Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ten artykuł to zbiór wskazówek i najlepszych rozwiązań dotyczących zwiększania wydajności zapytań i indeksowania wyszukiwania słów kluczowych. Wiedza, które czynniki najprawdopodobniej wpływają na wydajność wyszukiwania, może pomóc uniknąć nieefektywności i jak najlepiej wykorzystać usługę wyszukiwania. Oto niektóre kluczowe czynniki:
- Kompozycja indeksu (schemat i rozmiar)
- Projekt zapytania
- Pojemność usługi (poziom, liczba replik i liczba partycji)
Uwaga / Notatka
Szukasz strategii dotyczących indeksowania dużej ilości danych? Zobacz Indeksowanie dużych zestawów danych w usłudze Azure AI Search.
Rozmiar indeksu i schemat
Zapytania działają szybciej na mniejszych indeksach. Jest to częściowo funkcja mająca mniej pól do skanowania, ale jest to również spowodowane tym, jak system buforuje zawartość dla przyszłych zapytań. Po pierwszym zapytaniu część zawartości pozostaje w pamięci, w której jest wyszukiwana wydajniej. Ponieważ rozmiar indeksu zwykle rośnie wraz z upływem czasu, najlepszym rozwiązaniem jest okresowe ponowne zapoznanie się ze składem indeksu, zarówno schematem, jak i dokumentami, w celu wyszukania możliwości redukcji zawartości. Jeśli jednak indeks ma odpowiedni rozmiar, jedyną inną kalibracją, którą można wykonać, jest zwiększenie pojemności przez uaktualnienie usługi, dodanie replik lub przełączenie do wyższej warstwy cenowej. W sekcji "Porada: przełącz się na warstwę Standardową S2" omówiono decyzję dotyczącą skalowania w górę i skalowania w poziomie.
Złożoność schematu może również niekorzystnie wpłynąć na indeksowanie i wydajność zapytań. Nadmierne przypisywanie pól prowadzi do ograniczeń i wymagań dotyczących przetwarzania. Indeksowanie i wykonywanie zapytań w typach złożonych trwa dłużej. W następnych kilku sekcjach omówione zostaną wszystkie warunki.
Porada: selektywne przypisywanie pól
Typowym błędem, jaki administratorzy i deweloperzy popełniają podczas tworzenia indeksu wyszukiwania, jest wybranie wszystkich dostępnych właściwości pól, w przeciwieństwie do wybierania tylko potrzebnych właściwości. Jeśli na przykład pole nie musi być przeszukiwalne w pełnym tekście, pomiń to pole podczas ustawiania atrybutu z możliwością wyszukiwania.
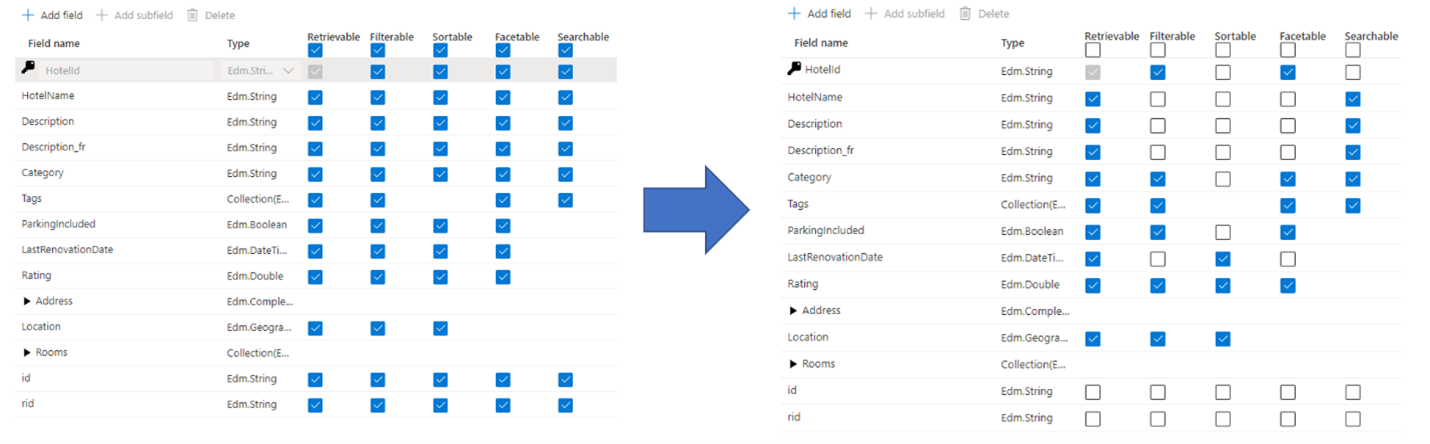
Obsługa filtrów, faset i sortowania może czterokrotnie zwiększyć wymagania dotyczące pamięci masowej. Jeśli dodasz sugestory, wymagania dotyczące magazynu będą jeszcze bardziej większe. Aby zapoznać się z ilustracją dotyczącą wpływu atrybutów na przechowywanie, zajrzyj do Atrybuty i rozmiar indeksu.
Podsumowując, konsekwencje nadmiernego przypisania obejmują:
Obniżenie wydajności indeksowania ze względu na dodatkową pracę wymaganą do przetworzenia zawartości w polu, a następnie zapisanie jej w indeksie odwróconym wyszukiwania (ustaw atrybut "z możliwością wyszukiwania" tylko na polach zawierających zawartość z możliwością wyszukiwania).
Tworzy większą powierzchnię, którą każde zapytanie musi obejmować. Wszystkie pola oznaczone jako możliwe do wyszukiwania są skanowane w wyszukiwaniu pełnotekstowym.
Zwiększa koszty operacyjne z powodu dodatkowego magazynu. Filtrowanie i sortowanie wymaga dodatkowego miejsca na przechowywanie oryginalnych (nieanalizowanych) ciągów. Unikaj ustawiania filtrowalności lub sortowalności na polach, które tego nie wymagają.
W wielu przypadkach nadmierne przypisywanie ogranicza możliwości pola. Jeśli na przykład pole można ująć w kategorie, filtrować i wyszukiwać, można przechowywać tylko 16 KB tekstu w polu, podczas gdy pole do wyszukiwania może przechowywać do 16 MB tekstu.
Uwaga / Notatka
Należy unikać tylko niepotrzebnego przypisywania. Filtry i aspekty są często niezbędne dla doświadczenia wyszukiwania, a w przypadkach, w których są używane filtry, często konieczne jest sortowanie, aby można było uporządkować wyniki (filtry same w sobie zwracają wyniki w nieuporządkowanym zestawie).
Porada: Rozważ alternatywy dla typów złożonych
Złożone typy danych są przydatne, gdy dane mają skomplikowaną zagnieżdżoną strukturę, taką jak elementy nadrzędno-podrzędne znalezione w dokumentach JSON. Wadą typów złożonych jest dodatkowe wymagania dotyczące magazynu i dodatkowe zasoby wymagane do indeksowania zawartości w porównaniu z nieskomplekcyjnymi typami danych.
W niektórych przypadkach można uniknąć tych kompromisów, mapując złożoną strukturę danych na prostszy typ pola, taki jak Kolekcja. Alternatywnie możesz zdecydować się na spłaszczenie hierarchii pól do indywidualnych pól na poziomie głównym.

Projekt zapytania
Kompozycja i złożoność zapytań są jednym z najważniejszych czynników wydajności, a optymalizacja zapytań może znacząco poprawić wydajność. Podczas projektowania zapytań zastanów się nad następującymi punktami:
Liczba pól z możliwością wyszukiwania. Każde dodatkowe pole z możliwością wyszukiwania powoduje więcej pracy dla usługi wyszukiwania. Pola przeszukiwane w czasie zapytania można ograniczyć przy użyciu parametru "searchFields". Najlepiej określić tylko faktycznie istotne pola, aby poprawić wydajność.
Ilość zwracanych danych. Pobieranie dużej ilości zawartości może sprawić, że zapytania będą wolniejsze. Podczas tworzenia zapytania zadbaj o zwrócenie tylko tych pól, które są potrzebne do renderowania strony wyników, a następnie po wybraniu zgodnej pozycji przez użytkownika pobierz pozostałe pola przy użyciu interfejsu API wyszukiwania.
Korzystanie z częściowych wyszukiwań terminów.Wyszukiwanie częściowe terminów, takie jak wyszukiwanie prefiksów, wyszukiwanie rozmyte i wyszukiwanie wyrażeń regularnych, są bardziej kosztowne obliczeniowo niż typowe wyszukiwania słów kluczowych, ponieważ wymagają pełnego skanowania indeksu w celu wygenerowania wyników.
Liczba aspektów. Dodawanie aspektów do zapytań wymaga wykonania agregacji dla każdego zapytania. Żądanie wyższej liczby („count”) dla aspektu również wymaga wykonania dodatkowej pracy przez usługę. Ogólnie rzecz biorąc, dodaj tylko aspekty, które planujesz renderować w aplikacji, i unikaj żądania wysokiej liczby dla aspektów, chyba że jest to konieczne.
Wysokie wartości pomijania. Ustawienie parametru
$skipna wysoką wartość (na przykład w tysiącach) zwiększa opóźnienie wyszukiwania, ponieważ aparat pobiera i klasyfikuje większą liczbę dokumentów dla każdego żądania. Ze względu na wydajność najlepiej unikać wysokich wartości$skipi używać w celu pobrania dużej liczby dokumentów innych technik, takich jak filtrowanie.Ogranicz pola o wysokiej kardynalności. Pole o wysokiej kardynalności odnosi się do pola aspektowego lub filtrowalnego, które ma znaczną liczbę unikatowych wartości, a w rezultacie zużywa znaczne zasoby podczas przetwarzania wyników. Na przykład ustawienie pola Identyfikator produktu lub Opis jako filtrowalne i przeszukiwane będzie uznawane za wysoką liczbę kardynalną, ponieważ większość wartości w każdym dokumencie jest unikatowa.
Porada: Zamiast tego użyj funkcji wyszukiwania przeciążających kryteria filtrowania
Ponieważ zapytanie używa coraz bardziej złożonych kryteriów filtrowania, wydajność zapytania wyszukiwania będzie spadać. Rozważmy następujący przykład, który pokazuje użycie filtrów do przycinania wyników na podstawie tożsamości użytkownika:
$filter= userid eq 123 or userid eq 234 or userid eq 345 or userid eq 456 or userid eq 567
W tym przypadku wyrażenia filtru są używane do sprawdzania, czy jedno pole w każdym dokumencie jest równe jednej z wielu możliwych wartości tożsamości użytkownika. Najprawdopodobniej znajdziesz ten wzorzec w aplikacjach, które implementują przycinanie dostępu (sprawdzanie pola zawierającego co najmniej jeden identyfikator główny względem listy identyfikatorów głównych reprezentujących użytkownika wystawiającego zapytanie).
Bardziej wydajnym sposobem wykonywania filtrów zawierających dużą liczbę wartości jest użycie search.in funkcji, jak pokazano w tym przykładzie:
search.in(userid, '123,234,345,456,567', ',')
Wskazówka: Dodaj partycje dla wolno działających zapytań indywidualnych
Gdy wydajność zapytań spowalnia ogólnie, dodanie większej liczby replik często rozwiązuje ten problem. Ale co zrobić, jeśli problem jest pojedynczym zapytaniem, które trwa zbyt długo? W tym scenariuszu dodanie replik nie pomoże, ale więcej partycji może. Partycja dzieli dane między dodatkowe zasoby obliczeniowe. Dwie partycje dzielą dane na pół, a trzecia partycja dzieli je na trzecie i tak dalej.
Jednym z pozytywnych skutków ubocznych dodawania partycji jest to, że wolniejsze zapytania czasami działają szybciej z powodu przetwarzania równoległego. Zauważyliśmy równoległość zapytań o niską selektywność, takich jak zapytania pasujące do wielu dokumentów lub fakty zapewniające liczy dokumentów w dużej liczbie dokumentów. Ponieważ istotne obliczenia są wymagane do oceny trafności dokumentów lub do zliczenia liczby dokumentów, dodanie dodatkowych partycji ułatwia szybsze wykonywanie zapytań.
Aby dodać partycje, użyj witryny Azure Portal, programu PowerShell, interfejsu wiersza polecenia platformy Azure lub zestawu SDK zarządzania.
Pojemność usługi
Usługa jest przeciążona, gdy zapytania trwają zbyt długo lub gdy usługa zaczyna upuszczać żądania. W takim przypadku możesz rozwiązać problem, uaktualniając usługę lub dodając pojemność.
Poziom usługi wyszukiwania oraz liczba replik/partycji mają również duży wpływ na wydajność. Każda stopniowo wyższa warstwa zapewnia szybsze procesory CPU i większą ilość pamięci, z których oba mają pozytywny wpływ na wydajność.
Porada: Tworzenie nowej usługi wyszukiwania o wysokiej pojemności
Usługi w warstwie Podstawowa i Standardowa utworzone w obsługiwanych regionach po 3 kwietnia 2024 r. mają więcej miejsca na partycję niż starsze usługi. Jeśli masz starszą usługę, sprawdź, czy możesz uaktualnić usługę , aby korzystać z większej pojemności przy użyciu tej samej stawki rozliczeniowej. Jeśli uaktualnienie nie jest dostępne, zapoznaj się z limitami warstwy usługi, aby sprawdzić, czy ta sama warstwa w nowszej usłudze zapewnia niezbędną przestrzeń magazynową.
Porada: Przełącz na plan Standardowy S2
Standardowy poziom wyszukiwania S1 jest często pierwszym wyborem klientów. Typowym wzorcem dla usług S1 jest to, że indeksy rosną wraz z upływem czasu, co wymaga większej liczby partycji. Więcej partycji prowadzi do wolniejszych czasów odpowiedzi, więc więcej replik jest dodawanych do obsługi obciążenia zapytania. Jak można sobie wyobrazić, koszt uruchamiania usługi S1 teraz przechodzi do poziomów poza początkową konfiguracją.
W tym momencie ważne jest, aby zadać pytanie, czy korzystne byłoby przejście do wyższej warstwy cenowej, w przeciwieństwie do stopniowego zwiększania liczby partycji lub replik bieżącej usługi.
Weźmy pod uwagę następującą topologię jako przykład serwisu, który przyjął zwiększający się poziom wydajności.
- Warstwa Standardowa S1
- Rozmiar indeksu: 190 GB
- Liczba partycji: 8 (na S1 rozmiar partycji wynosi 25 GB na partycję)
- Liczba replik: 2
- Całkowita liczba jednostek wyszukiwania: 16 (8 partycji x 2 repliki)
- Hipotetyczna cena detaliczna: ~$4,000 USD / miesiąc (załóżmy, że 250 USD x 16 jednostek wyszukiwania)
Załóżmy, że administrator usługi nadal widzi większe opóźnienia i rozważa dodanie kolejnej repliki. Spowoduje to zmianę liczby replik z 2 na 3, a w rezultacie zmień liczbę jednostek wyszukiwania na 24 i wynikową cenę w wysokości 6000 USD/miesiąc.
Jeśli jednak administrator zdecydował się przejść do warstwy Standardowa S2, topologia będzie wyglądać następująco:
- Poziom Standardowy S2
- Rozmiar indeksu: 190 GB
- Liczba partycji: 2 (na S2 rozmiar partycji wynosi 100 GB na partycję)
- Liczba replik: 2
- Całkowita liczba jednostek wyszukiwania: 4 (2 partycje x 2 repliki)
- Hipotetyczna cena detaliczna: ~$4,000 USD / miesiąc (1000 USD x 4 jednostki wyszukiwania)
Jak pokazano w tym hipotetycznym scenariuszu, konfiguracje można mieć w niższych warstwach, które powodują podobne koszty, jak w przypadku wybrania wyższej warstwy w pierwszej kolejności. Jednak wyższe warstwy są wyposażone w magazyn w warstwie Premium, co sprawia, że indeksowanie jest szybsze. Wyższe warstwy mają również znacznie więcej mocy obliczeniowej, a także dodatkową pamięć. W przypadku tych samych kosztów można mieć bardziej zaawansowaną infrastrukturę, która wspiera ten sam indeks.
Ważną zaletą dodania pamięci jest to, że więcej indeksu można buforować, co powoduje mniejsze opóźnienie wyszukiwania i większą liczbę zapytań na sekundę. Dzięki tej dodatkowej mocy administrator może nawet nie potrzebować zwiększenia liczby replik i może potencjalnie płacić mniej niż pozostając w usłudze S1.
Porada: Rozważ alternatywy dla zapytań wyrażeń regularnych
Zapytania wyrażeń regularnych lub wyrażenia regularnego mogą być szczególnie kosztowne. Chociaż mogą one być bardzo przydatne w przypadku wyszukiwania zaawansowanego, wykonywanie może wymagać dużej mocy obliczeniowej, zwłaszcza jeśli wyrażenie regularne jest skomplikowane lub jeśli przeszukujesz dużą ilość danych. Wszystkie te czynniki przyczyniają się do dużego opóźnienia wyszukiwania. Jako ograniczenie ryzyka spróbuj uprościć wyrażenie regularne lub podzielić złożone zapytanie w mniejsze, bardziej zarządzane zapytania.
Dalsze kroki
Przejrzyj inne artykuły związane z wydajnością usługi: