Partition Service Fabric reliable services (Partycjonowanie usług Reliable Services w ramach usługi Service Fabric)
Ten artykuł zawiera wprowadzenie do podstawowych pojęć związanych z partycjonowaniem niezawodnych usług azure Service Fabric. Partycjonowanie umożliwia przechowywanie danych na maszynach lokalnych, dzięki czemu dane i obliczenia można skalować razem.
Napiwek
Kompletny przykład kodu w tym artykule jest dostępny w witrynie GitHub.
Partycjonowanie
Partycjonowanie nie jest unikatowe dla usługi Service Fabric. W rzeczywistości jest to podstawowy wzorzec tworzenia skalowalnych usług. W szerszym sensie możemy myśleć o partycjonowaniu jako koncepcji dzielenia stanu (danych) i obliczeń na mniejsze dostępne jednostki, aby zwiększyć skalowalność i wydajność. Dobrze znaną formą partycjonowania jest partycjonowanie danych, nazywane również fragmentowaniem.
Partycjonowanie usług bezstanowych usługi Service Fabric
W przypadku usług bezstanowych można myśleć o partycji będącej jednostką logiczną zawierającą co najmniej jedno wystąpienie usługi. Rysunek 1 przedstawia usługę bezstanową z pięcioma wystąpieniami rozproszonymi w klastrze przy użyciu jednej partycji.
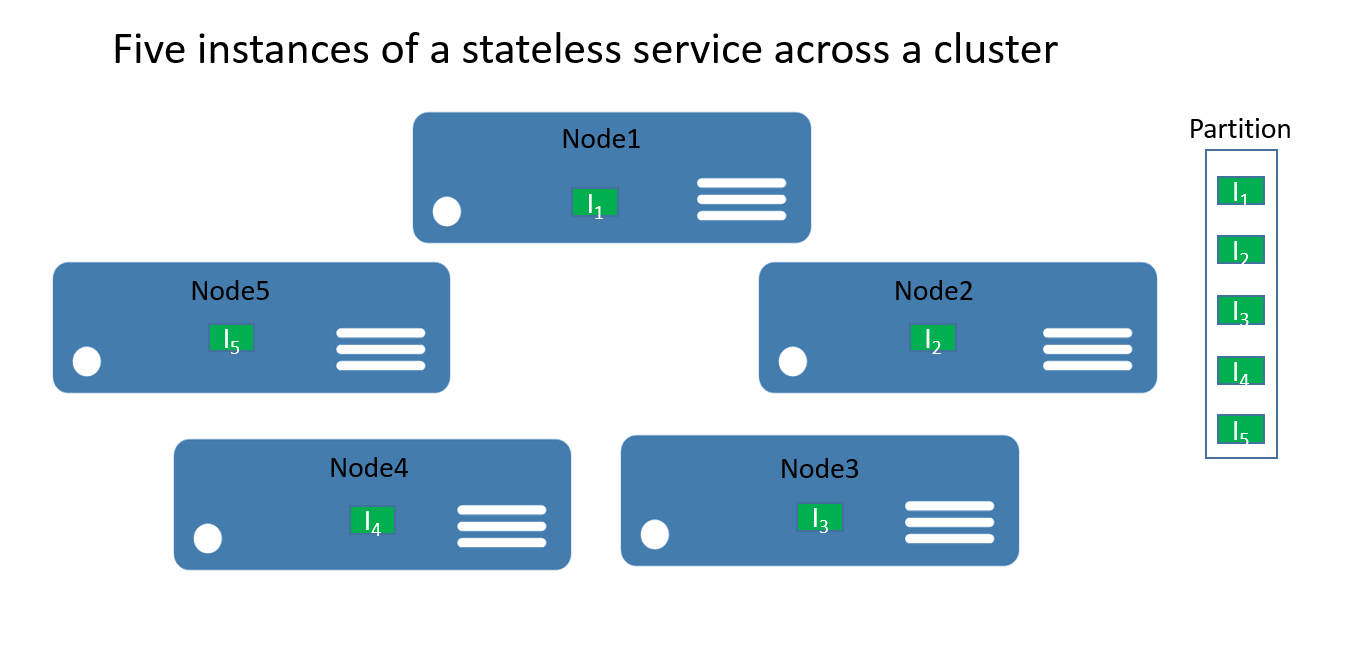
Istnieją naprawdę dwa typy rozwiązań usług bezstanowych. Pierwsza z nich to usługa, która utrzymuje stan zewnętrznie, na przykład w bazie danych w usłudze Azure SQL Database (na przykład w witrynie internetowej, w której przechowywane są informacje i dane sesji). Drugi to usługi tylko do obliczeń (takie jak kalkulator lub miniatury obrazu), które nie zarządzają żadnym stanem trwałym.
W obu przypadkach partycjonowanie usługi bezstanowej jest bardzo rzadkim scenariuszem— skalowalność i dostępność są zwykle osiągane przez dodanie większej liczby wystąpień. Jedynym czasem, w którym chcesz rozważyć wiele partycji dla wystąpień usługi bezstanowej, jest spełnienie specjalnych żądań routingu.
Rozważmy na przykład przypadek, w którym użytkownicy z identyfikatorami w określonym zakresie powinni być obsługiwani tylko przez określone wystąpienie usługi. Innym przykładem partycjonowania usługi bezstanowej jest to, że istnieje naprawdę partycjonowane zaplecze (np. baza danych podzielona na fragmenty w usłudze SQL Database) i chcesz kontrolować, które wystąpienie usługi powinno zapisywać w ramach fragmentu bazy danych lub wykonać inną pracę przygotowania w ramach usługi bezstanowej, która wymaga tych samych informacji partycjonowania, co jest używane w zapleczu. Te typy scenariuszy można również rozwiązać na różne sposoby i niekoniecznie wymagają partycjonowania usługi.
Pozostała część tego przewodnika koncentruje się na usługach stanowych.
Partycjonowanie usług stanowych usługi Service Fabric
Usługa Service Fabric ułatwia opracowywanie skalowalnych usług stanowych, oferując najwyższej klasy sposób partycjonowania stanu (danych). Koncepcyjnie można myśleć o partycji usługi stanowej jako jednostki skalowania, która jest wysoce niezawodna dzięki replikom rozproszonym i zrównoważonym między węzłami w klastrze.
Partycjonowanie w kontekście usług stanowych usługi Service Fabric odnosi się do procesu określania, że określona partycja usługi jest odpowiedzialna za część pełnego stanu usługi. (Jak wspomniano wcześniej, partycja jest zestawem replik). Świetną rzeczą w usłudze Service Fabric jest umieszczenie partycji w różnych węzłach. Dzięki temu mogą rosnąć do limitu zasobów węzła. Wraz ze wzrostem potrzeb dotyczących danych partycje rosną, a usługa Service Fabric ponownie równoważy partycje między węzłami. Zapewnia to ciągłe efektywne wykorzystanie zasobów sprzętowych.
Aby nadać przykład, załóżmy, że zaczynasz od klastra 5-węzłowego i usługi, która jest skonfigurowana tak, aby miała 10 partycji i element docelowy trzech replik. W takim przypadku usługa Service Fabric równoważy i dystrybuuje repliki w klastrze — w końcu dwie repliki podstawowe na węzeł. Jeśli chcesz teraz skalować klaster do 10 węzłów, usługa Service Fabric ponownie zrównoważy repliki podstawowe we wszystkich 10 węzłach . Podobnie w przypadku skalowania z powrotem do 5 węzłów usługa Service Fabric ponownie zrównoważy wszystkie repliki w 5 węzłach.
Rysunek 2 przedstawia rozkład 10 partycji przed skalowaniem klastra i po nim.
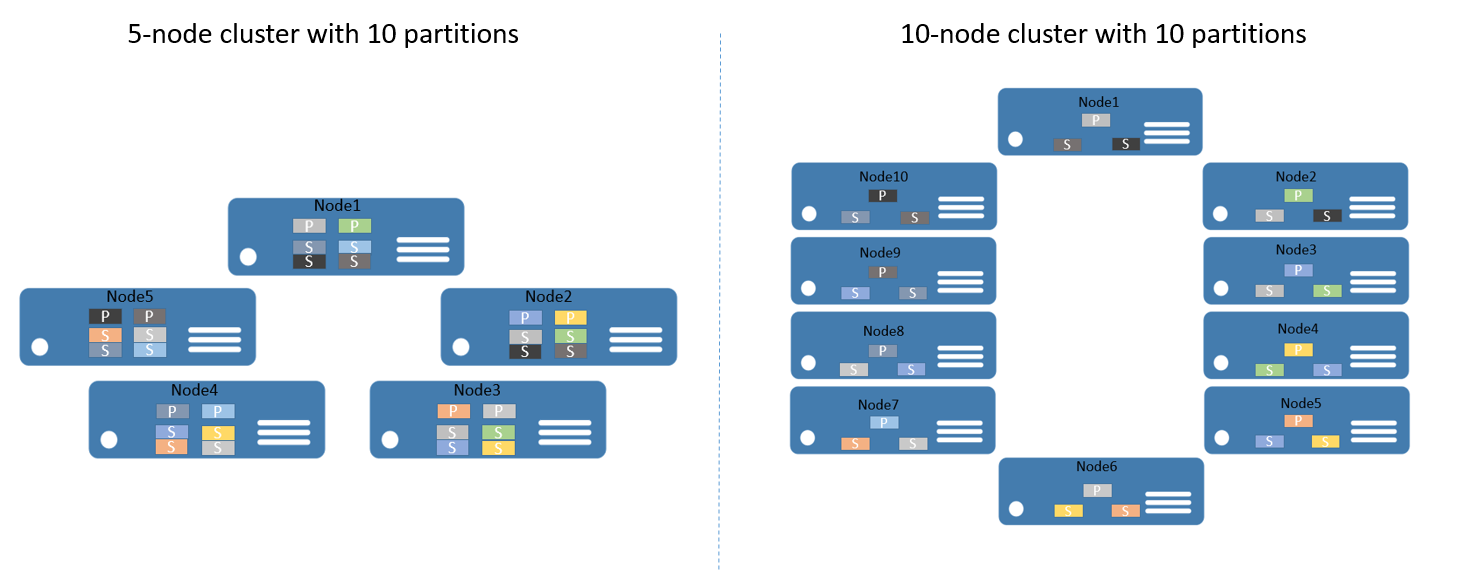
W związku z tym skalowanie w poziomie jest osiągane, ponieważ żądania klientów są dystrybuowane między komputerami, ogólna wydajność aplikacji jest większa, a rywalizacja o dostęp do fragmentów danych jest ograniczona.
Planowanie partycjonowania
Przed wdrożeniem usługi należy zawsze rozważyć strategię partycjonowania wymaganą do skalowania w poziomie. Istnieją różne sposoby, ale wszystkie z nich koncentrują się na tym, co aplikacja musi osiągnąć. W kontekście tego artykułu rozważmy niektóre z ważniejszych aspektów.
Dobrym podejściem jest zastanowienie się nad strukturą stanu, który należy podzielić na partycje, jako pierwszy krok.
Weźmy prosty przykład. Jeśli chcesz utworzyć usługę dla całego powiatu ankiety, możesz utworzyć partycję dla każdego miasta w hrabstwie. Następnie można przechowywać głosy dla każdej osoby w mieście w partycji, która odpowiada miastu. Rysunek 3 przedstawia zestaw osób i miasto, w którym się znajdują.
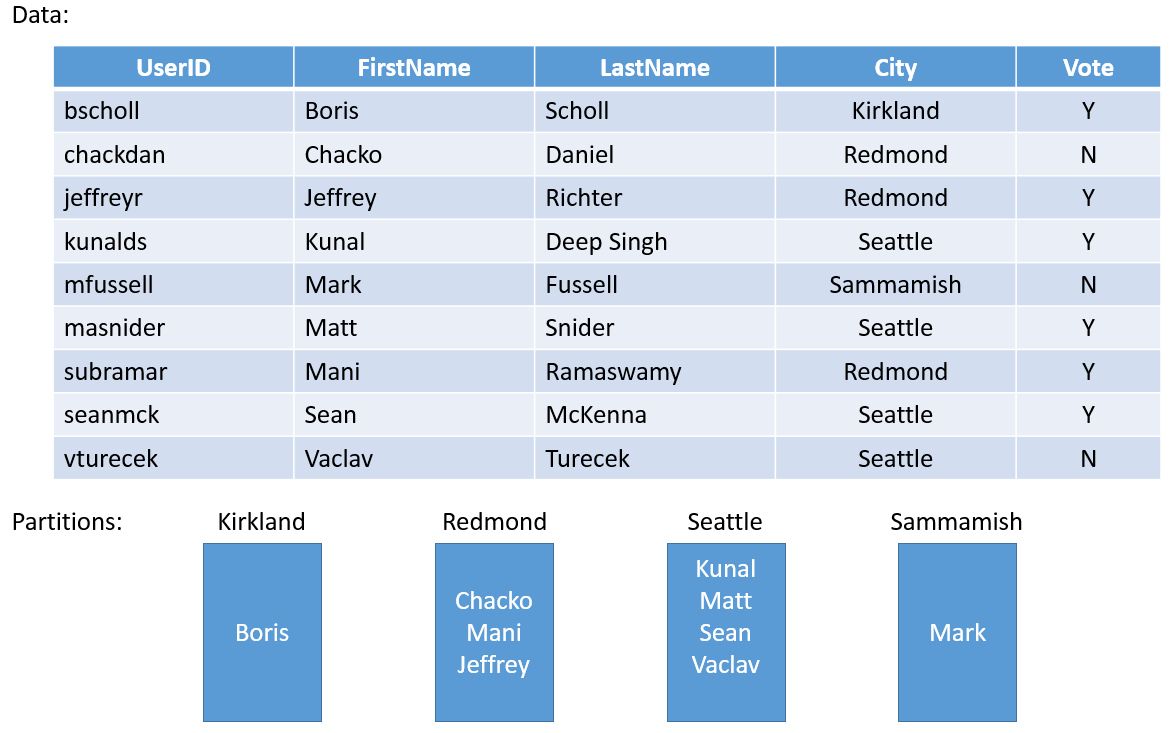
Ponieważ populacja miast jest bardzo różna, może się zdarzyć, że niektóre partycje zawierają dużo danych (np. Seattle) i inne partycje o bardzo małym stanie (np. Kirkland). Jaki jest więc wpływ na partycje z nierównomiernymi ilościami stanu?
Jeśli ponownie pomyślisz o przykładzie, możesz łatwo zobaczyć, że partycja, która posiada głosy dla Seattle, uzyska więcej ruchu niż Kirkland jeden. Domyślnie usługa Service Fabric zapewnia, że w każdym węźle znajduje się mniej więcej taka sama liczba replik podstawowych i pomocniczych. W związku z tym węzły przechowujące repliki obsługujące większy ruch i inne, które obsługują mniej ruchu. Najlepiej, aby uniknąć takich gorących i zimnych plam w klastrze.
Aby tego uniknąć, należy wykonać dwie czynności z punktu widzenia partycjonowania:
- Spróbuj podzielić stan na partycje, aby był równomiernie rozłożony na wszystkie partycje.
- Ładowanie raportów z każdej repliki usługi. (Aby uzyskać informacje na temat sposobu, zapoznaj się z tym artykułem na temat Metryki i ładowanie). Usługa Service Fabric umożliwia raportowanie obciążenia zużywanego przez usługi, takie jak ilość pamięci lub liczba rekordów. Na podstawie zgłoszonych metryk usługa Service Fabric wykrywa, że niektóre partycje obsługują wyższe obciążenia niż inne i ponownie równoważą klaster, przenosząc repliki do bardziej odpowiednich węzłów, tak aby ogólnie żaden węzeł nie był przeciążony.
Czasami nie można wiedzieć, ile danych będzie znajdować się w danej partycji. Ogólne zalecenie polega na tym, aby wykonać obie te czynności, przyjmując strategię partycjonowania, która równomiernie rozkłada dane między partycje, a po drugie przez raportowanie obciążenia. Pierwsza metoda zapobiega sytuacjom opisanym w przykładzie głosowania, a druga pomaga wygładzić tymczasowe różnice w dostępie lub obciążeniu w czasie.
Innym aspektem planowania partycji jest wybranie odpowiedniej liczby partycji, od których należy zacząć. Z perspektywy usługi Service Fabric nie ma nic, co uniemożliwia rozpoczęcie pracy z wyższą liczbą partycji niż oczekiwano w danym scenariuszu. W rzeczywistości przy założeniu, że maksymalna liczba partycji jest prawidłową metodą.
W rzadkich przypadkach może być potrzebnych więcej partycji, niż początkowo wybrano. Ponieważ nie można zmienić liczby partycji po fakcie, należy zastosować niektóre zaawansowane podejścia do partycji, takie jak utworzenie nowego wystąpienia usługi tego samego typu usługi. Należy również zaimplementować logikę po stronie klienta, która kieruje żądania do poprawnego wystąpienia usługi na podstawie wiedzy po stronie klienta, którą musi obsługiwać kod klienta.
Innym zagadnieniem podczas planowania partycjonowania jest dostępne zasoby komputera. Ponieważ stan musi być dostępny i przechowywany, musisz postępować zgodnie z poniższymi wymaganiami:
- Limity przepustowości sieci
- Limity pamięci systemowej
- Limity magazynu dysków
Co się stanie, jeśli wystąpią ograniczenia zasobów w uruchomionym klastrze? Odpowiedź polega na tym, że można po prostu skalować klaster w poziomie, aby uwzględnić nowe wymagania.
Przewodnik planowania pojemności zawiera wskazówki dotyczące określania liczby węzłów, których potrzebuje klaster.
Wprowadzenie do partycjonowania
W tej sekcji opisano, jak rozpocząć partycjonowanie usługi.
Usługa Service Fabric oferuje wybór trzech schematów partycji:
- Partycjonowanie zakresowe (znane inaczej jako UniformInt64Partition).
- Nazwane partycjonowanie. Aplikacje korzystające z tego modelu zwykle mają dane, które można zasobnikować w zestawie ograniczonym. Niektóre typowe przykłady pól danych używanych jako nazwane klucze partycji to regiony, kody pocztowe, grupy klientów lub inne granice biznesowe.
- Partycjonowanie jednotonowe. Partycje pojedyncze są zwykle używane, gdy usługa nie wymaga dodatkowego routingu. Na przykład usługi bezstanowe domyślnie używają tego schematu partycjonowania.
Schematy partycjonowania nazwane i jednotonowe to specjalne formy partycji zakresowych. Domyślnie szablony programu Visual Studio dla usługi Service Fabric używają partycjonowania z zakresem, ponieważ jest to najbardziej typowe i przydatne. Pozostała część tego artykułu koncentruje się na schemacie partycjonowania zakresowego.
Schemat partycjonowania zakresowego
Służy do określania zakresu liczby całkowitej (identyfikowanego przez niski klucz i wysoki klucz) oraz liczby partycji (n). Tworzy n partycji, z których każda jest odpowiedzialna za nienakładanie się podgrupy ogólnego zakresu kluczy partycji. Na przykład schemat partycjonowania z zakresem z niskim kluczem 0, wysokim kluczem 99 i liczbą 4 tworzy cztery partycje, jak pokazano poniżej.
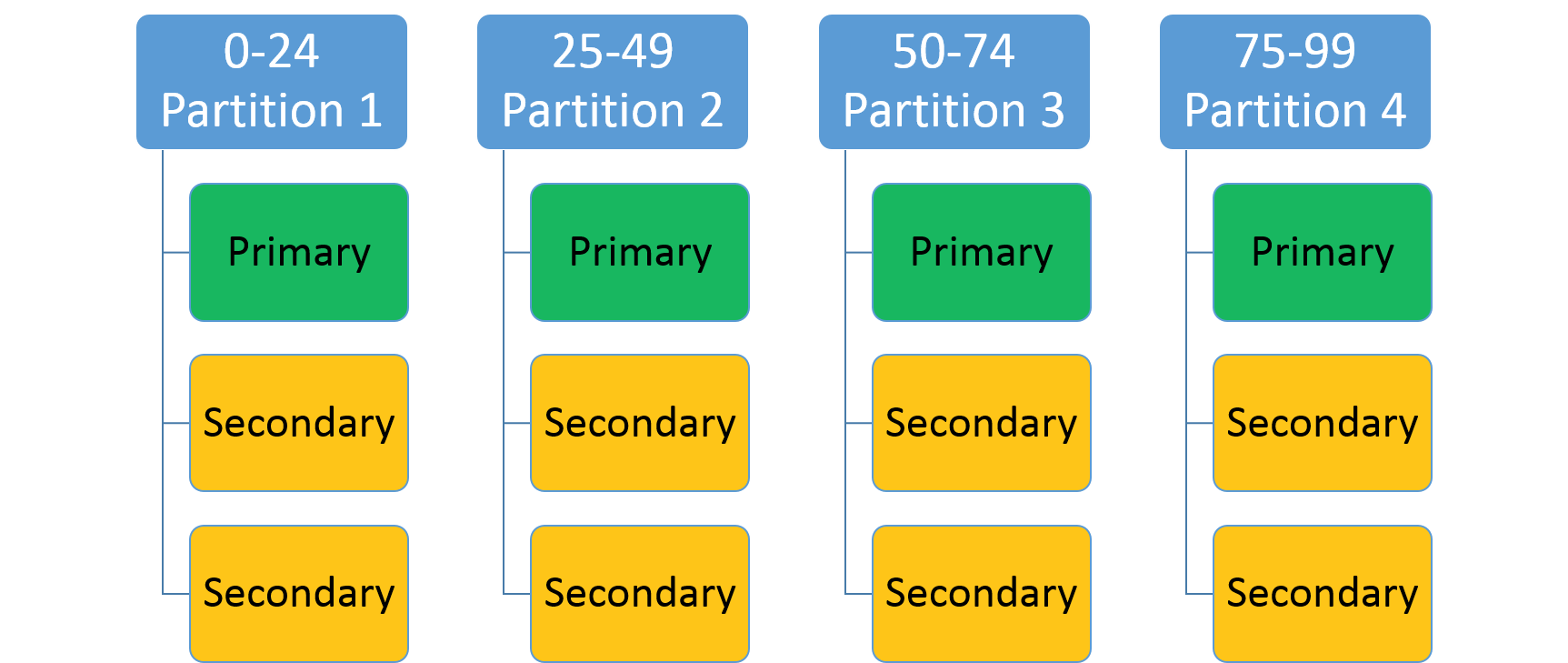
Typowym podejściem jest utworzenie skrótu na podstawie unikatowego klucza w zestawie danych. Niektóre typowe przykłady kluczy to numer identyfikacyjny pojazdu (VIN), identyfikator pracownika lub unikatowy ciąg. Używając tego unikatowego klucza, wygenerujesz kod skrótu, moduluje zakres kluczy, aby użyć go jako klucza. Możesz określić górne i dolne granice dozwolonego zakresu kluczy.
Wybieranie algorytmu skrótu
Ważną częścią tworzenia skrótów jest wybranie algorytmu skrótu. Należy wziąć pod uwagę, czy celem jest grupowanie podobnych kluczy w pobliżu siebie (skróty wrażliwe na lokalność) lub czy działanie powinno być szeroko dystrybuowane we wszystkich partycjach (skrót dystrybucji), co jest bardziej powszechne.
Cechy dobrego algorytmu tworzenia skrótów dystrybucji są takie, że łatwo jest go obliczyć, ma kilka kolizji i równomiernie rozkłada klucze. Dobrym przykładem wydajnego algorytmu skrótu jest algorytm skrótu FNV-1 .
Dobrym zasobem dla ogólnych wyborów algorytmów kodu skrótu jest strona Wikipedii na temat funkcji skrótu.
Tworzenie usługi stanowej z wieloma partycjami
Utwórzmy pierwszą niezawodną usługę stanową z wieloma partycjami. W tym przykładzie utworzysz bardzo prostą aplikację, w której chcesz przechowywać wszystkie nazwiska rozpoczynające się od tej samej litery w tej samej partycji.
Przed napisaniem jakiegokolwiek kodu należy zastanowić się nad partycjami i kluczami partycji. Potrzebujesz 26 partycji (po jednej dla każdej litery alfabetu), ale co z niskimi i wysokimi kluczami? Ponieważ dosłownie chcemy mieć jedną partycję na literę, możemy użyć wartości 0 jako niskiego klucza i 25 jako wysokiego klucza, ponieważ każda litera jest własnym kluczem.
Uwaga
Jest to uproszczony scenariusz, ponieważ w rzeczywistości rozkład byłby nierówny. Nazwiska rozpoczynające się od liter "S" lub "M" są bardziej powszechne niż te rozpoczynające się od "X" lub "Y".
Otwórz nowy>projekt w pliku>programu Visual Studio.>
W oknie dialogowym Nowy projekt wybierz aplikację usługi Service Fabric.
Wywołaj projekt "AlphabetPartitions".
W oknie dialogowym Tworzenie usługi wybierz pozycję Usługa stanowa i wywołaj ją jako "Alphabet.Processing".
Ustaw liczbę partycji. Otwórz plik ApplicationManifest.xml znajdujący się w folderze ApplicationPackageRoot projektu AlphabetPartitions i zaktualizuj parametr Processing_PartitionCount do 26, jak pokazano poniżej.
<Parameter Name="Processing_PartitionCount" DefaultValue="26" />Należy również zaktualizować właściwości LowKey i HighKey elementu StatefulService w ApplicationManifest.xml, jak pokazano poniżej.
<Service Name="Alphabet.Processing"> <StatefulService ServiceTypeName="Alphabet.ProcessingType" TargetReplicaSetSize="[Processing_TargetReplicaSetSize]" MinReplicaSetSize="[Processing_MinReplicaSetSize]"> <UniformInt64Partition PartitionCount="[Processing_PartitionCount]" LowKey="0" HighKey="25" /> </StatefulService> </Service>Aby usługa była dostępna, otwórz punkt końcowy na porcie, dodając element punktu końcowego ServiceManifest.xml (znajdujący się w folderze PackageRoot) dla usługi Alphabet.Processing, jak pokazano poniżej:
<Endpoint Name="ProcessingServiceEndpoint" Port="8089" Protocol="http" Type="Internal" />Teraz usługa jest skonfigurowana do nasłuchiwania wewnętrznego punktu końcowego z 26 partycjami.
Następnie należy zastąpić metodę
CreateServiceReplicaListeners()klasy Processing.Uwaga
W tym przykładzie przyjęto założenie, że używasz prostego elementu HttpCommunicationListener. Aby uzyskać więcej informacji na temat niezawodnej komunikacji z usługą, zobacz Model komunikacji usługi Reliable Service.
Zalecanym wzorcem adresu URL, na którym nasłuchuje replika, jest następujący format:
{scheme}://{nodeIp}:{port}/{partitionid}/{replicaid}/{guid}. Dlatego chcesz skonfigurować odbiornik komunikacji tak, aby nasłuchiwać prawidłowych punktów końcowych i za pomocą tego wzorca.Wiele replik tej usługi może być hostowanych na tym samym komputerze, więc ten adres musi być unikatowy dla repliki. Dlatego identyfikator partycji i identyfikator repliki znajdują się w adresie URL. Program HttpListener może nasłuchiwać na wielu adresach na tym samym porcie, o ile prefiks adresu URL jest unikatowy.
Dodatkowy identyfikator GUID jest dostępny w przypadku zaawansowanego przypadku, w którym repliki pomocnicze nasłuchują również żądań tylko do odczytu. W takim przypadku należy upewnić się, że nowy unikatowy adres jest używany podczas przechodzenia z podstawowego do pomocniczego w celu wymuszenia ponownego rozpoznania adresu przez klientów. Element "+" jest używany jako adres tutaj, dzięki czemu replika nasłuchuje na wszystkich dostępnych hostach (IP, FQDN, localhost itp.) Poniższy kod przedstawia przykład.
protected override IEnumerable<ServiceReplicaListener> CreateServiceReplicaListeners() { return new[] { new ServiceReplicaListener(context => this.CreateInternalListener(context))}; } private ICommunicationListener CreateInternalListener(ServiceContext context) { EndpointResourceDescription internalEndpoint = context.CodePackageActivationContext.GetEndpoint("ProcessingServiceEndpoint"); string uriPrefix = String.Format( "{0}://+:{1}/{2}/{3}-{4}/", internalEndpoint.Protocol, internalEndpoint.Port, context.PartitionId, context.ReplicaOrInstanceId, Guid.NewGuid()); string nodeIP = FabricRuntime.GetNodeContext().IPAddressOrFQDN; string uriPublished = uriPrefix.Replace("+", nodeIP); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInternalRequest); }Warto również zauważyć, że opublikowany adres URL różni się nieco od prefiksu adresu URL nasłuchiwania. Adres URL nasłuchiwania jest podawany httplistener. Opublikowany adres URL to adres URL opublikowany w usłudze Service Fabric Naming Service, który jest używany do odnajdywania usług. Klienci będą prosić o ten adres za pośrednictwem tej usługi odnajdywania. Adres pobierany przez klientów musi mieć rzeczywisty adres IP lub nazwę FQDN węzła w celu nawiązania połączenia. Dlatego należy zastąpić ciąg "+" adresem IP węzła lub nazwą FQDN, jak pokazano powyżej.
Ostatnim krokiem jest dodanie logiki przetwarzania do usługi, jak pokazano poniżej.
private async Task ProcessInternalRequest(HttpListenerContext context, CancellationToken cancelRequest) { string output = null; string user = context.Request.QueryString["lastname"].ToString(); try { output = await this.AddUserAsync(user); } catch (Exception ex) { output = ex.Message; } using (HttpListenerResponse response = context.Response) { if (output != null) { byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } } private async Task<string> AddUserAsync(string user) { IReliableDictionary<String, String> dictionary = await this.StateManager.GetOrAddAsync<IReliableDictionary<String, String>>("dictionary"); using (ITransaction tx = this.StateManager.CreateTransaction()) { bool addResult = await dictionary.TryAddAsync(tx, user.ToUpperInvariant(), user); await tx.CommitAsync(); return String.Format( "User {0} {1}", user, addResult ? "successfully added" : "already exists"); } }ProcessInternalRequestOdczytuje wartości parametru ciągu zapytania używanego do wywołania partycji i wywołańAddUserAsync, aby dodać nazwisko do niezawodnego słownikadictionary.Dodajmy do projektu usługę bezstanową, aby zobaczyć, jak można wywołać określoną partycję.
Ta usługa służy jako prosty interfejs internetowy, który akceptuje nazwisko jako parametr ciągu zapytania, określa klucz partycji i wysyła go do usługi Alphabet.Processing na potrzeby przetwarzania.
W oknie dialogowym Tworzenie usługi wybierz pozycję Usługa bezstanowa i wywołaj ją jako "Alphabet.Web", jak pokazano poniżej.
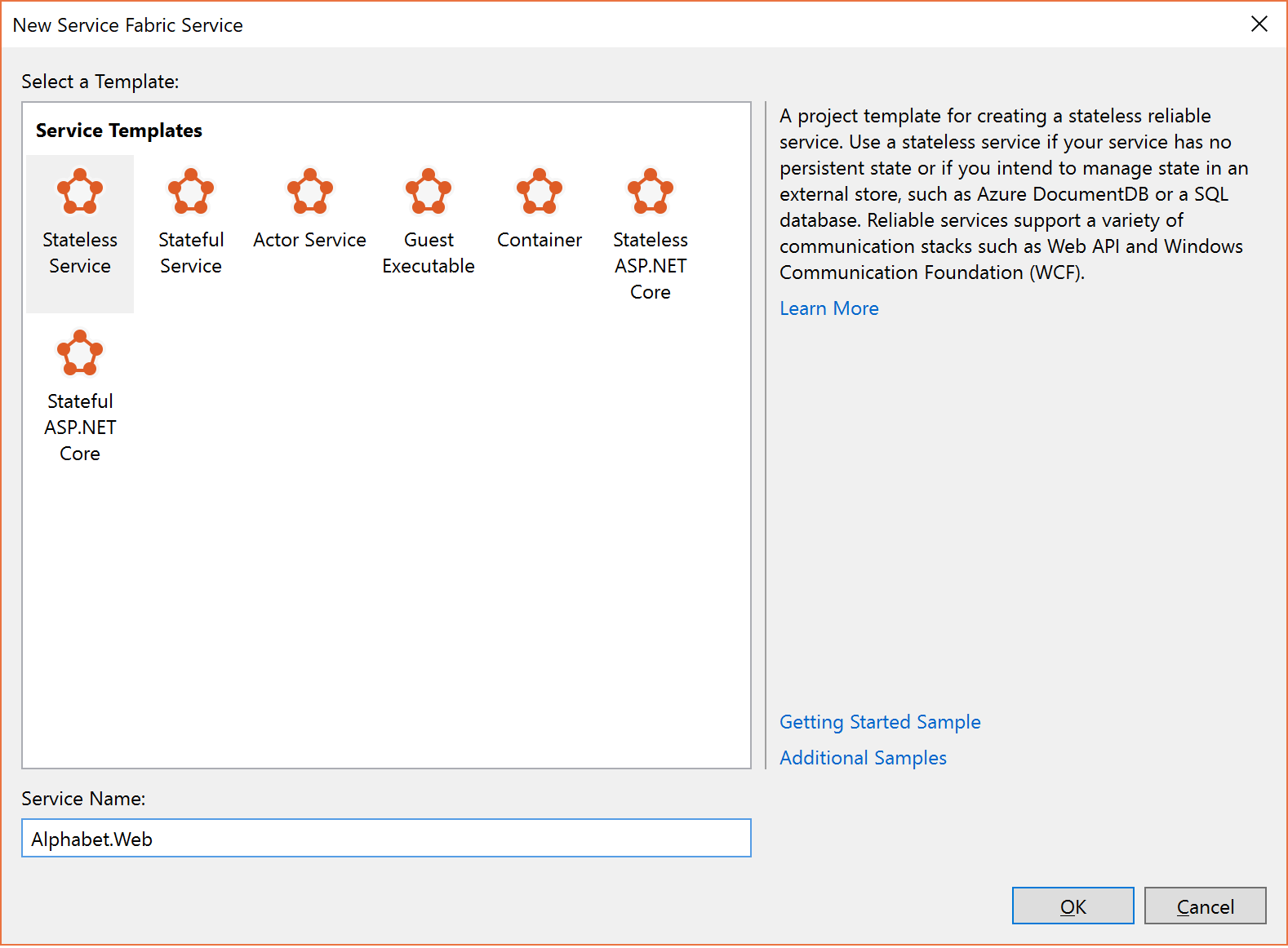 .
.Zaktualizuj informacje o punkcie końcowym w ServiceManifest.xml usługi Alphabet.WebApi, aby otworzyć port, jak pokazano poniżej.
<Endpoint Name="WebApiServiceEndpoint" Protocol="http" Port="8081"/>Musisz zwrócić kolekcję elementów ServiceInstanceListeners w klasie Web. Ponownie możesz zaimplementować prosty element HttpCommunicationListener.
protected override IEnumerable<ServiceInstanceListener> CreateServiceInstanceListeners() { return new[] {new ServiceInstanceListener(context => this.CreateInputListener(context))}; } private ICommunicationListener CreateInputListener(ServiceContext context) { // Service instance's URL is the node's IP & desired port EndpointResourceDescription inputEndpoint = context.CodePackageActivationContext.GetEndpoint("WebApiServiceEndpoint") string uriPrefix = String.Format("{0}://+:{1}/alphabetpartitions/", inputEndpoint.Protocol, inputEndpoint.Port); var uriPublished = uriPrefix.Replace("+", FabricRuntime.GetNodeContext().IPAddressOrFQDN); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInputRequest); }Teraz musisz zaimplementować logikę przetwarzania. Element HttpCommunicationListener wywołuje wywołanie
ProcessInputRequest, gdy pojawi się żądanie. Teraz dodajmy poniższy kod.private async Task ProcessInputRequest(HttpListenerContext context, CancellationToken cancelRequest) { String output = null; try { string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A'); ResolvedServicePartition partition = await this.servicePartitionResolver.ResolveAsync(alphabetServiceUri, partitionKey, cancelRequest); ResolvedServiceEndpoint ep = partition.GetEndpoint(); JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri); output = String.Format( "Result: {0}. <p>Partition key: '{1}' generated from the first letter '{2}' of input value '{3}'. <br>Processing service partition ID: {4}. <br>Processing service replica address: {5}", result, partitionKey, firstLetterOfLastName, lastname, partition.Info.Id, primaryReplicaAddress); } catch (Exception ex) { output = ex.Message; } using (var response = context.Response) { if (output != null) { output = output + "added to Partition: " + primaryReplicaAddress; byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } }Przejdźmy przez to krok po kroku. Kod odczytuje pierwszą literę parametru
lastnameciągu zapytania do znaku. Następnie określa klucz partycji dla tej litery, odejmując wartość szesnastkową od wartościAszesnastkowej pierwszej litery nazwiska.string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A');Pamiętaj, że w tym przykładzie używamy 26 partycji z jednym kluczem partycji na partycję. Następnie uzyskamy partycję
partitionusługi dla tego klucza przy użyciuResolveAsyncmetody wservicePartitionResolverobiekcie .servicePartitionResolverjest definiowany jakoprivate readonly ServicePartitionResolver servicePartitionResolver = ServicePartitionResolver.GetDefault();Metoda
ResolveAsyncprzyjmuje identyfikator URI usługi, klucz partycji i token anulowania jako parametry. Identyfikator URI usługi przetwarzania tofabric:/AlphabetPartitions/Processing. Następnie uzyskamy punkt końcowy partycji.ResolvedServiceEndpoint ep = partition.GetEndpoint()Na koniec utworzymy adres URL punktu końcowego oraz ciąg zapytania i wywołamy usługę przetwarzania.
JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri);Po zakończeniu przetwarzania zapisujemy dane wyjściowe z powrotem.
Ostatnim krokiem jest przetestowanie usługi. Program Visual Studio używa parametrów aplikacji do wdrożenia lokalnego i w chmurze. Aby przetestować usługę przy użyciu 26 partycji lokalnie, należy zaktualizować
Local.xmlplik w folderze ApplicationParameters projektu AlphabetPartitions, jak pokazano poniżej:<Parameters> <Parameter Name="Processing_PartitionCount" Value="26" /> <Parameter Name="WebApi_InstanceCount" Value="1" /> </Parameters>Po zakończeniu wdrażania możesz sprawdzić usługę i wszystkie jej partycje w narzędziu Service Fabric Explorer.
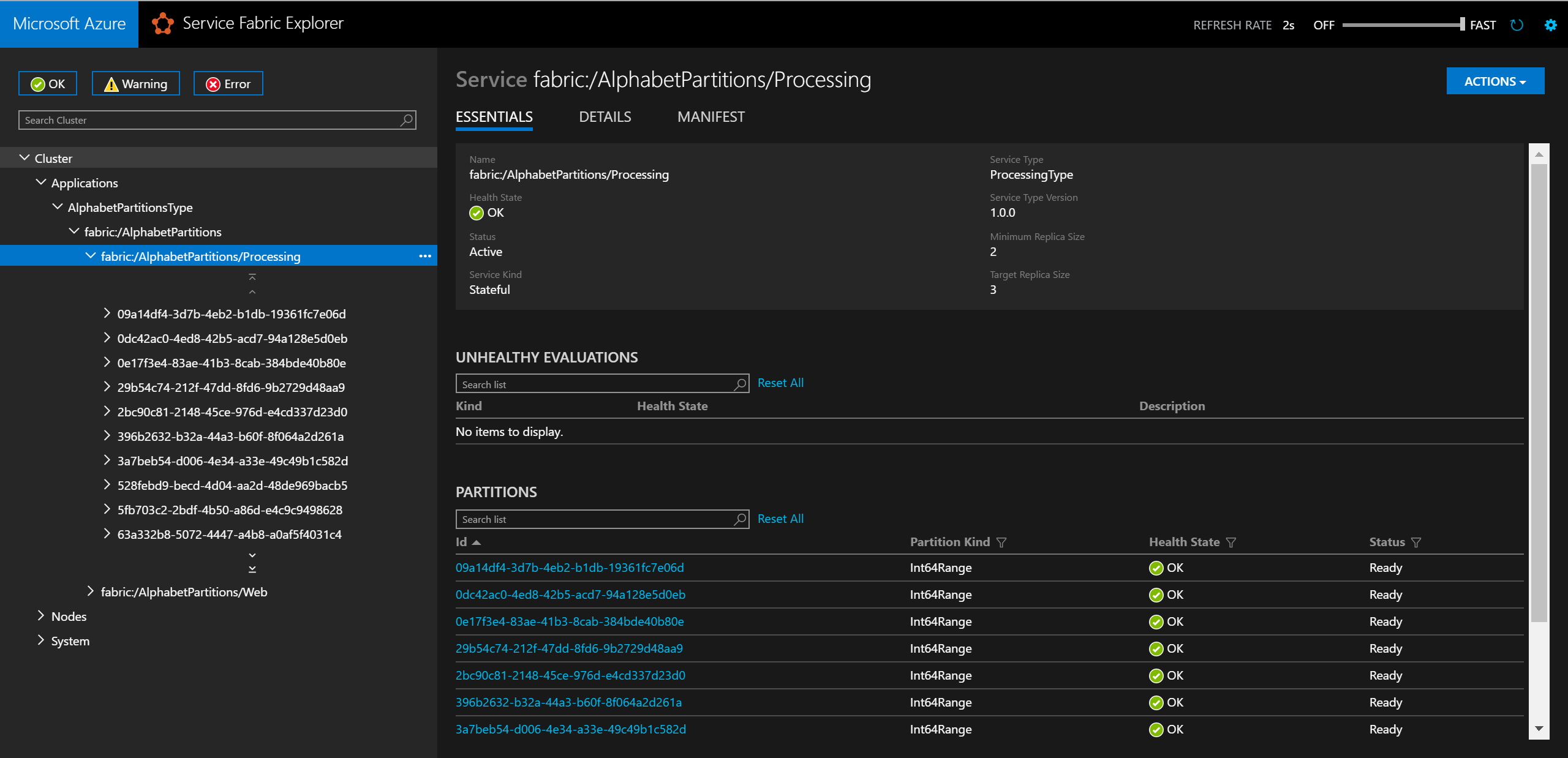
W przeglądarce można przetestować logikę partycjonowania, wprowadzając polecenie
http://localhost:8081/?lastname=somename. Zobaczysz, że każde nazwisko rozpoczynające się od tej samej litery jest przechowywane w tej samej partycji.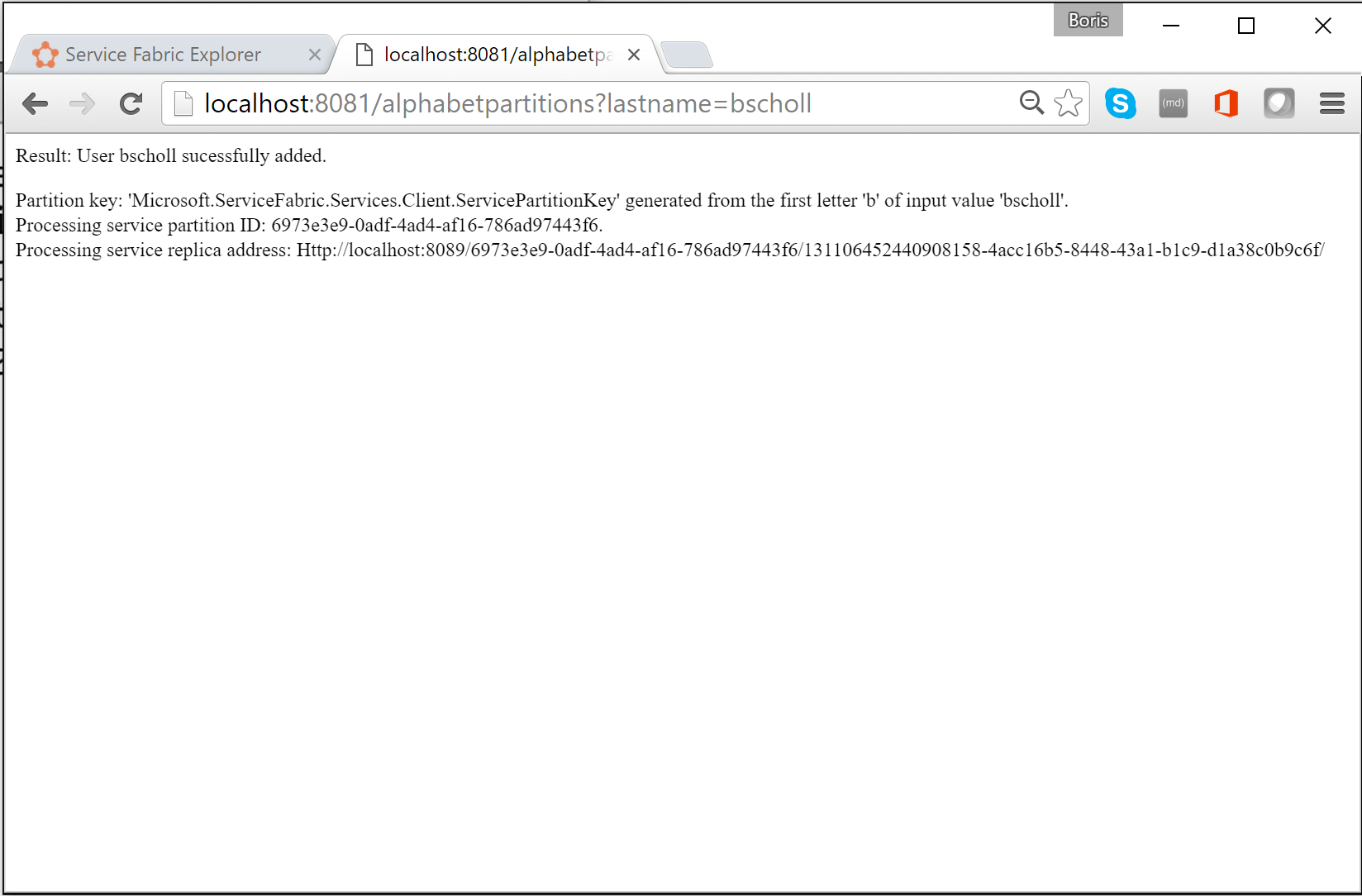
Kompletne rozwiązanie kodu używanego w tym artykule jest dostępne tutaj: https://github.com/Azure-Samples/service-fabric-dotnet-getting-started/tree/classic/Services/AlphabetPartitions.
Następne kroki
Dowiedz się więcej o usługach Service Fabric: