Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Usługa Azure AI Search może indeksować dokumenty i tablice JSON w usłudze Azure Blob Storage przy użyciu indeksatora, który wie, jak odczytywać dane częściowo ustrukturyzowane. Dane częściowo ustrukturyzowane zawierają tagi lub oznaczenia oddzielające zawartość w danych. Dzieli różnicę między danymi bez struktury, które muszą być w pełni indeksowane i formalnie ustrukturyzowane dane zgodne z modelem danych, takie jak schemat relacyjnej bazy danych, który można indeksować na podstawie poszczególnych pól.
W tym samouczku pokazano, jak indeksować zagnieżdżone tablice JSON przy użyciu klienta REST i interfejsów API REST wyszukiwania w celu:
- Skonfiguruj przykładowe dane i ustaw
azureblobjako źródło danych - Tworzenie indeksu usługi Azure AI Search zawierającego zawartość z możliwością wyszukiwania
- Tworzenie i uruchamianie indeksatora w celu odczytania kontenera i wyodrębnienia zawartości z możliwością wyszukiwania
- Przeszukać utworzony indeks
Wymagania wstępne
Konto platformy Azure z aktywną subskrypcją. Utwórz konto bezpłatnie.
Azure AI Search. Utwórz usługę lub znajdź istniejącą usługę w bieżącej subskrypcji.
Uwaga
W tym samouczku możesz użyć bezpłatnej usługi wyszukiwania. Warstwa Bezpłatna ogranicza do trzech indeksów, trzech indeksatorów i trzech źródeł danych. W ramach tego samouczka tworzony jest jeden element każdego z tych typów. Przed rozpoczęciem upewnij się, że masz wystarczającą ilość miejsca w swojej usłudze, aby przyjąć nowe zasoby.
Pobieranie plików
Pobierz plik zip z przykładowego repozytorium danych i wyodrębnij zawartość. Dowiedz się, jak to zrobić.
Przykładowe dane to pojedynczy plik JSON zawierający tablicę JSON i 1521 zagnieżdżonych elementów JSON. Dane pochodzą z Historii Występów Filharmonii Nowojorskiej na Kaggle. Wybraliśmy jeden plik JSON, aby pozostać w granicach limitu przechowywania w planie bezpłatnym.
Oto pierwszy zagnieżdżony kod JSON w pliku. Reszta pliku obejmuje 1520 występów koncertowych.
{
"id": "7358870b-65c8-43d5-ab56-514bde52db88-0.1",
"programID": "11640",
"orchestra": "New York Philharmonic",
"season": "2011-12",
"concerts": [
{
"eventType": "Non-Subscription",
"Location": "Manhattan, NY",
"Venue": "Avery Fisher Hall",
"Date": "2011-09-07T04:00:00Z",
"Time": "7:30PM"
},
{
"eventType": "Non-Subscription",
"Location": "Manhattan, NY",
"Venue": "Avery Fisher Hall",
"Date": "2011-09-08T04:00:00Z",
"Time": "7:30PM"
}
],
"works": [
{
"ID": "5733*",
"composerName": "Bernstein, Leonard",
"workTitle": "WEST SIDE STORY (WITH FILM)",
"conductorName": "Newman, David",
"soloists": []
},
{
"ID": "0*",
"interval": "Intermission",
"soloists": []
}
]
}
Przekazywanie przykładowych danych do usługi Azure Storage
W usłudze Azure Storage utwórz nowy kontener o nazwie ny-philharmonic-free.
Przekaż przykładowe pliki danych.
Uzyskaj parametry połączenia magazynu, aby można było sformułować połączenie w usłudze Azure AI Search.
Po lewej stronie wybierz pozycję Klucze dostępu.
Skopiuj parametry połączenia dla jednego lub drugiego klucza. Łańcuch połączenia jest podobny do poniższego przykładu:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
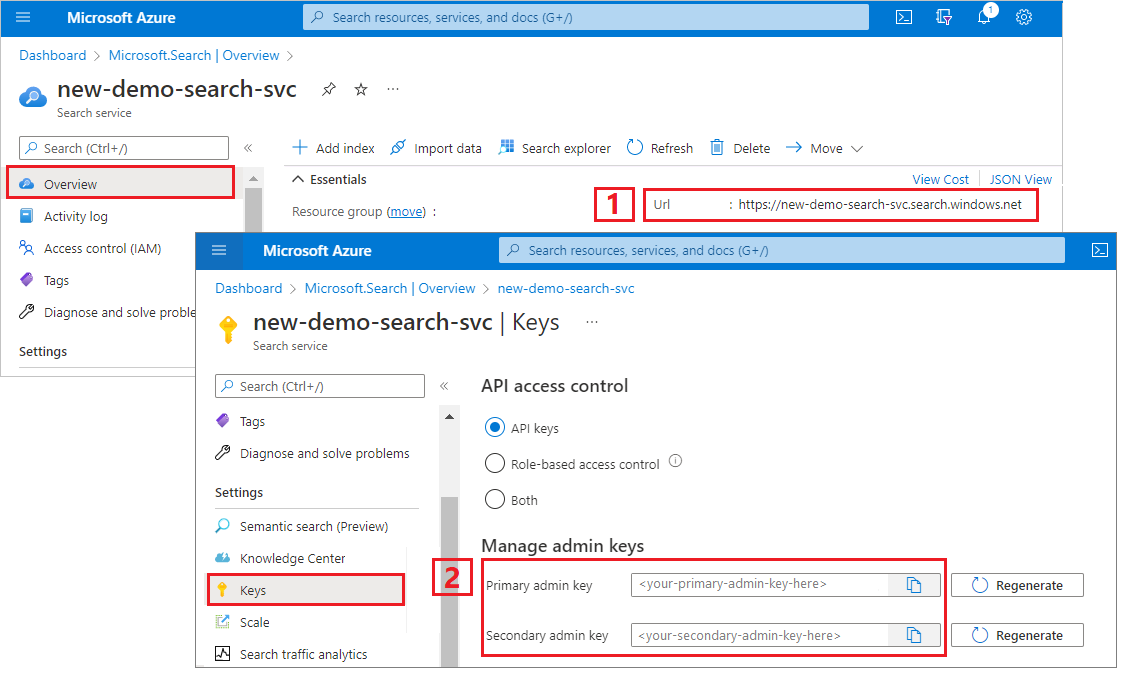
Kopiowanie adresu URL usługi wyszukiwania i klucza interfejsu API
Na potrzeby tego samouczka połączenia z usługą Azure AI Search wymagają punktu końcowego i klucza interfejsu API. Te wartości można uzyskać w witrynie Azure Portal. Aby zapoznać się z alternatywnymi metodami połączeń, zobacz Tożsamości zarządzane.
Zaloguj się do witryny Azure Portal, przejdź do strony Przegląd usługi wyszukiwania i skopiuj adres URL. Przykładowy punkt końcowy może wyglądać podobnie jak
https://mydemo.search.windows.net.W obszarze Klucze ustawień>skopiuj klucz administratora. Klucze administracyjne służą do dodawania, modyfikowania i usuwania obiektów. Istnieją dwa zamienne klucze administratora. Skopiuj jedną z nich.
Konfigurowanie pliku REST
Uruchom program Visual Studio Code i utwórz nowy plik.
Podaj wartości zmiennych używanych w żądaniu.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnection = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HEREZapisz plik z rozszerzeniem
.restlub.http.
Aby uzyskać pomoc dotyczącą klienta REST, zobacz Szybki start: wyszukiwanie pełnotekstowe przy użyciu interfejsu REST.
Utwórz źródło danych
Utwórz źródło danych (REST) tworzy połączenie ze źródłem danych, które określa, jakie dane mają być indeksowane.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "ny-philharmonic-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnection}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Wyślij żądanie. Odpowiedź powinna wyglądać następująco:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DC43A5FDB8448F"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('ny-philharmonic-ds')?api-version=2024-07-01
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 7ca53f73-1054-4959-bc1f-616148a9c74a
elapsed-time: 111
Date: Wed, 13 Mar 2024 21:38:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DC43A5FDB8448F\"",
"name": "ny-philharmonic-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "ny-philharmonic-free",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null
}
Tworzenie indeksu
Tworzenie indeksu (REST) powoduje utworzenie indeksu wyszukiwania w usłudze wyszukiwania. Indeks określa wszystkie parametry i ich atrybuty.
W przypadku zagnieżdżonego kodu JSON pola indeksu muszą być identyczne z polami źródłowymi. Obecnie usługa Azure AI Search nie obsługuje mapowań pól na zagnieżdżone dane JSON, więc nazwy pól i typy danych muszą być całkowicie zgodne. Poniższy indeks jest zgodny z elementami JSON w nieprzetworzonej zawartości.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "ny-philharmonic-index",
"fields": [
{"name": "programID", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "orchestra", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "season", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{ "name": "concerts", "type": "Collection(Edm.ComplexType)",
"fields": [
{ "name": "eventType", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": false, "sortable": false, "facetable": false},
{ "name": "Location", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Venue", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Date", "type": "Edm.String", "searchable": false, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Time", "type": "Edm.String", "searchable": false, "retrievable": true, "filterable": true, "sortable": false, "facetable": true }
]
},
{ "name": "works", "type": "Collection(Edm.ComplexType)",
"fields": [
{ "name": "ID", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": false, "sortable": false, "facetable": false},
{ "name": "composerName", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "workTitle", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "conductorName", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "soloists", "type": "Collection(Edm.String)", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true }
]
}
]
}
Najważniejsze kwestie:
Nie można używać mapowań pól do uzgadniania różnic w nazwach pól lub typach danych. Ten schemat indeksu jest przeznaczony do dublowania nieprzetworzonej zawartości.
Zagnieżdżony kod JSON jest modelowany jako
Collection(Edm.ComplextType). W nieprzetworzonej zawartości istnieje wiele koncertów dla każdego sezonu, a wiele utworów dla każdego koncertu. Aby uwzględnić tę strukturę, użyj kolekcji dla typów złożonych.W nieprzetworzonej zawartości
DateiTimesą ciągami, więc odpowiednie typy danych w indeksie są również ciągami.
Tworzenie i uruchamianie indeksatora
Utwórz indeksator tworzy indeksator w usłudze wyszukiwania. Indeksator łączy się ze źródłem danych, ładuje i indeksuje dane, a opcjonalnie udostępnia harmonogram automatyzowania odświeżania danych.
Konfiguracja indeksatora obejmuje jsonArray tryb analizowania oraz documentRoot.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "ny-philharmonic-indexer",
"dataSourceName" : "ny-philharmonic-ds",
"targetIndexName" : "ny-philharmonic-index",
"parameters" : {
"configuration" : {
"parsingMode" : "jsonArray", "documentRoot": "/programs"}
},
"fieldMappings" : [
]
}
Najważniejsze kwestie:
Plik nieprzetworzonej zawartości zawiera tablicę JSON (
"programs") z 1526 zagnieżdżonymi strukturami JSON. UstawparsingModenajsonArray, aby poinformować indeksator, że każdy obiekt blob zawiera tablicę JSON. Ponieważ zagnieżdżony kod JSON rozpoczyna się jeden poziom w dół, ustawdocumentRootna/programs.Indeksator działa przez kilka minut. Przed uruchomieniem zapytań poczekaj na zakończenie wykonywania indeksatora.
Uruchamianie zapytań
Możesz rozpocząć wyszukiwanie zaraz po załadowaniu pierwszego dokumentu.
### Query the index
POST {{baseUrl}}/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Wyślij żądanie. Jest to nieokreślone zapytanie wyszukiwania pełnotekstowego, które zwraca wszystkie pola oznaczone jako możliwe do pobrania w indeksie wraz z liczbą dokumentów. Odpowiedź powinna wyglądać następująco:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a95c4021-f7b4-450b-ba55-596e59ecb6ec
elapsed-time: 106
Date: Wed, 13 Mar 2024 22:09:59 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('ny-philharmonic-index')/$metadata#docs(*)",
"@odata.count": 1521,
"@search.nextPageParameters": {
"search": "*",
"count": true,
"skip": 50
},
"value": [
],
"@odata.nextLink": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01"
}
Dodaj parametr search do wyszukiwania w ciągu znaków, parametr select do ograniczenia wyników do mniejszej liczby pól, i filter aby dokładniej zawęzić wyszukiwanie.
### Query the index
POST {{baseUrl}}/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "puccini",
"count": true,
"select": "season, concerts/Date, works/composerName, works/workTitle",
"filter": "season gt '2015-16'"
}
W odpowiedzi są zwracane dwa dokumenty.
W przypadku filtrów można również używać operatorów logicznych (i, lub, nie) i operatorów porównania (eq, ne, gt, lt, ge, le). Porównania ciągów są rozróżniane pod względem wielkości liter. Aby uzyskać więcej informacji i przykładów, zobacz Tworzenie zapytania.
Uwaga
Parametr $filter działa tylko w przypadku pól, które zostały oznaczone jako filtrowalne podczas tworzenia indeksu.
Resetowanie i ponowne uruchamianie
Indeksatory można zresetować w celu wyczyszczenia historii wykonywania, co umożliwia pełne ponowne uruchamianie. Następujące żądania POST są przeznaczone do resetowania, a następnie ponownie uruchamiane.
### Reset the indexer
POST {{baseUrl}}/indexers/ny-philharmonic-indexer/reset?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/ny-philharmonic-indexer/run?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/ny-philharmonic-indexer/status?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
Czyszczenie zasobów
Gdy pracujesz we własnej subskrypcji, na końcu projektu warto usunąć zasoby, których już nie potrzebujesz. Pozostawione uruchomione zasoby mogą generować koszty. Zasoby możesz usuwać pojedynczo lub jako grupę zasobów, usuwając cały zestaw zasobów.
Za pomocą witryny Azure Portal można usuwać indeksy, indeksatory i źródła danych.
Następne kroki
Teraz, gdy znasz już podstawy indeksowania obiektów blob platformy Azure, przyjrzyj się bliżej konfiguracji indeksatora dla obiektów blob JSON w usłudze Azure Storage: