Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W usłudze Azure AI Search, jeśli masz indeks wektorowy, w tym artykule wyjaśniono, jak:
W tym artykule użyto architektury REST na potrzeby ilustracji. Po zapoznaniu się z podstawowym przepływem pracy przejdź do przykładów kodu zestawu Azure SDK w repozytorium azure-search-vector-samples , które udostępnia kompleksowe rozwiązania obejmujące zapytania wektorowe.
Eksplorator wyszukiwania można również użyć w witrynie Azure Portal.
Wymagania wstępne
Usługa Azure AI Search w dowolnym regionie i na dowolnym poziomie.
Indeks wektorowy. Sprawdź sekcję
vectorSearchw indeksie, aby potwierdzić jej obecność.Opcjonalnie dodaj wektoryzator do indeksu na potrzeby wbudowanej konwersji tekstu na wektor lub obraz-wektor podczas wykonywania zapytań.
Program Visual Studio Code z klientem REST i przykładowymi danymi, jeśli chcesz uruchomić te przykłady samodzielnie. Aby rozpocząć pracę z klientem REST, zobacz Szybki start: wyszukiwanie pełnotekstowe przy użyciu interfejsu REST.
Konwertowanie danych wejściowych ciągu zapytania na wektor
Aby wysłać zapytanie do pola wektora, samo zapytanie musi być wektorem.
Jedną z metod konwertowania ciągu zapytania tekstowego użytkownika na jego reprezentację wektorową jest wywołanie biblioteki osadzania lub interfejsu API w kodzie aplikacji. Najlepszym rozwiązaniem jest użycie tych samych modeli osadzania używanych do generowania osadzania w dokumentach źródłowych. Przykłady kodu przedstawiające sposób generowania osadzania można znaleźć w repozytorium azure-search-vector-samples .
Drugim podejściem jest użycie zintegrowanej wektoryzacji, teraz ogólnie dostępnej, aby usługa Azure AI Search obsługiwała dane wejściowe i wyjściowe wektoryzacji zapytań.
Oto przykładowy ciąg zapytania przesłany do wdrożenia modelu osadzania usługi Azure OpenAI za pomocą interfejsu API REST:
POST https://{{openai-service-name}}.openai.azure.com/openai/deployments/{{openai-deployment-name}}/embeddings?api-version={{openai-api-version}}
Content-Type: application/json
api-key: {{admin-api-key}}
{
"input": "what azure services support generative AI'"
}
Oczekiwana odpowiedź to 202 w przypadku pomyślnego wywołania wdrożonego modelu.
Pole embedding w treści odpowiedzi jest wektorową reprezentacją ciągu inputzapytania . W celach testowych należy skopiować wartość embedding tablicy do vectorQueries.vector zapytania, używając składni pokazanej w następnych sekcjach.
Rzeczywista odpowiedź na to wywołanie POST do wdrożonego modelu obejmuje 1536 osadzania. W przypadku czytelności w tym przykładzie pokazano tylko kilka pierwszych wektorów.
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.009171937,
0.018715322,
...
-0.0016804502
]
}
],
"model": "ada",
"usage": {
"prompt_tokens": 7,
"total_tokens": 7
}
}
W tym podejściu kod aplikacji jest odpowiedzialny za nawiązywanie połączenia z modelem, generowanie osadzonych i obsługę odpowiedzi.
Żądanie zapytania wektorowego
W tej sekcji przedstawiono podstawową strukturę zapytania wektorowego. Aby sformułować zapytanie wektorowe, możesz użyć witryny Azure Portal, interfejsów API REST lub zestawów SDK platformy Azure.
W przypadku migracji z wersji 2023-07-01-Preview istnieją zmiany powodujące niezgodność. Aby uzyskać więcej informacji, zobacz Uaktualnianie do najnowszego interfejsu API REST.
2024-07-01 to stabilna wersja REST API Search POST. Ta wersja obsługuje następujące wersję:
-
vectorQueriesto konstrukcja wyszukiwania wektorowego. -
vectorQueries.kindustaw navectordla tablicy wektorowej lubtextjeśli dane wejściowe są ciągiem i jeśli masz wektoryzatora. -
vectorQueries.vectorto zapytanie (wektorowa reprezentacja tekstu lub obrazu). -
vectorQueries.exhaustive(opcjonalnie) wywołuje wyczerpującą nazwę KNN w czasie zapytania, nawet jeśli pole jest indeksowane dla HNSW. -
vectorQueries.fields(opcjonalnie) dotyczy określonych pól wykonywania zapytań (do 10 na zapytanie). -
vectorQueries.weight(opcjonalnie) określa względną wagę każdego zapytania wektorowego uwzględnionego w operacjach wyszukiwania. Aby uzyskać więcej informacji, zobacz Wagi wektorów. -
vectorQueries.kto liczba dopasowań do zwrócenia.
W poniższym przykładzie wektor jest reprezentacją tego ciągu: "what Azure services support full text search". Zapytanie jest przeznaczone dla contentVector pola i zwraca k wyniki. Rzeczywisty wektor zawiera 1536 osadzonych elementów, które są przycinane w tym przykładzie w celu zapewnienia czytelności.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector",
"weight": 0.5,
"k": 5
}
]
}
Odpowiedź zapytania wektorowego
W usłudze Azure AI Search odpowiedzi zapytań składają się z wszystkich retrievable pól domyślnie. Jednak często można ograniczyć wyniki wyszukiwania do podzestawu retrievable pól, wyświetlając je w instrukcji select .
W zapytaniu wektorowym należy dokładnie rozważyć, czy należy wektorować pola w odpowiedzi. Pola wektorowe nie są czytelne dla człowieka, więc jeśli wypychasz odpowiedź na stronę internetową, wybierz pola niewektorowe reprezentujące wynik. Jeśli na przykład zapytanie jest wykonywane względem contentVectorelementu , możesz zamiast tego zwrócić content wartość .
Jeśli chcesz uwzględnić pola wektorowe w wyniku, oto przykład struktury odpowiedzi.
contentVector to tablica ciągów znaków reprezentujących osadzania, przycięte w tym przykładzie w celu zapewnienia czytelności. Wynik wyszukiwania wskazuje istotność. Inne pola niewektorowe są uwzględniane w kontekście.
{
"@odata.count": 3,
"value": [
{
"@search.score": 0.80025613,
"title": "Azure Search",
"category": "AI + Machine Learning",
"contentVector": [
-0.0018343845,
0.017952163,
0.0025753193,
...
]
},
{
"@search.score": 0.78856903,
"title": "Azure Application Insights",
"category": "Management + Governance",
"contentVector": [
-0.016821077,
0.0037742127,
0.016136652,
...
]
},
{
"@search.score": 0.78650564,
"title": "Azure Media Services",
"category": "Media",
"contentVector": [
-0.025449317,
0.0038463024,
-0.02488436,
...
]
}
]
}
Kluczowe punkty:
kokreśla liczbę zwracanych wyników najbliższego sąsiada, w tym przypadku trzy. Zapytania wektorowe zawsze zwracająkwyniki, zakładając, że istnieją co najmniejkdokumenty, nawet jeśli niektóre dokumenty mają słabą podobieństwo. Dzieje się tak, ponieważ algorytm znajduje jakichkolwiek najbliższychksąsiadów wektora zapytania.Algorytm wyszukiwania wektorowego określa
@search.score.Pola w wynikach wyszukiwania to wszystkie
retrievablepola lub pola w klauzuliselect. Podczas wykonywania zapytania wektorowego dopasowywanie odbywa się tylko na danych wektorowych. Jednak odpowiedź może zawierać dowolneretrievablepole w indeksie. Ponieważ nie ma możliwości dekodowania wyniku pola wektorowego, włączenie pól tekstowych niewektorów jest przydatne dla ich czytelnych dla człowieka wartości.
Wiele pól wektorów
Można ustawić właściwość vectorQueries.fields na wiele pól wektorowych. Zapytanie wektorowe jest wykonywane względem każdego pola wektora podanego na fields liście. Można określić maksymalnie 10 pól.
Podczas wykonywania zapytań dotyczących wielu pól wektorowych upewnij się, że każdy z nich zawiera osadzanie z tego samego modelu osadzania. Zapytanie powinno być również generowane na podstawie tego samego modelu osadzania.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector, titleVector",
"k": 5
}
]
}
Wiele zapytań wektorowych
Wyszukiwanie wektorów wielozasyłowych wysyła wiele zapytań w wielu polach wektorów w indeksie wyszukiwania. Ten typ zapytania jest często używany z modelami, takimi jak CLIP do wyszukiwania wielomodalnego, gdzie ten sam model może wektoryzować zarówno tekst, jak i obrazy.
Poniższy przykład zapytania szuka podobieństwa w obu myImageVector i myTextVector, ale wysyła dwa odpowiednie osadzenia zapytań, z których każde jest wykonywane równolegle. Wynik tego zapytania jest oceniany przy użyciu wzajemnego łączenia rangi (RRF).
-
vectorQueriesudostępnia tablicę zapytań wektorowych. -
vectorzawiera wektory obrazów i wektory tekstowe w indeksie wyszukiwania. Każde wystąpienie jest oddzielnym zapytaniem. -
fieldsokreśla, które pole wektora ma być docelowe. -
kto liczba dopasowań najbliższych sąsiadów do uwzględnienia w wynikach.
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"fields": "myimagevector",
"k": 5
},
{
"kind": "vector"
"vector": [
-0.002222222,
0.018708462,
-0.013770515,
. . .
],
"fields": "mytextvector",
"k": 5
}
]
}
Indeksy wyszukiwania nie mogą przechowywać obrazów. Zakładając, że indeks zawiera pole dla pliku obrazu, wyniki wyszukiwania będą zawierać kombinację tekstu i obrazów.
Wykonywanie zapytań ze zintegrowaną wektoryzacją
W tej sekcji przedstawiono zapytanie wektorowe, które wywołuje zintegrowaną wektoryzację w celu przekonwertowania zapytania tekstowego lub obrazu na wektor. Zalecamy stabilną 2024-07-01 interfejs API REST, Eksplorator wyszukiwania lub nowsze pakiety zestawu Azure SDK dla tej funkcji.
Wymaganie wstępne to indeks wyszukiwania, który ma wektoryzator skonfigurowany i przypisany do pola wektora. Wektoryzator udostępnia informacje o połączeniu z modelem osadzania używanym w czasie wykonywania zapytania.
Eksplorator wyszukiwania obsługuje wektoryzację zintegrowaną w czasie wykonywania zapytań. Jeśli indeks zawiera pola wektorowe i ma wektoryzator, możesz użyć wbudowanej konwersji tekstu na wektor.
Zaloguj się do witryny Azure Portal i znajdź usługę wyszukiwania.
Z lewego menu wybierz zarządzanie wyszukiwaniem>Indeksy, a następnie wybierz swój indeks.
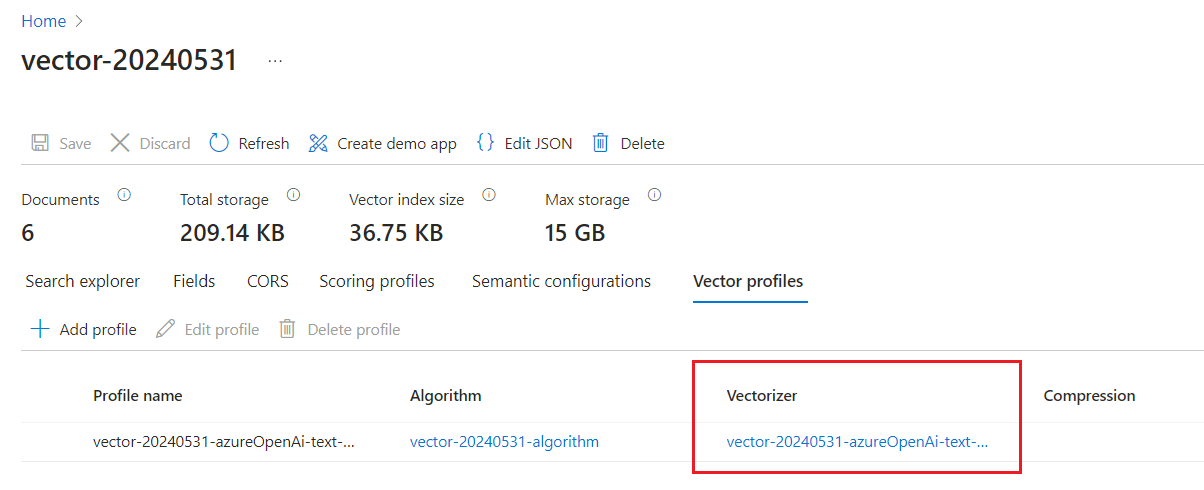
Wybierz kartę Profile wektorowe , aby potwierdzić, że masz wektoryzator.
Wybierz kartę Eksplorator wyszukiwania . Przy użyciu domyślnego widoku zapytania możesz wprowadzić ciąg tekstowy na pasku wyszukiwania. Wbudowany wektoryzator konwertuje ciąg na wektor, wykonuje wyszukiwanie i zwraca wyniki.
Alternatywnie możesz wybrać pozycję Wyświetl>widok JSON, aby wyświetlić lub zmodyfikować zapytanie. Jeśli istnieją wektory, Eksplorator wyszukiwania konfiguruje zapytanie wektorowe automatycznie. Widok JSON służy do wybierania pól do użycia w wyszukiwaniu i odpowiedzi, dodawaniu filtrów i konstruowaniu bardziej zaawansowanych zapytań, takich jak zapytania hybrydowe. Aby wyświetlić przykład JSON, wybierz kartę interfejsu API REST w tej sekcji.
Liczba sklasyfikowanych wyników w odpowiedzi na zapytanie wektorowe
Zapytanie wektorowe k określa parametr, który określa liczbę dopasowań zwracanych w wynikach. Aparat wyszukiwania zawsze zwraca k liczbę dopasowań. Jeśli k jest większa niż liczba dokumentów w indeksie, to liczba dokumentów określa górną granicę tego, co może zostać zwrócone.
Jeśli znasz wyszukiwanie pełnotekstowe, wiesz, że nie ma żadnych wyników, jeśli indeks nie zawiera terminu ani frazy. Jednak w wyszukiwaniu wektorowym operacja wyszukiwania identyfikuje najbliższych sąsiadów i zawsze zwraca k wyniki, nawet jeśli najbliższe sąsiady nie są podobne. Istnieje możliwość uzyskania wyników dla niesensownych lub poza tematem zapytań, zwłaszcza jeśli nie używasz monitów do ustawiania granic. Mniej istotne wyniki mają gorszy wynik podobieństwa, ale nadal są to "najbliższe" wektory, jeśli nie ma nic bliżej. W związku z tym, odpowiedź bez znaczących rezultatów może nadal zawierać k wyniki, ale ocena podobieństwa każdego z wyników będzie niska.
Hybrydowe podejście obejmujące wyszukiwanie pełnotekstowe może wyeliminować ten problem. Innym rozwiązaniem jest ustawienie minimalnej wartości progowej dla wyniku wyszukiwania, ale tylko wtedy, gdy zapytanie jest czystym pojedynczym zapytaniem wektorowym. Zapytania hybrydowe nie sprzyjają minimalnym progom, ponieważ zakresy RRF są znacznie mniejsze i bardziej niestabilne.
Parametry zapytania, które mają wpływ na liczbę wyników, obejmują:
-
"k": nwyniki dla zapytań tylko wektorów. -
"top": nwyniki dla zapytań hybrydowych, które zawierająsearchparametr.
Oba k elementy i top są opcjonalne. Gdy nie określono, domyślna liczba wyników w odpowiedzi to 50. Możesz ustawić top oraz skip na przeglądanie większej liczby wyników lub zmienić wartość domyślną.
Algorytmy klasyfikowania używane w zapytaniu wektorowym
Klasyfikacja wyników jest obliczana przez:
- Metryka podobieństwa.
- RRF, jeśli istnieje wiele zestawów wyników wyszukiwania.
Metryka podobieństwa
Metryka podobieństwa określona w sekcji indeksu vectorSearch dla zapytania tylko wektorów. Prawidłowe wartości to cosine, euclidean i dotProduct.
Modele osadzania usługi Azure OpenAI używają podobieństwa cosinus, więc jeśli używasz modeli osadzania w usłudze Azure OpenAI, cosine to zalecana metryka. Inne obsługiwane metryki klasyfikacji to euclidean i dotProduct.
RRF
Wiele zestawów jest tworzonych, jeśli zapytanie jest przeznaczone dla wielu pól wektorów, uruchamia wiele zapytań wektorowych równolegle lub jest hybrydą wyszukiwania wektorowego i pełnotekstowego z lub bez semantycznego rankingu.
Podczas wykonywania zapytania zapytanie wektorowe może dotyczyć tylko jednego indeksu wektora wewnętrznego. W przypadku wielu pól wektorowych i wielu zapytań wektorowych aparat wyszukiwania generuje wiele zapytań przeznaczonych dla odpowiednich indeksów wektorów każdego pola. Dane wyjściowe to zestaw sklasyfikowanych wyników dla każdego zapytania, które są połączone przy użyciu protokołu RRF. Aby uzyskać więcej informacji, zobacz Ocenianie istotności przy użyciu wzajemnego łączenia rangi.
Waga wektorów
Dodaj parametr zapytania, aby określić względną weight wagę każdego zapytania wektorowego uwzględnionego w operacjach wyszukiwania. Ta wartość jest używana podczas łączenia wyników wielu list klasyfikacji generowanych przez co najmniej dwa zapytania wektorowe w tym samym żądaniu lub z części wektorowej zapytania hybrydowego.
Wartość domyślna to 1.0, a wartość musi być liczbą dodatnią większą niż zero.
Wagi są używane podczas obliczania wyników RRF każdego dokumentu. Obliczenie jest wynikiem przemnożenia wartości weight względem oceny pozycji dokumentu w ramach odpowiedniego zestawu wyników.
Poniższy przykład to zapytanie hybrydowe z dwoma ciągami zapytania wektorowego i jednym ciągiem tekstowym. Wagi są przypisywane do zapytań wektorowych. Pierwsze zapytanie wynosi 0,5 lub połowę wagi, zmniejszając jego znaczenie w żądaniu. Drugie zapytanie wektorowe jest dwa razy ważniejsze.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-07-01
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my_first_vector_field",
"k": 10,
"weight": 0.5
},
{
"kind": "vector",
"vector": [4.0, 5.0, 6.0],
"fields": "my_second_vector_field",
"k": 10,
"weight": 2.0
}
],
"search": "hello world"
}
Waga wektorów ma zastosowanie tylko do wektorów. Zapytanie tekstowe w tym przykładzie "hello world"ma niejawną neutralną wagę 1,0. Jednak w zapytaniu hybrydowym można zwiększyć lub zmniejszyć znaczenie pól tekstowych, ustawiając wartość maxTextRecallSize.
Ustaw progi, aby wykluczyć wyniki z niską oceną (wersja zapoznawcza)
Ponieważ wyszukiwanie najbliższych sąsiadów zawsze zwraca żądanych k sąsiadów, można uzyskać wiele dopasowań o niskiej ocenie, spełniając wymogi dotyczące k liczby wyników wyszukiwania. Aby wykluczyć wyniki wyszukiwania z niską oceną, możesz dodać threshold parametr zapytania, który filtruje wyniki na podstawie minimalnej oceny. Filtrowanie występuje przed połączeniem wyników z różnych zestawów odwołań.
Ten parametr jest w wersji zapoznawczej. Zalecamy wersję interfejsu API REST 2024-05-01-preview .
W tym przykładzie wszystkie dopasowania, które mają ocenę poniżej 0,8, są wykluczone z wyników wyszukiwania wektorowego, nawet jeśli liczba wyników spada poniżej k.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my-cosine-field",
"threshold": {
"kind": "vectorSimilarity",
"value": 0.8
}
}
]
}
MaxTextSizeRecall na potrzeby wyszukiwania hybrydowego (wersja zapoznawcza)
Zapytania wektorowe są często używane w konstrukcjach hybrydowych, które zawierają pola niewektorowe. Jeśli okaże się, że wyniki w rankingu BM25 są ponad lub poniżej reprezentowane w wynikach zapytania hybrydowego, możesz ustawićmaxTextRecallSize, aby zwiększyć lub zmniejszyć wyniki klasyfikacji hybrydowej BM25.
Tę właściwość można ustawić tylko w żądaniach hybrydowych, które zawierają zarówno składniki, jak search i vectorQueries .
Ten parametr jest w wersji zapoznawczej. Zalecamy wersję interfejsu API REST 2024-05-01-preview .
Aby uzyskać więcej informacji, zobacz Set maxTextRecallSize — Tworzenie zapytania hybrydowego.
Następne kroki
W następnym kroku przejrzyj przykłady kodu zapytania wektorowego w języku Python, C# lub JavaScript.