Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Usługa Azure Synapse Analytics oferuje różne aparaty analityczne, które ułatwiają pozyskiwanie, przekształcanie, modelowanie, analizowanie i dystrybuowanie danych. Pula Apache Spark zapewnia open-source'owe możliwości obliczeniowe dla danych big data. Po utworzeniu puli platformy Apache Spark w obszarze roboczym usługi Synapse można ładować, modelować, przetwarzać i dystrybuować dane w celu uzyskania szybszych analiz analitycznych.
W tym szybkim przewodniku dowiesz się, jak za pomocą portalu Azure utworzyć pulę Apache Spark w workspacie Synapse.
Ważne
Rozliczanie instancji Spark odbywa się proporcjonalnie do minuty, niezależnie od tego, czy są używane. Pamiętaj, aby zamknąć instancję Spark po zakończeniu korzystania z niego lub ustawić krótki czas oczekiwania. Aby uzyskać więcej informacji, zobacz sekcję Czyszczenie zasobów w tym artykule.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
- Konieczna jest subskrypcja platformy Azure. W razie potrzeby utwórz bezpłatne konto platformy Azure
- Będziesz używać obszaru roboczego Synapse.
Zaloguj się do witryny Azure Portal
Zaloguj się do witryny Azure Portal.
Przejdź do obszaru roboczego usługi Synapse
Przejdź do obszaru roboczego usługi Synapse, w którym zostanie utworzona pula platformy Apache Spark, wpisując nazwę usługi (lub nazwę zasobu bezpośrednio) na pasku wyszukiwania.
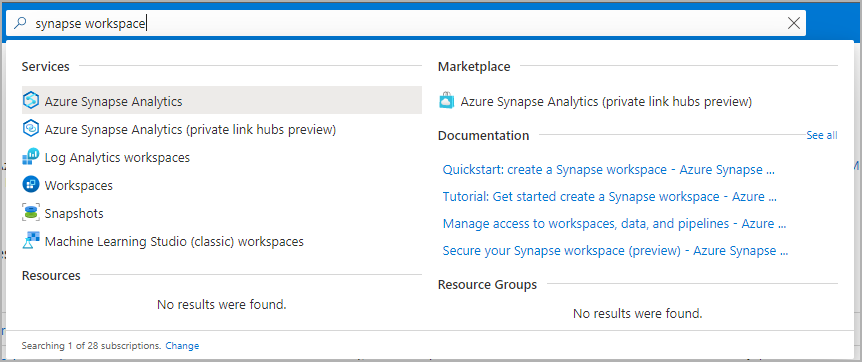
Z listy obszarów roboczych wpisz nazwę (lub część nazwy) obszaru roboczego do otwarcia. W tym przykładzie używamy obszaru roboczego o nazwie contosoanalytics.
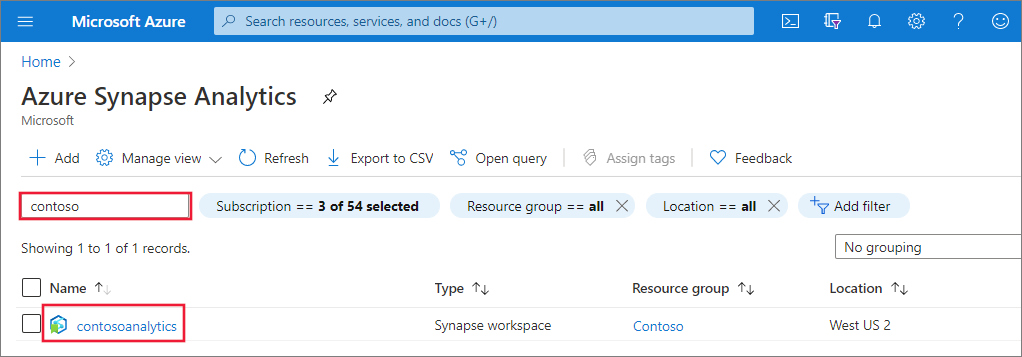


Utwórz nową pulę Apache Spark
W obszarze roboczym usługi Synapse, w którym chcesz utworzyć pulę platformy Apache Spark, wybierz pozycję Nowa pula platformy Apache Spark.
Wprowadź następujące szczegóły na karcie Podstawy :
Ustawienie Sugerowana wartość Opis Nazwa puli Apache Spark Prawidłowa nazwa puli, na przykład contososparkJest to nazwa, którą będzie miała pula Apache Spark. Rozmiar węzła Mały (4 procesory wirtualne / 32 GB) Ustaw ten rozmiar na najmniejszy, aby zmniejszyć koszty tej szybkiej instrukcji. Autoskalowanie Niepełnosprawny Dla tej szybkiej konfiguracji nie potrzebujemy automatycznego skalowania. Liczba węzłów 5 Użyj małego rozmiaru, aby ograniczyć koszty dla tego szybkiego startu 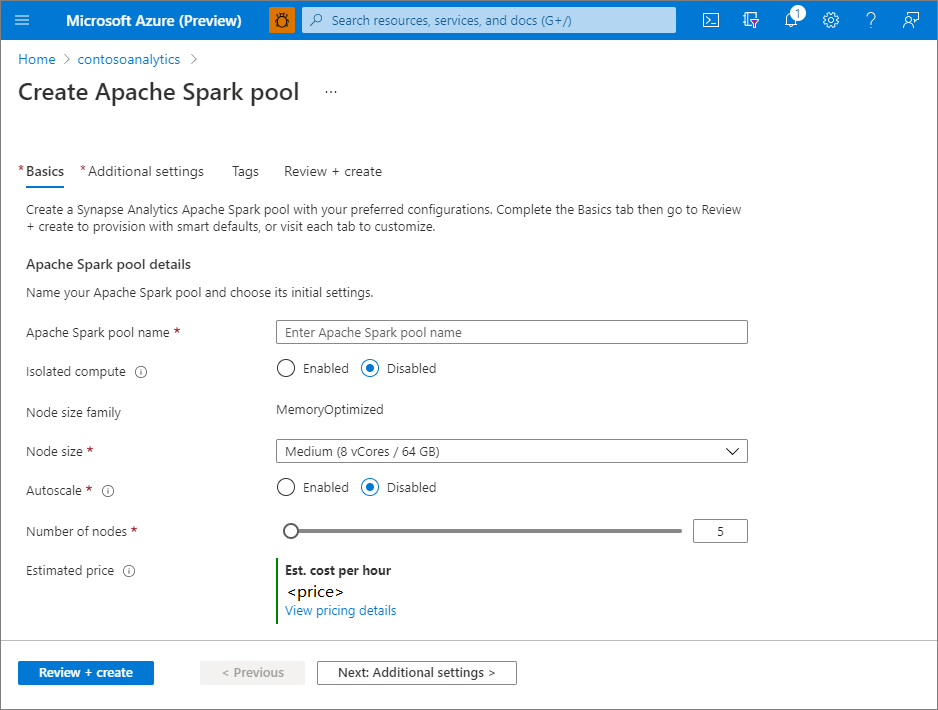
Ważne
Istnieją określone ograniczenia dotyczące nazw, których mogą używać pule platformy Apache Spark. Nazwy muszą zawierać tylko litery lub cyfry, muszą zawierać co najmniej 15 znaków, muszą zaczynać się literą, nie zawierać wyrazów zarezerwowanych i być unikatowe w obszarze roboczym.
Wybierz pozycję Dalej: dodatkowe ustawienia i przejrzyj ustawienia domyślne. Nie modyfikuj żadnych ustawień domyślnych.
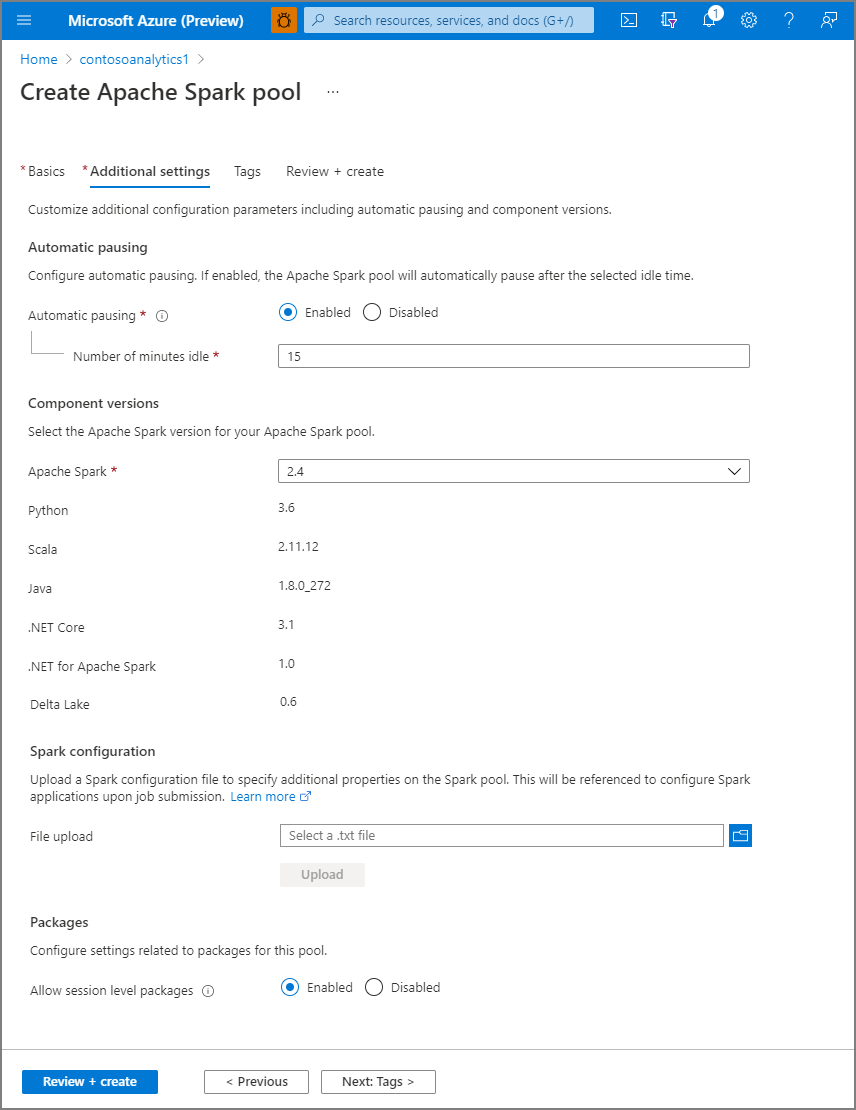
Wybierz Dalej: tagi. Rozważ użycie tagów platformy Azure. Na przykład tag "Właściciel" lub "CreatedBy", aby zidentyfikować, kto utworzył zasób, oraz tag "Środowisko", aby określić, czy ten zasób znajduje się w środowisku produkcyjnym, programistycznym itp. Aby uzyskać więcej informacji, zobacz Develop your naming and tagging strategy for Azure resources (Opracowywanie strategii nazewnictwa i tagowania zasobów platformy Azure).
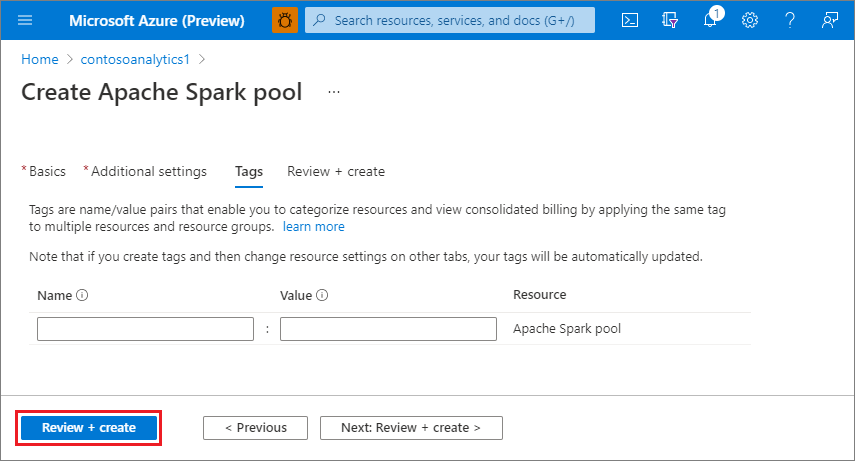
Wybierz opcję Recenzja i utwórz.
Upewnij się, że szczegóły wyglądają poprawnie w zależności od tego, co zostało wcześniej wprowadzone, i wybierz pozycję Utwórz.
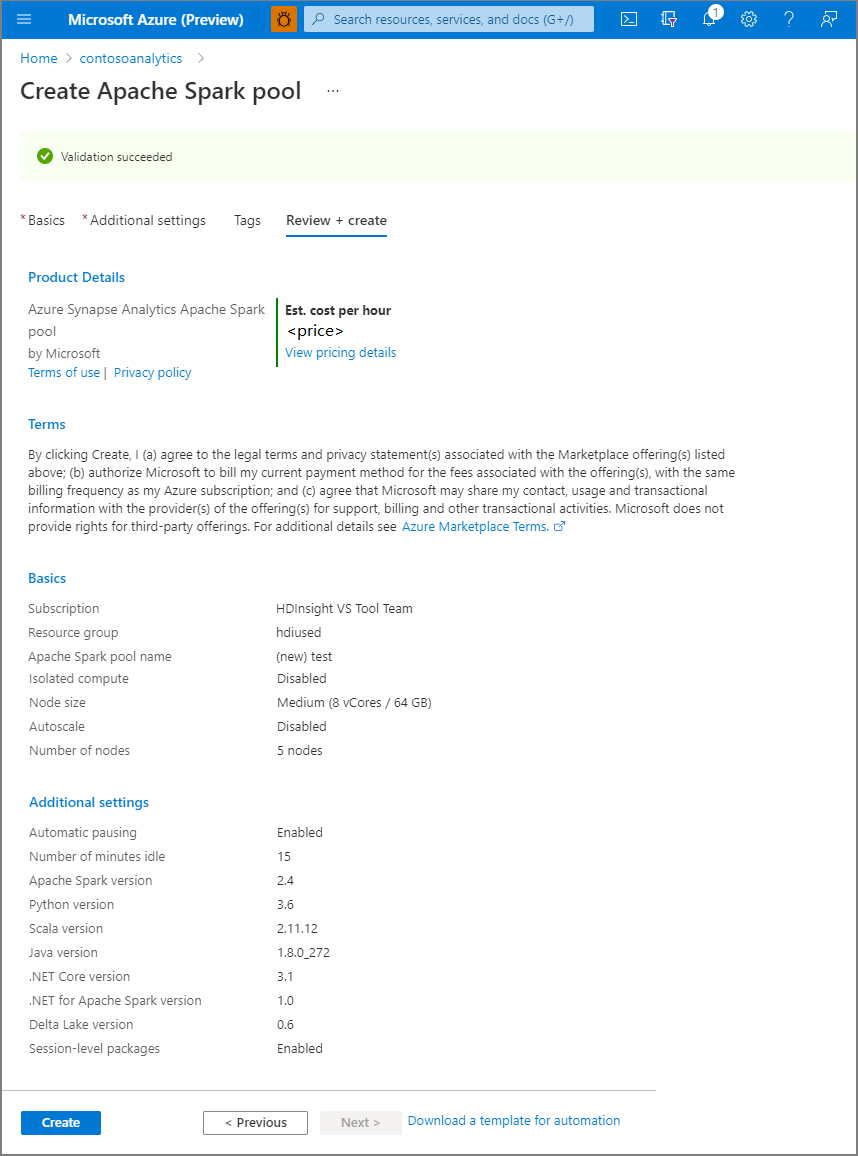
W tym momencie rozpocznie się proces aprowizacji zasobów, który zasygnalizuje, gdy zostanie zakończony.
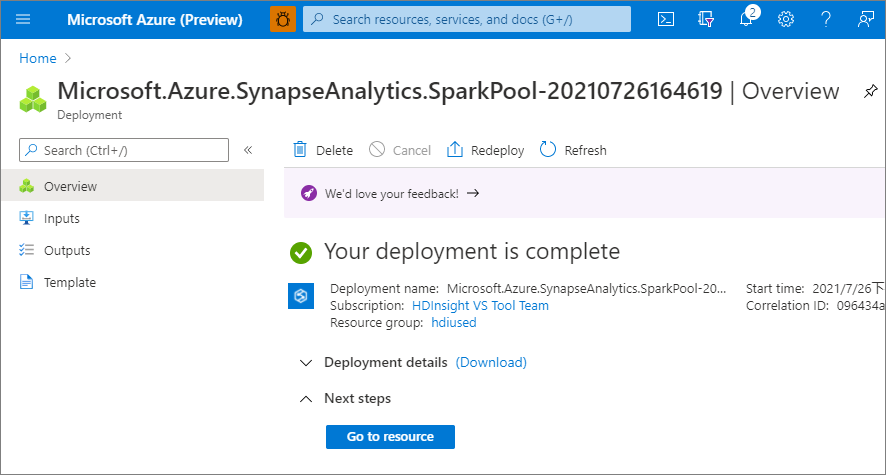
Po zakończeniu aprowizacji powrót do obszaru roboczego spowoduje wyświetlenie nowego wpisu dla nowo utworzonej puli Apache Spark.
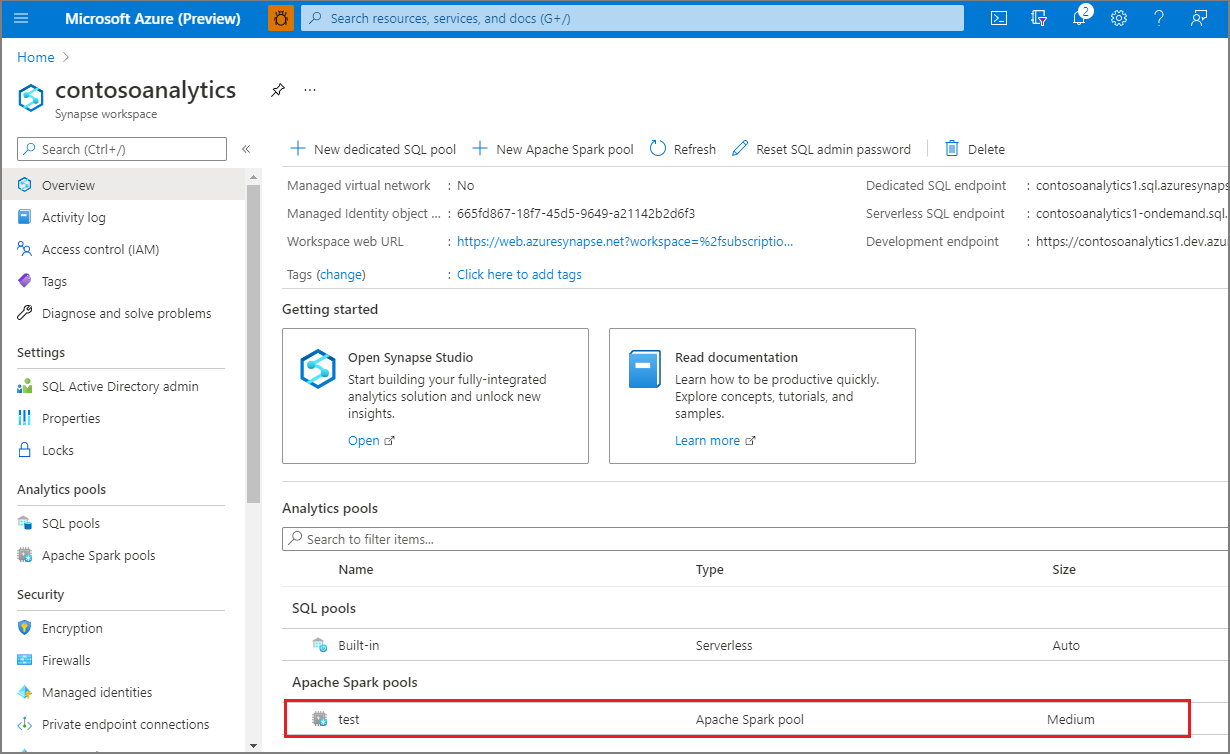
W tym momencie nie ma uruchomionych zasobów, nie są naliczane opłaty za korzystanie z platformy Spark; utworzyłeś metadane dotyczące wystąpień Spark, które zamierzasz utworzyć.







Czyszczenie zasobów
Poniższe kroki usuwają pulę Apache Spark z obszaru roboczego.
Ostrzeżenie
Usunięcie puli Apache Spark spowoduje usunięcie mechanizmu analitycznego z obszaru roboczego. Nie będzie już możliwe połączenie z klastrem, a wszystkie zapytania, przepływy danych i notesy używające tego klastra Apache Spark nie będą już działać.
Jeśli chcesz usunąć pulę platformy Apache Spark, wykonaj następujące kroki:
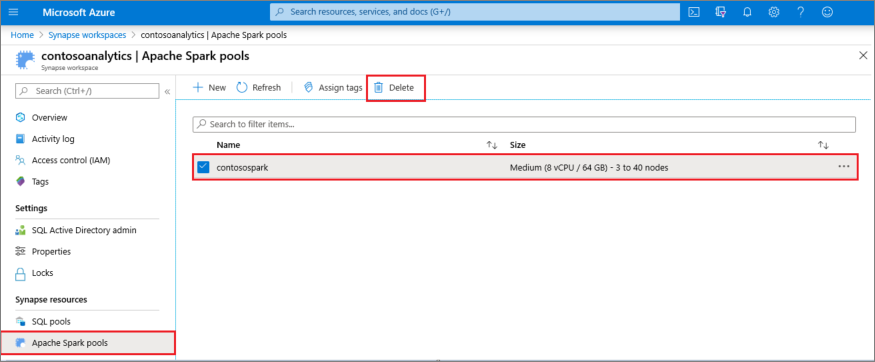
- Przejdź do panelu pul Apache Spark w obszarze roboczym.
- Wybierz pulę Apache Spark, która ma zostać usunięta (w tym przypadku contosospark).
- Wybierz Usuń.
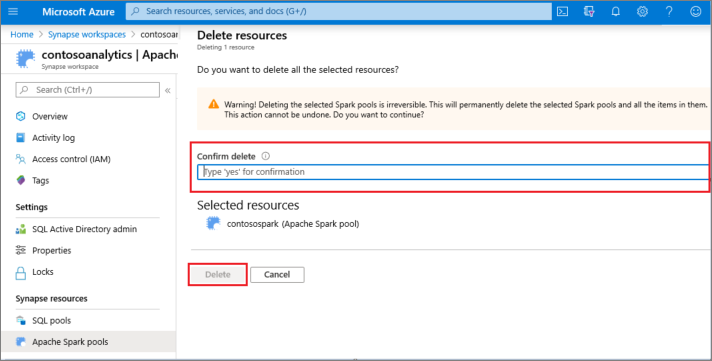
- Potwierdź usunięcie i wybierz przycisk Usuń .
- Po pomyślnym zakończeniu procesu pula platformy Apache Spark nie będzie już wyświetlana w zasobach obszaru roboczego.
