Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Usługa Azure Synapse Analytics oferuje różne aparaty analityczne ułatwiające pozyskiwanie, przekształcanie, modelowanie i analizowanie danych. Dedykowana pula SQL oferuje możliwości obliczeniowe i magazynowe oparte na języku T-SQL. Po utworzeniu dedykowanej puli SQL w obszarze roboczym usługi Synapse można ładować, modelować, przetwarzać i dostarczać dane w celu uzyskania szybszych analiz analitycznych.
Z tego przewodnika Szybki start dowiesz się, jak ładować dane z usługi Azure SQL Database do usługi Azure Synapse Analytics. Możesz wykonać podobne kroki, aby skopiować dane z innych typów magazynów danych. Ten podobny przepływ dotyczy również kopiowania danych dla innych źródeł i ujść.
Wymagania wstępne
- Subskrypcja platformy Azure: jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto platformy Azure .
- Obszar roboczy usługi Azure Synapse: utwórz obszar roboczy usługi Synapse przy użyciu witryny Azure Portal, postępując zgodnie z instrukcjami w przewodniku Szybki start: tworzenie obszaru roboczego usługi Synapse.
- Azure SQL Database: ten samouczek kopiuje dane z przykładowego zestawu danych Adventure Works LT w usłudze Azure SQL Database. Tę przykładową bazę danych można utworzyć w usłudze SQL Database, postępując zgodnie z instrukcjami w temacie Tworzenie przykładowej bazy danych w usłudze Azure SQL Database. Możesz też użyć innych magazynów danych, wykonując podobne kroki.
- Konto usługi Azure Storage: usługa Azure Storage jest używana jako obszar przejściowy w operacji kopiowania. Jeśli nie masz konta magazynu w usłudze Azure, zobacz instrukcje w Tworzenie konta magazynu.
- Azure Synapse Analytics: używasz dedykowanej puli SQL jako magazynu danych ujścia. Jeśli nie masz wystąpienia usługi Azure Synapse Analytics, zobacz Tworzenie dedykowanej puli SQL, aby dowiedzieć się, jak je utworzyć.
Przejdź do programu Synapse Studio
Po utworzeniu obszaru roboczego usługi Synapse dostępne są dwa sposoby otwierania programu Synapse Studio:
- Otwórz obszar roboczy usługi Synapse w witrynie Azure Portal. Wybierz pozycję Otwórz na karcie Open Synapse Studio w obszarze Wprowadzenie.
- Otwórz usługę Azure Synapse Analytics i zaloguj się do obszaru roboczego.
W tym przewodniku Szybki start jako przykład użyjemy obszaru roboczego o nazwie "adftest2020". Spowoduje to automatyczne przejście do strony głównej programu Synapse Studio.
Tworzenie połączonych usług
W usłudze Azure Synapse Analytics połączona usługa jest miejscem, gdzie definiujesz informacje o połączeniu z innymi usługami. W tej sekcji utworzysz następujące dwa rodzaje połączonych usług: połączone usługi Azure SQL Database i Azure Data Lake Storage Gen2 (ADLS Gen2).
Na stronie głównej programu Synapse Studio wybierz kartę Zarządzanie w obszarze nawigacji po lewej stronie.
W obszarze Połączenia zewnętrzne wybierz pozycję Połączone usługi.

Aby dodać połączoną usługę, wybierz pozycję Nowy.
Wybierz pozycję Azure SQL Database z galerii, a następnie wybierz pozycję Kontynuuj. Możesz wpisać "sql" w polu wyszukiwania, aby filtrować łączniki.

Na stronie Nowa połączona usługa wybierz nazwę serwera i nazwę bazy danych z listy rozwijanej, a następnie określ nazwę użytkownika i hasło. Kliknij pozycję Testuj połączenie , aby zweryfikować ustawienia, a następnie wybierz pozycję Utwórz.

Powtórz kroki 3–4, ale zamiast tego wybierz pozycję Azure Data Lake Storage Gen2 z galerii. Na stronie Nowa usługa połączenia wybierz nazwę konta przechowywania z listy rozwijanej. Kliknij pozycję Testuj połączenie , aby zweryfikować ustawienia, a następnie wybierz pozycję Utwórz.

Stwórz potok
Potok zawiera przepływ logiczny na potrzeby wykonywania zestawu działań. W tej sekcji utworzysz potok zawierający operację kopiowania, która pobiera dane z bazy danych Azure SQL do dedykowanej puli SQL.
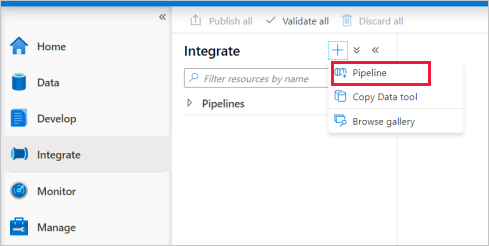
Przejdź do karty Integrate. Wybierz ikonę plus obok nagłówka pipelines i wybierz Pipeline.
W obszarze Przenieś i przekształć w okienku Działania przeciągnij pozycję Kopiuj dane na kanwę potoku.
Wybierz działanie kopiowania i przejdź do karty Źródło. Wybierz pozycję Nowy , aby utworzyć nowy źródłowy zestaw danych.

Wybierz Azure SQL Database jako magazyn danych i kliknij Kontynuuj.
W okienku Ustawianie właściwości wybierz połączoną usługę Azure SQL Database utworzoną we wcześniejszym kroku.
W obszarze Nazwa tabeli wybierz przykładową tabelę do użycia w następującym działaniu kopiowania. W tym szybkim starcie użyjemy tabeli "SalesLT.Customer" jako przykładu.

Po zakończeniu wybierz przycisk OK .
Wybierz operację kopiowania i przejdź do zakładki Ujście. Wybierz Nowy, aby utworzyć nowy zbiór danych dla ujścia.
Wybierz dedykowaną pulę SQL usługi Azure Synapse jako magazyn danych i wybierz pozycję Kontynuuj.
W okienku Ustawianie właściwości wybierz pulę SQL Analytics utworzoną we wcześniejszym kroku. Jeśli piszesz do istniejącej tabeli, w obszarze Nazwa tabeli wybierz ją z listy rozwijanej. W przeciwnym razie zaznacz pole "Edytuj" i wprowadź nazwę nowej tabeli. Po zakończeniu wybierz przycisk OK .
W ustawieniach zestawu danych Sink włącz opcję Automatyczne tworzenie tabeli w polu opcji Tabela.

Na stronie Ustawienia zaznacz pole wyboru Włącz inscenizację. Ta opcja ma zastosowanie, jeśli dane źródłowe nie są zgodne z technologią PolyBase. W sekcji Ustawienia przejściowe wybierz połączoną usługę Azure Data Lake Storage Gen2 utworzoną we wcześniejszym kroku jako magazyn przejściowy.
Magazyn jest używany do przemieszczania danych przed załadowaniem ich do usługi Azure Synapse Analytics przy użyciu technologii PolyBase. Po zakończeniu kopiowania dane tymczasowe w usłudze Azure Data Lake Storage Gen2 są automatycznie czyszczone.

Aby zweryfikować pipeline, wybierz pozycję Weryfikuj na pasku narzędzi. Wynik walidacji Pipeline jest widoczny po prawej stronie strony.
Debugowanie i publikowanie potoku
Po zakończeniu konfigurowania potoku możesz wykonać przebieg debugowania przed opublikowaniem artefaktów, aby sprawdzić, czy wszystko jest poprawne.
Aby debugować potok, wybierz na pasku narzędzi pozycję Debuguj. Na karcie Dane wyjściowe w dolnej części okna wyświetlany jest stan uruchomienia potoku.

Po pomyślnym uruchomieniu potoku na górnym pasku narzędzi wybierz pozycję Opublikuj wszystko. Ta akcja powoduje opublikowanie jednostek (zestawów danych i potoków) utworzonych w usłudze Synapse Analytics.
Poczekaj na wyświetlenie komunikatu Pomyślnie opublikowano. Aby wyświetlić komunikaty powiadomień, wybierz przycisk dzwonka w prawym górnym rogu.
Wyzwalanie i monitorowanie pipeliny
W tej sekcji ręcznie wyzwolisz potok opublikowany w poprzednim kroku.
Wybierz pozycję Dodaj wyzwalacz na pasku narzędzi, a następnie wybierz pozycję Wyzwól teraz. Na stronie Uruchamianie potoku wybierz przycisk OK.
Przejdź do karty Monitor znajdującej się na lewym pasku bocznym. Widoczne jest uruchomienie potoku, które zostało wyzwolone za pomocą wyzwalacza ręcznego.
Po pomyślnym zakończeniu przebiegu potoku wybierz link w kolumnie Nazwa potoku , aby wyświetlić szczegóły przebiegu działania lub ponownie uruchomić potok. W tym przykładzie istnieje tylko jedno działanie, dlatego na liście jest widoczny tylko jeden wpis.
Aby uzyskać szczegółowe informacje na temat operacji kopiowania, wybierz link Szczegóły (ikona okularów) w kolumnie Nazwa działania. Możesz monitorować szczegóły, takie jak ilość danych skopiowanych ze źródła do ujścia, przepływność danych, kroki wykonywania z odpowiednim czasem trwania i używane konfiguracje.

Aby wrócić do widoku przebiegów potoku, wybierz link Wszystkie uruchomienia potoku u góry. Wybierz pozycję Odśwież, aby odświeżyć listę.
Sprawdź, czy dane są poprawnie zapisywane w dedykowanej puli SQL.
Dalsze kroki
Przejdź do następującego artykułu, aby dowiedzieć się więcej o obsłudze usługi Azure Synapse Analytics: