Agregacja i zbieranie zdarzeń przy użyciu Diagnostyka Azure systemu Windows
Podczas uruchamiania klastra usługi Azure Service Fabric warto zebrać dzienniki ze wszystkich węzłów w centralnej lokalizacji. Posiadanie dzienników w centralnej lokalizacji ułatwia analizowanie i rozwiązywanie problemów w klastrze lub problemów z aplikacjami i usługami uruchomionymi w tym klastrze.
Jednym ze sposobów przekazywania i zbierania dzienników jest użycie rozszerzenia windows Diagnostyka Azure (WAD), które przekazuje dzienniki do usługi Azure Storage, a także ma możliwość wysyłania dzienników do usługi aplikacja systemu Azure Insights lub Event Hubs. Możesz również użyć procesu zewnętrznego, aby odczytać zdarzenia z magazynu i umieścić je w produkcie platformy analizy, takim jak dzienniki usługi Azure Monitor lub inne rozwiązanie do analizowania dzienników.
Uwaga
Do interakcji z platformą Azure zalecamy używanie modułu Azure Az w programie PowerShell. Aby rozpocząć, zobacz Instalowanie programu Azure PowerShell. Aby dowiedzieć się, jak przeprowadzić migrację do modułu Az PowerShell, zobacz Migracja programu Azure PowerShell z modułu AzureRM do modułu Az.
Wymagania wstępne
W tym artykule są używane następujące narzędzia:
Zdarzenia platformy Service Fabric
Usługa Service Fabric konfiguruje kilka gotowych kanałów rejestrowania, z których następujące kanały są wstępnie skonfigurowane za pomocą rozszerzenia w celu wysyłania danych monitorowania i diagnostyki do tabeli magazynu lub gdzie indziej:
- Zdarzenia operacyjne: operacje wyższego poziomu wykonywane przez platformę usługi Service Fabric. Przykłady obejmują tworzenie aplikacji i usług, zmiany stanu węzła i informacje o uaktualnianiu. Są one emitowane jako dzienniki śledzenia zdarzeń systemu Windows (ETW)
- Zdarzenia modelu programowania Reliable Actors
- Zdarzenia modelu programowania usług Reliable Services
Wdrażanie rozszerzenia diagnostyki za pośrednictwem portalu
Pierwszym krokiem zbierania dzienników jest wdrożenie rozszerzenia diagnostyki w węzłach zestawu skalowania maszyn wirtualnych w klastrze usługi Service Fabric. Rozszerzenie Diagnostyka zbiera dzienniki na każdej maszynie wirtualnej i przekazuje je do określonego konta magazynu. W poniższych krokach opisano, jak to zrobić dla nowych i istniejących klastrów za pośrednictwem witryny Azure Portal i szablonów usługi Azure Resource Manager.
Wdrażanie rozszerzenia diagnostyki w ramach tworzenia klastra za pośrednictwem witryny Azure Portal
Podczas tworzenia klastra w kroku konfiguracji klastra rozwiń opcjonalne ustawienia i upewnij się, że opcja Diagnostyka jest ustawiona na Wł . (ustawienie domyślne).
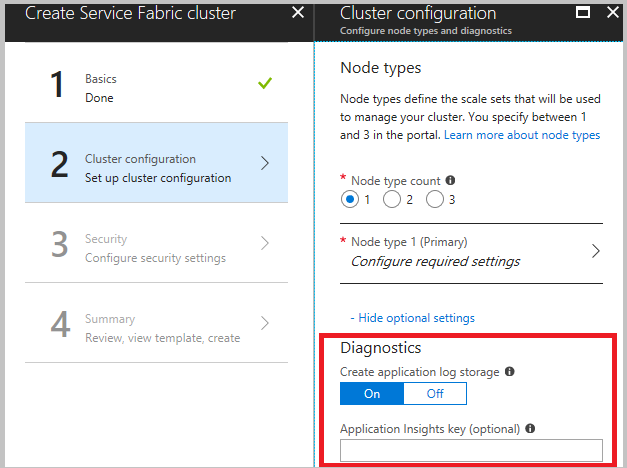
Zdecydowanie zalecamy pobranie szablonu przed kliknięciem przycisku Utwórz w ostatnim kroku. Aby uzyskać szczegółowe informacje, zobacz Konfigurowanie klastra usługi Service Fabric przy użyciu szablonu usługi Azure Resource Manager. Aby zbierać dane, musisz wprowadzić zmiany w kanałach (wymienionych powyżej).
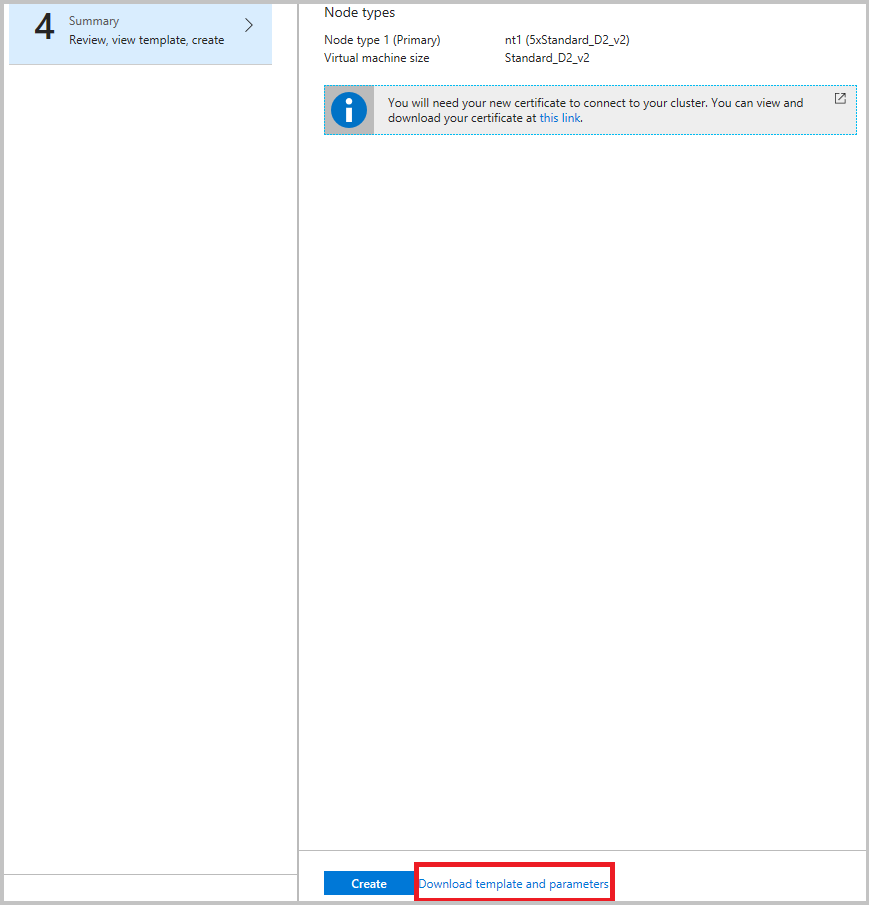
Teraz, gdy agregujesz zdarzenia w usłudze Azure Storage, skonfiguruj dzienniki usługi Azure Monitor, aby uzyskać szczegółowe informacje i wykonywać zapytania w portalu dzienników usługi Azure Monitor
Uwaga
Obecnie nie ma możliwości filtrowania ani pielęgnacji zdarzeń wysyłanych do tabel. Jeśli nie zaimplementujesz procesu usuwania zdarzeń z tabeli, tabela będzie nadal rosła (domyślny limit to 50 GB). Instrukcje dotyczące sposobu zmiany tego rozwiązania znajdują się poniżej w tym artykule. Ponadto istnieje przykład usługi pielęgnacji danych uruchomionej w przykładzie Watchdog i zaleca się napisanie jednego dla siebie, chyba że istnieje dobry powód, aby przechowywać dzienniki poza przedziałem czasu 30 lub 90 dni.
Wdrażanie rozszerzenia diagnostyki za pomocą usługi Azure Resource Manager
Tworzenie klastra z rozszerzeniem diagnostycznym
Aby utworzyć klaster przy użyciu usługi Resource Manager, należy dodać kod JSON konfiguracji diagnostyki do pełnego szablonu usługi Resource Manager. Udostępniamy szablon usługi Resource Manager dla klastra z pięcioma maszynami wirtualnymi z dodaną konfiguracją diagnostyki w ramach przykładów szablonów usługi Resource Manager. Tę lokalizację można zobaczyć w galerii Przykładów platformy Azure: klaster z pięcioma węzłami z przykładowym szablonem usługi Diagnostics Resource Manager.
Aby wyświetlić ustawienie Diagnostyka w szablonie usługi Resource Manager, otwórz plik azuredeploy.json i wyszukaj ciąg IaaSDiagnostics. Aby utworzyć klaster przy użyciu tego szablonu, wybierz przycisk Wdróż na platformie Azure dostępny pod poprzednim linkiem.
Alternatywnie możesz pobrać przykład usługi Resource Manager, wprowadzić w nim zmiany i utworzyć klaster przy użyciu zmodyfikowanego szablonu przy użyciu New-AzResourceGroupDeployment polecenia w oknie programu Azure PowerShell. Zobacz następujący kod parametrów przekazywanych do polecenia. Aby uzyskać szczegółowe informacje na temat wdrażania grupy zasobów przy użyciu programu PowerShell, zobacz artykuł Deploy a resource group with the Azure Resource Manager template (Wdrażanie grupy zasobów przy użyciu szablonu usługi Azure Resource Manager).
Dodawanie rozszerzenia diagnostyki do istniejącego klastra
Jeśli masz istniejący klaster, który nie ma wdrożonej diagnostyki, możesz dodać go lub zaktualizować za pomocą szablonu klastra. Zmodyfikuj szablon usługi Resource Manager użyty do utworzenia istniejącego klastra lub pobierz szablon z portalu zgodnie z wcześniejszym opisem. Zmodyfikuj plik template.json, wykonując następujące zadania:
Dodaj nowy zasób magazynu do szablonu, dodając go do sekcji zasobów.
{
"apiVersion": "2018-07-01",
"type": "Microsoft.Storage/storageAccounts",
"name": "[parameters('applicationDiagnosticsStorageAccountName')]",
"location": "[parameters('computeLocation')]",
"sku": {
"name": "[parameters('applicationDiagnosticsStorageAccountType')]"
"tier": "standard"
},
"tags": {
"resourceType": "Service Fabric",
"clusterName": "[parameters('clusterName')]"
}
},
Następnie dodaj do sekcji parameters tuż po definicjach konta magazynu między supportLogStorageAccountName. Zastąp symbol zastępczy nazwą tekstowego konta magazynu, które ma być nazwa konta magazynu, które chcesz.
"applicationDiagnosticsStorageAccountType": {
"type": "string",
"allowedValues": [
"Standard_LRS",
"Standard_GRS"
],
"defaultValue": "Standard_LRS",
"metadata": {
"description": "Replication option for the application diagnostics storage account"
}
},
"applicationDiagnosticsStorageAccountName": {
"type": "string",
"defaultValue": "**STORAGE ACCOUNT NAME GOES HERE**",
"metadata": {
"description": "Name for the storage account that contains application diagnostics data from the cluster"
}
},
Następnie zaktualizuj sekcję VirtualMachineProfile pliku template.json, dodając następujący kod w tablicy rozszerzeń. Pamiętaj, aby dodać przecinek na początku lub na końcu, w zależności od tego, gdzie jest wstawiony.
{
"name": "[concat(parameters('vmNodeType0Name'),'_Microsoft.Insights.VMDiagnosticsSettings')]",
"properties": {
"type": "IaaSDiagnostics",
"autoUpgradeMinorVersion": true,
"protectedSettings": {
"storageAccountName": "[parameters('applicationDiagnosticsStorageAccountName')]",
"storageAccountKey": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', parameters('applicationDiagnosticsStorageAccountName')),'2015-05-01-preview').key1]",
"storageAccountEndPoint": "https://core.windows.net/"
},
"publisher": "Microsoft.Azure.Diagnostics",
"settings": {
"WadCfg": {
"DiagnosticMonitorConfiguration": {
"overallQuotaInMB": "50000",
"EtwProviders": {
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
{
"provider": "Microsoft-ServiceFabric-Services",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableServiceEventTable"
}
}
],
"EtwManifestProviderConfiguration": [
{
"provider": "cbd93bc2-71e5-4566-b3a7-595d8eeca6e8",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
},
{
"provider": "02d06793-efeb-48c8-8f7f-09713309a810",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
}
]
}
}
},
"StorageAccount": "[parameters('applicationDiagnosticsStorageAccountName')]"
},
"typeHandlerVersion": "1.5"
}
}
Po zmodyfikowaniu pliku template.json zgodnie z opisem ponownie opublikuj szablon usługi Resource Manager. Jeśli szablon został wyeksportowany, uruchomienie pliku deploy.ps1 ponownie publikuje szablon. Po wdrożeniu upewnij się, że wartość ProvisioningState to Powodzenie.
Napiwek
Jeśli zamierzasz wdrożyć kontenery w klastrze, włącz funkcję WAD, aby pobrać statystyki platformy Docker, dodając je do sekcji WadCfg > DiagnosticMonitorConfiguration .
"DockerSources": {
"Stats": {
"enabled": true,
"sampleRate": "PT1M"
}
},
Aktualizowanie limitu przydziału magazynu
Ponieważ tabele wypełniane przez rozszerzenie rosną do momentu przekroczenia limitu przydziału, warto rozważyć zmniejszenie rozmiaru przydziału. Wartość domyślna to 50 GB i można go skonfigurować w szablonie w overallQuotaInMB polu w obszarze DiagnosticMonitorConfiguration
"overallQuotaInMB": "50000",
Konfiguracje zbierania dzienników
Dzienniki z dodatkowych kanałów są również dostępne dla kolekcji. Poniżej przedstawiono niektóre z najpopularniejszych konfiguracji, które można wykonać w szablonie dla klastrów działających na platformie Azure.
Kanał operacyjny — podstawa: domyślnie włączone operacje wysokiego poziomu wykonywane przez usługę Service Fabric i klaster, w tym zdarzenia dla węzła, wdrażana nowa aplikacja lub wycofywanie uaktualnienia itp. Aby uzyskać listę zdarzeń, zobacz Zdarzenia kanału operacyjnego.
"scheduledTransferKeywordFilter": "4611686018427387904"Kanał operacyjny — szczegółowe informacje: obejmuje to raporty o kondycji i decyzje dotyczące równoważenia obciążenia oraz wszystkie elementy w podstawowym kanale operacyjnym. Te zdarzenia są generowane przez system lub kod przy użyciu interfejsów API kondycji lub raportowania obciążenia, takich jak ReportPartitionHealth lub ReportLoad. Aby wyświetlić te zdarzenia w Podgląd zdarzeń diagnostycznych programu Visual Studio, dodaj do listy dostawców ETW "Microsoft-ServiceFabric:4:0x4000000000000008".
"scheduledTransferKeywordFilter": "4611686018427387912"Kanał obsługi danych i komunikatów — podstawa: dzienniki krytyczne i zdarzenia generowane w komunikatach (obecnie tylko ReverseProxy) i ścieżka danych oprócz szczegółowych dzienników kanału operacyjnego. Te zdarzenia to błędy przetwarzania żądań i inne krytyczne problemy w usłudze ReverseProxy, a także przetworzone żądania. Jest to nasze zalecenie dotyczące kompleksowego rejestrowania. Aby wyświetlić te zdarzenia w Podgląd zdarzeń diagnostycznym programu Visual Studio, dodaj do listy dostawców ETW "Microsoft-ServiceFabric:4:0x4000000000000010".
"scheduledTransferKeywordFilter": "4611686018427387928"Kanał obsługi danych i wiadomości — szczegółowy: pełny kanał zawierający wszystkie niekrytyczne dzienniki z danych i komunikatów w klastrze oraz szczegółowy kanał operacyjny. Aby uzyskać szczegółowe informacje na temat rozwiązywania problemów ze wszystkimi zdarzeniami zwrotnego serwera proxy, zapoznaj się z przewodnikiem diagnostyki zwrotnego serwera proxy. Aby wyświetlić te zdarzenia w podglądzie zdarzeń diagnostycznych programu Visual Studio, dodaj do listy dostawców ETW pozycję "Microsoft-ServiceFabric:4:0x4000000000000020".
"scheduledTransferKeywordFilter": "4611686018427387944"
Uwaga
Ten kanał ma bardzo dużą liczbę zdarzeń, umożliwiając zbieranie zdarzeń z tego szczegółowego kanału w wyniku szybkiego generowania wielu śladów i może zużywać pojemność magazynu. Włącz to tylko wtedy, gdy jest to absolutnie konieczne.
Aby włączyć podstawowy kanał operacyjny, zalecamy kompleksowe rejestrowanie z najmniejszą ilością szumu, element EtwManifestProviderConfiguration w WadCfg szablonie wygląda następująco:
"WadCfg": {
"DiagnosticMonitorConfiguration": {
"overallQuotaInMB": "50000",
"EtwProviders": {
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
{
"provider": "Microsoft-ServiceFabric-Services",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableServiceEventTable"
}
}
],
"EtwManifestProviderConfiguration": [
{
"provider": "cbd93bc2-71e5-4566-b3a7-595d8eeca6e8",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
},
{
"provider": "02d06793-efeb-48c8-8f7f-09713309a810",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
}
]
}
}
},
Zbieranie z nowych kanałów usługi EventSource
Aby zaktualizować diagnostykę w celu zbierania dzienników z nowych kanałów usługi EventSource reprezentujących nową aplikację, którą chcesz wdrożyć, wykonaj te same kroki, co wcześniej opisane podczas konfigurowania diagnostyki dla istniejącego klastra.
Zaktualizuj sekcję EtwEventSourceProviderConfiguration w pliku template.json, aby dodać wpisy dla nowych kanałów EventSource przed zastosowaniem aktualizacji konfiguracji za pomocą New-AzResourceGroupDeployment polecenia programu PowerShell. Nazwa źródła zdarzeń jest definiowana jako część kodu w pliku ServiceEventSource.cs wygenerowanym przez program Visual Studio.
Jeśli na przykład źródło zdarzeń ma nazwę My-Eventsource, dodaj następujący kod, aby umieścić zdarzenia z elementu My-Eventsource w tabeli o nazwie MyDestinationTableName.
{
"provider": "My-Eventsource",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "MyDestinationTableName"
}
}
Aby zbierać liczniki wydajności lub dzienniki zdarzeń, zmodyfikuj szablon usługi Resource Manager, korzystając z przykładów podanych w temacie Tworzenie maszyny wirtualnej z systemem Windows z monitorowaniem i diagnostyką przy użyciu szablonu usługi Azure Resource Manager. Następnie ponownie opublikuj szablon usługi Resource Manager.
Zbieranie liczników wydajności
Aby zebrać metryki wydajności z klastra, dodaj liczniki wydajności do elementu "WadCfg > DiagnosticMonitorConfiguration" w szablonie usługi Resource Manager dla klastra. Zobacz Monitorowanie wydajności za pomocą wad , aby uzyskać instrukcje dotyczące modyfikowania WadCfg w celu zbierania określonych liczników wydajności. Dokumentacja metryk wydajności zawiera listę liczników wydajności, które zalecamy zebrać.
Jeśli używasz ujścia usługi Application Insights, zgodnie z opisem w poniższej sekcji i chcesz, aby te metryki były wyświetlane w usłudze Application Insights, pamiętaj, aby dodać nazwę ujścia w sekcji "ujścia", jak pokazano powyżej. Spowoduje to automatyczne wysłanie liczników wydajności, które są indywidualnie skonfigurowane do zasobu usługi Application Insights.
Wysyłanie dzienników do usługi Application Insights
Konfigurowanie usługi Application Insights przy użyciu wad
Uwaga
Dotyczy to tylko klastrów systemu Windows w tej chwili.
Istnieją dwa podstawowe sposoby wysyłania danych z usługi WAD do usługi aplikacja systemu Azure Insights, która jest osiągana przez dodanie ujścia usługi Application Insights do konfiguracji wad za pośrednictwem witryny Azure Portal lub szablonu usługi Azure Resource Manager.
Dodawanie klucza instrumentacji usługi Application Insights podczas tworzenia klastra w witrynie Azure Portal
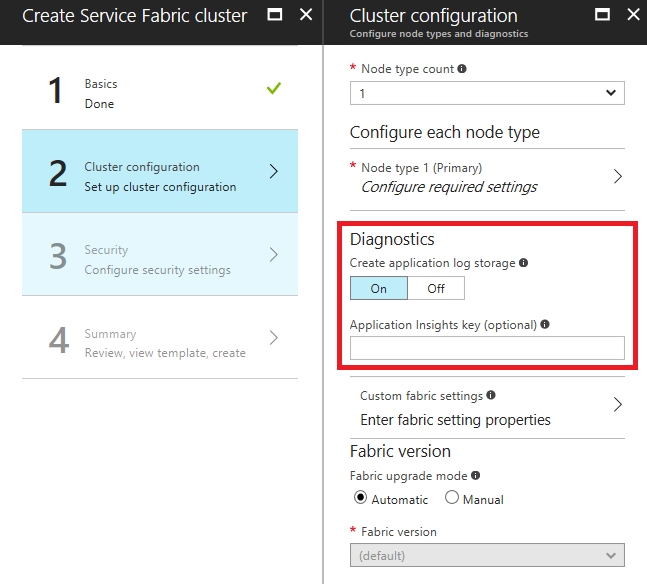
Jeśli podczas tworzenia klastra jest włączona diagnostyka, zostanie wyświetlone opcjonalne pole, które ma wprowadzić klucz instrumentacji usługi Application Insights. Jeśli w tym miejscu wklejesz klucz usługi Application Insights, ujście usługi Application Insights zostanie automatycznie skonfigurowane w szablonie usługi Resource Manager używanym do wdrażania klastra.
Dodawanie ujścia usługi Application Insights do szablonu usługi Resource Manager
W szablonie "WadCfg" szablonu usługi Resource Manager dodaj "Ujście", dołączając następujące dwie zmiany:
Dodaj konfigurację ujścia bezpośrednio po zakończeniu deklarowania
DiagnosticMonitorConfigurationelementu :"SinksConfig": { "Sink": [ { "name": "applicationInsights", "ApplicationInsights": "***ADD INSTRUMENTATION KEY HERE***" } ] }Dołącz ujście do
DiagnosticMonitorConfigurationelementu , dodając następujący wiersz wDiagnosticMonitorConfigurationelemecieWadCfg(bezpośrednio przed zadeklarowaną opcjąEtwProviders):"sinks": "applicationInsights"
W obu poprzednich fragmentach kodu nazwa "applicationInsights" została użyta do opisania ujścia. Nie jest to wymagane i tak długo, jak nazwa ujścia jest zawarta w "sinks", można ustawić nazwę na dowolny ciąg.
Obecnie dzienniki z klastra są wyświetlane jako ślady w podglądzie dzienników usługi Application Insights. Ponieważ większość śladów pochodzących z platformy jest na poziomie "Informacyjna", możesz również rozważyć zmianę konfiguracji ujścia, aby wysyłać tylko dzienniki typu "Ostrzeżenie" lub "Błąd". Można to zrobić, dodając "Kanały" do ujścia, jak pokazano w tym artykule.
Uwaga
Jeśli używasz nieprawidłowego klucza usługi Application Insights w portalu lub w szablonie usługi Resource Manager, musisz ręcznie zmienić klucz i zaktualizować klaster/ ponownie go wdrożyć.
Następne kroki
Po poprawnym skonfigurowaniu diagnostyki platformy Azure dane będą widoczne w tabelach usługi Storage z dzienników ETW i EventSource. Jeśli zdecydujesz się używać dzienników usługi Azure Monitor, Kibana lub innej platformy analizy danych i wizualizacji, która nie jest bezpośrednio skonfigurowana w szablonie usługi Resource Manager, upewnij się, że skonfigurowano wybraną platformę do odczytu danych z tych tabel magazynu. Wykonanie tej czynności w przypadku dzienników usługi Azure Monitor jest stosunkowo proste i zostało wyjaśnione w artykule Event and log analysis (Analiza zdarzeń i dzienników). Usługa Application Insights jest w tym sensie nieco specjalnym przypadkiem, ponieważ można ją skonfigurować w ramach konfiguracji rozszerzenia Diagnostyka, dlatego zapoznaj się z odpowiednim artykułem , jeśli zdecydujesz się używać sztucznej inteligencji.
Uwaga
Obecnie nie ma możliwości filtrowania ani pielęgnacji zdarzeń wysyłanych do tabeli. Jeśli nie zaimplementujesz procesu usuwania zdarzeń z tabeli, tabela będzie nadal rosła. Obecnie istnieje przykład usługi pielęgnacji danych uruchomionej w przykładzie Watchdog i zaleca się napisanie jednego dla siebie, chyba że istnieje dobry powód, aby przechowywać dzienniki poza przedziałem czasu 30 lub 90 dni.
- Dowiedz się, jak zbierać liczniki wydajności lub dzienniki przy użyciu rozszerzenia Diagnostyka
- Analiza zdarzeń i wizualizacja za pomocą usługi Application Insights
- Analiza zdarzeń i wizualizacja przy użyciu dzienników usługi Azure Monitor
- Analiza zdarzeń i wizualizacja za pomocą usługi Application Insights
- Analiza zdarzeń i wizualizacja przy użyciu dzienników usługi Azure Monitor