Analizowanie danych przy użyciu usługi Azure Machine Learning
W tym samouczku użyto projektanta usługi Azure Machine Learning do utworzenia predykcyjnego modelu uczenia maszynowego. Model jest oparty na danych przechowywanych w Azure Synapse. Scenariusz samouczka polega na przewidywaniu, czy klient prawdopodobnie kupi rower, a nie tak Adventure Works, sklep rowerowy, może zbudować docelową kampanię marketingową.
Wymagania wstępne
Do wykonania kroków opisanych w tym samouczku potrzebne są:
- pula SQL wstępnie załadowana z przykładowymi danymi AdventureWorksDW. Aby aprowizować tę pulę SQL, zobacz Tworzenie puli SQL i wybieranie ładowania przykładowych danych. Jeśli masz już magazyn danych, ale nie masz przykładowych danych, możesz załadować przykładowe dane ręcznie.
- obszar roboczy usługi Azure Machine Learning. Postępuj zgodnie z tym samouczkiem , aby utworzyć nowy.
Pobieranie danych
Używane dane są w widoku dbo.vTargetMail w adventureWorksDW. Aby użyć magazynu danych w tym samouczku, dane są najpierw eksportowane do konta Azure Data Lake Storage, ponieważ Azure Synapse obecnie nie obsługuje zestawów danych. Azure Data Factory można użyć do wyeksportowania danych z magazynu danych do Azure Data Lake Storage przy użyciu działania kopiowania. Użyj następującego zapytania do importowania:
SELECT [CustomerKey]
,[GeographyKey]
,[CustomerAlternateKey]
,[MaritalStatus]
,[Gender]
,cast ([YearlyIncome] as int) as SalaryYear
,[TotalChildren]
,[NumberChildrenAtHome]
,[EnglishEducation]
,[EnglishOccupation]
,[HouseOwnerFlag]
,[NumberCarsOwned]
,[CommuteDistance]
,[Region]
,[Age]
,[BikeBuyer]
FROM [dbo].[vTargetMail]
Gdy dane są dostępne w Azure Data Lake Storage, magazyny danych w usłudze Azure Machine Learning są używane do łączenia się z usługami Azure Storage. Wykonaj poniższe kroki, aby utworzyć magazyn danych i odpowiedni zestaw danych:
Uruchom Azure Machine Learning studio z Azure Portal lub zaloguj się przy Azure Machine Learning studio.
Kliknij pozycję Magazyny danych w okienku po lewej stronie w sekcji Zarządzanie , a następnie kliknij pozycję Nowy magazyn danych.
Podaj nazwę magazynu danych, wybierz typ "Azure Blob Storage", podaj lokalizację i poświadczenia. Następnie kliknij pozycję Utwórz.
Następnie kliknij pozycję Zestawy danych w okienku po lewej stronie w sekcji Zasoby . Wybierz pozycję Utwórz zestaw danych z opcją Z magazynu danych.
Określ nazwę zestawu danych i wybierz typ, który ma być tabelaryczny. Następnie kliknij przycisk Dalej , aby przejść do przodu.
W sekcji Wybierz lub utwórz magazyn danych wybierz opcję Wcześniej utworzony magazyn danych. Wybierz utworzony wcześniej magazyn danych. Kliknij przycisk Dalej i określ ścieżkę i ustawienia pliku. Pamiętaj, aby określić nagłówek kolumny, jeśli pliki zawierają jeden.
Na koniec kliknij pozycję Utwórz , aby utworzyć zestaw danych.
Konfigurowanie eksperymentu projektanta
Następnie wykonaj poniższe kroki, aby uzyskać konfigurację projektanta:
Kliknij kartę Projektant w okienku po lewej stronie w sekcji Autor.
Wybierz pozycję Łatwe w użyciu wstępnie utworzone składniki , aby utworzyć nowy potok.
W okienku ustawień po prawej stronie określ nazwę potoku.
Ponadto wybierz docelowy klaster obliczeniowy dla całego eksperymentu w ustawieniach przycisku do wcześniej aprowizowanego klastra. Zamknij okienko Ustawienia.
Importowanie danych
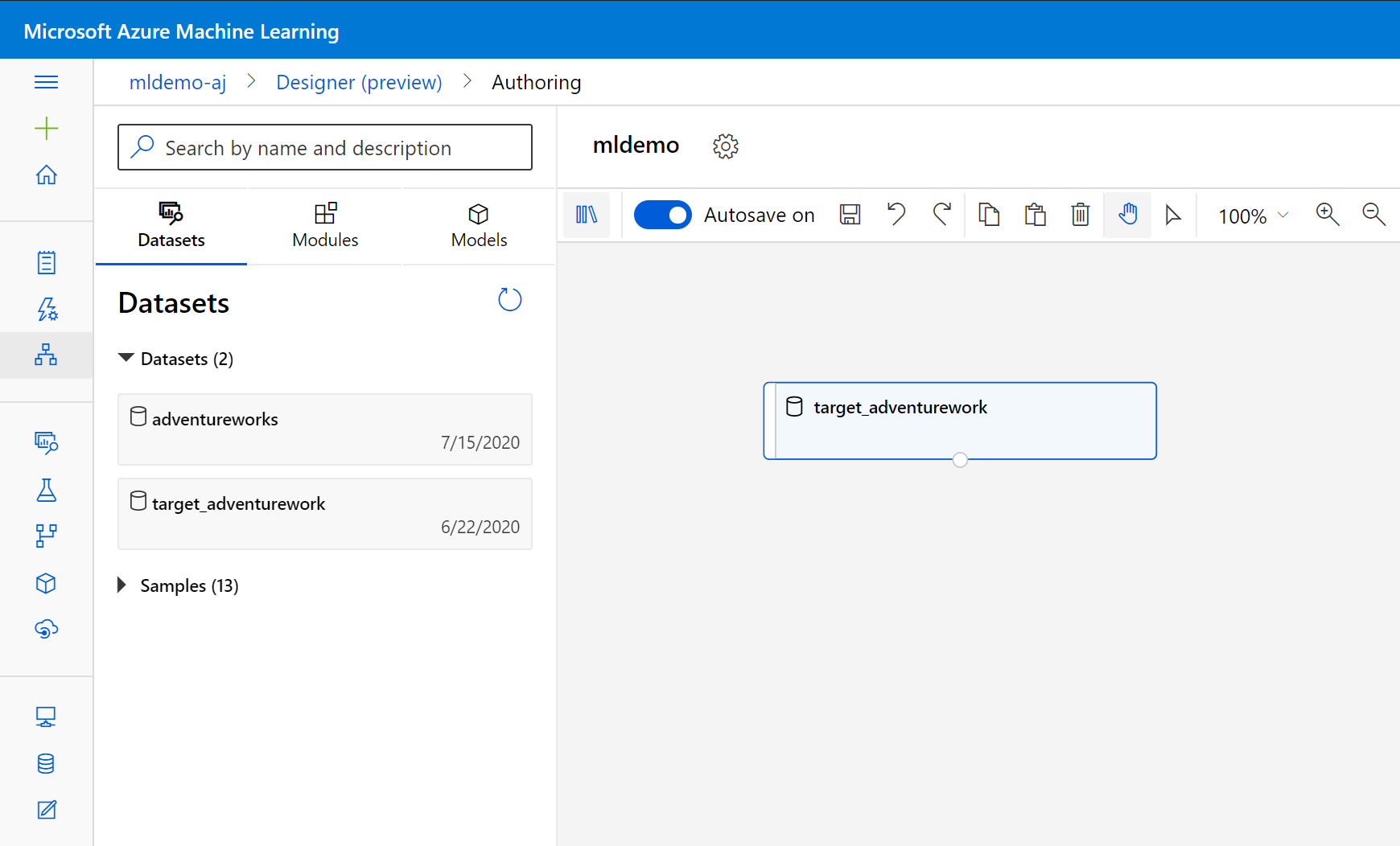
Wybierz podtabę Zestawy danych w okienku po lewej stronie poniżej pola wyszukiwania.
Przeciągnij utworzony wcześniej zestaw danych na kanwę.
Czyszczenie danych
Aby wyczyścić dane, upuść kolumny, które nie są istotne dla modelu. Wykonaj następujące czynności:
Wybierz podtabę Składniki w okienku po lewej stronie.
Przeciągnij składnik Select Columns in Dataset (Wybieranie kolumn w zestawie danych) w obszarze Manipulowanie przekształcaniem < danych na kanwę. Połącz ten składnik ze składnikiem Zestaw danych .
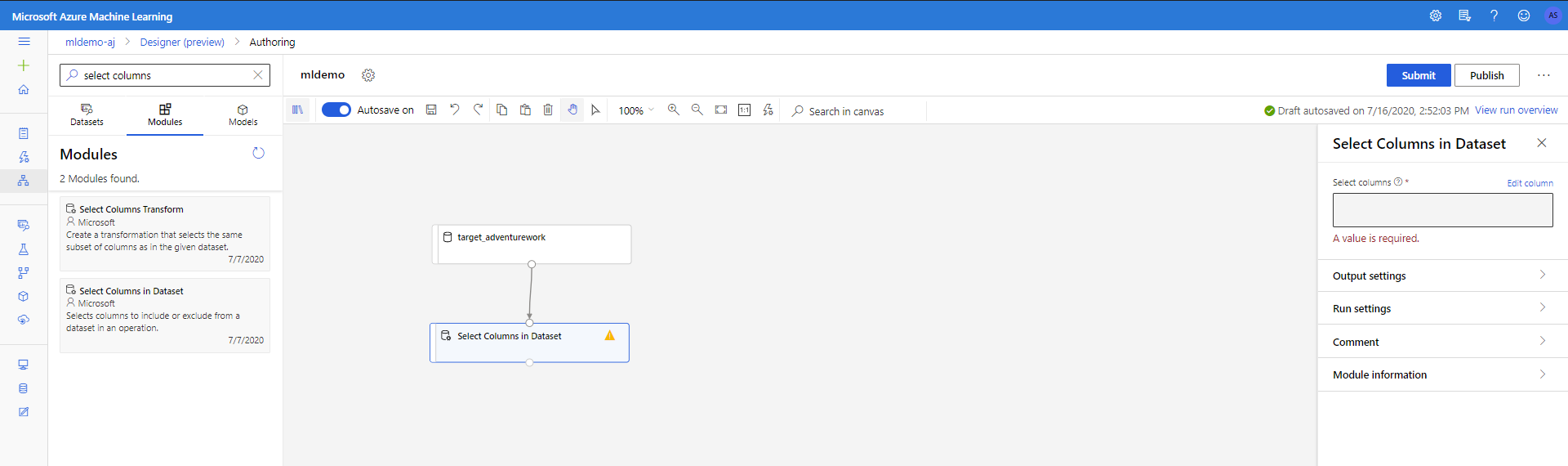
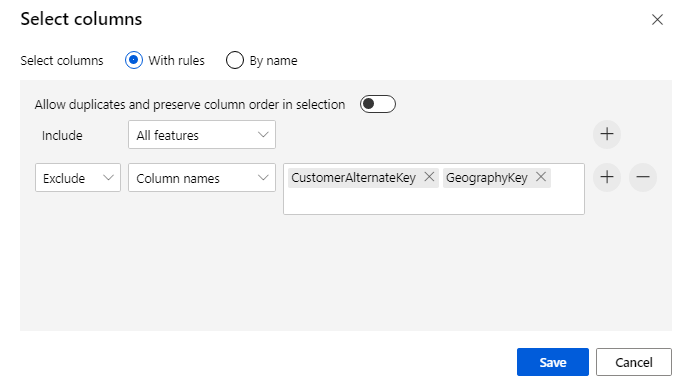
Kliknij składnik, aby otworzyć okienko właściwości. Kliknij pozycję Edytuj kolumnę, aby określić kolumny, które chcesz usunąć.
Wyklucz dwie kolumny: CustomerAlternateKey i GeographyKey. Kliknij pozycję Zapisz

Tworzenie modelu
Dane są podzielone na 80–20: 80%, aby wytrenować model uczenia maszynowego i 20% w celu przetestowania modelu. Algorytmy "Dwuklasowe" są używane w tym problemie klasyfikacji binarnej.
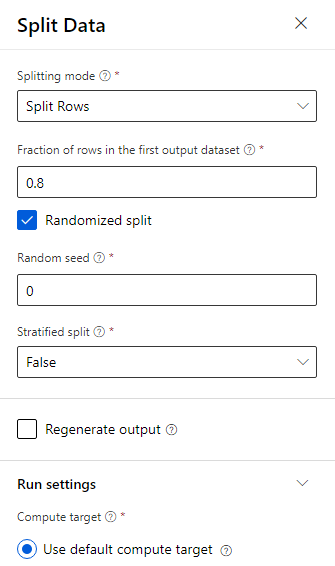
Przeciągnij składnik Split Data (Podział danych ) na kanwę.
W okienku właściwości wprowadź wartość 0.8 w polu Ułamek wierszy w pierwszym wyjściowym zestawie danych.
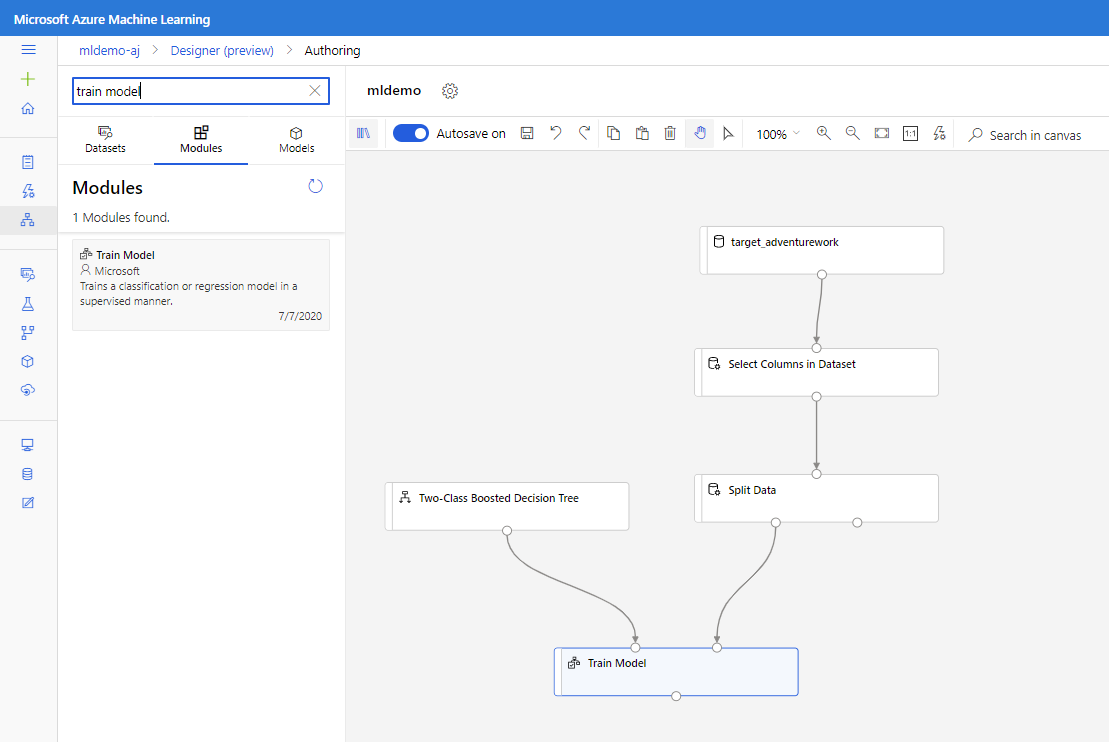
Przeciągnij składnik Dwuklasowe wzmocnione drzewo decyzyjne do kanwy.
Przeciągnij składnik Train Model (Trenowanie modelu ) na kanwę. Określ dane wejściowe, łącząc je ze składnikami Dwuklasowego Wzmocnione drzewo decyzyjne (algorytm uczenia maszynowego) i Podziel dane (dane do trenowania algorytmu).
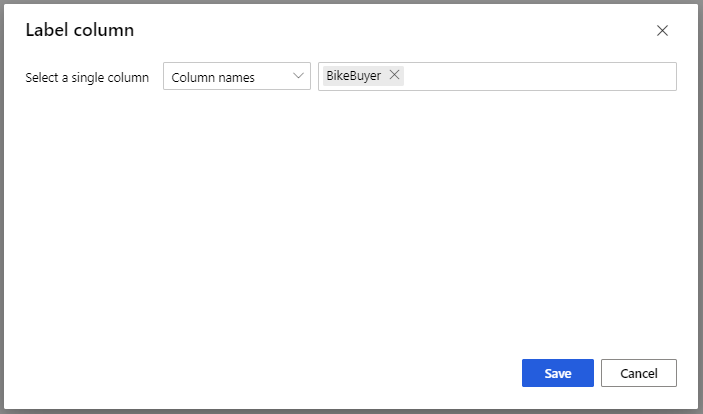
W obszarze Train Model model (Trenowanie modelu) w opcji Kolumna etykieta w okienku Właściwości wybierz pozycję Edytuj kolumnę. Wybierz kolumnę BikeBuyer jako kolumnę, aby przewidzieć i wybrać pozycję Zapisz.
Ocenianie modelu
Teraz przetestuj, jak model działa na danych testowych. Dwa różne algorytmy zostaną porównane, aby zobaczyć, który z nich działa lepiej. Wykonaj następujące czynności:
Przeciągnij składnik Score Model (Generowanie wyników modelu ) na kanwę i połącz go ze składnikami Train Model (Trenowanie modelu ) i Split Data (Podział danych ).
Przeciągnij dwuklasowy Bayes Averaged Perceptron do kanwy eksperymentu. Porównasz sposób działania tego algorytmu w porównaniu z Two-Class Wzmocnione drzewo decyzyjne.
Skopiuj i wklej składniki Train Model (Trenowanie modelu ) i Score Model (Generowanie wyników ) na kanwie.
Przeciągnij składnik Evaluate Model na kanwę, aby porównać dwa algorytmy.
Kliknij przycisk Prześlij, aby skonfigurować przebieg potoku.
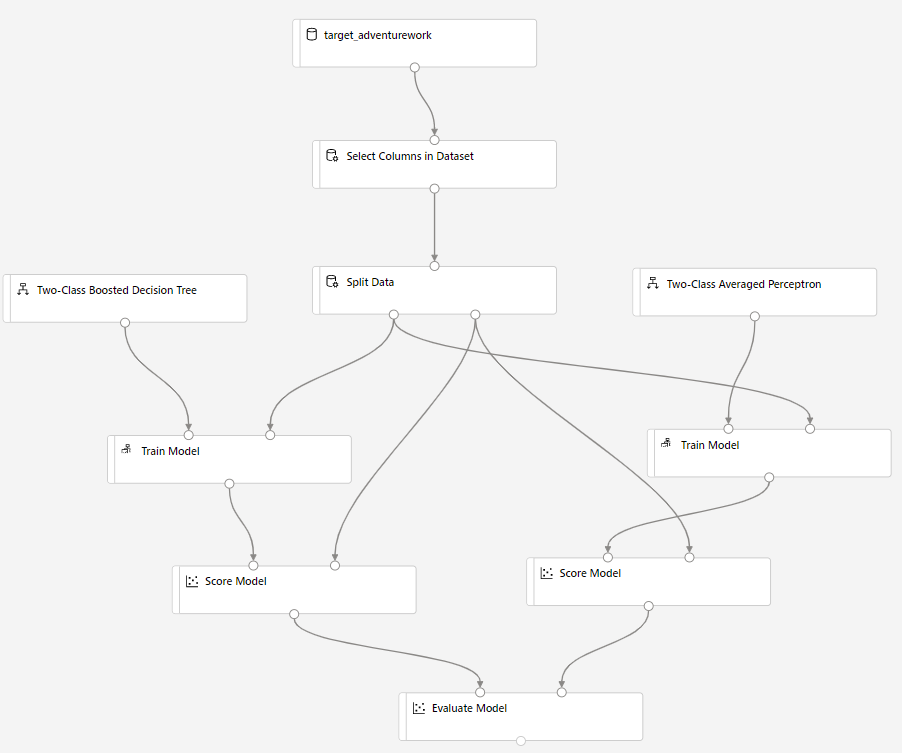
Po zakończeniu przebiegu kliknij prawym przyciskiem myszy składnik Evaluate Model (Ocena modelu ), a następnie kliknij pozycję Visualize Evaluation results (Wizualizacja wyników oceny).
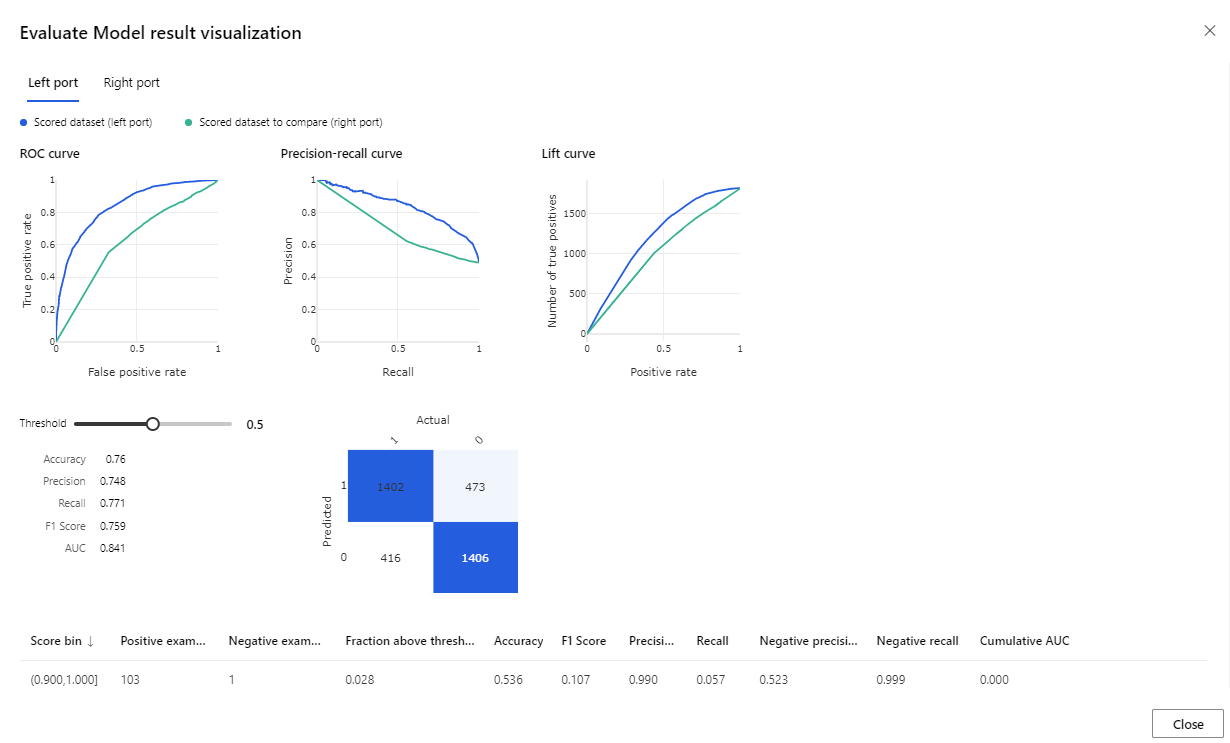

Podane metryki są krzywą ROC, diagramem kompletności precyzji i krzywą podnoszenia. Spójrz na te metryki, aby zobaczyć, że pierwszy model działał lepiej niż drugi. Aby przyjrzeć się przewidywaniu pierwszego modelu, kliknij prawym przyciskiem myszy składnik Score Model (Generowanie wyników modelu), a następnie kliknij pozycję Visualize Scored dataset (Wizualizuj wygenerowany wynik), aby wyświetlić przewidywane wyniki.
Zobaczysz jeszcze dwie kolumny dodane do zestawu danych testowych.
- Scored Probabilities (Sklasyfikowane prawdopodobieństwo): prawdopodobieństwo, że klient jest nabywcą roweru.
- Scored Labels (Sklasyfikowane etykiety): klasyfikacja dokonana przez model — nabywca roweru (1) lub nie (0). Ustawiony próg prawdopodobieństwa etykietowania wynosi 50% i można go dostosować.
Porównaj kolumnę BikeBuyer (rzeczywista) z etykietami scored (prediction), aby zobaczyć, jak dobrze model wykonał. Następnie możesz użyć tego modelu do przewidywania dla nowych klientów. Ten model można opublikować jako usługę internetową lub zapisać wyniki z powrotem do Azure Synapse.
Następne kroki
Aby dowiedzieć się więcej na temat usługi Azure Machine Learning, zobacz Wprowadzenie do usługi Machine Learning na platformie Azure.
Dowiedz się więcej o wbudowanym ocenianiu w magazynie danych tutaj.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla