Wysoka dostępność programu IBM Db2 LUW na maszynach wirtualnych platformy Azure w systemie Red Hat Enterprise Linux Server
Usługa IBM Db2 dla systemów Linux, UNIX i Windows (LUW) w konfiguracji wysokiej dostępności i odzyskiwania po awarii (HADR) składa się z jednego węzła, który uruchamia podstawowe wystąpienie bazy danych i co najmniej jeden węzeł z pomocniczym wystąpieniem bazy danych. Zmiany w podstawowym wystąpieniu bazy danych są replikowane synchronicznie lub asynchronicznie w zależności od konfiguracji.
Uwaga
Ten artykuł zawiera odwołania do terminów, których firma Microsoft już nie używa. Po usunięciu tych warunków z oprogramowania usuniemy je z tego artykułu.
W tym artykule opisano sposób wdrażania i konfigurowania maszyn wirtualnych platformy Azure, instalowania struktury klastra i instalowania bazy danych IBM Db2 LUW przy użyciu konfiguracji usługi HADR.
W tym artykule nie opisano sposobu instalowania i konfigurowania systemu IBM Db2 LUW z instalacją oprogramowania HADR lub SAP. Aby ułatwić wykonywanie tych zadań, udostępniamy odwołania do podręczników instalacji oprogramowania SAP i IBM. Ten artykuł koncentruje się na częściach specyficznych dla środowiska platformy Azure.
Obsługiwane wersje IBM Db2 to wersja 10.5 lub nowsza, jak opisano w 1928533 notatek SAP.
Przed rozpoczęciem instalacji zapoznaj się z następującymi uwagami i dokumentacją oprogramowania SAP:
| Uwaga SAP | opis |
|---|---|
| 1928533 | Aplikacje SAP na platformie Azure: obsługiwane produkty i typy maszyn wirtualnych platformy Azure |
| 2015553 | OPROGRAMOWANIE SAP na platformie Azure: wymagania wstępne dotyczące pomocy technicznej |
| 2178632 | Kluczowe metryki monitorowania oprogramowania SAP na platformie Azure |
| 2191498 | Oprogramowanie SAP w systemie Linux z platformą Azure: ulepszone monitorowanie |
| 2243692 | Maszyna wirtualna z systemem Linux na platformie Azure (IaaS): problemy z licencjami sap |
| 2002167 | Red Hat Enterprise Linux 7.x: instalacja i uaktualnianie |
| 2694118 | Dodatek Red Hat Enterprise Linux HA na platformie Azure |
| 1999351 | Rozwiązywanie problemów z rozszerzonym monitorowaniem platformy Azure dla oprogramowania SAP |
| 2233094 | DB6: aplikacje SAP na platformie Azure korzystające z bazy danych IBM Db2 dla systemów Linux, UNIX i Windows — dodatkowe informacje |
| 1612105 | DB6: często zadawane pytania dotyczące bazy danych Db2 z usługą HADR |
Omówienie
Aby uzyskać wysoką dostępność, system IBM Db2 LUW z usługą HADR jest instalowany na co najmniej dwóch maszynach wirtualnych platformy Azure, które są wdrażane w zestawie skalowania maszyn wirtualnych z elastyczną aranżacją w różnych strefach dostępności lub w zestawie dostępności.
Poniższa grafika przedstawia konfigurację dwóch maszyn wirtualnych platformy Azure serwera bazy danych. Obie maszyny wirtualne serwera bazy danych platformy Azure mają dołączony własny magazyn i są uruchomione. W usłudze HADR jedno wystąpienie bazy danych na jednej z maszyn wirtualnych platformy Azure ma rolę wystąpienia podstawowego. Wszyscy klienci są połączeni z wystąpieniem podstawowym. Wszystkie zmiany transakcji bazy danych są utrwalane lokalnie w dzienniku transakcji db2. Ponieważ rekordy dziennika transakcji są utrwalane lokalnie, rekordy są przesyłane za pośrednictwem protokołu TCP/IP do wystąpienia bazy danych na drugim serwerze bazy danych, serwerze rezerwowym lub wystąpieniu rezerwowym. Wystąpienie rezerwowe aktualizuje lokalną bazę danych przez przeniesienie przeniesionych rekordów dziennika transakcji. W ten sposób serwer rezerwowy jest synchronizowany z serwerem podstawowym.
USŁUGA HADR jest tylko funkcją replikacji. Nie ma wykrywania błędów i nie ma automatycznych funkcji przejęcia ani trybu failover. Przejęcie lub przeniesienie na serwer rezerwowy musi zostać zainicjowane ręcznie przez administratora bazy danych. Aby osiągnąć automatyczne przejęcie i wykrywanie błędów, możesz użyć funkcji klastrowania Pacemaker systemu Linux. Program Pacemaker monitoruje dwa wystąpienia serwera bazy danych. W przypadku awarii wystąpienia podstawowego serwera bazy danych program Pacemaker inicjuje automatyczne przejęcie usługi HADR przez serwer rezerwowy. Program Pacemaker zapewnia również przypisanie wirtualnego adresu IP do nowego serwera podstawowego.
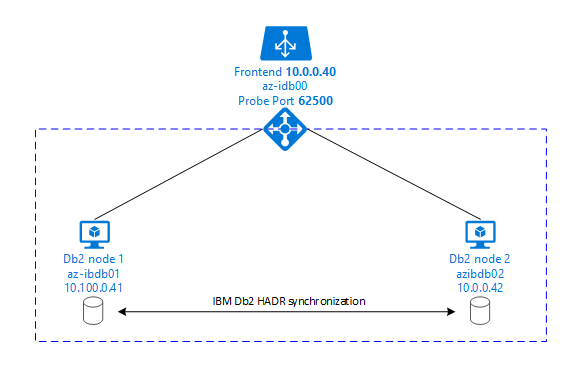
Aby serwery aplikacji SAP łączyły się z podstawową bazą danych, potrzebna jest nazwa hosta wirtualnego i wirtualny adres IP. Po przejściu w tryb failover serwery aplikacji SAP łączą się z nowym podstawowym wystąpieniem bazy danych. W środowisku platformy Azure moduł równoważenia obciążenia platformy Azure jest wymagany do używania wirtualnego adresu IP w sposób wymagany dla usługi HADR firmy IBM Db2.
Aby w pełni zrozumieć, jak system IBM Db2 LUW z usługami HADR i Pacemaker pasuje do konfiguracji systemu SAP o wysokiej dostępności, na poniższej ilustracji przedstawiono omówienie konfiguracji systemu SAP o wysokiej dostępności opartej na bazie danych IBM Db2. W tym artykule opisano tylko ibm Db2, ale zawiera on odwołania do innych artykułów dotyczących konfigurowania innych składników systemu SAP.

Ogólne omówienie wymaganych kroków
Aby wdrożyć konfigurację ibm Db2, należy wykonać następujące kroki:
- Planowanie środowiska.
- Wdrażanie maszyn wirtualnych.
- Zaktualizuj system RHEL Linux i skonfiguruj systemy plików.
- Instalowanie i konfigurowanie programu Pacemaker.
- Konfigurowanie klastra glusterfs lub usługi Azure NetApp Files
- Zainstaluj usługę ASCS/ERS w oddzielnym klastrze.
- Zainstaluj bazę danych IBM Db2 z opcją rozproszonej/wysokiej dostępności (SWPM).
- Zainstaluj i utwórz pomocniczy węzeł bazy danych oraz wystąpienie i skonfiguruj usługę HADR.
- Upewnij się, że usługa HADR działa.
- Zastosuj konfigurację programu Pacemaker, aby kontrolować ibm Db2.
- Konfigurowanie usługi Azure Load Balancer.
- Zainstaluj podstawowe i okna dialogowe serwery aplikacji.
- Sprawdź i dostosuj konfigurację serwerów aplikacji SAP.
- Przeprowadź testy przejścia w tryb failover i przejęcia.
Planowanie infrastruktury platformy Azure na potrzeby hostowania systemu IBM Db2 LUW za pomocą usługi HADR
Przed wykonaniem wdrożenia ukończ proces planowania. Planowanie tworzy podstawy wdrażania konfiguracji bazy danych Db2 z usługą HADR na platformie Azure. Kluczowe elementy, które muszą być częścią planowania usługi IMB Db2 LUW (część bazy danych środowiska SAP) są wymienione w poniższej tabeli:
| Temat | Krótki opis |
|---|---|
| Definiowanie grup zasobów platformy Azure | Grupy zasobów, w których wdrażasz maszynę wirtualną, sieć wirtualną, usługę Azure Load Balancer i inne zasoby. Może być istniejący lub nowy. |
| Definicja sieci wirtualnej/podsieci | Gdzie są wdrażane maszyny wirtualne dla produktów IBM Db2 i Azure Load Balancer. Może być istniejący lub nowo utworzony. |
| Maszyny wirtualne hostowania systemu IBM Db2 LUW | Rozmiar maszyny wirtualnej, magazyn, sieć, adres IP. |
| Nazwa hosta wirtualnego i wirtualny adres IP bazy danych IBM Db2 | Wirtualny adres IP lub nazwa hosta jest używana na potrzeby połączenia serwerów aplikacji SAP. db-virt-hostname, db-virt-ip. |
| Ogrodzenie platformy Azure | Zapobiega się metodom unikania podziałów sytuacji mózgu. |
| Azure Load Balancer | Użycie standardowego (zalecanego), portu sondy dla bazy danych Db2 (rekomendacja 62500) — port sondy. |
| Rozpoznawanie nazw | Jak działa rozpoznawanie nazw w środowisku. Usługa DNS jest zdecydowanie zalecana. Można użyć pliku hostów lokalnych. |
Aby uzyskać więcej informacji na temat programu Pacemaker systemu Linux na platformie Azure, zobacz Konfigurowanie programu Pacemaker w systemie Red Hat Enterprise Linux na platformie Azure.
Ważne
W przypadku bazy danych Db2 w wersji 11.5.6 lub nowszej zdecydowanie zalecamy rozwiązanie zintegrowane przy użyciu programu Pacemaker firmy IBM.
Wdrażanie w systemie Red Hat Enterprise Linux
Agent zasobów dla systemu IBM Db2 LUW jest zawarty w dodatku Red Hat Enterprise Linux Server HA. W przypadku konfiguracji opisanej w tym dokumencie należy użyć oprogramowania Red Hat Enterprise Linux dla oprogramowania SAP. Witryna Azure Marketplace zawiera obraz systemu Red Hat Enterprise Linux 7.4 dla oprogramowania SAP lub nowszego, którego można użyć do wdrożenia nowych maszyn wirtualnych platformy Azure. Należy pamiętać o różnych modelach pomocy technicznej lub usług oferowanych przez firmę Red Hat za pośrednictwem witryny Azure Marketplace podczas wybierania obrazu maszyny wirtualnej w witrynie Azure VM Marketplace.
Hosty: aktualizacje DNS
Utwórz listę wszystkich nazw hostów, w tym nazw hostów wirtualnych, i zaktualizuj serwery DNS, aby umożliwić prawidłowe adresy IP rozpoznawania nazw hostów. Jeśli serwer DNS nie istnieje lub nie możesz zaktualizować i utworzyć wpisów DNS, musisz użyć lokalnych plików hosta poszczególnych maszyn wirtualnych uczestniczących w tym scenariuszu. Jeśli używasz wpisów plików hosta, upewnij się, że wpisy są stosowane do wszystkich maszyn wirtualnych w środowisku systemu SAP. Zalecamy jednak użycie usługi DNS, która w idealnym przypadku rozciąga się na platformę Azure
Wdrażanie ręczne
Upewnij się, że wybrany system operacyjny jest obsługiwany przez firmę IBM/SAP dla systemu IBM Db2 LUW. Lista obsługiwanych wersji systemu operacyjnego dla maszyn wirtualnych platformy Azure i wersji Db2 jest dostępna w uwagach sap 1928533. Lista wydań systemu operacyjnego według poszczególnych wersji db2 jest dostępna w macierzy dostępności produktów SAP. Zdecydowanie zalecamy co najmniej system Red Hat Enterprise Linux 7.4 dla oprogramowania SAP ze względu na ulepszenia wydajności związane z platformą Azure w tej lub nowszej wersji systemu Red Hat Enterprise Linux.
- Utwórz lub wybierz grupę zasobów.
- Utwórz lub wybierz sieć wirtualną i podsieć.
- Wybierz odpowiedni typ wdrożenia dla maszyn wirtualnych SAP. Zazwyczaj zestaw skalowania maszyn wirtualnych z elastyczną aranżacją.
- Utwórz maszynę wirtualną 1.
- Użyj obrazu oprogramowania Red Hat Enterprise Linux dla oprogramowania SAP w witrynie Azure Marketplace.
- Wybierz zestaw skalowania, strefę dostępności lub zestaw dostępności utworzony w kroku 3.
- Utwórz maszynę wirtualną 2.
- Użyj obrazu oprogramowania Red Hat Enterprise Linux dla oprogramowania SAP w witrynie Azure Marketplace.
- Wybierz zestaw skalowania, strefę dostępności lub zestaw dostępności utworzony w kroku 3 (nie tę samą strefę co w kroku 4).
- Dodaj dyski danych do maszyn wirtualnych, a następnie sprawdź zalecenie konfiguracji systemu plików w artykule IBM Db2 Azure Virtual Machines DBMS deployment for SAP workload (Wdrażanie programu DBMS maszyn wirtualnych platformy AZURE w usłudze IBM Db2 Azure Virtual Machines dla obciążenia SAP).
Instalowanie środowiska IBM Db2 LUW i SAP
Przed rozpoczęciem instalacji środowiska SAP opartego na systemie IBM Db2 LUW zapoznaj się z następującą dokumentacją:
- Dokumentacja platformy Azure.
- Dokumentacja oprogramowania SAP.
- Dokumentacja firmy IBM.
Linki do tej dokumentacji znajdują się w sekcji wprowadzającej tego artykułu.
Zapoznaj się z podręcznikami instalacji oprogramowania SAP dotyczącymi instalowania aplikacji opartych na oprogramowaniu NetWeaver w systemie IBM Db2 LUW. Przewodniki można znaleźć w portalu pomocy sap, korzystając z narzędzia SAP Installation Guide Finder.
Liczbę przewodników wyświetlanych w portalu można zmniejszyć, ustawiając następujące filtry:
- Chcę: Zainstaluj nowy system.
- Moja baza danych: IBM Db2 dla systemów Linux, Unix i Windows.
- Dodatkowe filtry dla wersji oprogramowania SAP NetWeaver, konfiguracji stosu lub systemu operacyjnego.
Reguły zapory Red Hat
System Red Hat Enterprise Linux domyślnie ma włączoną zaporę.
#Allow access to SWPM tool. Rule is not permanent.
sudo firewall-cmd --add-port=4237/tcp
Wskazówki instalacji dotyczące konfigurowania systemu IBM Db2 LUW z usługą HADR
Aby skonfigurować podstawowe wystąpienie bazy danych IBM Db2 LUW:
- Użyj opcji wysokiej dostępności lub rozproszonej.
- Zainstaluj wystąpienie sap ASCS/ERS i bazy danych.
- Utwórz kopię zapasową nowo zainstalowanej bazy danych.
Ważne
Zapisz port "Port komunikacji bazy danych", który jest ustawiony podczas instalacji. Musi to być ten sam numer portu dla obu wystąpień bazy danych.
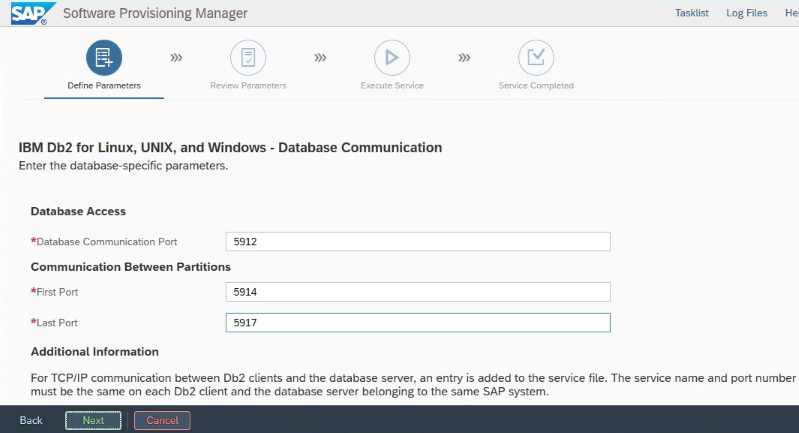
Ustawienia usługi HADR ibm Db2 dla platformy Azure
W przypadku korzystania z agenta ogrodzenia usługi Azure Pacemaker ustaw następujące parametry:
- Czas trwania okna równorzędnego usługi HADR (w sekundach) (HADR_PEER_WINDOW) = 240
- Wartość limitu czasu usługi HADR (HADR_TIMEOUT) = 45
Zalecamy poprzednie parametry na podstawie początkowego testowania trybu failover/przejęcia. Wymagane jest przetestowanie prawidłowej funkcjonalności trybu failover i przejęcia przy użyciu tych ustawień parametrów. Ponieważ poszczególne konfiguracje mogą się różnić, parametry mogą wymagać dostosowania.
Uwaga
Specyficzne dla programu IBM Db2 z konfiguracją usługi HADR z normalnym uruchamianiem: wystąpienie pomocniczej lub rezerwowej bazy danych musi być uruchomione przed uruchomieniem podstawowego wystąpienia bazy danych.
Uwaga
W przypadku instalacji i konfiguracji specyficznej dla platformy Azure i programu Pacemaker: podczas procedury instalacji za pośrednictwem programu SAP Software Provisioning Manager istnieje jawne pytanie dotyczące wysokiej dostępności systemu IBM Db2 LUW:
- Nie wybieraj bazy danych IBM Db2 pureScale.
- Nie wybieraj opcji Zainstaluj automatyzację systemu IBM Ibm Ibm Dla wieluplatform.
- Nie wybieraj pozycji Generuj pliki konfiguracji klastra.
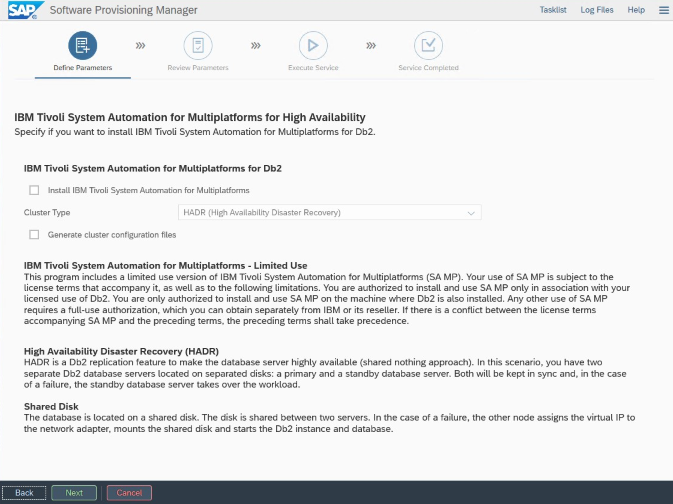
Aby skonfigurować serwer bazy danych rezerwowej przy użyciu procedury kopiowania homogenicznego systemu SAP, wykonaj następujące kroki:
- Wybierz opcję Kopiowanie systemu Docelowe >systemy>rozproszonej> bazy danych.
- Jako metodę kopiowania wybierz pozycję Homogeniczny system , aby można było użyć kopii zapasowej w celu przywrócenia kopii zapasowej w wystąpieniu serwera rezerwowego.
- Po osiągnięciu kroku zakończenia w celu przywrócenia bazy danych na potrzeby jednorodnej kopii systemu zamknij instalatora. Przywróć bazę danych z kopii zapasowej hosta podstawowego. Wszystkie kolejne fazy instalacji zostały już wykonane na podstawowym serwerze bazy danych.
Reguły zapory systemu Red Hat dla usługi HADR DB2
Dodaj reguły zapory, aby zezwolić na działanie ruchu do bazy danych DB2 i między bazą danych DB2 dla usługi HADR:
- Port komunikacji bazy danych. W przypadku używania partycji należy również dodać te porty.
- Port HADR (wartość parametru DB2 HADR_LOCAL_SVC).
- Port sondy platformy Azure.
sudo firewall-cmd --add-port=<port>/tcp --permanent
sudo firewall-cmd --reload
Sprawdzanie usługi HADR IBM Db2
W celach demonstracyjnych i procedurach opisanych w tym artykule identyfikator SID bazy danych ma identyfikator ID2.
Po skonfigurowaniu usługi HADR, a stan to PEER i CONNECTED w węzłach podstawowych i rezerwowych, wykonaj następujące sprawdzanie:
Execute command as db2<sid> db2pd -hadr -db <SID>
#Primary output:
Database Member 0 -- Database ID2 -- Active -- Up 1 days 15:45:23 -- Date 2019-06-25-10.55.25.349375
HADR_ROLE = PRIMARY
REPLAY_TYPE = PHYSICAL
HADR_SYNCMODE = NEARSYNC
STANDBY_ID = 1
LOG_STREAM_ID = 0
HADR_STATE = PEER
HADR_FLAGS =
PRIMARY_MEMBER_HOST = az-idb01
PRIMARY_INSTANCE = db2id2
PRIMARY_MEMBER = 0
STANDBY_MEMBER_HOST = az-idb02
STANDBY_INSTANCE = db2id2
STANDBY_MEMBER = 0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 06/25/2019 10:55:05.076494 (1561460105)
HEARTBEAT_INTERVAL(seconds) = 7
HEARTBEAT_MISSED = 5
HEARTBEAT_EXPECTED = 52
HADR_TIMEOUT(seconds) = 30
TIME_SINCE_LAST_RECV(seconds) = 5
PEER_WAIT_LIMIT(seconds) = 0
LOG_HADR_WAIT_CUR(seconds) = 0.000
LOG_HADR_WAIT_RECENT_AVG(seconds) = 598.000027
LOG_HADR_WAIT_ACCUMULATED(seconds) = 598.000
LOG_HADR_WAIT_COUNT = 1
SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 369280
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
HADR_LOG_GAP(bytes) = 132242668
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_RECV_REPLAY_GAP(bytes) = 0
PRIMARY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_REPLAY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_RECV_BUF_SIZE(pages) = 2048
STANDBY_RECV_BUF_PERCENT = 0
STANDBY_SPOOL_LIMIT(pages) = 1000
STANDBY_SPOOL_PERCENT = 0
STANDBY_ERROR_TIME = NULL
PEER_WINDOW(seconds) = 300
PEER_WINDOW_END = 06/25/2019 11:12:03.000000 (1561461123)
READS_ON_STANDBY_ENABLED = N
#Secondary output:
Database Member 0 -- Database ID2 -- Standby -- Up 1 days 15:45:18 -- Date 2019-06-25-10.56.19.820474
HADR_ROLE = STANDBY
REPLAY_TYPE = PHYSICAL
HADR_SYNCMODE = NEARSYNC
STANDBY_ID = 0
LOG_STREAM_ID = 0
HADR_STATE = PEER
HADR_FLAGS =
PRIMARY_MEMBER_HOST = az-idb01
PRIMARY_INSTANCE = db2id2
PRIMARY_MEMBER = 0
STANDBY_MEMBER_HOST = az-idb02
STANDBY_INSTANCE = db2id2
STANDBY_MEMBER = 0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 06/25/2019 10:55:05.078116 (1561460105)
HEARTBEAT_INTERVAL(seconds) = 7
HEARTBEAT_MISSED = 0
HEARTBEAT_EXPECTED = 10
HADR_TIMEOUT(seconds) = 30
TIME_SINCE_LAST_RECV(seconds) = 1
PEER_WAIT_LIMIT(seconds) = 0
LOG_HADR_WAIT_CUR(seconds) = 0.000
LOG_HADR_WAIT_RECENT_AVG(seconds) = 598.000027
LOG_HADR_WAIT_ACCUMULATED(seconds) = 598.000
LOG_HADR_WAIT_COUNT = 1
SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 367360
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
HADR_LOG_GAP(bytes) = 0
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_RECV_REPLAY_GAP(bytes) = 0
PRIMARY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_REPLAY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_RECV_BUF_SIZE(pages) = 2048
STANDBY_RECV_BUF_PERCENT = 0
STANDBY_SPOOL_LIMIT(pages) = 1000
STANDBY_SPOOL_PERCENT = 0
STANDBY_ERROR_TIME = NULL
PEER_WINDOW(seconds) = 1000
PEER_WINDOW_END = 06/25/2019 11:12:59.000000 (1561461179)
READS_ON_STANDBY_ENABLED = N
Konfigurowanie modułu Azure Load Balancer
Podczas konfigurowania maszyny wirtualnej masz możliwość utworzenia lub wybrania wyjścia z modułu równoważenia obciążenia w sekcji dotyczącej sieci. Wykonaj poniższe kroki, aby skonfigurować standardowy moduł równoważenia obciążenia na potrzeby konfiguracji bazy danych DB2 o wysokiej dostępności.
Wykonaj kroki opisane w temacie Tworzenie modułu równoważenia obciążenia, aby skonfigurować standardowy moduł równoważenia obciążenia dla systemu SAP o wysokiej dostępności przy użyciu witryny Azure Portal. Podczas konfigurowania modułu równoważenia obciążenia należy wziąć pod uwagę następujące kwestie:
- Konfiguracja adresu IP frontonu: utwórz adres IP frontonu. Wybierz tę samą sieć wirtualną i nazwę podsieci co maszyny wirtualne bazy danych.
- Pula zaplecza: utwórz pulę zaplecza i dodaj maszyny wirtualne bazy danych.
- Reguły ruchu przychodzącego: utwórz regułę równoważenia obciążenia. Wykonaj te same kroki dla obu reguł równoważenia obciążenia.
- Adres IP frontonu: wybierz adres IP frontonu.
- Pula zaplecza: wybierz pulę zaplecza.
- Porty wysokiej dostępności: wybierz tę opcję.
- Protokół: wybierz pozycję TCP.
- Sonda kondycji: utwórz sondę kondycji z następującymi szczegółami:
- Protokół: wybierz pozycję TCP.
- Port: na przykład 625<instance-no.>.
- Interwał: wprowadź wartość 5.
- Próg sondy: wprowadź wartość 2.
- Limit czasu bezczynności (w minutach): wprowadź wartość 30.
- Włącz pływający adres IP: wybierz tę opcję.
Uwaga
Właściwość numberOfProbeskonfiguracji sondy kondycji , inaczej znana jako próg złej kondycji w portalu, nie jest uwzględniana. Aby kontrolować liczbę pomyślnych lub zakończonych niepowodzeniem kolejnych sond, ustaw właściwość probeThreshold na 2wartość . Obecnie nie można ustawić tej właściwości przy użyciu witryny Azure Portal, dlatego użyj interfejsu wiersza polecenia platformy Azure lub polecenia programu PowerShell.
Uwaga
Jeśli maszyny wirtualne bez publicznych adresów IP są umieszczane w puli zaplecza wystąpienia wewnętrznego (bez publicznego adresu IP) usługi Azure Load Balancer w warstwie Standardowa, nie ma wychodzącej łączności z Internetem, chyba że zostanie wykonana więcej konfiguracji, aby umożliwić routing do publicznych punktów końcowych. Aby uzyskać więcej informacji na temat uzyskiwania łączności wychodzącej, zobacz Publiczna łączność punktów końcowych dla maszyn wirtualnych korzystających z usługi Azure usługa Load Balancer w warstwie Standardowa w scenariuszach wysokiej dostępności oprogramowania SAP.
Ważne
Nie włączaj sygnatur czasowych PROTOKOŁU TCP na maszynach wirtualnych platformy Azure umieszczonych za usługą Azure Load Balancer. Włączenie sygnatur czasowych protokołu TCP może spowodować niepowodzenie sond kondycji. Ustaw parametr net.ipv4.tcp_timestamps na 0. Aby uzyskać więcej informacji, zobacz Load Balancer health probes (Sondy kondycji usługi Load Balancer).
[A] Dodaj regułę zapory dla portu sondy:
sudo firewall-cmd --add-port=<probe-port>/tcp --permanent
sudo firewall-cmd --reload
Tworzenie klastra Pacemaker
Aby utworzyć podstawowy klaster Pacemaker dla tego serwera IBM Db2, zobacz Konfigurowanie programu Pacemaker w systemie Red Hat Enterprise Linux na platformie Azure.
Konfiguracja programu Pacemaker Db2
Jeśli używasz programu Pacemaker do automatycznego trybu failover w przypadku awarii węzła, należy odpowiednio skonfigurować wystąpienia bazy danych Db2 i program Pacemaker. W tej sekcji opisano ten typ konfiguracji.
Następujące elementy są poprzedzone prefiksem:
- [A]: Dotyczy wszystkich węzłów
- [1]: Dotyczy tylko węzła 1
- [2]: Dotyczy tylko węzła 2
[A] Wymaganie wstępne dotyczące konfiguracji programu Pacemaker:
Zamknij oba serwery baz danych przy użyciu identyfikatora SID> użytkownika db2<z bazą danych db2stop.
Zmień środowisko powłoki dla użytkownika sid> db2<na /bin/ksh:
# Install korn shell: sudo yum install ksh # Change users shell: sudo usermod -s /bin/ksh db2<sid>
Konfiguracja programu Pacemaker
[1] Konfiguracja narzędzia Pacemaker specyficznego dla usługi HADR firmy IBM Db2:
# Put Pacemaker into maintenance mode sudo pcs property set maintenance-mode=true[1] Tworzenie zasobów IBM Db2:
Jeśli tworzysz klaster w systemie RHEL 7.x, pamiętaj, aby zaktualizować agentów zasobów pakietu do wersji lub nowszej
resource-agents-4.1.1-61.el7_9.15. Użyj następujących poleceń, aby utworzyć zasoby klastra:# Replace bold strings with your instance name db2sid, database SID, and virtual IP address/Azure Load Balancer. sudo pcs resource create Db2_HADR_ID2 db2 instance='db2id2' dblist='ID2' master meta notify=true resource-stickiness=5000 #Configure resource stickiness and correct cluster notifications for master resource sudo pcs resource update Db2_HADR_ID2-master meta notify=true resource-stickiness=5000 # Configure virtual IP - same as Azure Load Balancer IP sudo pcs resource create vip_db2id2_ID2 IPaddr2 ip='10.100.0.40' # Configure probe port for Azure load Balancer sudo pcs resource create nc_db2id2_ID2 azure-lb port=62500 #Create a group for ip and Azure loadbalancer probe port sudo pcs resource group add g_ipnc_db2id2_ID2 vip_db2id2_ID2 nc_db2id2_ID2 #Create colocation constrain - keep Db2 HADR Master and Group on same node sudo pcs constraint colocation add g_ipnc_db2id2_ID2 with master Db2_HADR_ID2-master #Create start order constrain sudo pcs constraint order promote Db2_HADR_ID2-master then g_ipnc_db2id2_ID2Jeśli tworzysz klaster w systemie RHEL 8.x, pamiętaj, aby zaktualizować agentów zasobów pakietu do wersji lub nowszej
resource-agents-4.1.1-93.el8. Aby uzyskać szczegółowe informacje, zobacz Zasób Red Hat KBAdb2z usługą HADR kończy się niepowodzeniem i stanemPRIMARY/REMOTE_CATCHUP_PENDING/CONNECTED. Użyj następujących poleceń, aby utworzyć zasoby klastra:# Replace bold strings with your instance name db2sid, database SID, and virtual IP address/Azure Load Balancer. sudo pcs resource create Db2_HADR_ID2 db2 instance='db2id2' dblist='ID2' promotable meta notify=true resource-stickiness=5000 #Configure resource stickiness and correct cluster notifications for master resource sudo pcs resource update Db2_HADR_ID2-clone meta notify=true resource-stickiness=5000 # Configure virtual IP - same as Azure Load Balancer IP sudo pcs resource create vip_db2id2_ID2 IPaddr2 ip='10.100.0.40' # Configure probe port for Azure load Balancer sudo pcs resource create nc_db2id2_ID2 azure-lb port=62500 #Create a group for ip and Azure loadbalancer probe port sudo pcs resource group add g_ipnc_db2id2_ID2 vip_db2id2_ID2 nc_db2id2_ID2 #Create colocation constrain - keep Db2 HADR Master and Group on same node sudo pcs constraint colocation add g_ipnc_db2id2_ID2 with master Db2_HADR_ID2-clone #Create start order constrain sudo pcs constraint order promote Db2_HADR_ID2-clone then g_ipnc_db2id2_ID2[1] Uruchamianie zasobów IBM Db2:
Wyjmij program Pacemaker z trybu konserwacji.
# Put Pacemaker out of maintenance-mode - that start IBM Db2 sudo pcs property set maintenance-mode=false[1] Upewnij się, że stan klastra jest prawidłowy i że wszystkie zasoby są uruchomione. Nie jest ważne, w którym węźle działają zasoby.
sudo pcs status 2 nodes configured 5 resources configured Online: [ az-idb01 az-idb02 ] Full list of resources: rsc_st_azure (stonith:fence_azure_arm): Started az-idb01 Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2] Masters: [ az-idb01 ] Slaves: [ az-idb02 ] Resource Group: g_ipnc_db2id2_ID2 vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01 nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
Ważne
Należy zarządzać wystąpieniem klastrowanej bazy danych Db2 programu Pacemaker przy użyciu narzędzi pacemaker. Jeśli używasz poleceń db2, takich jak db2stop, program Pacemaker wykryje akcję jako błąd zasobu. Jeśli przeprowadzasz konserwację, możesz umieścić węzły lub zasoby w trybie konserwacji. Program Pacemaker zawiesza zasoby monitorowania, a następnie można użyć normalnych poleceń administracyjnych db2.
Wprowadzanie zmian w profilach SAP w celu używania wirtualnego adresu IP na potrzeby połączenia
Aby nawiązać połączenie z podstawowym wystąpieniem konfiguracji usługi HADR, warstwa aplikacji SAP musi używać wirtualnego adresu IP zdefiniowanego i skonfigurowanego dla usługi Azure Load Balancer. Wymagane są następujące zmiany:
/sapmnt/SID>/<profile/DEFAULT. PFL
SAPDBHOST = db-virt-hostname
j2ee/dbhost = db-virt-hostname
/sapmnt/SID>/<global/db6/db2cli.ini
Hostname=db-virt-hostname
Instalowanie serwerów aplikacji podstawowych i dialogowych
Podczas instalowania podstawowych i dialogowych serwerów aplikacji względem konfiguracji usługi HADR db2 użyj nazwy hosta wirtualnego wybranej dla konfiguracji.
Jeśli instalacja została wykonana przed utworzeniem konfiguracji db2 HADR, wprowadź zmiany zgodnie z opisem w poprzedniej sekcji i w następujący sposób dla stosów SAP Java.
Sprawdzanie adresu URL JDBC w systemach stosu ABAP+Java lub Java
Użyj narzędzia J2EE Config, aby sprawdzić lub zaktualizować adres URL JDBC. Ponieważ narzędzie Config J2EE jest narzędziem graficznym, musisz mieć zainstalowany serwer X:
Zaloguj się do podstawowego serwera aplikacji wystąpienia J2EE i wykonaj następujące polecenie:
sudo /usr/sap/*SID*/*Instance*/j2ee/configtool/configtool.shW lewej ramce wybierz pozycję Magazyn zabezpieczeń.
W prawej ramce wybierz klucz
jdbc/pool/\<SAPSID>/url.Zmień nazwę hosta w adresie URL JDBC na nazwę hosta wirtualnego.
jdbc:db2://db-virt-hostname:5912/TSP:deferPrepares=0Wybierz Dodaj.
Aby zapisać zmiany, wybierz ikonę dysku w lewym górnym rogu.
Zamknij narzędzie konfiguracji.
Uruchom ponownie wystąpienie języka Java.
Konfigurowanie archiwizowania dzienników dla konfiguracji usługi HADR
Aby skonfigurować archiwizowanie dzienników db2 dla konfiguracji usługi HADR, zalecamy skonfigurowanie zarówno podstawowej, jak i rezerwowej bazy danych w celu automatycznego pobierania dzienników ze wszystkich lokalizacji archiwum dzienników. Zarówno podstawowa, jak i rezerwowa baza danych musi mieć możliwość pobierania plików archiwum dziennika ze wszystkich lokalizacji archiwum dziennika, do których jeden z wystąpień bazy danych może archiwizować pliki dziennika.
Archiwizacja dziennika jest wykonywana tylko przez podstawową bazę danych. Jeśli zmienisz role usługi HADR serwerów baz danych lub wystąpi awaria, nowa podstawowa baza danych jest odpowiedzialna za archiwizowanie dzienników. Jeśli skonfigurowano wiele lokalizacji archiwum dzienników, dzienniki mogą być archiwizowane dwa razy. W przypadku lokalnego lub zdalnego nadrobienia zaległości może być również konieczne ręczne skopiowanie zarchiwizowanych dzienników ze starego serwera podstawowego do aktywnej lokalizacji dziennika nowego serwera podstawowego.
Zalecamy skonfigurowanie wspólnego udziału NFS lub glusterFS, w którym dzienniki są zapisywane z obu węzłów. Udział NFS lub GlusterFS musi być wysoce dostępny.
Do transportu lub katalogu profilów można użyć istniejących udziałów NFS o wysokiej dostępności lub glusterFS. Aby uzyskać więcej informacji, zobacz:
- GlusterFS na maszynach wirtualnych platformy Azure w systemie Red Hat Enterprise Linux dla oprogramowania SAP NetWeaver.
- Wysoka dostępność oprogramowania SAP NetWeaver na maszynach wirtualnych platformy Azure w systemie Red Hat Enterprise Linux przy użyciu usługi Azure NetApp Files for SAP Applications.
- Azure NetApp Files (w celu utworzenia udziałów NFS).
Testowanie konfiguracji klastra
W tej sekcji opisano sposób testowania konfiguracji usługi HADR db2. Każdy test zakłada, że baza danych IBM Db2 jest uruchomiona na maszynie wirtualnej az-idb01 . Należy użyć użytkownika z uprawnieniami sudo lub użytkownikiem głównym (niezalecane).
Stan początkowy dla wszystkich przypadków testowych jest wyjaśniony tutaj: (crm_mon -r lub pcs status)
- stan pcs to migawka stanu programu Pacemaker w czasie wykonywania.
- crm_mon -r to ciągłe dane wyjściowe stanu programu Pacemaker.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
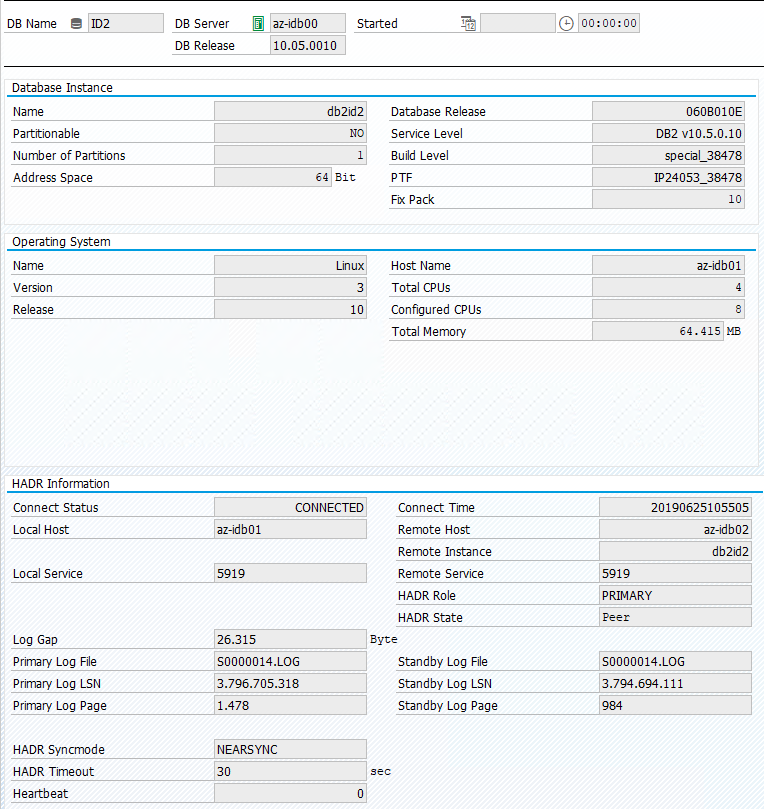
Oryginalny stan w systemie SAP jest udokumentowany w temacie Transaction DBACOCKPIT Configuration Overview (Omówienie konfiguracji > DBACOCKPIT > transakcji), jak pokazano na poniższej ilustracji:
Testowe przejęcie IBM Db2
Ważne
Przed rozpoczęciem testu upewnij się, że:
Program Pacemaker nie ma żadnych nieudanych akcji (stan pcs).
Brak ograniczeń lokalizacji (resztki testu migracji).
Synchronizacja usługi HADR IBM Db2 działa. Sprawdź identyfikator SID> użytkownika db2<.
db2pd -hadr -db <DBSID>
Przeprowadź migrację węzła, w którym działa podstawowa baza danych Db2, wykonując następujące polecenie:
# On RHEL 7.x
sudo pcs resource move Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource move Db2_HADR_ID2-clone --master
Po zakończeniu migracji dane wyjściowe stanu crm wyglądają następująco:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Oryginalny stan w systemie SAP jest udokumentowany w temacie Transaction DBACOCKPIT Configuration Overview (Omówienie konfiguracji > DBACOCKPIT > transakcji), jak pokazano na poniższej ilustracji:
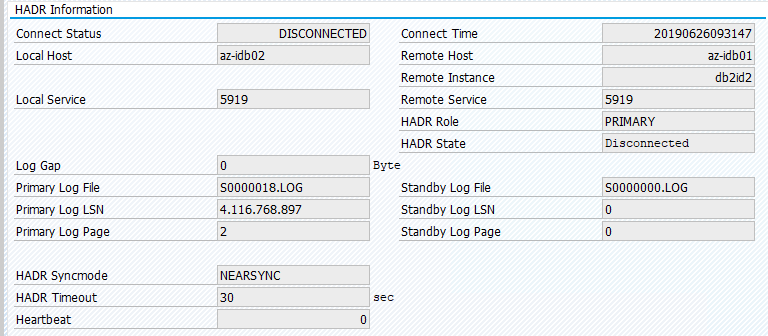
Migracja zasobów za pomocą polecenia "przenoszenie zasobów pcs" tworzy ograniczenia lokalizacji. Ograniczenia lokalizacji w tym przypadku uniemożliwiają uruchomienie wystąpienia IBM Db2 na az-idb01. Jeśli ograniczenia lokalizacji nie zostaną usunięte, zasób nie może powrócić po awarii.
Usunięcie ograniczenia lokalizacji i węzła rezerwowego zostanie uruchomione na az-idb01.
# On RHEL 7.x
sudo pcs resource clear Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource clear Db2_HADR_ID2-clone
A stan klastra zmienia się na:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
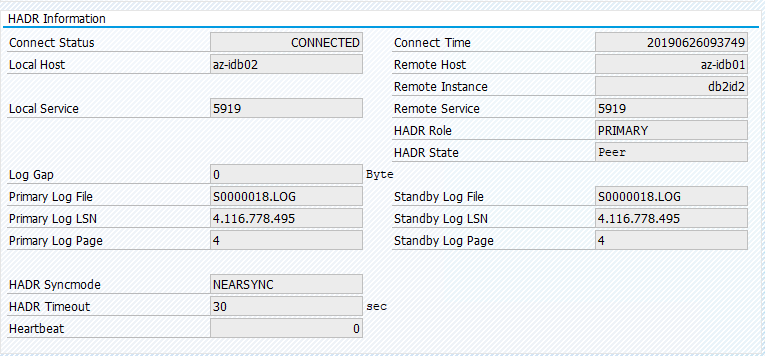
Przeprowadź migrację zasobu z powrotem do polecenia az-idb01 i wyczyść ograniczenia lokalizacji
# On RHEL 7.x
sudo pcs resource move Db2_HADR_ID2-master az-idb01
sudo pcs resource clear Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource move Db2_HADR_ID2-clone --master
sudo pcs resource clear Db2_HADR_ID2-clone
- W systemie RHEL 7.x —
pcs resource move <resource_name> <host>: Tworzy ograniczenia lokalizacji i może powodować problemy z przejęciem - W systemie RHEL 8.x —
pcs resource move <resource_name> --master: Tworzy ograniczenia lokalizacji i może powodować problemy z przejęciem pcs resource clear <resource_name>: Czyści ograniczenia lokalizacjipcs resource cleanup <resource_name>: czyści wszystkie błędy zasobu
Testowanie ręcznego przejęcia
Ręczne przejęcie można przetestować, zatrzymując usługę Pacemaker w węźle az-idb01 :
systemctl stop pacemaker
stan na az-ibdb02
2 nodes configured
5 resources configured
Node az-idb01: pending
Online: [ az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
Po przejściu w tryb failover możesz ponownie uruchomić usługę w narzędziu az-idb01.
systemctl start pacemaker
Zabij proces Db2 w węźle, w ramach którego jest uruchamiana podstawowa baza danych hadR
#Kill main db2 process - db2sysc
[sapadmin@az-idb02 ~]$ sudo ps -ef|grep db2sysc
db2ptr 34598 34596 8 14:21 ? 00:00:07 db2sysc 0
[sapadmin@az-idb02 ~]$ sudo kill -9 34598
Wystąpienie bazy danych Db2 zakończy się niepowodzeniem, a program Pacemaker przeniesie węzeł główny i zgłosi następujący stan:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=49, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 09:57:35 2019', queued=0ms, exec=362ms
Program Pacemaker ponownie uruchamia podstawowe wystąpienie bazy danych Db2 w tym samym węźle lub przechodzi w tryb failover do węzła, w którym uruchomiono wystąpienie pomocniczej bazy danych, a zgłaszany jest błąd.
Zabij proces Db2 w węźle, w ramach którego uruchomiono wystąpienie pomocniczej bazy danych
[sapadmin@az-idb02 ~]$ sudo ps -ef|grep db2sysc
db2id2 23144 23142 2 09:53 ? 00:00:13 db2sysc 0
[sapadmin@az-idb02 ~]$ sudo kill -9 23144
Węzeł zostanie przełączony w błąd określony i zgłoszony błąd.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Failed Actions:
* Db2_HADR_ID2_monitor_20000 on az-idb02 'not running' (7): call=144, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 10:02:09 2019', queued=0ms, exec=0ms
Wystąpienie bazy danych Db2 zostanie uruchomione ponownie w roli pomocniczej, do której przypisano wcześniej.
Zatrzymaj bazę danych za pomocą polecenia db2stop force w węźle, w ramach którego uruchomiono podstawowe wystąpienie bazy danych usługi HADR
Jako użytkownik db2<sid> wykonaj polecenie db2stop force:
az-idb01:db2ptr> db2stop force
Wykryto błąd:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Slaves: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Stopped
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Stopped
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=110, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 14:03:12 2019', queued=0ms, exec=355ms
Wystąpienie pomocniczej bazy danych usługi DB2 HADR zostało podniesione do roli podstawowej.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=110, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 14:03:12 2019', queued=0ms, exec=355ms
Awaria maszyny wirtualnej, na której uruchomiono podstawowe wystąpienie bazy danych usługi HADR z "zatrzymaniem"
#Linux kernel panic.
sudo echo b > /proc/sysrq-trigger
W takim przypadku program Pacemaker wykrywa, że węzeł z uruchomionym wystąpieniem podstawowej bazy danych nie odpowiada.
2 nodes configured
5 resources configured
Node az-idb01: UNCLEAN (online)
Online: [ az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Następnym krokiem jest sprawdzenie sytuacji podzielonego mózgu . Po ustaleniu, że węzeł, który ostatni raz uruchomił wystąpienie podstawowej bazy danych, nie działa, jest wykonywany tryb failover zasobów.
2 nodes configured
5 resources configured
Online: [ az-idb02 ]
OFFLINE: [ az-idb01 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
W przypadku paniki jądra węzeł, który zakończył się niepowodzeniem, zostanie uruchomiony ponownie przez agenta ogrodzenia. Po powrocie węzła, który zakończył się niepowodzeniem, należy uruchomić klaster pacemaker według
sudo pcs cluster start
uruchamia wystąpienie bazy danych Db2 w roli pomocniczej.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02