Samouczek: wdrażanie modelu uczenia maszynowego przy użyciu projektanta
W części jednego z tego samouczka wytrenujesz model regresji liniowej, który przewiduje ceny samochodów. W drugiej części użyjesz projektanta usługi Azure Machine Learning, aby wdrożyć model, aby inni mogli z niego korzystać.
Uwaga
Projektant obsługuje dwa typy składników: klasyczne wstępnie utworzone składniki (wersja 1) i składniki niestandardowe (wersja 2). Te dwa typy składników nie są zgodne.
Klasyczne wstępnie utworzone składniki udostępniają wstępnie utworzone składniki głównie do przetwarzania danych i tradycyjnych zadań uczenia maszynowego, takich jak regresja i klasyfikacja. Ten typ składnika będzie nadal obsługiwany, ale nie zostaną dodane żadne nowe składniki.
Składniki niestandardowe umożliwiają opakowywanie własnego kodu jako składnika. Obsługują udostępnianie składników między obszarami roboczymi i bezproblemowe tworzenie w usłudze Machine Learning Studio, interfejsie wiersza polecenia w wersji 2 i interfejsach SDK w wersji 2.
W przypadku nowych projektów zalecamy używanie składników niestandardowych, które są zgodne z usługą Azure Machine Learning w wersji 2 i będą otrzymywać nowe aktualizacje.
Ten artykuł dotyczy klasycznych wstępnie utworzonych składników i nie jest zgodny z interfejsem wiersza polecenia w wersji 2 i zestawem SDK w wersji 2.
W tym samouczku zostały wykonane następujące czynności:
- Tworzenie potoku wnioskowania w czasie rzeczywistym.
- Utwórz klaster wnioskowania.
- Wdróż punkt końcowy w czasie rzeczywistym.
- Przetestuj punkt końcowy w czasie rzeczywistym.
Wymagania wstępne
Ukończ część jedną z samouczków , aby dowiedzieć się, jak trenować i oceniać model uczenia maszynowego w projektancie.
Ważne
Jeśli nie widzisz elementów graficznych wymienionych w tym dokumencie, takich jak przyciski w studio lub projektancie, być może nie masz odpowiedniego poziomu uprawnień do obszaru roboczego. Skontaktuj się z administratorem subskrypcji platformy Azure, aby sprawdzić, czy udzielono Ci poprawnego poziomu dostępu. Aby uzyskać więcej informacji, zobacz Zarządzanie użytkownikami i rolami.
Tworzenie potoku wnioskowania w czasie rzeczywistym
Aby wdrożyć potok, należy najpierw przekonwertować potok trenowania na potok wnioskowania w czasie rzeczywistym. Ten proces powoduje usunięcie składników trenowania i dodanie danych wejściowych i wyjściowych usługi internetowej w celu obsługi żądań.
Uwaga
Funkcja Tworzenie potoku wnioskowania obsługuje potoki trenowania, które zawierają tylko wbudowane składniki projektanta i które mają składnik, taki jak Train Model (Trenowanie modelu), który generuje wytrenowany model.
Tworzenie potoku wnioskowania w czasie rzeczywistym
Wybierz pozycję Potoki z panelu nawigacji bocznej, a następnie otwórz utworzone zadanie potoku. Na stronie szczegółów nad kanwą potoku wybierz wielokropek ... a następnie wybierz pozycję Utwórz potok>wnioskowania w czasie rzeczywistym potoku wnioskowania w czasie rzeczywistym.
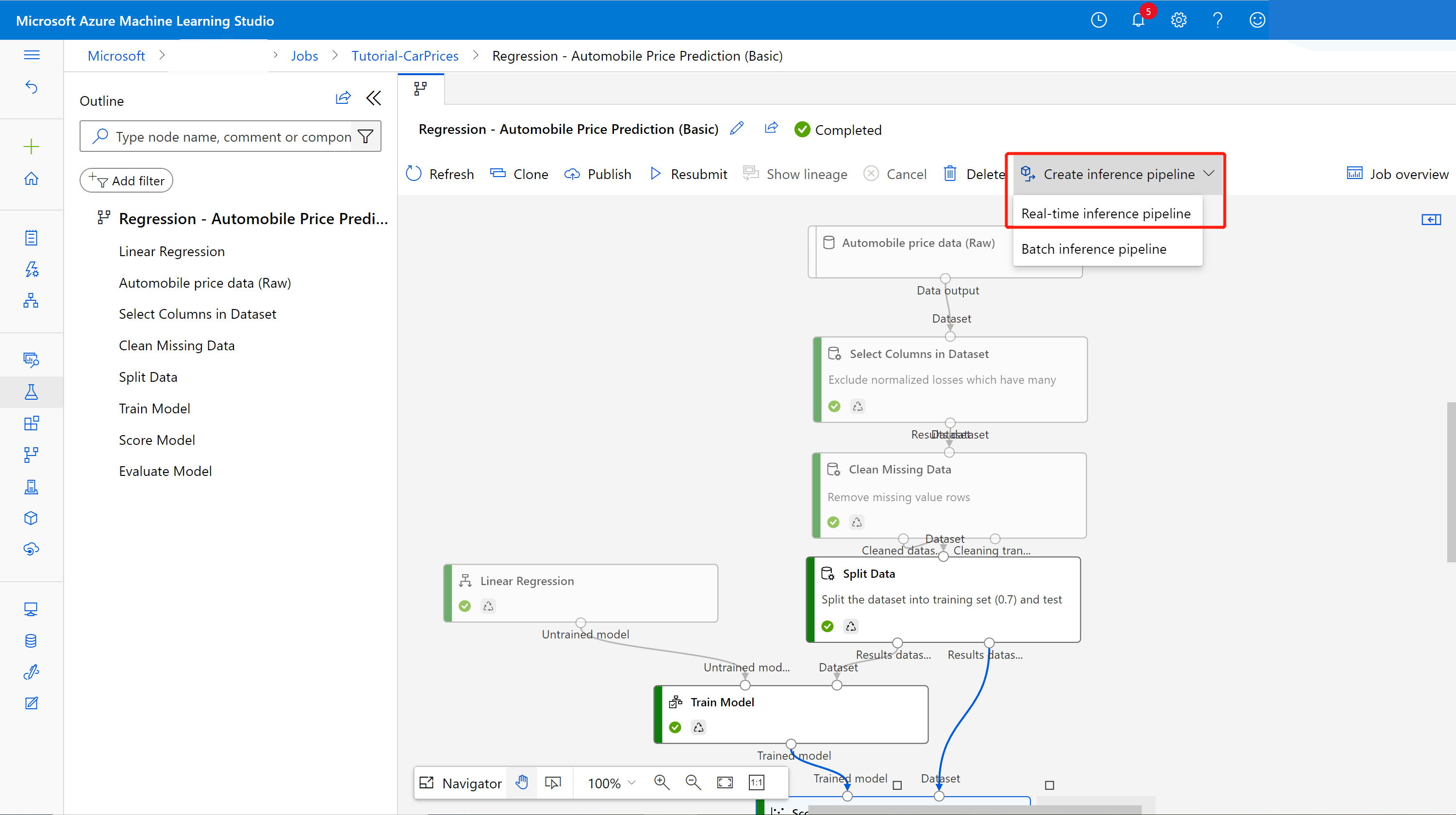
Nowy potok wygląda teraz następująco:
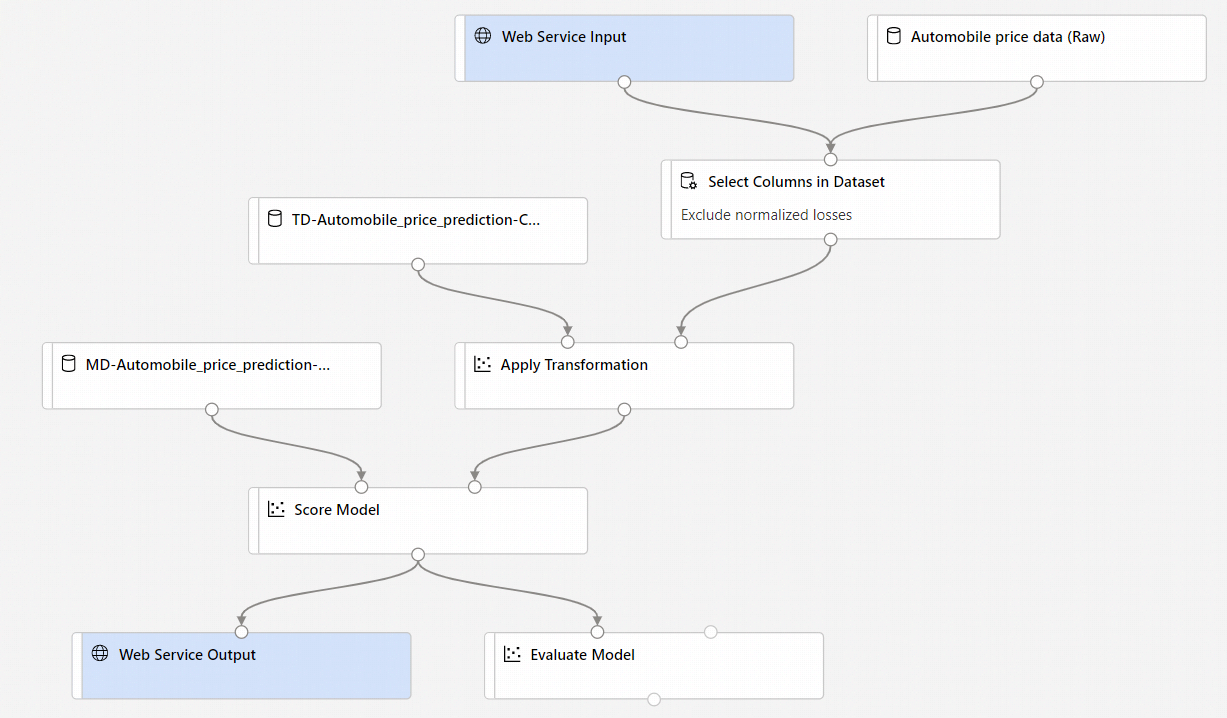
Po wybraniu pozycji Utwórz potok wnioskowania następuje kilka rzeczy:
- Wytrenowany model jest przechowywany jako składnik Zestawu danych na palecie składników. Możesz go znaleźć w obszarze Moje zestawy danych.
- Składniki trenowania, takie jak Train Model (Trenowanie modelu ) i Split Data (Podział danych), są usuwane.
- Zapisany wytrenowany model jest dodawany z powrotem do potoku.
- Dodawane są składniki wejściowe usługi sieci Web i dane wyjściowe usługi sieci Web. Te składniki pokazują, gdzie dane użytkownika wchodzą w potok i gdzie są zwracane dane.
Uwaga
Domyślnie dane wejściowe usługi sieci Web oczekują tego samego schematu danych co dane wyjściowe składnika, które łączą się z tym samym portem podrzędnym. W tym przykładzie dane wejściowe usługi sieci Web i dane cen samochodów (nieprzetworzone) łączą się z tym samym składnikiem podrzędnym, więc dane wejściowe usługi sieci Web oczekują tego samego schematu danych co dane cen samochodów (nieprzetworzone) i kolumna
pricezmiennej docelowej jest uwzględniona w schemacie. Jednak podczas oceniania danych nie będziesz wiedzieć wartości zmiennych docelowych. W takim przypadku możesz usunąć kolumnę zmiennej docelowej w potoku wnioskowania przy użyciu składnika Select Columns in Dataset (Wybieranie kolumn w zestawie danych ). Upewnij się, że dane wyjściowe polecenia Select Columns in Dataset (Wybieranie kolumn w zestawie danych ) usuwające zmienną docelową są połączone z tym samym portem co dane wyjściowe składnika Wejściowe usługi sieci Web.Wybierz pozycję Konfiguruj i prześlij, a następnie użyj tego samego celu obliczeniowego i eksperymentu użytego w części 1.
Jeśli jest to pierwsze zadanie, uruchomienie potoku może potrwać do 20 minut. Domyślne ustawienia obliczeniowe mają minimalny rozmiar węzła wynoszący 0, co oznacza, że projektant musi przydzielić zasoby po bezczynności. Powtarzające się zadania potoku zajmują mniej czasu, ponieważ zasoby obliczeniowe są już przydzielone. Ponadto projektant używa buforowanych wyników dla każdego składnika, aby zwiększyć wydajność.
Przejdź do szczegółów zadania potoku wnioskowania w czasie rzeczywistym, wybierając pozycję Szczegóły zadania w okienku po lewej stronie.
Wybierz pozycję Wdróż na stronie szczegółów zadania.
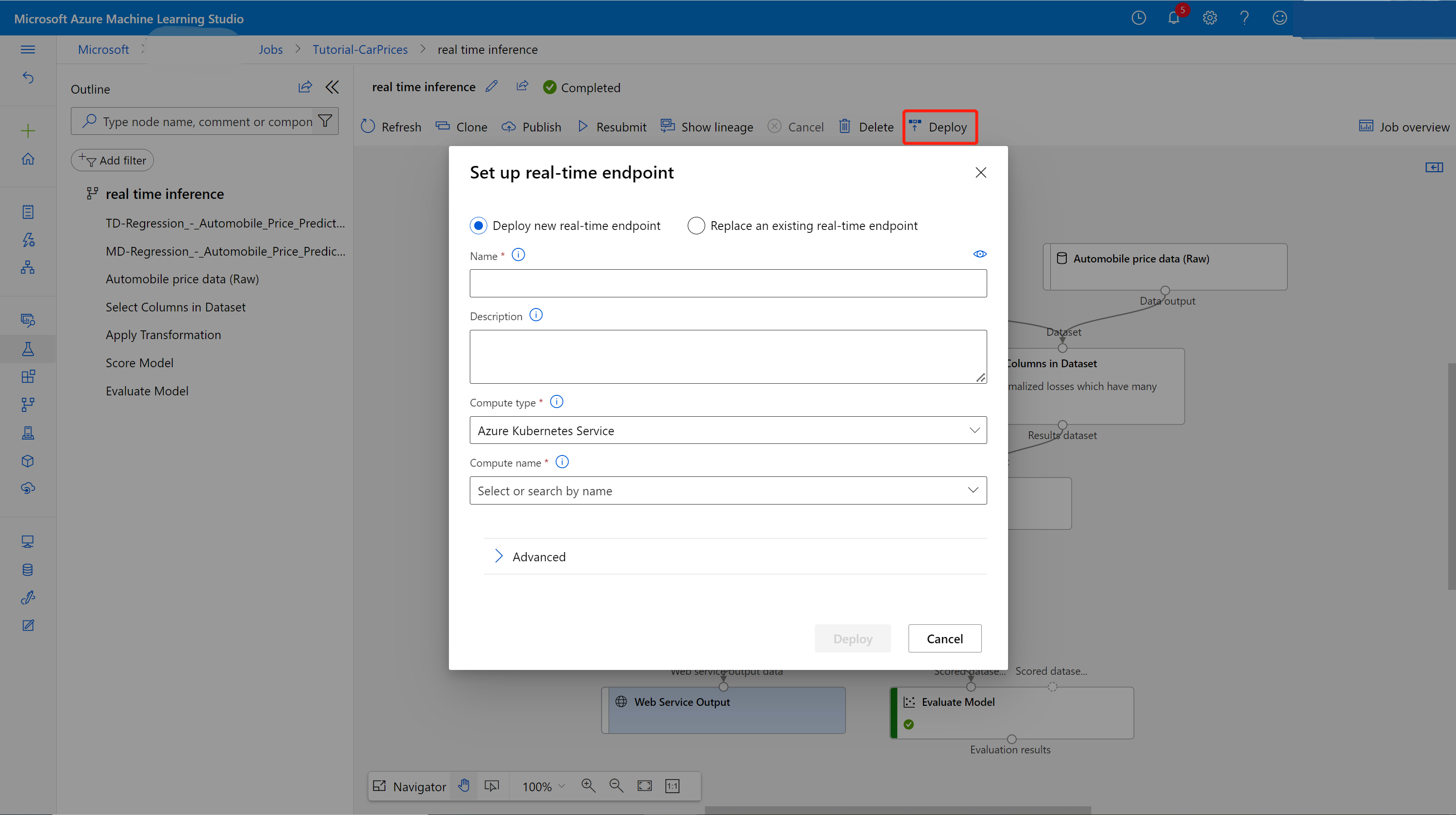


Tworzenie klastra wnioskowania
W wyświetlonym oknie dialogowym możesz wybrać dowolny istniejący klaster usługi Azure Kubernetes Service (AKS), aby wdrożyć model. Jeśli nie masz klastra usługi AKS, wykonaj następujące kroki, aby je utworzyć.
Przejdź do strony Obliczenia , wybierając pozycję Obliczenia w oknie dialogowym.
Na wstążce nawigacji wybierz pozycję Klastry> Kubernetes + Nowe.
W okienku klastra wnioskowania skonfiguruj nową usługę Kubernetes Service.
Wprowadź wartość aks-compute dla nazwy obliczeniowej.
Wybierz region w pobliżu, który jest dostępny dla regionu.
Wybierz pozycję Utwórz.
Uwaga
Utworzenie nowej usługi AKS trwa około 15 minut. Stan aprowizacji można sprawdzić na stronie Klastry wnioskowania.
Wdrażanie punktu końcowego w czasie rzeczywistym
Po zakończeniu aprowizacji usługi AKS wróć do potoku wnioskowania w czasie rzeczywistym, aby ukończyć wdrażanie.
Wybierz pozycję Wdróż nad kanwą.
Wybierz pozycję Wdróż nowy punkt końcowy w czasie rzeczywistym.
Wybierz utworzony klaster usługi AKS.
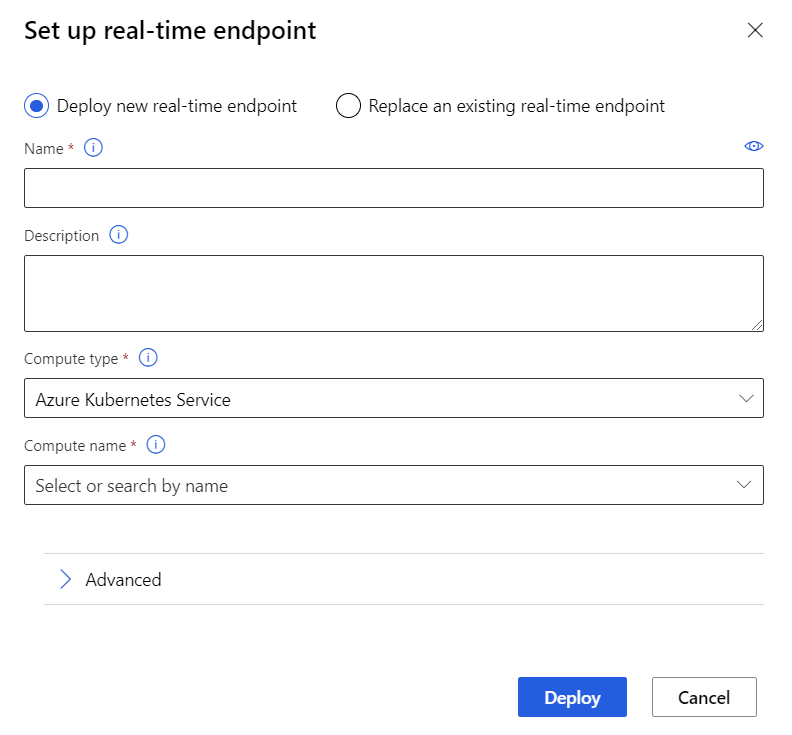
Możesz również zmienić ustawienie Zaawansowane dla punktu końcowego w czasie rzeczywistym.
Ustawienie zaawansowane opis Włączanie diagnostyki i zbierania danych usługi Application Insights Umożliwia aplikacja systemu Azure Insights zbieranie danych z wdrożonych punktów końcowych.
Domyślnie: false.Limit czasu oceniania Limit czasu w milisekundach wymuszany w przypadku oceniania wywołań do usługi internetowej.
Domyślnie: 60000.Automatyczne skalowanie włączone Umożliwia skalowanie automatyczne dla usługi internetowej.
Domyślnie: true.Minimalna liczba replik Minimalna liczba kontenerów do użycia podczas skalowania automatycznego tej usługi internetowej.
Domyślnie: 1.Maksymalna liczba replik Maksymalna liczba kontenerów do użycia podczas skalowania automatycznego tej usługi internetowej.
Domyślnie: 10.Wykorzystanie docelowe Wykorzystanie docelowe (jako wartość procentowa), które program autoskalowania powinien podjąć próbę utrzymania dla tej usługi internetowej.
Domyślnie: 70.Okres odświeżania Jak często (w sekundach) autoskalator próbuje skalować tę usługę internetową.
Domyślnie: 1.Pojemność rezerw procesora CPU Liczba rdzeni procesora CPU do przydzielenia dla tej usługi internetowej.
Domyślnie: 0.1.Pojemność rezerw pamięci Ilość pamięci (w GB) do przydzielenia dla tej usługi internetowej.
Domyślnie: 0,5.Wybierz Wdróż.
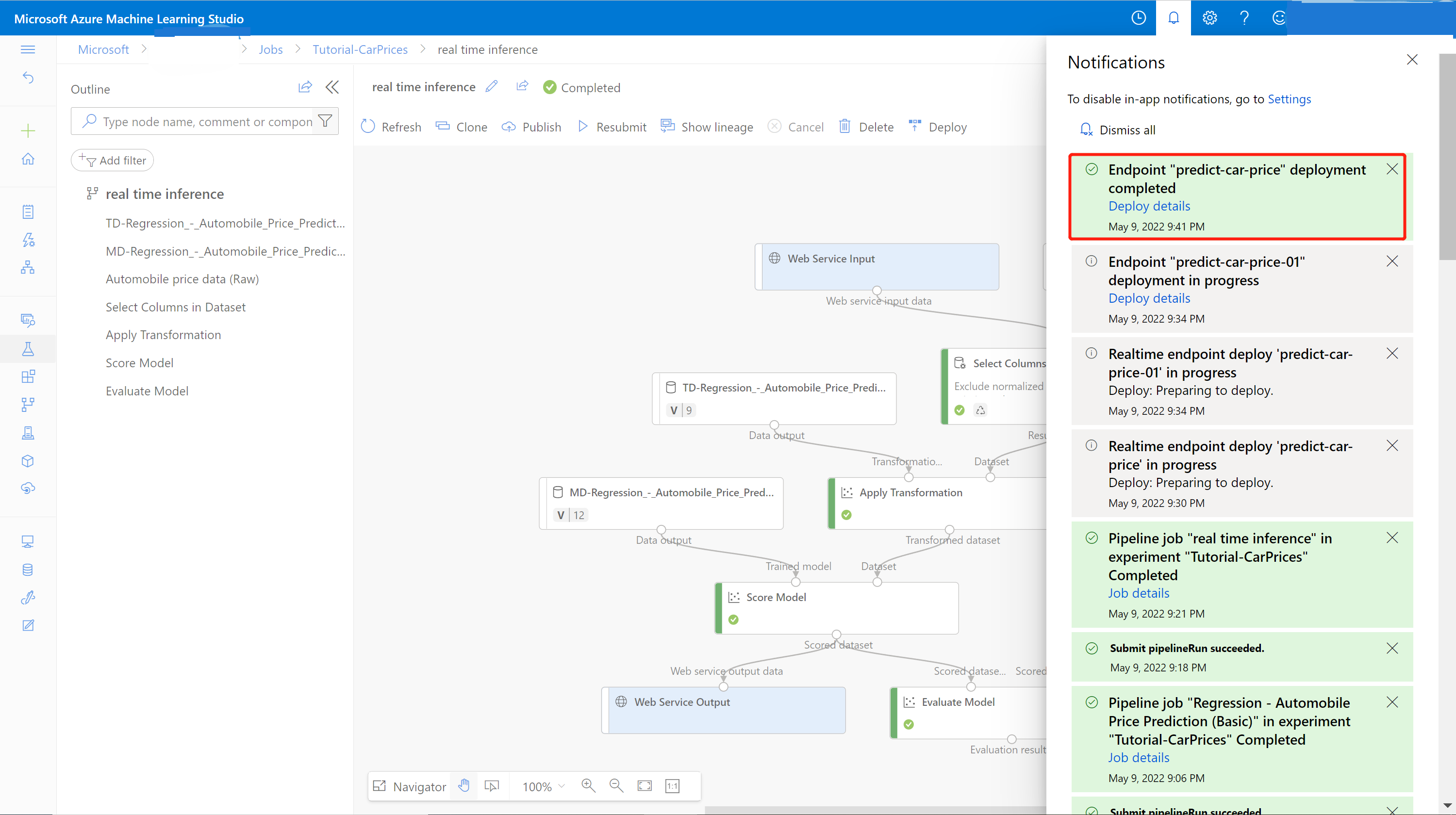
Po zakończeniu wdrażania zostanie wyświetlone powiadomienie o powodzeniu z centrum powiadomień. Może to potrwać kilka minut.

Napiwek
Możesz również wdrożyć w usłudze Azure Container Instance, jeśli wybierzesz pozycję Wystąpienie kontenera platformy Azure dla typu obliczeniowego w polu ustawienia punktu końcowego czasu rzeczywistego. Usługa Azure Container Instance jest używana do testowania lub programowania. Użyj usługi Azure Container Instance w przypadku obciążeń opartych na procesorach o niskiej skali, które wymagają mniej niż 48 GB pamięci RAM.
Testowanie punktu końcowego w czasie rzeczywistym
Po zakończeniu wdrażania możesz wyświetlić punkt końcowy w czasie rzeczywistym, przechodząc do strony Punkty końcowe .
Na stronie Punkty końcowe wybierz wdrożony punkt końcowy.
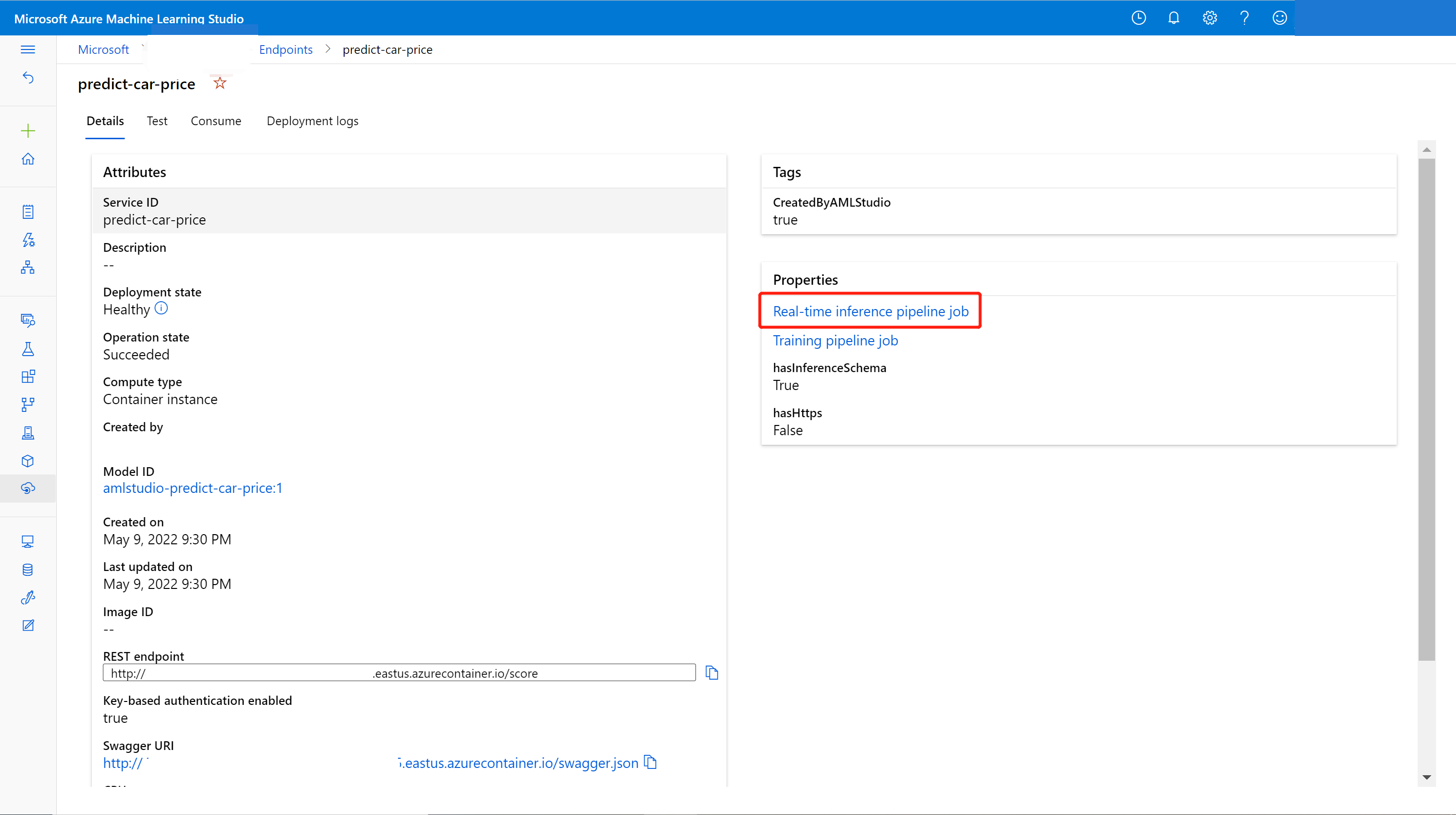
Na karcie Szczegóły można wyświetlić więcej informacji, takich jak identyfikator URI REST, definicja struktury Swagger, stan i tagi.
Na karcie Użycie możesz znaleźć przykładowy kod użycia, klucze zabezpieczeń i ustawić metody uwierzytelniania.
Na karcie Dzienniki wdrażania można znaleźć szczegółowe dzienniki wdrażania punktu końcowego w czasie rzeczywistym.
Aby przetestować punkt końcowy, przejdź do karty Testowanie . W tym miejscu możesz wprowadzić dane testowe i wybrać pozycję Testuj sprawdź dane wyjściowe punktu końcowego.
Aktualizowanie punktu końcowego w czasie rzeczywistym
Punkt końcowy online można zaktualizować przy użyciu nowego modelu wytrenowanego w projektancie. Na stronie szczegółów punktu końcowego online znajdź poprzednie zadanie potoku trenowania i zadanie potoku wnioskowania.
Wersję roboczą potoku trenowania można znaleźć i zmodyfikować na stronie głównej projektanta.
Możesz też otworzyć link zadania potoku trenowania, a następnie sklonować go do nowej wersji roboczej potoku, aby kontynuować edycję.
Po przesłaniu zmodyfikowanego potoku trenowania przejdź do strony szczegółów zadania.
Po zakończeniu zadania kliknij prawym przyciskiem myszy pozycję Train Model (Trenowanie modelu ) i wybierz pozycję Register data (Zarejestruj dane).
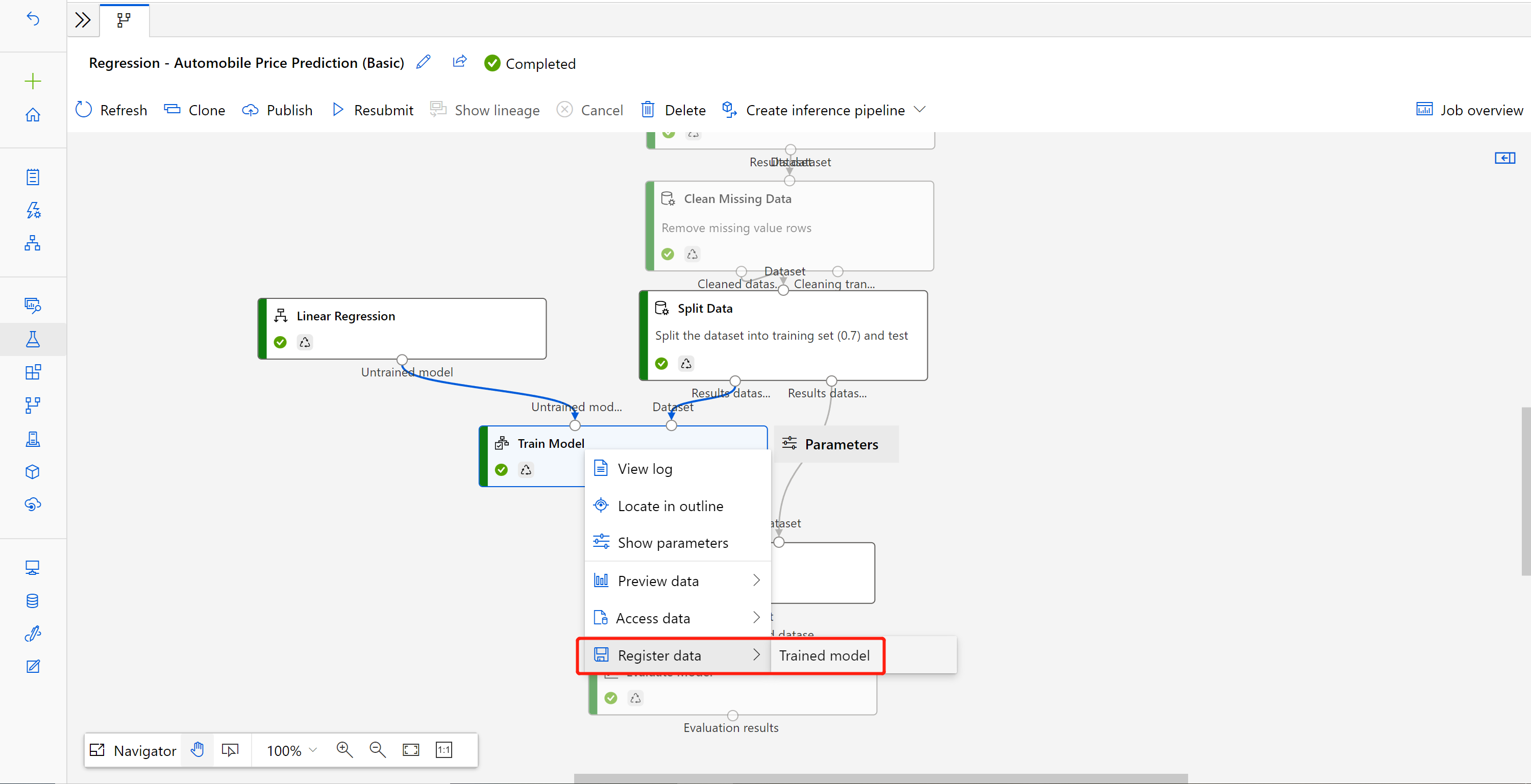
Nazwa danych wejściowych i wybierz pozycję Typ pliku .
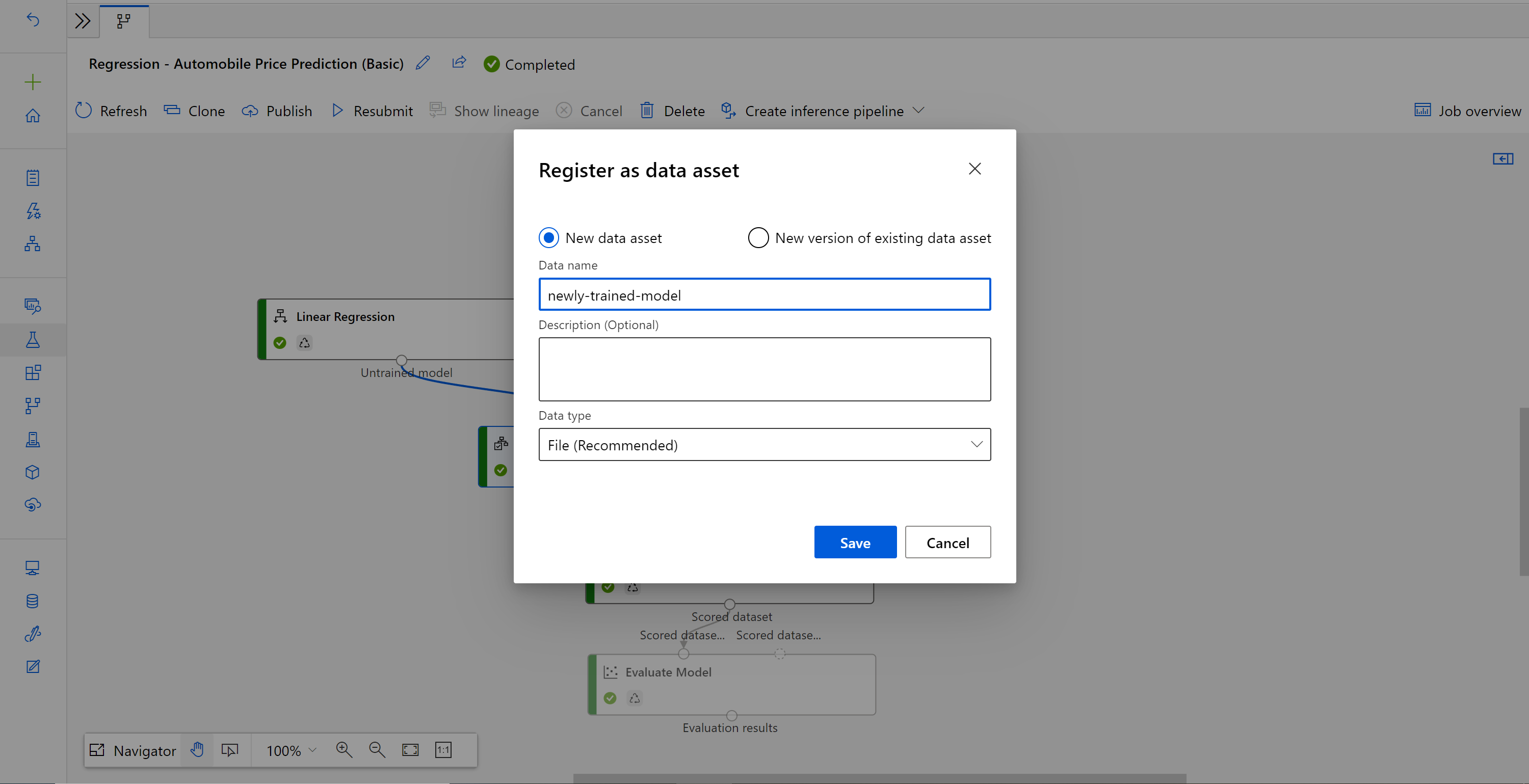
Po pomyślnym zarejestrowaniu zestawu danych otwórz wersję roboczą potoku wnioskowania lub sklonuj poprzednie zadanie potoku wnioskowania do nowej wersji roboczej. W wersji roboczej potoku wnioskowania zastąp poprzedni wytrenowany model pokazany jako węzeł MD-XXXX połączony ze składnikiem Score Model (Generowanie wyników dla modelu ) nowo zarejestrowanym zestawem danych.
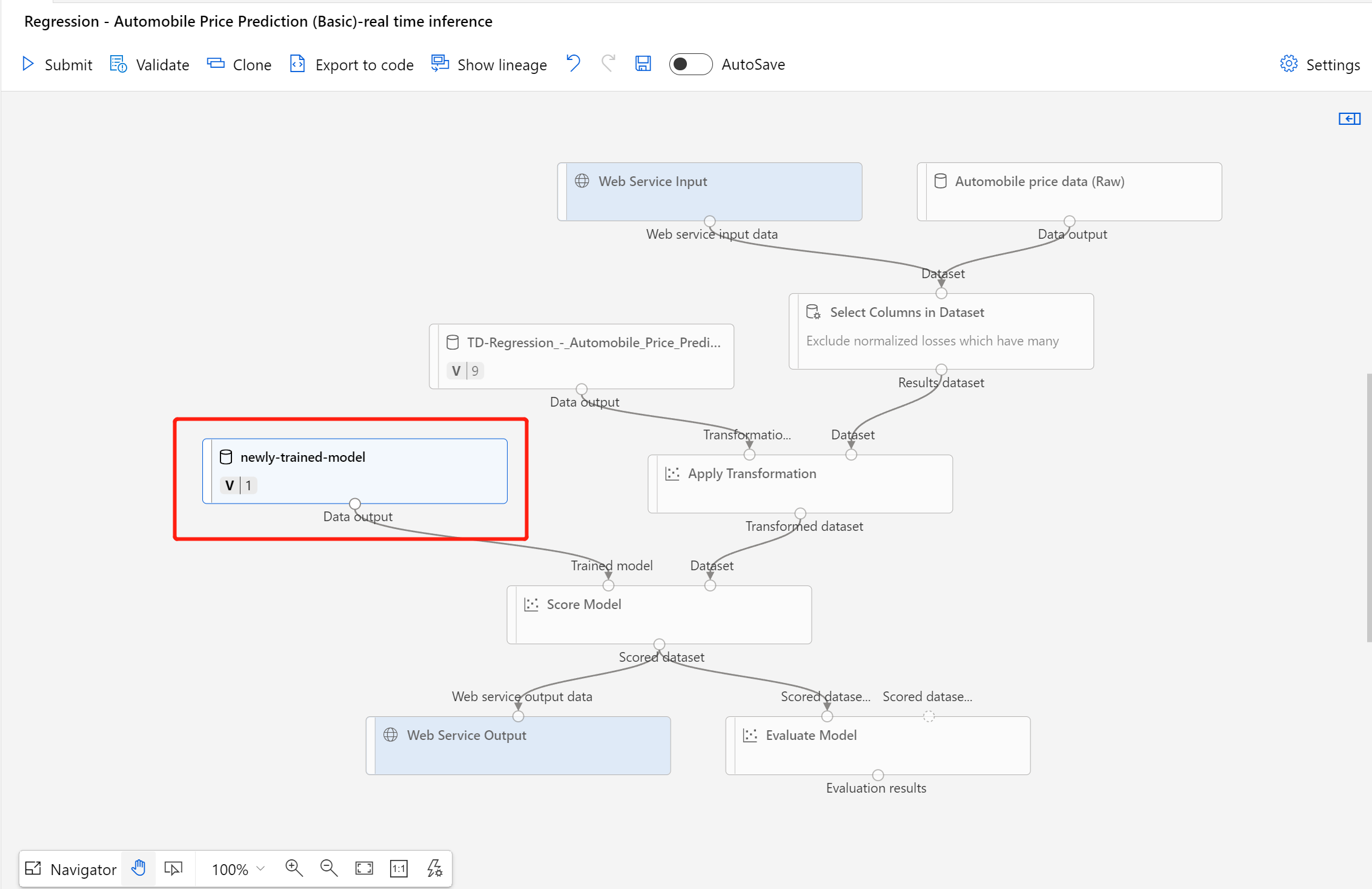
Jeśli musisz zaktualizować część przetwarzania wstępnego danych w potoku trenowania i chcesz zaktualizować je do potoku wnioskowania, przetwarzanie jest podobne do powyższych kroków.
Wystarczy zarejestrować dane wyjściowe przekształcenia składnika transformacji jako zestaw danych.
Następnie ręcznie zastąp składnik TD w potoku wnioskowania zarejestrowanym zestawem danych.
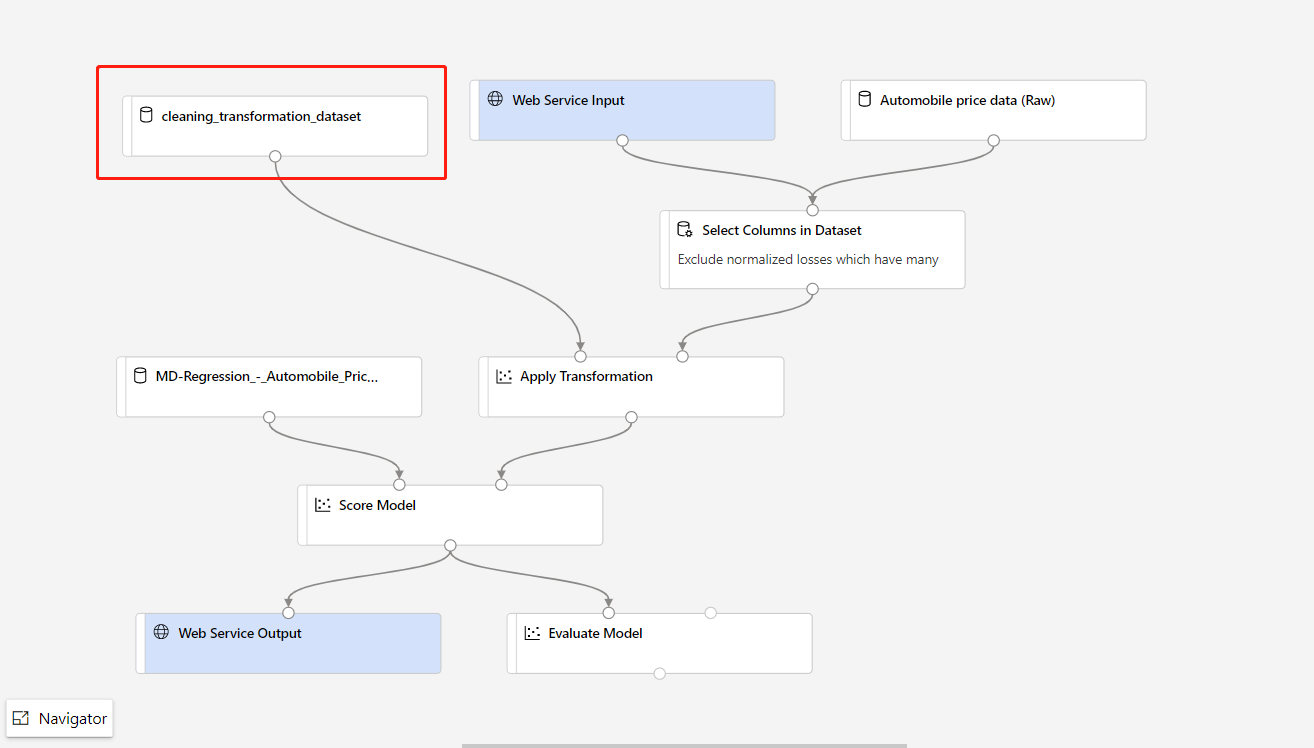
Po zmodyfikowaniu potoku wnioskowania przy użyciu nowo wytrenowanego modelu lub przekształcenia prześlij go. Po zakończeniu zadania wdróż je w istniejącym punkcie końcowym online wdrożonym wcześniej.
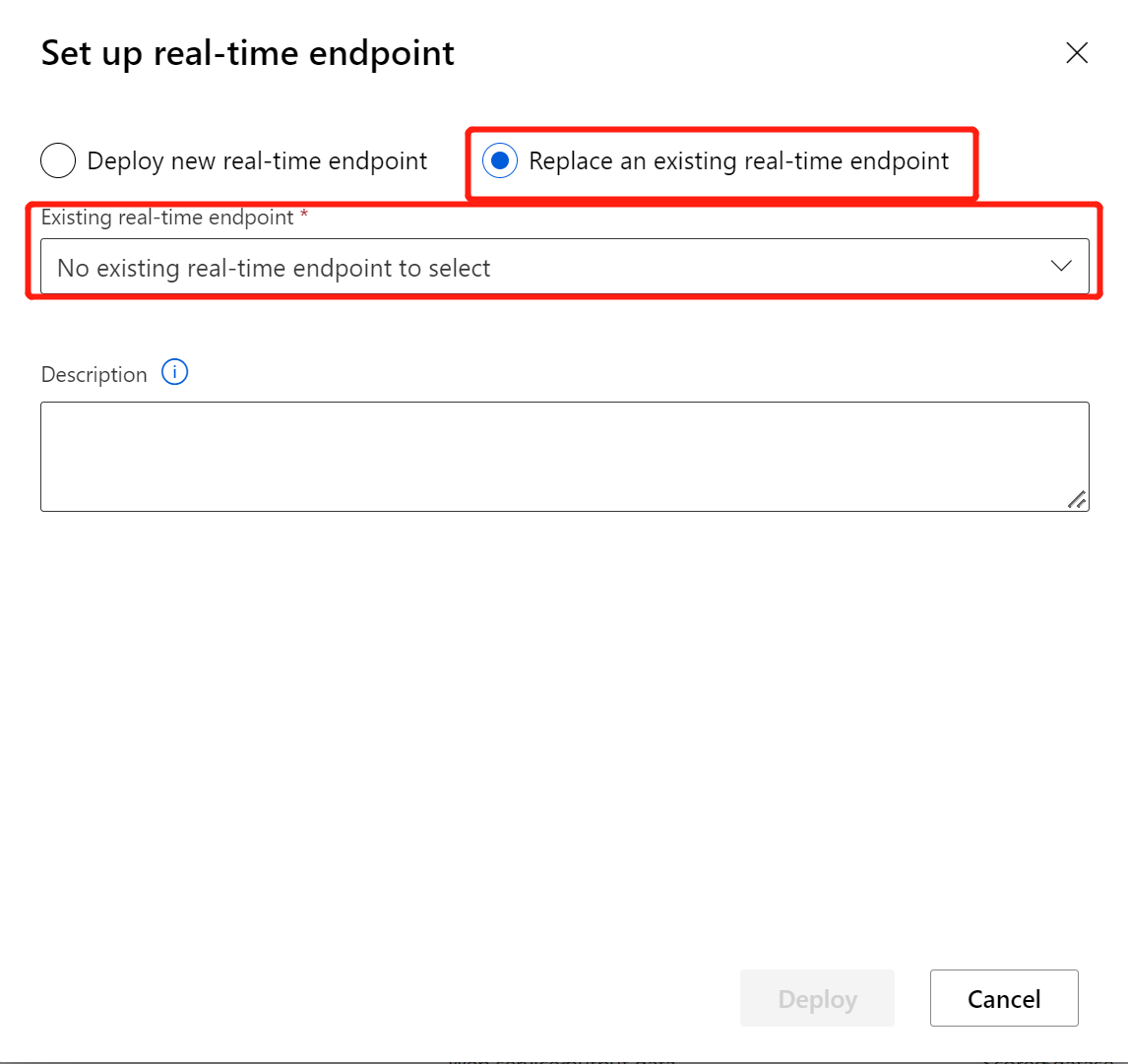




Ograniczenia
Ze względu na ograniczenie dostępu do magazynu danych, jeśli potok wnioskowania zawiera składniki Importuj dane lub Eksportuj dane, są one automatycznie usuwane po wdrożeniu do punktu końcowego czasu rzeczywistego.
Jeśli masz zestawy danych w potoku wnioskowania w czasie rzeczywistym i chcesz wdrożyć je w punkcie końcowym czasu rzeczywistego, obecnie ten przepływ obsługuje tylko zestawy danych zarejestrowane w magazynie danych obiektów blob . Jeśli chcesz używać zestawów danych z innych magazynów danych typu, możesz użyć pozycji Wybierz kolumnę , aby nawiązać połączenie z początkowym zestawem danych z ustawieniami wybierania wszystkich kolumn, zarejestruj dane wyjściowe zestawu danych Select Column as File dataset( Wybierz kolumnę jako zestaw danych), a następnie zastąp początkowy zestaw danych w potoku wnioskowania w czasie rzeczywistym tym nowo zarejestrowanym zestawem danych.
Jeśli graf wnioskowania zawiera składnik Wprowadź dane ręcznie , który nie jest połączony z tym samym portem co składnik Wejściowy usługi internetowej, składnik Wprowadź dane ręcznie nie jest wykonywany podczas przetwarzania wywołań HTTP. Obejściem jest zarejestrowanie danych wyjściowych tego składnika Enter Data Manually jako zestawu danych, a następnie w wersji roboczej potoku wnioskowania zastąp składnik Enter Data Manually zarejestrowanym zestawem danych.


Czyszczenie zasobów
Ważne
Możesz użyć zasobów utworzonych jako wymagania wstępne dla innych samouczków usługi Azure Machine Learning i artykułów z instrukcjami.
Usuń wszystko
Jeśli nie planujesz używać utworzonych elementów, usuń całą grupę zasobów, aby nie ponosić żadnych opłat.
W witrynie Azure Portal wybierz pozycję Grupy zasobów po lewej stronie okna.
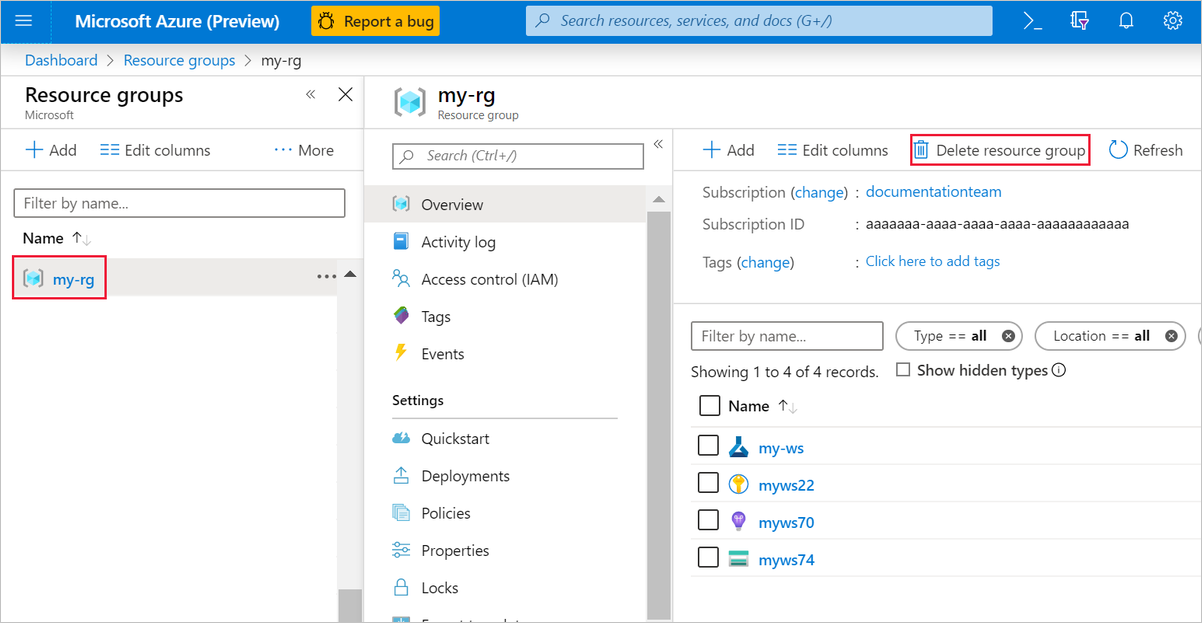
Na liście wybierz utworzoną grupę zasobów.
Wybierz pozycję Usuń grupę zasobów.
Usunięcie grupy zasobów powoduje również usunięcie wszystkich zasobów utworzonych w projektancie.
Usuwanie pojedynczych zasobów
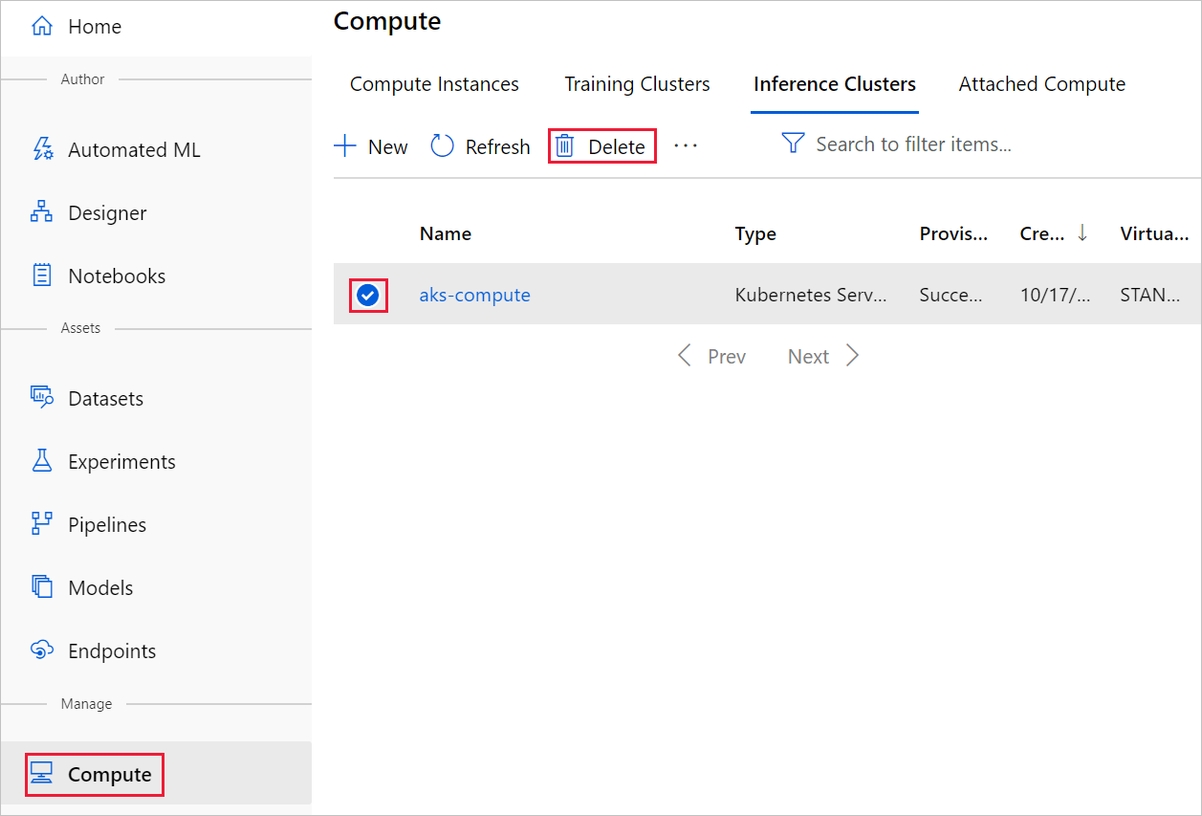
W projektancie, w którym utworzono eksperyment, usuń poszczególne zasoby, wybierając je, a następnie wybierając przycisk Usuń .
Docelowy obiekt obliczeniowy utworzony w tym miejscu automatycznie skaluje się do zera węzłów, gdy nie jest używany. Ta akcja jest podejmowana w celu zminimalizowania opłat. Jeśli chcesz usunąć docelowy obiekt obliczeniowy, wykonaj następujące kroki:
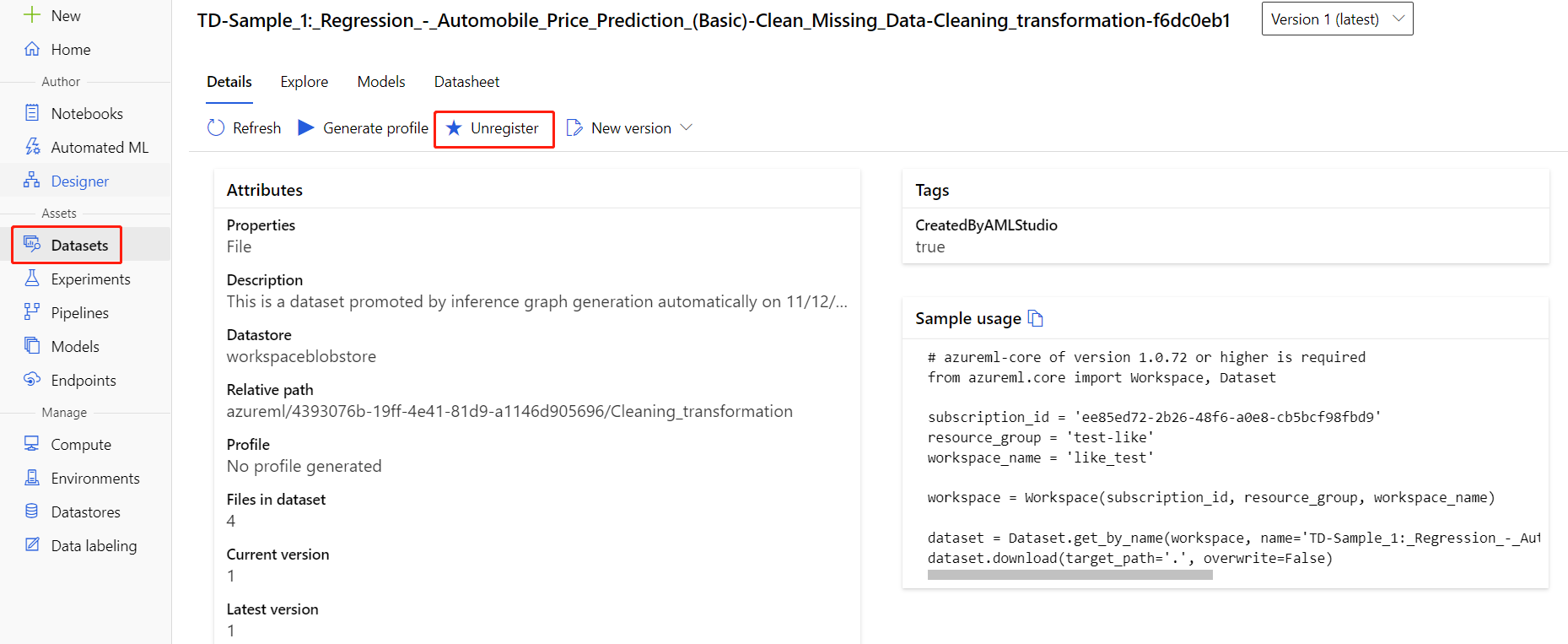
Zestawy danych można wyrejestrować z obszaru roboczego, wybierając każdy zestaw danych i wybierając pozycję Wyrejestruj.
Aby usunąć zestaw danych, przejdź do konta magazynu przy użyciu witryny Azure Portal lub Eksplorator usługi Azure Storage i ręcznie usuń te zasoby.
Powiązana zawartość
W tym samouczku przedstawiono sposób tworzenia, wdrażania i korzystania z modelu uczenia maszynowego w projektancie. Aby dowiedzieć się więcej o sposobie korzystania z projektanta, zobacz następujące artykuły: