Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ten dokument obejmuje kilka różnych obszarów, które należy wziąć pod uwagę podczas wdrażania programu SQL Server dla obciążenia SAP w usłudze Azure IaaS. Jako warunek wstępny tego dokumentu zapoznaj się z dokumentem Zagadnienia dotyczące wdrażania systemu DBMS maszyn wirtualnych Azure dla obciążenia SAP oraz z innymi przewodnikami zawartymi w dokumentacji obciążenia SAP na platformie Azure.
Ważne
Zakresem tego dokumentu jest wersja systemu Windows w programie SQL Server. Oprogramowanie SAP nie obsługuje wersji programu SQL Server z systemem Linux z żadnym oprogramowaniem SAP. Dokument nie omawia usługi Microsoft Azure SQL Database, która jest ofertą platformy jako usługi (Platform as a Service, PaaS) Microsoft Azure. W tym dokumencie omówiono uruchamianie produktu SQL Server, ponieważ jest on znany z wdrożeń lokalnych w usłudze Azure Virtual Machines, wykorzystując możliwości infrastruktury jako usługi platformy Azure. Możliwości i funkcje bazy danych między tymi dwiema ofertami są różne i nie powinny być ze sobą mieszane. Aby uzyskać więcej informacji, zobacz Azure SQL Database.
Ogólnie rzecz biorąc, należy rozważyć użycie najnowszych wersji programu SQL Server do uruchamiania obciążenia SAP w usłudze Azure IaaS. Najnowsze wersje programu SQL Server oferują lepszą integrację z niektórymi usługami i funkcjami platformy Azure. Lub zmiany, które optymalizują operacje w infrastrukturze IaaS platformy Azure.
Ogólną dokumentację dotyczącą programu SQL Server uruchomionego w usłudze Azure Virtual Machines (VM) można znaleźć w następujących artykułach:
- Program SQL Server na maszynach wirtualnych platformy Azure (Windows)
- Automatyzowanie zarządzania za pomocą rozszerzenia agenta IaaS systemu Windows SQL Server
- Konfigurowanie integracji usługi Azure Key Vault dla programu SQL Server na maszynach wirtualnych platformy Azure (Resource Manager)
- Lista kontrolna: najlepsze rozwiązania dotyczące programu SQL Server na maszynach wirtualnych platformy Azure
- Storage: najlepsze rozwiązania dotyczące wydajności programu SQL Server na maszynach wirtualnych platformy Azure
- Najlepsze praktyki dotyczące konfiguracji wysokiej dostępności i odzyskiwania po awarii (SQL Server na maszynach wirtualnych na platformie Azure)
Nie cała zawartość i stwierdzenia zawarte w ogólnej dokumentacji SQL Server na maszynach wirtualnych platformy Azure mają zastosowanie do obciążenia SAP. Jednak dokumentacja dobrze przedstawia zasady. Przykładem funkcjonalności, które nie są obsługiwane w przypadku obciążenia SAP, jest użycie klastrowania FCI.
Przed kontynuowaniem należy znać niektóre informacje specyficzne dla programu SQL Server w usłudze IaaS:
- Obsługa wersji programu SQL: nawet w przypadku programu SAP Note #1928533 stwierdzającego, że minimalna obsługiwana wersja programu SQL Server to SQL Server 2008 R2, okno obsługiwanych wersji programu SQL Server na platformie Azure jest również dyktowane cyklem życia programu SQL Server. Rozszerzona konserwacja programu SQL Server 2012 zakończyła się w połowie 2022 r. W związku z tym bieżąca minimalna wersja dla nowo wdrożonych systemów powinna być programem SQL Server 2014. Tym częściej, tym lepiej. Najnowsze wersje programu SQL Server oferują lepszą integrację z niektórymi usługami i funkcjami platformy Azure. Lub zmiany, które optymalizują operacje w infrastrukturze IaaS platformy Azure.
- Używanie obrazów z witryny Azure Marketplace: najszybszym sposobem wdrożenia nowej maszyny wirtualnej platformy Microsoft Azure jest użycie obrazu z witryny Azure Marketplace. W witrynie Azure Marketplace znajdują się obrazy zawierające najnowsze wersje programu SQL Server. Obrazy, na których program SQL Server jest już zainstalowany, nie mogą być natychmiast używane dla aplikacji SAP NetWeaver. Przyczyną jest zainstalowanie domyślnego sortowania programu SQL Server na tych obrazach, a nie sortowania wymaganego dla systemów SAP NetWeaver. Aby użyć takich obrazów, zapoznaj się z krokami opisanymi w rozdziale Using a SQL Server image out of the Microsoft Azure Marketplace (Korzystanie z obrazu programu SQL Server z witryny Microsoft Azure Marketplace).
- Obsługa wielu wystąpień programu SQL Server na jednej maszynie wirtualnej platformy Azure: ta metoda wdrażania jest obsługiwana. Należy jednak pamiętać o ograniczeniach zasobów, szczególnie w przypadku sieci i przepustowości magazynu używanego typu maszyny wirtualnej. Szczegółowe informacje są dostępne w artykule Rozmiary maszyn wirtualnych na platformie Azure. Te ograniczenia dotyczące limitów przydziału mogą uniemożliwić zaimplementowanie tej samej architektury wieloinstancyjnej, jaką można zaimplementować na miejscu. W zależności od konfiguracji i interferencji udostępniania zasobów dostępnych na jednej maszynie wirtualnej należy wziąć pod uwagę te same kwestie, które należy wziąć pod uwagę w środowisku lokalnym.
- Wiele baz danych SAP w jednym wystąpieniu programu SQL Server na jednej maszynie wirtualnej: obsługiwane są takie konfiguracje. Zagadnienia dotyczące sytuacji, gdy wiele baz danych SAP współdzieli zasoby jednego wystąpienia serwera SQL, są takie same jak w przypadku wdrożeń lokalnych. Zachowaj inne limity, takie jak liczba dysków, które można dołączyć do określonego typu maszyny wirtualnej. Limity przydziału sieci i magazynu dla określonych typów maszyn wirtualnych, takie jak opisano w rozmiarach maszyn wirtualnych na platformie Azure.
Nowe maszyny wirtualne serii M i program SQL Server
Platforma Azure wydała kilka nowych rodzin SKU serii M podrodziny Mv3. Niektóre typy maszyn wirtualnych w tej rodzinie nie powinny być używane dla SQL Server, w tym SQL Server 2022 bez wyłączania funkcji SMT (Hyperthreading) w systemie operacyjnym gościa Windows Server. Przyczyną jest liczba węzłów NUMA przedstawionych w systemie operacyjnym gościa Windows Server, która przy liczbie procesorów wirtualnych większej niż 64 staje się zbyt duża, żeby SQL Server mógł je obsłużyć. Wyłączenie protokołu SMT w systemie operacyjnym gościa systemu Windows Server zmniejsza liczbę procesorów wirtualnych. Dlatego liczba procesorów wirtualnych jest mniejsza niż 64 w każdym węźle NUMA. Sposób wyłączenia technologii SMT został opisany tutaj. Określone typy maszyn wirtualnych to:
- M176(d)s_3_v3 — wyłącz protokół SMT lub użyj M176bds_4_v3 lub M176bds_4_v3 jako alternatywy
- M176(d)s_4_v3 - wyłącz SMT lub użyj M176bds_4_v3 jako alternatywy
- M624(d)s_12_v3 — wyłącz protokół SMT lub użyj M416ms_v2 jako alternatywy
- M832(d)s_12_v3 — wyłącz protokół SMT lub użyj M416ms_v2 jako alternatywy
- M832i(d)s_16_v3 — wyłącz funkcję SMT lub użyj M416ms_v2 jako alternatywy
Uwaga / Notatka
W przypadku niektórych nowych typów maszyn wirtualnych M(b)v3, korzystanie z magazynu SSD Premium v1 z pamięcią podręczną odczytu może skutkować mniejszą liczbą operacji IOPS i niższą przepustowością, niż w przypadku niekorzystania z pamięci podręcznej odczytu.
Zalecenia dotyczące struktury maszyny wirtualnej/wirtualnego dysku twardego dla wdrożeń programu SQL Server związanych z oprogramowaniem SAP
Zgodnie z ogólnym opisem, system operacyjny, pliki wykonywalne programu SQL Server oraz pliki wykonywalne SAP powinny znajdować się lub być instalowane na oddzielnych dyskach platformy Azure. Zazwyczaj większość systemowych baz danych programu SQL Server nie jest używana na wysokim poziomie z obciążeniem SAP NetWeaver. Niemniej jednak systemowe bazy danych programu SQL Server powinny być, wraz z innymi katalogami programu SQL Server na oddzielnym dysku platformy Azure. Baza danych tempdb programu SQL Server powinna znajdować się na nieperystryzowanej stacji D:\ lub na oddzielnym dysku.
- Ze wszystkimi certyfikowanymi typami maszyn wirtualnych SAP (zobacz SAP Note #1928533), dane bazy danych tempdb i pliki dziennika mogą być umieszczane na niepersyfikowanym dysku D:\.
- W przypadku wydań programu SQL Server, w których program SQL Server instaluje bazę danych tempdb tylko z jednym plikiem danych, zaleca się używanie wielu plików danych bazy danych tempdb. Należy pamiętać, że woluminy dysku D:\ różnią się rozmiarem i możliwościami na podstawie typu maszyny wirtualnej. Aby uzyskać dokładne rozmiary dysku D:\ różnych maszyn wirtualnych, zapoznaj się z artykułem Rozmiary maszyn wirtualnych z systemem Windows na platformie Azure.
Te konfiguracje umożliwiają bazie danych tempdb większe wykorzystanie miejsca oraz zwiększenie liczby operacji we/wy na sekundę (IOPS) i przepustowości magazynu niż dysk systemowy może zapewnić. Dysk D:\ niepersistentny oferuje również lepsze opóźnienie we/wy i przepływność. Aby określić odpowiedni rozmiar bazy danych tempdb, można sprawdzić rozmiary bazy danych tempdb w istniejących systemach.
Uwaga / Notatka
W przypadku umieszczenia plików danych bazy danych tempdb i pliku dziennika w folderze na utworzonym dysku D:\ należy upewnić się, że folder istnieje po ponownym uruchomieniu maszyny wirtualnej. Ponieważ dysk D:\ może być świeżo zainicjowany po ponownym uruchomieniu maszyny wirtualnej wszystkie struktury plików i katalogów mogą zostać wyczyszczone. Możliwość ponownego utworzenia ewentualnych struktur katalogów na dysku D:\ przed rozpoczęciem usługi SQL Server jest udokumentowana w tym artykule.
Konfiguracja maszyny wirtualnej, która uruchamia program SQL Server z bazą danych SAP i gdzie dane bazy danych tempdb i plik dziennika bazy danych tempdb są umieszczane na dysku D:\ i w usłudze Azure Premium Storage w wersji 1 lub 2 wygląda następująco:
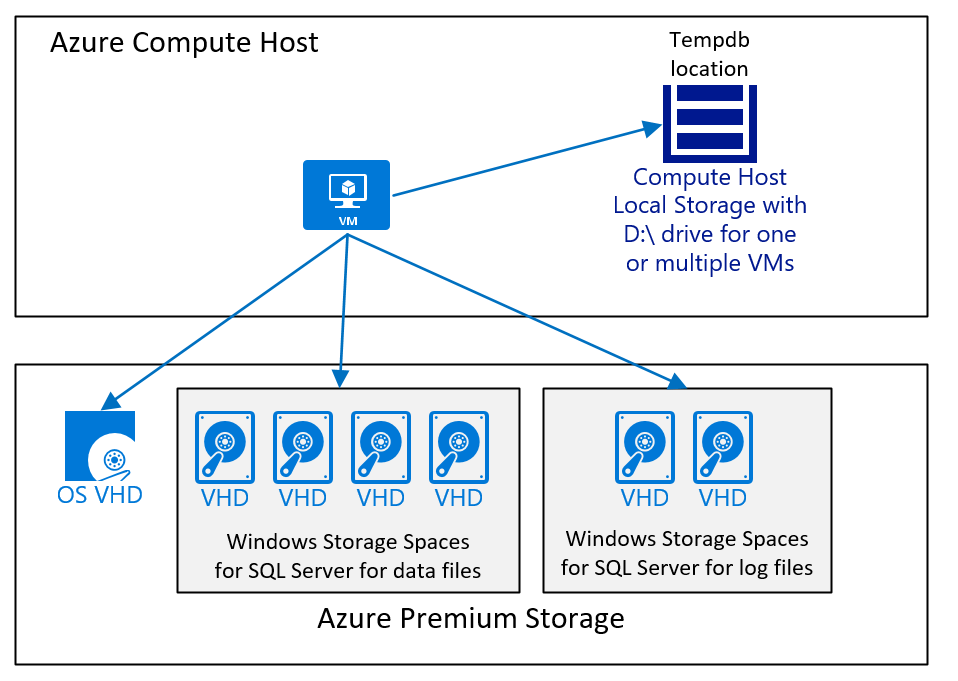
Diagram przedstawia prosty przypadek. Jak wyjaśniono w artykule Considerations for Azure Virtual Machines DBMS deployment for SAP workload, typ, liczba i rozmiar dysków w usłudze Azure Storage są zależne od różnych czynników. Ogólnie jednak zalecamy:
- W przypadku wdrożeń mniejszych i średnich zakresów należy użyć jednego dużego woluminu zawierającego pliki danych programu SQL Server. Przyczyną tej konfiguracji jest to, że łatwiej jest radzić sobie z różnymi obciążeniami we/wy, jeśli pliki danych programu SQL Server nie mają tego samego wolnego miejsca. Podczas dużych wdrożeń, zwłaszcza wdrożeń, w których klient przeprowadził się z heterogeniczną migracją bazy danych do programu SQL Server na platformie Azure, użyliśmy oddzielnych dysków, a następnie rozpowszechniliśmy pliki danych na tych dyskach. Taka architektura kończy się powodzeniem tylko wtedy, gdy każdy dysk ma taką samą liczbę plików danych, wszystkie pliki danych mają ten sam rozmiar i mają mniej więcej takie samo wolne miejsce.
- Użyj dysku D:\drive dla bazy danych tempdb, o ile wydajność jest wystarczająco dobra. Jeśli ogólne obciążenie jest ograniczone w wydajności bazy danych tempdb znajdującej się na dysku D:\, musisz przenieść bazę danych tempdb do usługi Azure Premium Storage w wersji 1 lub 2 lub ultra, zgodnie z zaleceniami w tym artykule.
Mechanizm wypełniania proporcjonalnego programu SQL Server rozprowadza odczyty i zapisy do wszystkich plików danych równomiernie, pod warunkiem że wszystkie pliki danych programu SQL Server mają taki sam rozmiar i mają tyle samo wolnego miejsca. Oprogramowanie SAP w programie SQL Server zapewnia najlepszą wydajność, gdy odczyty i zapisy są dystrybuowane równomiernie we wszystkich dostępnych plikach danych. Jeśli baza danych ma zbyt mało plików danych lub istniejące pliki danych są wysoce niezrównoważone, najlepszą metodą poprawienia jest eksportowanie i importowanie R3load. Eksportowanie i importowanie ładunku R3 obejmuje przestój i należy to zrobić tylko wtedy, gdy wystąpi oczywisty problem z wydajnością, który należy rozwiązać. Jeśli pliki danych mają tylko umiarkowanie różne rozmiary, zwiększ wszystkie pliki danych do tego samego rozmiaru, a program SQL Server z czasem ponownie zrówna dane. Program SQL Server automatycznie zwiększa pliki danych, nawet jeśli flaga śledzenia 1117 jest ustawiona lub jeśli program SQL Server 2016 lub nowszy jest używany bez flagi śledzenia.
Specjalne dla maszyn wirtualnych serii M
W przypadku maszyny wirtualnej z serii Azure M opóźnienie zapisu w dzienniku transakcji można zmniejszyć w porównaniu z wydajnością usługi Azure Premium Storage w wersji 1 podczas korzystania z akceleratora zapisu platformy Azure. Jeśli opóźnienie w magazynie Premium Storage v1 ogranicza skalowalność obciążenia SAP, dysk przechowujący plik dziennika transakcji programu SQL Server można włączyć jako akcelerator zapisu. Szczegóły można odczytać w dokumencie Akcelerator zapisu. Akcelerator zapisu platformy Azure nie działa z usługą Azure Premium Storage w wersji 2 i Ultra Disk. W obu przypadkach opóźnienie jest lepsze niż to, co zapewnia usługa Azure Premium Storage w wersji 1. Akcelerator zapisu nie obsługuje dysku Premium SSD v2.
Uwaga / Notatka
W przypadku niektórych nowych typów maszyn wirtualnych M(b)v3, korzystanie z magazynu SSD Premium v1 z pamięcią podręczną odczytu może skutkować mniejszą liczbą operacji IOPS i niższą przepustowością, niż w przypadku niekorzystania z pamięci podręcznej odczytu.
Formatowanie dysków
W przypadku programu SQL Server rozmiar bloku NTFS dla dysków zawierających dane i pliki dziennika programu SQL Server powinien wynosić 64 KB. Nie ma potrzeby formatowania dysku D:\. Ten dysk jest wstępnie sformatowany.
Aby uniknąć sytuacji, w której przywracanie lub tworzenie baz danych inicjuje pliki danych przez zerowanie ich zawartości, upewnij się, że kontekst użytkownika, w którym działa usługa SQL Server, ma prawo użytkownika Wykonywanie zadań konserwacji woluminów. Aby uzyskać więcej informacji, zobacz Natychmiastową inicjalizację plików bazy danych.
SQL Server 2014 i nowsze wersje programu SQL Server — przechowywanie plików bazy danych bezpośrednio w usłudze Azure Blob Storage
Program SQL Server 2014 i nowsze wersje otwierają możliwość przechowywania plików baz danych bezpośrednio w usłudze Azure Blob Store bez otoki wirtualnego dysku twardego wokół nich. Ta funkcja miała na celu rozwiązanie niedociągnięć magazynu blokowego platformy Azure sprzed kilku lat. W dzisiejszych czasach nie zaleca się używania tej metody wdrażania. Zamiast tego wybierz magazyn Azure Premium w wersji 1, Azure Premium w wersji 2 lub dysk Ultra. Zależne od wymagań.
Zagadnienia dotyczące tworzenia kopii zapasowych/odzyskiwania dla programu SQL Server
Wdrożenie programu SQL Server na platformie Azure wymaga przejrzenia architektury kopii zapasowej. Nawet jeśli system nie jest systemem produkcyjnym, kopia zapasowa bazy danych SAP programu SQL Server musi być okresowo tworzona. Ponieważ usługa Azure Storage przechowuje trzy kopie danych, kopia zapasowa jest teraz mniej ważna pod względem zrekompensowania awarii pamięci masowej. Priorytetowym powodem utrzymania odpowiedniego planu tworzenia kopii zapasowych i odzyskiwania jest zapewnienie funkcjonalności odzyskiwania danych do konkretnego punktu w czasie, aby zrekompensować błędy logiczne lub ręczne. Celem jest użycie kopii zapasowych w celu przywrócenia bazy danych z powrotem do określonego punktu w czasie. Możesz też użyć kopii zapasowych na platformie Azure do inicjowania innego systemu z kopiowaniem istniejącej kopii zapasowej bazy danych.
Istnieje kilka sposobów tworzenia kopii zapasowych i przywracania baz danych programu SQL Server na platformie Azure. Aby uzyskać najlepsze omówienie i szczegóły, przeczytaj dokument Tworzenie kopii zapasowej i przywracanie dla programu SQL Server na maszynach wirtualnych platformy Azure. Artykuł obejmuje kilka różnych możliwości.
Korzystanie z obrazu programu SQL Server z witryny Microsoft Azure Marketplace
Firma Microsoft oferuje maszyny wirtualne w witrynie Azure Marketplace, która zawiera już wersje programu SQL Server. W przypadku klientów SAP, którzy wymagają licencji dla programu SQL Server i systemu Windows, użycie tych obrazów może być okazją do pokrycia potrzeby licencji przez skonfigurowanie już zainstalowanych maszyn wirtualnych z programem SQL Server. Aby można było używać takich obrazów dla systemu SAP, należy wziąć pod uwagę następujące kwestie:
- Wersje nienadycyjne programu SQL Server uzyskują wyższe koszty niż maszyna wirtualna "tylko dla systemu Windows" wdrożona z witryny Azure Marketplace. Aby porównać ceny, zobacz Cennik maszyn wirtualnych z systemem Windows i Cennik maszyn wirtualnych programu SQL Server Enterprise.
- Można używać tylko wersji programu SQL Server, które są obsługiwane przez oprogramowanie SAP.
- Sortowanie wystąpienia programu SQL Server zainstalowanego na maszynach wirtualnych oferowanych w Azure Marketplace nie jest tym sortowaniem, którego wymaga SAP NetWeaver do uruchomienia wystąpienia SQL Server. Sortowanie można jednak zmienić za pomocą wskazówek w poniższej sekcji.
Zmienianie sortowania programu SQL Server na maszynie wirtualnej z systemem Microsoft Windows/SQL Server
Ponieważ obrazy programu SQL Server w witrynie Azure Marketplace nie są skonfigurowane do używania sortowania, co jest wymagane dla aplikacji SAP NetWeaver, należy je zmienić natychmiast po wdrożeniu. W przypadku programu SQL Server tę zmianę sortowania można wykonać, wykonując następujące czynności natychmiast po wdrożeniu maszyny wirtualnej, a administrator może zalogować się do wdrożonej maszyny wirtualnej:
- Otwórz okno poleceń systemu Windows jako administrator.
- Zmień katalog na C:\Program Files\Microsoft SQL Server\110\Setup Bootstrap\SQLServer2012.
- Wykonaj polecenie: Setup.exe /QUIET /ACTION=REBUILDDATABASE /INSTANCENAME=MSSQLSERVER /SQLSYSADMINACCOUNTS=
<local_admin_account_name> /SQLCOLLATION=SQL_Latin1_General_Cp850_BIN2-
<local_admin_account_name> to konto, które zostało zdefiniowane jako konto administratora podczas wdrażania maszyny wirtualnej po raz pierwszy za pośrednictwem galerii.
-
Proces powinien potrwać tylko kilka minut. Aby upewnić się, czy krok zakończył się prawidłowym wynikiem, wykonaj następujące kroki:
- Otwórz program SQL Server Management Studio.
- Otwórz okno zapytania.
- Wykonaj polecenie sp_helpsort w bazie danych master programu SQL Server.
Żądany wynik powinien wyglądać następująco:
Latin1-General, binary code point comparison sort for Unicode Data, SQL Server Sort Order 40 on Code Page 850 for non-Unicode Data
Jeśli wynik jest inny, zatrzymaj dowolne wdrożenie i zbadaj, dlaczego polecenie konfiguracji nie działa zgodnie z oczekiwaniami. Wdrażanie aplikacji SAP NetWeaver na instancji SQL Server z wersją o innym zestawie stron kodowych niż ta wspomniana nie jest obsługiwane w przypadku wdrożeń NetWeaver.
SQL Server High-Availability dla SAP na platformie Azure
Korzystając z programu SQL Server we wdrożeniach IaaS platformy Azure dla systemu SAP, istnieje kilka różnych możliwości dodania do wdrożenia warstwy bazy danych o wysokiej dostępności. Platforma Azure udostępnia różne umowy SLA dotyczące czasu pracy dla pojedynczej maszyny wirtualnej przy użyciu różnych magazynów blokowych platformy Azure, pary maszyn wirtualnych wdrożonych w zestawie dostępności platformy Azure lub pary maszyn wirtualnych wdrożonych w różnych strefach dostępności platformy Azure. W przypadku systemów produkcyjnych oczekujemy wdrożenia pary maszyn wirtualnych w zestawie skalowania maszyn wirtualnych z elastycznym zarządzaniem w dwóch różnych strefach dostępności. Aby uzyskać więcej informacji , zobacz porównanie różnych typów wdrożeń dla obciążenia SAP . Jedna maszyna wirtualna uruchamia aktywne wystąpienie programu SQL Server. Druga maszyna wirtualna uruchamia instancję pasywną
Klaster programu SQL Server przy użyciu serwera plików skalowalnego w poziomie systemu Windows lub dysku udostępnionego platformy Azure
W systemie Windows Server 2016 firma Microsoft wprowadziła Storage Spaces Direct. Na podstawie technologii Storage Spaces, bezpośrednie wdrażanie klastrowania FCI programu SQL Server jest ogólnie obsługiwane. Platforma Azure oferuje również dyski udostępnione platformy Azure , których można użyć do klastrowania systemu Windows. W przypadku obciążenia SAP nie obsługujemy tych opcji wysokiej dostępności.
Wysyłanie dzienników programu SQL Server
Jedną z funkcji wysokiej dostępności jest wysyłanie dzienników programu SQL Server. Jeśli maszyny wirtualne uczestniczące w konfiguracji wysokiej dostępności mają działające rozpoznawanie nazw, nie ma problemu. Konfiguracja na platformie Azure nie różni się od konfiguracji wykonywanej lokalnie w celu skonfigurowania wysyłania dzienników i zasad dotyczących wysyłania dzienników. Szczegółowe informacje na temat wysyłania dzienników programu SQL Server można znaleźć w artykule About Log Shipping (SQL Server) (Informacje o wysyłaniu dzienników (SQL Server).
Funkcja wysyłania dzienników programu SQL Server nie była używana na platformie Azure w celu osiągnięcia wysokiej dostępności w jednym regionie świadczenia usługi Azure. Jednak w następujących scenariuszach klienci SAP pomyślnie korzystali z wysyłania dzienników z platformą Azure:
- Scenariusze odzyskiwania po awarii z jednego regionu świadczenia usługi Azure do innego regionu świadczenia usługi Azure
- Konfiguracja odzyskiwania po awarii ze środowiska lokalnego do regionu Azure.
- Scenariusze przejścia z lokalnej infrastruktury na platformę Azure. W takich przypadkach wysyłanie dzienników jest używane do synchronizowania nowego wdrożenia bazy danych na platformie Azure z trwającym systemem produkcyjnym lokalnie. W momencie przełączania produkcja jest zatrzymywana i upewniamy się, że ostatnie kopie zapasowe dziennika transakcji zostały przeniesione do wdrożenia bazy danych w Azure. Następnie wdrożenie bazy danych platformy Azure jest otwarte dla środowiska produkcyjnego.
Zawsze włączony program SQL Server
Ponieważ funkcja Always On jest obsługiwana w środowisku lokalnym SAP (zobacz sap Note #1772688), jest obsługiwana w połączeniu z oprogramowaniem SAP na platformie Azure. Istnieją pewne specjalne zagadnienia dotyczące wdrażania odbiornika grupy dostępności programu SQL Server (nie należy mylić z zestawem dostępności platformy Azure). W związku z tym konieczne są pewne różne kroki instalacji.
Oto niektóre zagadnienia dotyczące korzystania z odbiornika grupy dostępności:
- Korzystanie z odbiornika grupy dostępności jest możliwe tylko z systemem Windows Server 2012 lub nowszym jako systemem operacyjnym gościa maszyny wirtualnej. W systemie Windows Server 2012 upewnij się, że zastosowano aktualizację w celu włączenia odbiorników grupy dostępności programu SQL Server na maszynach wirtualnych Microsoft Azure opartych na Windows Server 2008 R2 i Windows Server 2012.
- W systemie Windows Server 2008 R2 ta poprawka nie istnieje. W takim przypadku Always On powinno być używane w taki sam sposób jak Database Mirroring. Określając partnera awaryjnego przełączania w parametrze połączenia (za pomocą parametru SAP default.pfl dbs/mss/server — zobacz uwaga SAP #965908).
- Korzystając z odbiornika grupy dostępności, należy połączyć maszyny wirtualne bazy danych z dedykowanym modułem równoważenia obciążenia. Statyczne adresy IP należy przypisać do interfejsów sieciowych tych maszyn wirtualnych w konfiguracji Always On (definiowanie statycznego adresu IP zostało opisane w tym artykule). Statyczne adresy IP w porównaniu z protokołem DHCP uniemożliwiają przypisanie nowych adresów IP w przypadkach, gdy obie maszyny wirtualne mogą zostać zatrzymane.
- Podczas kompilowania konfiguracji klastra WSFC wymagane są specjalne kroki, w których klaster potrzebuje przypisanego specjalnego adresu IP, ponieważ platforma Azure z bieżącą funkcjonalnością przypisze nazwę klastra taki sam adres IP jak węzeł, w którym jest tworzony klaster. To zachowanie oznacza, że należy wykonać krok ręczny w celu przypisania innego adresu IP do klastra.
- Odbiornik grupy dostępności zostanie utworzony na platformie Azure z punktami końcowymi TCP/IP przypisanymi do maszyn wirtualnych uruchamiających repliki podstawowe i pomocnicze tej grupy dostępności.
- Może zaistnieć potrzeba zabezpieczenia tych punktów końcowych za pomocą list kontroli dostępu (ACL).
Szczegółowa dokumentacja dotycząca wdrażania funkcji Always On z programem SQL Server w maszynach wirtualnych platformy Azure opisuje:
- Wprowadzenie do grup dostępności Always On programu SQL Server na maszynach wirtualnych platformy Azure.
- Skonfiguruj zawsze włączoną grupę dostępności na maszynach wirtualnych platformy Azure w różnych regionach.
- Skonfiguruj moduł równoważenia obciążenia dla zawsze włączonej grupy dostępności na platformie Azure.
- Najlepsze praktyki dotyczące konfiguracji wysokiej dostępności i odzyskiwania po awarii (SQL Server na maszynach wirtualnych na platformie Azure)
Uwaga / Notatka
Będziesz czytać o wprowadzeniu do zawsze dostępnych grup dostępności programu SQL Server na maszynach wirtualnych platformy Azure, a także o nasłuchiwaczu Direct Network Name (DNN) programu SQL Server. Ta nowa funkcja została wprowadzona w programie SQL Server 2019 CU8. Ta nowa funkcja sprawia, że użycie modułu równoważenia obciążenia platformy Azure obsługującego wirtualny adres IP odbiornika grupy dostępności jest przestarzałe.
SQL Server Always On to najczęściej używana funkcjonalność wysokiej dostępności i odzyskiwania po awarii w platformie Azure na potrzeby wdrożeń obciążeń SAP. Większość klientów używa funkcji Always On w celu zapewnienia wysokiej dostępności w jednym regionie świadczenia usługi Azure. Jeśli wdrożenie jest ograniczone tylko do dwóch węzłów, masz dwie opcje łączności:
- Za pomocą odbiornika grupy dostępności. Odbiornik grupy dostępności wymaga wdrożenia modułu równoważenia obciążenia platformy Azure.
- W programie SQL Server 2016 SP3, SQL Server 2017 CU 25 lub SQL Server 2019 CU8 lub nowszych wersjach programu SQL Server w systemie Windows Server 2016 lub nowszym można użyć odbiornika nazwy sieci bezpośredniej (DNN) zamiast modułu równoważenia obciążenia platformy Azure. DNN eliminuje konieczność używania modułu równoważenia obciążenia Azure.
Użycie parametrów łączności mirroringu bazy danych SQL Server powinno być rozważane tylko w ramach badania problemów przy użyciu pozostałych dwóch metod. W takim przypadku należy skonfigurować łączność aplikacji SAP w taki sposób, w którym nazwy obu węzłów są nazwane. Szczegółowe informacje o takiej konfiguracji po stronie SAP są udokumentowane w nocie SAP #965908. Korzystając z tej opcji, nie trzeba konfigurować odbiornika grupy dostępności. Ponadto bez modułu równoważenia obciążenia platformy Azure i z tym rozwiązaniem może zbadać problemy z tymi składnikami. Pamiętaj jednak, że ta opcja działa tylko wtedy, gdy ograniczysz Grupę Dostępności do dwóch instancji.
Większość klientów korzysta z funkcji Always On programu SQL Server na potrzeby funkcji odzyskiwania po awarii między regionami świadczenia usługi Azure. Kilku klientów korzysta również z możliwości wykonywania kopii zapasowych z repliki pomocniczej.
SQL Server Transparent Data Encryption
Wielu klientów korzysta z funkcji Transparent Data Encryption (TDE) programu SQL Server podczas wdrażania baz danych programu SAP SQL Server na platformie Azure. Funkcja TDE programu SQL Server jest w pełni obsługiwana przez oprogramowanie SAP (zobacz sap Note #1380493).
Stosowanie funkcji TDE programu SQL Server
W przypadkach, gdy przeprowadzasz migrację heterogeniczną z innej bazy danych, uruchomionej lokalnie do systemu Windows/programu SQL Server uruchomionego na platformie Azure, należy z wyprzedzeniem utworzyć pustą docelową bazę danych w programie SQL Server. W następnym kroku zastosujesz funkcję TDE programu SQL Server do tej pustej bazy danych. Powodem, dla którego chcesz wykonać tę sekwencję, jest to, że proces szyfrowania pustej bazy danych może zająć sporo czasu. Procesy importowania oprogramowania SAP następnie importować dane do zaszyfrowanej bazy danych w fazie przestoju. Obciążenie związane z importowaniem do zaszyfrowanej bazy danych ma znacznie mniejszy wpływ na czas niż szyfrowanie bazy danych po fazie eksportowania w fazie czasu awarii. Negatywne środowiska zostały wykonane podczas próby zastosowania funkcji TDE z obciążeniem SAP uruchomionym na bazie danych. W związku z tym zaleca się traktowanie wdrożenia funkcji TDE jako działania, które należy wykonać bez obciążenia systemu SAP lub przy niskim obciążeniu w danej bazie danych. W programie SQL Server 2016 można zatrzymać i wznowić skanowanie TDE, które wykonuje początkowe szyfrowanie. W dokumencie Transparent Data Encryption (TDE) opisano polecenie i szczegóły.
W przypadku przenoszenia baz danych programu SAP SQL Server ze środowiska lokalnego na platformę Azure zalecamy przetestowanie, w której infrastrukturze można najszybciej zastosować szyfrowanie. W tym przypadku należy pamiętać o następujących faktach:
- Nie można zdefiniować, ile wątków jest używanych do stosowania szyfrowania danych do bazy danych. Liczba wątków jest zasadniczo zależna od liczby woluminów dysku, w których są dystrybuowane dane programu SQL Server i pliki dziennika. To oznacza, że im bardziej odrębne woluminy (litery dysku), tym więcej wątków jest zaangażowanych równolegle do przeprowadzenia szyfrowania. Taka konfiguracja jest nieco sprzeczna z sugestią wcześniejszej konfiguracji dysku na temat tworzenia jednej lub mniejszej liczby miejsc do magazynowania dla plików bazy danych programu SQL Server na maszynach wirtualnych platformy Azure. Konfiguracja z kilkoma woluminami doprowadziłaby do kilku wątków wykonujących szyfrowanie. Pojedynczy wątek szyfrowania odczytuje zakresy 64 KB, szyfruje je, a następnie zapisuje rekord w pliku dziennika transakcji, wskazując, że zakres został zaszyfrowany. W rezultacie obciążenie dziennika transakcji jest umiarkowane.
- W starszych wersjach programu SQL Server kompresja kopii zapasowych nie zapewniała już wydajności podczas szyfrowania bazy danych programu SQL Server. Takie zachowanie może przekształcić się w problem polegający na tym, że plan polegał na zaszyfrowaniu lokalnej bazy danych programu SQL Server, a następnie skopiowaniu kopii zapasowej na platformę Azure w celu przywrócenia bazy danych na platformie Azure. Kompresja kopii zapasowych programu SQL Server może osiągnąć współczynnik kompresji 4.
- W programie SQL Server 2016 program SQL Server wprowadził nowe funkcje, które umożliwiają kompresowanie kopii zapasowych zaszyfrowanych baz danych oraz w wydajny sposób. Aby uzyskać szczegółowe informacje, zobacz ten blog .
Korzystanie z usługi Azure Key Vault
Platforma Azure oferuje usługę Key Vault do przechowywania kluczy szyfrowania. Program SQL Server po drugiej stronie oferuje łącznik do używania usługi Azure Key Vault jako magazynu dla certyfikatów TDE.
Więcej szczegółów dotyczących używania usługi Azure Key Vault dla list TDE programu SQL Server, takich jak:
- Konfigurowanie integracji usługi Azure Key Vault dla programu SQL Server na maszynach wirtualnych platformy Azure (Resource Manager).
- Więcej pytań od klientów na temat funkcji Transparent Data Encryption programu SQL Server — TDE + Azure Key Vault.
Ważne
Korzystając z funkcji TDE w SQL Server, zwłaszcza z usługą Azure Key Vault, zaleca się używanie najnowszych poprawek dla SQL Server 2014, SQL Server 2016 i SQL Server 2017. Przyczyną jest to, że w oparciu o opinie klientów, optymalizacje i poprawki zostały zastosowane do kodu. Na przykład sprawdź KBA #4058175.
Minimalne konfiguracje wdrożenia
W tej sekcji sugerujemy zestaw minimalnych konfiguracji dla różnych rozmiarów baz danych w ramach obciążenia SAP. Zbyt trudno jest ocenić, czy te rozmiary pasują do określonego obciążenia. W niektórych przypadkach możemy być hojni w pamięci w porównaniu z rozmiarem bazy danych. Z drugiej strony rozmiar dysku może być zbyt niski dla niektórych obciążeń. W związku z tym te konfiguracje powinny być traktowane jako to, co są. Są to konfiguracje, które powinny dać ci punkt wyjścia. Konfiguracje w celu dostosowania do konkretnych wymagań dotyczących obciążenia i wydajności kosztów.
Przykład konfiguracji dla małego wystąpienia programu SQL Server o rozmiarze bazy danych z zakresu od 50 GB do 250 GB może wyglądać następująco:
| Konfiguracja | Maszyna wirtualna bazy danych | Komentarze |
|---|---|---|
| Typ maszyny wirtualnej | E4s_v3/v4/v5 (4 procesory wirtualne/32 GiB RAM) | |
| Przyspieszone Sieciowanie | Włącz | |
| Wersja programu SQL Server | SQL Server 2019 lub nowsze | |
| Liczba plików danych | 4 | |
| Liczba plików dziennika | 1 | |
| Liczba plików danych tymczasowych | 4 lub domyślne od programu SQL Server 2016 | |
| System operacyjny | Windows Server 2019 lub nowsze | |
| Agregacja dysku | Miejsca do magazynowania w razie potrzeby | |
| System plików | NTFS | |
| Formatowanie rozmiaru bloku | 64 KB | |
| Liczba i typ dysków danych | Premium Storage v1: 2 x P10 (RAID0) Pamięć masowa Premium v2: 2 x 150 GiB (RAID0) — domyślna liczba operacji we/wy na sekundę i przepływność lub równoważnik SSD Premium v2 |
Pamięć podręczna = tylko do odczytu dla magazynu Premium v1 |
| # i typ dysków logów | Premium storage v1: 1 x P20 Premium Storage w wersji 2: 1 x 128 GiB — domyślna liczba operacji we/wy na sekundę i przepływność lub odpowiednik SSD w warstwie Premium w wersji 2 |
Pamięć podręczna = BRAK |
| Parametr maksymalnej pamięci programu SQL Server | 90% pamięci RAM fizycznej | Przy założeniu pojedynczego wystąpienia |
Przykład konfiguracji lub małej instancji programu SQL Server o rozmiarze bazy danych wynoszącym od 250 GB do 750 GB, takiej jak mniejszy system SAP Business Suite, może wyglądać następująco:
| Konfiguracja | Maszyna wirtualna bazy danych | Komentarze |
|---|---|---|
| Typ maszyny wirtualnej | E16s_v3/v4/v5 (16 procesorów wirtualnych/128 GiB RAM) | |
| Przyspieszone Sieciowanie | Włącz | |
| Wersja programu SQL Server | SQL Server 2019 lub nowsze | |
| Liczba plików danych | 8 | |
| Liczba plików dziennika | 1 | |
| Liczba plików danych tymczasowych | 8 lub wartość domyślna od programu SQL Server 2016 | |
| System operacyjny | Windows Server 2019 lub nowsze | |
| Agregacja dysku | Miejsca do magazynowania w razie potrzeby | |
| System plików | NTFS | |
| Formatowanie rozmiaru bloku | 64 KB | |
| Liczba i typ dysków danych | Premium Storage v1: 4 x P20 (RAID0) Magazyn w warstwie Premium w wersji 2: 4 x 100 GiB — 200 GiB (RAID0) — domyślna liczba operacji we/wy na sekundę i dodatkowa przepływność 25 MB/s na dysk lub równoważny dysk SSD w warstwie Premium w wersji 2 |
Pamięć podręczna = tylko do odczytu dla magazynu Premium v1 |
| # i typ dysków logów | Premium storage v1: 1 x P20 Premium Storage w wersji 2: 1 x 200 GiB — domyślna liczba operacji wejść/wyjść na sekundę i przepływność lub równoważny SSD Premium w wersji 2 |
Pamięć podręczna = BRAK |
| Parametr maksymalnej pamięci programu SQL Server | 90% pamięci RAM fizycznej | Przy założeniu pojedynczego wystąpienia |
Przykład konfiguracji dla średniego wystąpienia programu SQL Server o rozmiarze bazy danych w przedziale od 750 GB do 2000 GB, takich jak średni system SAP Business Suite, może wyglądać następująco:
| Konfiguracja | Maszyna wirtualna bazy danych | Komentarze |
|---|---|---|
| Typ maszyny wirtualnej | E64s_v3/v4/v5 (64 wirtualne procesory/432 GiB RAM) | |
| Przyspieszone Sieciowanie | Włącz | |
| Wersja programu SQL Server | SQL Server 2019 lub nowsze | |
| Liczba urządzeń danych | 16 | |
| Liczba urządzeń dziennika | 1 | |
| Liczba plików danych tymczasowych | 8 lub wartość domyślna od programu SQL Server 2016 | |
| System operacyjny | Windows Server 2019 lub nowsze | |
| Agregacja dysku | Miejsca do magazynowania w razie potrzeby | |
| System plików | NTFS | |
| Formatowanie rozmiaru bloku | 64 KB | |
| Liczba i typ dysków danych | Magazyn Premium w wersji 1: 4 x P30 (RAID0) Magazyn w warstwie Premium w wersji 2: 4 x 250 GiB — 500 GiB — plus 2000 operacji we/wy na sekundę i 75 MB/s przepływności na dysk lub równoważny dysk SSD w warstwie Premium w wersji 2 |
Pamięć podręczna = tylko do odczytu dla magazynu Premium v1 |
| # i typ dysków logów | Premium storage v1: 1 x P20 Magazyn Premium w wersji 2: 1 x 400 GiB — domyślne IOPS i dodatkowa przepustowość 75 MB/s lub ekwiwalent SSD Premium w wersji 2 |
Pamięć podręczna = BRAK |
| Parametr maksymalnej pamięci programu SQL Server | 90% pamięci RAM fizycznej | Przy założeniu pojedynczego wystąpienia |
Przykład konfiguracji dla większego wystąpienia programu SQL Server, gdzie rozmiar bazy danych mieści się w przedziale od 2000 GB do 4000 GB, takim jak większy system SAP Business Suite, może wyglądać następująco:
| Konfiguracja | Maszyna wirtualna bazy danych | Komentarze |
|---|---|---|
| Typ maszyny wirtualnej | E96(d)s_v5 (96 procesorów wirtualnych/672 GiB RAM) | |
| Przyspieszone Sieciowanie | Włącz | |
| Wersja programu SQL Server | SQL Server 2019 lub nowsze | |
| Liczba urządzeń danych | 24 | |
| Liczba urządzeń dziennika | 1 | |
| Liczba plików danych tymczasowych | 8 lub wartość domyślna od programu SQL Server 2016 | |
| System operacyjny | Windows Server 2019 lub nowsze | |
| Agregacja dysku | Miejsca do magazynowania w razie potrzeby | |
| System plików | NTFS | |
| Formatowanie rozmiaru bloku | 64 KB | |
| Liczba i typ dysków danych | Magazyn Premium w wersji 1: 4 x P30 (RAID0) Magazyn w warstwie Premium w wersji 2: 4 x 500 GiB — 800 GiB — plus 2500 operacji we/wy na sekundę i 100 MB/s przepływności na dysk lub równoważny dysk SSD w warstwie Premium w wersji 2 |
Pamięć podręczna = tylko do odczytu dla magazynu Premium v1 |
| # i typ dysków logów | Premium storage v1: 1 x P20 Magazyn Premium w wersji 2: 1 x 400 GiB — plus 1000 operacji we/wy na sekundę i dodatkowa przepływność 75 MB/s lub równoważny SSD Premium w wersji 2 |
Pamięć podręczna = BRAK |
| Parametr maksymalnej pamięci programu SQL Server | 90% pamięci RAM fizycznej | Przy założeniu pojedynczego wystąpienia |
Przykład konfiguracji dużego wystąpienia serwera SQL o wielkości bazy danych 4 TB lub większej, takiego jak duży globalnie używany system SAP Business Suite, może wyglądać następująco:
| Konfiguracja | Maszyna wirtualna bazy danych | Komentarze |
|---|---|---|
| Typ maszyny wirtualnej | Seria M (od 1,0 do 4,0 TB pamięci RAM) | |
| Przyspieszone Sieciowanie | Włącz | |
| Wersja programu SQL Server | SQL Server 2019 lub nowsze | |
| Liczba urządzeń danych | 32 | |
| Liczba urządzeń dziennika | 1 | |
| Liczba plików danych tymczasowych | 8 lub wartość domyślna od programu SQL Server 2016 | |
| System operacyjny | Windows Server 2019 lub nowsze | |
| Agregacja dysku | Miejsca do magazynowania w razie potrzeby | |
| System plików | NTFS | |
| Formatowanie rozmiaru bloku | 64 KB | |
| Liczba i typ dysków danych | Premium Storage v1: 4+ x P40 (RAID0) Magazyn Premium w wersji 2: 4+ x 1000 GiB — 4000 GiB — oraz 4500 IOPS i przepustowość 125 MB/s na dysk lub równoważny dysk Premium SSD v2 |
Pamięć podręczna = tylko do odczytu dla magazynu Premium v1 |
| # i typ dysków logów | Przechowywanie premium v1: 1 x P30 Magazyn w warstwie Premium v2: 1 x 500 GiB — plus 2000 IOPS i przepustowość 125 MB/s lub odpowiednik Premium SSD v2 |
Pamięć podręczna = BRAK |
| Parametr maksymalnej pamięci programu SQL Server | 95% pamięci RAM fizycznej | Przy założeniu pojedynczego wystąpienia |
Na przykład ta konfiguracja to konfiguracja maszyny wirtualnej bazy danych pakietu SAP Business Suite w programie SQL Server. Ta maszyna wirtualna hostuje bazę danych o pojemności 30TB pojedynczej globalnej instancji pakietu SAP Business Suite globalnej firmy z ponad 200 miliardami dolarów rocznego przychodu i ponad 200 tys. pracowników zatrudnionych w pełnym wymiarze godzin. System uruchamia wszystkie procesy przetwarzania finansowego, sprzedaży i dystrybucji oraz wiele innych procesów biznesowych z różnych obszarów, w tym listy płac w Ameryce Północnej. System działa na platformie Azure od początku 2018 r. przy użyciu maszyn wirtualnych serii M platformy Azure jako maszyn wirtualnych bazy danych. W przypadku wysokiej dostępności system korzysta z Always On z jedną synchroniczną repliką w innej strefie dostępności w tym samym regionie Azure. Kolejna asynchroniczna replika w innym regionie świadczenia usługi Azure. Warstwa aplikacji NetWeaver jest wdrażana w najnowszych rodzinach maszyn wirtualnych D(a)/E(a).
| Konfiguracja | Maszyna wirtualna bazy danych | Komentarze |
|---|---|---|
| Typ maszyny wirtualnej | M192dms_v2 (192 vCPU/4,196 GiB RAM) | |
| Przyspieszone Sieciowanie | Włączone | |
| Wersja programu SQL Server | SQL Server 2019 | |
| Liczba plików danych | 32 | |
| Liczba plików dziennika | 1 | |
| Liczba plików danych tymczasowych | 8 | |
| System operacyjny | Windows Server 2019 | |
| Agregacja dysku | Przestrzenie magazynowe | |
| System plików | NTFS | |
| Formatowanie rozmiaru bloku | 64 KB | |
| Liczba i typ dysków danych | Premium Storage w wersji 1: 16 x P40 lub równoważny dysk SSD Premium w wersji 2 | Pamięć podręczna = tylko do odczytu |
| # i typ dysków logów | Magazyn Premium w wersji 1: 1 x P60 lub równoważny SSD Premium w wersji 2 | Korzystanie z akceleratora zapisu |
| Liczba i typ dysków bazy danych tempdb | Premium Storage w wersji 1: 1 x P30 lub równoważny SSD Premium w wersji 2 | Brak buforowania |
| Parametr maksymalnej pamięci programu SQL Server | 95% pamięci RAM fizycznej |
Ogólne podsumowanie programu SQL Server dla oprogramowania SAP na platformie Azure
W tym przewodniku znajduje się wiele zaleceń i zalecamy przeczytanie go więcej niż raz przed zaplanowanym wdrożeniem platformy Azure. Ogólnie jednak pamiętaj, aby postępować zgodnie z najlepszymi zaleceniami dotyczącymi programu SQL Server na platformie Azure:
- Użyj najnowszej wersji programu SQLServer, takiej jak SQL Server 2022, która ma największe zalety na platformie Azure.
- Starannie zaplanuj krajobraz systemowy SAP w Azure, aby zrównoważyć układ plików danych i ograniczenia Azure.
- Nie miej zbyt wielu dysków, ale wystarczająco dużo, aby zapewnić sobie wymaganą liczbę IOPS (operacji we/wy na sekundę).
- Paskuj dyski tylko wtedy, gdy potrzebujesz uzyskać większą przepustowość.
- Nie miej zbyt wielu dysków, ale wystarczająco dużo, aby zapewnić sobie wymaganą liczbę IOPS (operacji we/wy na sekundę).
- Nigdy nie instaluj oprogramowania ani nie zapisuj plików, które wymagają trwałego przechowywania, na dysku D:\, ponieważ jest on nietrwały. Wszystkie elementy na tym dysku można utracić podczas ponownego uruchamiania systemu Windows lub ponownego uruchamiania maszyny wirtualnej.
- Użyj rozwiązania ZAWSZE włączonego programu SQL Server, aby replikować dane bazy danych.
- Zawsze używaj rozpoznawania nazw, nie polegaj na adresach IP.
- Za pomocą funkcji TDE programu SQL Server zastosuj najnowsze poprawki programu SQL Server.
- Należy zachować ostrożność przy użyciu obrazów programu SQL Server z witryny Azure Marketplace. Jeśli używasz SQL Server, musisz zmienić ustawienia sortowania instancji przed zainstalowaniem dowolnego systemu SAP NetWeaver.
- Instalowanie i konfigurowanie monitorowania hosta SAP dla platformy Azure zgodnie z opisem w przewodniku wdrażania.
Dalsze kroki
Przeczytaj artykuł