, który jest zgodny z oczekiwanym projektem w metodzie run w skrypcie wyniku.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
deployment_name="blue",
)
Czyszczenie zasobów
Jeśli nie potrzebujesz punktu końcowego, usuń go, aby zatrzymać korzystanie z zasobu. Upewnij się, że żadne inne wdrożenia nie korzystają z punktu końcowego, zanim go usuniesz.
Uwaga
Spodziewaj się, że pełne usunięcie potrwa około 20 minut.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)
Zatrzymywanie wystąpienia obliczeniowego
Jeśli nie potrzebujesz go teraz, zatrzymaj wystąpienie obliczeniowe:
- W Studio w okienku po lewej stronie wybierz pozycję Komputer.
- Na pierwszych kartach wybierz pozycję Wystąpienia obliczeniowe.
- Wybierz wystąpienie obliczeniowe na liście.
- Na górnym pasku narzędzi wybierz pozycję Zatrzymaj.
Usuwanie wszystkich zasobów
Ważne
Utworzone zasoby mogą być używane jako wymagania wstępne w innych samouczkach usługi Azure Machine Learning i artykułach z instrukcjami.
Jeśli nie planujesz korzystać z żadnych utworzonych zasobów, usuń je, aby nie ponosić żadnych opłat:
W witrynie Azure Portal w polu wyszukiwania wprowadź ciąg Grupy zasobów i wybierz je z wyników.
Z listy wybierz utworzoną grupę zasobów.
Na stronie Przegląd wybierz pozycję Usuń grupę zasobów.
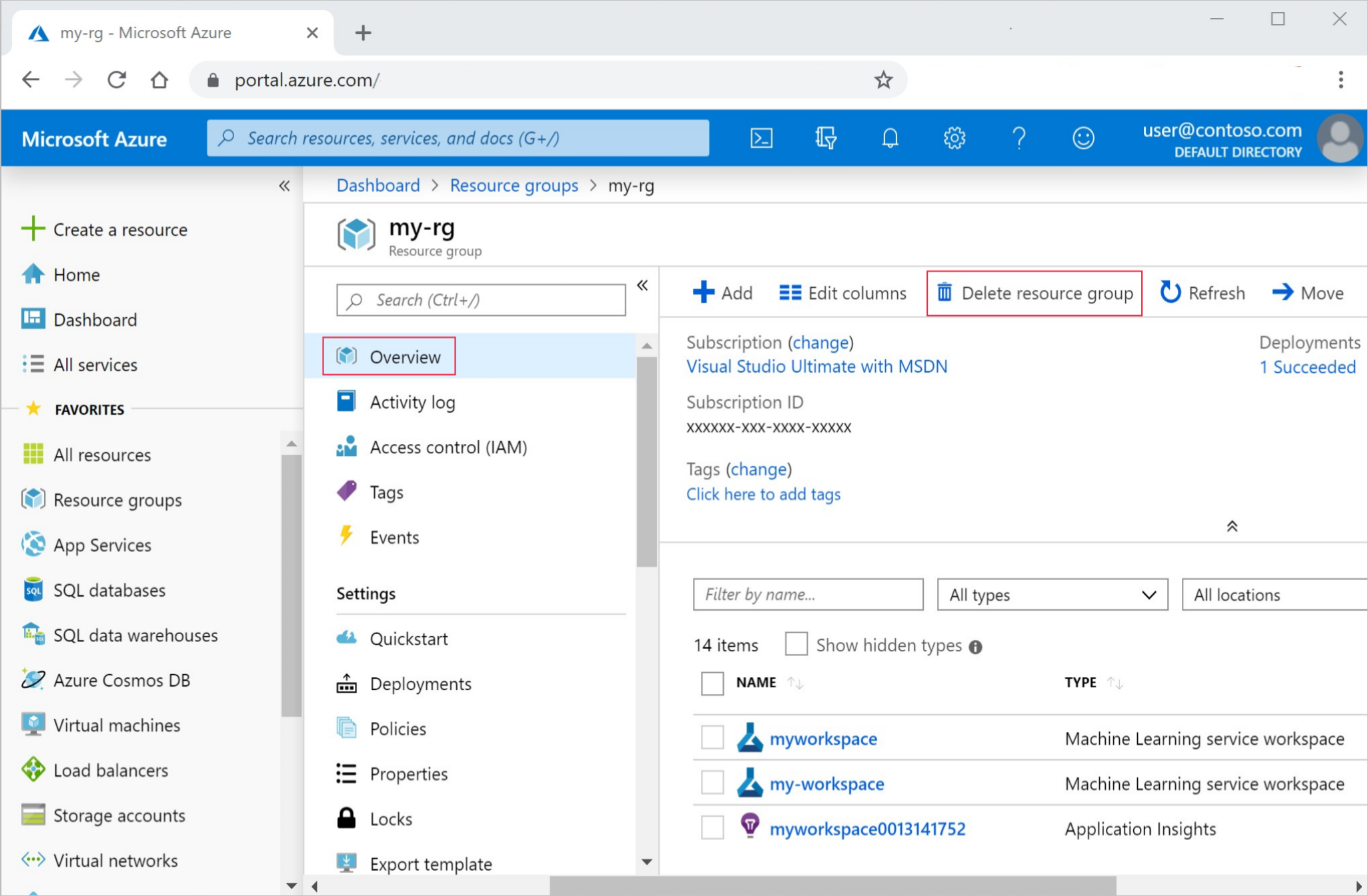
Wpisz nazwę grupy zasobów. Następnie wybierz Usuń.
Następne kroki
Poznaj więcej sposobów tworzenia za pomocą usługi Azure Machine Learning:
| Samouczek | opis |
|---|---|
| Przekazywanie, uzyskiwanie dostępu i eksplorowanie danych | Przechowywanie dużych danych w chmurze i uzyskiwanie do niej dostępu z notesów |
| Tworzenie modeli na stacji roboczej w chmurze | Tworzenie prototypów i tworzenie modeli interaktywnie |
| Wdrażanie modelu jako punktu końcowego online | Poznaj zaawansowane konfiguracje wdrażania |
| Tworzenie potoków produkcyjnych | Twórz zautomatyzowane, wielokrotnego użytku przepływy pracy ML |