Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy: ✔️ Maszyny wirtualne z systemem Linux Maszyny ✔️ wirtualne z systemem Windows ✔️ — elastyczne zestawy ✔️ skalowania
Interfejs MPI (Message Passing Interface) to otwarta biblioteka i standard defacto na potrzeby równoległego przetwarzania rozproszonej pamięci. Jest ona często używana w wielu obciążeniach HPC. Obciążenia HPC na maszynach wirtualnych serii HB i N obsługujących funkcję RDMA mogą używać interfejsu MPI do komunikowania się za pośrednictwem sieci InfiniBand o małych opóźnieniach i wysokiej przepustowości.
- Rozmiary maszyn wirtualnych z włączoną funkcją SR-IOV na platformie Azure umożliwiają korzystanie z mellanox OFED niemal dowolnego rodzaju interfejsu MPI.
- Na maszynach wirtualnych z obsługą funkcji SR-IOV obsługiwane implementacje MPI używają interfejsu Microsoft Network Direct (ND) do komunikacji między maszynami wirtualnymi. W związku z tym obsługiwane są tylko wersje Microsoft MPI (MS-MPI) 2012 R2 lub nowsze oraz Intel MPI 5.x. Nowsze wersje (2017, 2018) biblioteki środowiska uruchomieniowego Intel MPI mogą lub nie są zgodne ze sterownikami Usługi Azure RDMA.
W przypadku maszyn wirtualnych obsługujących funkcję RDMA z obsługą funkcji SR-IOV obrazy maszyn wirtualnych z systemem Ubuntu-HPC i obrazy maszyn wirtualnych AlmaLinux-HPC są odpowiednie. Te obrazy maszyn wirtualnych są optymalizowane i wstępnie ładowane ze sterownikami OFED dla funkcji RDMA oraz różnymi powszechnie używanymi bibliotekami MPI i pakietami obliczeń naukowych i są najprostszym sposobem rozpoczęcia pracy.
Chociaż poniżej przedstawiono przykłady dla systemu RHEL, ale kroki są ogólne i mogą być używane dla dowolnego zgodnego systemu operacyjnego Linux, takiego jak Ubuntu (18.04, 20.04, 22.04) i SLES (12 SP4 i 15 SP4). Więcej przykładów konfigurowania innych implementacji MPI na innych dystrybucjach znajduje się w repozytorium azhpc-images.
Uwaga
Uruchamianie zadań MPI na maszynach wirtualnych z włączoną funkcją SR-IOV z określonymi bibliotekami MPI (takimi jak interfejs MPI platformy) może wymagać skonfigurowania kluczy partycji (p-keys) w dzierżawie pod kątem izolacji i zabezpieczeń. Wykonaj kroki opisane w sekcji Odnajdywanie kluczy partycji, aby uzyskać szczegółowe informacje na temat określania wartości p-key i poprawnego ustawiania ich dla zadania MPI za pomocą tej biblioteki MPI.
Uwaga
Poniższe fragmenty kodu to przykłady. Zalecamy używanie najnowszych stabilnych wersji pakietów lub odwoływania się do repozytorium azhpc-images.
Wybieranie biblioteki MPI
Jeśli aplikacja HPC zaleca określoną bibliotekę MPI, spróbuj najpierw użyć tej wersji. Jeśli masz elastyczność w zakresie wybranego interfejsu MPI i chcesz uzyskać najlepszą wydajność, wypróbuj hpC-X. Ogólnie rzecz biorąc, interfejs MPI HPC-X działa najlepiej przy użyciu struktury UCX dla interfejsu InfiniBand i korzysta ze wszystkich funkcji sprzętu i oprogramowania Mellanox InfiniBand. Ponadto hpC-X i OpenMPI są zgodne z usługą ABI, dzięki czemu można dynamicznie uruchamiać aplikację HPC z hpC-X, która została skompilowana przy użyciu interfejsu OpenMPI. Podobnie intel MPI, MVAPICH i MPICH są zgodne z usługą ABI.
Na poniższej ilustracji przedstawiono architekturę popularnych bibliotek MPI.
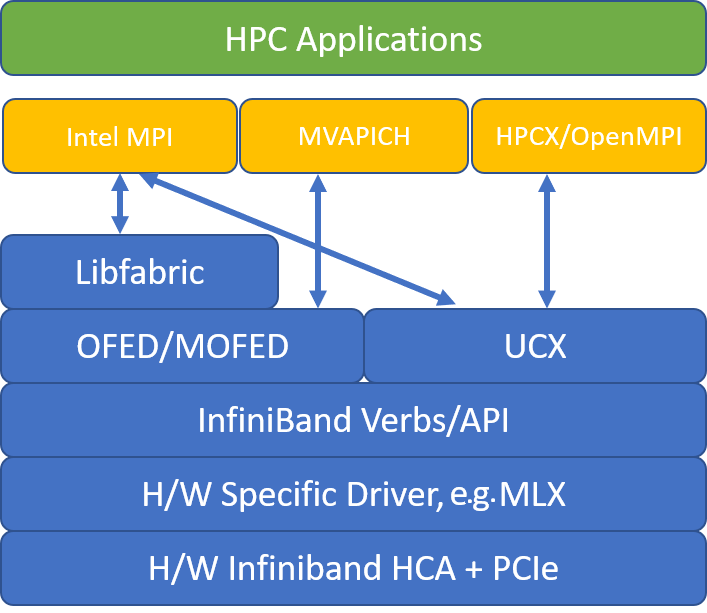
HPC-X
Zestaw narzędzi oprogramowania HPC-X zawiera zestaw narzędzi UCX i HCOLL i można go skompilować na podstawie interfejsu UCX.
HPCX_VERSION="v2.6.0"
HPCX_DOWNLOAD_URL=https://azhpcstor.blob.core.windows.net/azhpc-images-store/hpcx-v2.6.0-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
wget --retry-connrefused --tries=3 --waitretry=5 $HPCX_DOWNLOAD_URL
tar -xvf hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
mv hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64 ${INSTALL_PREFIX}
HPCX_PATH=${INSTALL_PREFIX}/hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64
Poniższe polecenie ilustruje niektóre zalecane argumenty mpirun dla HPC-X i OpenMPI.
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
gdzie:
| Parametr | Opis |
|---|---|
NPROCS |
Określa liczbę procesów MPI. Na przykład: -n 16. |
$HOSTFILE |
Określa plik zawierający nazwę hosta lub adres IP, aby wskazać lokalizację uruchamiania procesów MPI. Na przykład: --hostfile hosts. |
$NUMBER_PROCESSES_PER_NUMA |
Określa liczbę procesów MPI uruchamianych w każdej domenie NUMA. Aby na przykład określić cztery procesy MPI na NUMA, należy użyć polecenia --map-by ppr:4:numa:pe=1. |
$NUMBER_THREADS_PER_PROCESS |
Określa liczbę wątków na proces MPI. Aby na przykład określić jeden proces MPI i cztery wątki na jednostkę NUMA, należy użyć polecenia --map-by ppr:1:numa:pe=4. |
-report-bindings |
Drukuje mapowanie procesów MPI na rdzenie, co jest przydatne do sprawdzenia, czy przypinanie procesu MPI jest poprawne. |
$MPI_EXECUTABLE |
Określa plik wykonywalny MPI utworzony w bibliotekach MPI. Otoki kompilatora MPI wykonują to automatycznie. Na przykład: mpicc lub mpif90. |
Przykład uruchamiania mikrobenchmarku opóźnienia jednostki organizacyjnej jest następujący:
${HPCX_PATH}mpirun -np 2 --map-by ppr:2:node -x UCX_TLS=rc ${HPCX_PATH}/ompi/tests/osu-micro-benchmarks-5.3.2/osu_latency
Optymalizowanie zbiorczych interfejsów MPI
Typy pierwotne komunikacji zbiorowej MPI oferują elastyczny, przenośny sposób implementowania operacji komunikacji grupowej. Są one szeroko używane w różnych aplikacjach naukowych równoległych i mają znaczący wpływ na ogólną wydajność aplikacji. Zapoznaj się z artykułem TechCommunity, aby uzyskać szczegółowe informacje na temat parametrów konfiguracji, aby zoptymalizować wydajność komunikacji zbiorowej przy użyciu biblioteki HPC-X i HCOLL na potrzeby komunikacji zbiorowej.
Jeśli na przykład podejrzewasz, że ściśle sprzężona aplikacja MPI wykonuje nadmierną ilość komunikacji zbiorowej, możesz spróbować włączyć hierarchiczne kolektywy (HCOLL). Aby włączyć te funkcje, użyj następujących parametrów.
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
Uwaga
Z HPC-X 2.7.4 lub nowszym może być konieczne jawne przekazanie LD_LIBRARY_PATH, jeśli wersja UCX w moFED a w HPC-X jest inna.
OpenMPI
Zainstaluj program UCX zgodnie z powyższym opisem. HCOLL jest częścią zestawu narzędzi do oprogramowania HPC-X i nie wymaga specjalnej instalacji.
Interfejs OpenMPI można zainstalować z pakietów dostępnych w repozytorium.
sudo yum install –y openmpi
Zalecamy utworzenie najnowszej, stabilnej wersji interfejsu OpenMPI za pomocą interfejsu UCX.
OMPI_VERSION="4.0.3"
OMPI_DOWNLOAD_URL=https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-${OMPI_VERSION}.tar.gz
wget --retry-connrefused --tries=3 --waitretry=5 $OMPI_DOWNLOAD_URL
tar -xvf openmpi-${OMPI_VERSION}.tar.gz
cd openmpi-${OMPI_VERSION}
./configure --prefix=${INSTALL_PREFIX}/openmpi-${OMPI_VERSION} --with-ucx=${UCX_PATH} --with-hcoll=${HCOLL_PATH} --enable-mpirun-prefix-by-default --with-platform=contrib/platform/mellanox/optimized && make -j$(nproc) && make install
Aby uzyskać optymalną wydajność, uruchom narzędzie OpenMPI za pomocą elementów ucx i hcoll. Zobacz również przykład z hpc-X.
${INSTALL_PREFIX}/bin/mpirun -np 2 --map-by node --hostfile ~/hostfile -mca pml ucx --mca btl ^vader,tcp,openib -x UCX_NET_DEVICES=mlx5_0:1 -x UCX_IB_PKEY=0x0003 ./osu_latency
Sprawdź klucz partycji, jak wspomniano powyżej.
Intel MPI
Pobierz wybraną wersję programu Intel MPI. Wersja Intel MPI 2019 została przełączona z platformy Open Fabrics Alliance (OFA) do platformy Open Fabrics Interfaces (OFI) i obecnie obsługuje bibliotekę libfabric. Istnieją dwa dostawcy obsługi infiniBand: mlx i czasowniki. Zmień zmienną środowiskową I_MPI_FABRICS w zależności od wersji.
- Intel MPI 2019 i 2021: użyj polecenia
I_MPI_FABRICS=shm:ofi,I_MPI_OFI_PROVIDER=mlx. Dostawca używa interfejsumlxUCX. Stwierdzono, że użycie czasowników jest niestabilne i mniej wydajne. Aby uzyskać więcej informacji, zobacz artykuł TechCommunity. - Intel MPI 2018: użyj
I_MPI_FABRICS=shm:ofa - Intel MPI 2016: użyj
I_MPI_DAPL_PROVIDER=ofa-v2-ib0
Poniżej przedstawiono kilka sugerowanych argumentów mpirun dla intel MPI 2019 update 5+.
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
gdzie:
| Parametr | Opis |
|---|---|
FI_PROVIDER |
Określa, który dostawca libfabric ma być używany, co wpłynie na używany interfejs API, protokół i sieć. czasowniki to kolejna opcja, ale ogólnie mlx zapewnia lepszą wydajność. |
I_MPI_DEBUG |
Określa poziom dodatkowych danych wyjściowych debugowania, który może udostępniać szczegółowe informacje o tym, gdzie są przypięte procesy, oraz który protokół i sieć są używane. |
I_MPI_PIN_DOMAIN |
Określa sposób przypinania procesów. Można na przykład przypiąć rdzenie, gniazda lub domeny NUMA. W tym przykładzie ustawisz tę zmienną środowiskową na wartość numa, co oznacza, że procesy zostaną przypięte do domen węzłów NUMA. |
Optymalizowanie zbiorczych interfejsów MPI
Istnieją inne opcje, które można wypróbować, zwłaszcza jeśli operacje zbiorowe zużywają znaczną ilość czasu. Intel MPI 2019 update 5+ obsługuje dostarczanie mlx i używa struktury UCX do komunikowania się z InfiniBand. Obsługuje również HCOLL.
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
Maszyny wirtualne inne niż SR-IOV
W przypadku maszyn wirtualnych innych niż SR-IOV przykład pobierania bezpłatnej wersji ewaluacyjnej środowiska uruchomieniowego 5.x jest następujący:
wget http://registrationcenter-download.intel.com/akdlm/irc_nas/tec/9278/l_mpi_p_5.1.3.223.tgz
Aby uzyskać instrukcje instalacji, zobacz Przewodnik instalacji biblioteki Intel MPI. Opcjonalnie możesz włączyć funkcję ptrace dla procesów innych niż debuger innych niż root (wymagane w przypadku najnowszych wersji programu Intel MPI).
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
SUSE Linux
W przypadku wersji obrazów maszyn wirtualnych SUSE Linux Enterprise Server — SLES 12 SP3 dla HPC, SLES 12 SP3 dla HPC (Premium), SLES 12 SP1 dla HPC, SLES 12 SP1 dla HPC (Premium), SLES 12 SP4 i SLES 15 sterowniki RDMA są instalowane, a pakiety INTEL MPI są dystrybuowane na maszynie wirtualnej. Zainstaluj program Intel MPI, uruchamiając następujące polecenie:
sudo rpm -v -i --nodeps /opt/intelMPI/intel_mpi_packages/*.rpm
MVAPICH
Poniżej przedstawiono przykład tworzenia MVAPICH2. Zwróć uwagę, że nowsze wersje mogą być dostępne niż używane poniżej.
wget http://mvapich.cse.ohio-state.edu/download/mvapich/mv2/mvapich2-2.3.tar.gz
tar -xv mvapich2-2.3.tar.gz
cd mvapich2-2.3
./configure --prefix=${INSTALL_PREFIX}
make -j 8 && make install
Przykład uruchamiania mikrobenchmarku opóźnienia jednostki organizacyjnej jest następujący:
${INSTALL_PREFIX}/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=48 ./osu_latency
Poniższa lista zawiera kilka zalecanych mpirun argumentów.
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
gdzie:
| Parametr | Opis |
|---|---|
MV2_CPU_BINDING_POLICY |
Określa, które zasady powiązań mają być używane, co będzie miało wpływ na sposób przypinania procesów do podstawowych identyfikatorów. W tym przypadku należy określić scatterwartość , więc procesy są równomiernie rozpraszane między domenami NUMA. |
MV2_CPU_BINDING_LEVEL |
Określa, gdzie należy przypiąć procesy. W takim przypadku należy ustawić ją na numanode, co oznacza, że procesy są przypięte do jednostek domen NUMA. |
MV2_SHOW_CPU_BINDING |
Określa, czy chcesz uzyskać informacje debugowania o tym, gdzie są przypięte procesy. |
MV2_SHOW_HCA_BINDING |
Określa, czy chcesz uzyskać informacje debugowania o tym, której karty kanału hosta używa każdy proces. |
Interfejs MPI platformy
Zainstaluj wymagane pakiety dla platformy MPI Community Edition.
sudo yum install libstdc++.i686
sudo yum install glibc.i686
Download platform MPI at https://www.ibm.com/developerworks/downloads/im/mpi/index.html
sudo ./platform_mpi-09.01.04.03r-ce.bin
Postępuj zgodnie z procesem instalacji.
MPICH
Zainstaluj program UCX zgodnie z powyższym opisem. Kompilowanie MPICH.
wget https://www.mpich.org/static/downloads/3.3/mpich-3.3.tar.gz
tar -xvf mpich-3.3.tar.gz
cd mpich-3.3
./configure --with-ucx=${UCX_PATH} --prefix=${INSTALL_PREFIX} --with-device=ch4:ucx
make -j 8 && make install
Uruchamianie programu MPICH.
${INSTALL_PREFIX}/bin/mpiexec -n 2 -hostfile ~/hostfile -env UCX_IB_PKEY=0x0003 -bind-to hwthread ./osu_latency
Sprawdź klucz partycji, jak wspomniano powyżej.
Testy porównawcze MPI jednostek OSU
Pobierz testy porównawcze OSU MPI i untar.
wget http://mvapich.cse.ohio-state.edu/download/mvapich/osu-micro-benchmarks-5.5.tar.gz
tar –xvf osu-micro-benchmarks-5.5.tar.gz
cd osu-micro-benchmarks-5.5
Kompilowanie testów porównawczych przy użyciu określonej biblioteki MPI:
CC=<mpi-install-path/bin/mpicc>CXX=<mpi-install-path/bin/mpicxx> ./configure
make
Testy porównawcze MPI znajdują się w mpi/ folderze.
Odnajdywanie kluczy partycji
Odnajdź klucze partycji (p-keys) na potrzeby komunikacji z innymi maszynami wirtualnymi w tej samej dzierżawie (zestaw dostępności lub zestaw skalowania maszyn wirtualnych).
/sys/class/infiniband/mlx5_0/ports/1/pkeys/0
/sys/class/infiniband/mlx5_0/ports/1/pkeys/1
Większy z tych dwóch jest kluczem dzierżawy, który powinien być używany z interfejsem MPI. Przykład: jeśli poniżej znajdują się klucze p, 0x800b należy używać z interfejsem MPI.
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/0
0x800b
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/1
0x7fff
Interfejsy notatek są nazywane obrazami mlx5_ib* maszyn wirtualnych HPC.
Należy również pamiętać, że jeśli dzierżawa (zestaw dostępności lub zestaw skalowania maszyn wirtualnych) istnieje, PKEY pozostają takie same. Jest to prawdą nawet wtedy, gdy węzły są dodawane/usuwane. Nowe dzierżawy uzyskują różne PKEYs.
Konfigurowanie limitów użytkowników dla interfejsu MPI
Konfigurowanie limitów użytkowników dla interfejsu MPI.
cat << EOF | sudo tee -a /etc/security/limits.conf
* hard memlock unlimited
* soft memlock unlimited
* hard nofile 65535
* soft nofile 65535
EOF
Konfigurowanie kluczy SSH dla interfejsu MPI
Skonfiguruj klucze SSH dla typów MPI, które tego wymagają.
ssh-keygen -f /home/$USER/.ssh/id_rsa -t rsa -N ''
cat << EOF > /home/$USER/.ssh/config
Host *
StrictHostKeyChecking no
EOF
cat /home/$USER/.ssh/id_rsa.pub >> /home/$USER/.ssh/authorized_keys
chmod 600 /home/$USER/.ssh/authorized_keys
chmod 644 /home/$USER/.ssh/config
Powyższa składnia zakłada, że współużytkowany katalog macierzystowy musi .ssh zostać skopiowany do każdego węzła.
Następne kroki
- Dowiedz się więcej o maszynach wirtualnych z serii HB i N z obsługą technologii InfiniBand.
- Zapoznaj się z omówieniem serii HBv3 i omówieniem serii HC.
- Przeczytaj artykuł Optymalne umieszczanie procesów MPI dla maszyn wirtualnych serii HB.
- Przeczytaj o najnowszych ogłoszeniach, przykładach obciążeń HPC i wynikach wydajności na blogach społeczności technicznej usługi Azure Compute.
- Aby uzyskać widok architektury wyższego poziomu na potrzeby uruchamiania obciążeń HPC, zobacz Obliczenia o wysokiej wydajności (HPC) na platformie Azure.