Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Azure Table Storage to usługa, która przechowuje ustrukturyzowane dane NoSQL w chmurze. Zapewnia ona magazyn bez schematu, w którym każda jednostka jest uzyskiwana za pośrednictwem klucza i zawiera zestaw atrybutów. Pojedyncza tabela może zawierać jednostki, które mają różne zestawy właściwości, a właściwości mogą składać się z różnych typów danych.
W przypadku korzystania z platformy Azure niezawodność jest wspólną odpowiedzialnością. Firma Microsoft oferuje szereg możliwości wspierania odporności systemów i odzyskiwania. Odpowiadasz za zrozumienie, jak te możliwości działają w ramach wszystkich używanych usług oraz za wybór tych, które są potrzebne do osiągnięcia Twoich celów biznesowych i celów dotyczących niezawodności.
W tym artykule opisano, jak zapewnić odporność usługi Table Storage na różne potencjalne awarie i problemy, w tym przejściowe błędy, awarie strefy dostępności i awarie regionów. W tym artykule opisano również, jak można używać kopii zapasowych do odzyskiwania po innych typach problemów, oraz wyróżnia niektóre kluczowe informacje o umowie dotyczącej poziomu usług (SLA) usługi Table Storage.
Uwaga / Notatka
Usługa Table Storage jest częścią platformy Azure Storage. Niektóre możliwości usługi Table Storage są wspólne dla wielu usług Azure Storage. W tym artykule używamy usługi Azure Storage lub Storage do odwoływania się do tych typowych możliwości.
Zalecenia dotyczące wdrażania produkcyjnego pod kątem niezawodności
W przypadku środowisk produkcyjnych wykonaj następujące czynności:
Włącz strefowo-nadmiarowe magazynowanie (ZRS) dla kont magazynu zawierających zasoby Table Storage. Magazyn ZRS zapewnia wyższą dostępność, replikując dane synchronicznie w wielu strefach dostępności w regionie podstawowym. Ta replikacja chroni przed awariami strefy dostępności.
Jeśli potrzebujesz odporności na awarie regionów i region podstawowy konta magazynu jest sparowany, rozważ włączenie geograficznie nadmiarowego magazynu (GRS) w celu asynchronicznego replikowania danych do sparowanego regionu. W obsługiwanych regionach można połączyć nadmiarowość geograficzną z nadmiarowością strefy przy użyciu magazynu geograficznie nadmiarowego strefowo nadmiarowego (GZRS).
W przypadku obciążeń produkcyjnych o dużej skali lub jeśli masz wymagania dotyczące wysokiej odporności, rozważ użycie usługi Azure Cosmos DB dla tabeli. Usługa Azure Cosmos DB dla tabel jest zgodna z aplikacjami napisanymi dla usługi Table Storage. Zapewnia solidną globalną dystrybucję w wielu regionach, obsługując operacje odczytu i zapisu o małych opóźnieniach na dużą skalę z elastycznymi modelami spójności. Zapewnia również wbudowaną kopię zapasową i inne funkcje, które zwiększają odporność i wydajność aplikacji.
Omówienie architektury niezawodności
Usługa Table Storage działa jako rozproszona baza danych NoSQL w ramach infrastruktury platformy Azure Storage. Usługa zapewnia zapasowość przez wiele kopii danych tabeli, a konkretny model zapasowości zależy od konfiguracji konta magazynu danych.
Magazyn lokalnie nadmiarowy (LRS) replikuje dane w ramach kont magazynu do co najmniej jednej strefy dostępności platformy Azure znajdującej się w wybranym regionie podstawowym. Chociaż nie ma możliwości wyboru preferowanej strefy dostępności, platforma Azure może przenosić lub rozszerzać konta LRS między strefami, aby poprawić równoważenie obciążenia. Nie ma gwarancji, że dane będą rozłożone między strefy. Aby uzyskać więcej informacji na temat stref dostępności, zobacz Co to są strefy dostępności?.

Magazyn strefowo nadmiarowy (ZRS), magazyn geograficznie nadmiarowy (GRS) i magazyn geograficznie nadmiarowy (GZRS) zapewniają dodatkową ochronę. W tym artykule opisano szczegółowo te opcje.
Odporność na błędy przejściowe
Błędy przejściowe to krótkotrwałe, sporadyczne awarie w komponentach. Występują one często w środowisku rozproszonym, takich jak chmura, i są one normalną częścią operacji. Błędy przejściowe naprawiają się po krótkim czasie. Ważne jest, aby aplikacje mogły obsługiwać błędy przejściowe, zwykle ponawiając próby żądań, których dotyczy problem.
Wszystkie aplikacje hostowane w chmurze powinny postępować zgodnie ze wskazówkami dotyczącymi obsługi błędów przejściowych platformy Azure podczas komunikowania się z dowolnymi interfejsami API hostowanymi w chmurze, bazami danych i innymi składnikami. Aby uzyskać więcej informacji, zobacz Zalecenia dotyczące obsługi błędów przejściowych.
Biblioteki klienta usługi Table Storage i SDK zawierają wbudowane zasady ponawiania, które automatycznie obsługują typowe błędy przejściowe, takie jak przekroczenia limitu czasu sieci, tymczasowa niedostępność usługi (HTTP 503), odpowiedzi ograniczające (HTTP 429) i warunki przeciążenia serwera partycji. Gdy aplikacja doświadcza tych przejściowych warunków, biblioteki klienckie automatycznie ponawiają próby operacji przy użyciu strategii wycofywania wykładniczego.
Aby efektywnie zarządzać błędami przejściowymi podczas korzystania z usługi Table Storage, wykonaj następujące czynności:
Skonfiguruj odpowiednie limity czasu w kliencie usługi Table Storage, aby równoważyć czas reakcji z odpornością na tymczasowe spowolnienie. Domyślne limity czasu w bibliotekach klienckich usługi Azure Storage są zazwyczaj odpowiednie dla większości scenariuszy.
Zaimplementuj mechanizm wykładniczego zwiększania odstępów czasowych dla zasad ponawiania prób, zwłaszcza gdy aplikacja napotka błędy związane z zajętością serwera (HTTP 503) lub przekroczeniem limitu czasu operacji (HTTP 500). Usługa Table Storage może ograniczać żądania, gdy poszczególne partycje stają się przeciążone lub gdy limity konta magazynowego są blisko osiągnięcia.
Projektowanie logiki ponawiania prób z obsługą partycji w aplikacjach o dużej skali. Logika ponawiania prób z obsługą partycji to bardziej zaawansowane podejście, które uwzględnia architekturę partycjonowaną w usłudze Table Storage i dystrybuuje operacje na wielu partycjach, aby zmniejszyć prawdopodobieństwo wystąpienia ograniczania przepustowości na poszczególnych serwerach partycji.
Aby dowiedzieć się więcej na temat architektury usługi Table Storage i sposobu projektowania odpornych i wysokoskalowych aplikacji, zobacz Lista kontrolna wydajności i skalowalności dla usługi Table Storage.
Odporność na błędy strefy dostępności
Strefy dostępności są fizycznie oddzielnymi grupami centrów danych w regionie świadczenia usługi Azure. Gdy jedna strefa ulegnie awarii, usługi mogą przejść w tryb failover do jednej z pozostałych stref.
Usługa Table Storage jest strefowo nadmiarowa, gdy wdrażasz ją przy użyciu konfiguracji ZRS. W przeciwieństwie do magazynu lokalnie nadmiarowego (LRS), magazyn ZRS gwarantuje, że platforma Azure synchronicznie replikuje dane tabeli w wielu strefach dostępności. Ta konfiguracja gwarantuje, że tabele pozostaną dostępne, nawet jeśli cała strefa dostępności stanie się niedostępna. Wszystkie operacje zapisu muszą być potwierdzane w wielu strefach przed ukończeniem zapisu przez usługę, co zapewnia silne gwarancje spójności.
Nadmiarowość strefowa jest włączona na poziomie konta magazynu i ma zastosowanie do wszystkich zasobów Table Storage w ramach tego konta. Ponieważ to ustawienie dotyczy całego konta magazynu, nie można skonfigurować poszczególnych jednostek dla różnych poziomów nadmiarowości. Gdy strefa dostępności powoduje awarię, usługa Azure Storage automatycznie kieruje żądania do stref w dobrej kondycji bez konieczności interwencji użytkownika lub aplikacji.

Requirements
- Obsługa regionów: Konta usługi Azure Storage strefowo nadmiarowe można wdrażać w dowolnym regionie obsługującym strefy dostępności.
- Typy kont magazynu: Aby włączyć magazyn ZRS dla Table Storage, należy użyć konta magazynu ogólnego przeznaczenia w wersji 2 typu Standardowa. Konta usługi Premium Storage nie obsługują usługi Table Storage.
Koszt
Po włączeniu magazynu strefowo nadmiarowego (ZRS) opłaty są naliczane z innej stawki niż magazyn lokalnie nadmiarowy (LRS) ze względu na dodatkową replikację i obciążenie magazynu.
Aby uzyskać szczegółowe informacje o cenach, zobacz Cennik usługi Table Storage.
Konfiguruj obsługę stref dostępności
Utwórz strefowo nadmiarowe konto magazynowe i tabelę:
Utwórz konto magazynowe. Upewnij się, że jako opcję nadmiarowości wybrano magazyn geograficznie nadmiarowy ZRS, GZRS lub magazyn geograficznie nadmiarowy z dostępem do odczytu (RA-GZRS).
Zmień typ replikacji. Aby dowiedzieć się, jak zmienić istniejące konto magazynu na magazyn strefowo nadmiarowy (ZRS) oraz o opcjach konfiguracji i wymaganiach, zobacz Zmienianie sposobu replikacji konta magazynu.
Wyłącz strefową nadmiarowość. Przekonwertuj konta magazynu ZRS z powrotem na konfigurację niezonową, taką jak magazyn lokalnie nadmiarowy (LRS), przy użyciu tego samego procesu zmiany konfiguracji nadmiarowości.
Zachowanie, gdy wszystkie strefy są w dobrej kondycji
W tej sekcji opisano, czego można oczekiwać, gdy konto usługi Table Storage jest skonfigurowane pod kątem nadmiarowości strefowej, a wszystkie strefy dostępności są w pełni operacyjne.
Routing ruchu między strefami: Usługa Azure Storage z magazynem strefowo nadmiarowym (ZRS) automatycznie dystrybuuje żądania między klastrami magazynu w wielu strefach dostępności. Dystrybucja ruchu jest niewidoczna dla aplikacji i nie wymaga konfiguracji po stronie klienta.
Replikacja danych między strefami: Wszystkie operacje zapisu w magazynach ZRS są replikowane synchronicznie we wszystkich strefach dostępności w regionie. Podczas przekazywania lub modyfikowania danych operacja nie jest uznawana za ukończoną, dopóki dane nie zostaną pomyślnie zreplikowane we wszystkich strefach dostępności. Ta synchroniczna replikacja zapewnia silną spójność i zero utraty danych podczas awarii strefy.
Zachowanie podczas awarii strefy
** Gdy strefa dostępności stanie się niedostępna, usługa Table Storage automatycznie obsługuje proces przełączenia awaryjnego, wykonując następujące działania:
- Wykrywanie i reagowanie: Firma Microsoft automatycznie wykrywa błędy strefy i inicjuje procesy odzyskiwania. Dla kont magazynu nadmiarowego na poziomie stref (ZRS) nie jest wymagana żadna akcja ze strony klienta. Jeśli jakaś strefa stanie się niedostępna, platforma Azure przeprowadza aktualizacje sieci, takie jak przeadresowywanie w systemie nazw domen (DNS).
- Powiadomienie: firma Microsoft nie powiadamia cię automatycznie, gdy strefa nie działa. Możesz jednak użyć usługi Azure Resource Health do monitorowania kondycji pojedynczego zasobu i skonfigurować alerty usługi Resource Health w celu powiadamiania o problemach. Możesz również użyć usługi Azure Service Health , aby zrozumieć ogólną kondycję usługi, w tym wszelkie błędy strefy, i skonfigurować alerty usługi Service Health w celu powiadamiania o problemach.
Aktywne żądania: Żądania w locie mogą zostać porzucone podczas procesu odzyskiwania i należy je ponowić. Aplikacje powinny implementować logikę ponawiania prób w celu obsługi tych tymczasowych przerw.
Oczekiwana utrata danych: Brak utraty danych podczas awarii strefy, ponieważ dane są synchronicznie replikowane w wielu strefach przed zakończeniem operacji zapisu.
Oczekiwany przestój: Niewielka ilość przestojów, zazwyczaj kilka sekund, może wystąpić podczas automatycznego odzyskiwania, ponieważ ruch jest przekierowywany do stref w dobrej kondycji. Podczas projektowania aplikacji dla magazynu ZRS postępuj zgodnie z rozwiązaniami dotyczącymi obsługi błędów przejściowych, w tym implementowania zasad ponawiania z wycofywaniem wykładniczym.
- Przekierowywanie ruchu: Jeśli strefa stanie się niedostępna, platforma Azure podejmuje aktualizacje sieciowe, takie jak repointing systemu nazw domen (DNS), aby żądania były kierowane do pozostałych funkcjonujących stref dostępności. Usługa utrzymuje pełną funkcjonalność przy użyciu zdrowych obszarów i nie wymaga interwencji klienta.
Odzyskiwanie strefy
Gdy strefa dostępności zostanie przywrócona, usługa Azure Storage automatycznie przywraca normalne operacje we wszystkich strefach dostępności. Usługa automatycznie zapewnia spójność danych, synchronizując wszystkie operacje, które wystąpiły w okresie awarii.
Testowanie pod kątem niepowodzeń strefy
W przypadku korzystania z magazynu strefowo nadmiarowego (ZRS) usługa Azure Storage automatycznie zarządza replikacją, routingiem ruchu i odpowiedziami strefowymi. Ponieważ ta funkcja jest w pełni zarządzana, nie trzeba inicjować ani weryfikować procesów awarii strefy dostępności.
Odporność na awarie całego regionu
Usługa Azure Storage, w tym Azure Blob Storage, Azure Files, Azure Table Storage i Azure Queue Storage, udostępnia szereg funkcji nadmiarowości geograficznej i trybu failover, które spełniają różne wymagania.
Ważne
Magazyn geograficznie nadmiarowy (GRS) działa tylko w sparowanych regionach platformy Azure. Jeśli region konta magazynu nie jest sparowany, rozważ użycie niestandardowych rozwiązań z wieloma regionami w celu zapewnienia odporności.
Przechowywanie geo-nadmiarowe dla sparowanych regionów
Usługa Azure Storage udostępnia kilka typów grs w sparowanych regionach. Niezależnie od używanego typu magazynu GRS dane w regionie pomocniczym są zawsze replikowane przy użyciu magazynu lokalnie nadmiarowego (LRS). Takie podejście zapewnia ochronę przed awariami sprzętu w regionie pomocniczym.
Magazyn GRS zapewnia obsługę planowanych i nieplanowanych przełączeń w tryb failover do sparowanego regionu platformy Azure w przypadku awarii w regionie podstawowym. Replika GRS asynchronicznie replikuje dane z regionu podstawowego do sparowanego regionu.
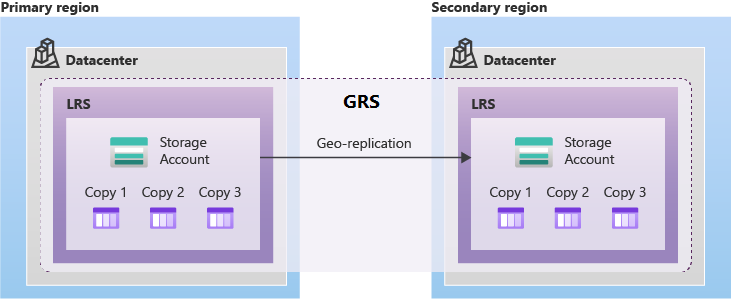
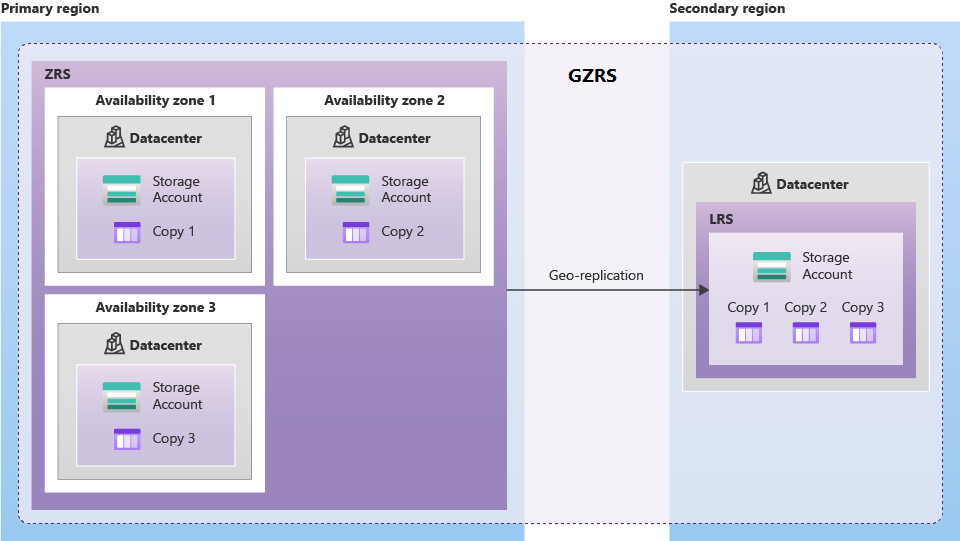
Magazyn geograficznie nadmiarowy (GZRS) replikuje dane w wielu strefach dostępności w regionie podstawowym i w sparowanym regionie.


- Magazyn geograficznie nadmiarowy dostępny do odczytu (RA-GRS) i magazyn geograficznie nadmiarowy z dostępem do odczytu (RA-GZRS) rozszerza magazyn geograficznie nadmiarowy (GRS) i magazyn geograficznie nadmiarowy (GZRS) z dodatkową korzyścią dostępu do odczytu do pomocniczego punktu końcowego. Te opcje są idealne dla aplikacji zaprojektowanych pod kątem wysokiej dostępności aplikacji krytycznych dla działania firmy. W mało prawdopodobnym przypadku awarii podstawowego punktu końcowego aplikacje skonfigurowane pod kątem dostępu do odczytu do regionu pomocniczego mogą nadal działać.
Typy przełączania awaryjnego
Usługa Azure Storage obsługuje trzy typy trybu failover w różnych scenariuszach.
Nieplanowana praca w trybie failover zarządzana przez klienta: Odpowiadasz za inicjowanie odzyskiwania, jeśli w regionie podstawowym wystąpi awaria magazynu w całym regionie.
Planowane przełączenie awaryjne zarządzane przez klienta: Jesteś odpowiedzialny za inicjowanie procesu odzyskiwania, jeśli inna część twojego rozwiązania ulegnie awarii w regionie podstawowym. Musisz wtedy przełączyć całe rozwiązanie do regionu pomocniczego. Użyj planowanego przełączenia awaryjnego, gdy magazyn danych pozostaje operacyjny w regionie podstawowym, ale musisz przenieść całe rozwiązanie do regionu pomocniczego, na przykład podczas ćwiczeń odzyskiwania danych po awarii mających na celu zapewnienie zgodności z wymaganiami audytu i inspekcji.
Tryb failover zarządzany przez firmę Microsoft: W wyjątkowych okolicznościach firma Microsoft może zainicjować tryb failover dla wszystkich kont magazynu geograficznie nadmiarowego (GRS) w regionie. Jednak tryb failover zarządzany przez firmę Microsoft jest ostatecznością i powinien być wykonywany tylko po dłuższym okresie awarii. Nie należy polegać na zarządzanym przez Microsoft mechanizmie awaryjnego przełączania.
Konta GRS mogą używać dowolnego z tych typów trybu failover. Nie musisz wstępnie konfigurować konta magazynowego, aby z wyprzedzeniem korzystać z dowolnego typu przełączania awaryjnego.
Requirements
Obsługa regionów: Konfiguracje geograficznie nadmiarowe usługi Azure Storage używają sparowanych regionów platformy Azure na potrzeby replikacji regionów pomocniczych. Region pomocniczy jest automatycznie określany na podstawie wybranego regionu podstawowego i nie można go dostosować. Pełną listę sparowanych regionów platformy Azure można znaleźć na liście regionów platformy Azure.
Jeśli region konta magazynu nie jest sparowany, rozważ użycie niestandardowych rozwiązań z wieloma regionami w celu zapewnienia odporności.
- Typy kont magazynu: Geograficznie nadmiarowa pamięć masowa (GRS) i inicjowane przez klienta przełączenie awaryjne oraz powrót po awarii są dostępne we wszystkich sparowanych regionach platformy Azure, które obsługują konta typu Azure Storage ogólnego przeznaczenia w wersji 2.
Rozważania
Podczas implementowania usługi Table Storage w wielu regionach należy wziąć pod uwagę następujące ważne czynniki:
Opóźnienie replikacji asynchronicznej: Replikacja danych do regionu pomocniczego jest asynchroniczna, co oznacza, że występuje opóźnienie między tym, kiedy dane są zapisywane w regionie podstawowym i gdy staną się dostępne w regionie pomocniczym. To opóźnienie może spowodować potencjalną utratę danych, jeśli wystąpi awaria regionu podstawowego przed zreplikowanie ostatnich danych. Utrata danych jest mierzona przez cel punktu odzyskiwania (RPO). Opóźnienie replikacji może być mniejsze niż 15 minut, ale tym razem jest szacowane i nie jest gwarantowane.
Możesz sprawdzić właściwość Czas ostatniej synchronizacji , aby dowiedzieć się, ile danych może zostać utraconych, jeśli konto magazynu ma nieplanowany tryb failover.
Dostęp do regionu pomocniczego: W przypadku konfiguracji magazynu geograficznie nadmiarowego (GRS) i magazynu geograficznie nadmiarowego (GZRS) region pomocniczy nie jest dostępny do odczytu do czasu przejścia w tryb failover.
Konfiguracje magazynu geograficznie nadmiarowego z dostępem do odczytu (RA-GRS) i magazynu geograficznie nadmiarowego z dostępem do odczytu (RA-GZRS) zapewniają dostęp do odczytu do regionu pomocniczego podczas normalnych operacji, ale ze względu na opóźnienie replikacji asynchronicznej mogą zwracać nieco nieaktualne dane.
- Ograniczenia funkcji: Niektóre funkcje usługi Azure Storage nie są obsługiwane lub mają ograniczenia dotyczące korzystania z magazynu geograficznie nadmiarowego (GRS) ani trybu failover zarządzanego przez klienta. Przed wdrożeniem nadmiarowości geograficznej przejrzyj zgodność funkcji .
Koszt
Konfiguracje konta usługi Azure Storage w wielu regionach generują dodatkowe koszty replikacji między regionami i magazynu w regionie pomocniczym. Opłaty za transfer danych między regionami platformy Azure są naliczane na podstawie standardowych stawek przepustowości między regionami.
Aby uzyskać szczegółowe informacje o cenach, zobacz Cennik usługi Table Storage.
Konfigurowanie obsługi wielu regionów
- Utwórz nowe konto magazynu geograficznie nadmiarowego (GRS). Aby utworzyć konto GRS, zobacz Tworzenie konta magazynu i wybieranie magazynu GRS, magazyn geograficznie nadmiarowy dostępny do odczytu (RA-GRS), magazyn geograficznie nadmiarowy strefowo nadmiarowy (GZRS) lub magazyn geograficznie nadmiarowy dostępny do odczytu (RA-GZRS) podczas tworzenia konta.
Włącz nadmiarowość geograficzną na istniejącym koncie magazynu. Aby przekonwertować istniejące konto magazynu na magazyn geograficznie nadmiarowy (GRS), zobacz Zmienianie sposobu replikacji konta magazynu.
Ostrzeżenie
Po ponownym skonfigurowaniu konta na potrzeby nadmiarowości geograficznej może upłynąć dużo czasu, zanim istniejące dane w nowym regionie podstawowym będą w pełni kopiowane do nowego regionu pomocniczego.
Aby uniknąć poważnej utraty danych, sprawdź wartość właściwości Czas ostatniej synchronizacji przed zainicjowaniem nieplanowanego trybu failover. Aby ocenić potencjalną utratę danych, porównaj czas ostatniej synchronizacji z ostatnim zapisem danych w nowym regionie podstawowym.
Wyłącz nadmiarowość geograficzną. Przekonwertuj konta GRS z powrotem na konfiguracje z jednym regionem, takie jak magazyn lokalnie nadmiarowy (LRS) lub magazyn strefowo nadmiarowy (ZRS), korzystając z tego samego procesu zmiany konfiguracji nadmiarowości.
Zachowanie, gdy wszystkie regiony są w dobrej kondycji
W tej sekcji opisano, czego można oczekiwać, gdy konto magazynu jest skonfigurowane na potrzeby nadmiarowości geograficznej, a wszystkie regiony działają.
Routing ruchu między regionami: Usługa Azure Storage używa podejścia aktywnego pasywnego, w którym wszystkie operacje zapisu i większość operacji odczytu są kierowane do regionu podstawowego.
W przypadku konfiguracji magazynu geograficznie nadmiarowego dostępnego do odczytu (RA-GRS) i magazynu geograficznie nadmiarowego z dostępem do odczytu (RA-GZRS) aplikacje mogą opcjonalnie odczytywać z regionu pomocniczego, korzystając z pomocniczego punktu końcowego. Takie podejście wymaga jawnej konfiguracji aplikacji i nie jest automatyczne. Ponadto ze względu na opóźnienie replikacji asynchronicznej dane w regionie pomocniczym mogą być nieco nieaktualne.
Replikacja danych między regionami: Operacje zapisu są najpierw zatwierdzane w regionie podstawowym przy użyciu następujących skonfigurowanych typów nadmiarowości:
- Magazyn lokalnie nadmiarowy (LRS) dla magazynu geograficznie nadmiarowego (GRS) i RA-GRS
- Magazyn strefowo nadmiarowy (ZRS) dla magazynu geograficznie nadmiarowego (GZRS) i RA-GZRS
Po pomyślnym zakończeniu w regionie podstawowym dane są asynchronicznie replikowane do regionu pomocniczego, w którym są przechowywane przy użyciu magazynu LRS.
Asynchroniczny charakter replikacji między regionami oznacza, że zazwyczaj występuje opóźnienie między czasem zapisywania danych w regionie podstawowym a dostępnością w regionie pomocniczym. Czas replikacji można monitorować przy użyciu właściwości Czas ostatniej synchronizacji.
Zachowanie podczas awarii regionu
W tej sekcji opisano, czego oczekiwać po skonfigurowaniu konta magazynowego dla nadmiarowości geograficznej w przypadku awarii w regionie podstawowym.
Tryb failover zarządzany przez klienta (nieplanowany): Użyj nieplanowanego trybu failover, gdy magazyn w regionie podstawowym jest niedostępny.
Wykrywanie i reagowanie: W mało prawdopodobnym przypadku niedostępności konta magazynu w regionie podstawowym można rozważyć zainicjowanie nieplanowanego trybu failover zarządzanego przez klienta. Aby podjąć tę decyzję, należy wziąć pod uwagę następujące czynniki:
Czy usługa Azure Resource Health pokazuje problemy z uzyskiwaniem dostępu do konta magazynu w regionie podstawowym
Czy firma Microsoft zaleca przeprowadzenie przejścia w tryb failover do innego regionu
Ostrzeżenie
Nieplanowane przejście w tryb failover może spowodować utratę danych. Przed zainicjowaniem trybu failover zarządzanego przez klienta zdecyduj, czy przywrócenie usługi uzasadnia ryzyko utraty danych.
Powiadomienie: firma Microsoft nie powiadamia cię automatycznie, gdy region nie działa. Jednak:
Za pomocą usługi Azure Resource Health można monitorować kondycję pojedynczego zasobu i skonfigurować alerty usługi Resource Health w celu powiadamiania o problemach.
Możesz użyć usługi Azure Service Health , aby zrozumieć ogólną kondycję usługi, w tym wszelkie błędy regionów, i skonfigurować alerty usługi Service Health w celu powiadamiania o problemach.
Aktywne żądania: Podczas procesu failover punkty końcowe konta przechowywania podstawowego i pomocniczego stają się tymczasowo niedostępne dla operacji zarówno odczytu, jak i zapisu. Wszystkie aktywne żądania mogą zostać porzucone, a aplikacje klienckie muszą ponowić próbę po zakończeniu pracy w trybie failover.
Oczekiwana utrata danych: Utrata danych jest powszechna podczas nieplanowanego trybu failover z powodu opóźnienia replikacji asynchronicznej, co oznacza, że ostatnie zapisy mogą nie być replikowane. Możesz sprawdzić właściwość Czas ostatniej synchronizacji , aby dowiedzieć się, ile danych może zostać utraconych podczas nieplanowanego przejścia w tryb failover. Oczekiwana utrata danych jest często określana jako cel punktu odzyskiwania (RPO). Zazwyczaj można oczekiwać, że RPO będzie poniżej 15 minut, ale ten czas nie jest gwarantowany.
Oczekiwany przestój: Oczekiwany przestój jest często określany jako cel czasu odzyskiwania (RTO). Proces failover zarządzany przez klienta zazwyczaj kończy się w ciągu 60 minut, w zależności od wielkości konta i stopnia złożoności.
Przekierowywanie ruchu: Po zakończeniu pracy w trybie failover platforma Azure automatycznie aktualizuje punkty końcowe konta magazynu, aby aplikacje nie musiały być ponownie skonfigurowane. Jeśli aplikacja przechowuje buforowane wpisy systemu nazw domen (DNS), może być konieczne wyczyszczenie pamięci podręcznej w celu zapewnienia, że aplikacja wysyła ruch do nowego regionu podstawowego.
Konfiguracja po przejściu w tryb failover: Po zakończeniu nieplanowanego przejścia w tryb failover konto magazynu w regionie docelowym używa warstwy magazynu lokalnie nadmiarowego (LRS). Jeśli musisz ponownie replikować geograficznie, musisz ponownie włączyć magazyn geograficznie nadmiarowy (GRS) i poczekać, aż dane zostaną zreplikowane do nowego regionu pomocniczego.
Aby uzyskać więcej informacji na temat inicjowania trybu failover zarządzanego przez klienta, zobacz Jak działa tryb failover zarządzany przez klienta (nieplanowany) i Inicjowanie trybu failover konta magazynu.
Tryb failover zarządzany przez klienta (planowany): Użyj planowanego trybu failover, gdy magazyn pozostaje operacyjny w regionie podstawowym, ale z innego powodu musisz przejąć całe rozwiązanie w tryb failover w regionie pomocniczym. Na przykład inna usługa platformy Azure może mieć problem i musisz przełączyć się na korzystanie z regionu pomocniczego dla całego rozwiązania. Możesz też użyć planowanego przejścia w tryb failover do przeprowadzenia próbnego odzyskiwania po awarii na potrzeby zgodności i inspekcji.
Wykrywanie i reagowanie: Odpowiadasz za podjęcie decyzji o przejściu w tryb failover. Zazwyczaj podejmujesz tę decyzję, jeśli konieczne jest przełączenie w tryb failover między regionami, nawet jeśli konto magazynu jest w dobrej kondycji. Na przykład możesz wyzwolić przełączenie awaryjne, gdy wystąpi poważna awaria innego składnika aplikacji, której nie można naprawić w regionie podstawowym.
Powiadomienie: firma Microsoft nie powiadamia cię automatycznie, gdy region nie działa. Jednak:
Za pomocą usługi Azure Resource Health można monitorować kondycję pojedynczego zasobu i skonfigurować alerty usługi Resource Health w celu powiadamiania o problemach.
Możesz użyć usługi Azure Service Health , aby zrozumieć ogólną kondycję usługi, w tym wszelkie błędy regionów, i skonfigurować alerty usługi Service Health w celu powiadamiania o problemach.
Aktywne żądania: Podczas procesu failover punkty końcowe konta przechowywania podstawowego i pomocniczego stają się tymczasowo niedostępne dla operacji zarówno odczytu, jak i zapisu. Wszystkie aktywne żądania mogą zostać porzucone, a aplikacje klienckie muszą ponowić próbę po zakończeniu pracy w trybie failover.
Oczekiwana utrata danych: Utraty danych nie należy się spodziewać, ponieważ proces failover kończy się dopiero po zsynchronizowaniu wszystkich danych, co daje wskaźnik RPO równy zero.
Oczekiwany przestój: Proces failover zwykle trwa do 60 minut, co oznacza, że oczekiwany czas odzyskiwania również wynosi 60 minut, w zależności od rozmiaru konta i złożoności. Podczas procesu trybu failover punkty końcowe konta magazynu podstawowego i pomocniczego stają się tymczasowo niedostępne zarówno dla operacji odczytu, jak i zapisu.
Przekierowywanie ruchu: Po zakończeniu pracy w trybie failover platforma Azure automatycznie aktualizuje punkty końcowe konta magazynu, aby aplikacje nie musiały być ponownie skonfigurowane. Jeśli aplikacja przechowuje wpisy DNS w pamięci podręcznej, może być konieczne wyczyszczenie pamięci podręcznej w celu zapewnienia, że aplikacja wysyła ruch do nowego regionu podstawowego.
Konfiguracja po przejściu w tryb failover: Po zakończeniu planowanego przejścia w tryb failover konto magazynu w regionie docelowym będzie nadal replikowane geograficznie i pozostaje w warstwie GRS.
Aby uzyskać więcej informacji na temat inicjowania trybu failover zarządzanego przez klienta, zobacz Jak działa tryb failover zarządzany przez klienta (planowany) i Inicjowanie trybu failover konta magazynu.
Tryb failover zarządzany przez firmę Microsoft: W rzadkim przypadku poważnej awarii, w której firma Microsoft ustali, że region podstawowy jest trwale nieodwracalny, może zostać zainicjowane automatyczne przejście w tryb failover do regionu pomocniczego. Firma Microsoft obsługuje cały proces i nie jest wymagana żadna akcja klienta. Czas, który upłynął przed przejściem w tryb failover, zależy od ważności awarii i czasu wymaganego do oceny sytuacji.
Powiadomienie: firma Microsoft nie powiadamia cię automatycznie, gdy region nie działa. Jednak:
Za pomocą usługi Azure Resource Health można monitorować kondycję pojedynczego zasobu i skonfigurować alerty usługi Resource Health w celu powiadamiania o problemach.
Możesz użyć usługi Azure Service Health , aby zrozumieć ogólną kondycję usługi, w tym wszelkie błędy regionów, i skonfigurować alerty usługi Service Health w celu powiadamiania o problemach.
Ważne
Użyj opcji failover zarządzanej przez klienta, aby opracowywać, testować i implementować plany odzyskiwania po awarii. Nie należy polegać na trybie failover zarządzanym przez firmę Microsoft, który może być używany tylko w ekstremalnych okolicznościach. Tryb failover zarządzany przez firmę Microsoft prawdopodobnie jest inicjowany dla całego regionu. Nie można go zainicjować dla poszczególnych kont przechowywania, subskrypcji ani klientów. Przełączenie awaryjne może wystąpić w różnym czasie dla różnych usług Azure. Zalecamy korzystanie z trybu failover zarządzanego przez klienta.
Odzyskiwanie regionów
Proces powrotu po awarii różni się znacznie między scenariuszami trybu failover zarządzanymi przez firmę Microsoft i zarządzanymi przez klienta.
Tryb failover zarządzany przez klienta (nieplanowany): Po nieplanowanym przejściu w tryb failover konto magazynu jest skonfigurowane z magazynem lokalnie nadmiarowym (LRS). Aby powrócić po awarii, należy ponownie ustanowić relację magazynu geograficznie nadmiarowego (GRS) i poczekać na replikowanie danych.
Tryb failover zarządzany przez klienta (planowany): Po zaplanowanym przejściu w tryb failover konto magazynu pozostaje replikowane geograficznie. Możesz zainicjować inny tryb failover zarządzany przez klienta, aby powrócić po awarii do oryginalnego regionu podstawowego. Mają zastosowanie te same zagadnienia dotyczące trybu failover.
Tryb failover zarządzany przez firmę Microsoft: Jeśli firma Microsoft inicjuje tryb failover, prawdopodobnie wystąpi znaczna awaria w regionie podstawowym, a region podstawowy może nie być możliwy do odzyskania. Wszelkie harmonogramy lub plany odzyskiwania zależą od zakresu regionalnych działań związanych z awarią i odzyskiwaniem. Aby uzyskać szczegółowe informacje, należy monitorować komunikację usługi Azure Service Health.
Testowanie pod kątem błędów regionów
Możesz symulować regionalne błędy w celu przetestowania procedur odzyskiwania po awarii.
Planowane testowanie trybu failover: W przypadku kont magazynu geograficznie nadmiarowego (GRS) można wykonać zaplanowane operacje pracy w trybie failover podczas okien konserwacji, aby przetestować kompletny proces pracy w trybie failover i powrotu po awarii. Planowane przejście w tryb failover nie wymaga utraty danych, ale wiąże się z przestojami podczas przechodzenia w tryb failover i powrotu po awarii.
Dodatkowe testowanie punktów końcowych: W przypadku konfiguracji magazynu geograficznie nadmiarowego dostępnego do odczytu (RA-GRS) i magazynu geograficznie nadmiarowego z dostępem do odczytu (RA-GZRS) regularnie testuje operacje odczytu względem pomocniczego punktu końcowego, aby upewnić się, że aplikacja może pomyślnie odczytywać dane z regionu pomocniczego.
Niestandardowe rozwiązania obejmujące wiele regionów w celu zapewnienia odporności
Możliwości trybu failover między regionami usługi Azure Storage mogą być nieodpowiednie z następujących powodów:
Twoje konto magazynu znajduje się w regionie niepowiązanym.
Cele czasu pracy firmy nie są spełnione przez czas odzyskiwania lub utratę danych, które zapewniają wbudowane opcje trybu failover.
Musisz przejść w tryb failover do regionu, który nie jest parą regionu podstawowego.
Potrzebna jest aktywna/aktywna konfiguracja w różnych regionach.
Ta sekcja zawiera ogólne omówienie niektórych podejść do rozważenia. Kompleksowy przegląd topologii wdrażania w wielu regionach dla usługi Azure Storage wykracza poza zakres tego artykułu.
Uwaga / Notatka
W przypadku aplikacji utworzonych do korzystania z usługi Table Storage rozważ użycie usługi Azure Cosmos DB dla tabel. Usługa Azure Cosmos DB dla tabel obsługuje zaawansowane wymagania dotyczące wielu regionów, w tym obsługę regionów niepairowanych. Jest ona również zaprojektowana pod kątem zgodności z aplikacjami utworzonymi dla usługi Table Storage.
Usługę Azure Storage można wdrożyć w wielu regionach przy użyciu oddzielnych kont magazynu w każdym regionie. Takie podejście zapewnia elastyczność wyboru regionów, możliwość korzystania z niepairowanych regionów i bardziej szczegółową kontrolę nad czasem replikacji i spójnością danych. Podczas implementowania wielu kont magazynu w różnych regionach należy skonfigurować replikację danych między regionami, zaimplementować zasady równoważenia obciążenia i trybu failover oraz zapewnić spójność danych w różnych regionach.
W przypadku usługi Table Storage podejście obejmujące wiele kont wymaga zarządzania dystrybucją danych, obsługi synchronizacji między tabelami między regionami, w tym rozwiązywania konfliktów i implementowania niestandardowej logiki trybu failover.
Tworzenie kopii zapasowej i przywracanie
Usługa Table Storage nie zapewnia tradycyjnych funkcji tworzenia kopii zapasowych, takich jak przywracanie do punktu w czasie (PITR). Można jednak zaimplementować niestandardowe strategie tworzenia kopii zapasowych dla danych tabeli.
Jeśli potrzebujesz wbudowanych funkcji tworzenia kopii zapasowych, rozważ przejście do usługi Azure Cosmos DB dla tabeli, która zapewnia obsługę okresowych i ciągłych kopii zapasowych. Aby uzyskać więcej informacji, zobacz Online backup and on-demand data restore in Azure Cosmos DB (Tworzenie kopii zapasowych online i przywracanie danych na żądanie w usłudze Azure Cosmos DB).
W przypadku scenariuszy wymagających tworzenia kopii zapasowej danych z usługi Table Storage należy wziąć pod uwagę następujące podejścia:
Eksportowanie przy użyciu usługi Azure Data Factory. Użyj łącznika usługi Azure Data Factory dla usługi Table Storage , aby wyeksportować jednostki do innej lokalizacji. Można na przykład utworzyć kopię zapasową każdej jednostki w pliku JSON przechowywanym w usłudze Azure Blob Storage.
Wykonaj kopię zapasową na poziomie aplikacji. Zaimplementuj niestandardową logikę tworzenia kopii zapasowych w aplikacjach, aby wyeksportować krytyczne jednostki tabeli do innych usług magazynu, takich jak Azure SQL Database lub Azure Cosmos DB, w celu uzyskania bardziej niezawodnych możliwości tworzenia kopii zapasowych i przywracania.
Podczas projektowania strategii tworzenia kopii zapasowych dla usługi Table Storage należy wziąć pod uwagę partycjonowany charakter danych i upewnić się, że procesy tworzenia kopii zapasowych mogą wydajnie obsługiwać duże tabele, przetwarzając wiele partycji równolegle.
W przypadku większości rozwiązań nie należy polegać wyłącznie na kopiach zapasowych. Zamiast tego skorzystaj z innych możliwości opisanych w tym przewodniku, aby spełnić wymagania dotyczące odporności. Jednak kopie zapasowe chronią przed pewnymi zagrożeniami, których nie zapewniają inne podejścia. Aby uzyskać więcej informacji, zobacz Co to jest nadmiarowość, replikacja i kopia zapasowa?.
Umowa dotycząca poziomu usług
Umowa dotycząca poziomu usług (SLA) dla usługi Azure Storage opisuje oczekiwaną dostępność usługi oraz warunki, które muszą zostać spełnione, aby osiągnąć te oczekiwania dotyczące dostępności. Umowa SLA dotycząca dostępności, dla której kwalifikujesz się, zależy od warstwy magazynowania i używanego typu replikacji. Aby uzyskać więcej informacji, zobacz Umowy SLA dla usług online.
Treści powiązane
- Co to jest usługa Table Storage?
- Projektowanie skalowalnych i wydajnych tabel
- Nadmiarowość usługi Azure Storage
- Planowanie i przechodzenie w tryb failover w usłudze Azure Storage po awarii
- Lista kontrolna wydajności i skalowalności dla usługi Table Storage
- Niezawodność platformy Azure
- Zalecenia dotyczące obsługi błędów przejściowych