Wdrażanie modeli uczenia maszynowego na platformie Azure
DOTYCZY: Rozszerzenie uczenia maszynowego platformy Azure w wersji 1Zestaw SDK języka Python w wersji 1
Rozszerzenie uczenia maszynowego platformy Azure w wersji 1Zestaw SDK języka Python w wersji 1
Dowiedz się, jak wdrożyć model uczenia maszynowego lub uczenia głębokiego jako usługę internetową w chmurze platformy Azure.
Uwaga
Punkty końcowe usługi Azure Machine Learning (wersja 2) zapewniają ulepszone, prostsze środowisko wdrażania. Punkty końcowe obsługują scenariusze wnioskowania w czasie rzeczywistym i wsadowe. Punkty końcowe zapewniają ujednolicony interfejs do wywoływania wdrożeń modelu i zarządzania nimi w różnych typach obliczeniowych. Zobacz Co to są punkty końcowe usługi Azure Machine Learning?.
Przepływ pracy wdrażania modelu
Przepływ pracy wygląda podobnie niezależnie od tego, gdzie wdrażasz model:
- Zarejestrowanie modelu.
- Przygotuj skrypt wejściowy.
- Przygotuj konfigurację wnioskowania.
- Wdróż model lokalnie, aby upewnić się, że wszystko działa.
- Wybierz docelowy obiekt obliczeniowy.
- Wdrażanie modelu w chmurze.
- Przetestuj wynikową usługę internetową.
Aby uzyskać więcej informacji na temat pojęć związanych z przepływem pracy wdrażania uczenia maszynowego, zobacz Zarządzanie, wdrażanie i monitorowanie modeli za pomocą usługi Azure Machine Learning.
Wymagania wstępne
DOTYCZY:Rozszerzenie uczenia maszynowego platformy Azure w wersji 1
Ważne
Polecenia interfejsu wiersza polecenia platformy Azure w tym artykule wymagająazure-cli-mlrozszerzenia lub v1 dla usługi Azure Machine Learning. Obsługa rozszerzenia w wersji 1 zakończy się 30 września 2025 r. Będzie można zainstalować rozszerzenie v1 i używać go do tej daty.
Zalecamy przejście do mlrozszerzenia , lub v2 przed 30 września 2025 r. Aby uzyskać więcej informacji na temat rozszerzenia w wersji 2, zobacz Rozszerzenie interfejsu wiersza polecenia usługi Azure ML i zestaw Python SDK w wersji 2.
- Obszar roboczy usługi Azure Machine Learning. Aby uzyskać więcej informacji, zobacz Tworzenie zasobów obszaru roboczego.
- Model. W przykładach w tym artykule użyto wstępnie wytrenowanego modelu.
- Maszyna, na którą można uruchomić platformę Docker, na przykład wystąpienie obliczeniowe.
Nawiązywanie połączenia z obszarem roboczym
DOTYCZY:Rozszerzenie uczenia maszynowego platformy Azure w wersji 1
Aby wyświetlić obszary robocze, do których masz dostęp, użyj następujących poleceń:
az login
az account set -s <subscription>
az ml workspace list --resource-group=<resource-group>
Rejestrowanie modelu
Typowa sytuacja w przypadku wdrożonej usługi uczenia maszynowego polega na tym, że potrzebne są następujące składniki:
- Zasoby reprezentujące konkretny model, który chcesz wdrożyć (na przykład plik modelu pytorch).
- Kod, który będzie uruchamiany w usłudze, która wykonuje model na danych wejściowych.
Usługa Azure Machine Learning pozwala na rozdzielenie wdrożenia na dwa oddzielne składniki, dzięki czemu można zachować ten sam kod i zaktualizować jedynie model. Definiujemy mechanizm, za pomocą którego przekazujesz model oddzielnie od kodu jako "rejestrowanie modelu".
Podczas rejestrowania modelu przekazujemy go do chmury (na domyślne konto magazynu obszaru roboczego), a następnie instalujemy w tym samym środowisku obliczeniowym, w którym działa usługa internetowa.
W poniższych przykładach pokazano, jak zarejestrować model.
Ważne
Należy używać tylko modeli samodzielnie utworzonych lub uzyskanych z zaufanego źródła. Modele serializowane należy traktować jako kod, ponieważ w wielu popularnych formatach wykryto luki w zabezpieczeniach. Ponadto modele mogą być celowo wytrenowane ze złośliwym zamiarem, aby dawać stronnicze lub niedokładne dane wyjściowe.
DOTYCZY:Rozszerzenie uczenia maszynowego platformy Azure w wersji 1
Następujące polecenia pobierają model, a następnie rejestrują go w obszarze roboczym usługi Azure Machine Learning:
wget https://aka.ms/bidaf-9-model -O model.onnx --show-progress
az ml model register -n bidaf_onnx \
-p ./model.onnx \
-g <resource-group> \
-w <workspace-name>
Ustaw -p ścieżkę folderu lub pliku, który chcesz zarejestrować.
Aby uzyskać więcej informacji na az ml model registertemat programu , zobacz dokumentację referencyjną.
Rejestrowanie modelu z zadania szkoleniowego usługi Azure Machine Learning
Jeśli musisz zarejestrować model utworzony wcześniej za pomocą zadania trenowania usługi Azure Machine Learning, możesz określić eksperyment, przebieg i ścieżkę do modelu:
az ml model register -n bidaf_onnx --asset-path outputs/model.onnx --experiment-name myexperiment --run-id myrunid --tag area=qna
Parametr --asset-path odwołuje się do lokalizacji chmury modelu. W tym przykładzie jest używana ścieżka pojedynczego pliku. Aby dołączyć wiele plików do rejestracji modelu, ustaw --asset-path ścieżkę folderu zawierającego pliki.
Aby uzyskać więcej informacji na az ml model registertemat programu , zobacz dokumentację referencyjną.
Uwaga
Model można również zarejestrować z pliku lokalnego za pośrednictwem portalu interfejsu użytkownika obszaru roboczego.
Obecnie istnieją dwie opcje przekazywania lokalnego pliku modelu w interfejsie użytkownika:
- Z plików lokalnych, które będą rejestrować model w wersji 2.
- Z plików lokalnych (opartych na strukturze) rejestrujących model w wersji 1.
Należy pamiętać, że tylko modele zarejestrowane za pośrednictwem wejścia z plików lokalnych (opartego na strukturze) (nazywanego modelami w wersji 1) można wdrożyć jako usługi internetowe przy użyciu zestawu SDKKv1/CLIv1.
Definiowanie fikcyjnego skryptu wpisu
Skrypt wejściowy odbiera dane przesyłane do wdrożonej usługi internetowej i przekazuje je do modelu. Następnie zwraca odpowiedź modelu na klienta. Skrypt jest specyficzny dla twojego modelu. Skrypt wejściowy musi rozumieć dane oczekiwane i zwracane przez model.
Dwie czynności, które należy wykonać w skry skrycie wejściowym, to:
- Ładowanie modelu (przy użyciu funkcji o nazwie
init()) - Uruchamianie modelu na danych wejściowych (przy użyciu funkcji o nazwie
run())
W przypadku początkowego wdrożenia użyj fikcyjnego skryptu wejściowego, który wyświetla odbierane dane.
import json
def init():
print("This is init")
def run(data):
test = json.loads(data)
print(f"received data {test}")
return f"test is {test}"
Zapisz ten plik w echo_score.py katalogu o nazwie source_dir. Ten fikcyjny skrypt zwraca wysyłane do niego dane, więc nie używa modelu. Warto jednak przetestować, czy skrypt oceniania jest uruchomiony.
Definiowanie konfiguracji wnioskowania
W konfiguracji wnioskowania opisano kontener i pliki platformy Docker do użycia podczas inicjowania usługi internetowej. Wszystkie pliki w katalogu źródłowym, w tym podkatalogi, zostaną spakowane i przekazane do chmury podczas wdrażania usługi internetowej.
Poniższa konfiguracja wnioskowania określa, że wdrożenie uczenia maszynowego będzie używać pliku echo_score.py w ./source_dir katalogu do przetwarzania żądań przychodzących i że będzie używać obrazu platformy Docker z pakietami języka Python określonymi project_environment w środowisku.
Podczas tworzenia środowiska projektu możesz użyć dowolnego środowiska wyselekcjonowania usługi Azure Machine Learning jako obrazu podstawowego platformy Docker. Zainstalujemy wymagane zależności na górze i zapiszemy wynikowy obraz platformy Docker w repozytorium skojarzonym z obszarem roboczym.
Uwaga
Przekazywanie katalogu źródłowego do wnioskowania w usłudze Azure Machine Learning nie uwzględnia pliku .gitignore ani amlignore
DOTYCZY:Rozszerzenie uczenia maszynowego platformy Azure w wersji 1
Konfigurację wnioskowania minimalnego można zapisać jako:
{
"entryScript": "echo_score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "1"
}
}
Zapisz ten plik pod nazwą dummyinferenceconfig.json.
Zapoznaj się z tym artykułem , aby zapoznać się z bardziej szczegółowym omówieniem konfiguracji wnioskowania.
Definiowanie konfiguracji wdrożenia
Konfiguracja wdrożenia określa ilość pamięci i rdzeni, których potrzebuje usługa internetowa w celu uruchomienia. Zawiera również szczegółowe informacje o konfiguracji podstawowej usługi internetowej. Na przykład konfiguracja wdrożenia pozwala określić, że usługa wymaga 2 gigabajtów pamięci, 2 rdzeni procesora CPU, 1 rdzeni procesora GPU i chcesz włączyć skalowanie automatyczne.
Opcje dostępne dla konfiguracji wdrożenia różnią się w zależności od wybranego celu obliczeniowego. W przypadku wdrożenia lokalnego wystarczy określić, na którym porcie będzie obsługiwana twoja usługa internetowa.
DOTYCZY:Rozszerzenie uczenia maszynowego platformy Azure w wersji 1
Wpisy w dokumencie deploymentconfig.json są mapowe na parametry LocalWebservice.deploy_configuration. W poniższej tabeli opisano mapowanie między jednostkami w dokumencie JSON i parametrami metody :
| Jednostka JSON | Parametr metody | Opis |
|---|---|---|
computeType |
NA | Docelowy zasób obliczeniowy. W przypadku lokalnych obiektów docelowych wartość musi mieć wartość local. |
port |
port |
Port lokalny, na którym można uwidocznić punkt końcowy HTTP usługi. |
Ten kod JSON jest przykładową konfiguracją wdrożenia do użycia z interfejsem wiersza polecenia:
{
"computeType": "local",
"port": 32267
}
Zapisz ten kod JSON jako plik o nazwie deploymentconfig.json.
Aby uzyskać więcej informacji, zobacz schemat wdrażania.
Wdrażanie modelu uczenia maszynowego
Teraz możesz przystąpić do wdrażania modelu.
DOTYCZY:Rozszerzenie uczenia maszynowego platformy Azure w wersji 1
Zastąp bidaf_onnx:1 ciąg nazwą modelu i jego numerem wersji.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic dummyinferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Wywoływanie modelu
Sprawdźmy, czy model echa został pomyślnie wdrożony. Powinno być możliwe wykonywanie prostego żądania aktualności, a także żądanie oceniania:
DOTYCZY:Rozszerzenie uczenia maszynowego platformy Azure w wersji 1
curl -v http://localhost:32267
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Definiowanie skryptu wpisu
Teraz nadszedł czas, aby rzeczywiście załadować model. Najpierw zmodyfikuj skrypt wejściowy:
import json
import numpy as np
import os
import onnxruntime
from nltk import word_tokenize
import nltk
def init():
nltk.download("punkt")
global sess
sess = onnxruntime.InferenceSession(
os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model.onnx")
)
def run(request):
print(request)
text = json.loads(request)
qw, qc = preprocess(text["query"])
cw, cc = preprocess(text["context"])
# Run inference
test = sess.run(
None,
{"query_word": qw, "query_char": qc, "context_word": cw, "context_char": cc},
)
start = np.asscalar(test[0])
end = np.asscalar(test[1])
ans = [w for w in cw[start : end + 1].reshape(-1)]
print(ans)
return ans
def preprocess(word):
tokens = word_tokenize(word)
# split into lower-case word tokens, in numpy array with shape of (seq, 1)
words = np.asarray([w.lower() for w in tokens]).reshape(-1, 1)
# split words into chars, in numpy array with shape of (seq, 1, 1, 16)
chars = [[c for c in t][:16] for t in tokens]
chars = [cs + [""] * (16 - len(cs)) for cs in chars]
chars = np.asarray(chars).reshape(-1, 1, 1, 16)
return words, chars
Zapisz ten plik jako score.py wewnątrz pliku source_dir.
Zwróć uwagę na użycie zmiennej środowiskowej AZUREML_MODEL_DIR do zlokalizowania zarejestrowanego modelu. Teraz, po dodaniu niektórych pakietów pip.
DOTYCZY:Rozszerzenie uczenia maszynowego platformy Azure w wersji 1
{
"entryScript": "score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults",
"nltk",
"numpy",
"onnxruntime"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "2"
}
}
Zapisz ten plik jako inferenceconfig.json
Wdróż ponownie i wywołaj usługę
Ponownie wdróż usługę:
DOTYCZY:Rozszerzenie uczenia maszynowego platformy Azure w wersji 1
Zastąp bidaf_onnx:1 ciąg nazwą modelu i jego numerem wersji.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Następnie upewnij się, że możesz wysłać żądanie końcowe do usługi:
DOTYCZY:Rozszerzenie uczenia maszynowego platformy Azure w wersji 1
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Wybieranie docelowego obiektu obliczeniowego
Docelowy obiekt obliczeniowy używany do hostowania modelu będzie mieć wpływ na koszt i dostępność wdrożonego punktu końcowego. Użyj tej tabeli, aby wybrać odpowiedni docelowy obiekt obliczeniowy.
| Docelowy zasób obliczeniowy | Sposób użycia | Obsługa procesora GPU | Opis |
|---|---|---|---|
| Lokalna usługa internetowa | Testowanie/debugowanie | Służy do ograniczonego testowania i rozwiązywania problemów. Przyspieszanie sprzętowe zależy od używania bibliotek w systemie lokalnym. | |
| Punkty końcowe usługi Azure Machine Learning (tylko zestaw SDK/interfejs wiersza polecenia w wersji 2) | Wnioskowanie w czasie rzeczywistym Wnioskowanie wsadowe |
Tak | W pełni zarządzane obliczenia dla punktów końcowych online w czasie rzeczywistym (zarządzanych punktów końcowych online) i oceniania wsadowego (punkty końcowe wsadowe) w bezserwerowych obliczeniach. |
| Azure Machine Learning Kubernetes | Wnioskowanie w czasie rzeczywistym Wnioskowanie wsadowe |
Tak | Uruchamiaj wnioskowanie obciążeń w klastrach lokalnych, w chmurze i na brzegowych klastrach Kubernetes. |
| Azure Container Instances (tylko zestaw SDK/interfejs wiersza polecenia w wersji 1) | Wnioskowanie w czasie rzeczywistym Zalecane tylko do celów tworzenia i testowania. |
Służy do obsługi obciążeń opartych na procesorach o niskiej skali, które wymagają mniej niż 48 GB pamięci RAM. Nie wymaga zarządzania klastrem. Obsługiwane w projektancie. |
Uwaga
Podczas wybierania jednostki SKU klastra najpierw skaluj w górę, a następnie skaluj w poziomie. Zacznij od maszyny, która ma 150% pamięci RAM wymaganej przez model, sprofiluj wynik i znajdź maszynę, która ma wymaganą wydajność. Gdy już wiesz, zwiększ liczbę maszyn, aby dopasować je do potrzeb współbieżnych wnioskowania.
Uwaga
Wystąpienia kontenerów wymagają zestawu SDK lub interfejsu wiersza polecenia w wersji 1 i są odpowiednie tylko dla małych modeli mniejszych niż 1 GB rozmiaru.
Wdrażanie w chmurze
Po potwierdzeniu, że usługa działa lokalnie i wybrano zdalny docelowy obiekt obliczeniowy, możesz przystąpić do wdrażania w chmurze.
Zmień konfigurację wdrożenia, aby odpowiadała wybranemu celowi obliczeniowemu, w tym przypadku Azure Container Instances:
DOTYCZY:Rozszerzenie uczenia maszynowego platformy Azure w wersji 1
Opcje dostępne dla konfiguracji wdrożenia różnią się w zależności od wybranego celu obliczeniowego.
{
"computeType": "aci",
"containerResourceRequirements":
{
"cpu": 0.5,
"memoryInGB": 1.0
},
"authEnabled": true,
"sslEnabled": false,
"appInsightsEnabled": false
}
Zapisz ten plik jako re-deploymentconfig.json.
Aby uzyskać więcej informacji, zobacz tę dokumentację.
Ponownie wdróż usługę:
DOTYCZY:Rozszerzenie uczenia maszynowego platformy Azure w wersji 1
Zastąp bidaf_onnx:1 ciąg nazwą modelu i jego numerem wersji.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc re-deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Aby wyświetlić dzienniki usługi, użyj następującego polecenia:
az ml service get-logs -n myservice \
-g <resource-group> \
-w <workspace-name>
Wywoływanie zdalnej usługi internetowej
Podczas wdrażania zdalnego może być włączone uwierzytelnianie kluczy. W poniższym przykładzie pokazano, jak pobrać klucz usługi za pomocą języka Python w celu utworzenia żądania wnioskowania.
import requests
import json
from azureml.core import Webservice
service = Webservice(workspace=ws, name="myservice")
scoring_uri = service.scoring_uri
# If the service is authenticated, set the key or token
key, _ = service.get_keys()
# Set the appropriate headers
headers = {"Content-Type": "application/json"}
headers["Authorization"] = f"Bearer {key}"
# Make the request and display the response and logs
data = {
"query": "What color is the fox",
"context": "The quick brown fox jumped over the lazy dog.",
}
data = json.dumps(data)
resp = requests.post(scoring_uri, data=data, headers=headers)
print(resp.text)print(service.get_logs())Zobacz artykuł dotyczący aplikacji klienckich do korzystania z usług internetowych , aby uzyskać więcej przykładowych klientów w innych językach.
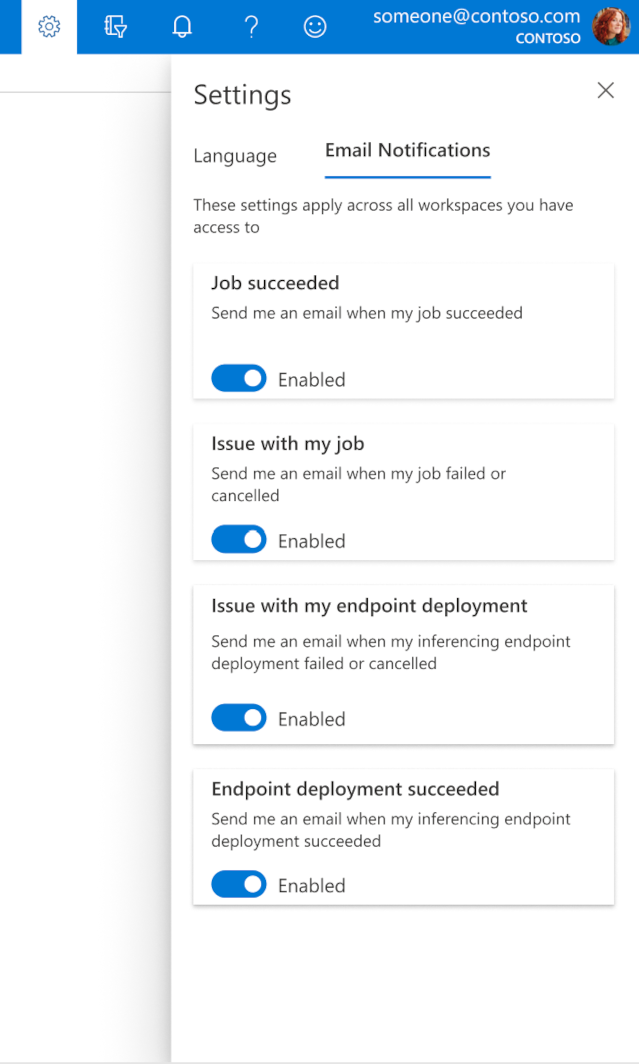
Jak skonfigurować wiadomości e-mail w programie Studio
Aby rozpocząć odbieranie wiadomości e-mail po ukończeniu zadania, punktu końcowego online lub punktu końcowego wsadowego lub w przypadku wystąpienia problemu (niepowodzenie, anulowanie), wykonaj następujące kroki:
- W usłudze Azure ML Studio przejdź do ustawień, wybierając ikonę koła zębatego.
- Wybierz kartę powiadomienia Email.
- Przełącz, aby włączyć lub wyłączyć powiadomienia e-mail dla określonego zdarzenia.
Opis stanu usługi
Podczas wdrażania modelu może zostać wyświetlona zmiana stanu usługi podczas pełnego wdrażania.
W poniższej tabeli opisano różne stany usług:
| Stan usługi internetowej | Opis | Stan końcowy? |
|---|---|---|
| Przejście | Usługa jest w trakcie wdrażania. | Nie |
| Nieprawidłowy | Usługa została wdrożona, ale jest obecnie niemożliwa do osiągnięcia. | Nie |
| Nieplanowalne | Nie można obecnie wdrożyć usługi z powodu braku zasobów. | Nie |
| Niepowodzenie | Wdrożenie usługi nie powiodło się z powodu błędu lub awarii. | Tak |
| Dobra kondycja | Usługa jest w dobrej kondycji, a punkt końcowy jest dostępny. | Tak |
Porada
Podczas wdrażania obrazy platformy Docker dla docelowych obiektów obliczeniowych są kompilowane i ładowane z usługi Azure Container Registry (ACR). Domyślnie usługa Azure Machine Learning tworzy usługę ACR korzystającą z podstawowej warstwy usługi. Zmiana usługi ACR dla obszaru roboczego na warstwę Standardowa lub Premium może skrócić czas potrzebny na kompilowanie i wdrażanie obrazów do celów obliczeniowych. Aby uzyskać więcej informacji, zobacz Warstwy usługi Azure Container Registry.
Uwaga
Jeśli wdrażasz model w usłudze Azure Kubernetes Service (AKS), zalecamy włączenie usługi Azure Monitor dla tego klastra. Pomoże to zrozumieć ogólną kondycję klastra i użycie zasobów. Przydatne mogą być również następujące zasoby:
- Sprawdzanie zdarzeń usługi Resource Health wpływających na klaster usługi AKS
- Diagnostyka usługi Azure Kubernetes Service
Jeśli próbujesz wdrożyć model w klastrze, który jest w złej kondycji lub jest przeciążony, wystąpienie problemów jest bardzo prawdopodobne. Jeśli potrzebujesz pomocy w rozwiązywaniu problemów z klastrem usługi AKS, skontaktuj się z pomocą techniczną usługi AKS.
Usuwanie zasobów
DOTYCZY:Rozszerzenie uczenia maszynowego platformy Azure w wersji 1
# Get the current model id
import os
stream = os.popen(
'az ml model list --model-name=bidaf_onnx --latest --query "[0].id" -o tsv'
)
MODEL_ID = stream.read()[0:-1]
MODEL_IDaz ml service delete -n myservice
az ml service delete -n myaciservice
az ml model delete --model-id=<MODEL_ID>
Aby usunąć wdrożona usługę internetową, użyj polecenia az ml service delete <name of webservice>.
Aby usunąć zarejestrowany model z obszaru roboczego, użyj polecenia az ml model delete <model id>
Przeczytaj więcej na temat usuwania usługi internetowej i usuwania modelu.
Następne kroki
- Rozwiązywanie problemów z niepowodzeniem wdrożenia
- Aktualizowanie usługi internetowej
- Wdrażanie za pomocą jednego kliknięcia dla zautomatyzowanego uczenia maszynowego działa w Azure Machine Learning studio
- Zabezpieczanie usługi internetowej za pomocą usługi Azure Machine Learning przy użyciu protokołu TLS
- Monitorowanie modeli usługi Azure Machine Learning za pomocą usługi Application Insights
- Tworzenie alertów zdarzeń i wyzwalaczy dla wdrożeń modelu