Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Inteligentna pamięć podręczna działa bezproblemowo w tle i buforuje dane, aby przyspieszyć wykonywanie platformy Spark podczas odczytywania z magazynu data lake usługi ADLS Gen2. Automatycznie wykrywa również zmiany w plikach bazowych i automatycznie odświeża pliki w pamięci podręcznej, zapewniając najnowsze dane i gdy rozmiar pamięci podręcznej osiągnie limit, pamięć podręczna automatycznie zwolni najmniej odczytywane dane, aby zwolnić miejsce na najnowsze dane. Ta funkcja obniża całkowity koszt posiadania, zwiększając wydajność do 65% kolejnych odczytów plików przechowywanych w dostępnej pamięci podręcznej dla plików Parquet i 50% dla plików CSV.
Podczas wykonywania zapytań dotyczących pliku lub tabeli z magazynu data lake aparat Apache Spark w usłudze Synapse wykona wywołanie zdalnego magazynu usługi ADLS Gen2 w celu odczytania źródłowych plików. Przy każdym żądaniu zapytania odczytu tych samych danych aparat Spark musi wykonać wywołanie zdalnego magazynu usługi ADLS Gen2. Ten nadmiarowy proces dodaje opóźnienie do łącznego czasu przetwarzania. Platforma Spark udostępnia funkcję buforowania, którą należy ręcznie ustawić i zwolnić pamięć podręczną, aby zminimalizować opóźnienia i poprawić ogólną wydajność. Może to jednak spowodować, że wyniki będą miały nieaktualne dane, jeśli bazowe dane się zmienią.
Inteligentna pamięć podręczna usługi Synapse upraszcza ten proces przez automatyczne buforowanie każdego odczytu w ramach przydzielonego miejsca do magazynowania pamięci podręcznej na każdym węźle platformy Spark. Każde żądanie pliku sprawdza, czy plik istnieje w pamięci podręcznej i porównuje tag z magazynu zdalnego, aby ustalić, czy plik jest nieaktualny. Jeśli plik nie istnieje lub plik jest nieaktualny, platforma Spark odczytuje plik i zapisze go w pamięci podręcznej. Gdy pamięć podręczna stanie się pełna, plik o najstarszym ostatnim czasie dostępu zostanie wykluczony z pamięci podręcznej, aby umożliwić korzystanie z nowszych plików.
Pamięć podręczna usługi Synapse to pojedyncza pamięć podręczna na węzeł. Jeśli używasz węzła o średnim rozmiarze i uruchamiasz z dwoma małymi funkcjami wykonawczych w jednym węźle o średnim rozmiarze, te dwie funkcje wykonawcze będą współdzielić tę samą pamięć podręczną.
Włączanie lub wyłączanie pamięci podręcznej
Rozmiar pamięci podręcznej można dostosować na podstawie procentu całkowitego rozmiaru dysku dostępnego dla każdej puli platformy Apache Spark. Domyślnie pamięć podręczna jest ustawiona na wyłączoną, ale jest tak prosta, jak przeniesienie paska suwaka z 0 (wyłączone) do żądanej wartości procentowej rozmiaru pamięci podręcznej w celu jej włączenia. Rezerwujemy co najmniej 20% dostępnego miejsca na dysku na potrzeby mieszania danych. W przypadku obciążeń intensywnie korzystających z mieszania można zminimalizować rozmiar pamięci podręcznej lub wyłączyć pamięć podręczną. Zalecamy rozpoczęcie od rozmiaru pamięci podręcznej 50% i dostosowanie go w razie potrzeby. Należy pamiętać, że jeśli obciążenie wymaga dużo miejsca na lokalnym dysku SSD na potrzeby mieszania lub buforowania RDD, rozważ zmniejszenie rozmiaru pamięci podręcznej, aby zmniejszyć prawdopodobieństwo awarii z powodu niewystarczającej ilości miejsca w magazynie. Rzeczywisty rozmiar dostępnego magazynu i rozmiar pamięci podręcznej w każdym węźle zależy od rodziny węzłów i rozmiaru węzła.
Włączanie pamięci podręcznej dla nowych pul platformy Spark
Podczas tworzenia nowej puli Platformy Spark przejdź na karcie dodatkowe ustawienia , aby znaleźć suwak Inteligentnej pamięci podręcznej , który można przenieść do preferowanego rozmiaru, aby włączyć tę funkcję.

Włączanie/wyłączanie pamięci podręcznej dla istniejących pul platformy Spark
W przypadku istniejących pul platformy Spark przejdź do pozycji Ustawienia skalowania wybranej puli platformy Apache Spark, aby ją włączyć, przesuwając suwak na wartość większą niż 0 lub wyłączając ją, przesuwając suwak na 0.
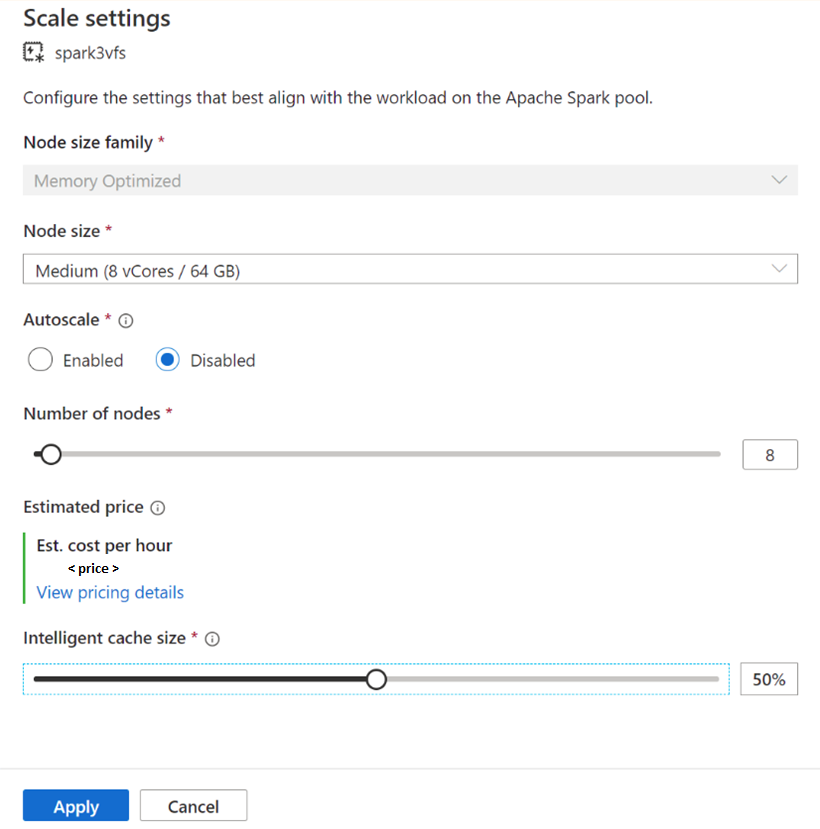
Zmiana rozmiaru pamięci podręcznej dla istniejących pul platformy Spark
Aby zmienić rozmiar inteligentnej pamięci podręcznej puli, należy wymusić ponowne uruchomienie, jeśli pula ma aktywne sesje. Jeśli pula Spark ma aktywną sesję, zostanie wyświetlona wartość Wymuś nowe ustawienia. Kliknij pole wyboru i wybierz pozycję Zastosuj , aby automatycznie ponownie uruchomić sesję.

Włączanie i wyłączanie pamięci podręcznej w ramach sesji
Łatwo wyłącz inteligentną pamięć podręczną w ramach sesji, uruchamiając następujący kod w notesie:
%spark
spark.conf.set("spark.synapse.vegas.useCache", "false")
%pyspark
spark.conf.set('spark.synapse.vegas.useCache', 'false')
I włącz, uruchamiając polecenie:
%spark
spark.conf.set("spark.synapse.vegas.useCache", "true")
%pyspark
spark.conf.set('spark.synapse.vegas.useCache', 'true')
Kiedy należy używać inteligentnej pamięci podręcznej i kiedy nie?
Ta funkcja będzie korzyść w następujących przypadkach:
Obciążenie wymaga wielokrotnego odczytywania tego samego pliku, a rozmiar pliku może mieścić się w pamięci podręcznej.
Obciążenie używa tabel delty, formatów plików parquet i plików CSV.
Używasz platformy Apache Spark 3 lub nowszej w usłudze Azure Synapse.
Korzyści z tej funkcji nie będą widoczne, jeśli:
Odczytujesz plik, który przekracza rozmiar pamięci podręcznej, ponieważ początek plików może zostać wykluczony, a kolejne zapytania będą musiały ponownie pobrać dane z magazynu zdalnego. W takim przypadku nie zobaczysz żadnych korzyści z inteligentnej pamięci podręcznej i możesz zwiększyć rozmiar pamięci podręcznej i/lub rozmiar węzła.
Obciążenie wymaga dużych ilości mieszania, a następnie wyłączenie inteligentnej pamięci podręcznej zwolni dostępne miejsce, aby zapobiec awarii zadania z powodu niewystarczającej ilości miejsca do magazynowania.
Używasz puli platformy Spark 3.3, musisz uaktualnić pulę do najnowszej wersji platformy Spark.
Dowiedz się więcej
Aby dowiedzieć się więcej na temat platformy Apache Spark, zobacz następujące artykuły:
- Co to jest platforma Apache Spark
- Podstawowe pojęcia dotyczące platformy Apache Spark
- Rozmiary i konfiguracje puli platformy Apache Spark
Aby dowiedzieć się więcej o konfigurowaniu ustawień sesji platformy Spark
- Konfigurowanie ustawień sesji platformy Spark
- Jak ustawić niestandardowe konfiguracje platformy Spark/Pyspark
Dalsze kroki
Pula platformy Apache Spark udostępnia funkcje obliczeniowe danych big data typu open source, w których można ładować, modelować, przetwarzać i dystrybuować w celu szybszego analizowania. Aby dowiedzieć się więcej na temat tworzenia jednego do uruchamiania obciążeń platformy Spark, odwiedź następujące samouczki: