Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano narzędzia, zachowania i podejścia do analizowania wydajności zapytań i indeksowania w usłudze Azure AI Search.
Ten artykuł dotyczy tylko klasycznych scenariuszy wyszukiwania pełnotekstowego.
Opracowywanie wartości bazowych
W każdej dużej implementacji przed wdrożeniem w środowisku produkcyjnym krytyczne jest przeprowadzenie testu porównawczego wydajności usługi wyszukiwania Azure AI. Należy przetestować oczekiwane obciążenie zapytania wyszukiwania, ale także oczekiwane obciążenia pozyskiwania danych (jeśli to możliwe, uruchamiać jednocześnie oba obciążenia). Posiadanie numerów testów porównawczych pomaga zweryfikować odpowiednią warstwę wyszukiwania, konfigurację usługi i oczekiwane opóźnienie zapytań.
Aby odizolować efekty architektury usługi rozproszonej, spróbuj przetestować konfiguracje usługi jednej repliki i jednej partycji.
Note
W przypadku warstw zoptymalizowanych pod kątem pamięci (L1 i L2) należy oczekiwać mniejszej przepływności zapytań i większego opóźnienia w porównaniu do warstw standardowych.
Korzystanie z rejestrowania zasobów
Najważniejszym narzędziem diagnostycznym do dyspozycji administratora jest rejestrowanie zasobów. Rejestrowanie zasobów to kolekcja danych operacyjnych i metryk dotyczących usługi wyszukiwania. Rejestrowanie zasobów jest włączone za pośrednictwem usługi Azure Monitor. Istnieją koszty związane z używaniem usługi Azure Monitor i przechowywaniem danych, ale jeśli włączysz je dla usługi, może to mieć kluczowe znaczenie w badaniu problemów z wydajnością.
Na poniższej ilustracji przedstawiono łańcuch zdarzeń w żądaniu zapytania i odpowiedzi. Opóźnienie może wystąpić w dowolnym z nich, niezależnie od tego, czy podczas transferu sieciowego, przetwarzania zawartości w warstwie usług aplikacji, czy w usłudze wyszukiwania. Kluczową zaletą rejestrowania zasobów jest to, że działania są rejestrowane z perspektywy usługi wyszukiwania, co oznacza, że dziennik może pomóc w ustaleniu, czy problem z wydajnością jest spowodowany problemami z zapytaniem lub indeksowaniem, lub innym punktem awarii.
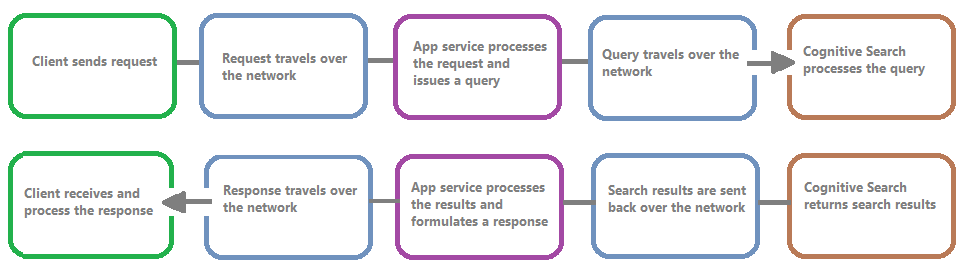
Rejestrowanie zasobów umożliwia przechowywanie zarejestrowanych informacji. Zalecamy używanie usługi Log Analytics , aby można było wykonywać zaawansowane zapytania Kusto względem danych, aby odpowiedzieć na wiele pytań dotyczących użycia i wydajności.
Na stronach portalu usługi wyszukiwania można włączyć rejestrowanie za pomocą ustawień diagnostycznych, a następnie wysyłać zapytania Kusto względem usługi Log Analytics, wybierając pozycję Dzienniki. Aby dowiedzieć się, jak wysyłać dzienniki zasobów do obszaru roboczego usługi Log Analytics, w którym można je analizować za pomocą zapytań dzienników, zobacz Zbieranie i analizowanie dzienników zasobów z zasobu platformy Azure.
Zachowania throttlingu
Ograniczanie występuje, gdy usługa wyszukiwania osiąga maksymalną pojemność. Ograniczanie przepustowości może wystąpić podczas wykonywania zapytań lub indeksowania. Po stronie klienta wywołanie interfejsu API powoduje odpowiedź HTTP 503, gdy została ograniczona. Podczas indeksowania istnieje również możliwość otrzymania odpowiedzi HTTP 207, co oznacza, że indeksowanie jednego lub więcej elementów nie powiodło się. Ten błąd jest wskaźnikiem, że usługa wyszukiwania zbliża się do pojemności.
Ogólnie rzecz biorąc, spróbuj określić stopień ograniczania i wszelkie wzorce. Jeśli na przykład jedno zapytanie z 500 000 zostanie ograniczone, może nie być sensu go badać. Jeśli jednak duży procent zapytań jest ograniczany przez pewien okres, byłby to większy problem. Patrząc na ograniczanie przepustowości w danym okresie, pomaga również zidentyfikować przedziały czasu, w których ograniczanie przepustowości może wystąpić bardziej prawdopodobne, i pomóc w podjęciu decyzji, jak najlepiej je uwzględnić.
Prostym rozwiązaniem większości problemów z ograniczaniem przepustowości jest przydzielanie większej liczby zasobów do usługi wyszukiwania (zazwyczaj replik dla ograniczania przepustowości opartej na zapytaniach lub partycji dla ograniczania opartego na indeksowaniu). Jednak zwiększenie liczby replik lub partycji zwiększa koszty, dlatego ważne jest, aby wiedzieć, dlaczego w ogóle dochodzi do ograniczania przepustowości. Badanie warunków powodujących ograniczanie przepustowości zostanie wyjaśnione w kilku następnych sekcjach.
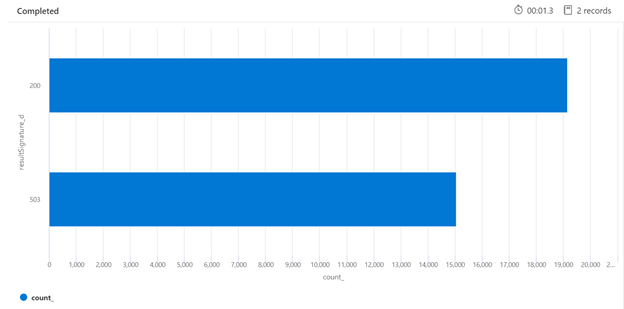
Poniżej znajduje się przykład zapytania Kusto, które może zidentyfikować podział HTTP odpowiedzi z usługi wyszukiwania znajdującej się pod obciążeniem. Na przestrzeni 7 dni renderowany wykres słupkowy pokazuje, że stosunkowo duży procent zapytań w wyszukiwarce był dławiony, w porównaniu do liczby pomyślnych odpowiedzi (200).
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
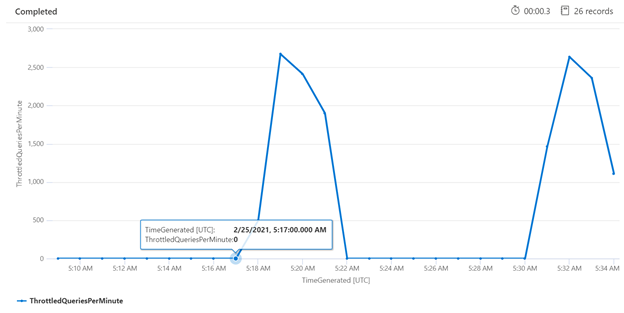
Badanie ograniczania przepustowości w określonym przedziale czasu może pomóc w ustaleniu, kiedy ograniczanie przepustowości może wystąpić częściej. W poniższym przykładzie wykres szeregów czasowych służy do pokazywania liczby zapytań z ograniczeniami, które wystąpiły w określonym przedziale czasu. W tym przypadku ograniczone zapytania są skorelowane z czasami, kiedy przeprowadzano testy porównawcze wydajności.
let ['_startTime']=datetime('2024-02-25T20:45:07Z');
let ['_endTime']=datetime('2024-03-03T20:45:07Z');
let intervalsize = 1m;
AzureDiagnostics
| where TimeGenerated > ago(7d)
| where resultSignature_d != 403 and resultSignature_d != 404 and OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete")
| summarize
ThrottledQueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete") and resultSignature_d == 503)/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
Mierzenie poszczególnych zapytań
W niektórych przypadkach przydatne może być przetestowanie poszczególnych zapytań w celu sprawdzenia, jak działają. Aby to zrobić, ważne jest, aby móc zobaczyć, jak długo trwa ukończenie procesu wyszukiwania, a także ile czasu zajmuje realizacja żądania od klienta i z powrotem do klienta. Dzienniki diagnostyczne mogą służyć do wyszukiwania poszczególnych operacji, ale może być łatwiej wykonać to wszystko z poziomu klienta REST.
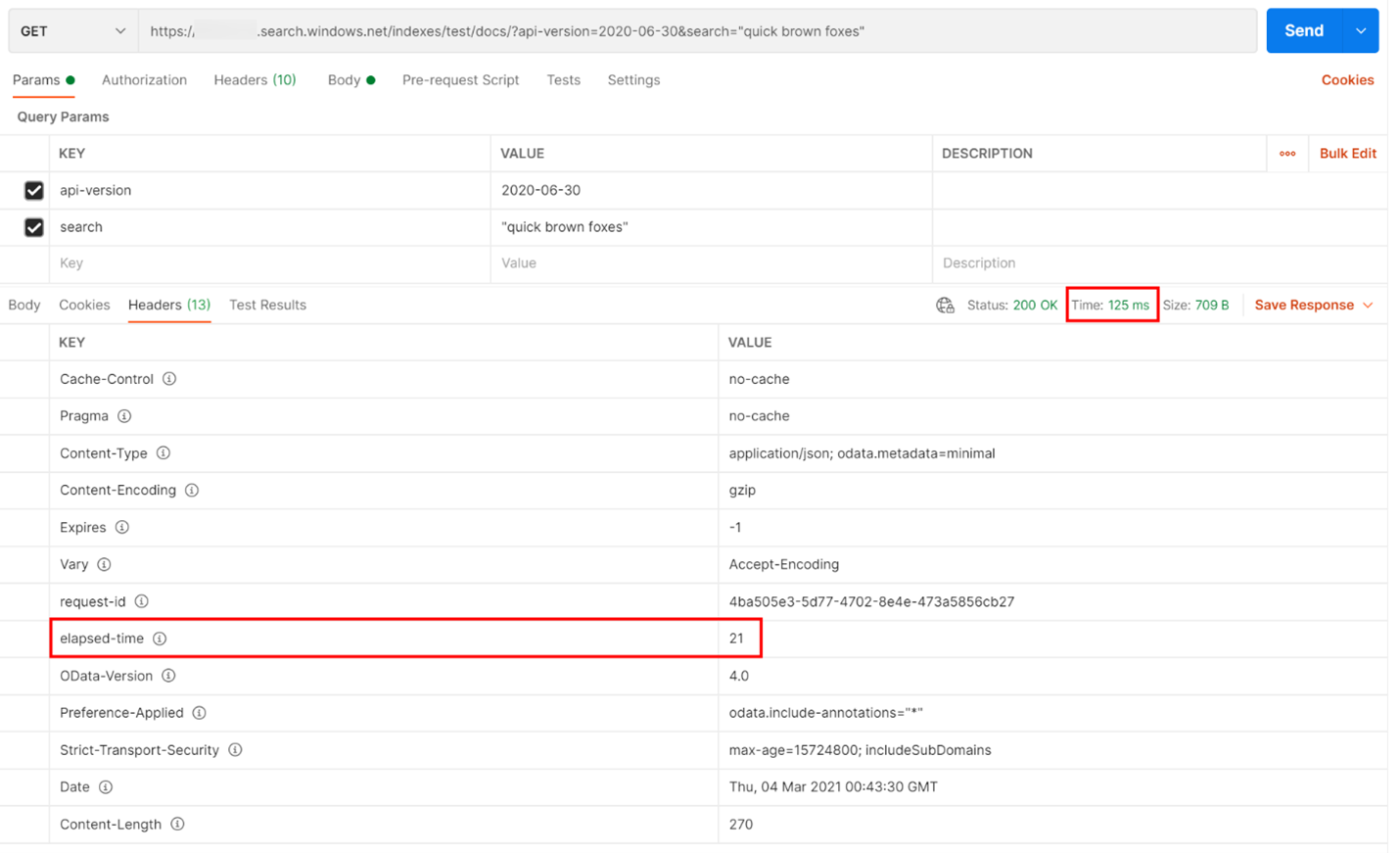
W poniższym przykładzie wykonano zapytanie wyszukiwania oparte na protokole REST. Usługa Azure AI Search zawiera w każdej odpowiedzi liczbę milisekund potrzebnych do wykonania zapytania, widoczną na karcie Nagłówki, w polu "elapsed-time". Obok sekcji Stan na górze odpowiedzi znajdziesz czas trwania podróży w obie strony, w tym przypadku 125 milisekund (ms). W sekcji wyników została wybrana karta "Nagłówki". Używając tych dwóch wartości, wyróżnionych czerwonym polem na poniższej ilustracji, zobaczymy, że usługa wyszukiwania potrzebowała 21 ms na ukończenie zapytania, a całkowity czas w obie strony dla klienta zajął 125 ms. Odejmując te dwie liczby, możemy określić, że przesłanie zapytania wyszukiwania do usługi i przekazanie wyników z powrotem do klienta zajęło dodatkowe 104 ms.
Ta technika pomaga odizolować opóźnienia sieci od innych czynników wpływających na wydajność zapytań.
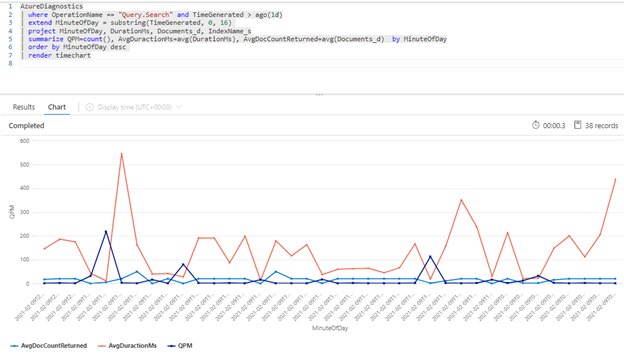
Współczynniki zapytań
Jedną z potencjalnych przyczyn ograniczania żądań przez usługę wyszukiwania jest duża liczba wykonywanych zapytań, gdzie ich wolumen mierzony jest jako liczba zapytań na sekundę (QPS) lub na minutę (QPM). W miarę odbierania większej liczby zapytań QPS usługa wyszukiwania zwykle będzie dłużej i dłużej odpowiadać na te zapytania, dopóki nie będzie mogła już nadążyć, ponieważ będzie wysyłać z powrotem odpowiedź HTTP o ograniczeniach przepustowości 503.
Następujące zapytanie Kusto pokazuje wolumin zapytania mierzony w QPM wraz ze średnim czasem trwania zapytania w milisekundach (AvgDurationMS) i średnią liczbę dokumentów (AvgDocCountReturned) zwróconych w każdym z nich.
AzureDiagnostics
| where OperationName == "Query.Search" and TimeGenerated > ago(1d)
| extend MinuteOfDay = substring(TimeGenerated, 0, 16)
| project MinuteOfDay, DurationMs, Documents_d, IndexName_s
| summarize QPM=count(), AvgDuractionMs=avg(DurationMs), AvgDocCountReturned=avg(Documents_d) by MinuteOfDay
| order by MinuteOfDay desc
| render timechart
Tip
Aby wyświetlić dane za tym wykresem, usuń wiersz | render timechart , a następnie uruchom ponownie zapytanie.
Wpływ indeksowania zapytań
Ważnym czynnikiem, który należy wziąć pod uwagę przy rozważaniu wydajności, jest to, że indeksowanie używa tych samych zasobów co zapytania wyszukiwania. Jeśli indeksujesz dużą ilość zawartości, możesz spodziewać się wzrostu opóźnienia, gdy usługa próbuje obsłużyć oba obciążenia.
Jeśli zapytania spowalniają, sprawdź czas działania indeksowania, aby sprawdzić, czy zbiegają się one z obniżeniem wydajności zapytań. Na przykład indeksator uruchamia zadanie dzienne lub godzinowe, które jest skorelowane ze zmniejszoną wydajnością zapytań wyszukiwania.
Ta sekcja zawiera zestaw zapytań, które mogą ułatwić wizualizowanie współczynników wyszukiwania i indeksowania. W tych przykładach zakres czasu jest ustawiany w zapytaniu. Pamiętaj, aby wskazać opcję Ustaw w zapytaniu podczas uruchamiania zapytań w witrynie Azure Portal.
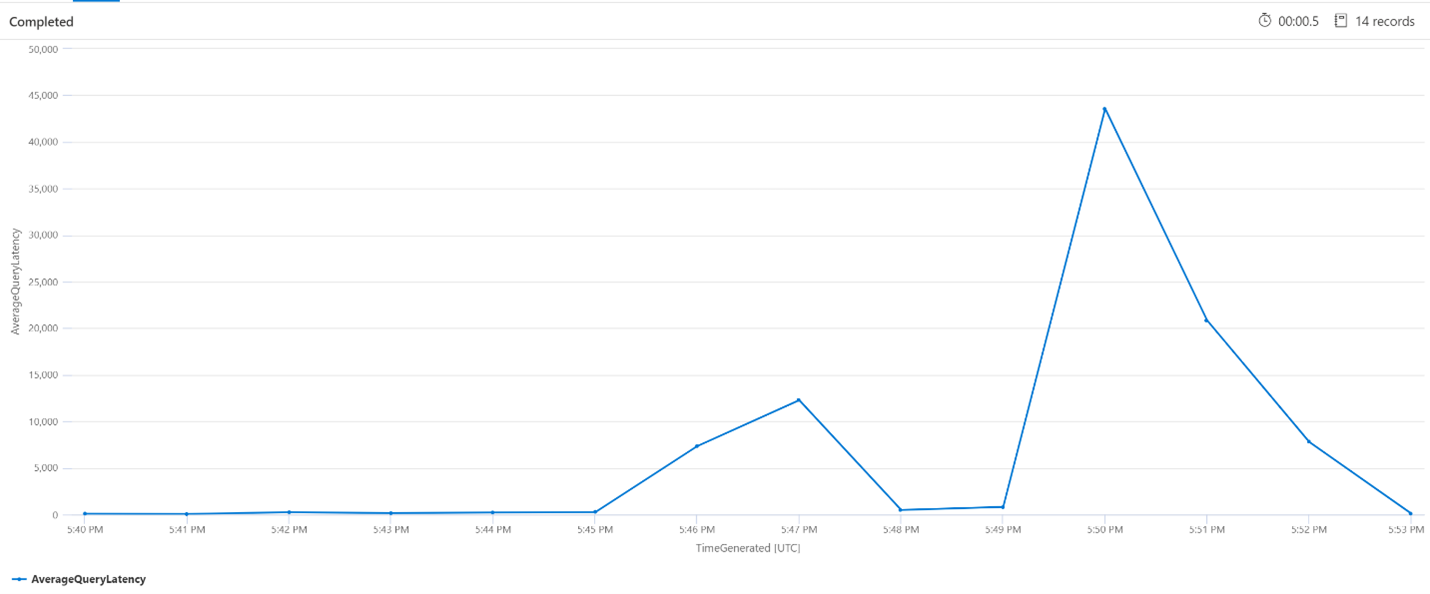
Średnie opóźnienie zapytań
W poniższym zapytaniu rozmiar interwału wynoszący 1 minutę służy do pokazywania średniego opóźnienia zapytań wyszukiwania. Na wykresie widać, że średnie opóźnienie było niskie do 17:45 i trwało do 17:53.
let intervalsize = 1m;
let _startTime = datetime('2024-02-23 17:40');
let _endTime = datetime('2024-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime']..['_endTime']) // Time range filtering
| summarize AverageQueryLatency = avgif(DurationMs, OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))
by bin(TimeGenerated, intervalsize)
| render timechart
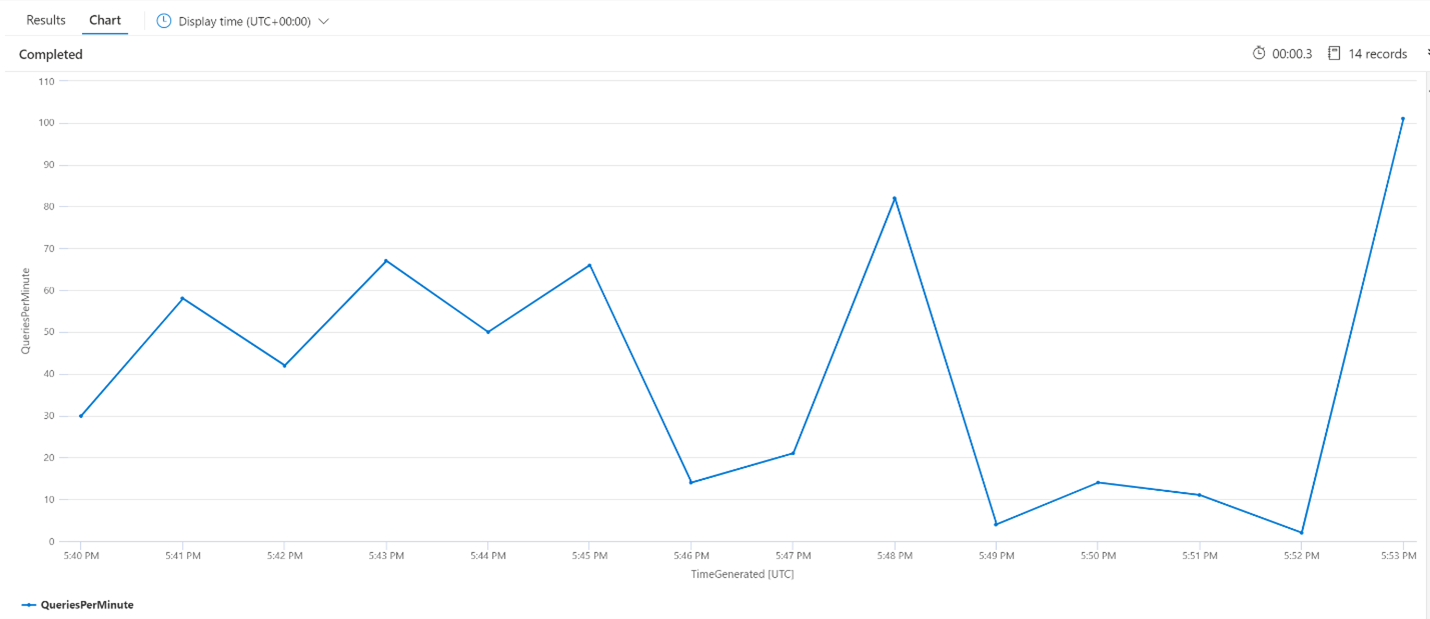
Średnie zapytania na minutę (QPM)
Poniższe zapytanie analizuje średnią liczbę zapytań na minutę, aby upewnić się, że nie nastąpił skok liczby żądań wyszukiwania, które mogły mieć wpływ na opóźnienie. Na wykresie widać, że istnieje pewna wariancja, ale nic nie wskazuje na wzrost liczby żądań.
let intervalsize = 1m;
let _startTime = datetime('2024-02-23 17:40');
let _endTime = datetime('2024-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize QueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
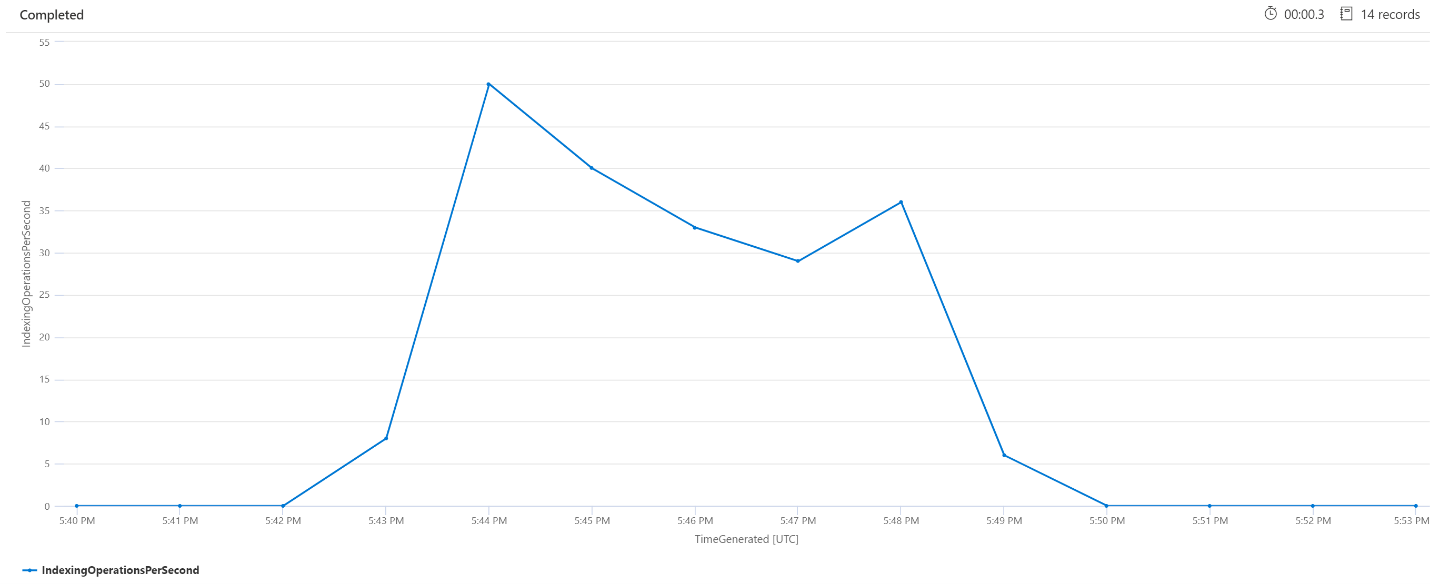
Operacje indeksowania na minutę (OPM)
W tym miejscu przyjrzymy się liczbie operacji indeksowania na minutę. Na wykresie widać, że duża ilość danych została zaindeksowana rozpoczęta o godzinie 17:42 i zakończyła się o godzinie 17:50. Indeksowanie rozpoczęło się 3 minuty przed tym, jak zapytania wyszukiwania zaczęły mieć opóźnienia, i zakończyło się 3 minuty zanim zapytania wyszukiwania przestały być opóźnione.
Z tego wglądu widać, że usługa wyszukiwania potrzebowała około 3 minut, aby stać się na tyle obciążoną, by indeksowanie zaczęło wpływać na opóźnienie zapytań. Widzimy również, że po zakończeniu indeksowania wykonanie całej pracy z nowo indeksowanej zawartości zajęło kolejne 3 minuty, a opóźnienie zapytań zostało rozwiązane.
let intervalsize = 1m;
let _startTime = datetime('2024-02-23 17:40');
let _endTime = datetime('2024-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize IndexingOperationsPerSecond=bin(countif(OperationName == "Indexing.Index")/ (intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
Przetwarzanie usługi w tle
Często występuje sporadyczne wzrosty opóźnienia zapytań lub indeksowania. Skoki mogą wystąpić w odpowiedzi na indeksowanie lub wysokie współczynniki zapytań, ale mogą również wystąpić podczas operacji scalania. Indeksy wyszukiwania są przechowywane w kawałkach — lub fragmentach. Okresowo system scala mniejsze fragmenty z dużymi fragmentami, co może pomóc w optymalizacji wydajności usługi. Ten proces scalania usuwa również dokumenty, które zostały wcześniej oznaczone do usunięcia z indeksu, co powoduje odzyskanie miejsca do magazynowania.
Scalanie fragmentów jest szybkie, ale także intensywnie korzystające z zasobów, a tym samym może obniżyć wydajność usługi. Jeśli zauważysz krótkotrwałe skoki opóźnień zapytań, a te skoki zbiegają się z ostatnimi zmianami w indeksowanej zawartości, możesz założyć, że opóźnienie jest spowodowane operacjami scalania segmentów.
Dalsze kroki
Zapoznaj się z tymi artykułami dotyczącymi analizowania wydajności usługi.