Dodawanie dodatkowych lokacji dodatkowych do klastra HANA Pacemaker
W tym artykule opisano wymagania i konfigurację konfigurowania dodatkowej lokacji replikacji HANA w celu uzupełnienia istniejącego klastra Pacemaker. Opisano zarówno specyfikę oprogramowania SUSE Linux Enterprise Server (SLES) i redHat Enterprise Linux (RHEL).
Omówienie
Platforma SAP HANA obsługuje replikację systemu (HSR) z więcej niż dwiema połączonymi lokacjami. Możesz skonfigurować dodatkowe lokacje do istniejącej pary HSR, którą program Pacemaker zarządza w konfiguracji o wysokiej dostępności. Można na przykład wdrożyć te dodatkowe lokacje w drugim regionie świadczenia usługi Azure na potrzeby odzyskiwania po awarii.
Program Pacemaker i agent zasobów klastra HANA zarządzają tylko dwoma pierwszymi lokacjami w module HSR. Dodatkowe lokacje nie są kontrolowane przez klaster Pacemaker.
Platforma SAP HANA obsługuje dodatkową replikację systemu lokacji dodatkowych w dwóch trybach:
- Funkcja Multitarget replikuje zmiany danych z podstawowego na więcej niż jeden system docelowy. Dodatkowe lokacje są połączone z replikacją podstawową w topologii gwiazdy.
- Multitier to kaskadowa lub łańcuchowa konfiguracja replikacji systemu HANA. Trzecia lokacja łączy się z pomocniczym.
Aby uzyskać więcej informacji koncepcyjnych na temat modułu HSR platformy HANA w jednym regionie i w różnych regionach, zobacz Dostępność oprogramowania SAP HANA w różnych regionach świadczenia usługi Azure.
Wymagania wstępne dotyczące usługi SLES
Wymagania dotyczące dodatkowych lokacji HSR różnią się w przypadku skalowania w górę platformy HANA i skalowania w poziomie platformy HANA.
Uwaga
- Wymagania zawarte w tym artykule są prawidłowe tylko dla środowiska z obsługą programu Pacemaker. Bez programu Pacemaker wymagania dotyczące wersji oprogramowania SAP HANA mają zastosowanie do wybranego trybu replikacji.
- Program Pacemaker i agent zasobów klastra HANA zarządzają tylko dwoma lokacjami. Dodatkowa lokacja modułu HSR nie jest kontrolowana przez klaster Pacemaker.
- System SUSE obsługuje maksymalnie jedną dodatkową lokację replikacji systemu do bazy danych SAP HANA spoza klastra Pacemaker.
- Zarówno skalowanie w górę, jak i skalowanie w poziomie: platforma SAP HANA SPS 04 lub nowsza jest wymagana do korzystania z wielotargetowego modułu HSR z klastrem Pacemaker.
- Zarówno skalowanie w górę, jak i skalowanie w poziomie: maksymalnie jedna replikacja systemu SAP HANA połączona spoza klastra systemu Linux.
- Tylko skalowanie w poziomie platformy HANA: SLES 15 SP1 lub nowszy.
- Tylko skalowanie w poziomie platformy HANA: pakiet systemu operacyjnego SAPHanaSR-ScaleOut w wersji 0.180 lub nowszej.
- Tylko skalowanie w poziomie platformy HANA: platforma SAP HANA wysokiej dostępności (HA) hak SAPHanaSrMultiTarget jest używana. Punkt zaczepienia
SAPHanaSRwysokiej dostępności platformy HANA nie jest wielowersyjny do skalowania w poziomie.
Wymagania wstępne dotyczące systemu RHEL
Wymagania dotyczące dodatkowych lokacji HSR różnią się w przypadku skalowania w górę platformy HANA i skalowania w poziomie platformy HANA.
Uwaga
- Wymagania zawarte w tym artykule są prawidłowe tylko dla środowiska z obsługą programu Pacemaker. Bez programu Pacemaker wymagania dotyczące wersji oprogramowania SAP HANA mają zastosowanie do wybranego trybu replikacji.
- Program Pacemaker i agent zasobów klastra HANA zarządzają tylko dwoma lokacjami. Dodatkowe lokacje modułu HSR nie są kontrolowane przez klaster Pacemaker.
- Oprogramowanie RedHat obsługuje co najmniej jedną dodatkową lokację replikacji systemu do bazy danych SAP HANA spoza klastra Pacemaker.
- Tylko skalowanie w górę platformy HANA: zobacz Zasady obsługi oprogramowania RedHat dla klastrów RHEL HA, aby uzyskać szczegółowe informacje na temat minimalnej wersji systemu operacyjnego, platformy SAP HANA i agentów zasobów klastra.
- Tylko skalowanie w poziomie platformy HANA: replikacja wielotargetowa platformy HANA nie jest obsługiwana na platformie Azure z klastrem Pacemaker.
Napiwek
Konfiguracja ilustruje sposób konfigurowania trzeciej lokacji poza klastrem Pacemaker. W systemie RHEL, jeśli masz więcej niż jedną dodatkową lokację poza klastrem Pacemaker, musisz również rozszerzyć konfigurację na inne lokacje.
Skalowanie platformy HANA w górę: dodawanie replikacji systemu wielotargetowego HANA na potrzeby odzyskiwania po awarii
Dzięki hakom SAP HANA HA SAPHanaSR/susHanaSR dla systemów SLES i RHEL można dodać dodatkowe lokacje do replikacji systemu HANA. Środowisko Pacemaker ma świadomość konfiguracji wielotargetu HANA.
Niepowodzenie dodatkowych lokacji nie powoduje wyzwolenia żadnej akcji klastra. Klaster wykrywa stan replikacji połączonych lokacji i monitorowany atrybut dla trzeciej lokacji może ulec zmianie między stanami SOK i SFAIL . Wszelkie testy przejęcia do dodatkowej lokacji lub wykonywania procesu ćwiczenia odzyskiwania po awarii powinny najpierw umieścić zasoby klastra w tryb konserwacji, aby zapobiec niepożądanej akcji klastra.
W poniższym przykładzie przedstawiono system replikacji systemu wielotargetowego. Aby uzyskać więcej informacji, zobacz dokumentację systemu SAP.

Wdróż zasoby platformy Azure dla trzeciego węzła. W zależności od wymagań możesz użyć innego regionu świadczenia usługi Azure do celów odzyskiwania po awarii.
Kroki wymagane dla trzeciej lokacji są podobne do maszyn wirtualnych (maszyn wirtualnych) dla klastra skalowalnego w górę platformy HANA. Trzecia witryna korzysta z infrastruktury platformy Azure. System operacyjny i wersja HANA są zgodne z istniejącym klastrem Pacemaker z następującymi wyjątkami:
- Dla trzeciej lokacji nie wdrożono modułu równoważenia obciążenia. Brak integracji z istniejącym modułem równoważenia obciążenia klastra dla maszyny wirtualnej trzeciej lokacji.
- Nie instaluj pakietów systemu operacyjnego SAPHanaSR, SAPHanaSR-doc i wzorca pakietu systemu operacyjnego ha_sles na trzeciej maszynie wirtualnej lokacji.
- Brak integracji z klastrem dla zasobów maszyny wirtualnej lub HANA trzeciej lokacji.
- Brak konfiguracji haka ha platformy HANA dla trzeciej lokacji w global.ini.
Zainstaluj oprogramowanie SAP HANA w trzecim węźle.
Ten sam identyfikator SID platformy HANA i numer instalacji platformy HANA muszą być używane dla trzeciej lokacji.
Po zainstalowaniu i uruchomieniu oprogramowania SAP HANA w trzeciej lokacji zarejestruj trzecią lokację w lokacji głównej.
W poniższym przykładzie użyto
SITE-DRnazwy trzeciej witryny.# Execute on the third site su - hn1adm # Register the HANA third site to the primary. Switch --online will shutdown the HANA instance on third site. hdbnsutil -sr_register --name=SITE-DR --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=async --onlineSprawdź, czy replikacja systemu HANA pokazuje lokację dodatkową i trzecią lokację.
# Verify HANA HSR is in sync, execute on primary sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"SAPHanaSRSprawdź atrybut trzeciej witryny.SITE-DRpowinna być wyświetlana ze stanemSOKSitesw sekcji .# Check SAPHanaSR attribute on any cluster managed host (first or second site) sudo SAPHanaSR-showAttr # Example result # Global cib-time maintenance # -------------------------------------------- # global Tue Feb 21 19:28:21 2023 false # # Sites srHook # ----------------- # HN1-SITE1 PRIM # HN1-SITE2 SOK # SITE-DR SOKKlaster wykrywa stan replikacji połączonych lokacji. Monitorowane atrybuty mogą zmieniać się między
SOKiSFAIL. Jeśli replikacja do lokacji odzyskiwania po awarii nie powiedzie się, nie ma żadnej akcji klastra.
Skalowanie w poziomie platformy HANA: dodawanie replikacji systemu wielotargetowego HANA na potrzeby odzyskiwania po awarii
Za pomocą dostawcy SAP HANA HA SAPHanaSrMultiTarget możesz dodać trzecią witrynę skalowaną w poziomie platformy HANA. Ta trzecia witryna jest często używana do odzyskiwania po awarii w innym regionie świadczenia usługi Azure. Środowisko Pacemaker zdaje sobie sprawę z konfiguracji wielotargetu odzyskiwania po awarii HANA. Ta sekcja dotyczy tylko systemów z uruchomionym programem Pacemaker w systemie SUSE. Aby uzyskać szczegółowe informacje, zobacz sekcję "Wymagania wstępne" w tym dokumencie.
Niepowodzenie trzeciego węzła nie powoduje wyzwolenia żadnej akcji klastra. Klaster wykrywa stan replikacji połączonych lokacji i monitorowany atrybut dla trzeciej lokacji może ulec zmianie między stanami SOK i SFAIL . Wszelkie testy przejęcia do lokacji trzeciej/odzyskiwania po awarii lub wykonywania procesu ćwiczenia odzyskiwania po awarii powinny najpierw umieścić zasoby klastra w tryb konserwacji, aby zapobiec niepożądanej akcji klastra.
W poniższym przykładzie przedstawiono system replikacji systemu wielotargetowego. Aby uzyskać więcej informacji, zobacz dokumentację systemu SAP.

Wdrażanie zasobów platformy Azure dla trzeciej witryny. W zależności od wymagań możesz użyć innego regionu świadczenia usługi Azure do celów odzyskiwania po awarii.
Kroki wymagane do skalowania w poziomie platformy HANA w trzecim miejscu odzwierciedlają kroki wdrażania klastra skalowalnego w poziomie platformy HANA. Trzecia lokacja korzysta z kroków instalacji infrastruktury, systemu operacyjnego i platformy HANA platformy Azure dla
SITE1klastra skalowalnego w poziomie z następującymi wyjątkami:- Dla trzeciej lokacji nie wdrożono modułu równoważenia obciążenia. Nie ma integracji z istniejącym modułem równoważenia obciążenia klastra dla maszyn wirtualnych trzeciej lokacji.
- Nie instaluj pakietów systemu operacyjnego SAPHanaSR-ScaleOut, SAPHanaSR-ScaleOut-doc i wzorca pakietu systemu operacyjnego ha_sles na maszynach wirtualnych innych lokacji.
- Brak maszyny wirtualnej twórcy większości dla trzeciej lokacji, ponieważ nie ma integracji klastra.
- Utwórz wolumin NFS /hana/shared dla wyłącznego użycia witryny trzeciej.
- Brak integracji z klastrem dla maszyn wirtualnych lub zasobów platformy HANA trzeciej lokacji.
- Brak konfiguracji haka ha platformy HANA dla trzeciej lokacji w global.ini.
Musisz użyć tego samego identyfikatora SID platformy HANA i numeru instalacji platformy HANA dla trzeciej lokacji.
W przypadku skalowania oprogramowania SAP HANA w poziomie w trzeciej lokacji zainstalowanej i uruchomionej zarejestruj trzecią lokację w lokacji głównej.
W poniższym przykładzie użyto
SITE-DRnazwy trzeciej witryny.# Execute on the third site su - hn1adm # Register the HANA third site to the primary. Switch --online will shutdown the HANA instance on third site. hdbnsutil -sr_register --name=SITE-DR --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=async --onlineSprawdź, czy replikacja systemu HANA pokazuje lokację dodatkową i trzecią lokację.
# Verify HANA HSR is in sync, execute on primary sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"SAPHanaSRSprawdź atrybut trzeciej witryny.SITE-DRpowinna być wyświetlana ze stanemSOKSitesw sekcji .# Check SAPHanaSR attribute on any cluster managed host (first or second site) sudo SAPHanaSR-showAttr # Expected result # Global cib-time maintenance prim sec sync_state upd # --------------------------------------------------------------------- # HN1 Fri Jan 27 10:38:46 2023 false HANA_S1 - SOK ok # # Sites lpt lss mns srHook srr # ------------------------------------------------ # SITE-DR SOK # HANA_S1 1674815869 4 hana-s1-db1 PRIM P # HANA_S2 30 4 hana-s2-db1 SOK SKlaster wykrywa stan replikacji połączonych lokacji. Monitorowany atrybut może ulec zmianie między
SOKiSFAIL. Jeśli replikacja do lokacji odzyskiwania po awarii nie powiedzie się, nie ma żadnej akcji klastra.
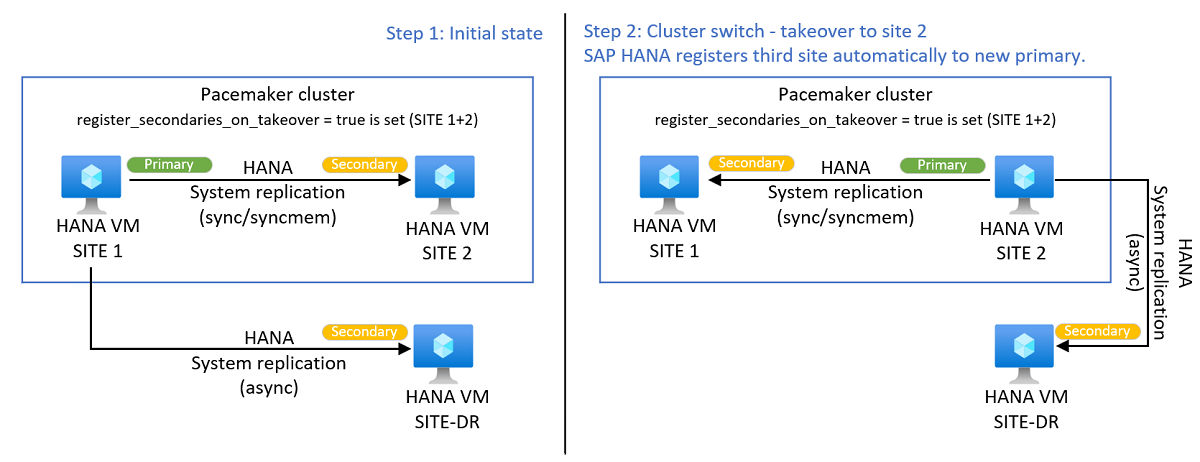
Autoregister trzeciej witryny
Podczas planowanego lub nieplanowanego zdarzenia przejęcia między dwoma lokacjami klastra Pacemaker moduł HSR do trzeciej lokacji również zostanie przerwany. Program Pacemaker nie modyfikuje replikacji platformy HANA do trzeciej lokacji.
Oprogramowanie SAP udostępnia od czasu parametru register_secondaries_on_takeoverHANA 2 SPS 04 . Przy ustawieniu parametru na wartość true, po przejęciu modułu HSR między lokacjami klastra 1 i 2 platforma HANA automatycznie rejestruje trzecią lokację w nowej lokacji podstawowej, aby zachować konfigurację wielotargetową modułu HSR. Skonfiguruj parametr register_secondaries_on_takeover = true HANA skonfigurowany w bloku global.ini w [system_replication] obu lokacjach sap HANA w klastrze systemu Linux. Zarówno WITRYNA1, jak i SITE2 potrzebują parametru w odpowiednim pliku konfiguracji global.ini platformy HANA. Parametr może być również używany poza klastrem Pacemaker.
W przypadku wielowarstwowego modułu HSR nie istnieje automatyczna rejestracja platformy SAP HANA w trzeciej lokacji. Należy ręcznie zarejestrować trzecią lokację w bieżącej pomocniczej lokacji, aby zachować łańcuch replikacji HSR dla wielu warstw.