Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Z tego samouczka dowiesz się, jak wykonywać eksploracyjne analizy danych przy użyciu zestawów danych Platformy Azure Open i platformy Apache Spark. Następnie możesz zwizualizować wyniki w notesie programu Synapse Studio w usłudze Azure Synapse Analytics.
W szczególności przeanalizujemy zestaw danych Taksówek w Nowym Jorku (NYC). Dane są dostępne za pośrednictwem usługi Azure Open Datasets. Ten podzestaw zestawu danych zawiera informacje o żółtych przejazdach taksówkami: informacje o każdej podróży, godzinie rozpoczęcia i zakończenia oraz lokalizacjach, kosztach i innych interesujących atrybutach.
Zanim rozpoczniesz
Utwórz pulę platformy Apache Spark, postępując zgodnie z samouczkiem Tworzenie puli platformy Apache Spark.
Pobieranie i przygotowywanie danych
Utwórz notes przy użyciu jądra PySpark. Aby uzyskać instrukcje, zobacz Tworzenie notesu.
Uwaga / Notatka
Ze względu na jądro PySpark nie trzeba jawnie tworzyć żadnych kontekstów. Kontekst platformy Spark jest automatycznie tworzony podczas uruchamiania pierwszej komórki kodu.
W tym samouczku zastosujemy kilka różnych bibliotek, aby pomóc w wizualizacji zestawu danych. Aby wykonać tę analizę, zaimportuj następujące biblioteki:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pdPonieważ nieprzetworzone dane są w formacie Parquet, możesz użyć kontekstu platformy Spark, aby bezpośrednio ściągnąć plik do pamięci jako ramkę danych. Utwórz ramkę danych platformy Spark, pobierając dane za pośrednictwem interfejsu API Open Datasets. W tym miejscu używamy funkcji schema on read w ramce danych Spark, aby wywnioskować typy danych i schemat.
from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())Po odczytaniu danych należy wykonać wstępne filtrowanie, aby wyczyścić zestaw danych. Możemy usunąć niepotrzebne kolumny i dodać kolumny, które wyodrębnią ważne informacje. Ponadto odfiltrujemy anomalie w zestawie danych.
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
Analizowanie danych
Jako analityk danych masz szeroką gamę narzędzi, które ułatwiają wyodrębnianie szczegółowych informacji z danych. W tej części samouczka omówimy kilka przydatnych narzędzi dostępnych w notesach usługi Azure Synapse Analytics. W tej analizie chcemy zrozumieć czynniki, które w wybranym przez nas okresie prowadzą do wyższych napiwków dla taksówek.
Apache Spark SQL Magic
Najpierw wykonamy eksploracyjne analizy danych za pomocą języka Apache Spark SQL i poleceń magic za pomocą notesu usługi Azure Synapse. Po wykonaniu zapytania zwizualizujemy wyniki przy użyciu wbudowanej chart options funkcji.
W notesie utwórz nową komórkę i skopiuj następujący kod. Chcemy zrozumieć, jak średnie kwoty napiwków zmieniały się w wybranym okresie, korzystając z tego zapytania. To zapytanie pomoże nam również zidentyfikować inne przydatne szczegółowe informacje, w tym minimalną/maksymalną kwotę napiwku dziennie i średnią kwotę opłaty.
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASCPo zakończeniu działania zapytania możemy zwizualizować wyniki, przełączając się do widoku wykresu. W tym przykładzie tworzony jest wykres liniowy, określając
day_of_monthpole jako klucz iavgTipAmountjako wartość. Po wybraniu opcji wybierz pozycję Zastosuj , aby odświeżyć wykres.
Wizualizowanie danych
Oprócz wbudowanych opcji tworzenia wykresów notesów można tworzyć własne wizualizacje przy użyciu popularnych bibliotek typu open source. W poniższych przykładach użyjemy bibliotek Seaborn i Matplotlib. Są to często używane biblioteki języka Python do wizualizacji danych.
Uwaga / Notatka
Domyślnie każda pula platformy Apache Spark w usłudze Azure Synapse Analytics zawiera zestaw często używanych i domyślnych bibliotek. Pełną listę bibliotek można wyświetlić w dokumentacji środowiska uruchomieniowego usługi Azure Synapse . Ponadto, aby udostępnić kod innej firmy lub kod lokalny dla twoich aplikacji, możesz zainstalować bibliotekę w jednej z pul Spark.
Aby ułatwić tworzenie i obniżyć koszty programowania, obniżymy poziom próbkowania zestawu danych. Użyjemy wbudowanej funkcji próbkowania platformy Apache Spark. Ponadto zarówno biblioteki Seaborn, jak i Matplotlib wymagają tablicy Pandas DataFrame lub NumPy. Aby uzyskać ramkę danych biblioteki Pandas, użyj polecenia
toPandas(), aby ją przekonwertować.# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()Chcemy zrozumieć dystrybucję porad w naszym zestawie danych. Użyjemy biblioteki Matplotlib do utworzenia histogramu pokazującego rozkład kwoty napiwków i liczby. Na podstawie rozkładu widać, że napiwki są przechylone w stronę kwot mniejszych lub równych 10 $.
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()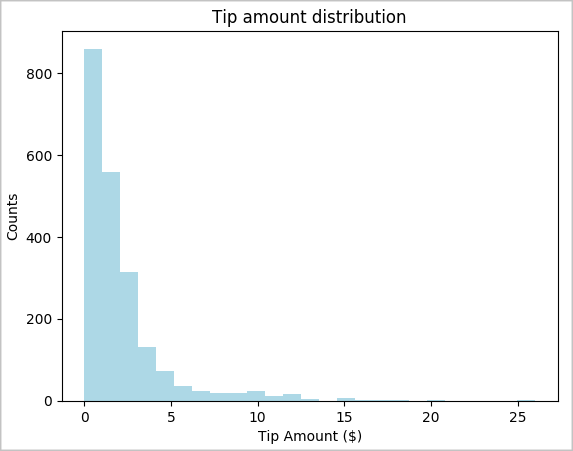
Następnie chcemy zrozumieć relację między poradami dotyczącymi danej podróży a dniem tygodnia. Użyj platformy Seaborn, aby utworzyć wykres skrzynkowy, który podsumowuje trendy dla każdego dnia tygodnia.
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()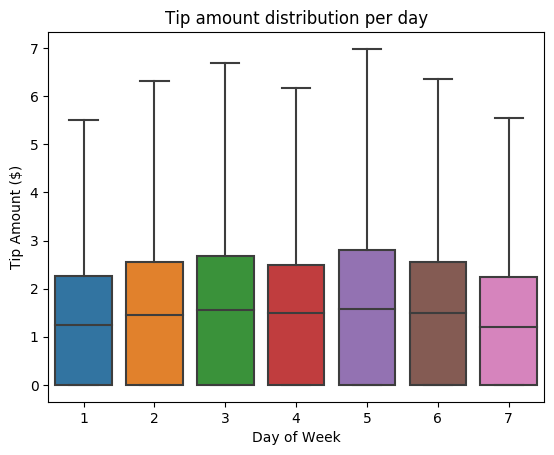
Nasza inna hipoteza może być taka, że istnieje pozytywny związek między liczbą pasażerów a całkowitą kwotą napiwków taksówek. Aby zweryfikować tę relację, uruchom następujący kod, aby wygenerować wykres skrzynkowy ilustrujący rozkład napiwków w zależności od liczby pasażerów.
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()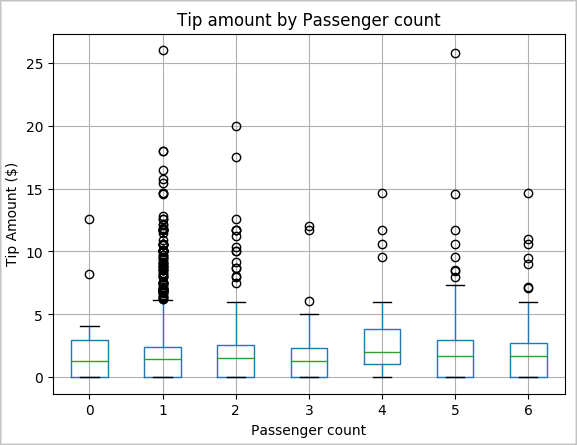
Na koniec chcemy zrozumieć relację między kwotą taryfy a kwotą napiwku. Na podstawie wyników widać, że istnieje kilka sytuacji, w których ludzie nie dają napiwków. Jednak widzimy również pozytywny związek między ogólną taryfą a kwotami napiwków.
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()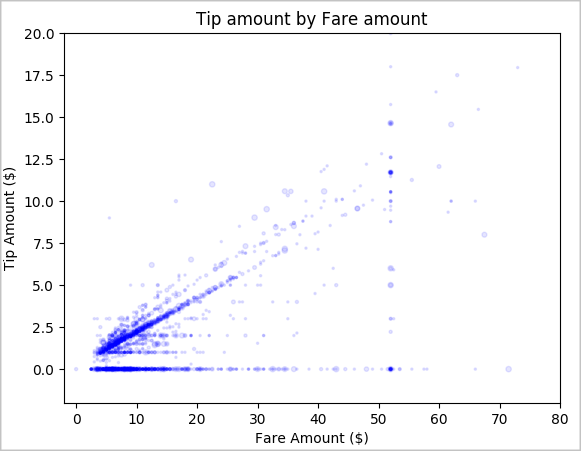
Wyłącz wystąpienie Spark
Po zakończeniu uruchamiania aplikacji zamknij notes, aby zwolnić zasoby. Zamknij kartę lub wybierz pozycję Zakończ sesję z panelu stanu w dolnej części notesu.
Zobacz także
- Omówienie: Platforma Apache Spark w usłudze Azure Synapse Analytics
- Tworzenie modelu uczenia maszynowego przy użyciu języka Apache SparkML