Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano sposób konfigurowania podstawowego klastra Pacemaker na serwerze Red Hat Enterprise Server (RHEL). Instrukcje obejmują RHEL 7, RHEL 8 i RHEL 9.
Wymagania wstępne
Najpierw zapoznaj się z następującymi uwagami i artykułami SAP:
Dokumentacja wysokiej dostępności systemu RHEL (HA)
- Konfigurowanie klastrów wysokiej dostępności i zarządzanie nimi.
- Zasady obsługi klastrów wysokiej dostępności RHEL — sbd i fence_sbd.
- Zasady obsługi klastrów wysokiej dostępności RHEL — fence_azure_arm.
- Znane ograniczenia dotyczące emulowanego oprogramowania watchdog.
- Eksplorowanie składników wysokiej dostępności systemu RHEL — sbd i fence_sbd.
- Wskazówki dotyczące projektowania klastrów wysokiej dostępności RHEL — rozważania dotyczące sbd.
- Zagadnienia dotyczące wdrażania systemu RHEL 8 — wysoka dostępność i klastry
dokumentacja systemu RHEL specyficzna dla Azure
Dokumentacja systemu RHEL dla ofert SAP
- Zasady obsługi klastrów wysokiej dostępności RHEL — zarządzanie oprogramowaniem SAP S/4HANA w klastrze.
- Konfigurowanie programu SAP S/4HANA ASCS/ERS z wykorzystaniem samodzielnego serwera Enqueue 2 (ENSA2) w programie Pacemaker.
- Konfigurowanie replikacji systemu SAP HANA w klastrze Pacemaker.
- Rozwiązanie HA Red Hat Enterprise Linux dla SAP HANA Scale-Out i Replikacji Systemu.
Omówienie
Ważne
Klastry Pacemaker obejmujące wiele sieci wirtualnych/podsieci nie są objęte standardowymi zasadami pomocy technicznej.
W Azure dostępne są dwie opcje konfigurowania ogrodzenia w klastrze pacemaker dla systemu RHEL: agent ogrodzenia Azure, który uruchamia ponownie węzeł, który uległ awarii przez interfejsy API Azure, lub można użyć urządzenia SBD.
Ważne
W usłudze Azure klaster wysokiej dostępności RHEL z ogrodzeniem opartym na pamięci masowej (fence_sbd) używa programowo emulowanego watchdoga. Ważne jest, aby przejrzeć Software-Emulated Watchdog Znane ograniczenia i zasady pomocy technicznej dla klastrów wysokiej dostępności RHEL — sbd i fence_sbd podczas wybierania usługi SBD jako mechanizmu ogrodzenia.
Korzystanie z urządzenia SBD
Uwaga
Mechanizm ogrodzenia z funkcją SBD jest obsługiwany w systemach RHEL 8.8 i nowszych oraz RHEL 9.0 i nowszych.
Urządzenie SBD można skonfigurować przy użyciu jednej z dwóch opcji:
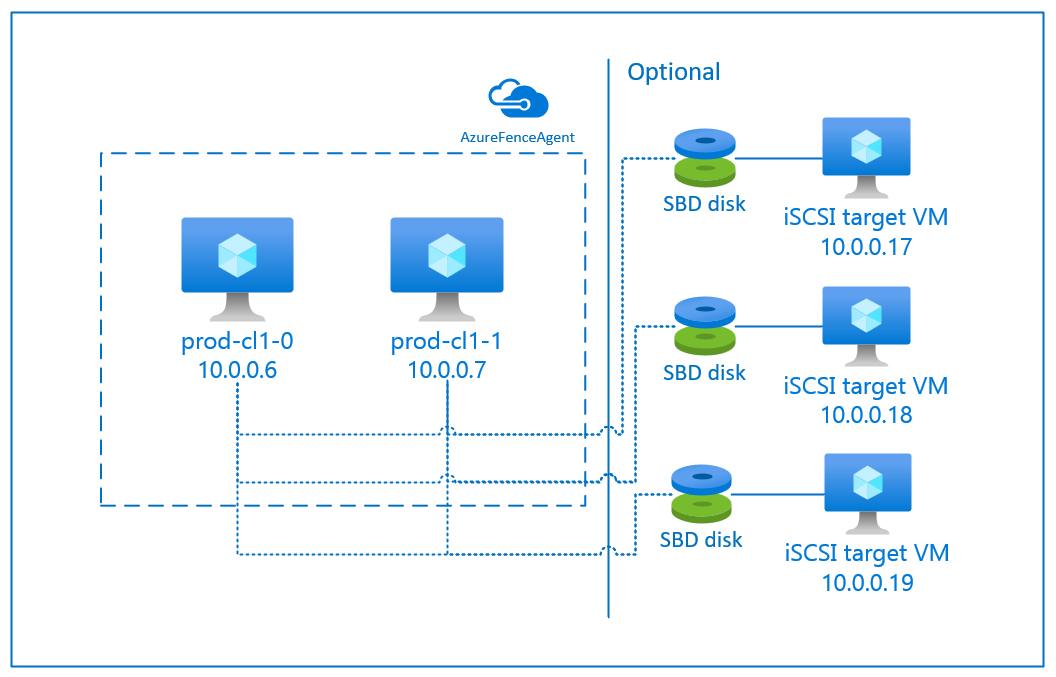
SBD z serwerem docelowym iSCSI
Urządzenie SBD wymaga co najmniej jednej dodatkowej maszyny wirtualnej, która działa jako serwer docelowy Internet Small Compute System Interface (iSCSI) i udostępnia urządzenie SBD. Te serwery docelowe iSCSI można jednak współdzielić z innymi klastrami pacemaker. Zaletą korzystania z urządzenia SBD jest to, że jeśli korzystasz już z urządzeń SBD lokalnie, nie wymagają one żadnych zmian sposobu działania klastra pacemaker.
Można użyć maksymalnie trzech urządzeń SBD w klastrze pacemaker, co pozwala na tymczasowe wyłączenie jednego z urządzeń SBD (na przykład podczas stosowania poprawek systemu operacyjnego na serwerze docelowym iSCSI). Jeśli chcesz użyć więcej niż jednego urządzenia SBD na rozrusznik, pamiętaj, aby wdrożyć wiele serwerów docelowych dla iSCSI i połączyć jedno urządzenie SBD z każdego serwera docelowego dla iSCSI. Zalecamy użycie jednego lub trzech urządzeń SBD. Program Pacemaker nie może automatycznie ogrodzać węzła klastra, jeśli skonfigurowano tylko dwa urządzenia SBD i jeden z nich jest niedostępny. Jeśli chcesz mieć możliwość ogrodzenia, gdy jeden serwer docelowy iSCSI nie działa, musisz użyć trzech urządzeń SBD i w związku z tym trzech serwerów docelowych iSCSI. Jest to najbardziej odporna konfiguracja podczas korzystania z dysków SSD.
Ważne
Podczas planowania wdrażania i konfigurowania węzłów klastra Pacemaker w systemie Linux oraz urządzeń SBD, nie zezwalaj na przesyłanie ruchu między maszynami wirtualnymi a maszynami wirtualnymi hostującymi urządzenia SBD przez jakiekolwiek inne urządzenia, takie jak wirtualne urządzenie sieciowe (NVA).
Zdarzenia konserwacji i inne problemy z NVA mogą mieć negatywny wpływ na stabilność i niezawodność ogólnej konfiguracji klastra. Aby uzyskać więcej informacji, zobacz Reguły routingu zdefiniowane przez użytkownika.
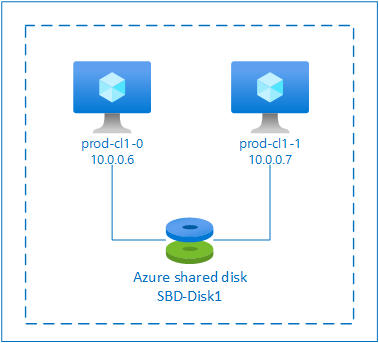
Usługa SBD z udostępnionym dyskiem Azure
Aby skonfigurować urządzenie SBD, należy dołączyć co najmniej jeden dysk udostępniony Azure do wszystkich maszyn wirtualnych będących częścią klastra pacemaker. Zaletą urządzenia SBD przy użyciu dysku udostępnionego Azure jest to, że nie trzeba wdrażać i konfigurować dodatkowych maszyn wirtualnych.
Poniżej przedstawiono kilka ważnych zagadnień dotyczących urządzeń SBD podczas konfigurowania przy użyciu Azure dysku udostępnionego:
- Dysk współdzielony Azure z dyskiem SSD w warstwie Premium, jest obsługiwany jako urządzenie SBD.
- Urządzenia SBD korzystające z dysku udostępnionego Azure są obsługiwane w systemie RHEL 8.8 lub nowszym.
- Urządzenia SBD korzystające z dysku współdzielonego Azure Premium są obsługiwane na lokalnie nadmiarowej pamięci masowej (LRS) i strefowo nadmiarowej pamięci masowej (ZRS).
- W zależności od typu wdrożenia wybierz odpowiedni magazyn redundantny na potrzeby dysku udostępnianego w Azure jako urządzenia SBD.
- Urządzenie SBD korzystające z magazynu LRS dla dysku udostępnionego w warstwie Azure Premium (skuName — Premium_LRS) jest obsługiwane tylko w przypadku wdrożenia regionalnego, takiego jak zestaw dostępności.
- Urządzenie SBD wykorzystujące magazyn ZRS dla dysku udostępnionego w ramach Azure Premium (skuName — Premium_ZRS) jest zalecane do wdrożeń strefowych, takich jak strefy dostępności, lub zestawy skalowania z FD=1.
- ZRS dla zarządzanego dysku jest obecnie dostępny w regionach wymienionych w dokumencie dostępności regionalnej.
- Dysk udostępniony Azure używany na potrzeby urządzeń SBD nie musi być duży. Wartość maxShares określa, ile węzłów klastra może używać dysku udostępnionego. Można na przykład użyć rozmiarów dysków P1 lub P2 dla urządzenia SBD w klastrze dwuwęzłowym, takim jak SAP ASCS/ERS lub SAP HANA w trybie scale-up.
- W przypadku skalowania w poziomie platformy HANA z replikacją systemu HANA (HSR) i modułem rozrusznika można użyć dysku udostępnionego Azure dla urządzeń SBD w klastrach z maksymalnie pięcioma węzłami na lokację replikacji z powodu bieżącego limitu maxShares.
- Nie zalecamy dołączania urządzenia SBD dysku udostępnionego Azure w klastrach pacemaker.
- Jeśli używasz wielu urządzeń SBD z dyskami udostępnionymi Azure, sprawdź limit maksymalnej liczby dysków danych, które mogą być dołączone do maszyny wirtualnej.
- Aby uzyskać więcej informacji na temat ograniczeń dotyczących dysków udostępnionych Azure, uważnie zapoznaj się z sekcją "Ograniczenia" Azure dokumentacją dysku udostępnionego.
Korzystanie z agenta ogrodzenia Azure
Ogrodzenia można skonfigurować przy użyciu agenta ogrodzenia Azure. Azure agent ogrodzenia wymaga tożsamości zarządzanych dla maszyn wirtualnych klastra lub jednostki usługi lub tożsamości zarządzanego systemu (MSI), która zarządza ponownym uruchomieniem węzłów, które zakończyły się niepowodzeniem za pośrednictwem interfejsów API Azure. Azure agent ogrodzenia nie wymaga wdrożenia dodatkowych maszyn wirtualnych.
SBD z serwerem docelowym iSCSI
Aby użyć urządzenia SBD, które używa serwera docelowego iSCSI do ogrodzenia, postępuj zgodnie z instrukcjami w następnych sekcjach.
Konfigurowanie serwera docelowego iSCSI
Najpierw należy utworzyć wirtualne maszyny docelowe iSCSI. Docelowe serwery iSCSI można udostępniać dla wielu klastrów Pacemaker.
Wdróż maszyny wirtualne działające w obsługiwanej wersji systemu operacyjnego RHEL i nawiąż z nimi połączenie za pośrednictwem protokołu SSH. Maszyny wirtualne nie muszą mieć dużego rozmiaru. Rozmiary maszyn wirtualnych, takie jak Standard_E2s_v3 lub Standard_D2s_v3, są wystarczające. Pamiętaj, aby używać magazynu Premium dla dysku systemu operacyjnego.
Nie jest konieczne używanie systemu RHEL dla oprogramowania SAP z wysoką dostępnością i usług aktualizacji ani używanie obrazu systemu operacyjnego RHEL dla SAP Apps jako serwera docelowego iSCSI. Zamiast tego można użyć standardowego obrazu systemu operacyjnego RHEL. Jednak cykl życia wsparcia różni się między różnymi wersjami produktów systemu operacyjnego.
Uruchom następujące polecenia na wszystkich maszynach wirtualnych docelowych iSCSI.
Zaktualizuj RHEL.
sudo yum -y updateUwaga
Po uaktualnieniu lub zaktualizowaniu systemu operacyjnego może być konieczne ponowne uruchomienie węzła.
Zainstaluj pakiet docelowy iSCSI.
sudo yum install targetcliUruchom i skonfiguruj element docelowy do uruchomienia w czasie rozruchu.
sudo systemctl start target sudo systemctl enable targetOtwieranie portu
3260w zaporzesudo firewall-cmd --add-port=3260/tcp --permanent sudo firewall-cmd --add-port=3260/tcp
Tworzenie urządzenia iSCSI na serwerze docelowym iSCSI
Aby utworzyć dyski iSCSI dla klastrów systemowych SAP, wykonaj następujące polecenia na każdej docelowej maszynie wirtualnej iSCSI. W przykładzie pokazano tworzenie urządzeń SBD dla kilku klastrów, pokazując użycie jednego serwera docelowego iSCSI dla wielu klastrów. Urządzenie SBD jest skonfigurowane na dysku systemu operacyjnego, więc upewnij się, że jest wystarczająca ilość miejsca.
- ascsnw1: reprezentuje klaster ASCS/ERS NW1.
- dbhn1: reprezentuje klaster bazy danych HN1.
- sap-cl1 i sap-cl2: nazwy hostów węzłów klastra NW1 ASCS/ERS.
- hn1-db-0 i hn1-db-1: nazwy hostów węzłów klastra bazy danych.
W poniższych instrukcjach zmodyfikuj polecenie, wstawiając odpowiednie nazwy hostów i identyfikatory SID według potrzeb.
Utwórz folder główny dla wszystkich urządzeń SBD.
sudo mkdir /sbdUtwórz urządzenie SBD dla serwerów ASCS/ERS systemu NW1.
sudo targetcli backstores/fileio create sbdascsnw1 /sbd/sbdascsnw1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.ascsnw1.local:ascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/luns/ create /backstores/fileio/sbdascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl1.local:sap-cl1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl2.local:sap-cl2Utwórz urządzenie SBD dla klastra bazy danych systemu HN1.
sudo targetcli backstores/fileio create sbddbhn1 /sbd/sbddbhn1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.dbhn1.local:dbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/luns/ create /backstores/fileio/sbddbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-0.local:hn1-db-0 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-1.local:hn1-db-1Zapisz konfigurację targetcli.
sudo targetcli saveconfigSprawdź, czy wszystko zostało poprawnie skonfigurowane
sudo targetcli ls o- / ......................................................................................................................... [...] o- backstores .............................................................................................................. [...] | o- block .................................................................................................. [Storage Objects: 0] | o- fileio ................................................................................................. [Storage Objects: 2] | | o- sbdascsnw1 ............................................................... [/sbd/sbdascsnw1 (50.0MiB) write-thru activated] | | | o- alua ................................................................................................... [ALUA Groups: 1] | | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | | o- sbddbhn1 ................................................................... [/sbd/sbddbhn1 (50.0MiB) write-thru activated] | | o- alua ................................................................................................... [ALUA Groups: 1] | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | o- pscsi .................................................................................................. [Storage Objects: 0] | o- ramdisk ................................................................................................ [Storage Objects: 0] o- iscsi ............................................................................................................ [Targets: 2] | o- iqn.2006-04.dbhn1.local:dbhn1 ..................................................................................... [TPGs: 1] | | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | | o- acls .......................................................................................................... [ACLs: 2] | | | o- iqn.2006-04.hn1-db-0.local:hn1-db-0 .................................................................. [Mapped LUNs: 1] | | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | | o- iqn.2006-04.hn1-db-1.local:hn1-db-1 .................................................................. [Mapped LUNs: 1] | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | o- luns .......................................................................................................... [LUNs: 1] | | | o- lun0 ............................................................. [fileio/sbddbhn1 (/sbd/sbddbhn1) (default_tg_pt_gp)] | | o- portals .................................................................................................... [Portals: 1] | | o- 0.0.0.0:3260 ..................................................................................................... [OK] | o- iqn.2006-04.ascsnw1.local:ascsnw1 ................................................................................. [TPGs: 1] | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | o- acls .......................................................................................................... [ACLs: 2] | | o- iqn.2006-04.sap-cl1.local:sap-cl1 .................................................................... [Mapped LUNs: 1] | | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | | o- iqn.2006-04.sap-cl2.local:sap-cl2 .................................................................... [Mapped LUNs: 1] | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | o- luns .......................................................................................................... [LUNs: 1] | | o- lun0 ......................................................... [fileio/sbdascsnw1 (/sbd/sbdascsnw1) (default_tg_pt_gp)] | o- portals .................................................................................................... [Portals: 1] | o- 0.0.0.0:3260 ..................................................................................................... [OK] o- loopback ......................................................................................................... [Targets: 0]
Konfigurowanie urządzenia SBD serwera docelowego iSCSI
[A]: Dotyczy wszystkich węzłów. [1]: Dotyczy tylko węzła 1. [2]: Dotyczy tylko węzła 2.
Na węzłach klastra połącz się i wykryj urządzenie iSCSI utworzone we wcześniejszej sekcji. Uruchom następujące polecenia w węzłach nowego klastra, który chcesz utworzyć.
[A] Zainstaluj lub zaktualizuj narzędzia inicjatora iSCSI na wszystkich węzłach klastra.
sudo yum install -y iscsi-initiator-utils[A] Zainstaluj pakiety klastra i SBD na wszystkich węzłach klastra.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] Włącz usługę iSCSI.
sudo systemctl enable iscsid iscsi[1] Zmień nazwę inicjatora w pierwszym węźle klastra.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl1.local:sap-cl1[2] Zmień nazwę inicjatora w drugim węźle klastra.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl2.local:sap-cl2[A] Uruchom ponownie usługę iSCSI, aby zastosować zmiany.
sudo systemctl restart iscsid sudo systemctl restart iscsi[A] Łączenie urządzeń iSCSI. W poniższym przykładzie 10.0.0.17 jest adresem IP serwera docelowego iSCSI, a 3260 jest portem domyślnym. Nazwa
iqn.2006-04.ascsnw1.local:ascsnw1docelowa zostanie wyświetlona podczas uruchamiania pierwszego poleceniaiscsiadm -m discovery.sudo iscsiadm -m discovery --type=st --portal=10.0.0.17:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.17:3260 sudo iscsiadm -m node -p 10.0.0.17:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Jeśli używasz wielu urządzeń SBD, połącz się również z drugim serwerem docelowym iSCSI.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.18:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.18:3260 sudo iscsiadm -m node -p 10.0.0.18:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Jeśli używasz wielu urządzeń SBD, połącz się również z trzecim serwerem docelowym iSCSI.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.19:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.19:3260 sudo iscsiadm -m node -p 10.0.0.19:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Upewnij się, że urządzenia iSCSI są dostępne i zanotuj nazwę urządzenia. W poniższym przykładzie trzy urządzenia iSCSI są odnajdywane przez połączenie węzła z trzema serwerami docelowymi iSCSI.
lsscsi [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sde [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdb [1:0:0:2] disk Msft Virtual Disk 1.0 /dev/sdc [1:0:0:3] disk Msft Virtual Disk 1.0 /dev/sdd [2:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdf [3:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdh [4:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdg[A] Pobieranie identyfikatorów urządzeń iSCSI.
ls -l /dev/disk/by-id/scsi-* | grep -i sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf ls -l /dev/disk/by-id/scsi-* | grep -i sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh ls -l /dev/disk/by-id/scsi-* | grep -i sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdgPolecenie wyświetla listę trzech identyfikatorów urządzeń dla każdego urządzenia SBD. Zalecamy użycie identyfikatora rozpoczynającego się od scsi-3. W poprzednim przykładzie identyfikatory to:
- /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2
- /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d
- /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65
[1] Tworzenie urządzenia SBD.
Użyj identyfikatora urządzenia urządzeń iSCSI, aby utworzyć nowe urządzenia SBD w pierwszym węźle klastra.
sudo sbd -d /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -1 60 -4 120 createUtwórz również drugie i trzecie urządzenia SBD, jeśli chcesz użyć więcej niż jednego.
sudo sbd -d /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -1 60 -4 120 create sudo sbd -d /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -1 60 -4 120 create
[A] Dostosowywanie konfiguracji SBD
Otwórz plik konfiguracji SBD.
sudo vi /etc/sysconfig/sbdZmień właściwość urządzenia SBD, włącz integrację modułu pacemaker i zmień tryb uruchamiania usługi SBD.
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2;/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d;/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] # # In some cases, a longer delay than the default "msgwait" seconds is needed. So, set a specific delay value, in seconds. See, `man sbd` for more information. SBD_DELAY_START=186 [...]
[A] Uruchom następujące polecenie, aby załadować
softdogmoduł.modprobe softdog[A] Uruchom następujące polecenie, aby upewnić się, że
softdogjest automatycznie ładowane po ponownym uruchomieniu węzła.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-loadGdy jest ustawione na określoną wartość, opóźnia to uruchomienie usługi SBD podczas rozruchu. Jeśli ustawienie domyślne systemd
TimeoutSecdla usługi SBD (90 sekund) pozostaje niezmienione, usługa może przekroczyć limit czasu i nie uruchomić się, dlategoTimeoutSecnależy zwiększyć do wartości większej niżSBD_DELAY_START.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=223" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=3min 43s # TimeoutStopUSec=3min 43s # TimeoutAbortUSec=3min 43s
SBD z udostępnionym dyskiem Azure
Ta sekcja ma zastosowanie tylko wtedy, gdy chcesz użyć urządzenia SBD z dyskiem udostępnionym Azure.
Konfigurowanie dysku udostępnionego Azure za pomocą programu PowerShell
Aby utworzyć i dołączyć dysk udostępniony Azure za pomocą programu PowerShell, wykonaj następującą instrukcję. Jeśli chcesz wdrożyć zasoby przy użyciu Azure CLI lub portalu Azure, możesz również zapoznać się z artykułem Deploy a ZRS disk.
$ResourceGroup = "MyResourceGroup"
$Location = "MyAzureRegion"
$DiskSizeInGB = 4
$DiskName = "SBD-disk1"
$ShareNodes = 2
$LRSSkuName = "Premium_LRS"
$ZRSSkuName = "Premium_ZRS"
$vmNames = @("prod-cl1-0", "prod-cl1-1") # VMs to attach the disk
# ZRS Azure shared disk: Configure an Azure shared disk with ZRS for a premium shared disk
$zrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $ZRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$zrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $zrsDiskConfig
# Attach ZRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $zrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
# LRS Azure shared disk: Configure an Azure shared disk with LRS for a premium shared disk
$lrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $LRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$lrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $lrsDiskConfig
# Attach LRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $lrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
Skonfiguruj urządzenie SBD współdzielonego dysku Azure
[A] Zainstaluj pakiety klastra i SBD na wszystkich węzłach klastra.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] Upewnij się, że dołączony dysk jest dostępny.
lsblk # NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT # sda 8:0 0 4G 0 disk # sdb 8:16 0 64G 0 disk # ├─sdb1 8:17 0 500M 0 part /boot # ├─sdb2 8:18 0 63G 0 part # │ ├─rootvg-tmplv 253:0 0 2G 0 lvm /tmp # │ ├─rootvg-usrlv 253:1 0 10G 0 lvm /usr # │ ├─rootvg-homelv 253:2 0 1G 0 lvm /home # │ ├─rootvg-varlv 253:3 0 8G 0 lvm /var # │ └─rootvg-rootlv 253:4 0 2G 0 lvm / # ├─sdb14 8:30 0 4M 0 part # └─sdb15 8:31 0 495M 0 part /boot/efi # sr0 11:0 1 1024M 0 rom lsscsi # [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sdb # [0:0:0:2] cd/dvd Msft Virtual DVD-ROM 1.0 /dev/sr0 # [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda # [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdc[A] Pobierz identyfikator urządzenia dołączonego dysku udostępnionego.
ls -l /dev/disk/by-id/scsi-* | grep -i sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-14d534654202020200792c2f5cc7ef14b8a7355cb3cef0107 -> ../../sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -> ../../sdaPolecenie wyświetla identyfikator urządzenia podłączonego dysku współdzielonego. Zalecamy użycie identyfikatora rozpoczynającego się od scsi-3. W tym przykładzie identyfikator to /dev/disk/by-id/scsi-3600224800792c2f5cc7e5cb3cef0107.
[1] Tworzenie urządzenia SBD
# Use the device ID from step 3 to create the new SBD device on the first cluster node sudo sbd -d /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -1 60 -4 120 create[A] Dostosowywanie konfiguracji SBD
Otwórz plik konfiguracji SBD.
sudo vi /etc/sysconfig/sbdZmień właściwość urządzenia SBD, włącz integrację pacemakera, zmień tryb uruchamiania SBD i dostosuj wartość SBD_DELAY_START.
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] # In some cases, a longer delay than the default "msgwait" seconds is needed. So, set a specific delay value, in seconds. See, `man sbd` for more information. SBD_DELAY_START=186 [...]
[A] Uruchom następujące polecenie, aby załadować
softdogmoduł.modprobe softdog[A] Uruchom następujące polecenie, aby upewnić się, że
softdogjest automatycznie ładowane po ponownym uruchomieniu węzła.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-loadGdy jest ustawione na określoną wartość, opóźnia to uruchomienie usługi SBD podczas rozruchu. Jeśli ustawienie domyślne systemd
TimeoutSecdla usługi SBD (90 sekund) pozostaje niezmienione, usługa może przekroczyć limit czasu i nie uruchomić się, dlategoTimeoutSecnależy zwiększyć do wartości większej niżSBD_DELAY_START.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=223" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=3min 43s # TimeoutStopUSec=3min 43s # TimeoutAbortUSec=3min 43s
konfiguracja agenta ogrodzenia Azure
Urządzenie ogrodzenia używa tożsamości zarządzanej dla zasobu Azure lub jednostki usługi do autoryzacji względem Azure. W zależności od metody zarządzania tożsamościami postępuj zgodnie z odpowiednimi procedurami —
Konfigurowanie zarządzania tożsamościami
Użyj tożsamości zarządzanej lub głównego użytkownika usługi.
Aby utworzyć tożsamość zarządzaną (MSI), utwórz tożsamość zarządzaną przypisaną przez system dla każdej maszyny wirtualnej w klastrze. Jeśli tożsamość zarządzana przypisana przez system już istnieje, zostanie użyta. Nie używaj obecnie tożsamości zarządzanych przypisanych przez użytkownika z programem Pacemaker. Urządzenie ogrodzenia oparte na tożsamości zarządzanej jest obsługiwane w systemach RHEL 7.9 i RHEL 8.x/RHEL 9.x/RHEL 10.x.
Utwórz rolę niestandardową dla agenta ogrodzenia
Zarówno tożsamość zarządzana, jak i jednostka usługi nie mają domyślnie uprawnień dostępu do zasobów Azure. Musisz przyznać zarządzanej tożsamości lub głównemu podmiotowi usługi uprawnienia do uruchamiania i zatrzymywania (wyłączania) wszystkich maszyn wirtualnych klastra. Jeśli rola niestandardowa nie została jeszcze utworzona, możesz ją utworzyć przy użyciu PowerShell lub Azure CLI.
Użyj następującej zawartości dla pliku wejściowego. Musisz dostosować zawartość do swoich subskrypcji, zastępując
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxiyyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyyidentyfikatorami subskrypcji. Jeśli masz tylko jedną subskrypcję, usuń drugi wpis w plikuAssignableScopes.{ "Name": "Linux Fence Agent Role", "description": "Allows to power-off and start virtual machines", "assignableScopes": [ "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "/subscriptions/yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy" ], "actions": [ "Microsoft.Compute/*/read", "Microsoft.Compute/virtualMachines/powerOff/action", "Microsoft.Compute/virtualMachines/start/action" ], "notActions": [], "dataActions": [], "notDataActions": [] }Przypisz rolę niestandardową
Użyj tożsamości zarządzanej lub głównego użytkownika usługi.
Przypisz rolę
Linux Fence Agent Roleniestandardową utworzoną w ostatniej sekcji do każdej tożsamości zarządzanej maszyn wirtualnych klastra. Każda tożsamość zarządzana przypisana systemowo dla maszyny wirtualnej wymaga przypisania roli do każdego zasobu maszyn wirtualnych w klastrze. Aby uzyskać więcej informacji, zobacz Przydziel dostęp tożsamości zarządzanej do zasobu przy użyciu portalu Azure. Sprawdź, czy przypisanie roli tożsamości zarządzanej każdej maszyny wirtualnej zawiera wszystkie maszyny wirtualne klastra.Ważne
Należy pamiętać, że przypisanie i usunięcie autoryzacji z tożsamościami zarządzanymi może być opóźnione do momentu wprowadzenia w życie.
Instalacja klastra
Różnice w poleceniach lub konfiguracji między RHEL 7 i RHEL 8/RHEL 9 są oznaczone w dokumencie.
[A] Zainstaluj dodatek RHEL HA.
sudo yum install -y pcs pacemaker nmap-ncat[A] W systemie RHEL 9.x zainstaluj agentów zasobów na potrzeby wdrażania w chmurze.
sudo yum install -y resource-agents-cloud[A] Zainstaluj pakiet sterowników do ogrodzeń, jeśli korzystasz z urządzenia ogrodzeniowego opartego na agencie Azure.
sudo yum install -y fence-agents-azure-armWażne
Zalecamy następujące wersje agenta ogrodzenia Azure (lub nowszego) dla klientów, którzy chcą używać tożsamości zarządzanych dla zasobów Azure zamiast nazw głównych usług agenta ogrodzenia:
- RHEL 8.4: ogrodzenie-agenci-4.2.1-54.el8.
- RHEL 8.2: fence-agents-4.2.1-41.el8_2.4
- RHEL 8.1: fence-agents-4.2.1-30.el8_1.4
- RHEL 7.9: fence-agents-4.2.1-41.el7_9.4.
Ważne
W systemie RHEL 9 zalecamy wykonanie następujących wersji pakietów (lub nowszych), aby uniknąć problemów z agentem ogrodzenia Azure:
- fence-agents-4.10.0-20.el9_0.7
- fence-agents-common-4.10.0-20.el9_0.6
- ha-cloud-support-4.10.0-20.el9_0.6.x86_64.rpm
Sprawdź wersję agenta Fence dla Azure. W razie potrzeby zaktualizuj ją do minimalnej wymaganej wersji lub nowszej.
# Check the version of the Azure Fence Agent sudo yum info fence-agents-azure-armWażne
Jeśli musisz zaktualizować agenta ogrodzenia Azure, a jeśli używasz roli niestandardowej, zaktualizuj rolę niestandardową, aby uwzględnić akcję powerOff. Aby uzyskać więcej informacji, zobacz Utwórz rolę niestandardową dla agenta ogrodzenia.
[A] Skonfiguruj rozpoznawanie nazw hostów.
Możesz użyć serwera DNS lub zmodyfikować
/etc/hostsplik na wszystkich węzłach. Ten przykład pokazuje, jak używać pliku/etc/hosts. Zastąp adres IP i nazwę hosta w następujących poleceniach.Ważne
Jeśli używasz nazw hostów w konfiguracji klastra, ważne jest, aby mieć niezawodne rozpoznawanie nazw hostów. Komunikacja z klastrem zawodzi, jeśli nazwy nie są dostępne, co może prowadzić do opóźnień w przełączaniu awaryjnym klastra.
Zaletą użycia
/etc/hostsjest to, że klaster staje się niezależny od systemu DNS, co może być również pojedynczym punktem awarii.sudo vi /etc/hostsWstaw następujące wiersze do
/etc/hosts. Zmień adres IP i nazwę hosta, aby pasować do twojego środowiska.# IP address of the first cluster node 10.0.0.6 prod-cl1-0 # IP address of the second cluster node 10.0.0.7 prod-cl1-1[A] Zmień
haclusterhasło na to samo hasło.sudo passwd hacluster[A] Dodaj reguły zapory dla programu Pacemaker.
Dodaj następujące reguły zapory do całej komunikacji między węzłami klastra.
sudo firewall-cmd --add-service=high-availability --permanent sudo firewall-cmd --add-service=high-availability[A] Włącz podstawowe usługi klastra.
Uruchom następujące polecenia, aby włączyć usługę Pacemaker i uruchomić ją.
sudo systemctl start pcsd.service sudo systemctl enable pcsd.service[1] Tworzenie klastra Pacemaker.
Uruchom następujące polecenia, aby uwierzytelnić węzły i utworzyć klaster. Ustaw token na 30000, aby umożliwić konserwację pamięci. Aby uzyskać więcej informacji, zobacz ten artykuł dla systemu Linux.
Jeśli tworzysz klaster w systemie RHEL 7.x, użyj następujących poleceń:
sudo pcs cluster auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup --name nw1-azr prod-cl1-0 prod-cl1-1 --token 30000 sudo pcs cluster start --allJeśli tworzysz klaster w systemie RHEL 8.x/RHEL 9.x/RHEL 10.x, użyj następujących poleceń:
sudo pcs host auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup nw1-azr prod-cl1-0 prod-cl1-1 totem token=30000 sudo pcs cluster start --allSprawdź stan klastra, uruchamiając następujące polecenie:
# Run the following command until the status of both nodes is online sudo pcs status # Cluster name: nw1-azr # WARNING: no stonith devices and stonith-enabled is not false # Stack: corosync # Current DC: prod-cl1-1 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum # Last updated: Fri Aug 17 09:18:24 2018 # Last change: Fri Aug 17 09:17:46 2018 by hacluster via crmd on prod-cl1-1 # # 2 nodes configured # 0 resources configured # # Online: [ prod-cl1-0 prod-cl1-1 ] # # No resources # # Daemon Status: # corosync: active/disabled # pacemaker: active/disabled # pcsd: active/enabled[A] Ustaw oczekiwane głosy.
# Check the quorum votes pcs quorum status # If the quorum votes are not set to 2, execute the next command sudo pcs quorum expected-votes 2Wskazówka
Jeśli tworzysz klaster wielowęzłowy, czyli klaster z więcej niż dwoma węzłami, nie ustawiaj głosów na 2.
[1] Zezwalaj na współbieżne akcje ogrodzenia.
sudo pcs property set concurrent-fencing=true
Utwórz urządzenie ochronne w klastrze Pacemaker
Wskazówka
- Aby uniknąć konfliktów typu fencing w klastrze zarządzanym przez Pacemaker z dwoma węzłami, możesz skonfigurować właściwość klastra
priority-fencing-delay. Ta właściwość wprowadza dodatkowe opóźnienie procesu ogrodzenia węzła, który ma wyższy całkowity priorytet zasobów, gdy wystąpi scenariusz rozdziału systemu. Aby uzyskać więcej informacji, zobacz Czy program Pacemaker może odizolować węzeł klastra z najmniejszą liczbą uruchomionych zasobów operacyjnych? - Właściwość
priority-fencing-delayma zastosowanie do programu Pacemaker w wersji 2.0.4-6.el8 lub nowszej i w klastrze z dwoma węzłami. Jeśli skonfigurujesz właściwość klastrapriority-fencing-delay, nie musisz ustawiaćpcmk_delay_maxwłaściwości. Jeśli jednak wersja Pacemaker jest mniejsza niż 2.0.4-6.el8, należy ustawić właściwośćpcmk_delay_max. - Aby uzyskać instrukcje dotyczące ustawiania właściwości klastra
priority-fencing-delay, zobacz odpowiednie dokumenty dotyczące SAP ASCS/ERS i skalowania pionowego SAP HANA HA.
Na podstawie wybranego mechanizmu ogrodzenia wykonaj tylko jedną sekcję, aby uzyskać odpowiednie instrukcje: SBD jako urządzenie ogrodzeniowe lub Azure agent ogrodzenia jako urządzenie ogrodzeniowe.
SBD jako urządzenie ogrodzeniowe
[A] Włączanie usługi SBD
sudo systemctl enable sbd[1] Dla urządzenia SBD skonfigurowanego z użyciem serwerów docelowych iSCSI lub dysku współużytkowanego Azure, uruchom następujące polecenia.
sudo pcs property set stonith-timeout=210 sudo pcs property set stonith-enabled=true # Replace the device IDs with your device ID. pcs stonith create sbd fence_sbd \ devices=/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2,/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d,/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 \ op monitor interval=600 timeout=15[1] Uruchom ponownie klaster
sudo pcs cluster stop --all # It would take time to start the cluster as "SBD_DELAY_START" is set to "yes" sudo pcs cluster start --allUwaga
Jeśli napotkasz następujący błąd w trakcie rozruchu klastra pacemaker, możesz zignorować ten komunikat. Alternatywnie możesz uruchomić klaster przy użyciu polecenia
pcs cluster start --all --request-timeout 140.Błąd: nie można uruchomić wszystkich węzłów node1/node2: Nie można nawiązać połączenia z węzłem1/node2, sprawdź, czy pcsd jest tam uruchomiony, lub spróbuj ustawić wyższy limit czasu z opcją
--request-timeout(upłynął limit czasu operacji po 60000 milisekundach z odebranymi 0 bajtami)
Azure agent ogrodzenia jako urządzenie ogrodzeniowe
[1] Po przypisaniu ról do obu węzłów klastra można skonfigurować urządzenia ogrodzeniowe w klastrze.
sudo pcs property set stonith-timeout=900 sudo pcs property set stonith-enabled=true[1] Uruchom odpowiednie polecenie w zależności od tego, czy używasz tożsamości zarządzanej, czy jednostki usługi dla agenta ogrodzenia Azure.
Uwaga
W przypadku korzystania z chmury Azure dla instytucji rządowych należy określić opcję
cloud=podczas konfigurowania agenta ogrodzenia. Na przykładcloud=usgovdla chmury Azure dla instytucji rządowych USA. Aby uzyskać szczegółowe informacje na temat wsparcia RedHat w chmurze rządowej Azure, zobacz Support Policies for RHEL High Availability Clusters - Microsoft Azure Virtual Machines as Cluster Members.Wskazówka
Opcja
pcmk_host_mapjest wyłącznie wymagana w poleceniu, jeśli nazwy hostów RHEL i nazwy maszyn wirtualnych Azure nie są* identyczne. Określ mapowanie w formacie nazwa hosta:vm-name. Aby uzyskać więcej informacji, zobacz Jakiego formatu należy używać do określania mapowań węzłów na urządzeniach ogrodzeniowych w pcmk_host_map?W przypadku systemu RHEL 7.x użyj następującego polecenia, aby skonfigurować urządzenie ogrodzenia:
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ meta failure-timeout=120s \ op monitor interval=3600W przypadku systemu RHEL 8.x/9.x/10.x użyj następującego polecenia, aby skonfigurować urządzenie ogrodzenia:
# Run following command if you are setting up fence agent on (two-node cluster and pacemaker version greater than 2.0.4-6.el8) OR (HANA scale out) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 \ meta failure-timeout=120s \ op monitor interval=3600 # Run following command if you are setting up fence agent on (two-node cluster and pacemaker version less than 2.0.4-6.el8) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ meta failure-timeout=120s \ op monitor interval=3600
Jeśli używasz urządzenia zabezpieczającego opartego na konfiguracji zaufanej jednostki usługi, przeczytaj Zmiana z nazwy SPN na MSI dla klastrów Pacemaker przy użyciu zabezpieczeń Azure i dowiedz się, jak skonwertować na konfigurację tożsamości zarządzanej.
Operacje monitorowania i ogrodzenia są deserializowane. W związku z tym, jeśli istnieje już uruchomiona operacja monitorowania i jednoczesne zdarzenie zabezpieczenia, nie ma opóźnienia w przełączaniu awaryjnym klastra, ponieważ operacja monitorowania jest już uruchomiona.
Wskazówka
Agent ogrodzenia Azure wymaga łączności wychodzącej z publicznymi punktami końcowymi. Aby uzyskać więcej informacji wraz z możliwymi rozwiązaniami, zobacz Łączność z publicznym punktem końcowym dla maszyn wirtualnych korzystających ze standardowego modułu równoważenia obciążenia.
Konfigurowanie programu Pacemaker pod kątem zaplanowanych zdarzeń Azure
Azure oferuje schedulowane zdarzenia. Zaplanowane zdarzenia są udostępniane za pośrednictwem usługi metadanych i umożliwiają aplikacji przygotowanie się do takich zdarzeń.
Agent zasobów azure-events-az monitoruje zaplanowane zdarzenia Azure. Jeśli zdarzenia zostaną wykryte i agent zasobów ustali, że inny węzeł klastra jest dostępny, ustawia atrybut kondycji na poziomie węzła na wartość #health-azure.
Gdy ten specjalny atrybut kondycji klastra jest ustawiony dla węzła, węzeł jest uznawany za w złej kondycji przez klaster, a wszystkie zasoby są migrowane z dala od węzła, którego dotyczy problem. Ograniczenie lokalizacji gwarantuje, że zasoby o nazwie rozpoczynającej się od "health-" są wykluczone, ponieważ agent musi działać w tym stanie złej kondycji. Gdy węzeł klastra, którego dotyczy problem, nie będzie mógł uruchamiać zasobów klastra, zaplanowane zdarzenie może wykonać jego akcję, taką jak ponowne uruchomienie, bez ryzyka uruchomienia zasobów.
Atrybut #heath-azure jest ponownie ustawiany na 0 podczas uruchamiania modułu pacemaker, po przetworzeniu wszystkich zdarzeń, oznaczając węzeł jako ponownie zdrowy.
[A] Upewnij się, że pakiet agenta
azure-events-azjest już zainstalowany i aktualny.RHEL 8.x: sudo dnf info resource-agents RHEL 9.x: sudo dnf info resource-agents-cloudMinimalne wymagania dotyczące wersji:
- RHEL 8.4:
resource-agents-4.1.1-90.13 - RHEL 8.6:
resource-agents-4.9.0-16.9 - RHEL 8.8:
resource-agents-4.9.0-40.1 - RHEL 9.0:
resource-agents-cloud-4.10.0-9.6 - RHEL 9.2 i nowsze:
resource-agents-cloud-4.10.0-34.1
- RHEL 8.4:
[1] Konfigurowanie zasobów w narzędziu Pacemaker.
#Place the cluster in maintenance mode sudo pcs property set maintenance-mode=true[1] Ustaw strategię i ograniczenia węzła zdrowia klastra Pacemaker.
sudo pcs property set node-health-strategy=custom # For RHEL 8.x/9.x sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ defined '#uname' # For RHEL 10.x sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ "defined #uname"Ważne
Nie należy definiować żadnych innych zasobów w klastrze, które zaczynają się od
health-, chyba że są one opisane w następnych krokach.[1] Ustaw początkową wartość atrybutów klastra. Uruchom polecenie dla każdego węzła klastra i dla środowisk rozproszonych, w tym maszyny wirtualnej zapewniającej większość.
sudo crm_attribute --node prod-cl1-0 --name '#health-azure' --update 0 sudo crm_attribute --node prod-cl1-1 --name '#health-azure' --update 0[1] Konfigurowanie zasobów w narzędziu Pacemaker. Upewnij się, że zasoby zaczynają się od
health-azure.sudo pcs resource create health-azure-events \ ocf:heartbeat:azure-events-az \ meta failure-timeout=120s \ op monitor interval=10s timeout=240s \ op start timeout=10s start-delay=90s # For RHEL 8.x/9.x sudo pcs resource clone health-azure-events allow-unhealthy-nodes=true # For RHEL 10.x sudo pcs resource clone health-azure-events meta allow-unhealthy-nodes=trueUsuń klaster Pacemaker z trybu konserwacji.
sudo pcs property set maintenance-mode=falseWyczyść wszelkie błędy podczas włączania i sprawdź, czy zasoby
health-azure-eventszostały pomyślnie uruchomione we wszystkich węzłach klastra.sudo pcs resource cleanupWykonywanie zapytania po raz pierwszy dla zaplanowanych zdarzeń może potrwać do dwóch minut. Testy Pacemaker z zaplanowanymi zdarzeniami mogą używać akcji ponownego uruchomienia i wdrożenia dla maszyn wirtualnych w klastrze. Aby uzyskać więcej informacji, zobacz Zaplanowane zdarzenia.
Opcjonalna konfiguracja ogrodzenia
Wskazówka
Ta sekcja ma zastosowanie tylko wtedy, gdy chcesz skonfigurować specjalne urządzenie fence_kdumpogrodzeniowe .
Jeśli musisz zebrać informacje diagnostyczne w ramach maszyny wirtualnej, może być przydatne skonfigurowanie innego urządzenia do odgradzania na podstawie agenta ogrodzenia fence_kdump.
fence_kdump Agent może wykryć, że węzeł wszedł w tryb odzyskiwania po awarii kdump i może pozwolić na ukończenie usługi odzyskiwania awaryjnego przed wywołaniem innych metod izolacji. Należy pamiętać, że fence_kdump nie zastępuje tradycyjnych mechanizmów ogrodzenia, takich jak SBD lub agent fencing dla Azure, gdy używasz maszyn wirtualnych Azure.
Ważne
Należy pamiętać, że jeśli fence_kdump jest skonfigurowane jako urządzenie odgradzające pierwszego poziomu, powoduje to opóźnienia w operacjach odgradzania, a co za tym idzie, opóźnienia w przełączaniu awaryjnym zasobów aplikacji.
Jeśli zrzut awaryjny zostanie pomyślnie wykryty, izolacja zostanie opóźniona aż do zakończenia usługi odzyskiwania po awarii. Jeśli węzeł, który zakończył się niepowodzeniem, jest nieosiągalny lub nie odpowiada, izolacja jest opóźniona o określony z góry czas, skonfigurowaną liczbę iteracji i fence_kdump limit czasu. Aby uzyskać więcej informacji, zobacz Jak skonfigurować fence_kdump w klastrze Red Hat Pacemaker?
Może być konieczne dostosowanie proponowanego fence_kdump limitu czasu do określonego środowiska.
Zalecamy skonfigurowanie fence_kdump fencing tylko wtedy, gdy jest to konieczne do zbierania diagnostyki na maszynie wirtualnej i zawsze w połączeniu z tradycyjnymi metodami fencing, takimi jak SBD lub Azure fence agent.
Następujące artykuły z bazy wiedzy red hat zawierają ważne informacje dotyczące konfigurowania fence_kdump ogrodzenia:
- Zobacz Jak skonfigurować fence_kdump w klastrze Red Hat Pacemaker?
- Zobacz Jak skonfigurować poziomy ogrodzenia i zarządzać nimi w klastrze RHEL za pomocą programu Pacemaker.
- Zobacz fence_kdump zawodzi z "timeoutem po X sekundach" w klastrze RHEL 6 lub 7 HA z narzędziami kexec-tools starszymi niż 2.0.14.
- Aby uzyskać informacje na temat zmiany domyślnego limitu czasu, zobacz Jak skonfigurować kdump do użycia z dodatkiem RHEL 6, 7, 8 HA?
- Aby uzyskać informacje na temat ograniczania opóźnienia przełączenia awaryjnego w przypadku korzystania z
fence_kdump, zobacz Czy mogę zmniejszyć oczekiwane opóźnienie przełączenia awaryjnego podczas dodawania konfiguracji fence_kdump?
Uruchom następujące opcjonalne kroki, aby dodać fence_kdump jako konfigurację ogrodzenia pierwszego poziomu, oprócz konfiguracji agenta ogrodzenia Azure.
[A] Sprawdź, czy
kdumpjest aktywny i skonfigurowany.systemctl is-active kdump # Expected result # active[A] Zainstaluj agenta ogrodzenia
fence_kdump.yum install fence-agents-kdump[1] Utwórz
fence_kdumpurządzenie ogrodzeniowe w klastrze.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" timeout=30[1] Skonfiguruj poziomy ogrodzenia,
fence_kdumpaby mechanizm ogrodzenia został uruchomiony jako pierwszy.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" pcs stonith level add 1 prod-cl1-0 rsc_st_kdump pcs stonith level add 1 prod-cl1-1 rsc_st_kdump # Replace <stonith-resource-name> to the resource name of the STONITH resource configured in your pacemaker cluster (example based on above configuration - sbd or rsc_st_azure) pcs stonith level add 2 prod-cl1-0 <stonith-resource-name> pcs stonith level add 2 prod-cl1-1 <stonith-resource-name> # Check the fencing level configuration pcs stonith level # Example output # Target: prod-cl1-0 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name> # Target: prod-cl1-1 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name>[A] Zezwalaj na wymagane porty w zaporze
fence_kdump.firewall-cmd --add-port=7410/udp firewall-cmd --add-port=7410/udp --permanent[A] Wykonaj konfigurację w
fence_kdump_nodes, aby uniknąć sytuacji, w której/etc/kdump.confkończy się niepowodzeniem z powodu upływu limitu czasu w niektórych wersjachfence_kdump. Aby uzyskać więcej informacji, zobacz fence_kdump przekracza limit czasu, gdy fence_kdump_nodes nie jest określony, z wersją narzędzi kexec-tools 2.0.15 lub nowszą oraz fence_kdump kończy się niepowodzeniem z "przekroczeniem limitu czasu po X sekundach" w klastrze RHEL 6 lub 7 High Availability z wersjami kexec-tools starszymi niż 2.0.14. W tym miejscu przedstawiono przykładową konfigurację klastra z dwoma węzłami. Po dokonaniu zmiany w/etc/kdump.conftrzeba ponownie wygenerować obraz kdump. Uruchom ponownie usługękdump, aby odtworzyć ją na nowo.vi /etc/kdump.conf # On node prod-cl1-0 make sure the following line is added fence_kdump_nodes prod-cl1-1 # On node prod-cl1-1 make sure the following line is added fence_kdump_nodes prod-cl1-0 # Restart the service on each node systemctl restart kdump[A] Upewnij się, że
initramfsplik obrazu zawiera plikifence_kdumpihosts. Aby uzyskać więcej informacji, zobacz Jak skonfigurować fence_kdump w klastrze Red Hat Pacemaker?lsinitrd /boot/initramfs-$(uname -r)kdump.img | egrep "fence|hosts" # Example output # -rw-r--r-- 1 root root 208 Jun 7 21:42 etc/hosts # -rwxr-xr-x 1 root root 15560 Jun 17 14:59 usr/libexec/fence_kdump_sendPrzetestuj konfigurację, rozbijając węzeł. Aby uzyskać więcej informacji, zobacz Jak skonfigurować fence_kdump w klastrze Red Hat Pacemaker?
Ważne
Jeśli klaster jest już wydajnie używany, należy odpowiednio zaplanować test, ponieważ awaria węzła ma wpływ na aplikację.
echo c > /proc/sysrq-trigger
Następne kroki
- Zobacz planowanie i wdrażanie Azure Virtual Machines dla SAP.
- Zobacz Wdrażanie maszyn wirtualnych Azure dla SAP.
- Zobacz wdrażanie systemu zarządzania bazą danych (DBMS) na maszynach wirtualnych Azure dla SAP.
- Aby dowiedzieć się, jak zapewnić wysoką dostępność i zaplanować odzyskiwanie po awarii SAP HANA na maszynach wirtualnych Azure, zobacz Wysoka dostępność SAP HANA na maszynach wirtualnych Azure.