Indeksowanie danych z bibliotek dokumentów programu SharePoint
Ważne
Obsługa indeksatora usługi SharePoint Online jest dostępna w publicznej wersji zapoznawczej. Jest ona oferowana jako "as-is", zgodnie z dodatkowymi warunkami użytkowania i obsługiwana tylko na podstawie najlepszych wysiłków. Funkcje w wersji zapoznawczej nie są zalecane w przypadku obciążeń produkcyjnych i nie mają gwarancji, że staną się ogólnie dostępne.
Przed rozpoczęciem zapoznaj się ze znaną sekcją ograniczeń .
Aby użyć tej wersji zapoznawczej, wypełnij ten formularz. Nie otrzymasz żadnego powiadomienia o zatwierdzeniu bezpośrednio po tym, ponieważ każde żądanie dostępu zostanie automatycznie zaakceptowane po przesłaniu. Po włączeniu dostępu użyj interfejsu API REST w wersji zapoznawczej, aby indeksować zawartość.
W tym artykule wyjaśniono, jak skonfigurować indeksator wyszukiwania w celu indeksowania dokumentów przechowywanych w bibliotekach dokumentów programu SharePoint na potrzeby wyszukiwania pełnotekstowego w usłudze Azure AI Search. Najpierw należy wykonać kroki konfiguracji, a następnie zachowania i scenariusze
Funkcje
Indeksator w usłudze Azure AI Search to przeszukiwarka, która wyodrębnia dane i metadane z możliwością wyszukiwania ze źródła danych. Indeksator usługi SharePoint Online łączy się z witryną programu SharePoint i indeksuje dokumenty z co najmniej jednej biblioteki dokumentów. Indeksator zapewnia następujące funkcje:
- Indeksowanie plików i metadanych z co najmniej jednej biblioteki dokumentów.
- Przyrostowe indeksowanie, pobieranie tylko nowych i zmienionych plików i metadanych.
- Wykrywanie usuwania jest wbudowane. Usunięcie w bibliotece dokumentów jest pobierane podczas następnego uruchomienia indeksatora, a dokument zostanie usunięty z indeksu.
- Obrazy tekstowe i znormalizowane są domyślnie wyodrębniane z indeksowanych dokumentów. Opcjonalnie możesz dodać zestaw umiejętności umożliwiający dokładniejsze wzbogacanie sztucznej inteligencji, takie jak OCR lub tłumaczenie tekstu.
Wymagania wstępne
Program SharePoint w usłudze w chmurze platformy Microsoft 365
Pliki w bibliotece dokumentów
Obsługiwane formaty dokumentów
Indeksator usługi SharePoint Online może wyodrębnić tekst z następujących formatów dokumentów:
- CSV (zobacz Indeksowanie obiektów blob CSV)
- EML
- EPUB
- GZ
- HTML
- JSON (zobacz Indeksowanie obiektów blob JSON)
- KML (XML dla reprezentacji geograficznych)
- Formaty pakietu Microsoft Office: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (wiadomości e-mail programu Outlook), XML (zarówno 2003, jak i 2006 WORD XML)
- Otwieranie formatów dokumentów: ODT, ODS, ODP
- Pliki zwykłego tekstu (zobacz też Indeksowanie zwykłego tekstu)
- RTF
- Plik XML
- ZIP
Ograniczenia i istotne zagadnienia
Poniżej przedstawiono ograniczenia tej funkcji:
Indeksowanie list programu SharePoint nie jest obsługiwane.
Indeksowanie programu SharePoint. Zawartość witryny ASPX nie jest obsługiwana.
Pliki notesu programu OneNote nie są obsługiwane.
Prywatny punkt końcowy nie jest obsługiwany.
Zmiana nazwy folderu programu SharePoint nie powoduje wyzwalania indeksowania przyrostowego. Zmieniona nazwa folderu jest traktowana jako nowa zawartość.
Program SharePoint obsługuje szczegółowy model autoryzacji, który określa dostęp poszczególnych użytkowników na poziomie dokumentu. Indeksator nie pobiera tych uprawnień do indeksu, a usługa Azure AI Search nie obsługuje autoryzacji na poziomie dokumentu. Gdy dokument jest indeksowany z programu SharePoint do usługi wyszukiwania, zawartość jest dostępna dla każdego, kto ma dostęp do odczytu do indeksu. Jeśli potrzebujesz uprawnień na poziomie dokumentu, należy rozważyć filtry zabezpieczeń w celu przycinania wyników i automatyzowania kopiowania uprawnień na poziomie pliku do pola w indeksie.
Indeksowanie plików zaszyfrowanych przez użytkownika, pliki chronione za pomocą usługi Zarządzanie prawami do informacji (IRM), pliki ZIP z hasłami lub podobną zaszyfrowaną zawartością nie są obsługiwane. Aby zaszyfrowana zawartość była przetwarzana, użytkownik z odpowiednimi uprawnieniami do określonego pliku musi usunąć szyfrowanie, aby element mógł być odpowiednio indeksowany, gdy indeksator uruchamia kolejną zaplanowaną iterację.
Indeksowanie podwitryn rekursywnie z określonej udostępnionej witryny nie jest obsługiwane.
Indeksator usługi SharePoint Online nie jest obsługiwany, gdy jest włączony dostęp warunkowy identyfikatora ENTRA firmy Microsoft.
Poniżej przedstawiono zagadnienia dotyczące korzystania z tej funkcji:
Jeśli musisz utworzyć niestandardową aplikację Copilot /RAG (Retrieval Augmented Generation), aby porozmawiać z danymi programu SharePoint, zalecane jest użycie programu Microsoft Copilot Studio zamiast tej funkcji w wersji zapoznawczej.
Jeśli potrzebujesz rozwiązania indeksowania zawartości programu SharePoint w środowisku produkcyjnym, rozważ utworzenie łącznika niestandardowego za pomocą elementów webhook programu SharePoint, wywołanie interfejsu API programu Microsoft Graph w celu wyeksportowania danych do kontenera obiektów blob platformy Azure, a następnie użycie indeksatora obiektów blob platformy Azure do indeksowania przyrostowego.
- Jeśli konfiguracja programu SharePoint umożliwia procesom platformy Microsoft 365 aktualizowanie metadanych systemu plików programu SharePoint, należy pamiętać, że te aktualizacje mogą wyzwolić indeksator usługi SharePoint Online, co powoduje wielokrotne pozyskiwanie dokumentów przez indeksator. Ponieważ indeksator usługi SharePoint Online jest łącznikiem innej firmy z platformą Azure, indeksator nie może odczytać konfiguracji ani zmienić jego zachowania. Reaguje na zmiany w nowej i zmienionej zawartości, niezależnie od sposobu wprowadzania tych aktualizacji. Z tego powodu upewnij się, że testujesz konfigurację i rozumiesz liczbę przetwarzania dokumentów przed użyciem indeksatora i dowolnego wzbogacania sztucznej inteligencji.
Konfigurowanie indeksatora usługi SharePoint Online
Aby skonfigurować indeksator usługi SharePoint Online, użyj witryny Azure Portal i interfejsu API REST w wersji zapoznawczej. Możesz użyć wersji 2020-06-30-preview lub nowszej. Zalecamy najnowszą wersję zapoznawcza interfejsu API.
Ta sekcja zawiera kroki. Możesz również obejrzeć poniższy film wideo.
Krok 1 (opcjonalnie): Włączanie tożsamości zarządzanej przypisanej przez system
Włącz tożsamość zarządzaną przypisaną przez system, aby automatycznie wykryć dzierżawę, w której jest aprowizowana usługa wyszukiwania.
Wykonaj ten krok, jeśli witryna programu SharePoint znajduje się w tej samej dzierżawie co usługa wyszukiwania. Pomiń ten krok, jeśli witryna programu SharePoint znajduje się w innej dzierżawie. Tożsamość nie jest używana do indeksowania, po prostu wykrywania dzierżawy. Możesz również pominąć ten krok, jeśli chcesz umieścić identyfikator dzierżawy w parametry połączenia.
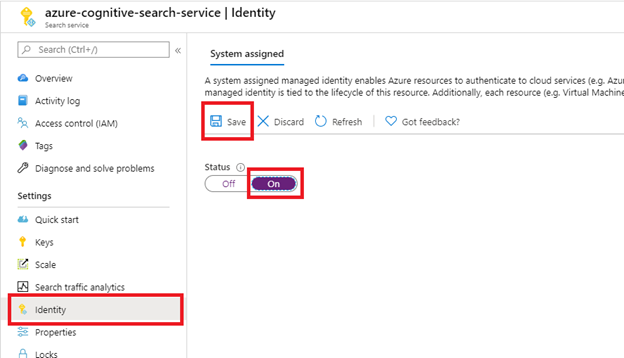
Po wybraniu pozycji Zapisz otrzymasz identyfikator obiektu, który został przypisany do usługi wyszukiwania.
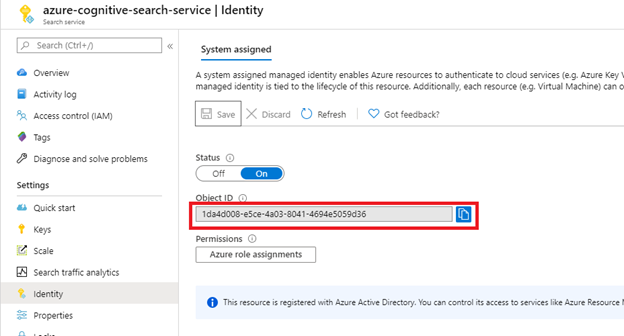
Krok 2. Podjęcie decyzji o uprawnieniach wymaganych przez indeksator
Indeksator usługi SharePoint Online obsługuje zarówno uprawnienia delegowane, jak i uprawnienia aplikacji . Wybierz uprawnienia, których chcesz użyć w zależności od scenariusza.
Zalecamy uprawnienia oparte na aplikacji. Zobacz ograniczenia dotyczące znanych problemów związanych z delegowanymi uprawnieniami.
Uprawnienia aplikacji (zalecane), gdzie indeksator działa w ramach tożsamości dzierżawy programu SharePoint z dostępem do wszystkich witryn i plików. Indeksator wymaga wpisu tajnego klienta. Indeksator będzie również wymagać zatwierdzenia przez administratora dzierżawy, zanim będzie mógł indeksować dowolną zawartość.
Uprawnienia delegowane, gdzie indeksator działa w ramach tożsamości użytkownika lub aplikacji wysyłającej żądanie. Dostęp do danych jest ograniczony do witryn i plików, do których obiekt wywołujący ma dostęp. Aby obsługiwać delegowane uprawnienia, indeksator wymaga monitu o kod urządzenia w celu zalogowania się w imieniu użytkownika. Uprawnienia delegowane przez użytkownika wymuszają wygaśnięcie tokenu co 75 minut, na najnowsze biblioteki zabezpieczeń używane do implementowania tego typu uwierzytelniania. Nie jest to zachowanie, które można dostosować. Wygasły token wymaga ręcznego indeksowania przy użyciu narzędzia Run Indexer (wersja zapoznawcza). Z tego powodu możesz zamiast tego chcieć mieć uprawnienia oparte na aplikacji.
Krok 3. Tworzenie rejestracji aplikacji Firmy Microsoft Entra
Indeksator usługi SharePoint Online używa tej aplikacji Firmy Microsoft Entra do uwierzytelniania.
Zaloguj się w witrynie Azure Portal.
Wyszukaj lub przejdź do pozycji Microsoft Entra ID, a następnie wybierz pozycję Rejestracje aplikacji.
Wybierz pozycję + Nowa rejestracja:
- Podaj nazwę aplikacji.
- Wybierz pozycję Pojedyncza dzierżawa.
- Pomiń krok oznaczenia identyfikatora URI. Nie jest wymagany identyfikator URI przekierowania.
- Wybierz pozycję Zarejestruj.
Po lewej stronie wybierz pozycję Uprawnienia interfejsu API, a następnie dodaj uprawnienie, a następnie pozycję Microsoft Graph.
Jeśli indeksator korzysta z uprawnień interfejsu API aplikacji, wybierz pozycję Uprawnienia aplikacji i dodaj następujące elementy:
- Aplikacja — Files.Read.All
- Aplikacja — Sites.Read.All

Użycie uprawnień aplikacji oznacza, że indeksator uzyskuje dostęp do witryny programu SharePoint w kontekście usługi. Dlatego po uruchomieniu indeksatora będzie on miał dostęp do całej zawartości w dzierżawie programu SharePoint, co wymaga zatwierdzenia przez administratora dzierżawy. Klucz tajny klienta jest również wymagany do uwierzytelniania. Konfigurowanie wpisu tajnego klienta zostało opisane w dalszej części tego artykułu.
Jeśli indeksator korzysta z delegowanych uprawnień interfejsu API, wybierz pozycję Delegowane uprawnienia i dodaj następujące elementy:
- Delegowane — Files.Read.All
- Delegowane — Sites.Read.All
- Delegowane — User.Read
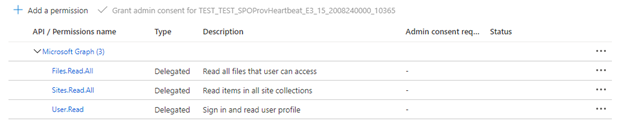
Delegowane uprawnienia umożliwiają klientowi wyszukiwania nawiązywanie połączenia z programem SharePoint w ramach tożsamości zabezpieczeń bieżącego użytkownika.
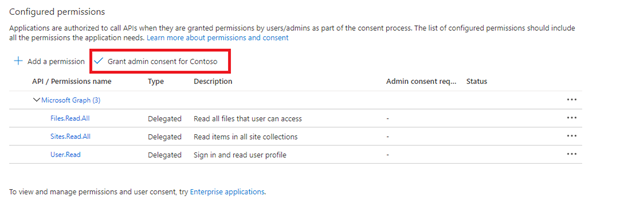
Udziel zgody administratora.
Zgoda administratora dzierżawy jest wymagana w przypadku korzystania z uprawnień interfejsu API aplikacji. Niektóre dzierżawy są zablokowane w taki sposób, że zgoda administratora dzierżawy jest również wymagana dla delegowanych uprawnień interfejsu API. Jeśli którykolwiek z tych warunków ma zastosowanie, przed utworzeniem indeksatora musisz wyrazić zgodę administratora dzierżawy na tę aplikację firmy Microsoft Entra.
Wybierz kartę Uwierzytelnianie.
Ustaw opcję Zezwalaj na przepływy klientów publicznych na wartość Tak , a następnie wybierz pozycję Zapisz.
Wybierz pozycję + Dodaj platformę, a następnie pozycję Aplikacje mobilne i klasyczne, a następnie zaznacz pozycję , a następnie pozycję
https://login.microsoftonline.com/common/oauth2/nativeclientKonfiguruj.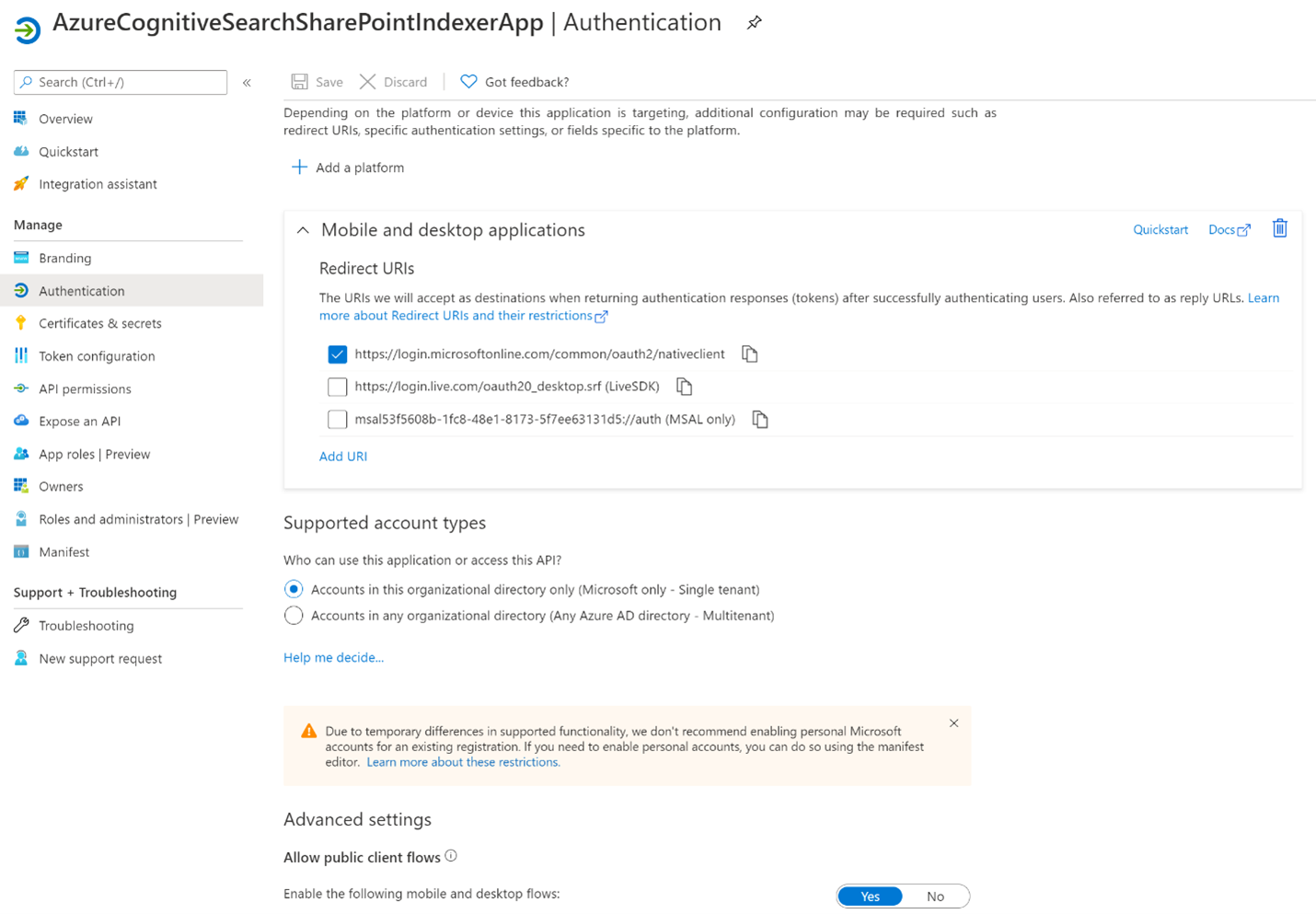
(Tylko uprawnienia interfejsu API aplikacji) Aby uwierzytelnić się w aplikacji Microsoft Entra przy użyciu uprawnień aplikacji, indeksator wymaga wpisu tajnego klienta.
Wybierz pozycję Certyfikaty i wpisy tajne z menu po lewej stronie, a następnie pozycję Wpisy tajne klienta, a następnie Pozycję Nowy klucz tajny klienta.

W wyświetlonym menu wprowadź opis nowego wpisu tajnego klienta. W razie potrzeby dostosuj datę wygaśnięcia. Jeśli wpis tajny wygaśnie, należy go ponownie utworzyć, a indeksator musi zostać zaktualizowany przy użyciu nowego wpisu tajnego.
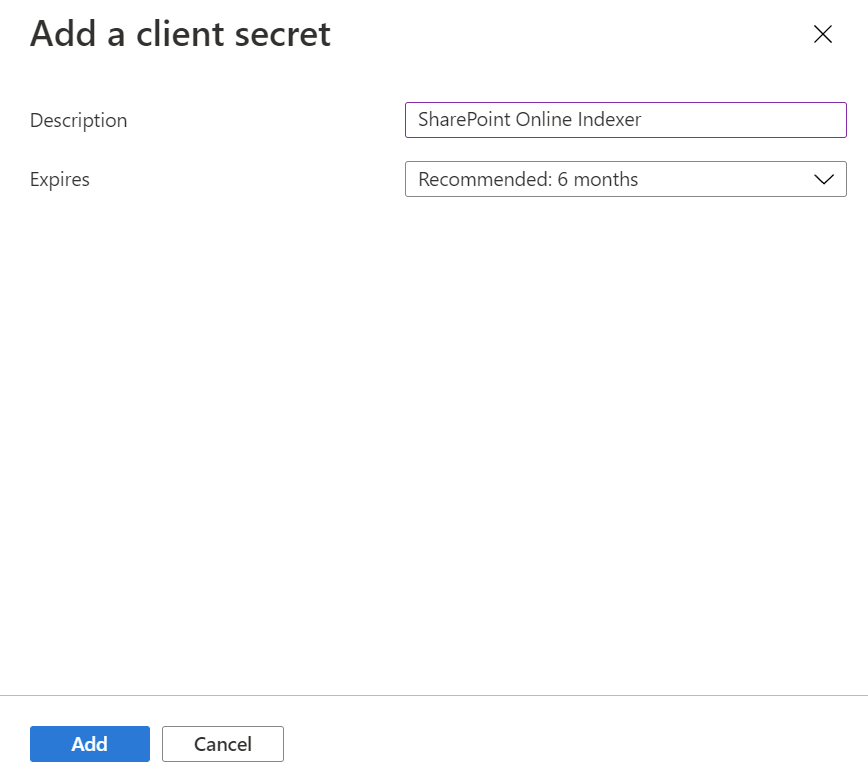
Nowy wpis tajny klienta zostanie wyświetlony na liście wpisów tajnych. Po odejściu od strony wpis tajny nie będzie już widoczny, dlatego skopiuj go przy użyciu przycisku kopiowania i zapisz go w bezpiecznej lokalizacji.

Krok 4. Tworzenie źródła danych
Począwszy od tej sekcji, użyj interfejsu API REST w wersji zapoznawczej, aby wykonać pozostałe kroki. Zalecamy najnowszą wersję zapoznawcza interfejsu API.
Źródło danych określa, które dane mają być indeksowane, poświadczenia i zasady, aby efektywnie identyfikować zmiany w danych (nowe, zmodyfikowane lub usunięte wiersze). Źródło danych może być używane przez wiele indeksatorów w tej samej usłudze wyszukiwania.
W przypadku indeksowania programu SharePoint źródło danych musi mieć następujące wymagane właściwości:
- name to unikatowa nazwa źródła danych w usłudze wyszukiwania.
- typ musi mieć wartość "sharepoint". Ta wartość jest uwzględniana w wielkości liter.
- poświadczenia zapewniają punkt końcowy programu SharePoint i identyfikator aplikacji Microsoft Entra (klienta). Przykładem punktu końcowego programu SharePoint jest
https://microsoft.sharepoint.com/teams/MySharePointSite. Punkt końcowy można uzyskać, przechodząc do strony głównej witryny programu SharePoint i kopiując adres URL z przeglądarki. - kontener określa bibliotekę dokumentów do indeksowania. Właściwości określają, które dokumenty są indeksowane.
Aby utworzyć źródło danych, wywołaj metodę Create Data Source (wersja zapoznawcza).
POST https://[service name].search.windows.net/datasources?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"name" : "sharepoint-datasource",
"type" : "sharepoint",
"credentials" : { "connectionString" : "[connection-string]" },
"container" : { "name" : "defaultSiteLibrary", "query" : null }
}
Format parametrów połączenia
Format parametry połączenia zmienia się na podstawie tego, czy indeksator korzysta z delegowanych uprawnień interfejsu API lub uprawnień interfejsu API aplikacji
Delegowane uprawnienia interfejsu API parametry połączenia format
SharePointOnlineEndpoint=[SharePoint site url];ApplicationId=[Azure AD App ID];TenantId=[SharePoint site tenant id]Uprawnienia interfejsu API aplikacji parametry połączenia format
SharePointOnlineEndpoint=[SharePoint site url];ApplicationId=[Azure AD App ID];ApplicationSecret=[Azure AD App client secret];TenantId=[SharePoint site tenant id]
Uwaga
Jeśli witryna programu SharePoint znajduje się w tej samej dzierżawie co usługa wyszukiwania, a tożsamość zarządzana przypisana przez system jest włączona, TenantId nie musi być uwzględniona w parametry połączenia. Jeśli witryna programu SharePoint znajduje się w innej dzierżawie niż usługa wyszukiwania, TenantId musi zostać uwzględniona.
Krok 5. Tworzenie indeksu
Indeks określa pola w dokumencie, atrybutach i innych konstrukcjach, które kształtuje środowisko wyszukiwania.
Aby utworzyć indeks, wywołaj metodę Create Index (wersja zapoznawcza):
POST https://[service name].search.windows.net/indexes?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"name" : "sharepoint-index",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "metadata_spo_item_name", "type": "Edm.String", "key": false, "searchable": true, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_path", "type": "Edm.String", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_content_type", "type": "Edm.String", "key": false, "searchable": false, "filterable": true, "sortable": false, "facetable": true },
{ "name": "metadata_spo_item_last_modified", "type": "Edm.DateTimeOffset", "key": false, "searchable": false, "filterable": false, "sortable": true, "facetable": false },
{ "name": "metadata_spo_item_size", "type": "Edm.Int64", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": false, "facetable": false }
]
}
Ważne
Tylko metadata_spo_site_library_item_id może być używane jako pole klucza w indeksie wypełnionym przez indeksator usługi SharePoint Online. Jeśli pole klucza nie istnieje w źródle danych, metadata_spo_site_library_item_id zostanie automatycznie zamapowane na pole klucza.
Krok 6. Tworzenie indeksatora
Indeksator łączy źródło danych z docelowym indeksem wyszukiwania i udostępnia harmonogram automatyzowania odświeżania danych. Po utworzeniu indeksu i źródła danych można utworzyć indeksator.
Jeśli używasz uprawnień delegowanych, w tym kroku zostanie wyświetlony monit o zalogowanie się przy użyciu poświadczeń organizacji, które mają dostęp do witryny programu SharePoint. Jeśli to możliwe, zalecamy utworzenie nowego konta użytkownika organizacyjnego i nadanie nowemu użytkownikowi dokładnych uprawnień, które mają mieć indeksator.
Istnieje kilka kroków tworzenia indeksatora:
Wyślij żądanie tworzenia indeksatora (wersja zapoznawcza):
POST https://[service name].search.windows.net/indexers?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key] { "name" : "sharepoint-indexer", "dataSourceName" : "sharepoint-datasource", "targetIndexName" : "sharepoint-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpg", "dataToExtract": "contentAndMetadata" } }, "schedule" : { }, "fieldMappings" : [ { "sourceFieldName" : "metadata_spo_site_library_item_id", "targetFieldName" : "id", "mappingFunction" : { "name" : "base64Encode" } } ] }Jeśli używasz uprawnień aplikacji, musisz poczekać, aż początkowy przebieg zostanie ukończony przed rozpoczęciem wykonywania zapytania względem indeksu. Poniższe instrukcje podane w tym kroku dotyczą konkretnie uprawnień delegowanych i nie mają zastosowania do uprawnień aplikacji.
Podczas tworzenia indeksatora po raz pierwszy żądanie Tworzenie indeksatora (wersja zapoznawcza) czeka na ukończenie następnego kroku. Aby uzyskać link, musisz wywołać metodę Pobierz stan indeksatora i wprowadzić nowy kod urządzenia.
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key]Jeśli nie uruchomisz stanu get indexer w ciągu 10 minut, kod wygaśnie i musisz ponownie utworzyć źródło danych.
Skopiuj kod logowania urządzenia z odpowiedzi Pobierz stan indeksatora . Identyfikator logowania urządzenia można znaleźć w "errorMessage".
{ "lastResult": { "status": "transientFailure", "errorMessage": "To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code <CODE> to authenticate." } }Podaj kod dołączony do komunikatu o błędzie.
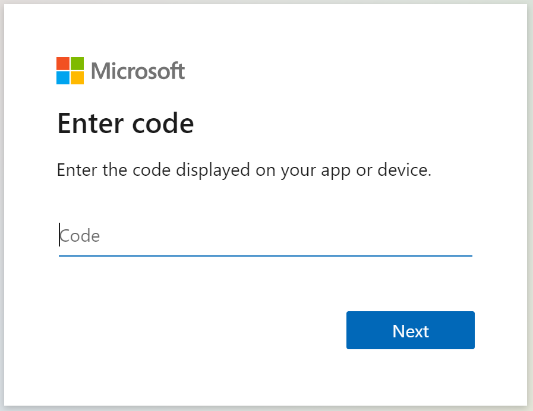
Indeksator usługi SharePoint Online będzie uzyskiwać dostęp do zawartości programu SharePoint jako zalogowany użytkownik. Użytkownik, który loguje się w tym kroku, będzie zalogowanym użytkownikiem. Dlatego jeśli zalogujesz się przy użyciu konta użytkownika, które nie ma dostępu do dokumentu w bibliotece dokumentów, którą chcesz indeksować, indeksator nie będzie miał dostępu do tego dokumentu.
Jeśli to możliwe, zalecamy utworzenie nowego konta użytkownika i nadanie nowemu użytkownikowi dokładnych uprawnień, które mają mieć indeksator.
Zatwierdź żądane uprawnienia.
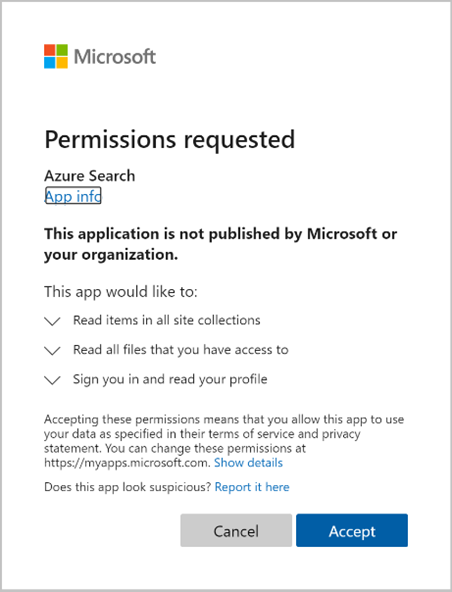
Początkowe żądanie tworzenia indeksatora (wersja zapoznawcza) zostanie ukończone, jeśli wszystkie podane powyżej uprawnienia są poprawne i w przedziale czasu 10 minut.
Uwaga
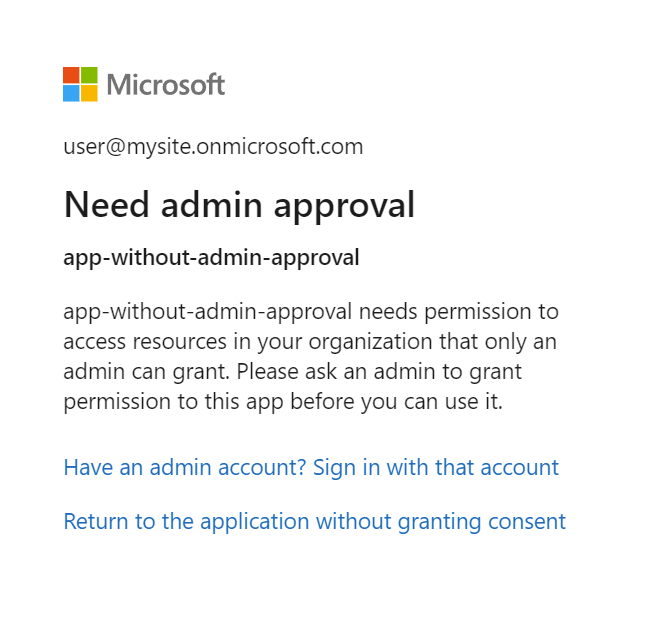
Jeśli aplikacja Microsoft Entra wymaga zatwierdzenia przez administratora i nie została zatwierdzona przed zalogowaniem, może zostać wyświetlony następujący ekran. Aby kontynuować, wymagane jest zatwierdzenie przez administratora.
Krok 7. Sprawdzanie stanu indeksatora
Po utworzeniu indeksatora można wywołać metodę Pobierz stan indeksatora:
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
Aktualizowanie źródła danych
Jeśli nie ma aktualizacji obiektu źródła danych, indeksator jest uruchamiany zgodnie z harmonogramem bez żadnej interakcji użytkownika.
Jeśli jednak zmodyfikujesz obiekt źródła danych, gdy kod urządzenia wygasł, musisz zalogować się ponownie, aby indeksator był uruchamiany. Jeśli na przykład zmienisz zapytanie źródła danych, zaloguj się ponownie przy użyciu polecenia https://microsoft.com/devicelogin i pobierz nowy kod urządzenia.
Poniżej przedstawiono kroki aktualizowania źródła danych przy założeniu, że wygasły kod urządzenia:
Wywołaj funkcję Run Indexer (wersja zapoznawcza), aby ręcznie uruchomić wykonywanie indeksatora.
POST https://[service name].search.windows.net/indexers/sharepoint-indexer/run?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key]Sprawdź stan indeksatora.
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2024-05-01-preview Content-Type: application/json api-key: [admin key]Jeśli wystąpi błąd z prośbą o wizytę
https://microsoft.com/devicelogin, otwórz stronę i skopiuj nowy kod.Wklej kod do okna dialogowego.
Ręcznie uruchom indeksator ponownie i sprawdź stan indeksatora. Tym razem uruchomienie indeksatora powinno zostać pomyślnie uruchomione.
Indeksowanie metadanych dokumentu
Jeśli indeksujesz metadane dokumentu ("dataToExtract": "contentAndMetadata"), następujące metadane będą dostępne dla indeksowania.
| Identyfikator | Type | Opis |
|---|---|---|
| metadata_spo_site_library_item_id | Edm.String | Klucz kombinacji identyfikatora witryny, identyfikatora biblioteki i identyfikatora elementu, który jednoznacznie identyfikuje element w bibliotece dokumentów dla witryny. |
| metadata_spo_site_id | Edm.String | Identyfikator witryny programu SharePoint. |
| metadata_spo_library_id | Edm.String | Identyfikator biblioteki dokumentów. |
| metadata_spo_item_id | Edm.String | Identyfikator elementu (dokumentu) w bibliotece. |
| metadata_spo_item_last_modified | Edm.DateTimeOffset | Data/godzina ostatniej modyfikacji (UTC) elementu. |
| metadata_spo_item_name | Edm.String | Nazwa elementu. |
| metadata_spo_item_size | Edm.Int64 | Rozmiar (w bajtach) elementu. |
| metadata_spo_item_content_type | Edm.String | Typ zawartości elementu. |
| metadata_spo_item_extension | Edm.String | Rozszerzenie elementu. |
| metadata_spo_item_weburi | Edm.String | Identyfikator URI elementu. |
| metadata_spo_item_path | Edm.String | Kombinacja ścieżki nadrzędnej i nazwy elementu. |
Indeksator usługi SharePoint Online obsługuje również metadane specyficzne dla każdego typu dokumentu. Więcej informacji można znaleźć we właściwościach metadanych zawartości używanych w usłudze Azure AI Search.
Uwaga
Aby indeksować metadane niestandardowe, należy określić wartość "additionalColumns" w parametrze zapytania źródła danych.
Dołączanie lub wykluczanie według typu pliku
Możesz kontrolować, które pliki są indeksowane, ustawiając kryteria dołączania i wykluczania w sekcji "parameters" definicji indeksatora.
Uwzględnij określone rozszerzenia plików, ustawiając "indexedFileNameExtensions" na rozdzielaną przecinkami listę rozszerzeń plików (z kropką wiodącą). Wyklucz określone rozszerzenia plików, ustawiając "excludedFileNameExtensions" na rozszerzenia, które powinny zostać pominięte. Jeśli to samo rozszerzenie znajduje się na obu listach, jest wykluczone z indeksowania.
PUT /indexers/[indexer name]?api-version=2024-05-01-preview
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
Kontrolowanie, które dokumenty są indeksowane
Pojedynczy indeksator usługi SharePoint Online może indeksować zawartość z co najmniej jednej biblioteki dokumentów. Użyj parametru "container" w definicji źródła danych, aby wskazać witryny i biblioteki dokumentów do indeksowania.
Sekcja "kontener" źródła danych ma dwie właściwości dla tego zadania: "name" i "query".
Nazwisko
Właściwość "name" jest wymagana i musi być jedną z trzech wartości:
| Wartość | Opis |
|---|---|
| defaultSiteLibrary | Zaindeksuj całą zawartość z domyślnej biblioteki dokumentów witryny. |
| allSiteLibraries | Indeksowanie całej zawartości ze wszystkich bibliotek dokumentów w witrynie. Biblioteki dokumentów z podwitryny są poza zakresem/ Jeśli potrzebujesz zawartości z podwitryn, wybierz pozycję "useQuery" i określ "includeLibrariesInSite". |
| useQuery | Indeksuj tylko zawartość zdefiniowaną w "zapytaniu". |
Query
Parametr "query" źródła danych składa się z par słów kluczowych/wartości. Poniżej znajdują się słowa kluczowe, których można użyć. Wartości to adresy URL witryny lub adresy URL biblioteki dokumentów.
Uwaga
Aby uzyskać wartość określonego słowa kluczowego, zalecamy przejście do biblioteki dokumentów, którą próbujesz dołączyć/wykluczyć i skopiować identyfikator URI z przeglądarki. Jest to najprostszy sposób uzyskania wartości do użycia ze słowem kluczowym w zapytaniu.
| Słowo kluczowe | Opis wartości i przykłady |
|---|---|
| null | Jeśli wartość null lub jest pusta, indeksuj domyślną bibliotekę dokumentów lub wszystkie biblioteki dokumentów w zależności od nazwy kontenera. Przykład: "container" : { "name" : "defaultSiteLibrary", "query" : null } |
| includeLibrariesInSite | Indeksowanie zawartości ze wszystkich bibliotek w określonej witrynie w parametry połączenia. Wartość powinna być identyfikatorem URI witryny lub podwitryny. Przykład 1: "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/mysite" } Przykład 2 (obejmuje tylko kilka podwitryn): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/sites/TopSite/SubSite1;includeLibrariesInSite=https://mycompany.sharepoint.com/sites/TopSite/SubSite2" } |
| includeLibrary | Indeksuj całą zawartość z tej biblioteki. Wartość jest w pełni kwalifikowaną ścieżką do biblioteki, którą można skopiować z przeglądarki: Przykład 1 (w pełni kwalifikowana ścieżka): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/mysite/MyDocumentLibrary" } Przykład 2 (identyfikator URI skopiowany z przeglądarki): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx" } |
| excludeLibrary | Nie indeksuj zawartości z tej biblioteki. Wartość jest w pełni kwalifikowaną ścieżką do biblioteki, którą można skopiować z przeglądarki: Przykład 1 (w pełni kwalifikowana ścieżka): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mysite.sharepoint.com/subsite1; excludeLibrary=https://mysite.sharepoint.com/subsite1/MyDocumentLibrary" } Przykład 2 (identyfikator URI skopiowany z przeglądarki): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/teams/mysite; excludeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx" } |
| additionalColumns | Indeksowanie kolumn z biblioteki dokumentów. Wartość jest rozdzielaną przecinkami listą nazw kolumn, które chcesz indeksować. Użyj podwójnego ukośnika odwrotnego, aby uniknąć średników i przecinków w nazwach kolumn: Przykład 1 (additionalColumns=MyCustomColumn,MyCustomColumn2): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/mysite/MyDocumentLibrary;additionalColumns=MyCustomColumn,MyCustomColumn2" } Przykład 2 (znaki ucieczki używające podwójnego ukośnika odwrotnego): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx;additionalColumns=MyCustomColumnWith\\,,MyCustomColumnWith\\;" } |
Obsługa błędów
Domyślnie indeksator usługi SharePoint Online zatrzymuje się zaraz po napotkaniu dokumentu z nieobsługiwanym typem zawartości (na przykład obrazem). Możesz użyć parametru excludedFileNameExtensions , aby pominąć niektóre typy zawartości. Jednak może być konieczne indeksowanie dokumentów bez wcześniejszej znajomości wszystkich możliwych typów zawartości. Aby kontynuować indeksowanie po napotkaniu nieobsługiwanego typu zawartości, ustaw failOnUnsupportedContentType parametr konfiguracji na false:
PUT https://[service name].search.windows.net/indexers/[indexer name]?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
... other parts of indexer definition
"parameters" : { "configuration" : { "failOnUnsupportedContentType" : false } }
}
W przypadku niektórych dokumentów usługa Azure AI Search nie może określić typu zawartości lub nie może przetworzyć dokumentu innego obsługiwanego typu zawartości. Aby zignorować ten tryb niepowodzenia, ustaw failOnUnprocessableDocument parametr konfiguracji na false:
"parameters" : { "configuration" : { "failOnUnprocessableDocument" : false } }
Usługa Azure AI Search ogranicza rozmiar indeksowanych dokumentów. Te limity są udokumentowane w artykule Limity usług w usłudze Azure AI Search. Zawyczone dokumenty są domyślnie traktowane jako błędy. Jednak nadal można indeksować metadane magazynu za pośrednictwem dokumentów, jeśli ustawisz indexStorageMetadataOnlyForOversizedDocuments parametr konfiguracji na true:
"parameters" : { "configuration" : { "indexStorageMetadataOnlyForOversizedDocuments" : true } }
Możesz również kontynuować indeksowanie, jeśli w dowolnym momencie przetwarzania wystąpią błędy podczas analizowania dokumentów lub podczas dodawania dokumentów do indeksu. Aby zignorować określoną liczbę błędów, ustaw maxFailedItems parametry konfiguracji i maxFailedItemsPerBatch na żądane wartości. Na przykład:
{
... other parts of indexer definition
"parameters" : { "maxFailedItems" : 10, "maxFailedItemsPerBatch" : 10 }
}
Jeśli plik w witrynie programu SharePoint ma włączone szyfrowanie, może wystąpić komunikat o błędzie podobny do następującego:
Code: resourceModified Message: The resource has changed since the caller last read it; usually an eTag mismatch Inner error: Code: irmEncryptFailedToFindProtector
Komunikat o błędzie będzie również zawierać identyfikator witryny programu SharePoint, identyfikator dysku i identyfikator elementu dysku w następującym wzorcu: <sharepoint site id> :: <drive id> :: <drive item id>. Te informacje mogą służyć do identyfikowania, który element kończy się niepowodzeniem na końcu programu SharePoint. Użytkownik może następnie usunąć szyfrowanie z elementu, aby rozwiązać ten problem.