Opcje konfiguracji w celu zminimalizowania opóźnienia sieci za pomocą aplikacji SAP
Ważne
W listopadzie 2021 r. wprowadziliśmy znaczące zmiany w sposobie użycia grup umieszczania w pobliżu z obciążeniem SAP we wdrożeniach strefowych.
Aplikacje SAP oparte na architekturze SAP NetWeaver lub SAP S/4HANA są wrażliwe na opóźnienia sieci między warstwą aplikacji SAP a warstwą bazy danych SAP. Ta czułość jest wynikiem większości logiki biznesowej działającej w warstwie aplikacji. Ponieważ warstwa aplikacji SAP uruchamia logikę biznesową, wysyła zapytania do warstwy bazy danych z wysoką częstotliwością w tempie tysięcy lub dziesiątek tysięcy na sekundę. W większości przypadków charakter tych zapytań jest prosty. Często można je uruchamiać w warstwie bazy danych w 500 mikrosekundach lub mniej.
Czas spędzony w sieci w celu wysłania takiego zapytania z warstwy aplikacji do warstwy bazy danych i otrzymania zwróconego wyniku ma duży wpływ na czas potrzebny do uruchamiania procesów biznesowych. Ta wrażliwość na opóźnienie sieci jest powodem, dla którego może być konieczne osiągnięcie określonego minimalnego opóźnienia sieci w projektach wdrażania sap. Zobacz Artykuł SAP Note #1100926 — często zadawane pytania: Wydajność sieci, aby uzyskać wskazówki dotyczące klasyfikowania opóźnienia sieci.
W wielu regionach świadczenia usługi Azure liczba centrów danych wzrosła. W tym samym czasie klienci, zwłaszcza w przypadku systemów SAP wysokiej klasy, korzystają z bardziej specjalnych rodzin maszyn wirtualnych, takich jak Mv2 lub Mv3 i nowsze. Te typy maszyn wirtualnych platformy Azure nie zawsze są dostępne w każdym z centrów danych zbierających się w regionie świadczenia usługi Azure. Te fakty mogą tworzyć możliwości optymalizacji opóźnienia sieci między warstwą aplikacji SAP i warstwą SAP DBMS.
Platforma Azure oferuje różne opcje wdrażania dla obciążeń SAP. W przypadku wybranego typu wdrożenia dostępne są opcje optymalizacji opóźnienia sieci w razie potrzeby. Szczegółowe informacje o każdej opcji zostały dokładnie opisane w poniższych sekcjach w tym artykule:
Grupy umieszczania w pobliżu
Grupy umieszczania w pobliżu umożliwiają grupowanie różnych typów maszyn wirtualnych w ramach jednego kręgosłupa sieci, zapewniając optymalne małe opóźnienie sieci między nimi. Po wdrożeniu pierwszej maszyny wirtualnej w grupie umieszczania w pobliżu ta maszyna wirtualna jest powiązana z określonym kręgosłupem sieciowym. Ponieważ wszystkie inne maszyny wirtualne, które zostaną wdrożone w tej samej grupie umieszczania w pobliżu, te maszyny wirtualne zostaną zgrupowane w ramach tego samego kręgosłupa sieciowego. Równie atrakcyjne, jak brzmi to perspektywa, użycie konstrukcji wprowadza pewne ograniczenia i pułapki, jak również:
- Nie można założyć, że wszystkie typy maszyn wirtualnych platformy Azure są dostępne we wszystkich centrach danych platformy Azure lub w każdym i każdym kręgosłupie sieci. W związku z tym połączenie różnych typów maszyn wirtualnych w jednej grupie umieszczania w pobliżu może być poważnie ograniczone. Te ograniczenia występują, ponieważ sprzęt hosta wymagany do uruchomienia określonego typu maszyny wirtualnej może nie znajdować się w centrum danych lub w kręgosłupie sieci, do którego przypisano grupę umieszczania w pobliżu
- Podczas zmiany rozmiaru części maszyn wirtualnych znajdujących się w jednej grupie umieszczania w pobliżu nie można automatycznie założyć, że we wszystkich przypadkach nowy typ maszyny wirtualnej jest dostępny w tym samym centrum danych lub w kręgosłupie sieci grupa umieszczania w pobliżu została przypisana do
- W miarę likwidacji sprzętu platformy Azure może wymusić użycie niektórych maszyn wirtualnych grupy umieszczania w pobliżu do innego centrum danych platformy Azure lub innego kręgosłupa sieci. Aby uzyskać szczegółowe informacje dotyczące tego przypadku, przeczytaj dokument Grupy umieszczania w pobliżu
Ważne
W wyniku potencjalnych ograniczeń grupy umieszczania w pobliżu powinny być używane tylko:
- Jeśli jest to konieczne w niektórych scenariuszach (zobacz później)
- Gdy opóźnienie sieci między warstwą aplikacji i warstwą DBMS jest zbyt wysokie i ma wpływ na obciążenie
- Tylko na stopień szczegółowości pojedynczego systemu SAP, a nie dla całego środowiska systemu lub kompletnego środowiska SAP
- Aby zachować różne typy maszyn wirtualnych i liczbę maszyn wirtualnych w grupie umieszczania w pobliżu do minimum
Scenariusze, w których grupy umieszczania w pobliżu mogą służyć do optymalizowania opóźnienia sieci:
- Chcesz wdrożyć krytyczne zasoby obciążenia SAP w różnych strefach dostępności, a z drugiej strony należy rozłożyć maszyny wirtualne warstwy aplikacji w różnych domenach błędów przy użyciu zestawów dostępności w każdej ze stref. W takim przypadku, jak opisano w dalszej części dokumentu, potrzebne są grupy umieszczania w pobliżu.
- Obciążenie SAP jest wdrażane przy użyciu zestawów dostępności. W przypadku warstwy bazy danych SAP warstwa aplikacji SAP i maszyny wirtualne ASCS/SCS są grupowane w trzech różnych zestawach dostępności. W takim przypadku należy upewnić się, że zestawy dostępności nie są rozłożone w całym regionie świadczenia usługi Azure, ponieważ może to być zależne od regionu świadczenia usługi Azure, co może spowodować opóźnienie sieci, które może negatywnie wpłynąć na obciążenie SAP.
- Grupy umieszczania w pobliżu służą do grupowania maszyn wirtualnych w celu osiągnięcia najmniejszego możliwego opóźnienia sieci między usługami hostowanymi na maszynach wirtualnych. Na przykład opóźnienie w samej strefie dostępności nie spełnia wymagań aplikacji.
Jeśli chodzi o scenariusz wdrażania nr 2, w wielu regionach, zwłaszcza w regionach bez stref dostępności i większości regionów ze strefami dostępności, opóźnienie sieci niezależne od miejsca, w którym są dopuszczalne. Chociaż istnieją niektóre regiony platformy Azure, które nie mogą zapewnić wystarczająco dobrego środowiska bez sortowania trzech różnych zestawów dostępności bez użycia grup umieszczania w pobliżu.
Co to są grupy umieszczania w pobliżu?
Grupa umieszczania w pobliżu platformy Azure jest konstrukcją logiczną. Po zdefiniowaniu grupy umieszczania w pobliżu jest ona powiązana z regionem platformy Azure i grupą zasobów platformy Azure. Podczas wdrażania maszyn wirtualnych grupa umieszczania w pobliżu jest przywoływane przez:
- Pierwsza maszyna wirtualna platformy Azure wdrożona w ramach kręgosłupa sieci z wieloma jednostkami obliczeniowymi platformy Azure i małym opóźnieniem sieci. Taki kręgosłup sieci często pasuje do pojedynczego centrum danych platformy Azure. Pierwszą maszynę wirtualną można traktować jako "maszynę wirtualną o zakresie", która jest wdrażana w jednostce skalowania obliczeniowego na podstawie algorytmów alokacji platformy Azure, które są ostatecznie łączone z parametrami wdrożenia.
- Wszystkie kolejne maszyny wirtualne wdrożone, które odwołują się do grupy umieszczania w pobliżu, zostaną wdrożone w ramach tego samego kręgosłupa sieci co pierwsza maszyna wirtualna.
Uwaga
Jeśli nie wdrożono sprzętu hosta, który może uruchomić określony typ maszyny wirtualnej w kręgosłupie sieci, w którym została umieszczona pierwsza maszyna wirtualna, wdrożenie żądanego typu maszyny wirtualnej nie powiedzie się. Zostanie wyświetlony komunikat o niepowodzeniu alokacji wskazujący, że maszyna wirtualna nie może być obsługiwana w obwodzie grupy umieszczania w pobliżu.
Aby zmniejszyć ryzyko wystąpienia powyższego, zaleca się użycie opcji intencji podczas tworzenia grupy umieszczania w pobliżu. Opcja intencji umożliwia wyświetlenie listy typów maszyn wirtualnych, które zamierzasz uwzględnić w grupie umieszczania w pobliżu. Ta lista typów maszyn wirtualnych zostanie przeniesiona w celu znalezienia najlepszego centrum danych hostujących te typy maszyn wirtualnych. Jeśli takie centrum danych zostanie znalezione, grupa PPG zostanie utworzona i zostanie ograniczona do centrum danych spełniającego wymagania dotyczące jednostki SKU maszyny wirtualnej. Jeśli nie znaleziono takiego centrum danych, utworzenie grupy umieszczania w pobliżu zakończy się niepowodzeniem. Więcej informacji można znaleźć w dokumentacji PPG — użyj intencji , aby określić rozmiary maszyn wirtualnych. Należy pamiętać, że rzeczywiste sytuacje pojemności nie są uwzględniane w kontrolach wyzwalanych przez opcję intencji. W związku z tym nadal mogą występować błędy alokacji zakorzenione w niewystarczającej dostępnej pojemności.
Do jednej grupy zasobów platformy Azure może być przypisanych wiele grup umieszczania w pobliżu. Jednak grupę umieszczania w pobliżu można przypisać tylko do jednej grupy zasobów platformy Azure.
Aby uzyskać więcej informacji i przykładów wdrażania grup umieszczania w pobliżu, zobacz dostępną dokumentację.
Grupy umieszczania w pobliżu z wdrożeniami strefowymi
Ważne jest, aby zapewnić dość małe opóźnienie sieci między warstwą aplikacji SAP i warstwą DBMS. W większości sytuacji wdrożenie strefowe spełnia to wymaganie. W przypadku ograniczonego zestawu scenariuszy wdrożenie strefowe może nie spełniać wymagań dotyczących opóźnień aplikacji. Takie sytuacje wymagają jak największego rozmieszczenia maszyn wirtualnych i umożliwiają stosunkowo małe opóźnienie sieci. Dla takiego systemu SAP można zdefiniować grupę umieszczania w pobliżu platformy Azure.
Unikaj łączenia kilku systemów produkcyjnych lub nieprodukcyjnych SAP w jednej grupie umieszczania w pobliżu. Unikaj pakietów systemów SAP, ponieważ im więcej systemów grupujesz w grupie umieszczania w pobliżu, tym większe są szanse:
- Wymaga to typu maszyny wirtualnej, która nie jest dostępna w kręgosłupie sieci, do którego przypisano grupę umieszczania w pobliżu.
- Te zasoby niemainstreamowych maszyn wirtualnych, takich jak maszyny wirtualne serii M, mogą ostatecznie zostać wypełnione, gdy trzeba będzie rozszerzyć liczbę maszyn wirtualnych do grupy umieszczania w pobliżu w czasie.
W oparciu o wiele ulepszeń wdrożonych przez firmę Microsoft w regionach świadczenia usługi Azure w celu zmniejszenia opóźnienia sieci w strefie dostępności platformy Azure wskazówki dotyczące wdrażania w przypadku korzystania z grup umieszczania w pobliżu dla wdrożeń strefowych wyglądają następująco:
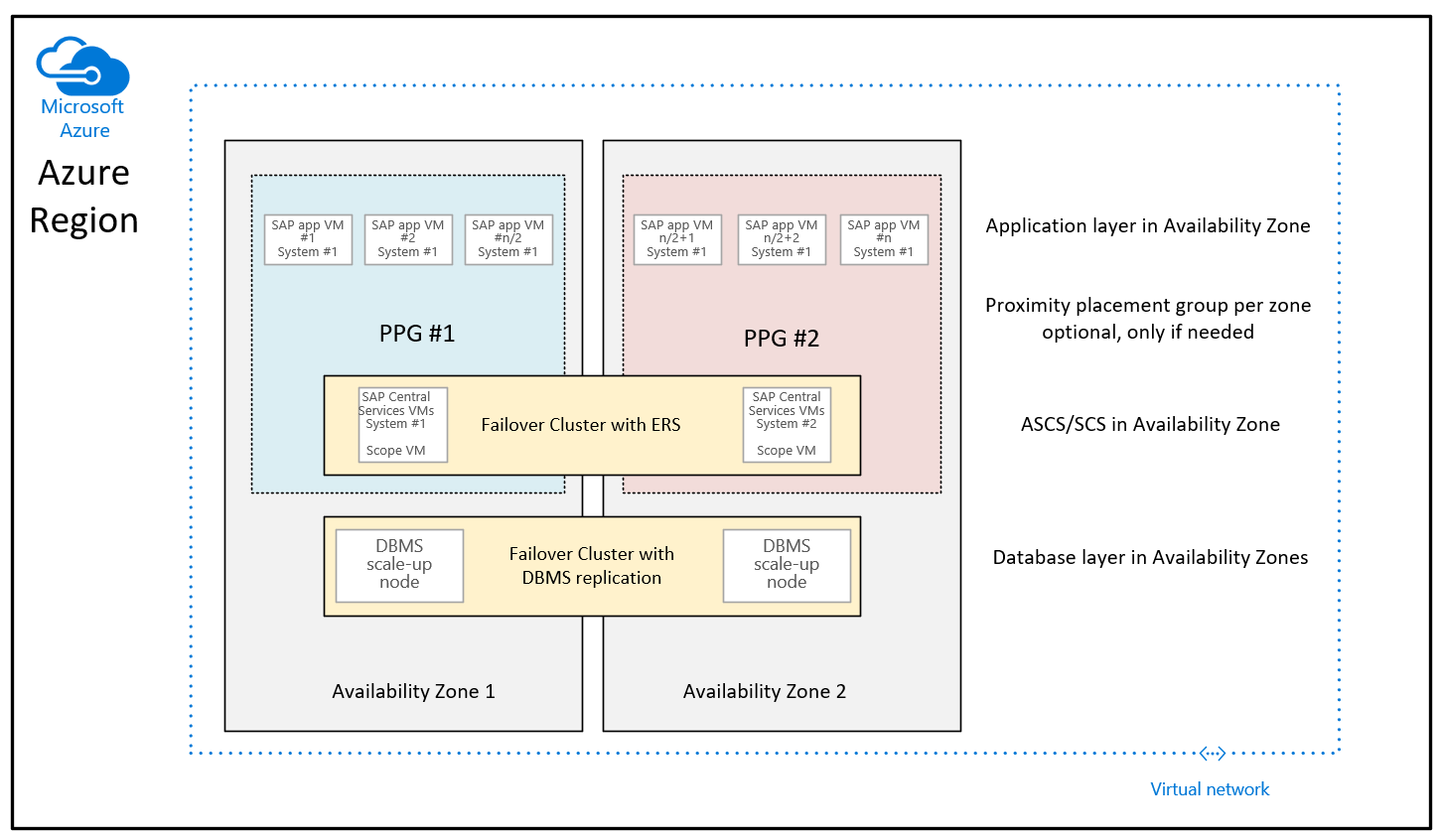
Różnica w rekomendacji podanej do tej pory polega na tym, że maszyny wirtualne bazy danych w dwóch strefach nie są już częścią grup umieszczania w pobliżu. Grupy umieszczania w pobliżu dla strefy są teraz ograniczone do wdrożenia maszyny wirtualnej z uruchomionymi wystąpieniami SAP ASCS/SCS. Oznacza to również, że w regionach, w których strefy dostępności są zbierane przez wiele centrów danych, wystąpienie usługi ASCS/SCS, a warstwa aplikacji może działać w ramach jednego kręgosłupa sieciowego, a maszyny wirtualne bazy danych mogą działać w innym kręgosłupie sieci. Mimo że w przypadku ulepszeń sieci opóźnienie sieci między warstwą aplikacji SAP i warstwą DBMS nadal powinno być wystarczające dla wystarczająco dobrej wydajności i przepływności. Zaletą tej nowej konfiguracji jest większa elastyczność zmiany rozmiaru maszyn wirtualnych lub przenoszenie do nowych typów maszyn wirtualnych za pomocą warstwy DBMS lub/i warstwy aplikacji systemu SAP.
W przypadku użycia usługi Azure NetApp Files (ANF) dla środowiska DBMS i powiązanej nowej funkcjonalności grupy woluminów aplikacji Usługi Azure NetApp Files dla platformy SAP HANA i jej konieczności w przypadku grup umieszczania w pobliżu zapoznaj się z dokumentem woluminy NFS w wersji 4.1 w usłudze Azure NetApp Files dla platformy SAP HANA.
Grupy umieszczania w pobliżu z wdrożeniami zestawu dostępności
W takim przypadku celem jest użycie grup umieszczania w pobliżu w celu sortowania maszyn wirtualnych wdrożonych za pomocą różnych zestawów dostępności. W tym scenariuszu użycia nie używasz kontrolowanego wdrożenia w różnych strefach dostępności w regionie. Zamiast tego chcesz wdrożyć system SAP przy użyciu zestawów dostępności. W związku z tym masz co najmniej zestaw dostępności dla maszyn wirtualnych DBMS, maszyn wirtualnych USŁUGI ASCS/SCS i maszyn wirtualnych warstwy aplikacji. Ponieważ nie można określić w czasie wdrażania maszyny wirtualnej zestawu dostępności i strefy dostępności, nie można kontrolować, gdzie maszyny wirtualne w różnych zestawach dostępności mają zostać przydzielone. Może to spowodować, że w niektórych regionach świadczenia usługi Azure opóźnienie sieci między różnymi maszynami wirtualnymi nadal może być zbyt wysokie, aby zapewnić wystarczająco dobre środowisko wydajności. W związku z tym wynikowa architektura będzie wyglądać następująco:
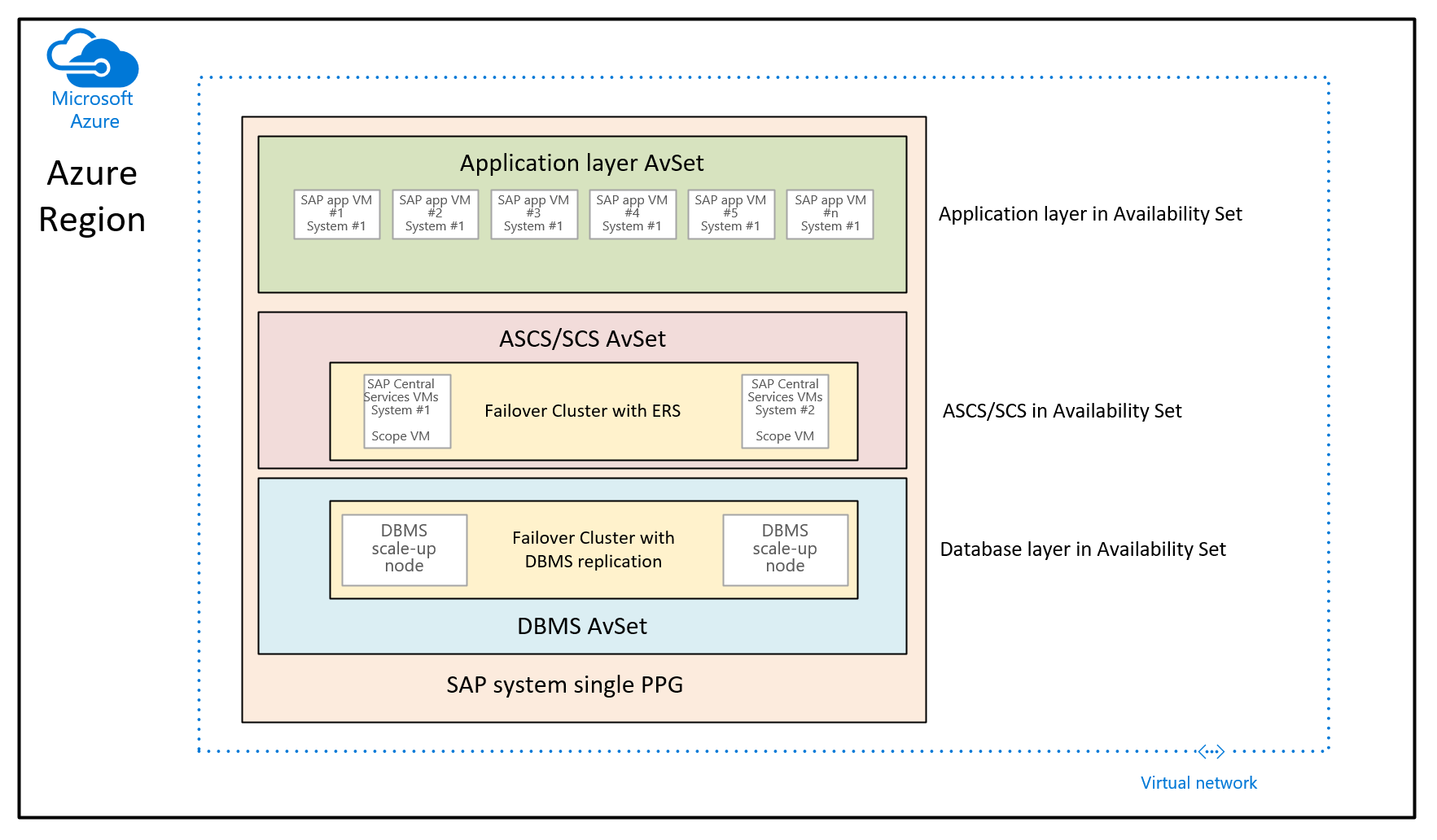
Na tej ilustracji do pojedynczego systemu SAP zostanie przypisana pojedyncza grupa umieszczania w pobliżu. Ta grupa PPG zostanie przypisana do trzech zestawów dostępności. Grupa umieszczania w pobliżu jest następnie ograniczona przez wdrożenie maszyn wirtualnych pierwszej warstwy bazy danych w zestawie dostępności programu DBMS. To zalecenie dotyczące architektury powoduje połączenie wszystkich maszyn wirtualnych w ramach tego samego kręgosłupa sieci. Wprowadzenie do ograniczeń wymienionych wcześniej w tym artykule. W związku z tym architektura grupy umieszczania w pobliżu powinna być używana rozrzedliwie.
Łączenie zestawów dostępności i stref dostępności z grupami umieszczania w pobliżu
Jednym z problemów z używaniem stref dostępności dla wdrożeń systemu SAP jest to, że nie można wdrożyć warstwy aplikacji SAP przy użyciu zestawów dostępności w określonej strefie dostępności. Chcesz, aby warstwa aplikacji SAP została wdrożona w tych samych strefach co maszyny wirtualne SAP ASCS/SCS. Odwoływanie się do strefy dostępności i zestawu dostępności podczas wdrażania pojedynczej maszyny wirtualnej nie jest do tej pory możliwe. Jednak po prostu wdrożenie maszyny wirtualnej instruując strefę dostępności, utracisz możliwość upewnienia się, że maszyny wirtualne warstwy aplikacji są rozmieszczone w różnych domenach aktualizacji i błędów.
Korzystając z grup umieszczania w pobliżu, można obejść to ograniczenie. Oto sekwencja wdrażania:
- Utwórz grupę umieszczania w pobliżu.
- Wdróż zakotwiczoną maszynę wirtualną, zalecaną jako maszynę wirtualną ASCS/SCS, odwołując się do strefy dostępności.
- Utwórz zestaw dostępności odwołujący się do grupy umieszczania w pobliżu platformy Azure. (Zobacz polecenie w dalszej części tego artykułu).
- Wdróż maszyny wirtualne warstwy aplikacji, odwołując się do zestawu dostępności i grupy umieszczania w pobliżu.
Ważne
Należy pamiętać, że dyski maszyn wirtualnych warstwy aplikacji nie mają gwarancji przydzielenia w tej samej strefie dostępności, co maszyny wirtualne są kierowane do korzystania z grupy umieszczania w pobliżu. Wynikiem wdrożenia pokazanego w następnych krokach może być to, że maszyny wirtualne są przydzielane w tym samym kręgosłupie sieci i z tą samą strefą dostępności co zakotwiczona maszyna wirtualna. Dyski respctive (podstawowy dysk VHD i zainstalowane dyski magazynu blokowego platformy Azure) mogą nie być przydzielane w ramach tego samego kręgosłupa sieci, a nawet tej samej strefy dostępności. Zamiast tego dyski tych maszyn wirtualnych można przydzielić w dowolnym z centrów danych określonego regionu. Chociaż dyski maszyny wirtualnej zakotwiczonej, która została wdrożona przez zdefiniowanie strefy, zostaną wdrożone w tej samej strefie co wdrożona maszyna wirtualna.
Zamiast wdrażać pierwszą maszynę wirtualną, jak pokazano w poprzedniej sekcji, należy odwołać się do strefy dostępności i grupy umieszczania w pobliżu podczas wdrażania maszyny wirtualnej:
New-AzVm -ResourceGroupName "ppgexercise" -Name "centralserviceszone1" -Location "westus2" -OpenPorts 80,3389 -Zone "1" -ProximityPlacementGroup "collocate" -Size "Standard_E8s_v4"
Pomyślne wdrożenie tej maszyny wirtualnej spowoduje hostowanie wystąpienia usługi ASCS/SCS systemu SAP w jednej strefie dostępności. W takim przypadku maszyna wirtualna i podstawowy wirtualny dysk twardy maszyny wirtualnej oraz potencjalnie zainstalowane dyski magazynu blokowego platformy Azure są przydzielane w tej samej strefie dostępności. Zakres grupy umieszczania w pobliżu jest stały dla jednego z kolców sieci w zdefiniowanej strefie dostępności.
W następnym kroku należy utworzyć zestawy dostępności, których chcesz użyć dla warstwy aplikacji systemu SAP.
Zdefiniuj i utwórz grupę umieszczania w pobliżu. Polecenie tworzenia zestawu dostępności wymaga dodatkowego odwołania do identyfikatora grupy umieszczania w pobliżu (a nie nazwy). Identyfikator grupy umieszczania w pobliżu można uzyskać przy użyciu tego polecenia:
Get-AzProximityPlacementGroup -ResourceGroupName "ppgexercise" -Name "collocate"
Podczas tworzenia zestawu dostępności należy wziąć pod uwagę dodatkowe parametry podczas korzystania z dysków zarządzanych (ustawienie domyślne, chyba że określono inaczej) i grup umieszczania w pobliżu:
New-AzAvailabilitySet -ResourceGroupName "ppgexercise" -Name "ppgavset" -Location "westus2" -ProximityPlacementGroupId "/subscriptions/my very long ppg id string" -sku "aligned" -PlatformUpdateDomainCount 3 -PlatformFaultDomainCount 2
W idealnym przypadku należy użyć trzech domen błędów. Jednak liczba obsługiwanych domen błędów może się różnić w zależności od regionu do regionu. W takim przypadku maksymalna liczba domen błędów możliwych dla określonych regionów wynosi dwa. Aby wdrożyć maszyny wirtualne warstwy aplikacji, należy dodać odwołanie do nazwy zestawu dostępności i nazwy grupy umieszczania w pobliżu, jak pokazano poniżej:
New-AzVm -ResourceGroupName "ppgexercise" -Name "appinstance1" -Location "westus2" -OpenPorts 80,3389 -AvailabilitySetName "myppgavset" -ProximityPlacementGroup "collocate" -Size "Standard_E16s_v4"
Uwaga
Dyski maszyn wirtualnych wdrożonych w powyższym zestawie dostępności nie muszą być przydzielane w tej samej strefie dostępności, co maszyna wirtualna. Chociaż osiągnięto, że maszyny wirtualne warstwy aplikacji są rozmieszczone w różnych domenach błędów w ramach tego samego kręgosłupa sieci, co maszyna wirtualna kotwicy jest przydzielana, dyski, choć również przydzielone w różnych domenach błędów mogą być przydzielane w różnych lokalizacjach w szerokim zakresie regionu.
Wynikiem tego wdrożenia jest:
- Usługi centralne dla systemu SAP znajdującego się w określonych strefach dostępności.
- Warstwa aplikacji SAP znajdująca się za pośrednictwem zestawów dostępności w tym samym kręgosłupie sieci co maszyna wirtualna lub maszyny wirtualne usług SAP Central (ASCS/SCS).
Uwaga
Ponieważ wdrażasz jedną maszynę wirtualną DBMS i ASCS/SCS w jednej strefie, a drugą maszynę wirtualną DBMS i ASCS/SCS w innej strefie, aby utworzyć konfiguracje wysokiej dostępności, musisz mieć inną grupę umieszczania w pobliżu dla każdej ze stref. To samo dotyczy dowolnego zestawu dostępności, którego używasz.
Zmienianie konfiguracji grup umieszczania w pobliżu istniejącego systemu
Jeśli zaimplementowano grupy umieszczania w pobliżu zgodnie z zaleceniami podanymi do tej pory i chcesz dostosować się do nowej konfiguracji, możesz to zrobić przy użyciu metod opisanych w następujących artykułach:
- Wdrażanie maszyn wirtualnych w grupach umieszczania w pobliżu przy użyciu interfejsu wiersza polecenia platformy Azure.
- Wdrażanie maszyn wirtualnych w grupach umieszczania w pobliżu przy użyciu programu PowerShell.
Możesz również użyć tych poleceń w przypadkach, w których występują błędy alokacji w przypadkach, gdy nie można przejść do nowego typu maszyny wirtualnej z istniejącą maszyną wirtualną w grupie umieszczania w pobliżu.
Zestaw skalowania maszyn wirtualnych z elastyczną aranżacją
Aby uniknąć ograniczeń związanych z grupą umieszczania w pobliżu, zaleca się wdrożenie obciążenia SAP w różnych strefach dostępności przy użyciu elastycznego zestawu skalowania z FD=1. Ta strategia wdrażania gwarantuje, że maszyny wirtualne wdrożone w każdej strefie nie są ograniczone do jednego centrum danych lub kręgosłupa sieci, a wszystkie składniki systemu SAP, takie jak bazy danych, usługi ASCS/ERS i warstwa aplikacji, są objęte zakresem w strefie. Ze względu na zakres wszystkich składników systemu SAP na poziomie strefowym opóźnienie sieci między różnymi składnikami pojedynczego systemu SAP musi być wystarczające, aby zapewnić zadowalającą wydajność i przepływność. Kluczową zaletą tej nowej opcji wdrażania z elastycznym zestawem skalowania Z FD=1 jest to, że zapewnia większą elastyczność zmiany rozmiaru maszyn wirtualnych lub przełączania na nowe typy maszyn wirtualnych dla wszystkich warstw systemu SAP. Ponadto zestaw skalowania przydziela maszyny wirtualne w wielu domenach błędów w ramach jednej strefy, co jest idealne do uruchamiania wielu maszyn wirtualnych warstwy aplikacji w każdej strefie. Aby uzyskać więcej informacji, zobacz dokument zestaw skalowania maszyn wirtualnych dla obciążenia SAP.
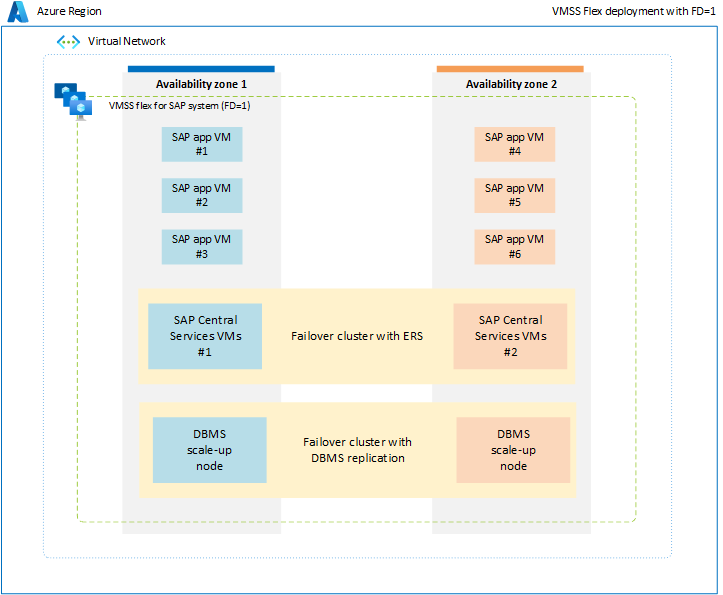
W środowisku nieprodukcyjnym lub innym niż ha można wdrożyć wszystkie składniki systemu SAP, w tym bazę danych, usługę ASCS i warstwę aplikacji w ramach jednej strefy przy użyciu elastycznego zestawu skalowania z FD=1.
Wcześniej zalecane opcje wdrażania
Ta sekcja zawiera szczegółowe informacje o wcześniej zalecanych opcjach wdrażania w celu zoptymalizowania opóźnienia sieci dla oprogramowania SAP. Wraz z upływem czasu nowe funkcje i rozwój platformy Azure szczegóły w tej sekcji powinny być stosowane tylko w rzadkich przypadkach.
Grupy umieszczania w pobliżu dla całego systemu SAP z wdrożeniami strefowymi
Użycie grup umieszczania w pobliżu, które zalecamy do tej pory, wygląda jak na tej ilustracji.

Utworzysz grupę umieszczania w pobliżu (PPG) w każdej z dwóch stref dostępności wdrożonych w systemie SAP. Wszystkie maszyny wirtualne określonej strefy są częścią pojedynczej grupy umieszczania w pobliżu tej konkretnej strefy. Rozpoczniesz pracę w każdej strefie, wdrażając maszynę wirtualną DBMS w celu określenia zakresu ppG, a następnie wdrożysz maszynę wirtualną usługi ASCS w tej samej strefie i ppg. W trzecim kroku utworzysz zestaw dostępności platformy Azure, przypiszesz zestaw dostępności do grupy ppg o określonym zakresie i wdrożysz w niej warstwę aplikacji SAP. Zaletą tej konfiguracji było to, że wszystkie składniki są ładnie wyrównane pod tym samym kręgosłupem sieciowym. Duża wada polega na tym, że elastyczność zmiany rozmiaru maszyn wirtualnych może być ograniczona.
W oparciu o wiele ulepszeń wdrożonych przez firmę Microsoft w regionach świadczenia usługi Azure w celu zmniejszenia opóźnienia sieci w strefie dostępności platformy Azure istnieją bieżące wskazówki dotyczące wdrażania strefowego w tym artykule.
Grupy umieszczania w pobliżu i duże wystąpienia platformy HANA
Jeśli niektóre systemy SAP bazują na dużych wystąpieniach platformy HANA dla warstwy bazy danych, mogą wystąpić znaczne ulepszenia opóźnienia sieci między jednostką dużych wystąpień platformy HANA a maszynami wirtualnymi platformy Azure podczas korzystania z jednostek dużych wystąpień platformy HANA wdrożonych w wierszach lub sygnaturach wersji 4. Jedną z ulepszeń jest to, że jednostki dużych wystąpień platformy HANA w miarę ich wdrażania są wdrażane z grupą umieszczania w pobliżu. Możesz użyć tej grupy umieszczania w pobliżu, aby wdrożyć maszyny wirtualne warstwy aplikacji. W związku z tym te maszyny wirtualne zostaną wdrożone w tym samym centrum danych, które hostuje jednostkę HANA Large Instances.
Aby określić, czy jednostka dużych wystąpień platformy HANA jest wdrożona w sygnaturze wersji 4 lub wierszu, zapoznaj się z artykułem Kontrola dużych wystąpień platformy Azure HANA za pośrednictwem witryny Azure Portal. W omówieniu atrybutów JEDNOSTKI dużych wystąpień platformy HANA można również określić nazwę grupy umieszczania w pobliżu, ponieważ została utworzona podczas wdrażania jednostki dużych wystąpień platformy HANA. Nazwa wyświetlana w przeglądzie atrybutów to nazwa grupy umieszczania w pobliżu, w której należy wdrożyć maszyny wirtualne warstwy aplikacji.
W porównaniu z systemami SAP, które korzystają tylko z maszyn wirtualnych platformy Azure, w przypadku korzystania z dużych wystąpień platformy HANA mniejsza elastyczność w podejmowaniu decyzji o liczbie grup zasobów platformy Azure do użycia. Wszystkie jednostki dużych wystąpień platformy HANA w dzierżawie dużych wystąpień platformy HANA są grupowane w jednej grupie zasobów, zgodnie z opisem w tym artykule. Jeśli nie wdrożysz w różnych dzierżawach na potrzeby oddzielenia, na przykład systemów produkcyjnych i nieprodukcyjnych lub innych systemów, wszystkie jednostki dużych wystąpień platformy HANA zostaną wdrożone w jednej dzierżawie dużych wystąpień platformy HANA. Ta dzierżawa ma relację jeden do jednego z grupą zasobów. Jednak oddzielna grupa umieszczania w pobliżu zostanie zdefiniowana dla każdej z pojedynczych jednostek.
W związku z tym relacje między grupami zasobów platformy Azure i grupami umieszczania w pobliżu dla jednej dzierżawy będą następujące:

Następne kroki
Zapoznaj się z dokumentacją:
- Obciążenia SAP na platformie Azure: lista kontrolna planowania i wdrażania
- Wdrażanie maszyn wirtualnych w grupach umieszczania w pobliżu przy użyciu interfejsu wiersza polecenia platformy Azure
- Wdrażanie maszyn wirtualnych w grupach umieszczania w pobliżu przy użyciu programu PowerShell
- Zagadnienia dotyczące wdrażania usługi Azure Virtual Machines DBMS dla obciążeń SAP