Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Tip
Microsoft Fabric Data Warehouse to magazyn relacyjny w skali przedsiębiorstwa na podstawie bazy danych data lake z architekturą gotową do użycia w przyszłości, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz korzystać z magazynowania danych, zacznij od Fabric Data Warehouse. Istniejące obciążenia dedykowanej puli SQL mogą zostać zaktualizowane do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analizy w czasie rzeczywistym i raportowania.
Ta ściągawka zawiera przydatne porady i najlepsze praktyki dotyczące tworzenia dedykowanych rozwiązań puli SQL (dawniej SQL DW).
Poniższa ilustracja przedstawia proces projektowania magazynu danych z dedykowaną pulą SQL (dawniej SQL DW):
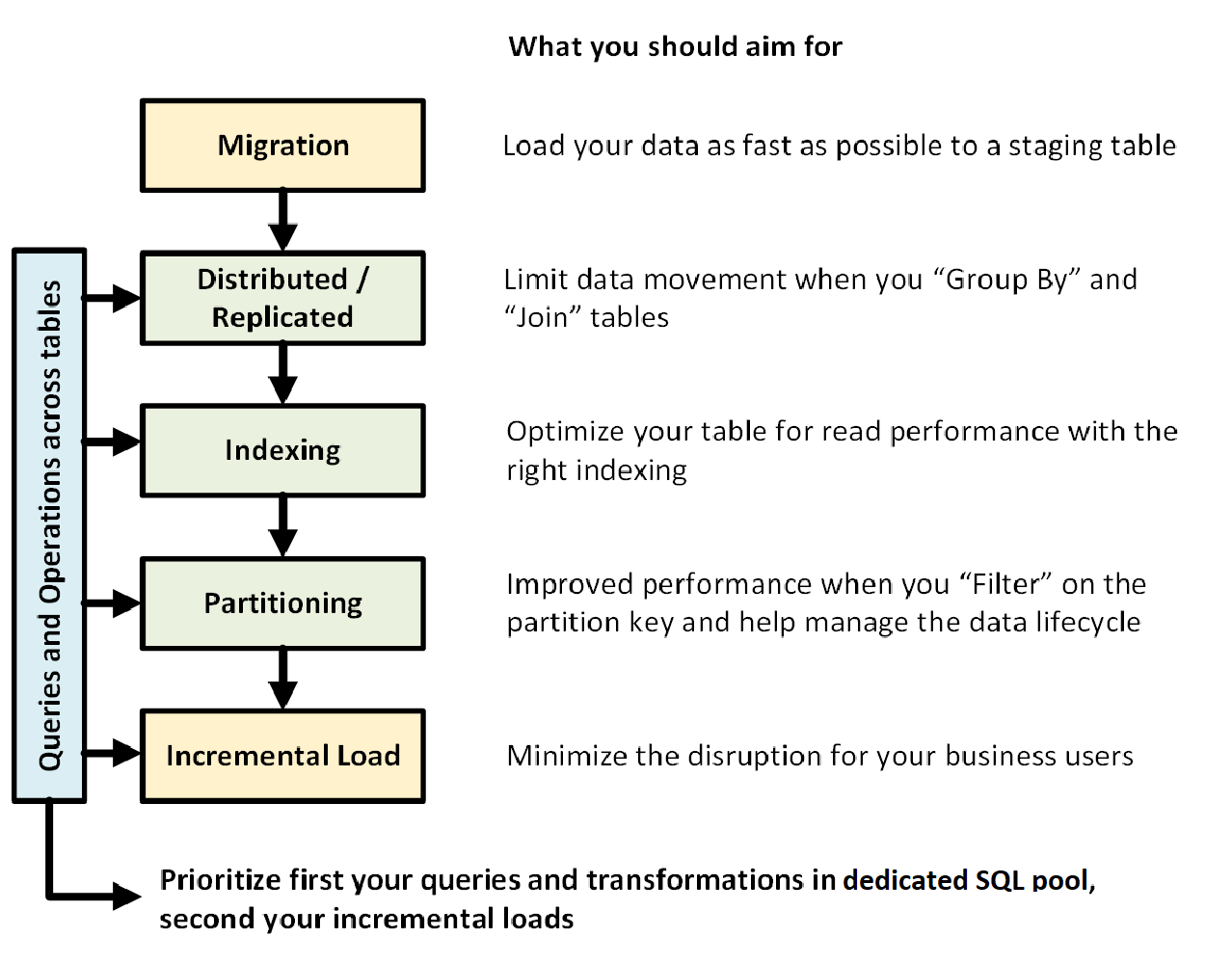
Zapytania i operacje między tabelami
Kiedy wiesz z wyprzedzeniem, jakie podstawowe operacje i zapytania będą wykonywane w twoim magazynie danych, możesz nadać priorytet architekturze magazynu danych pod kątem tych operacji. Te zapytania i operacje mogą obejmować:
- Łączenie jednej lub dwóch tabel faktów z tabelami wymiarów, filtrowanie połączonej tabeli, a następnie dołączanie wyników do składnic danych.
- Wprowadzanie dużych lub małych aktualizacji w danych sprzedażowych.
- Dołączanie tylko danych do tabel.
Znajomość typów operacji z wyprzedzeniem pomaga zoptymalizować projekt tabel.
Migracja danych
Najpierw załaduj dane do Azure Data Lake Storage lub Azure Blob Storage. Następnie użyj instrukcji COPY , aby załadować dane do tabel przejściowych. Użyj następującej konfiguracji:
| Projektowanie | Zalecenie |
|---|---|
| Dystrybucja | System kołowy |
| Indeksowanie | Heap |
| Partycjonowanie | Żaden |
| Klasa zasobów | largerc lub xlargerc |
Dowiedz się więcej o migracji danych, ładowaniu danych oraz procesie wyodrębniania, ładowania i przekształcania (ELT).
Tabele rozproszone lub replikowane
Użyj następujących strategii, w zależności od właściwości tabeli:
| Typ | Doskonałe dopasowanie do... | Uważaj, jeśli... |
|---|---|---|
| Zreplikowany | * Małe tabele wymiarów w schemacie gwiazdy z mniej niż 2 GB miejsca do magazynowania po kompresji (kompresja~5x) | * Wiele transakcji zapisu jest wykonywanych na tabeli (takich jak wstawianie, łączenie lub aktualizacja, usuwanie) * Często zmieniasz aprowizację jednostek Data Warehouse (DWU) * Używasz tylko 2–3 kolumn, ale tabela ma wiele kolumn * Indeksowanie replikowanej tabeli |
| Round Robin (domyślnie) | * Tabela tymczasowa/stagingowa * Brak oczywistego klucza łączenia lub dobrze nadającej się kolumny |
* Wydajność jest niska z powodu przenoszenia danych |
| Hash | * Tabele faktów * Duże tabele wymiarów |
* Nie można zaktualizować klucza dystrybucji |
Tips:
- Zacznij od Round Robin, ale aspiruj do strategii dystrybucji skrótów, aby skorzystać z masowo równoległej architektury.
- Upewnij się, że typowe klucze skrótów mają ten sam format danych.
- Nie dystrybuuj w formacie varchar.
- Tabele wymiarów, które mają wspólny klucz skrótu z tabelą faktów oraz często wykonywane operacje sprzężeń, mogą być rozproszone przy użyciu skrótu.
- Użyj sys.dm_pdw_nodes_db_partition_stats , aby przeanalizować wszelkie niesymetryczność danych.
- Użyj sys.dm_pdw_request_steps do analizowania ruchu danych w trakcie wykonywania zapytań, monitorowania czasu emisji i czasu trwania operacji mieszania. Jest to przydatne do przejrzenia strategii dystrybucji.
Dowiedz się więcej o replikowanych tabelach i tabelach rozproszonych.
Indeksowanie tabeli
Indeksowanie jest przydatne do szybkiego odczytywania tabel. Istnieje unikatowy zestaw technologii, których można używać na podstawie Twoich potrzeb:
| Typ | Doskonałe dopasowanie do... | Uważaj, jeśli... |
|---|---|---|
| Heap | * Tabela przejściowa/tymczasowa * Małe tabele z małymi odnośnikami |
* Wszystkie wyszukiwania skanują pełną tabelę |
| Indeks klastrowany | * Tabele z maksymalnie 100 milionami wierszy * Duże tabele (ponad 100 milionów wierszy) z tylko 1–2 kolumnami intensywnie używanymi |
* Stosowane w zreplikowanej tabeli * Masz złożone zapytania obejmujące wiele operacji łączenia i grupowania * Aktualizujesz indeksowane kolumny: zużywa pamięć |
| Indeks klastrowanego magazynu kolumn (CCI) (ustawienie domyślne) | * Duże tabele (ponad 100 milionów wierszy) | * Stosowane w zreplikowanej tabeli * Dokonujesz ogromnych operacji aktualizacji na swojej tabeli * Nadmierna partycja tabeli: grupy wierszy nie obejmują różnych węzłów dystrybucji i partycji |
Tips:
- Oprócz indeksu klastrowanego możesz dodać indeks nieklastrowany do kolumny intensywnie używanej do filtrowania.
- Zachowaj ostrożność podczas zarządzania pamięcią w tabeli za pomocą CCI. Podczas ładowania danych chcesz, aby użytkownik (lub zapytanie) korzystał z dużej klasy zasobów. Pamiętaj, aby uniknąć przycinania i tworzenia wielu małych skompresowanych grup wierszy.
- W usłudze Gen2 tabele CCI są buforowane lokalnie w węzłach obliczeniowych, aby zmaksymalizować wydajność.
- W przypadku CCI niska wydajność może wystąpić z powodu słabej kompresji grup wierszy. W takim przypadku odbuduj lub zreorganizuj swoje CCI. Chcesz mieć co najmniej 100 000 wierszy w każdej skompresowanej grupie wierszy. Idealnym rozwiązaniem jest 1 milion wierszy w grupie wierszy.
- Na podstawie częstotliwości i rozmiaru obciążenia przyrostowego chcesz zautomatyzować proces reorganizacji lub ponownego kompilowania indeksów. Wiosenne czyszczenie jest zawsze pomocne.
- Zastanów się strategicznie, gdy chcesz przyciąć grupę wierszy. Jakie są rozmiary otwartych grup wierszy? Ile danych oczekujesz załadować w najbliższych dniach?
Dowiedz się więcej o indeksach.
Partycjonowanie
Tabelę można podzielić na partycje, jeśli masz dużą tabelę faktów (więcej niż 1 miliard wierszy). W 99 procentach przypadków klucz partycji powinien być oparty na dacie.
W przypadku tabel przejściowych, które wymagają ELT, można korzystać z partycjonowania. Ułatwia zarządzanie cyklem życia danych. Należy zachować ostrożność, aby nie nadmiernie partycjonować tabeli faktów ani tabeli przejściowej, zwłaszcza na sklasteryzowanym indeksie kolumnowym.
Dowiedz się więcej o partycjach.
Obciążenie przyrostowe
Jeśli zamierzasz przyrostowo załadować dane, najpierw upewnij się, że przydzielasz większe klasy zasobów do ładowania danych. Jest to szczególnie ważne podczas ładowania do tabel z kolumnowymi indeksami klastrowanymi. Aby uzyskać więcej informacji, zobacz klasy zasobów .
Zalecamy używanie technologii PolyBase i ADF w wersji 2 do automatyzacji potoków ELT w magazynie danych.
W przypadku dużej partii aktualizacji w danych historycznych rozważ użycie funkcji CTAS do zapisania danych, które chcesz przechowywać w tabeli, zamiast używania funkcji INSERT, UPDATE i DELETE.
Prowadzenie statystyk
Ważne jest zaktualizowanie statystyk w miarę wprowadzania istotnych zmian w danych. Zobacz statystyki aktualizacji , aby określić, czy wystąpiły znaczące zmiany. Zaktualizowane statystyki optymalizują plany zapytań. Jeśli okaże się, że utrzymywanie wszystkich statystyk trwa zbyt długo, należy bardziej selektywnie określić, które kolumny mają statystyki.
Można również zdefiniować częstotliwość aktualizacji. Na przykład możesz zaktualizować kolumny dat, w których można codziennie dodawać nowe wartości. Największą korzyścią jest uzyskanie statystyk dotyczących kolumn zaangażowanych w sprzężenia, kolumn używanych w klauzuli WHERE i kolumn znalezionych w klauzuli GROUP BY.
Dowiedz się więcej o statystykach.
Klasa zasobów
Grupy zasobów są używane jako sposób przydzielania pamięci do zapytań. Jeśli potrzebujesz więcej pamięci, aby poprawić szybkość wykonywania zapytań lub ładowania, należy przydzielić wyższe klasy zasobów. Z drugiej strony użycie większych klas zasobów ma wpływ na współbieżność. Chcesz wziąć to pod uwagę przed przeniesieniem wszystkich użytkowników do dużej klasy zasobów.
Jeśli zauważysz, że zapytania trwa zbyt długo, sprawdź, czy użytkownicy nie działają w dużych klasach zasobów. Duże klasy zasobów zużywają wiele slotów współbieżności. Mogą powodować kolejki innych zapytań.
Na koniec, korzystając z usługi Gen2 dedykowanej puli SQL (dawniej SQL DW), każda klasa zasobów otrzymuje 2,5 razy więcej pamięci niż Gen1.
Dowiedz się więcej na temat pracy z klasami zasobów i współbieżnością.
Obniżanie kosztów
Kluczową funkcją Azure Synapse jest możliwość zarządzanie zasobami obliczeniowymi. Możesz wstrzymać dedykowaną pulę SQL (dawniej SQL DW), gdy jej nie używasz, co uniemożliwia naliczanie opłat za zasoby obliczeniowe. Zasoby można skalować w celu spełnienia wymagań dotyczących wydajności. Aby wstrzymać, użyj portalu Azure lub PowerShell. Aby przeprowadzić skalowanie, użyj portalu AzurePowerShell, T-SQL lub interfejsu API REST.
Autoskaluj wtedy, kiedy chcesz, z użyciem Azure Functions.

Optymalizowanie architektury pod kątem wydajności
Zalecamy rozważenie usługi SQL Database i Azure Analysis Services w architekturze hub-and-spoke. To rozwiązanie może zapewnić izolację obciążenia między różnymi grupami użytkowników, a jednocześnie korzystać z zaawansowanych funkcji zabezpieczeń z usługi SQL Database i Azure Analysis Services. Jest to również sposób zapewniania użytkownikom nieograniczonej współbieżności.
Dowiedz się więcej na temat architektur typowych, które korzystają z dedykowanej puli SQL (dawniej SQL DW) w Azure Synapse Analytics.
Wdróż szprychy w bazach danych SQL z dedykowanej puli SQL (dawniej SQL DW):