Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Apache Spark jest platformą przetwarzania równoległego, która obsługuje przetwarzanie w pamięci w celu zwiększania wydajności aplikacji do analizy danych big data. Platforma Apache Spark w usłudze Azure Synapse Analytics to jedna z implementacji platformy Apache Spark oferowanych przez firmę Microsoft w chmurze.
Usługa Azure Synapse oferuje teraz możliwość tworzenia pul z obsługą procesora GPU usługi Azure Synapse w celu uruchamiania obciążeń platformy Spark przy użyciu bazowych bibliotek RAPIDS, które używają ogromnej mocy przetwarzania równoległego procesorów GPU w celu przyspieszenia przetwarzania. Akcelerator RAPIDS dla platformy Apache Spark umożliwia uruchamianie istniejących aplikacji Spark bez żadnej zmiany kodu, włączając tylko ustawienie konfiguracji, które jest wstępnie skonfigurowane dla puli z obsługą procesora GPU. Możesz włączyć/wyłączyć przyspieszanie procesora GPU oparte na usłudze RAPIDS dla obciążenia lub części obciążenia, ustawiając następującą konfigurację:
spark.conf.set('spark.rapids.sql.enabled','true/false')
Uwaga
Wersja zapoznawcza pul z obsługą procesora GPU usługi Azure Synapse jest teraz przestarzała.
Akcelerator RAPIDS dla platformy Apache Spark
Akcelerator Spark RAPIDS to wtyczka, która działa przez zastąpienie fizycznego planu zadania platformy Spark przez obsługiwane operacje procesora GPU i uruchomienie tych operacji na procesorach GPU, co przyspiesza przetwarzanie. Ta biblioteka jest obecnie w wersji zapoznawczej i nie obsługuje wszystkich operacji platformy Spark (poniżej znajduje się lista aktualnie obsługiwanych operatorów, a większa obsługa jest dodawana przyrostowo za pośrednictwem nowych wersji).
Opcje konfiguracji klastra
Wtyczka akceleratora RAPIDS obsługuje tylko mapowanie jeden do jednego między procesorami GPU i funkcjami wykonawczych. Oznacza to, że zadanie platformy Spark musi zażądać funkcji wykonawczej i zasobów sterowników, które mogą zostać obsłużone przez zasoby puli (zgodnie z liczbą dostępnych rdzeni procesora GPU i procesora CPU). Aby spełnić ten warunek i zapewnić optymalne wykorzystanie wszystkich zasobów puli, wymagamy następującej konfiguracji sterowników i funkcji wykonawczych dla aplikacji Spark działającej w pulach z obsługą procesora GPU:
| Rozmiar puli | Opcje rozmiaru sterownika | Rdzenie sterowników | Pamięć sterownika (GB) | Rdzenie funkcji wykonawczej | Pamięć funkcji wykonawczej (GB) | Liczba funkcji wykonawczych |
|---|---|---|---|---|---|---|
| Procesor GPU — duży rozmiar | Mały sterownik | 100 | 30 | 12 | 60 | Liczba węzłów w puli |
| Procesor GPU — duży rozmiar | Średni sterownik | 7 | 30 | 9 | 60 | Liczba węzłów w puli |
| Gpu-XLarge | Średni sterownik | 8 | 40 | 14 | 80 | 4 * Liczba węzłów w puli |
| Gpu-XLarge | Duży sterownik | 12 | 40 | 13 | 80 | 4 * Liczba węzłów w puli |
Wszystkie obciążenia, które nie spełniają jednej z powyższych konfiguracji, nie zostaną zaakceptowane. Należy to zrobić, aby upewnić się, że zadania platformy Spark są uruchamiane z najbardziej wydajną i wydajną konfiguracją wykorzystującą wszystkie dostępne zasoby w puli.
Użytkownik może ustawić powyższą konfigurację za pomocą obciążenia. W przypadku notesów użytkownik może użyć %%configure polecenia magic, aby ustawić jedną z powyższych konfiguracji, jak pokazano poniżej.
Na przykład użycie dużej puli z trzema węzłami:
%%configure -f
{
"driverMemory": "30g",
"driverCores": 4,
"executorMemory": "60g",
"executorCores": 12,
"numExecutors": 3
}
Uruchamianie przykładowego zadania platformy Spark za pomocą notesu w puli przyspieszonej przez procesor GPU usługi Azure Synapse
Przed kontynuowaniem tej sekcji warto zapoznać się z podstawowymi pojęciami dotyczącymi używania notesu w usłudze Azure Synapse Analytics. Zapoznajmy się z krokami uruchamiania aplikacji Platformy Spark korzystającej z przyspieszania procesora GPU. Aplikację Platformy Spark można napisać we wszystkich czterech językach obsługiwanych w usługach Synapse, PySpark (Python), Spark (Scala), SparkSQL i .NET for Spark (C#).
Utwórz pulę z obsługą procesora GPU.
Utwórz notes i dołącz go do puli z obsługą procesora GPU utworzonej w pierwszym kroku.
Ustaw konfiguracje zgodnie z wyjaśnieniem w poprzedniej sekcji.
Utwórz przykładową ramkę danych, kopiując poniższy kod w pierwszej komórce notesu:
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.Row
import scala.collection.JavaConversions._
val schema = StructType( Array(
StructField("emp_id", IntegerType),
StructField("name", StringType),
StructField("emp_dept_id", IntegerType),
StructField("salary", IntegerType)
))
val emp = Seq(Row(1, "Smith", 10, 100000),
Row(2, "Rose", 20, 97600),
Row(3, "Williams", 20, 110000),
Row(4, "Jones", 10, 80000),
Row(5, "Brown", 40, 60000),
Row(6, "Brown", 30, 78000)
)
val empDF = spark.createDataFrame(emp, schema)
- Teraz wykonajmy agregację, uzyskując maksymalną pensję na identyfikator działu i wyświetlając wynik:
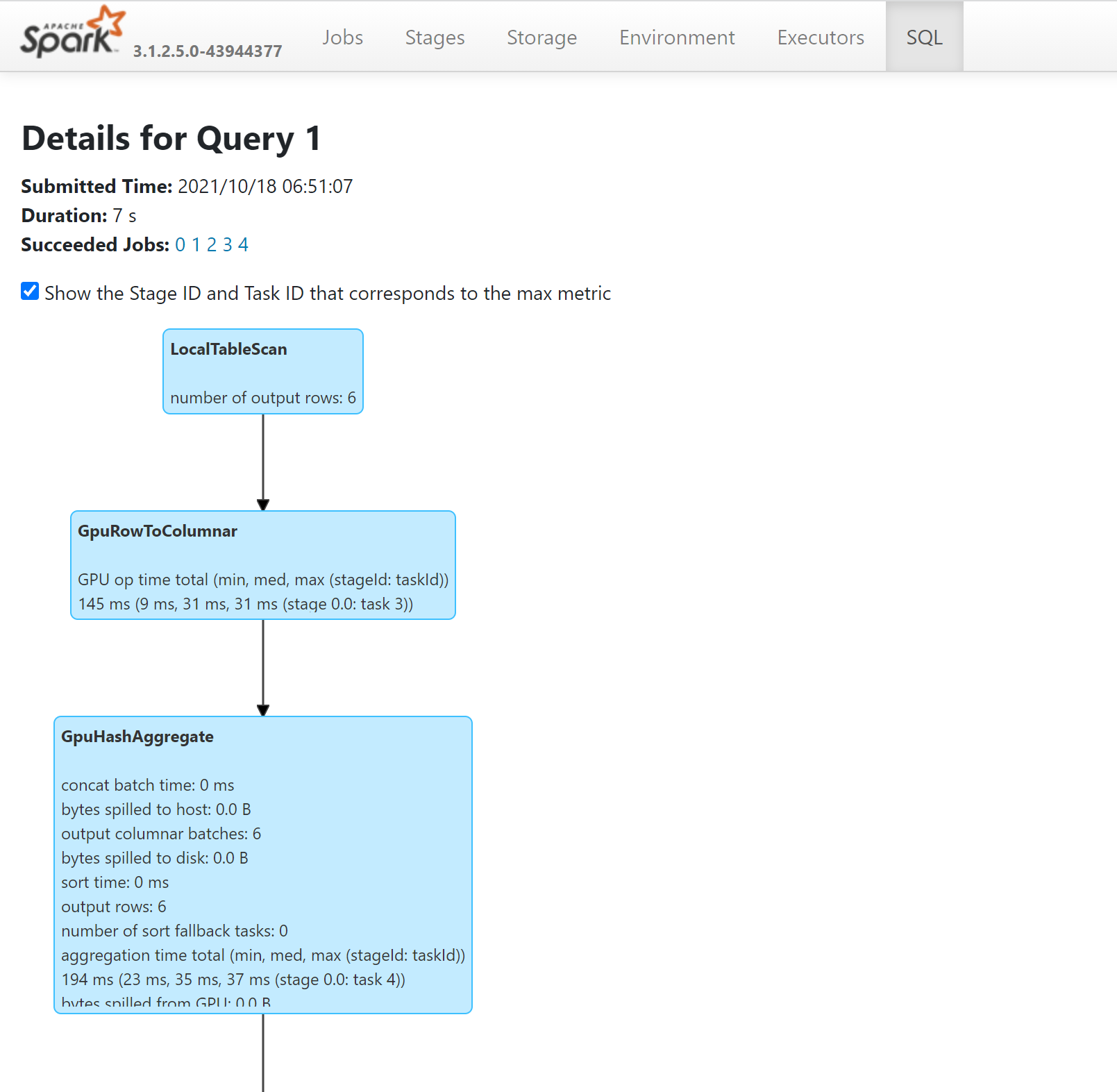
- Operacje w zapytaniu uruchomionym na procesorach GPU można wyświetlić, przeglądając plan SQL za pośrednictwem serwera historii platformy Spark:
Jak dostosować aplikację dla procesorów GPU
Większość zadań platformy Spark może zobaczyć lepszą wydajność dzięki dostrajaniu ustawień konfiguracji z ustawień domyślnych, a to samo dotyczy zadań korzystających z wtyczki akceleratora RAPIDS dla platformy Apache Spark.
Limity przydziału i ograniczenia zasobów w pulach z obsługą procesora GPU usługi Azure Synapse
Poziom obszaru roboczego
Każdy obszar roboczy usługi Azure Synapse ma domyślny limit przydziału 50 rdzeni wirtualnych procesora GPU. Aby zwiększyć limit przydziału rdzeni procesora GPU, prześlij wniosek o pomoc techniczną za pośrednictwem witryny Azure Portal.