Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ciągłość działalności biznesowej w usłudze Azure Database for PostgreSQL odnosi się do mechanizmów, zasad i procedur, które umożliwiają firmie kontynuowanie działania w obliczu zakłóceń, szczególnie w odniesieniu do infrastruktury obliczeniowej. W większości przypadków usługa Azure Database for PostgreSQL obsługuje destrukcyjne zdarzenia, które mogą wystąpić w środowisku chmury, oraz zapewniają uruchamianie aplikacji i procesów biznesowych. Istnieją jednak pewne zdarzenia, które nie mogą być obsługiwane automatycznie, takie jak:
- Użytkownik przypadkowo usuwa lub aktualizuje wiersz w tabeli.
- Trzęsienie ziemi powoduje awarię zasilania i tymczasowo wyłącza strefę dostępności lub region.
- Poprawki bazy danych wymagane do rozwiązania problemu z usterką lub zabezpieczeniami.
Usługa Azure Database for PostgreSQL udostępnia funkcje, które chronią dane i zmniejszają przestoje baz danych o znaczeniu krytycznym podczas planowanych i nieplanowanych zdarzeń przestojów. Oparta na infrastrukturze platformy Azure, która oferuje niezawodną odporność i dostępność, usługa Azure Database for PostgreSQL ma funkcje ciągłości działania, które zapewniają kolejną ochronę błędów, spełniają wymagania dotyczące czasu odzyskiwania i zmniejszają narażenie na utratę danych. Podczas tworzenia architektury aplikacji należy wziąć pod uwagę tolerancję przestojów — cel czasu odzyskiwania (RTO) i narażenie na utratę danych — cel punktu odzyskiwania (RPO). Na przykład baza danych o krytycznym znaczeniu dla działania firmy wymaga bardziej rygorystycznego czasu pracy niż testowa baza danych.
W poniższej tabeli przedstawiono funkcje oferowanych przez usługę Azure Database for PostgreSQL.
| Cecha | Opis | Zagadnienia dotyczące |
|---|---|---|
| Automatyczne kopie zapasowe | Instancja elastycznego serwera usługi Azure Database for PostgreSQL automatycznie wykonuje codzienne kopie zapasowe plików bazy danych i stale tworzy kopie zapasowe dzienników transakcji. Okres przechowywania kopii zapasowych może wynosić od 7 do 35 dni. Możesz przywrócić serwer bazy danych do dowolnego punktu w czasie w okresie przechowywania kopii zapasowych. Cel czasu odzyskiwania zależy od rozmiaru danych do przywrócenia i czasu do wykonania odzyskiwania dziennika. Może to potrwać od kilku minut do 12 godzin. Aby uzyskać więcej informacji, zobacz Pojęcia — tworzenie kopii zapasowych i przywracanie. | Dane kopii zapasowej pozostają w regionie. |
| Strefowo nadmiarowa wysoka dostępność | Instancję elastycznego serwera 'Azure Database for PostgreSQL' można wdrożyć w konfiguracji wysokiej dostępności z nadmiarowością strefową, gdzie serwery główny i zapasowy są wdrażane w dwóch różnych strefach dostępności w regionie. Ta konfiguracja wysokiej dostępności chroni bazy danych przed awariami na poziomie strefy, a także pomaga zmniejszyć przestoje aplikacji podczas planowanych i nieplanowanych zdarzeń przestojów. Dane z serwera podstawowego są replikowane do repliki rezerwowej w trybie synchronicznym. W przypadku zakłóceń na serwerze podstawowym serwer jest automatycznie przełączony w tryb failover do repliki rezerwowej. Cel czasu odzyskiwania w większości przypadków powinien być mniejszy niż 120s. Oczekuje się, że wartość celu punktu odzyskiwania będzie równa zero (bez utraty danych). Aby uzyskać więcej informacji, zobacz [Pojęcia — wysoka dostępność]/azure/reliability/reliability-postgresql-flexible-server. | Obsługiwane w warstwach obliczeniowych ogólnego przeznaczenia i zoptymalizowanych pod kątem pamięci. Dostępne tylko w regionach, w których dostępnych jest wiele stref. |
| Wysoka dostępność w tej samej strefie | Instancja serwera elastycznego usługi Azure Database for PostgreSQL może zostać wdrożona z konfiguracją wysokiej dostępności w tej samej strefie, gdzie serwer podstawowy i zapasowy są wdrażane w tej samej strefie dostępności w ramach regionu. Ta konfiguracja wysokiej dostępności chroni bazy danych przed awariami na poziomie węzła, a także pomaga zmniejszyć przestoje aplikacji podczas planowanych i nieplanowanych zdarzeń przestojów. Dane z serwera podstawowego są replikowane do repliki rezerwowej w trybie synchronicznym. W przypadku zakłóceń na serwerze podstawowym serwer jest automatycznie przełączony w tryb failover do repliki rezerwowej. Cel czasu odzyskiwania w większości przypadków powinien być mniejszy niż 120s. Oczekuje się, że wartość celu punktu odzyskiwania będzie równa zero (bez utraty danych). Aby uzyskać więcej informacji, zobacz [Pojęcia — wysoka dostępność]/azure/reliability/reliability-postgresql-flexible-server. | Obsługiwane w warstwach obliczeniowych ogólnego przeznaczenia i zoptymalizowanych pod kątem pamięci. |
| Dyski zarządzane w warstwie Premium | Pliki bazy danych są przechowywane w wysoce trwałym i niezawodnym magazynie zarządzanym w warstwie Premium. Zapewnia to nadmiarowość danych dzięki trzem kopiom repliki przechowywanym w strefie dostępności z funkcjami automatycznego odzyskiwania danych. Aby uzyskać więcej informacji, zobacz dokumentację dysków zarządzanych. | Dane przechowywane w strefie dostępności. |
| Kopia zapasowa strefowo nadmiarowa | Kopie zapasowe elastycznego serwera usługi Azure Database for PostgreSQL są automatycznie i bezpiecznie przechowywane w nadmiarowym przechowywaniu w wielu strefach w regionie, o ile region obsługuje strefy dostępności. Podczas awarii na poziomie strefy, w której jest aprowizowany serwer, a jeśli serwer nie jest skonfigurowany z nadmiarowością strefy, nadal można przywrócić bazę danych przy użyciu najnowszego punktu przywracania w innej strefie. Aby uzyskać więcej informacji, zobacz Koncepty — tworzenie kopii zapasowych i przywracanie. | Dotyczy tylko regionów, w których dostępnych jest wiele stref. |
| Geograficznie redundantna kopia zapasowa | Kopie zapasowe wystąpień serwera elastycznego usługi Azure Database for PostgreSQL są kopiowane do regionu zdalnego. pomaga to w sytuacji odzyskiwania po awarii w przypadku awarii regionu serwera podstawowego. | Ta funkcja jest obecnie włączona w wybranych regionach. Czas odzyskiwania trwa dłużej i wyższy cel punktu odzyskiwania w zależności od rozmiaru danych do przywrócenia i ilości odzyskiwania do wykonania. |
| Replika do odczytu | Repliki odczytu między regionami można wdrożyć w celu ochrony baz danych przed awariami na poziomie regionu. Repliki do odczytu są aktualizowane asynchronicznie przy użyciu technologii replikacji fizycznej bazy danych PostgreSQL i mogą opóźnić replikację podstawową. Aby uzyskać więcej informacji, zobacz Koncepcje - repliki do odczytu. | Obsługiwane w warstwach obliczeniowych ogólnego przeznaczenia i zoptymalizowanych pod kątem pamięci. |
Poniższa tabela porównuje RTO i RPO w typowym scenariuszu obciążenia:
| Zdolność | Jednostka SKU produkcji (ogólnego przeznaczenia/zoptymalizowana pod kątem pamięci) | |
|---|---|---|
| Przywracanie do punktu w czasie z kopii zapasowej | Dowolny punkt przywracania w okresie przechowywania Cel czasu odzyskiwania — różni się < Cel punktu odzyskiwania 5 minut |
Dowolny punkt przywracania w okresie przechowywania Cel czasu odzyskiwania — różni się < Cel punktu odzyskiwania 5 minut |
| Przywracanie geograficzne z kopii zapasowych replikowanych geograficznie | Cel czasu odzyskiwania — różni się < Cel punktu odzyskiwania 1 godz. |
Cel czasu odzyskiwania — różni się < Cel punktu odzyskiwania 1 godz. |
| Repliki do odczytu | Nie dotyczy | Cel czasu odzyskiwania — minuty* RPO — zazwyczaj w zakresie od 30 sekund do 5 minut* |
| Wysoka dostępność | Nie dotyczy | RTO < 120 s Docelowy punkt odzyskiwania = 0 |
Zdarzenia zaplanowanego przestoju
Poniżej przedstawiono niektóre scenariusze planowanej konserwacji. Te zdarzenia zwykle powodują nawet kilka minut przestojów i bez utraty danych.
| Scenariusz | Proces |
|---|---|
| Skalowanie obliczeń (zainicjowane przez użytkownika) | Podczas operacji skalowania obliczeń aktywne punkty kontrolne mogą zostać ukończone, połączenia klienckie są opróżniane, wszystkie niezatwierdzone transakcje są anulowane, magazyn jest odłączony, a następnie zamykany. Nowe wystąpienie serwera elastycznego usługi Azure Database for PostgreSQL o tej samej nazwie serwera bazy danych jest aprowizowane przy użyciu skalowanej konfiguracji obliczeniowej. Magazyn jest następnie dołączony do nowego serwera, a baza danych jest uruchamiana, co w razie potrzeby wykonuje odzyskiwanie przed zaakceptowaniem połączeń klienckich. |
| Skalowanie magazynu w górę (zainicjowane przez użytkownika) | Po zainicjowaniu operacji skalowania w górę magazynu aktywne punkty kontrolne mogą być ukończone, połączenia klientów są opróżniane, a wszystkie niezatwierdzone transakcje zostaną anulowane. Następnie serwer zostanie zamknięty. Magazyn jest skalowany do żądanego rozmiaru, a następnie dołączony do nowego serwera. Odzyskiwanie jest wykonywane w razie potrzeby przed zaakceptowaniem połączeń klienckich. Należy pamiętać, że skalowanie w dół rozmiaru magazynu nie jest obsługiwane. |
| Nowe wdrożenie oprogramowania (zainicjowane przez platformę Azure) | Nowe funkcje lub poprawki błędów są automatycznie wprowadzane w ramach planowanej konserwacji usługi i można zaplanować, kiedy te działania mają miejsce. Aby uzyskać więcej informacji, zapoznaj się z portalem. |
| Uaktualnienia wersji pomocniczych (zainicjowane przez platformę Azure) | Usługa Azure Database for PostgreSQL automatycznie poprawia serwery baz danych do wersji pomocniczej określonej przez platformę Azure. Dzieje się to w ramach planowanej konserwacji usługi. Serwer bazy danych jest automatycznie uruchamiany ponownie przy użyciu nowej wersji pomocniczej. Aby uzyskać więcej informacji, zobacz dokumentację. Możesz również sprawdzić portal. |
Gdy elastyczne wystąpienie serwera usługi Azure Database for PostgreSQL jest skonfigurowane z wysoką dostępnością, usługa najpierw wykonuje skalowanie i operacje konserwacji na serwerze rezerwowym. Aby uzyskać więcej informacji, zobacz [Pojęcia — wysoka dostępność]/azure/reliability/reliability-postgresql-flexible-server.
Ograniczanie niezaplanowanych przestojów
Nieplanowane przestoje mogą wystąpić w wyniku nieprzewidzianych zakłóceń, takich jak błędy sprzętowe, problemy z siecią i błędy oprogramowania. Jeśli serwer bazy danych skonfigurowany z wysoką dostępnością niespodziewanie ulegnie awarii, replika rezerwowa zostanie aktywowana, a klienci mogą wznowić operacje. Jeśli nie skonfigurowano wysokiej dostępności, to jeśli próba ponownego uruchomienia zakończy się niepowodzeniem, nowy serwer bazy danych zostanie automatycznie aprowizowany. Chociaż nie można uniknąć nieplanowanego przestoju, usługa Azure Database for PostgreSQL pomaga ograniczyć przestoje, automatycznie wykonując operacje odzyskiwania bez konieczności interwencji człowieka.
Mimo że stale dążymy do zapewnienia wysokiej dostępności, czasami występuje awaria usługi Azure Database for PostgreSQL powodująca niedostępność baz danych, co wpływa na twoją aplikację. Gdy nasze monitorowanie usługi wykryje problemy, które powodują powszechne błędy łączności, błędy lub problemy z wydajnością, usługa automatycznie deklaruje awarię, aby informować Użytkownika.
Awaria usługi
W przypadku awarii elastycznego serwera Azure Database for PostgreSQL można znaleźć więcej szczegółów dotyczących awarii w następujących miejscach:
- Banner w Azure portal: jeśli twoja subskrypcja zostanie zidentyfikowana jako dotknięta, w Powiadomieniach w Azure portal pojawi się alert awarii dotyczący problemu z usługą.
- Pomoc + obsługa techniczna lub Obsługa techniczna + rozwiązywanie problemów: Podczas tworzenia zgłoszenia pomocy technicznej z Pomoc + obsługa techniczna lub Obsługa techniczna + rozwiązywanie problemów zostaną dostarczone informacje o wszelkich problemach wpływających na zasoby. Wybierz pozycję Wyświetl szczegóły awarii, aby uzyskać więcej informacji i podsumowanie wpływu. Na stronie Nowy wniosek o pomoc techniczną pojawi się również alert.
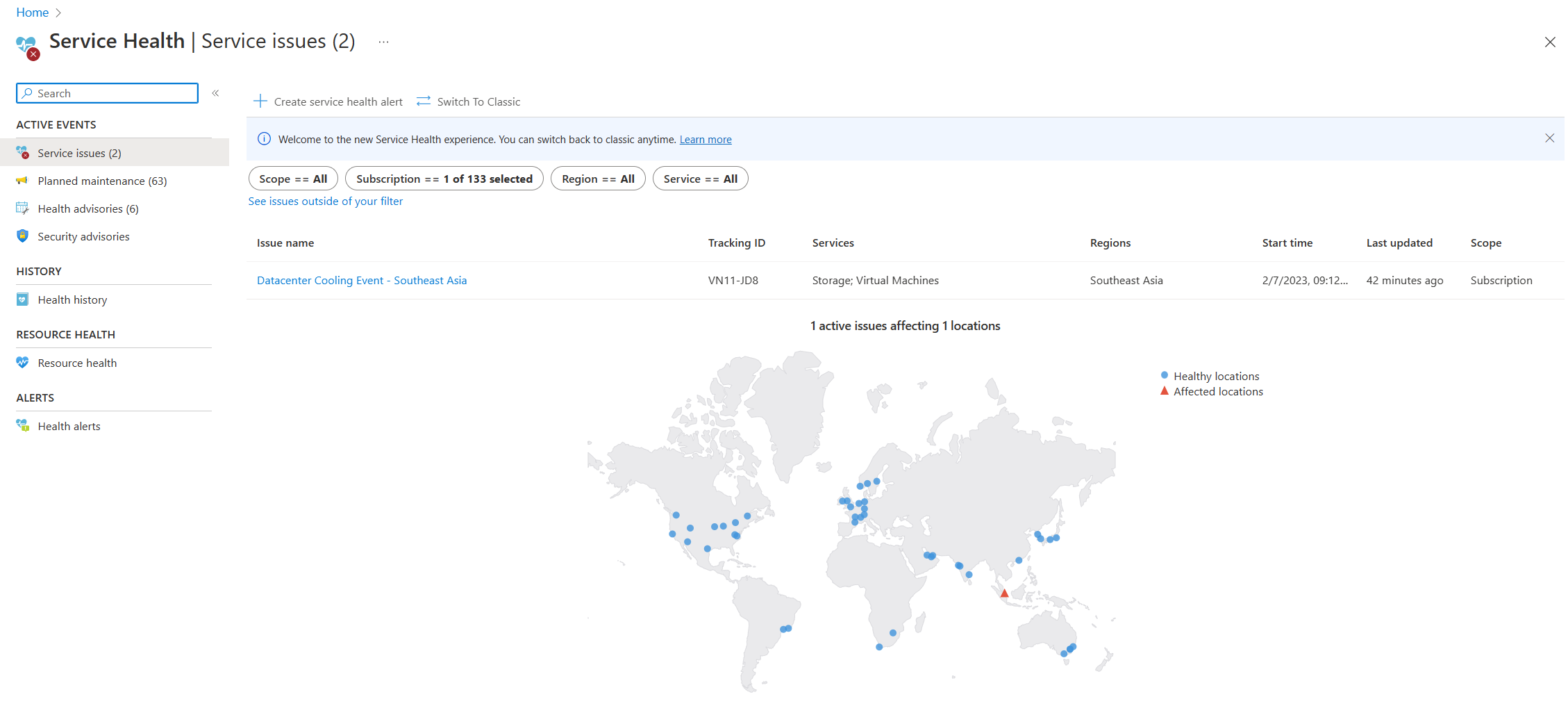
- Pomoc dotycząca usługi: strona Kondycja usługi w witrynie Azure Portal zawiera informacje o stanie centrum danych platformy Azure globalnie. Wyszukaj ciąg "service health" na pasku wyszukiwania w witrynie Azure Portal, a następnie wyświetl pozycję Problemy z usługą w kategorii Aktywne zdarzenia. Kondycję poszczególnych zasobów można również wyświetlić na stronie Kondycja zasobu dowolnego zasobu w menu Pomoc. Poniższy przykładowy zrzut ekranu przedstawiający stronę Kondycja usługi z informacjami o aktywnym problemie z usługą w Azji Południowo-Wschodniej.
- Powiadomienie e-mail: jeśli skonfigurowaliśmy alerty, powiadomienie e-mail pojawi się, gdy awaria usługi wpłynie na subskrypcję i zasób. Wiadomości e-mail pochodzą z "azure-noreply@microsoft.com". Treść wiadomości e-mail zaczyna się od "Alert dziennika aktywności ... został wyzwolony przez problem z usługą dla subskrypcji platformy Azure...". Aby uzyskać więcej informacji na temat alertów dotyczących kondycji usługi, zobacz Odbieranie alertów dziennika aktywności w powiadomieniach usługi platformy Azure przy użyciu witryny Azure Portal.
Ważne
Jak wskazuje nazwa, tymczasowe przestrzenie tabel w bazie danych PostgreSQL są używane do obiektów tymczasowych, a także innych operacji wewnętrznej bazy danych, takich jak sortowanie. W związku z tym nie zalecamy tworzenia obiektów schematu użytkownika w tymczasowej przestrzeni tabel, ponieważ nie gwarantujemy trwałości takich obiektów po ponownym uruchomieniu serwera, przejściu w tryb failover wysokiej dostępności itp.
Nieplanowany przestój: scenariusze awarii i odzyskiwanie usługi
Poniżej przedstawiono niektóre nieplanowane scenariusze awarii i proces odzyskiwania.
| Scenariusz |
Proces odzyskiwania [Serwery skonfigurowane bez strefowo nadmiarowej wysokiej dostępności] |
Proces odzyskiwania [Serwery skonfigurowane ze strefowo nadmiarową wysoką dostępnością] |
|---|---|---|
| Błąd serwera bazy danych | Jeśli serwer bazy danych nie działa, platforma Azure podejmie próbę ponownego uruchomienia serwera bazy danych. Jeśli to się nie powiedzie, serwer bazy danych zostanie uruchomiony ponownie w innym węźle fizycznym. Czas odzyskiwania (RTO) zależy od różnych czynników, w tym działania w momencie wystąpienia błędu, takich jak duża transakcja, oraz wolumin odzyskiwania do wykonania podczas procesu uruchamiania serwera bazy danych. Aplikacje korzystające z baz danych PostgreSQL muszą być tworzone w sposób, w jaki wykrywają i ponawiają próby porzuconych połączeń i nieudanych transakcji. |
Jeśli zostanie wykryta awaria serwera bazy danych, serwer zostanie przełączony w tryb failover na serwer rezerwowy, co zmniejsza czas przestoju. Aby uzyskać więcej informacji, zobacz [strona pojęć wysokiej dostępności]/azure/reliability/reliability-postgresql-flexible-server. Cel czasu odzyskiwania powinien wynosić od 60 do 120, przy zerowej utracie danych. |
| Błąd magazynu | Aplikacje nie widzą żadnego wpływu na problemy związane z magazynem, takie jak awaria dysku lub uszkodzenie fizycznego bloku. Ponieważ dane są przechowywane w trzech kopiach, kopia danych jest obsługiwana przez magazyn ocalały. Uszkodzony blok danych zostanie automatycznie naprawiony i zostanie automatycznie utworzona nowa kopia danych. | W przypadku rzadkich i niemożliwych do odzyskania błędów, takich jak cały magazyn, jest niedostępny, wystąpienie serwera elastycznego usługi Azure Database for PostgreSQL jest przełączone w tryb failover do repliki rezerwowej w celu zmniejszenia przestoju. Aby uzyskać więcej informacji, zobacz [strona pojęć wysokiej dostępności]/azure/reliability/reliability-postgresql-flexible-server. |
| Błędy użytkownika/logiczne | Aby odzyskać dane po błędach użytkownika, takich jak przypadkowo usunięte tabele lub niepoprawnie zaktualizowane dane, należy wykonać odzyskiwanie z określonego punktu w czasie (PITR). Podczas wykonywania operacji przywracania należy określić niestandardowy punkt przywracania, czyli czas bezpośrednio przed wystąpieniem błędu. Jeśli chcesz przywrócić tylko podzbiór baz danych lub określonych tabel, a nie wszystkich baz danych na serwerze bazy danych, możesz przywrócić serwer bazy danych w nowym wystąpieniu, wyeksportować tabele za pośrednictwem pg_dump, a następnie użyć pg_restore , aby przywrócić te tabele do bazy danych. |
Te błędy użytkownika nie są chronione z wysoką dostępnością, ponieważ wszystkie zmiany są replikowane synchronicznie do repliki rezerwowej. Aby odzyskać dane po takich błędach, należy wykonać przywracanie do punktu w czasie. |
| Niepowodzenie strefy dostępności | Aby odzyskać sprawność po awarii na poziomie strefy, możesz wykonać przywracanie do punktu w czasie przy użyciu kopii zapasowej i wybrać niestandardowy punkt przywracania z najnowszym czasem, aby przywrócić najnowsze dane. Nowe wystąpienie serwera elastycznego usługi Azure Database for PostgreSQL jest wdrażane w innej strefie bez wpływu. Czas potrzebny na przywrócenie zależy od poprzedniej kopii zapasowej i ilości dzienników transakcji do odzyskania. | Instancja elastycznego serwera Azure Database for PostgreSQL jest automatycznie przełączana w trybie failover na serwer rezerwowy w ciągu 60–120 sekund, bez utraty danych. Aby uzyskać więcej informacji, zobacz [strona pojęć wysokiej dostępności]/azure/reliability/reliability-postgresql-flexible-server. |
| Błąd regionu | Jeśli serwer jest skonfigurowany z geograficznie nadmiarową kopią zapasową, możesz wykonać przywracanie geograficzne w sparowanym regionie. Nowy serwer zostanie aprowizowany i odzyskany do ostatnich dostępnych danych skopiowanych do tego regionu. Można również użyć replik do odczytu między regionami. W przypadku awarii regionu można wykonać operację odzyskiwania po awarii, promując replikę do odczytu jako autonomiczny serwer do odczytu i zapisu. Oczekuje się, że cel punktu odzyskiwania będzie do 5 minut (możliwa utrata danych), z wyjątkiem przypadków poważnej awarii regionalnej, gdy cel punktu odzyskiwania może być bliski opóźnienia replikacji w momencie awarii. |
Ten sam proces. |
Konfigurowanie bazy danych po odzyskaniu po awarii regionalnej
- Jeśli używasz przywracania geograficznego lub repliki geograficznej do odzyskiwania po awarii, upewnij się, że łączność z nowym serwerem jest prawidłowo skonfigurowana, aby można było wznowić normalną funkcję aplikacji. Możesz wykonać zadania po przywróceniu.
- Jeśli wcześniej skonfigurowano ustawienie diagnostyczne na oryginalnym serwerze, pamiętaj, aby, jeśli to konieczne, zrobić to samo na serwerze docelowym, zgodnie z opisem w Configure and Access Logs in Azure Database for PostgreSQL.
- Skonfiguruj alerty telemetryczne, musisz upewnić się, że istniejące ustawienia reguły alertu są aktualizowane w celu mapowania na nowy serwer. Aby uzyskać więcej informacji na temat reguł alertów, zobacz Konfigurowanie alertów dotyczących metryk dla usługi Azure Database for PostgreSQL przy użyciu witryny Azure Portal.
Ważne
Usunięte serwery można przywrócić. Jeśli usuniesz serwer, możesz postępować zgodnie z naszymi wskazówkami Przywracanie usuniętej bazy danych platformy Azure w celu odzyskania. Użyj blokady zasobów platformy Azure, aby zapobiec przypadkowemu usunięciu serwera.