Skalowanie w usłudze Service Fabric
Usługa Azure Service Fabric ułatwia tworzenie skalowalnych aplikacji przez zarządzanie usługami, partycjami i replikami w węzłach klastra. Uruchamianie wielu obciążeń na tym samym sprzęcie umożliwia maksymalne wykorzystanie zasobów, ale także zapewnia elastyczność w zakresie sposobu skalowania obciążeń. W tym filmie wideo channel 9 opisano sposób tworzenia skalowalnych aplikacji mikrousług:
Skalowanie w usłudze Service Fabric odbywa się na kilka różnych sposobów:
- Skalowanie przez utworzenie lub usunięcie wystąpień usługi bezstanowej
- Skalowanie przez utworzenie lub usunięcie nowych nazwanych usług
- Skalowanie przez utworzenie lub usunięcie nowych nazwanych wystąpień aplikacji
- Skalowanie przy użyciu usług partycjonowanych
- Skalowanie przez dodawanie i usuwanie węzłów z klastra
- Skalowanie przy użyciu metryk usługi Resource Manager klastra
Skalowanie przez utworzenie lub usunięcie wystąpień usługi bezstanowej
Jednym z najprostszych sposobów skalowania w usłudze Service Fabric działa z usługami bezstanowymi. Podczas tworzenia usługi bezstanowej możesz zdefiniować element InstanceCount. InstanceCount Określa liczbę uruchomionych kopii kodu tej usługi tworzonych podczas uruchamiania usługi. Załóżmy na przykład, że w klastrze znajduje się 100 węzłów. Załóżmy również, że usługa jest tworzona z wartością InstanceCount 10. W czasie wykonywania te 10 uruchomionych kopii kodu może stać się zbyt zajęte (lub nie może być wystarczająco zajęte). Jednym ze sposobów skalowania tego obciążenia jest zmiana liczby wystąpień. Na przykład część kodu monitorowania lub zarządzania może zmienić istniejącą liczbę wystąpień na 50 lub 5, w zależności od tego, czy obciążenie musi być skalowane w poziomie lub na podstawie obciążenia.
C#:
StatelessServiceUpdateDescription updateDescription = new StatelessServiceUpdateDescription();
updateDescription.InstanceCount = 50;
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
Program PowerShell:
Update-ServiceFabricService -Stateless -ServiceName $serviceName -InstanceCount 50
Używanie liczby wystąpień dynamicznych
W szczególności w przypadku usług bezstanowych usługa Service Fabric oferuje automatyczny sposób zmiany liczby wystąpień. Dzięki temu usługa może dynamicznie skalować się z liczbą dostępnych węzłów. Sposobem wyrażenia zgody na to zachowanie jest ustawienie liczby wystąpień = -1. InstanceCount = -1 to instrukcja dla usługi Service Fabric z informacją "Uruchom tę usługę bezstanową na każdym węźle". Jeśli liczba węzłów ulegnie zmianie, usługa Service Fabric automatycznie zmieni liczbę wystąpień tak, aby odpowiadała, upewniając się, że usługa jest uruchomiona na wszystkich prawidłowych węzłach.
C#:
StatelessServiceDescription serviceDescription = new StatelessServiceDescription();
//Set other service properties necessary for creation....
serviceDescription.InstanceCount = -1;
await fc.ServiceManager.CreateServiceAsync(serviceDescription);
Program PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName -Stateless -PartitionSchemeSingleton -InstanceCount "-1"
Skalowanie przez utworzenie lub usunięcie nowych nazwanych usług
Nazwane wystąpienie usługi jest konkretnym wystąpieniem typu usługi (zobacz cykl życia aplikacji usługi Service Fabric) w ramach niektórych nazwanych wystąpień aplikacji w klastrze.
Nowe nazwane wystąpienia usługi można tworzyć (lub usuwać), ponieważ usługi stają się mniej lub bardziej zajęte. Dzięki temu żądania mogą być rozmieszczone w większej liczbie wystąpień usługi, co zwykle pozwala zmniejszyć obciążenie istniejących usług. Podczas tworzenia usług menedżer zasobów klastra usługi Service Fabric umieszcza usługi w klastrze w sposób rozproszony. Dokładne decyzje dotyczą metryk w klastrze i innych reguł umieszczania. Usługi można utworzyć na kilka różnych sposobów, ale najczęściej są to akcje administracyjne, takie jak wywołanie New-ServiceFabricServicemetody lub przez wywołanie CreateServiceAsynckodu . CreateServiceAsync można nawet wywołać z poziomu innych usług uruchomionych w klastrze.
Dynamiczne tworzenie usług może być używane w różnych scenariuszach i jest typowym wzorcem. Rozważmy na przykład stanową usługę reprezentującą określony przepływ pracy. Wywołania reprezentujące pracę będą wyświetlane w tej usłudze, a ta usługa wykona kroki dla tego przepływu pracy i zarejestruje postęp.
Jak utworzyć tę konkretną skalę usług? Usługa może być wielodostępna w jakiejś formie i akceptować wywołania i uruchamiać kroki dla wielu różnych wystąpień tego samego przepływu pracy jednocześnie. Jednak może to sprawić, że kod będzie bardziej złożony, ponieważ teraz musi martwić się o wiele różnych wystąpień tego samego przepływu pracy, na różnych etapach i od różnych klientów. Ponadto obsługa wielu przepływów pracy w tym samym czasie nie rozwiązuje problemu ze skalowaniem. Dzieje się tak, ponieważ w pewnym momencie ta usługa będzie zużywać zbyt wiele zasobów, aby zmieścić się na określonej maszynie. Wiele usług, które nie zostały utworzone dla tego wzorca w pierwszej kolejności, również doświadcza trudności ze względu na pewne nieodłączne wąskie gardło lub spowolnienie w kodzie. Te typy problemów powodują, że usługa nie działa, a także wtedy, gdy liczba współbieżnych przepływów pracy, które śledzi, jest większa.
Rozwiązaniem jest utworzenie wystąpienia tej usługi dla każdego innego wystąpienia przepływu pracy, które chcesz śledzić. Jest to doskonały wzorzec i działa niezależnie od tego, czy usługa jest bezstanowa, czy stanowa. Ten wzorzec działa zwykle w innej usłudze, która działa jako "Usługa menedżera obciążeń". Zadaniem tej usługi jest odbieranie żądań i kierowanie tych żądań do innych usług. Menedżer może dynamicznie utworzyć wystąpienie usługi obciążenia po odebraniu komunikatu, a następnie przekazać żądania do tych usług. Usługa menedżera może również odbierać wywołania zwrotne, gdy dana usługa przepływu pracy ukończy zadanie. Gdy menedżer odbiera te wywołania zwrotne, może usunąć to wystąpienie usługi przepływu pracy lub pozostawić je, jeśli oczekuje się więcej wywołań.
Zaawansowane wersje tego typu menedżera mogą nawet tworzyć pule usług, którymi zarządza. Pula pomaga zagwarantować, że gdy pojawi się nowe żądanie, nie musi czekać na uruchomienie usługi. Zamiast tego menedżer może po prostu wybrać usługę przepływu pracy, która nie jest obecnie zajęta z puli lub kierować losowo. Utrzymywanie dostępnej puli usług sprawia, że obsługa nowych żądań jest szybsza, ponieważ jest mniej prawdopodobne, że żądanie musi czekać, aż nowa usługa zostanie spun up. Tworzenie nowych usług jest szybkie, ale nie bezpłatne lub natychmiastowe. Pula pomaga zminimalizować czas oczekiwania żądania przed obsługą. Ten menedżer i wzorzec puli często są widoczne, gdy czasy odpowiedzi mają największe znaczenie. Kolejkowanie żądania i tworzenie usługi w tle, a następnie przekazywanie jej w tle jest również popularnym wzorcem menedżera, ponieważ tworzy i usuwa usługi na podstawie pewnego śledzenia ilości pracy, którą obecnie oczekuje usługa.
Skalowanie przez utworzenie lub usunięcie nowych nazwanych wystąpień aplikacji
Tworzenie i usuwanie całych wystąpień aplikacji jest podobne do wzorca tworzenia i usuwania usług. W przypadku tego wzorca istnieje usługa menedżera, która podejmuje decyzję na podstawie żądań, które widzi, oraz informacji otrzymywanych od innych usług w klastrze.
Kiedy należy utworzyć nowe nazwane wystąpienie aplikacji, zamiast tworzyć nowe nazwane wystąpienia usługi w niektórych już istniejących aplikacjach? Istnieje kilka przypadków:
- Nowe wystąpienie aplikacji jest przeznaczone dla klienta, którego kod musi działać w ramach określonych ustawień tożsamości lub zabezpieczeń.
- Usługa Service Fabric umożliwia definiowanie różnych pakietów kodu do uruchamiania w ramach określonych tożsamości. Aby uruchomić ten sam pakiet kodu w różnych tożsamościach, aktywacje muszą być wykonywane w różnych wystąpieniach aplikacji. Rozważmy przypadek, w którym wdrożono obciążenia istniejącego klienta. Mogą one działać w ramach określonej tożsamości, dzięki czemu można monitorować i kontrolować ich dostęp do innych zasobów, takich jak zdalne bazy danych lub inne systemy. W takim przypadku, gdy nowy klient zarejestruje się, prawdopodobnie nie chcesz aktywować kodu w tym samym kontekście (obszar procesu). Chociaż można, utrudnia to kodowi usługi działanie w kontekście określonej tożsamości. Zazwyczaj musisz mieć więcej zabezpieczeń, izolacji i kodu zarządzania tożsamościami. Zamiast używać różnych nazwanych wystąpień usługi w ramach tego samego wystąpienia aplikacji, a tym samym obszarem procesu, można użyć różnych wystąpień aplikacji usługi Service Fabric. Ułatwia to definiowanie różnych kontekstów tożsamości.
- Nowe wystąpienie aplikacji służy również jako środek konfiguracji
- Domyślnie wszystkie nazwane wystąpienia usługi określonego typu usługi w wystąpieniu aplikacji będą uruchamiane w tym samym procesie w danym węźle. Oznacza to, że chociaż każde wystąpienie usługi można skonfigurować inaczej, jest to skomplikowane. Usługi muszą mieć token, którego używają, aby wyszukać konfigurację w pakiecie konfiguracji. Zazwyczaj jest to tylko nazwa usługi. Działa to dobrze, ale łączy konfigurację z nazwami poszczególnych nazwanych wystąpień usługi w ramach tego wystąpienia aplikacji. Może to być mylące i trudne do zarządzania, ponieważ konfiguracja jest zwykle artefaktem czasu projektowania z określonymi wartościami wystąpienia aplikacji. Tworzenie większej liczby usług zawsze oznacza więcej uaktualnień aplikacji, aby zmienić informacje w pakietach konfiguracji lub wdrożyć nowe, aby nowe usługi mogły wyszukać określone informacje. Często łatwiej jest utworzyć zupełnie nowe nazwane wystąpienie aplikacji. Następnie możesz użyć parametrów aplikacji, aby ustawić dowolną konfigurację niezbędną dla usług. Dzięki temu wszystkie usługi utworzone w ramach tego nazwanego wystąpienia aplikacji mogą dziedziczyć określone ustawienia konfiguracji. Na przykład zamiast mieć jeden plik konfiguracji z ustawieniami i dostosowaniami dla każdego klienta, takich jak wpisy tajne lub limity zasobów klienta, zamiast tego będziesz mieć inne wystąpienie aplikacji dla każdego klienta z tymi ustawieniami zastąpionymi.
- Nowa aplikacja służy jako granica uaktualniania
- W usłudze Service Fabric różne nazwane wystąpienia aplikacji służą jako granice uaktualniania. Uaktualnienie jednego nazwanego wystąpienia aplikacji nie będzie miało wpływu na kod uruchomiony przez inne nazwane wystąpienie aplikacji. Różne aplikacje będą uruchamiać różne wersje tego samego kodu w tych samych węzłach. Może to być czynnikiem, gdy trzeba podjąć decyzję o skalowaniu, ponieważ możesz wybrać, czy nowy kod powinien być zgodny z tymi samymi uaktualnieniami co inna usługa, czy nie. Załóżmy na przykład, że wywołanie przychodzi do usługi menedżera, która jest odpowiedzialna za skalowanie obciążeń określonego klienta przez dynamiczne tworzenie i usuwanie usług. W tym przypadku jednak wywołanie dotyczy obciążenia skojarzonego z nowym klientem. Większość klientów, takich jak odizolowanie się od siebie, nie tylko ze względów zabezpieczeń i konfiguracji wymienionych wcześniej, ale dlatego, że zapewnia większą elastyczność w zakresie uruchamiania określonych wersji oprogramowania i wybierania po uaktualnieniu. Możesz również utworzyć nowe wystąpienie aplikacji i utworzyć tam usługę po prostu, aby jeszcze bardziej podzielić ilość usług, którą będzie dotykać każde uaktualnienie. Oddzielne wystąpienia aplikacji zapewniają większy stopień szczegółowości podczas uaktualniania aplikacji, a także umożliwiają testowanie A/B i wdrożenia Blue/Green.
- Istniejące wystąpienie aplikacji jest pełne
- W usłudze Service Fabric pojemność aplikacji jest koncepcją, której można użyć do kontrolowania ilości zasobów dostępnych dla określonych wystąpień aplikacji. Na przykład możesz zdecydować, że dana usługa musi mieć utworzone inne wystąpienie w celu skalowania. Jednak to wystąpienie aplikacji nie ma pojemności dla określonej metryki. Jeśli dany klient lub obciążenie nadal powinny otrzymać więcej zasobów, możesz zwiększyć istniejącą pojemność dla tej aplikacji lub utworzyć nową aplikację.
Skalowanie na poziomie partycji
Usługa Service Fabric obsługuje partycjonowanie. Partycjonowanie dzieli usługę na kilka sekcji logicznych i fizycznych, z których każda działa niezależnie. Jest to przydatne w przypadku usług stanowych, ponieważ żaden zestaw replik nie musi obsługiwać wszystkich wywołań i manipulować wszystkim stanem jednocześnie. Omówienie partycjonowania zawiera informacje na temat typów obsługiwanych schematów partycjonowania. Repliki każdej partycji są rozłożone na węzły w klastrze, dystrybuując obciążenie tej usługi i zapewniając, że żadna usługa jako całość ani żadna partycja nie ma jednego punktu awarii.
Rozważ usługę, która używa schematu partycjonowania z zakresem z niskim kluczem 0, kluczem wysokim 99 i liczbą partycji 4. W klastrze z trzema węzłami usługa może zostać ułożona z czterema replikami, które współużytkować zasoby w każdym węźle, jak pokazano poniżej:
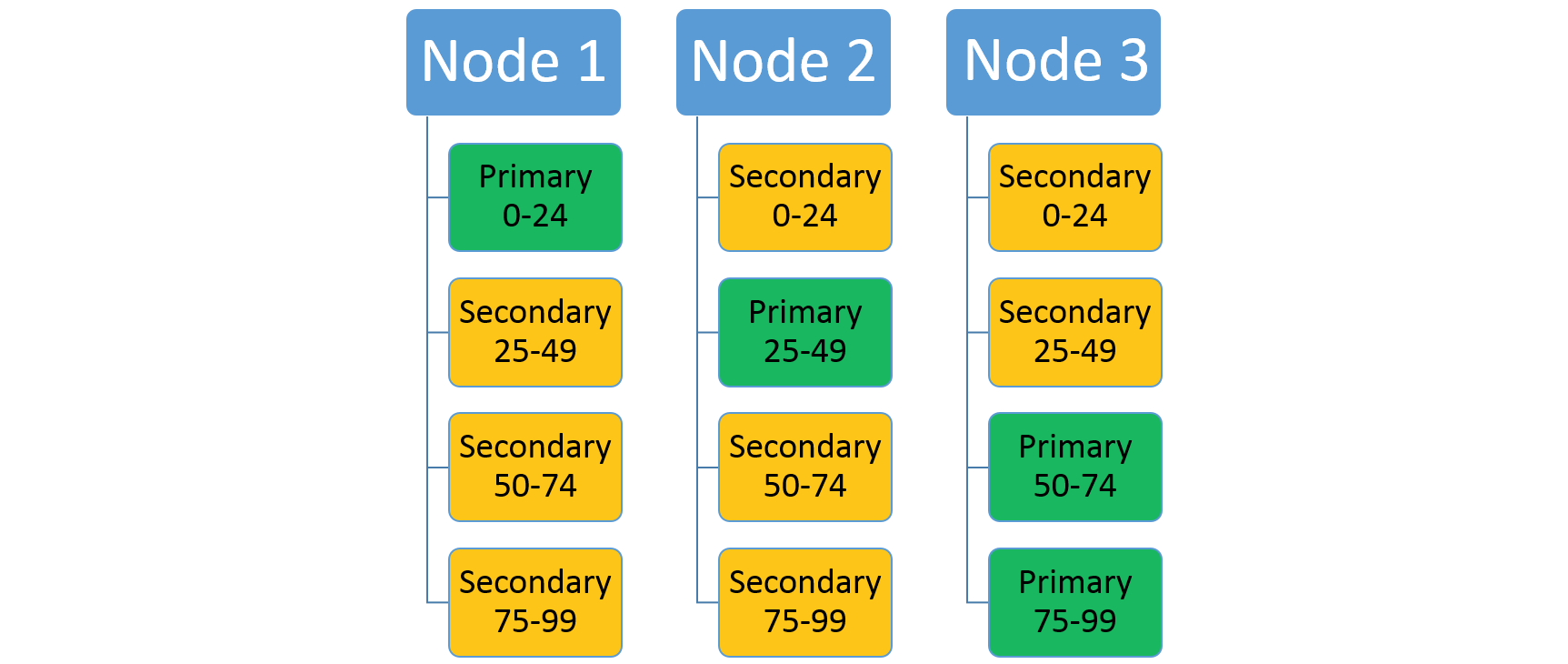
Jeśli zwiększysz liczbę węzłów, usługa Service Fabric przeniesie tam niektóre z istniejących replik. Załóżmy na przykład, że liczba węzłów zwiększa się do czterech, a repliki są redystrybuowane. Teraz usługa ma teraz trzy repliki uruchomione w każdym węźle, z których każda należy do różnych partycji. Umożliwia to lepsze wykorzystanie zasobów, ponieważ nowy węzeł nie jest zimny. Zazwyczaj zwiększa również wydajność, ponieważ każda usługa ma więcej dostępnych zasobów.
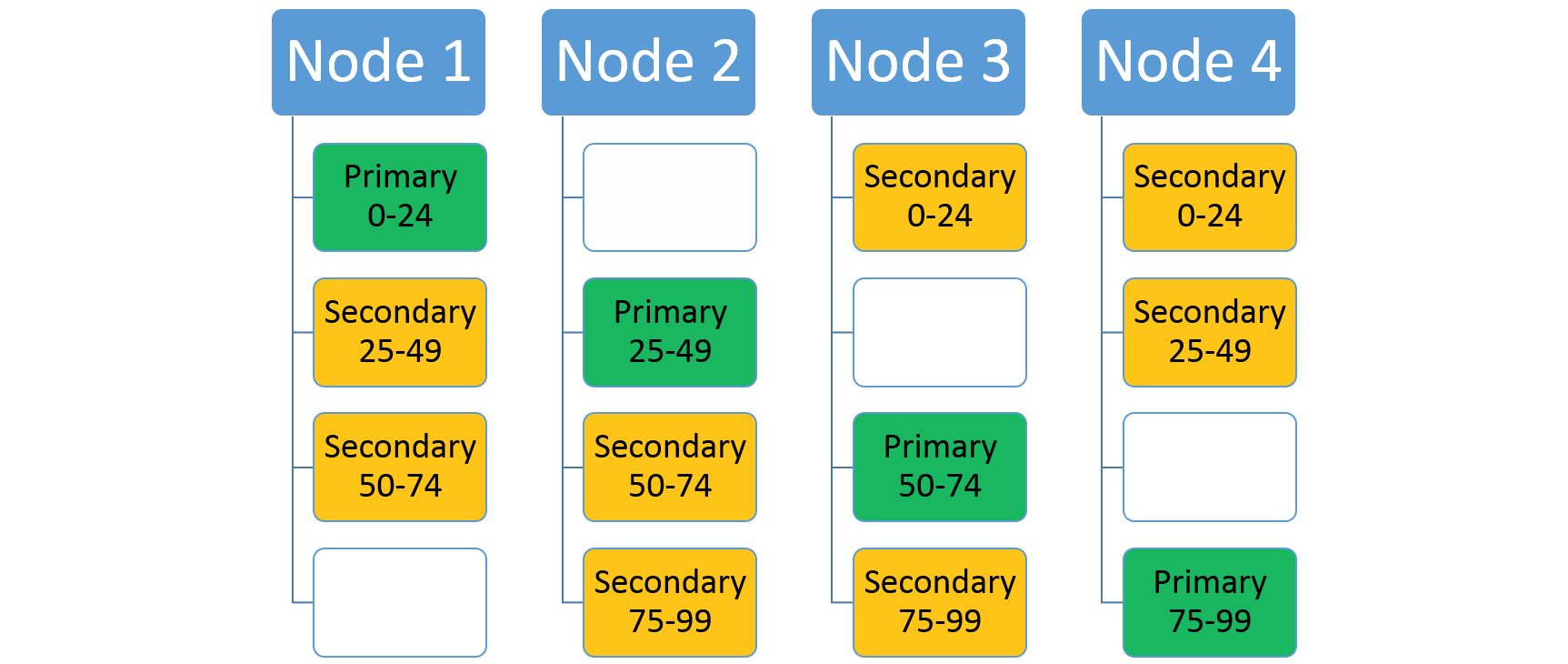
Skalowanie przy użyciu menedżera zasobów klastra usługi Service Fabric i metryk
Metryki to sposób wyrażania użycia zasobów przez usługi Service Fabric. Użycie metryk daje usłudze Resource Manager klastra możliwość reorganizacji i zoptymalizowania układu klastra. Na przykład w klastrze może istnieć wiele zasobów, ale mogą nie zostać przydzielone do usług, które obecnie wykonują pracę. Użycie metryk umożliwia usłudze Resource Manager klastra reorganizację klastra w celu zapewnienia, że usługi mają dostęp do dostępnych zasobów.
Skalowanie przez dodawanie i usuwanie węzłów z klastra
Inną opcją skalowania za pomocą usługi Service Fabric jest zmiana rozmiaru klastra. Zmiana rozmiaru klastra oznacza dodawanie lub usuwanie węzłów dla co najmniej jednego typu węzłów w klastrze. Rozważmy na przykład przypadek, w którym wszystkie węzły w klastrze są gorące. Oznacza to, że zasoby klastra są prawie wszystkie używane. W takim przypadku dodanie większej liczby węzłów do klastra jest najlepszym sposobem skalowania. Po dołączeniu nowych węzłów do klastra menedżer zasobów klastra usługi Service Fabric przenosi do nich usługi, co powoduje mniejsze całkowite obciążenie istniejących węzłów. W przypadku usług bezstanowych z liczbą wystąpień = -1 tworzone jest automatycznie więcej wystąpień usługi. Dzięki temu niektóre wywołania mogą przechodzić z istniejących węzłów do nowych węzłów.
Aby uzyskać więcej informacji, zobacz Skalowanie klastra.
Wybieranie platformy
Ze względu na różnice implementacji między systemami operacyjnymi wybranie usługi Service Fabric z systemem Windows lub Linux może być istotną częścią skalowania aplikacji. Jedną z potencjalnych barier jest sposób wykonywania rejestrowania etapowego. Usługa Service Fabric w systemie Windows używa sterownika jądra dla dziennika jeden na maszynę współużytkowanego między replikami usługi stanowej. Ten dziennik waży około 8 GB. Z drugiej strony system Linux używa dziennika przejściowego o wartości 256 MB dla każdej repliki, co czyni go mniej idealnym rozwiązaniem dla aplikacji, które chcą zmaksymalizować liczbę lekkich replik usług uruchomionych w danym węźle. Te różnice w wymaganiach dotyczących magazynu tymczasowego mogą potencjalnie poinformować żądaną platformę wdrożenia klastra usługi Service Fabric.
Zebranie wszystkich elementów
Przyjrzyjmy się wszystkim pomysłom, które omówiliśmy tutaj, i porozmawiajmy za pomocą przykładu. Rozważmy następującą usługę: próbujesz utworzyć usługę, która działa jako książka adresowa, trzymając się nazw i informacji kontaktowych.
Z góry masz kilka pytań związanych ze skalowaniem: Ilu użytkowników masz? Ile kontaktów będzie przechowywać każdy użytkownik? Próba uzyskania tego wszystkiego, gdy staniesz w obronie usługi po raz pierwszy, jest trudna. Załóżmy, że zamierzasz korzystać z jednej usługi statycznej z określoną liczbą partycji. Konsekwencje wybrania nieprawidłowej liczby partycji mogą spowodować problemy ze skalowaniem później. Podobnie, nawet jeśli wybierzesz odpowiednią liczbę, możesz nie mieć wszystkich potrzebnych informacji. Na przykład należy również zdecydować o rozmiarze klastra z góry, zarówno pod względem liczby węzłów, jak i ich rozmiarów. Zwykle trudno jest przewidzieć, ile zasobów usługa będzie zużywać w całym okresie istnienia. Trudno jest również znać wcześniej wzorzec ruchu, który faktycznie widzi usługa. Na przykład może ludzie dodają i usuwają swoje kontakty tylko w godzinach porannych, a może są dystrybuowane równomiernie w ciągu dnia. W oparciu o to może być konieczne skalowanie w poziomie i w sposób dynamiczny. Być może możesz nauczyć się przewidywać, kiedy trzeba będzie skalować w poziomie i w poziomie, ale prawdopodobnie trzeba będzie reagować na zmieniające się użycie zasobów przez usługę. Może to obejmować zmianę rozmiaru klastra w celu zapewnienia większej ilości zasobów podczas reorganizacji istniejących zasobów nie wystarczy.
Ale dlaczego nawet spróbować wybrać pojedynczy schemat partycji dla wszystkich użytkowników? Dlaczego ogranicz siebie do jednej usługi i jednego klastra statycznego? Rzeczywista sytuacja jest zwykle bardziej dynamiczna.
Podczas kompilowania na potrzeby skalowania należy wziąć pod uwagę następujący wzorzec dynamiczny. Może być konieczne dostosowanie go do swojej sytuacji:
- Zamiast próbować wybrać schemat partycjonowania dla wszystkich z góry, utwórz "usługę menedżera".
- Zadaniem usługi menedżera jest zapoznanie się z informacjami o klientach podczas tworzenia konta usługi. Następnie w zależności od tych informacji usługa menedżera tworzy wystąpienie rzeczywistej usługi contact-storage tylko dla tego klienta. Jeśli wymagają one określonej konfiguracji, izolacji lub uaktualnień, możesz również zdecydować się na uruchomienie wystąpienia aplikacji dla tego klienta.
Ten wzorzec tworzenia dynamicznego ma wiele korzyści:
- Nie próbujesz odgadnąć poprawnej liczby partycji dla wszystkich użytkowników z góry lub utworzyć pojedynczą usługę, która jest nieskończenie skalowalna samodzielnie.
- Różni użytkownicy nie muszą mieć tej samej liczby partycji, liczby replik, ograniczeń umieszczania, metryk, obciążeń domyślnych, nazw usług, ustawień dns lub innych właściwości określonych na poziomie usługi lub aplikacji.
- Zyskujesz dodatkową segmentację danych. Każdy klient ma własną kopię usługi
- Każda obsługa klienta może być skonfigurowana inaczej i udzielać więcej lub mniej zasobów, z większą lub mniejszą liczbą partycji lub replik zgodnie z potrzebami w zależności od ich oczekiwanej skali.
- Załóżmy na przykład, że klient zapłacił za warstwę "Gold" — może uzyskać więcej replik lub większą liczbę partycji oraz potencjalnie zasoby przeznaczone dla swoich usług za pośrednictwem metryk i pojemności aplikacji.
- Albo mówią, że dostarczyli informacje wskazujące liczbę potrzebnych kontaktów: "Mały" - otrzymają tylko kilka partycji, a nawet mogą zostać umieszczone w udostępnionej puli usług innym klientom.
- Każda obsługa klienta może być skonfigurowana inaczej i udzielać więcej lub mniej zasobów, z większą lub mniejszą liczbą partycji lub replik zgodnie z potrzebami w zależności od ich oczekiwanej skali.
- Nie uruchamiasz wielu wystąpień usługi ani replik, gdy czekasz, aż klienci pojawią się
- Jeśli klient kiedykolwiek opuści usługę, usunięcie ich informacji z usługi jest tak proste, jak usunięcie przez niego utworzonej usługi lub aplikacji przez menedżera.
Następne kroki
Aby uzyskać więcej informacji na temat pojęć związanych z usługą Service Fabric, zobacz następujące artykuły: