Usługa Azure Traffic Manager z usługą Azure Site Recovery
Usługa Azure Traffic Manager umożliwia kontrolowanie dystrybucji ruchu między punktami końcowymi aplikacji. Punkt końcowy to dowolna internetowa usługa hostowana wewnątrz platformy Azure lub poza nią.
Usługa Traffic Manager używa systemu nazw domen (DNS) do kierowania żądań klientów do najbardziej odpowiedniego punktu końcowego na podstawie metody routingu ruchu i kondycji punktów końcowych. Usługa Traffic Manager udostępnia szereg metod routingu ruchu oraz opcji monitorowania punktów końcowych, które zaspokoją potrzeby różnych aplikacji i modeli automatycznej pracy w trybie failover. Klienci bezpośrednio łączą się z wybranym punktem końcowym. Usługa Traffic Manager nie jest serwerem proxy ani bramą i nie widzi ruchu przechodzącego między klientem a usługą.
W tym artykule opisano sposób łączenia inteligentnego routingu usługi Azure Traffic Monitor z zaawansowanymi funkcjami odzyskiwania po awarii i migracji usługi Azure Site Recovery.
Przechodzenie w tryb failover w środowisku lokalnym do platformy Azure
W pierwszym scenariuszu rozważmy firmę A , która ma całą infrastrukturę aplikacji działającą w środowisku lokalnym. Ze względu na ciągłość działania i zgodność firma A decyduje się na korzystanie z usługi Azure Site Recovery w celu ochrony swoich aplikacji.
Firma A uruchamia aplikacje z publicznymi punktami końcowymi i chce bezproblemowo przekierowywać ruch do platformy Azure w przypadku awarii. Metoda priorytetowego routingu ruchu w usłudze Azure Traffic Manager umożliwia firmie A łatwe zaimplementowanie tego wzorca trybu failover.
Konfiguracja jest następująca:
- Firma A tworzy profil usługi Traffic Manager.
- Korzystając z metody routingu Priorytet , firma A tworzy dwa punkty końcowe — podstawowy dla środowiska lokalnego i trybu failover dla platformy Azure. Podstawowy jest przypisany priorytet 1, a tryb failover ma przypisany priorytet 2.
- Ponieważ podstawowy punkt końcowy jest hostowany poza platformą Azure, punkt końcowy jest tworzony jako zewnętrzny punkt końcowy.
- W usłudze Azure Site Recovery witryna platformy Azure nie ma żadnych maszyn wirtualnych ani aplikacji uruchomionych przed przejściem w tryb failover. Dlatego punkt końcowy trybu failover jest również tworzony jako zewnętrzny punkt końcowy.
- Domyślnie ruch użytkowników jest kierowany do aplikacji lokalnej, ponieważ ten punkt końcowy ma skojarzony najwyższy priorytet. Żaden ruch nie jest kierowany do platformy Azure, jeśli podstawowy punkt końcowy jest w dobrej kondycji.
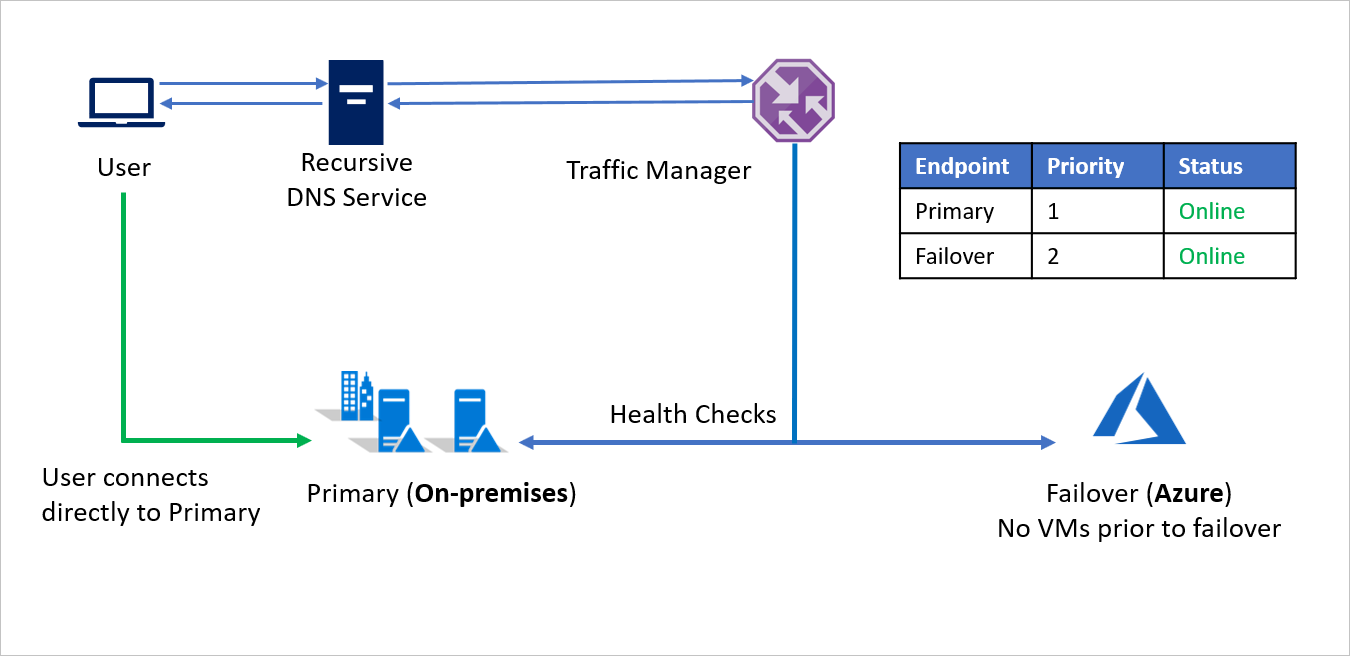
W przypadku awarii firma A może wyzwolić przejście w tryb failover na platformę Azure i odzyskać swoje aplikacje na platformie Azure. Gdy usługa Azure Traffic Manager wykryje, że podstawowy punkt końcowy nie jest już w dobrej kondycji, automatycznie używa punktu końcowego trybu failover w odpowiedzi DNS, a użytkownicy łączą się z aplikacją odzyskaną na platformie Azure.
W zależności od wymagań biznesowych firma A może wybrać wyższą lub niższą częstotliwość sondowania, aby przełączać się między środowiskiem lokalnym a platformą Azure w przypadku awarii i zapewnić minimalny przestój dla użytkowników.
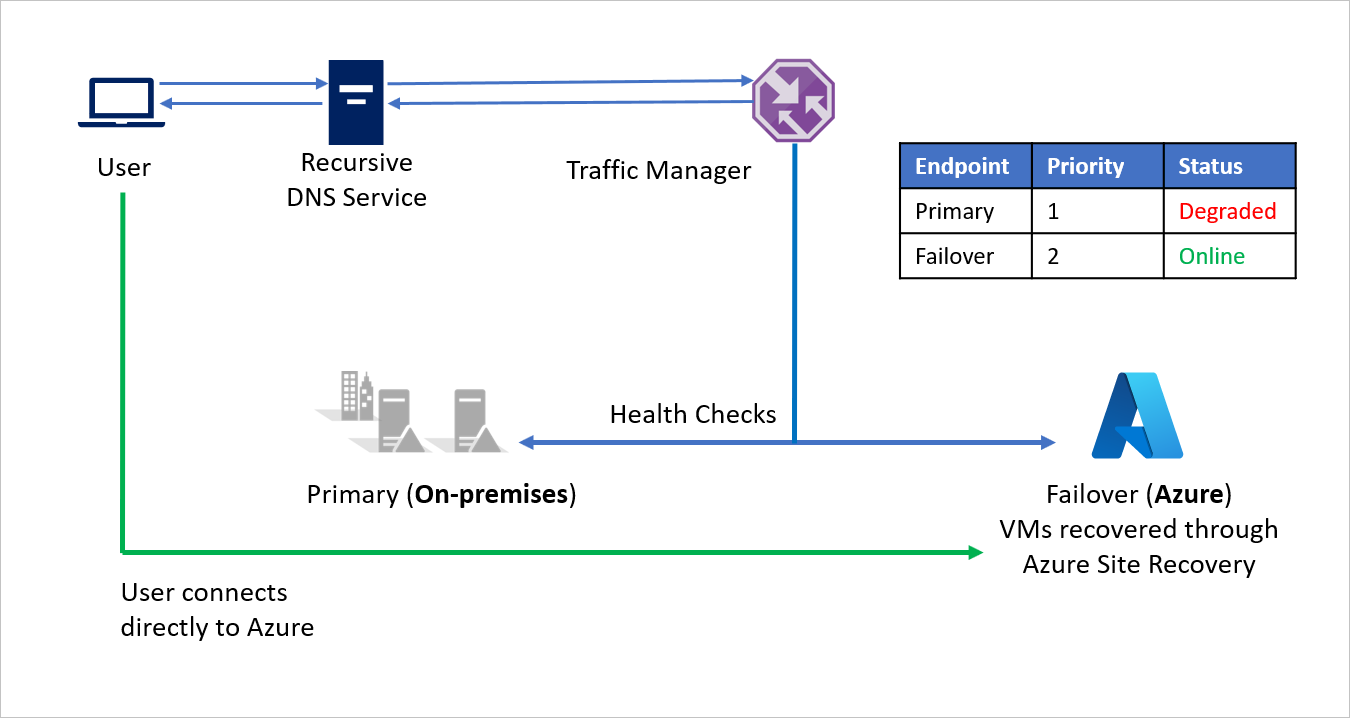
Gdy awaria zostanie zawarta, firma A może uruchomić powrót po awarii z platformy Azure do środowiska lokalnego (VMware lub Hyper-V) przy użyciu usługi Azure Site Recovery. Teraz, gdy usługa Traffic Manager wykryje, że podstawowy punkt końcowy ponownie jest w dobrej kondycji, automatycznie korzysta z podstawowego punktu końcowego w odpowiedziach DNS.
Migracja lokalna na platformę Azure
Oprócz odzyskiwania po awarii usługa Azure Site Recovery umożliwia również migracje na platformę Azure. Korzystając z zaawansowanych możliwości testowania pracy w trybie failover usługi Azure Site Recovery, klienci mogą ocenić wydajność aplikacji na platformie Azure bez wpływu na środowisko lokalne. A gdy klienci są gotowi do migracji, mogą wybrać migrację całych obciążeń razem lub wybrać migrację i stopniowe skalowanie.
Metoda routingu ważonego usługi Azure Traffic Manager może służyć do kierowania niektórych części ruchu przychodzącego na platformę Azure przy jednoczesnym kierowaniu większości do środowiska lokalnego. Takie podejście może pomóc ocenić wydajność skalowania, ponieważ można nadal zwiększać wagę przypisaną do platformy Azure w miarę migrowania coraz większej liczby obciążeń na platformę Azure.
Na przykład firma B wybiera migrację w fazach, przenosząc część swojego środowiska aplikacji przy zachowaniu pozostałej części środowiska lokalnego. W początkowych etapach, gdy większość środowiska jest lokalna, większa waga jest przypisywana do środowiska lokalnego. Usługa Traffic Manager zwraca punkt końcowy na podstawie wag przypisanych do dostępnych punktów końcowych.
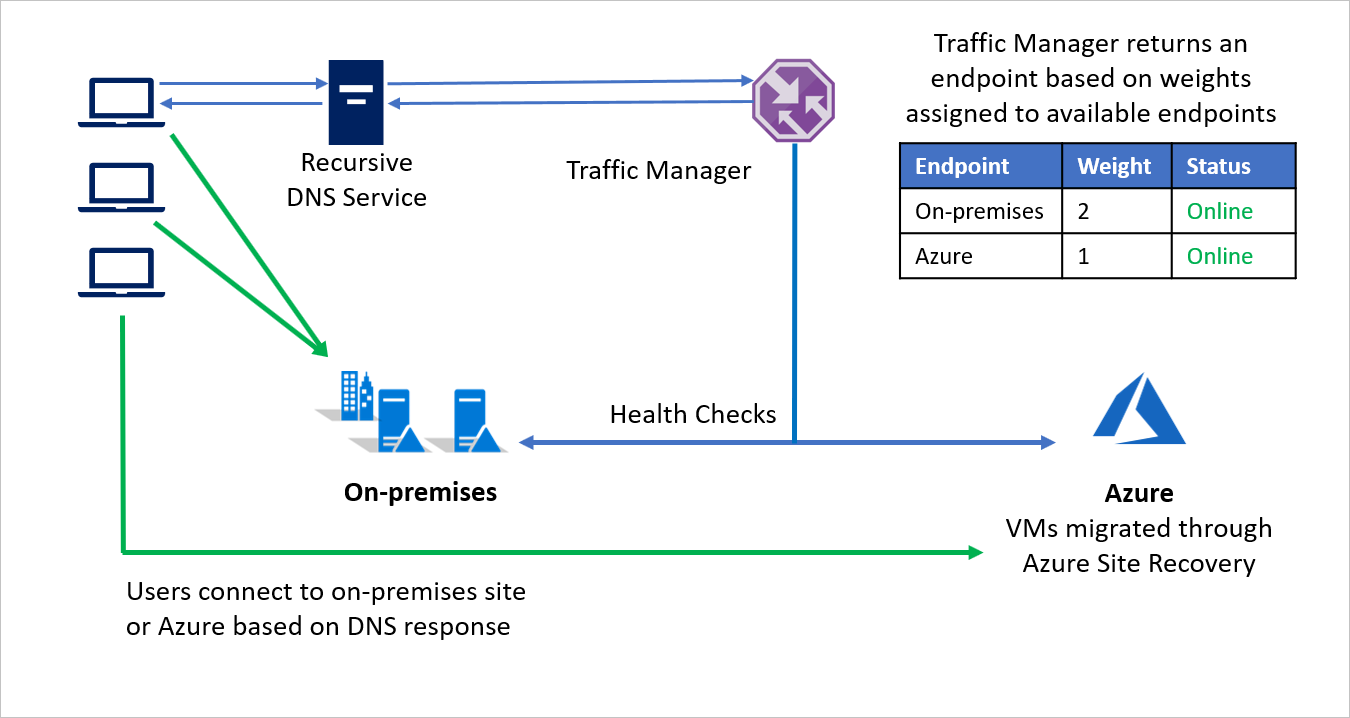
Podczas migracji oba punkty końcowe są aktywne, a większość ruchu jest kierowana do środowiska lokalnego. Podczas migracji można przypisać większą wagę do punktu końcowego na platformie Azure, a na koniec lokalny punkt końcowy można dezaktywować po migracji.
Przechodzenie w tryb failover z platformy Azure do platformy Azure
W tym przykładzie rozważmy firmę C , która ma całą infrastrukturę aplikacji działającą na platformie Azure. Ze względu na ciągłość działania i zgodność firma C decyduje się na korzystanie z usługi Azure Site Recovery w celu ochrony swoich aplikacji.
Firma C uruchamia aplikacje z publicznymi punktami końcowymi i chce bezproblemowo przekierowywać ruch do innego regionu świadczenia usługi Azure w przypadku awarii. Metoda priorytetowego routingu ruchu umożliwia firmie C łatwe zaimplementowanie tego wzorca trybu failover.
Konfiguracja jest następująca:
- Firma C tworzy profil usługi Traffic Manager.
- Korzystając z metody routingu Priorytet , firma C tworzy dwa punkty końcowe — podstawowy dla regionu źródłowego (Azja Wschodnia) i tryb failover dla regionu odzyskiwania (Azja Południowo-Wschodnia Azure). Podstawowy jest przypisany priorytet 1, a tryb failover ma przypisany priorytet 2.
- Ponieważ podstawowy punkt końcowy jest hostowany na platformie Azure, punkt końcowy może być punktem końcowym platformy Azure.
- W usłudze Azure Site Recovery lokacja odzyskiwania platformy Azure nie ma żadnych maszyn wirtualnych ani aplikacji uruchomionych przed przejściem w tryb failover. W związku z tym punkt końcowy trybu failover można utworzyć jako zewnętrzny punkt końcowy.
- Domyślnie ruch użytkowników jest kierowany do aplikacji regionu źródłowego (Azja Wschodnia), ponieważ ten punkt końcowy ma skojarzony najwyższy priorytet. Jeśli podstawowy punkt końcowy jest w dobrej kondycji, żaden ruch nie jest kierowany do regionu odzyskiwania.
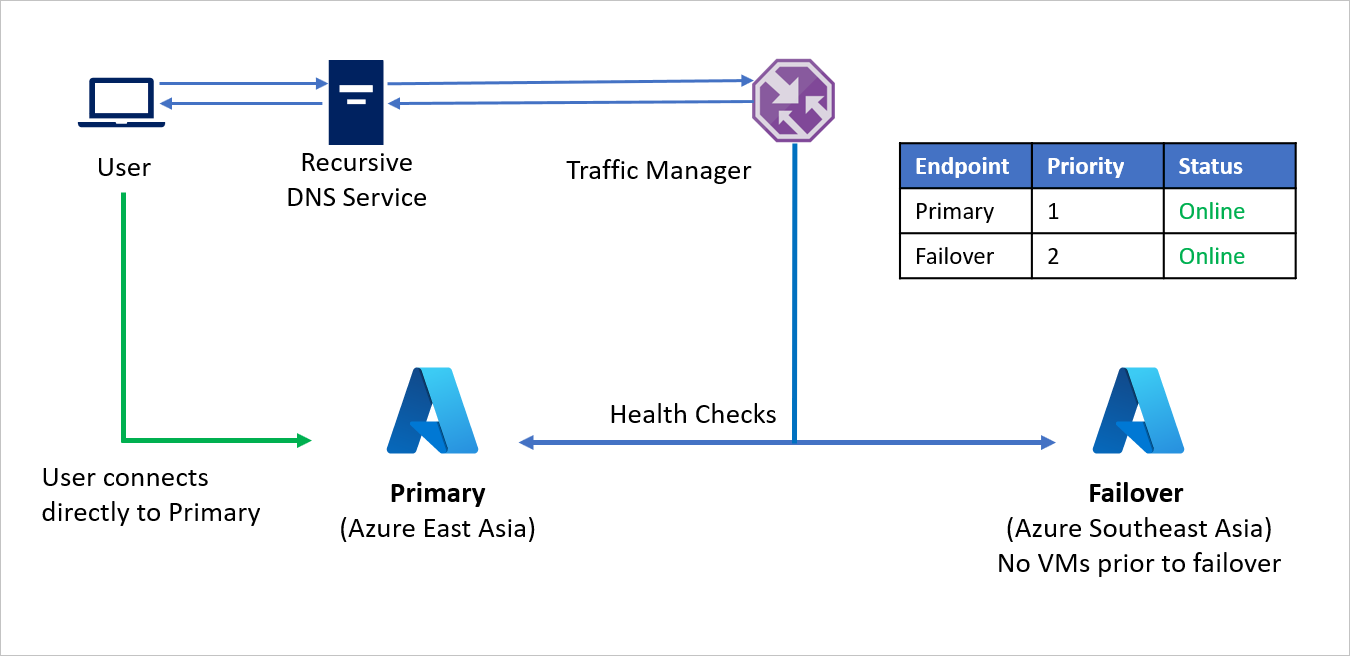
W przypadku awarii firma C może wyzwolić tryb failover i odzyskać aplikacje w regionie odzyskiwania platformy Azure. Gdy usługa Azure Traffic Manager wykryje, że podstawowy punkt końcowy nie jest już w dobrej kondycji, automatycznie używa punktu końcowego trybu failover w odpowiedzi DNS, a użytkownicy łączą się z aplikacją odzyskaną w regionie odzyskiwania platformy Azure (Azja Południowo-Wschodnia).
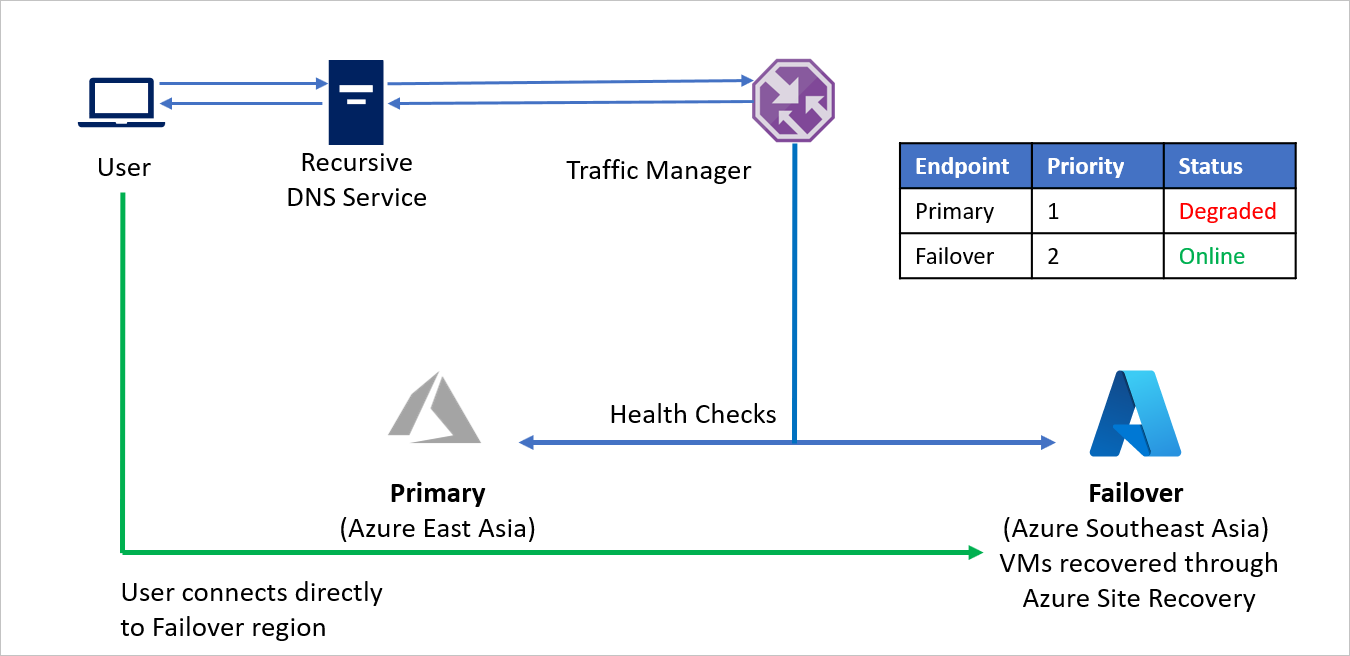
W zależności od wymagań biznesowych firma C może wybrać wyższą lub niższą częstotliwość sondowania, aby przełączać się między regionami źródła i odzyskiwania i zapewnić minimalny przestój dla użytkowników.
Gdy awaria zostanie zawarta, firma C może uruchomić powrót po awarii z regionu odzyskiwania platformy Azure do źródłowego regionu platformy Azure przy użyciu usługi Azure Site Recovery. Teraz, gdy usługa Traffic Manager wykryje, że podstawowy punkt końcowy ponownie jest w dobrej kondycji, automatycznie korzysta z podstawowego punktu końcowego w odpowiedziach DNS.
Ochrona aplikacji dla przedsiębiorstw w wielu regionach
Globalne przedsiębiorstwa często zwiększają jakość obsługi klientów, dostosowując aplikacje do potrzeb regionalnych. Zmniejszenie lokalizacji i opóźnień może prowadzić do podziału infrastruktury aplikacji w różnych regionach. Przedsiębiorstwa są również powiązane z regionalnymi przepisami dotyczącymi danych w niektórych obszarach i decydują się odizolować część infrastruktury aplikacji w granicach regionalnych.
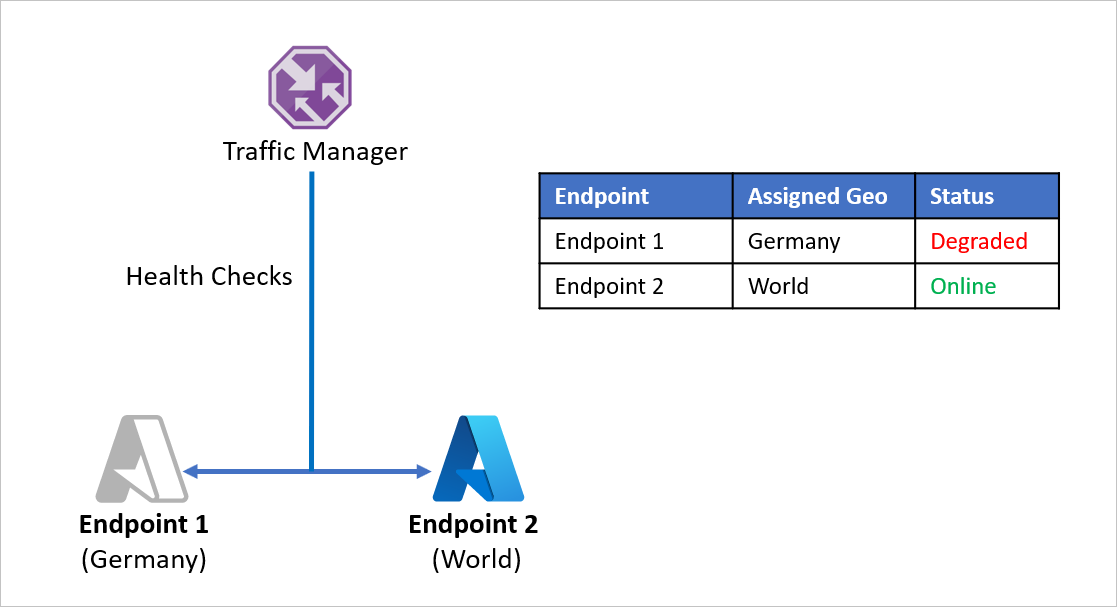
Rozważmy przykład, w którym firma D podzieliła punkty końcowe aplikacji, aby oddzielnie obsługiwać Niemcy i resztę świata. Firma D używa metody routingu geograficznego usługi Azure Traffic Manager, aby to skonfigurować. Każdy ruch pochodzący z Niemiec jest kierowany do punktu końcowego 1 , a każdy ruch pochodzący z Niemiec jest kierowany do punktu końcowego 2.
Problem z tą konfiguracją polega na tym, że jeśli punkt końcowy 1 przestanie działać z jakiegokolwiek powodu, nie ma przekierowania ruchu do punktu końcowego 2. Ruch pochodzący z Niemiec nadal jest kierowany do punktu końcowego 1 niezależnie od kondycji punktu końcowego, pozostawiając niemieckich użytkowników bez dostępu do aplikacji firmy D. Podobnie, jeśli punkt końcowy 2 przechodzi w tryb offline, nie ma przekierowania ruchu do punktu końcowego 1.
Aby uniknąć wystąpienia tego problemu i zapewnić odporność aplikacji, firma D używa zagnieżdżonych profilów usługi Traffic Manager z usługą Azure Site Recovery. W konfiguracji profilu zagnieżdżonego ruch nie jest kierowany do poszczególnych punktów końcowych, ale do innych profilów usługi Traffic Manager. Oto jak działa ta konfiguracja:
- Zamiast używać routingu geograficznego z poszczególnymi punktami końcowymi, firma D używa routingu geograficznego z profilami usługi Traffic Manager.
- Każdy podrzędny profil usługi Traffic Manager korzysta z routingu priorytetowego z podstawowym i punktem końcowym odzyskiwania, dlatego zagnieżdża routing priorytetowy w ramach routingu geograficznego .
- Aby umożliwić odporność aplikacji, każda dystrybucja obciążeń korzysta z usługi Azure Site Recovery do przejścia w tryb failover do regionu odzyskiwania opartego na przypadku wystąpienia awarii.
- Gdy nadrzędna usługa Traffic Manager odbiera zapytanie DNS, jest kierowana do odpowiedniego podrzędnego usługi Traffic Manager, która odpowiada na zapytanie przy użyciu dostępnego punktu końcowego.
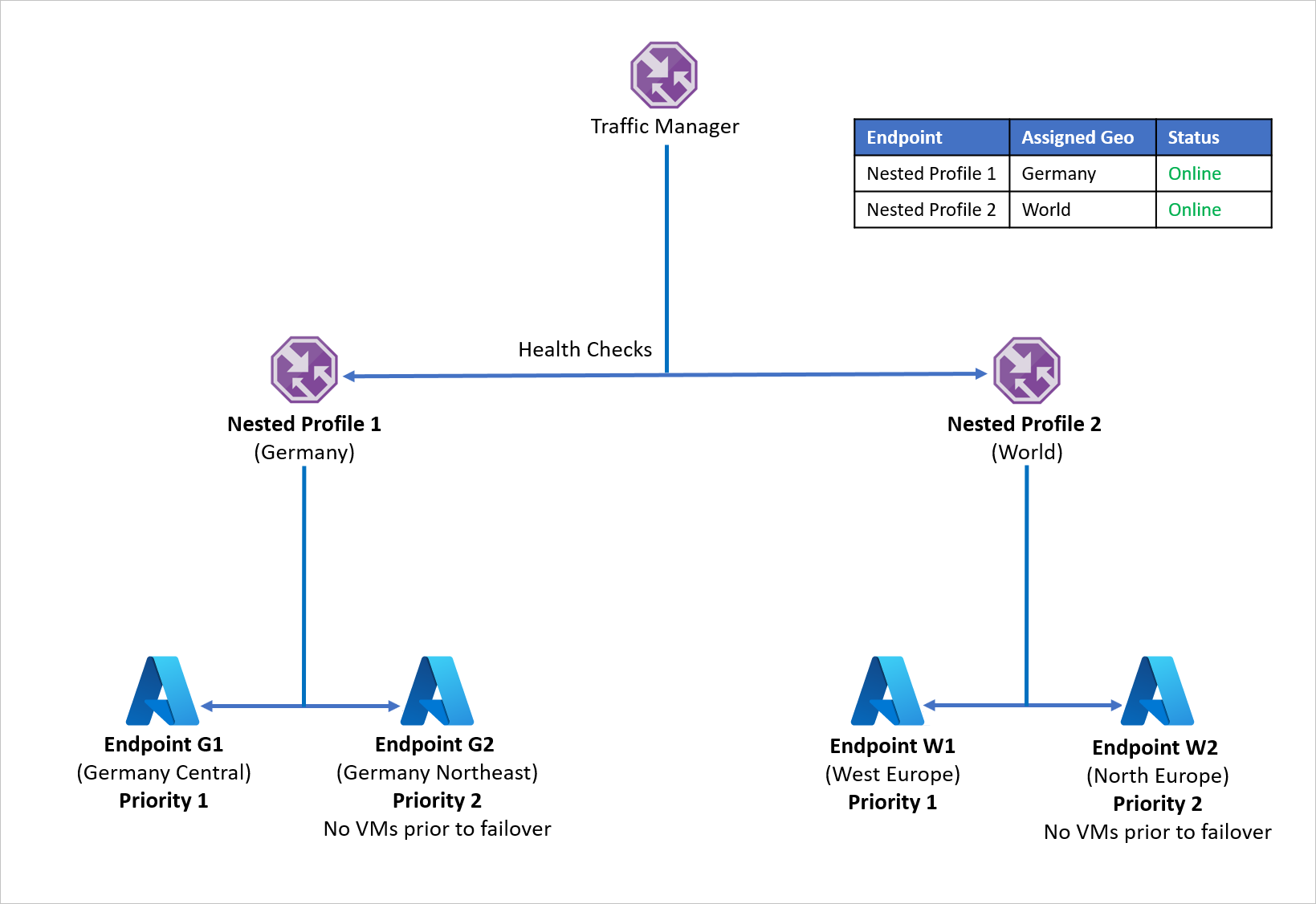
Jeśli na przykład punkt końcowy w Niemczech Środkowych ulegnie awarii, można szybko odzyskać aplikację na północny wschód od Niemiec. Nowy punkt końcowy obsługuje ruch pochodzący z Niemiec z minimalnym przestojem dla użytkowników. Podobnie awaria punktu końcowego w regionie Europa Zachodnia może być obsługiwana przez odzyskanie obciążenia aplikacji do Europy Północnej, a usługa Azure Traffic Manager obsługuje przekierowania DNS do dostępnego punktu końcowego.
Powyższa konfiguracja można rozszerzyć tak, aby zawierała dowolną liczbę wymaganych kombinacji regionów i punktów końcowych. Usługa Traffic Manager umożliwia maksymalnie 10 poziomów zagnieżdżonych profilów i nie zezwala na pętle w ramach konfiguracji zagnieżdżonej.
Zagadnienia dotyczące celu czasu odzyskiwania (RTO)
W większości organizacji dodawanie lub modyfikowanie rekordów DNS jest obsługiwane przez oddzielny zespół lub przez kogoś spoza organizacji. Sprawia to, że zadanie zmiany rekordów DNS jest bardzo trudne. Czas potrzebny na zaktualizowanie rekordów DNS przez inne zespoły lub organizacje zarządzające infrastrukturą DNS różni się w zależności od organizacji i ma wpływ na cel czasu odzyskiwania aplikacji.
Korzystając z usługi Traffic Manager, można z góry załadować pracę wymaganą do aktualizacji DNS. W momencie rzeczywistego przejścia w tryb failover nie jest wymagana żadna akcja ręczna ani skryptowa. Takie podejście pomaga w szybkim przełączaniu (a tym samym obniżaniu celu czasu odzyskiwania), a także unikaniu kosztownych czasochłonnych błędów zmian DNS w przypadku awarii. W przypadku usługi Traffic Manager nawet krok powrotu po awarii jest zautomatyzowany, co w przeciwnym razie byłoby konieczne oddzielne zarządzanie.
Ustawienie poprawnego interwału sondowania za pomocą podstawowych lub szybkich testów kondycji interwału może znacznie obniżyć cel czasu odzyskiwania podczas pracy w trybie failover i zmniejszyć czas przestoju dla użytkowników.
Możesz dodatkowo zoptymalizować wartość czasu wygaśnięcia (TTL) dns dla profilu usługi Traffic Manager. Czas wygaśnięcia to wartość, dla której wpis DNS będzie buforowany przez klienta. W przypadku rekordu usługa DNS nie będzie dwukrotnie odpytywała w zakresie czasu wygaśnięcia. Każdy rekord DNS ma skojarzony czas wygaśnięcia. Zmniejszenie tej wartości powoduje zwiększenie liczby zapytań DNS do usługi Traffic Manager, ale może zmniejszyć cel czasu odzyskiwania przez szybsze odnajdywanie awarii.
Czas wygaśnięcia napotkany przez klienta również nie zwiększa się, jeśli liczba rozpoznawania nazw DNS między klientem a autorytatywnym serwerem DNS zwiększa się. Rozpoznawanie nazw DNS "odlicza czas wygaśnięcia" i przekazuje tylko wartość czasu wygaśnięcia, która odzwierciedla czas, który upłynął od momentu buforowania rekordu. Dzięki temu rekord DNS zostanie odświeżony na kliencie po upływie czasu wygaśnięcia, niezależnie od liczby rozpoznawania nazw DNS w łańcuchu.
Następne kroki
- Dowiedz się więcej o metodach routingu usługi Traffic Manager.
- Dowiedz się więcej na temat zagnieżdżonych profilów usługi Traffic Manager.
- Dowiedz się więcej o monitorowaniu punktów końcowych.
- Dowiedz się więcej o planach odzyskiwania w celu zautomatyzowania trybu failover aplikacji.