Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dostępne zarówno w chmurze, jak i Azure IoT Edge, Azure Stream Analytics oferuje wbudowane funkcje wykrywania anomalii oparte na uczeniu maszynowym, których można użyć do monitorowania dwóch najczęściej występujących anomalii: tymczasowych i trwałych. Korzystając z funkcji AnomalyDetection_SpikeAndDip i AnomalyDetection_ChangePoint , można wykonywać wykrywanie anomalii bezpośrednio w zadaniu usługi Stream Analytics.
Modele uczenia maszynowego zakładają jednolicie próbkowane szeregi czasowe. Jeśli szereg czasowy nie jest jednolity, wstaw krok agregacji z oknem toczącym się przed wywołaniem detekcji anomalii.
Obecnie operacje uczenia maszynowego nie obsługują trendów sezonowości ani korelacji wielowariancji.
Wykrywanie anomalii przy użyciu uczenia maszynowego w Azure Stream Analytics
W poniższym filmie wideo pokazano, jak wykryć anomalię w czasie rzeczywistym przy użyciu funkcji uczenia maszynowego w Azure Stream Analytics.
Zachowanie modelu
Ogólnie rzecz biorąc, dokładność modelu poprawia się wraz z większą ilością danych w oknie przesuwnym. Dane w określonym oknie przesuwnym są traktowane jako część normalnego zakresu wartości dla tego przedziału czasu. Model bierze pod uwagę tylko historię zdarzeń w oknie przesuwnym, aby sprawdzić, czy bieżące zdarzenie jest anomalne. W miarę przesuwania okna stare wartości są usuwane z procesu trenowania modelu.
Funkcje działają poprzez ustanowienie pewnej normy na podstawie tego, co zaobserwowały do tej pory. Wartości odstające są identyfikowane przez porównanie z ustaloną normą, w ramach poziomu ufności. Rozmiar okna powinien być oparty na minimalnych zdarzeniach wymaganych do wytrenowania modelu pod kątem normalnego zachowania, tak aby w przypadku wystąpienia anomalii był w stanie ją rozpoznać.
Czas odpowiedzi modelu zwiększa się wraz z rozmiarem historii, ponieważ musi on zostać porównany z większą liczbą przeszłych zdarzeń. Aby uzyskać lepszą wydajność, uwzględnij tylko wymaganą liczbę zdarzeń.
Przerwy w szeregach czasowych mogą wystąpić, gdy model nie odbiera zdarzeń w określonych punktach w czasie. Usługa Stream Analytics obsługuje tę sytuację przy użyciu logiki imputacji. Rozmiar historii i czas trwania tego samego okna przesuwnego są wykorzystywane do obliczania średniej szybkości, z jaką oczekuje się przybywania zdarzeń.
Możesz użyć generatora anomalii do zasilania IoT Hub danymi zawierającymi różne wzorce anomalii. Można skonfigurować zadanie Azure Stream Analytics, używając tych funkcji wykrywania anomalii, aby odczytywać z tego IoT Hub i wykrywać anomalie.
Skok i spadek
Tymczasowe anomalie w strumieniu zdarzeń szeregów czasowych są znane jako skoki i spadki. Skoki i spadki można monitorować za pomocą operatora opartego na Machine Learning, AnomalyDetection_SpikeAndDip.
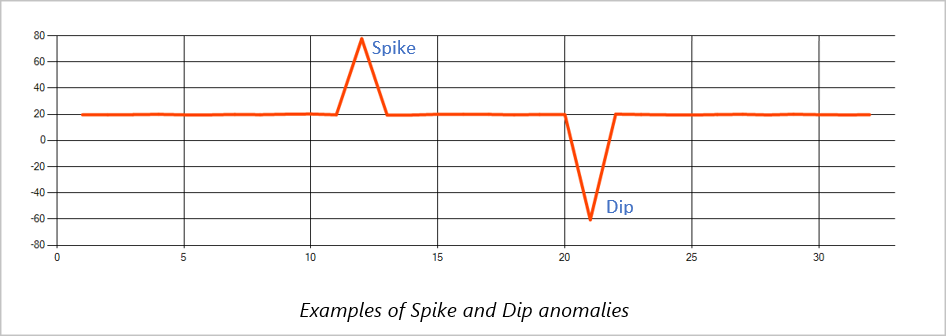
W tym samym oknie przesuwnym, jeśli drugi skok jest mniejszy niż pierwszy, obliczony wynik dla mniejszego skoku może nie być wystarczająco znaczący w porównaniu z wynikiem pierwszego skoku w określonym poziomie ufności. Możesz spróbować zmniejszyć poziom ufności modelu, aby wykryć takie anomalie. Jeśli jednak zaczniesz otrzymywać zbyt wiele alertów, użyj większego interwału ufności.
Poniższe przykładowe zapytanie zakłada jednolitą szybkość wprowadzania jednego zdarzenia na sekundę w 2-minutowym oknie przesuwania z historią 120 zdarzeń. Końcowa instrukcja SELECT wyodrębnia i wyprowadza wynik i stan anomalii z poziomem ufności 95%.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO output
FROM AnomalyDetectionStep
Punkt zmiany
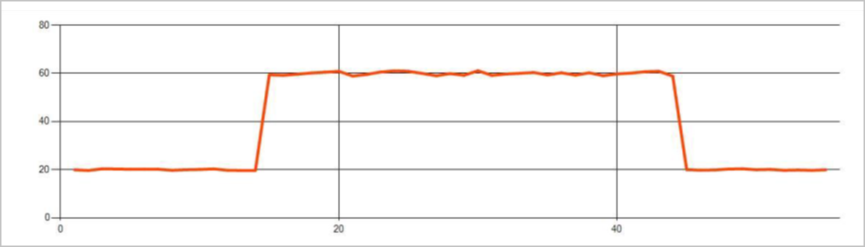
Trwałe anomalie w strumieniu zdarzeń szeregów czasowych to zmiany w rozkładzie wartości w strumieniu zdarzeń, takie jak zmiany poziomu i trendy. W usłudze Stream Analytics operator Machine Learning oparty na
Trwałe zmiany trwają znacznie dłużej niż skoki i spadki i mogą wskazywać na katastrofalne wydarzenia. Trwałe zmiany nie są zwykle widoczne dla nagiego oka, ale operator AnomalyDetection_ChangePoint może je wykryć.
Na poniższej ilustracji przedstawiono przykład zmiany poziomu:
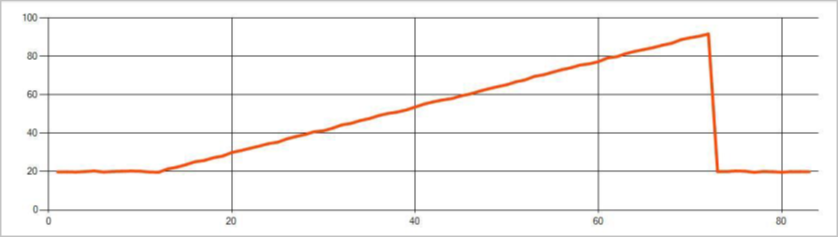
Na poniższej ilustracji przedstawiono przykład zmiany trendu:
Poniższe przykładowe zapytanie zakłada stałą szybkość wprowadzania jednego zdarzenia na sekundę w 20-minutowym oknie przesuwnym z rozmiarem historii 1 200 zdarzeń. Końcowa instrukcja SELECT wyodrębnia i wyprowadza wynik i stan anomalii z poziomem ufności 80%.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_ChangePoint(CAST(temperature AS float), 80, 1200)
OVER(LIMIT DURATION(minute, 20)) AS ChangePointScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(ChangePointScores, 'Score') AS float) AS
ChangePointScore,
CAST(GetRecordPropertyValue(ChangePointScores, 'IsAnomaly') AS bigint) AS
IsChangePointAnomaly
INTO output
FROM AnomalyDetectionStep
Charakterystyka wydajności
Wydajność tych modeli zależy od rozmiaru historii, czasu trwania okna, obciążenia zdarzeń i tego, czy jest używane partycjonowanie na poziomie funkcji. W tej sekcji omówiono te konfiguracje i przedstawiono przykłady dotyczące utrzymania przepustowości przyjmowania danych 1 K, 5 K i 10 K zdarzeń na sekundę.
- Rozmiar historii — te modele działają liniowo z rozmiarem historii. Im dłuższa historia, tym więcej czasu zajmuje modelom ocenienie nowego zdarzenia. Modele porównują nowe zdarzenie z każdym z poprzednich zdarzeń w buforze historii.
- Czas trwania okna — czas trwania okna powinien odzwierciedlać czas odbierania jak największej liczby zdarzeń określonych przez rozmiar historii. Bez wielu zdarzeń w oknie, Azure Stream Analytics wypełniałoby brakujące wartości. W związku z tym użycie procesora jest funkcją rozmiaru historii.
- Obciążenie zdarzeń — im większe obciążenie zdarzeń, tym więcej pracy wykonują modele, co ma wpływ na zużycie procesora. Zadanie można skalować poziomo, czyniąc je łatwo równoległym, o ile logika biznesowa uzasadnia użycie większej liczby partycji wejściowych.
-
Partycjonowanie na poziomie funkcji — użyj
PARTITION BYfunkcji wykrywania anomalii, aby wykonać partycjonowanie na poziomie funkcji. Ten typ partycjonowania dodaje obciążenie, ponieważ zadanie musi obsługiwać stan wielu modeli jednocześnie. Partycjonowanie na poziomie funkcji można używać w scenariuszach, takich jak partycjonowanie na poziomie urządzenia.
Relacja
Rozmiar historii, czas trwania okna i łączne obciążenie zdarzeń są powiązane w następujący sposób:
windowDuration (w ms) = 1000 * historySize / (łączna liczba zdarzeń wejściowych na sekundę / liczba partycji wejściowych)
Podczas partycjonowania funkcji według identyfikatora deviceId dodaj wartość "PARTITION BY deviceId" do wywołania funkcji wykrywania anomalii.
Obserwacje
W poniższej tabeli przedstawiono obserwacje przepływności dla jednego węzła (sześć jednostek SU) dla przypadku niepartycyjnego:
| Rozmiar historii (zdarzenia) | Czas trwania okna (ms) | Łączna liczba zdarzeń wejściowych na sekundę |
|---|---|---|
| 60 | 55 | 2200 |
| 600 | 728 | 1,650 |
| 6000 | 10,910 | 1,100 |
W poniższej tabeli przedstawiono obserwacje przepustowości dla jednego węzła (sześć jednostek SU) w przypadku podziału:
| Rozmiar historii (zdarzenia) | Czas trwania okna (ms) | Łączna liczba zdarzeń wejściowych na sekundę | Liczba urządzeń |
|---|---|---|---|
| 60 | 1,091 | 1,100 | 10 |
| 600 | 10,910 | 1,100 | 10 |
| 6000 | 218,182 | <550 | 10 |
| 60 | 21,819 | 550 | 100 |
| 600 | 218,182 | 550 | 100 |
| 6000 | 2,181,819 | <550 | 100 |
Przykładowy kod służący do uruchamiania niepartycjonowanych konfiguracji można znaleźć w repozytorium Streaming At Scale przykładów Azure. Kod tworzy zadanie Stream Analytics bez partycjonowania na poziomie funkcji, które używa Event Hubs jako dane wejściowe i wyjściowe. Klienci testowi generują obciążenie wejściowe. Każde zdarzenie wejściowe jest dokumentem JSON o rozmiarze 1 KB. Zdarzenia symulują urządzenie IoT wysyłające dane JSON (do 1 K urządzeń). Rozmiar historii, czas trwania okna i łączne obciążenie zdarzeń różnią się w zależności od dwóch partycji wejściowych.
Uwaga
Aby uzyskać dokładniejsze oszacowanie, dostosuj próbki do swojego scenariusza.
Identyfikacja wąskich gardeł
Aby zidentyfikować wąskie gardła w potoku danych, użyj okienka Metryki w pracy Azure Stream Analytics. Przejrzyj zdarzenia wejścia/wyjścia pod kątem przepustowości oraz "Opóźnienia znacznika wodnego" lub zaległych zdarzeń, aby sprawdzić, czy zadanie nadąża za szybkością wprowadzania danych. W przypadku metryk usługi Event Hubs poszukaj żądań ograniczonych i odpowiednio dostosuj jednostki progowe. W przypadku metryk Azure Cosmos DB zapoznaj się z Maksymalne zużywane RU/s na zakres kluczy partycji w sekcji Przepustowość, aby sprawdzić, czy zakresy kluczy partycji są równomiernie zużywane. W przypadku bazy danych Azure SQL monitoruj Log IO i CPU.