Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Z tego samouczka usługi Azure AI Search dowiesz się, jak indeksować i wykonywać zapytania dotyczące dużych danych załadowanych z klastra Spark. Skonfigurujesz notes Jupyter w taki sposób, aby:
- Ładowanie różnych formularzy (faktur) do ramki danych w sesji platformy Apache Spark
- Analizowanie formularzy w celu określenia ich funkcji
- Złóż wynikowe dane wyjściowe do struktury danych tabelarycznych
- Zapisywanie danych wyjściowych w indeksie wyszukiwania hostowanym w usłudze Azure AI Search
- Eksplorowanie i wykonywanie zapytań o utworzoną zawartość
Ten samouczek opiera się na bibliotece SynapseML typu open source, która obsługuje równoległe uczenie maszynowe w dużej skali na danych big data. W usłudze SynapseML indeksowanie wyszukiwania i uczenie maszynowe są udostępniane za pośrednictwem transformatorów wykonujących wyspecjalizowane zadania. Transformatory zapewniają szeroką gamę możliwości sztucznej inteligencji. W tym ćwiczeniu użyjesz interfejsów API azureSearchWriter do analizy i wzbogacania sztucznej inteligencji.
Chociaż usługa Azure AI Search posiada natywną funkcję wzbogacania za pomocą AI, ten samouczek pokazuje, jak uzyskać dostęp do zewnętrznych funkcji sztucznej inteligencji poza usługą Azure AI Search. Korzystając z usługi SynapseML zamiast indeksatorów lub umiejętności, nie podlegasz limitom danych ani innym ograniczeniom skojarzonym z tymi obiektami.
Napiwek
Obejrzyj krótki film z tego pokazu. Film wideo rozszerza ten samouczek o więcej kroków i wizualizacji.
Wymagania wstępne
Potrzebna jest biblioteka i kilka zasobów platformy synapseml Azure. Jeśli to możliwe, użyj tej samej subskrypcji i regionu dla zasobów platformy Azure i umieść wszystko w jednej grupie zasobów w celu późniejszego prostego czyszczenia. Poniższe linki dotyczą instalacji portalu. Przykładowe dane są importowane z witryny publicznej.
- Pakiet SynapseML 1
- Azure AI Search (dowolna warstwa) 2
-
Wielosługowe konto usług Azure AI (dowolna warstwa) z Rodzajem interfejsu API
AIServices3 - Usługa Azure Databricks (dowolna warstwa) ze środowiskiem uruchomieniowym Apache Spark 3.3.0 4
1 Ten link prowadzi do samouczka dotyczącego ładowania pakietu.
2 Możesz użyć warstwy Bezpłatna do indeksowania przykładowych danych, ale wybierz wyższą warstwę , jeśli woluminy danych są duże. W przypadku płatnych poziomów podaj klucz API wyszukiwania na etapie Konfigurowanie zależności.
3 W tym samouczku używane są Azure AI Document Intelligence i Azure AI Translator. W poniższych instrukcjach podaj klucz konta z wieloma usługami i region. Ten sam klucz działa dla obu usług.
Na potrzeby tego samouczka ważne jest, aby używać konta wielosługowego usług Azure AI z rodzajem interfejsu AIServicesAPI. Rodzaj interfejsu API można sprawdzić w portalu Azure w sekcji Omówienie strony konta wielosługowego usług Azure AI. Aby uzyskać więcej informacji na temat rodzaju interfejsu API, zobacz Dołączanie zasobu wielousługowego usług Azure AI w usłudze Azure AI Search.
4 W tym samouczku Azure Databricks udostępnia platformę obliczeniową Spark. Użyliśmy instrukcji portalu do skonfigurowania klastra i obszaru roboczego.
Uwaga
Powyższe zasoby platformy Azure obsługują funkcje zabezpieczeń na platformie Microsoft Identity. Dla uproszczenia w tym samouczku założono, że uwierzytelnianie oparte na kluczach jest używane przy użyciu punktów końcowych i kluczy skopiowanych ze stron witryny Azure Portal dla każdej usługi. Jeśli zaimplementujesz ten przepływ pracy w środowisku produkcyjnym lub udostępnisz rozwiązanie innym osobom, pamiętaj, aby zastąpić zakodowane klucze zintegrowanymi zabezpieczeniami lub zaszyfrowanymi kluczami.
Tworzenie klastra Spark i notesu
W tej sekcji utworzysz klaster, zainstalujesz synapseml bibliotekę i utworzysz notes, aby uruchomić kod.
W witrynie Azure Portal znajdź obszar roboczy usługi Azure Databricks i wybierz pozycję Uruchom obszar roboczy.
W menu po lewej stronie wybierz pozycję Obliczenia.
Wybierz pozycję Utwórz zasoby obliczeniowe.
Zaakceptuj konfigurację domyślną. Utworzenie klastra trwa kilka minut.
Sprawdź, czy klaster jest operacyjny i uruchomiony. Zielona kropka według nazwy klastra potwierdza jego stan.
Po utworzeniu klastra zainstaluj bibliotekę
synapseml:Wybierz Biblioteki z kart na górze strony klastra.
Wybierz pozycję Zainstaluj nową.
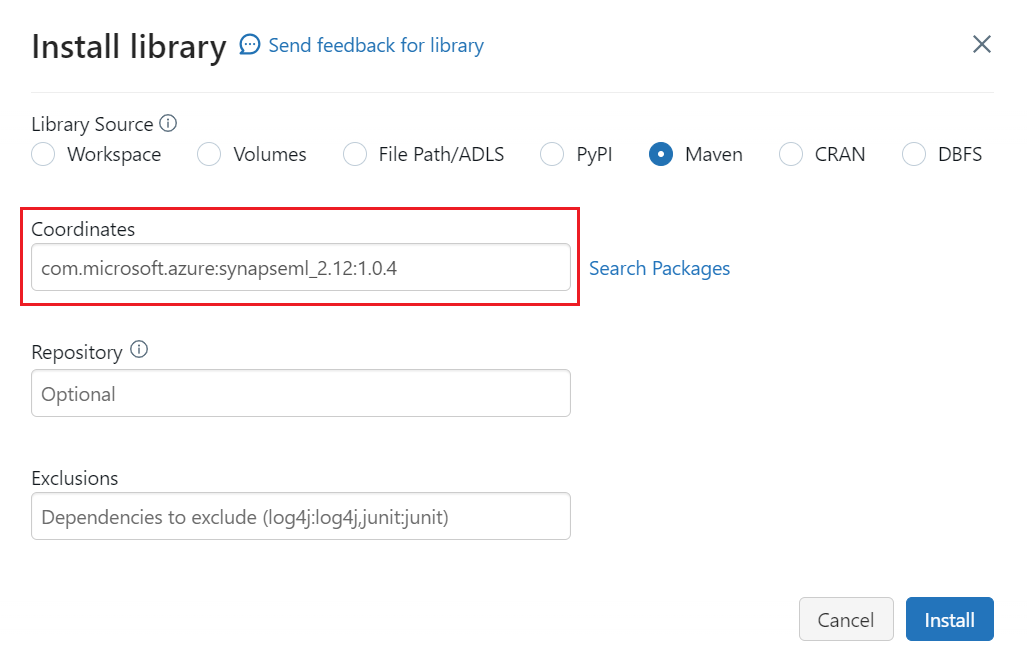
Wybierz pozycję Maven.
W obszarze Współrzędne wyszukaj ciąg
com.microsoft.azure:synapseml_2.12:1.0.9.Wybierz Zainstaluj.
W menu po lewej stronie wybierz Utwórz>Notatnik.
Nadaj notesowi nazwę, wybierz język Python jako język domyślny, a następnie wybierz klaster, który ma bibliotekę
synapseml.Utwórz siedem kolejnych komórek. W poniższych sekcjach wklejasz kod w tych komórkach.
Konfigurowanie zależności
Wklej następujący kod do pierwszej komórki notesu.
Zastąp symbole zastępcze punktami końcowymi i kluczami dostępu dla każdego zasobu. Podaj nazwę nowego indeksu wyszukiwania, który ma zostać utworzony. Nie są wymagane żadne inne modyfikacje, więc uruchom kod, gdy wszystko będzie gotowe.
Ten kod importuje wiele pakietów i konfiguruje dostęp do zasobów platformy Azure używanych w tym samouczku.
import os
from pyspark.sql.functions import udf, trim, split, explode, col, monotonically_increasing_id, lit
from pyspark.sql.types import StringType
from synapse.ml.core.spark import FluentAPI
cognitive_services_key = "placeholder-azure-ai-services-multi-service-key"
cognitive_services_region = "placeholder-azure-ai-services-region"
search_service = "placeholder-search-service-name"
search_key = "placeholder-search-service-admin-api-key"
search_index = "placeholder-for-new-search-index-name"
Ładowanie danych do platformy Spark
Wklej następujący kod do drugiej komórki. Nie są wymagane żadne modyfikacje, dlatego uruchom kod, gdy wszystko będzie gotowe.
Ten kod ładuje kilka plików zewnętrznych z konta usługi Azure Storage. Pliki to różne faktury odczytywane w ramce danych.
def blob_to_url(blob):
[prefix, postfix] = blob.split("@")
container = prefix.split("/")[-1]
split_postfix = postfix.split("/")
account = split_postfix[0]
filepath = "/".join(split_postfix[1:])
return "https://{}/{}/{}".format(account, container, filepath)
df2 = (spark.read.format("binaryFile")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/form_subset/*")
.select("path")
.limit(10)
.select(udf(blob_to_url, StringType())("path").alias("url"))
.cache())
display(df2)
Dodawanie inteligencji dokumentów
Wklej następujący kod do trzeciej komórki. Nie są wymagane żadne modyfikacje, dlatego uruchom kod, gdy wszystko będzie gotowe.
Ten kod ładuje transformator AnalyzeInvoices i przekazuje odwołanie do ramki danych zawierającej faktury. Wywołuje wstępnie zdefiniowany model faktur usługi Azure AI Document Intelligence w celu wyodrębnienia informacji z faktur.
from synapse.ml.services import AnalyzeInvoices
analyzed_df = (AnalyzeInvoices()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setImageUrlCol("url")
.setOutputCol("invoices")
.setErrorCol("errors")
.setConcurrency(5)
.transform(df2)
.cache())
display(analyzed_df)
Dane wyjściowe powinny wyglądać podobnie do poniższego zrzutu ekranu. Zwróć uwagę, że analiza formularzy jest pakowana w gęsto ustrukturyzowaną kolumnę, z którą trudno jest pracować. Kolejna transformacja rozwiązuje ten problem przez przekształcenie kolumny na wiersze i kolumny.
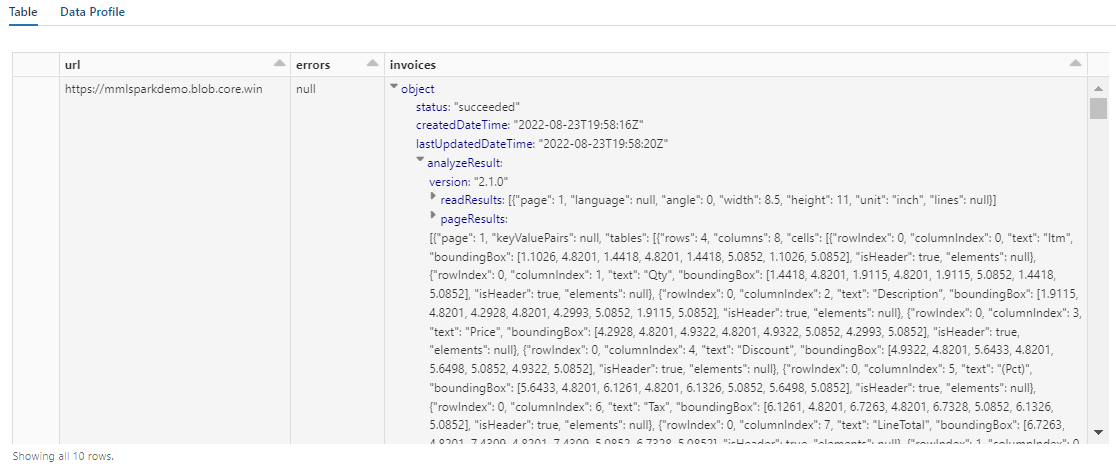
Zmiana struktury danych wyjściowych analizy dokumentów
Wklej następujący kod do czwartej komórki i uruchom go. Nie są wymagane żadne modyfikacje.
Ten kod ładuje FormOntologyLearner, transformator, który analizuje dane wyjściowe transformatorów analizy dokumentów i wnioskuje strukturę danych tabelarycznych. Dane wyjściowe funkcji AnalyzeInvoices są dynamiczne i różnią się w zależności od funkcji wykrytych w zawartości. Ponadto transformator konsoliduje dane wyjściowe w jedną kolumnę. Ponieważ dane wyjściowe są dynamiczne i skonsolidowane, trudno jest ich używać w przekształceniach podrzędnych, które wymagają większej struktury.
FormOntologyLearner rozszerza narzędzie przekształcania AnalyzeInvoices, wyszukując wzorce, których można użyć do utworzenia struktury danych tabelarycznych. Organizowanie danych wyjściowych w wielu kolumnach i wierszach sprawia, że zawartość jest dostępna do użycia w innych transformatorach, takich jak AzureSearchWriter.
from synapse.ml.cognitive import FormOntologyLearner
itemized_df = (FormOntologyLearner()
.setInputCol("invoices")
.setOutputCol("extracted")
.fit(analyzed_df)
.transform(analyzed_df)
.select("url", "extracted.*").select("*", explode(col("Items")).alias("Item"))
.drop("Items").select("Item.*", "*").drop("Item"))
display(itemized_df)
Zwróć uwagę, że ta transformacja przekształca zagnieżdżone pola w tabelę, co umożliwia wykonanie dwóch następnych przekształceń. Ten zrzut ekranu został skrócony dla zwięzłości. Jeśli śledzisz to we własnym notesie, masz 19 kolumn i 26 wierszy.
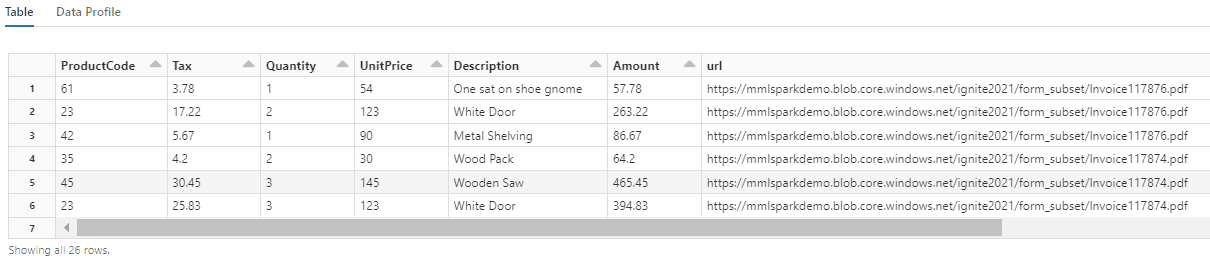
Dodawanie tłumaczeń
Wklej następujący kod do piątej komórki. Nie są wymagane żadne modyfikacje, dlatego uruchom kod, gdy wszystko będzie gotowe.
Ten kod ładuje moduł Translate, transformator, który wywołuje usługę Azure AI Translator w usługach Azure AI. Oryginalny tekst, który jest w języku angielskim w kolumnie "Opis", jest tłumaczony maszynowo na różne języki. Wszystkie dane wyjściowe są konsolidowane w tablicy "output.translations".
from synapse.ml.cognitive import Translate
translated_df = (Translate()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setTextCol("Description")
.setErrorCol("TranslationError")
.setOutputCol("output")
.setToLanguage(["zh-Hans", "fr", "ru", "cy"])
.setConcurrency(5)
.transform(itemized_df)
.withColumn("Translations", col("output.translations")[0])
.drop("output", "TranslationError")
.cache())
display(translated_df)
Napiwek
Aby sprawdzić przetłumaczone ciągi, przewiń do końca wierszy.
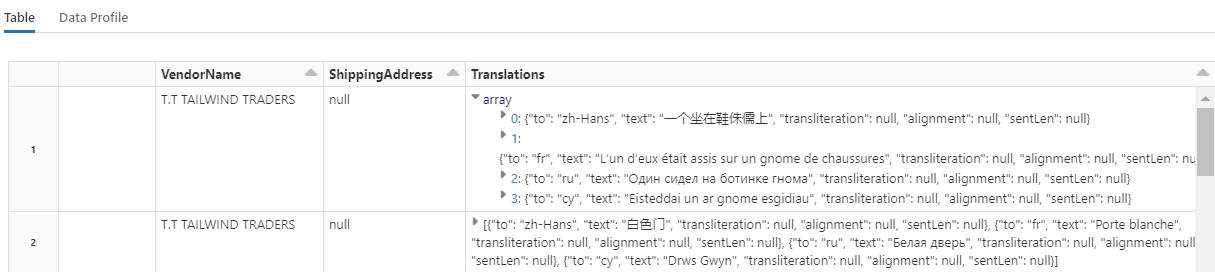
Dodawanie indeksu wyszukiwania za pomocą narzędzia AzureSearchWriter
Wklej następujący kod w szóstej komórce i uruchom go. Nie są wymagane żadne modyfikacje.
Ten kod ładuje AzureSearchWriter. Korzysta z tabelarycznego zestawu danych i wywnioskuje schemat indeksu wyszukiwania, który definiuje jedno pole dla każdej kolumny. Ponieważ struktura tłumaczeń jest tablicą, jest ona wyrażana w indeksie jako złożona kolekcja z polami podrzędnymi dla każdego tłumaczenia języka. Wygenerowany indeks ma klucz dokumentu i używa wartości domyślnych dla pól utworzonych przy użyciu interfejsu API REST tworzenia indeksu.
from synapse.ml.cognitive import *
(translated_df.withColumn("DocID", monotonically_increasing_id().cast("string"))
.withColumn("SearchAction", lit("upload"))
.writeToAzureSearch(
subscriptionKey=search_key,
actionCol="SearchAction",
serviceName=search_service,
indexName=search_index,
keyCol="DocID",
))
Aby zapoznać się z definicją indeksu utworzoną przez usługę AzureSearchWriter, sprawdź strony usługi wyszukiwania w witrynie Azure Portal.
Uwaga
Jeśli nie możesz użyć domyślnego indeksu wyszukiwania, możesz podać zewnętrzną definicję niestandardową w formacie JSON, przekazując jej identyfikator URI jako ciąg we właściwości "indexJson". Najpierw wygeneruj indeks domyślny, aby wiedzieć, które pola mają być określone, a następnie postępuj zgodnie z dostosowanymi właściwościami, jeśli na przykład potrzebujesz określonych analizatorów.
Wykonywanie zapytań względem indeksu
Wklej następujący kod do siódmej komórki i uruchom go. Nie są wymagane żadne modyfikacje, z wyjątkiem tego, że warto zmienić składnię lub wypróbować więcej przykładów, aby dokładniej zapoznać się z zawartością:
Nie ma transformatora ani modułu, który wystawia zapytania. Ta komórka to proste wywołanie REST API wyszukiwania dokumentów.
W tym konkretnym przykładzie wyszukiwany jest wyraz "drzwi" ("search": "door"). Zwraca również wartość "count" liczby pasujących dokumentów i wybiera tylko zawartość pól "Description" i "Translations" dla wyników. Jeśli chcesz wyświetlić pełną listę pól, usuń parametr "select".
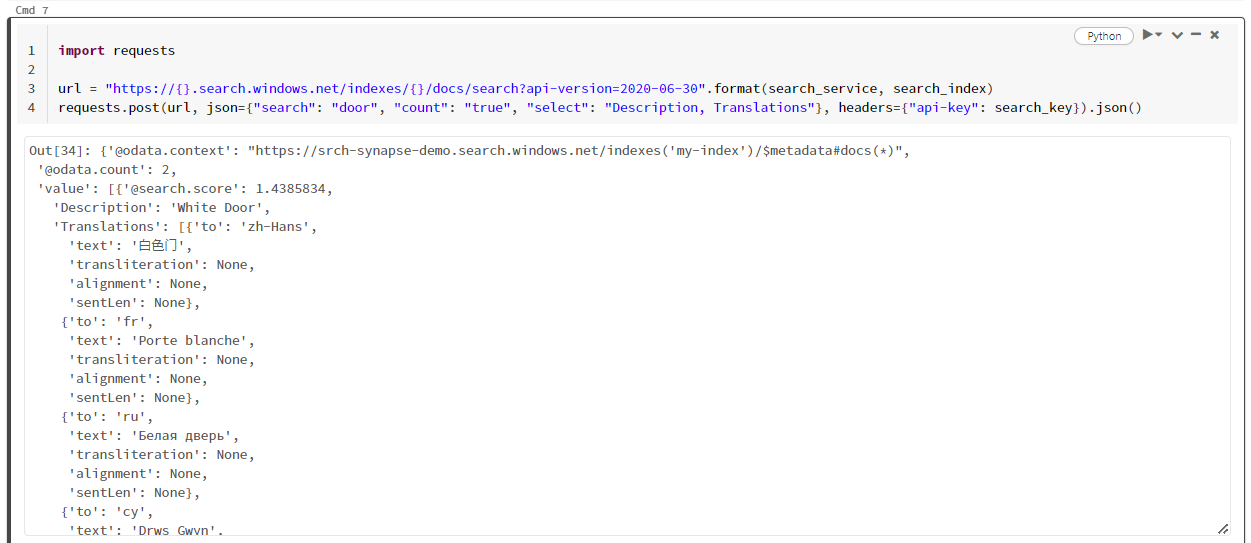
import requests
url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2024-07-01".format(search_service, search_index)
requests.post(url, json={"search": "door", "count": "true", "select": "Description, Translations"}, headers={"api-key": search_key}).json()
Poniższy zrzut ekranu przedstawia wynik działania komórki dla przykładowego skryptu.
Czyszczenie zasobów
Gdy pracujesz we własnej subskrypcji, na końcu projektu warto usunąć zasoby, których już nie potrzebujesz. Zasoby pozostawione w działaniu mogą generować koszty. Zasoby możesz usuwać pojedynczo lub jako grupę zasobów, usuwając cały zestaw zasobów.
Zasoby można znaleźć w witrynie Azure Portal i zarządzać nimi, korzystając z linku Wszystkie zasoby lub Grupy zasobów w okienku nawigacji po lewej stronie.
Następne kroki
W tym samouczku nauczyłeś się o transformatorze AzureSearchWriter w SynapseML, który jest nowym sposobem tworzenia i ładowania indeksów wyszukiwania w usłudze Azure AI Search. Funkcja przekształcania przyjmuje ustrukturyzowany kod JSON jako dane wejściowe. FormOntologyLearner może zapewnić niezbędną strukturę danych wyjściowych generowanych przez transformatory analizy dokumentów w usłudze SynapseML.
W następnym kroku zapoznaj się z innymi samouczkami usługi SynapseML, które generują przekształconą zawartość, którą warto eksplorować za pomocą usługi Azure AI Search: