Uruchamianie lub resetowanie indeksatorów, umiejętności lub dokumentów
W usłudze Azure AI Search istnieje kilka sposobów uruchamiania indeksatora:
- Uruchamiaj natychmiast po utworzeniu indeksatora, zakładając, że nie jest on tworzony w trybie "wyłączony".
- Uruchom polecenie zgodnie z harmonogramem , aby wywołać wykonywanie w regularnych odstępach czasu.
- Uruchamianie na żądanie z użyciem resetowania lub bez "resetuj".
W tym artykule wyjaśniono, jak uruchamiać indeksatory na żądanie i bez resetowania. Opisuje również wykonywanie indeksatora, czas trwania i współbieżność.
Jak indeksatory łączą się z zasobami platformy Azure
Indeksatory są jednym z niewielu podsystemów, które tworzą overt wychodzące wywołania do innych zasobów platformy Azure. Jeśli chodzi o role platformy Azure, indeksatory nie mają oddzielnych tożsamości: połączenie z wyszukiwarki do innego zasobu platformy Azure jest wykonywane przy użyciu tożsamości zarządzanej przypisanej przez użytkownika systemu lub użytkownika usługi wyszukiwania. Jeśli indeksator łączy się z zasobem platformy Azure w sieci wirtualnej, należy utworzyć udostępniony link prywatny dla tego połączenia. Aby uzyskać więcej informacji na temat bezpiecznych połączeń, zobacz Zabezpieczenia w usłudze Azure AI Search.
Wykonywanie indeksatora
Usługa wyszukiwania uruchamia jedno zadanie indeksatora na jednostkę wyszukiwania. Każda usługa wyszukiwania rozpoczyna się od jednej jednostki wyszukiwania, ale każda nowa partycja lub replika zwiększa liczbę jednostek wyszukiwania usługi. Liczbę jednostek wyszukiwania można sprawdzić w sekcji Podstawy portalu na stronie Przegląd . Jeśli potrzebujesz przetwarzania współbieżnego, upewnij się, że masz wystarczające repliki. Indeksatory nie działają w tle, więc możesz wykryć więcej ograniczania zapytań niż zwykle, jeśli usługa jest pod presją.
Poniższy zrzut ekranu przedstawia liczbę jednostek wyszukiwania, która określa liczbę indeksatorów, które mogą być uruchamiane jednocześnie.

Po uruchomieniu wykonywania indeksatora nie można go wstrzymać ani zatrzymać. Wykonywanie indeksatora zostaje zatrzymane, gdy nie ma więcej dokumentów do załadowania lub odświeżenia lub gdy zostanie osiągnięty maksymalny limit czasu działania.
Jednocześnie można uruchomić wiele indeksatorów przy założeniu wystarczającej pojemności, ale każdy indeksator jest pojedynczym wystąpieniem. Uruchomienie nowego wystąpienia, gdy indeksator jest już w wykonaniu, powoduje następujący błąd: "Failed to run indexer "<indexer name>" error: "Another indexer invocation is currently in progress; concurrent invocations are not allowed."
Zadanie indeksatora jest uruchamiane w zarządzanym środowisku wykonywania. Obecnie istnieją dwa środowiska. Nie można kontrolować ani konfigurować używanego środowiska. Usługa Azure AI Search określa środowisko na podstawie kompozycji zadań i możliwość przeniesienia zadania indeksatora na procesor zawartości (niektóre funkcje zabezpieczeń blokują środowisko wielodostępne).
Środowiska wykonywania indeksatora obejmują:
Prywatne środowisko wykonawcze, które działa w węzłach wyszukiwania, specyficzne dla usługi wyszukiwania.
Wielodostępne środowisko z procesorami zawartości, zarządzane i zabezpieczone przez firmę Microsoft bez dodatkowych kosztów. To środowisko służy do odciążania przetwarzania intensywnie korzystającego z obliczeń, pozostawiając zasoby specyficzne dla usługi dostępne dla rutynowych operacji. Jeśli to możliwe, większość zadań indeksatora jest wykonywana w środowisku wielodostępnym.
Limity indeksatora różnią się w zależności od środowiska:
| Obciążenie | Maksymalny czas trwania | Maksymalna liczba zadań | Środowisko wykonywania |
|---|---|---|---|
| Wykonywanie prywatne | 24 godz. | Jedno zadanie indeksatora na jednostkęwyszukiwania 1. | Indeksowanie nie jest uruchamiane w tle. Zamiast tego usługa wyszukiwania równoważy wszystkie zadania indeksowania względem bieżących zapytań i akcji zarządzania obiektami (takich jak tworzenie lub aktualizowanie indeksów). Podczas uruchamiania indeksatorów należy oczekiwać, że niektóre opóźnienia zapytań będą widoczne, jeśli woluminy indeksowania są duże. |
| Wielodostępność | 2 godziny 2 | Nieokreślony 3 | Ponieważ klaster przetwarzania zawartości jest wielodostępny, węzły są dodawane w celu spełnienia wymagań. Jeśli wystąpi opóźnienie w wykonywaniu na żądanie lub zaplanowanym, prawdopodobnie jest to spowodowane dodawaniem węzłów przez system lub oczekiwaniem na udostępnienie jednego z nich. |
1 Jednostki wyszukiwania mogą być elastycznymi kombinacjami partycji i replik, ale zadania indeksatora nie są powiązane z jedną lub drugą. Innymi słowy, jeśli masz 12 jednostek, możesz mieć 12 zadań indeksatora działających współbieżnie w ramach wykonywania prywatnego, niezależnie od sposobu wdrażania jednostek wyszukiwania.
2 Jeśli do przetwarzania wszystkich danych potrzebne są ponad dwie godziny, włącz wykrywanie zmian i zaplanuj uruchamianie indeksatora w dwóch godzinach. Aby uzyskać więcej strategii, zobacz Indeksowanie dużego zestawu danych.
3 "Nieokreślone" oznacza, że limit nie jest kwantyfikowany przez liczbę zadań. Niektóre obciążenia, takie jak przetwarzanie zestawu umiejętności, mogą działać równolegle, co może spowodować powstanie wielu zadań, mimo że zaangażowany jest tylko jeden indeksator. Mimo że środowisko nie nakłada ograniczeń, nadal obowiązują limity indeksatora dla usługi wyszukiwania.
Uruchamianie bez resetowania
Operacja uruchom indeksatora wykryje i przetworzy tylko to, co konieczne do zsynchronizowania indeksu wyszukiwania ze zmianami w bazowym źródle danych. Indeksowanie przyrostowe rozpoczyna się od zlokalizowania wewnętrznego znacznika wysokiej wody w celu znalezienia ostatniego zaktualizowanego dokumentu wyszukiwania, który staje się punktem wyjścia do wykonywania indeksatora w nowych i zaktualizowanych dokumentach w źródle danych.
Wykrywanie zmian jest niezbędne do określenia nowości lub aktualizacji w źródle danych. Indeksatory używają funkcji wykrywania zmian bazowego źródła danych, aby określić, co nowego lub zaktualizowanego w źródle danych.
Usługa Azure Storage ma wbudowane wykrywanie zmian za pośrednictwem swojej właściwości LastModified.
Inne źródła danych, takie jak Azure SQL lub Azure Cosmos DB, muszą być skonfigurowane do wykrywania zmian, zanim indeksator będzie mógł odczytać nowe i zaktualizowane wiersze.
Jeśli zawartość bazowa jest niezmieniona, operacja uruchamiania nie ma żadnego efektu. W takim przypadku historia wykonywania indeksatora będzie wskazywać 0\0 przetworzone dokumenty.
Aby ponownie przetworzyć proces ponownego przetwarzania, należy zresetować indeksator, zgodnie z wyjaśnieniem w następnej sekcji.
Resetowanie indeksatorów
Po początkowym uruchomieniu indeksator śledzi, które dokumenty wyszukiwania zostały indeksowane za pomocą wewnętrznego znacznika wysokiej wody. Znacznik nigdy nie jest ujawniany, ale wewnętrznie indeksator wie, gdzie ostatnio został zatrzymany.
Jeśli musisz ponownie skompilować cały indeks lub część indeksu, możesz wyczyścić znak wysokiej wody indeksatora za pomocą resetowania. Interfejsy API resetowania są dostępne na malejących poziomach w hierarchii obiektów:
- Resetuj indeksatory czyści znacznik wysokiego poziomu i wykonuje pełną ponowną indeksowanie wszystkich dokumentów
- Ponowne indeksowanie określonego dokumentu lub listy dokumentów przez resetowanie dokumentów (wersja zapoznawcza)
- Resetowanie umiejętności (wersja zapoznawcza) wywołuje przetwarzanie umiejętności dla określonej umiejętności
Po zresetowaniu wykonaj polecenie Uruchom, aby ponownie przetworzyć nowe i istniejące dokumenty. Oddzielone dokumenty wyszukiwania bez odpowiednika w źródle danych nie mogą być usuwane za pośrednictwem resetowania/uruchamiania. Jeśli chcesz usunąć dokumenty, zobacz Zamiast tego dodawanie, aktualizowanie lub usuwanie dokumentów .
Jak zresetować i uruchomić indeksatory
Reset czyści znak wysokiej wody. Wszystkie dokumenty w indeksie wyszukiwania będą oflagowane w celu pełnego zastąpienia bez wbudowanych aktualizacji ani scalania z istniejącą zawartością. W przypadku indeksatorów z zestawem umiejętności i buforowaniem wzbogacania resetowanie indeksu spowoduje również niejawne zresetowanie zestawu umiejętności.
Rzeczywista praca odbywa się po zresetowaniu za pomocą polecenia Uruchom:
- Wszystkie nowe dokumenty, które znalazły bazowe źródło, są dodawane do indeksu wyszukiwania.
- Wszystkie dokumenty istniejące zarówno w źródle danych, jak i indeksie wyszukiwania zostaną zastąpione w indeksie wyszukiwania.
- Każda wzbogacona zawartość utworzona na podstawie zestawów umiejętności zostanie przebudowana. Pamięć podręczna wzbogacania, jeśli jest włączona, jest odświeżona.
Jak wspomniano wcześniej, resetowanie jest operacją pasywną: musisz wykonać żądanie Uruchomienia, aby ponownie skompilować indeks.
Operacje resetowania/uruchamiania mają zastosowanie do indeksu wyszukiwania lub magazynu wiedzy, do określonych dokumentów lub projekcji oraz do buforowanych wzbogacenia, jeśli resetowanie jawnie lub niejawnie obejmuje umiejętności.
Resetowanie dotyczy również operacji tworzenia i aktualizowania. Nie spowoduje to usunięcia ani wyczyszczenia oddzielonych dokumentów w indeksie wyszukiwania. Aby uzyskać więcej informacji na temat usuwania dokumentów, zobacz Dodawanie, aktualizowanie lub usuwanie dokumentów.
Po zresetowaniu indeksatora nie można cofnąć akcji.
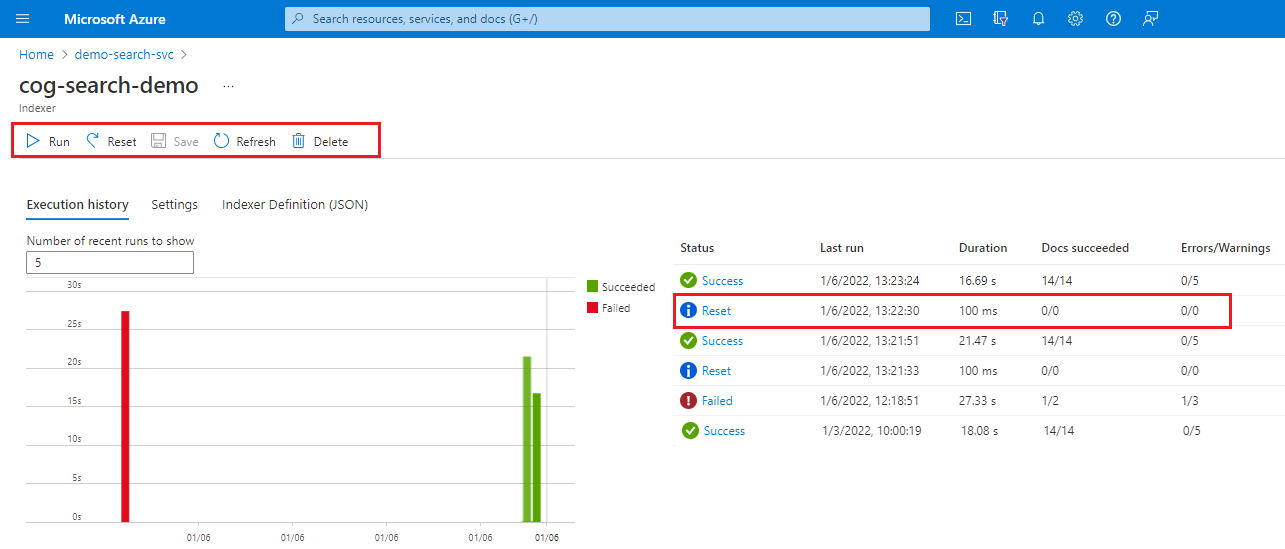
Zaloguj się do witryny Azure Portal i otwórz stronę usługi wyszukiwania.
Na stronie Przegląd wybierz kartę Indeksatory.
Wybierz indeksator.
Wybierz polecenie Resetuj, a następnie wybierz pozycję Tak, aby potwierdzić akcję.
Odśwież stronę, aby wyświetlić stan. Możesz wybrać element, aby wyświetlić jego szczegóły.
Wybierz pozycję Uruchom , aby rozpocząć przetwarzanie indeksatora lub poczekaj na następne zaplanowane wykonanie.
Jak zresetować umiejętności (wersja zapoznawcza)
W przypadku indeksatorów, którzy mają zestawy umiejętności, można zresetować indywidualne umiejętności, aby wymusić przetwarzanie tylko tej umiejętności i wszelkich umiejętności podrzędnych, które zależą od jego danych wyjściowych. Pamięć podręczna wzbogacania, jeśli ją włączono, jest również odświeżona.
Resetowanie umiejętności jest obecnie dostępne tylko w api-version=2020-06-30-Preview interfejsie REST lub nowszym.
POST /skillsets/[skillset name]/resetskills?api-version=2020-06-30-Preview
{
"skillNames" : [
"#1",
"#5",
"#6"
]
}
Możesz określić indywidualne umiejętności, jak wskazano w powyższym przykładzie, ale jeśli którekolwiek z tych umiejętności wymaga danych wyjściowych z umiejętności nieznajdujących się na liście (od #2 do 4), nie będą uruchamiane umiejętności niewymienione, chyba że pamięć podręczna może dostarczyć niezbędnych informacji. Aby było to prawdziwe, buforowane wzbogacania umiejętności od #2 do #4 nie mogą mieć zależności od #1 (wymienione do zresetowania).
Jeśli nie określono żadnych umiejętności, cały zestaw umiejętności jest wykonywany i jeśli buforowanie jest włączone, pamięć podręczna jest również odświeżona.
Pamiętaj, aby postępować zgodnie z instrukcjami Uruchom indeksator w celu wywołania rzeczywistego przetwarzania.
Jak zresetować dokumenty (wersja zapoznawcza)
Interfejs API resetowania dokumentów akceptuje listę kluczy dokumentów, dzięki czemu można odświeżyć określone dokumenty. Jeśli zostanie określony, parametry resetowania stają się jedynym determinantem tego, co jest przetwarzane, niezależnie od innych zmian w danych bazowych. Jeśli na przykład 20 obiektów blob zostało dodanych lub zaktualizowanych od ostatniego uruchomienia indeksatora, ale tylko jeden dokument zostanie zresetowany, tylko ten dokument jest przetwarzany.
Na podstawie poszczególnych dokumentów wszystkie pola w tym dokumencie wyszukiwania są odświeżane wartościami ze źródła danych. Nie można wybrać i wybrać pól do odświeżenia.
Jeśli dokument jest wzbogacony za pomocą zestawu umiejętności i zawiera dane buforowane, zestaw umiejętności jest wywoływany tylko dla określonych dokumentów, a pamięć podręczna jest aktualizowana dla ponownie przetworzonych dokumentów.
Podczas testowania tego interfejsu API po raz pierwszy następujące interfejsy API mogą pomóc w weryfikowaniu i testowaniu zachowań:
Wywołaj metodę Pobierz stan indeksatora z wersją
api-version=2020-06-30-Previewinterfejsu API lub nowszą wersją, aby sprawdzić stan resetowania i stan wykonywania. Informacje o żądaniu resetowania można znaleźć na końcu odpowiedzi stanu.Wywołaj funkcję Resetuj dokumenty przy użyciu wersji interfejsu API lub nowszej
api-version=2020-06-30-Previewwersji, aby określić dokumenty do przetworzenia.POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2020-06-30-Preview { "documentKeys" : [ "1001", "4452" ] }Klucze dokumentów podane w żądaniu to wartości z indeksu wyszukiwania, które mogą różnić się od odpowiednich pól w źródle danych. Jeśli nie masz pewności co do wartości klucza, wyślij zapytanie , aby zwrócić wartość. Możesz użyć
selectpolecenia , aby zwrócić tylko pole klucza dokumentu.W przypadku obiektów blob, które są analizowane w wielu dokumentach wyszukiwania (gdzie parametr parsingMode jest ustawiony na wartość jsonLines lub jsonArrays lub delimitedText), klucz dokumentu jest generowany przez indeksator i może być nieznany. W tym scenariuszu zapytanie dotyczące klucza dokumentu w celu zwrócenia poprawnej wartości.
Wywołaj usługę Run Indexer (dowolną wersję interfejsu API), aby przetworzyć określone dokumenty. Indeksowane są tylko te określone dokumenty.
Wywołaj funkcję Run Indexer po raz drugi, aby przetworzyć z ostatniego znacznika wysokiej wody.
Wywołaj funkcję Wyszukaj dokumenty , aby sprawdzić zaktualizowane wartości, a także zwrócić klucze dokumentów, jeśli nie masz pewności co do wartości. Użyj polecenia
"select": "<field names>", jeśli chcesz ograniczyć pola wyświetlane w odpowiedzi.
Zastępowanie listy kluczy dokumentu
Wywołanie interfejsu API resetowania dokumentów wiele razy z różnymi kluczami dołącza nowe klucze do listy resetowania kluczy dokumentów. Wywołanie interfejsu API z parametrem ustawionym overwrite na true spowoduje zastąpienie bieżącej listy nowym:
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2020-06-30-Preview
{
"documentKeys" : [
"200",
"630"
],
"overwrite": true
}
Sprawdź stan resetowania "currentState"
Aby sprawdzić stan resetowania i sprawdzić, które klucze dokumentów są w kolejce do przetworzenia, wykonaj następujące kroki.
Wywołaj metodę Pobierz stan indeksatora za pomocą
api-version=06-30-2020-Previewpolecenia lub nowszego.Interfejs API w wersji zapoznawczej zwróci sekcję
currentStateznajdującą się na końcu odpowiedzi."currentState": { "mode": "indexingResetDocs", "allDocsInitialTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "allDocsFinalTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "resetDocsInitialTrackingState": null, "resetDocsFinalTrackingState": null, "resetDocumentKeys": [ "200", "630" ] }Sprawdź tryb:
W obszarze Resetowanie umiejętności należy ustawić
indexingAllDocswartość "tryb" (ponieważ potencjalnie wszystkie dokumenty mają wpływ na pola wypełniane za pomocą wzbogacania sztucznej inteligencji).W obszarze Resetuj dokumenty należy ustawić wartość "mode" na
indexingResetDocswartość . Indeksator zachowuje ten stan do momentu przetworzenia wszystkich kluczy dokumentów podanych w wywołaniu dokumentów resetowania, w tym czasie żadne inne zadania indeksatora nie będą wykonywane podczas wykonywania operacji. Znalezienie wszystkich dokumentów na liście kluczy dokumentów wymaga złamania każdego dokumentu w celu zlokalizowania i dopasowania go w kluczu. Może to chwilę potrwać, jeśli zestaw danych jest duży. Jeśli kontener obiektów blob zawiera setki obiektów blob, a dokumenty, które chcesz zresetować, znajdują się na końcu, indeksator nie znajdzie pasujących obiektów blob, dopóki wszystkie inne nie zostaną najpierw sprawdzone.Po ponownym przetworzeniu dokumentów ponownie uruchom polecenie Pobierz stan indeksatora. Indeksator powróci do
indexingAllDocstrybu i przetworzy wszystkie nowe lub zaktualizowane dokumenty w następnym uruchomieniu.
Następne kroki
Resetowanie interfejsów API służy do informowania o zakresie następnego uruchomienia indeksatora. W przypadku rzeczywistego przetwarzania należy wywołać uruchomienie indeksatora na żądanie lub zezwolić na ukończenie pracy zaplanowanego zadania. Po zakończeniu przebiegu indeksator powraca do normalnego przetwarzania, niezależnie od tego, czy jest to przetwarzanie według harmonogramu, czy przetwarzania na żądanie.
Po zresetowaniu i ponownym uruchomieniu zadań indeksatora można monitorować stan z usługi wyszukiwania lub uzyskać szczegółowe informacje za pośrednictwem rejestrowania zasobów.