Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Z tego przewodnika Szybki start dowiesz się, jak utworzyć bezserwerową pulę platformy Apache Spark w usłudze Azure Synapse przy użyciu narzędzi internetowych. Następnie dowiesz się, jak nawiązać połączenie z pulą platformy Apache Spark i uruchamiać zapytania Spark SQL dotyczące plików i tabel. Platforma Apache Spark umożliwia szybką analizę danych i przetwarzanie klastrów przy użyciu przetwarzania w pamięci. Aby uzyskać informacje na temat platformy Spark w usłudze Azure Synapse, zobacz Omówienie: Apache Spark w usłudze Azure Synapse.
Ważne
Rozliczanie instancji Spark odbywa się proporcjonalnie do minuty, niezależnie od tego, czy są używane. Pamiętaj, aby zamknąć instancję Spark po zakończeniu korzystania z niego lub ustawić krótki czas oczekiwania. Aby uzyskać więcej informacji, zobacz sekcję Czyszczenie zasobów w tym artykule.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
- Konieczna jest subskrypcja platformy Azure. W razie potrzeby utwórz bezpłatne konto platformy Azure
- Obszar roboczy usługi Synapse Analytics
- Bezserwerowa pula platformy Apache Spark
Zaloguj się do witryny Azure Portal
Zaloguj się w witrynie Azure Portal.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto platformy Azure.
Tworzenie notesu
Notatnik to interaktywne środowisko, które obsługuje różne języki programowania. Notatnik umożliwia interakcję z danymi, łączenie kodu z Markdownem i tekstem, a także wykonywanie prostych wizualizacji.
W widoku witryny Azure Portal dla obszaru roboczego usługi Azure Synapse, którego chcesz użyć, wybierz pozycję Uruchom program Synapse Studio.
Po uruchomieniu programu Synapse Studio wybierz pozycję Opracuj. Następnie wybierz ikonę "+", aby dodać nowy zasób.
W tym miejscu wybierz pozycję Notatnik. Zostanie utworzony i otwarty nowy notes z automatycznie wygenerowaną nazwą.

W oknie Właściwości podaj nazwę notesu.
Na pasku narzędzi kliknij pozycję Publikuj.
Jeśli w obszarze roboczym znajduje się tylko jedna pula platformy Apache Spark, jest ona domyślnie wybrana. Użyj listy rozwijanej, aby wybrać poprawną pulę Apache Spark, jeśli żadna nie została wybrana.
Kliknij pozycję Dodaj kod. Domyślnym językiem jest
Pyspark. Użyjesz kombinacji narzędzi Pyspark i Spark SQL, więc wybór domyślny jest odpowiedni. Inne obsługiwane języki to Scala i .NET dla platformy Spark.Następnie utworzysz prosty obiekt ramki danych Spark do manipulowania. W tym przypadku utworzysz go na podstawie kodu. Istnieją trzy wiersze i trzy kolumny:
new_rows = [('CA',22, 45000),("WA",35,65000) ,("WA",50,85000)] demo_df = spark.createDataFrame(new_rows, ['state', 'age', 'salary']) demo_df.show()Teraz uruchom komórkę przy użyciu jednej z następujących metod:
Naciśnij SHIFT + ENTER.
Wybierz niebieską ikonę odtwarzania po lewej stronie komórki.
Wybierz przycisk Uruchom wszystko na pasku narzędzi.
Jeśli instancja puli platformy Apache Spark nie jest jeszcze uruchomiona, zostanie ona uruchomiona automatycznie. Stan wystąpienia puli Apache Spark można zobaczyć poniżej uruchamianej komórki, a także na panelu stanu w dolnej części notebooka. W zależności od rozmiaru basenu, rozpoczęcie powinno potrwać od 2 do 5 minut. Po zakończeniu działania kodu poniżej komórki zostaną wyświetlone informacje pokazujące, jak długo trwało uruchomienie i jego wykonanie. W komórce wyjściowej widzisz dane wyjściowe.
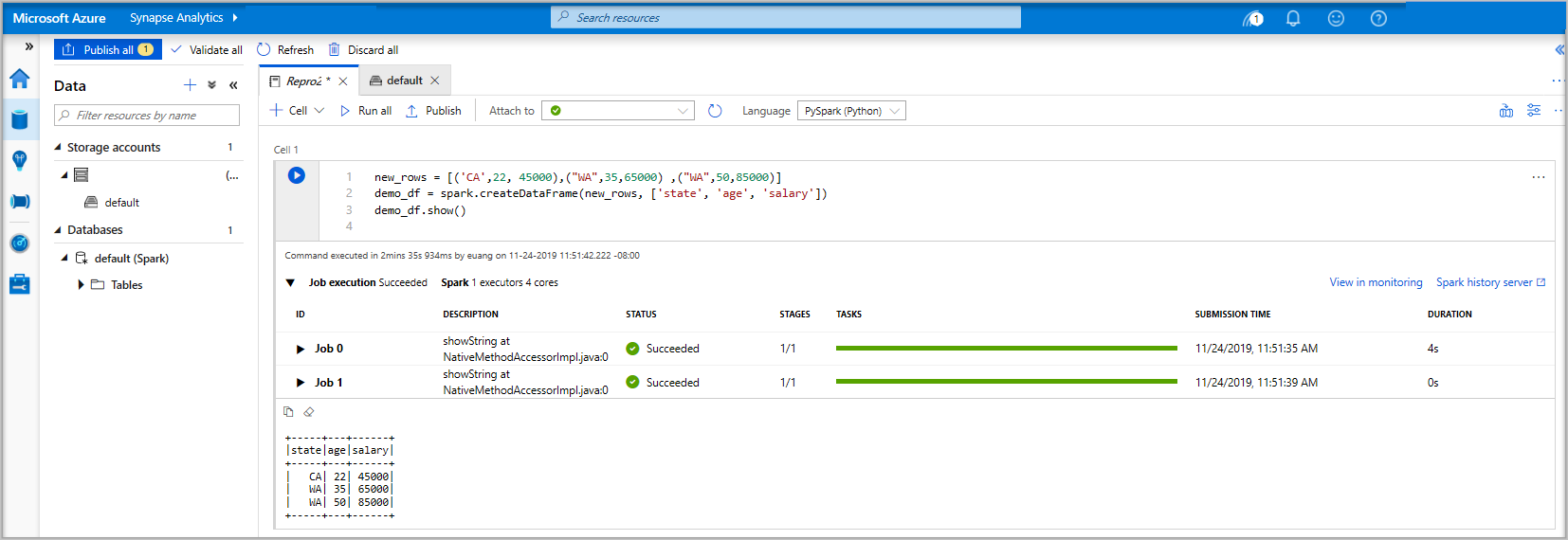
Dane istnieją teraz w ramce danych, z której można korzystać na wiele różnych sposobów. Będziesz potrzebować go w różnych formatach w pozostałej części tego przewodnika Szybki start.
Wprowadź poniższy kod w innej komórce i uruchom go. Spowoduje to utworzenie tabeli Spark, pliku CSV i pliku Parquet ze wszystkimi kopiami danych:
demo_df.createOrReplaceTempView('demo_df') demo_df.write.csv('demo_df', mode='overwrite') demo_df.write.parquet('abfss://<<TheNameOfAStorageAccountFileSystem>>@<<TheNameOfAStorageAccount>>.dfs.core.windows.net/demodata/demo_df', mode='overwrite')Jeśli używasz Eksploratora pamięci masowej, możesz zobaczyć, jak wpływają dwa różne sposoby zapisu pliku wykorzystywane powyżej. Jeśli system plików nie zostanie określony, zostanie użyty domyślny, w tym przypadku
default>user>trusted-service-user>demo_df. Dane są zapisywane w lokalizacji określonego systemu plików.Zwróć uwagę, że zarówno podczas operacji zapisu w formatach "csv", jak i "parquet", tworzony jest katalog z wieloma plikami podzielonymi na partycje.


Uruchamianie instrukcji Spark SQL
Język SQL (Structured Query Language) jest najczęściej używanym językiem do wykonywania zapytań i definiowania danych. Rozwiązanie Spark SQL stanowi rozszerzenie platformy Apache Spark służące do przetwarzania danych strukturalnych za pomocą dobrze znanej składni języka SQL.
Wklej następujący kod w pustej komórce, a następnie uruchom kod. Polecenie wyświetla listę tabel w puli.
%%sql SHOW TABLESJeśli używasz notatnika z pulą usługi Azure Synapse Apache Spark, otrzymasz predefiniowane ustawienie
sqlContext, którego możesz użyć do uruchamiania zapytań za pomocą Spark SQL.%%sqlpoleca, aby notes użył ustawienia wstępnegosqlContextdo uruchomienia zapytania. Zapytanie pobiera 10 pierwszych wierszy z tabeli systemowej, która jest domyślnie dostarczana ze wszystkimi pulami platformy Apache Spark w usłudze Azure Synapse.Uruchom inne zapytanie, aby wyświetlić dane z tabeli
demo_df.%%sql SELECT * FROM demo_dfKod tworzy dwie komórki wyjściowe, z których jedna zawiera wyniki danych, a drugi wyświetla widok zadania.
Domyślnie w widoku wyników jest wyświetlana siatka. Istnieje jednak przełącznik widoków pod siatką, który umożliwia przełączanie widoku między widokami siatki i grafów.

W przełączniku Widoki wybierz Wykres.
Wybierz ikonę Wyświetl opcje z prawej strony.
W polu Typ wykresu wybierz pozycję "Wykres słupkowy".
W polu kolumny osi X wybierz pozycję "state".
W polu kolumny oś Y wybierz pozycję "wynagrodzenie".
W polu Agregacja wybierz pozycję "AVG".
Wybierz i zastosuj.

Istnieje możliwość uzyskania tego samego środowiska uruchamiania języka SQL, ale bez konieczności przełączania języków. Można to zrobić, zastępując komórkę SQL powyżej tą komórką PySpark, środowisko wyjściowe jest takie samo, ponieważ jest używane polecenie wyświetlania :
display(spark.sql('SELECT * FROM demo_df'))Każda z wykonanych wcześniej komórek miała opcję przejścia na serwer historii i monitorowanie. Kliknięcie linków spowoduje przejście do różnych części środowiska użytkownika.
Uwaga
Niektóre oficjalne dokumenty platformy Apache Spark korzystają z konsoli Spark, która nie jest dostępna na platformie Synapse Spark. Zamiast tego użyj notesu lub środowiska IntelliJ .
Czyszczenie zasobów
Usługa Azure Synapse zapisuje dane w usłudze Azure Data Lake Storage. Możesz bezpiecznie zezwolić na zamknięcie wystąpienia platformy Spark, gdy nie jest ono używane. Opłaty są naliczane za bezserwerową pulę Apache Spark tak długo, jak jest uruchomiona, nawet jeśli nie jest używana.
Ponieważ opłaty za pulę są wielokrotnie większe niż opłaty za magazyn, warto ekonomicznie umożliwić zamykanie wystąpień platformy Spark, gdy nie są używane.
Aby upewnić się, że wystąpienie Spark jest wyłączone, zakończ wszystkie aktywne sesje (notatniki). Zasób zostanie zamknięty, gdy w puli Apache Spark zostanie osiągnięty określony czas bezczynności. Możesz również wybrać pozycję Zakończ sesję na pasku stanu w dolnej części notesu.
Następne kroki
W tym przewodniku Szybki start przedstawiono sposób tworzenia bezserwerowej puli platformy Apache Spark i uruchamiania podstawowego zapytania Spark SQL.